ربما كنت قد واجهت مهمة الحوسبة المتوازية على dataframes الباندا. يمكن حل هذه المشكلة عن طريق بايثون الأصلية ، وبمساعدة مكتبة رائعة - متوازية. في هذه المقالة سأوضح كيف تسمح لك هذه المكتبة بمعالجة بياناتك باستخدام جميع القدرات المتاحة.
تسمح لك المكتبة بعدم التفكير في عدد سلاسل العمليات وإنشاء العمليات وتوفر واجهة تفاعلية لمراقبة التقدم.
التركيب
pip install pandas jupyter pandarallel requests tqdm
كما ترون ، أقوم أيضًا بتثبيت tqdm. مع ذلك ، سأوضح بوضوح الفرق في سرعة تنفيذ التعليمات البرمجية في نهج متسلسل ومتوازي.
التخصيص
import pandas as pd
import requests
from tqdm import tqdm
tqdm.pandas()
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
يمكنك العثور على قائمة الإعدادات الكاملة في وثائق pandarallel.
إنشاء إطار بيانات
للتجارب ، قم بإنشاء إطار بيانات بسيط - 100 صف وعمود واحد.
df = pd.DataFrame(
[i for i in range(100)],
columns=["sample_column"]
)

مثال على مهمة مناسبة للتوازي
كما نعلم ، يمكن موازاة حل جميع المشاكل. مثال بسيط على مهمة مناسبة هو استدعاء مصدر خارجي ، مثل API أو قاعدة بيانات. في الوظيفة أدناه ، أتصل بواجهة برمجة التطبيقات التي تعيد لي كلمة عشوائية واحدة. هدفي هو إضافة عمود بكلمات مشتقة من واجهة برمجة التطبيقات هذه إلى إطار البيانات.
def function_to_apply(i):
r = requests.get(f'https://random-word-api.herokuapp.com/word').json()
return r[0]
df["sample-word"] = df.sample_column.progress_apply(function_to_apply)
, tqdm, — progress_apply apply. , , progress bar.

"" 35 .
, parallel_apply:
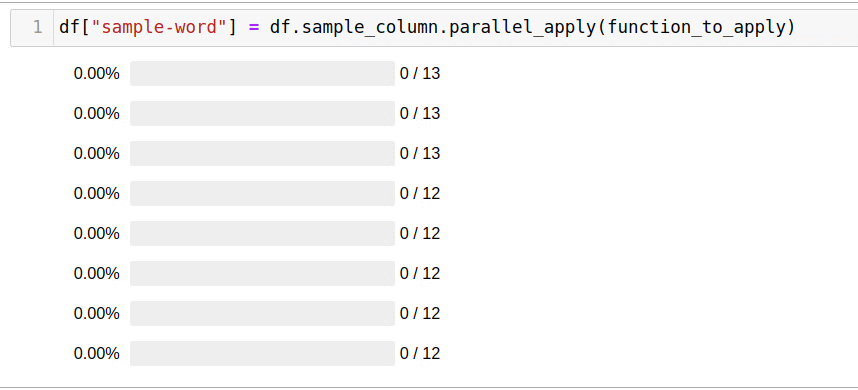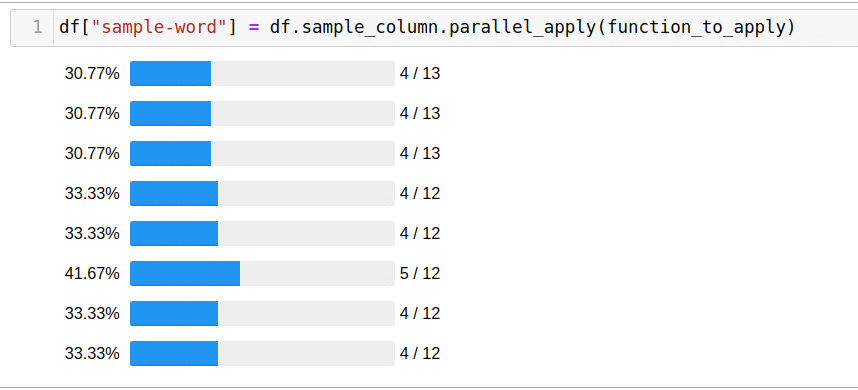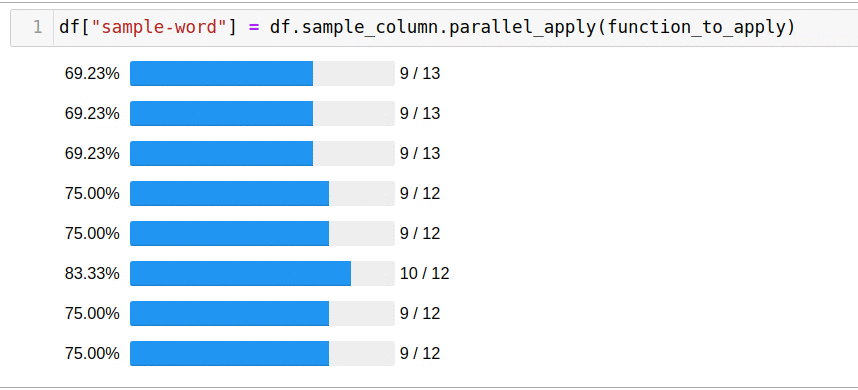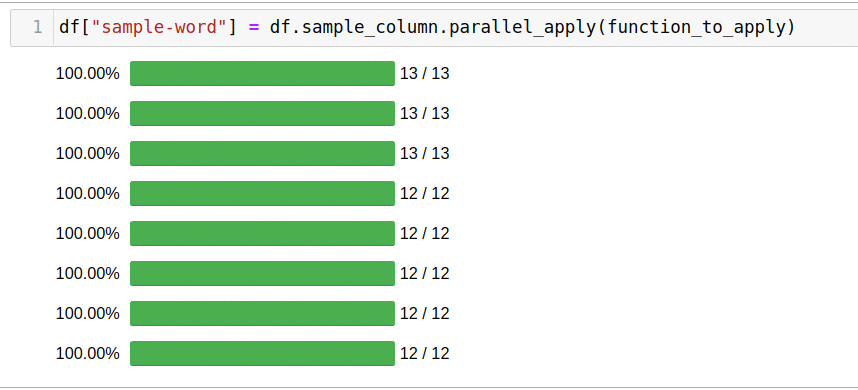
df["sample-word"] = df.sample_column.parallel_apply(function_to_apply)
5 .
pandas , pandarallel, Github .

! — .