ماذا أفعل إذا كنت أرغب في تدوين الكثير من "الحقائق" في قاعدة البيانات بحجم أكبر بكثير مما يمكنها تحمله؟ أولاً ، بالطبع ، نأتي بالبيانات إلى شكل عادي أكثر اقتصادا ونحصل على "قواميس" ، والتي سنكتبها مرة واحدة . ولكن كيف نفعل ذلك بشكل أكثر فاعلية؟هذا هو بالضبط السؤال الذي واجهناه عند تطوير مراقبة وتحليل سجلات خادم PostgreSQL ، عندما تم استنفاد طرق أخرى لتحسين السجل في قاعدة البيانات .سنقوم بإجراء حجز على الفور حيث يقوم هواة الجمع لدينا بتشغيل Node.js ، لذلك لا نتفاعل مع سجلات المعالج وذاكرة التخزين المؤقت بأي شكل من الأشكال. وخيار استخدام "مئات" أو خدمات / قواعد بيانات التخزين المؤقت الخارجية يعطي الكثير من التأخير للتدفقات الواردة من عدة مئات ميغابت في الثانية .لذلك ، نحاول تخزين كل شيء في ذاكرة الوصول العشوائي (RAM) ، وتحديداً في ذاكرة عملية JavaScript. حول كيفية تنظيم هذا بكفاءة أكبر ، وسنذهب أبعد من ذلك.توفر التخزين المؤقت
مهمتنا الرئيسية هي التأكد من أن المثيل الوحيد لأي كائن يدخل في قاعدة البيانات. يتم تكرار هذه النصوص الأصلية بشكل متكرر لاستعلامات SQL ، ونماذج خطط التنفيذ الخاصة بها ، وعقد هذه الخطط - باختصار ، بعض كتل النص .تاريخيا ، UUIDكمعرف استخدمنا -القيمة التي تم الحصول عليها نتيجة الحساب المباشر لتجزئة MD5 من نص الكائن. بعد ذلك ، نتحقق من توفر مثل هذا التجزئة في "القاموس" المحلي في ذاكرة العملية ، وإذا لم يكن موجودًا ، فإننا فقط نكتب إلى قاعدة البيانات في جدول "القاموس".أي أننا لسنا بحاجة إلى تخزين قيمة النص الأصلية نفسها (وأحيانًا يستغرق عشرات الكيلوبايتات) - مجرد حقيقة وجود التجزئة المقابلة في القاموس كافية .القاموس الرئيسي
يمكن الاحتفاظ بمثل هذا القاموس Arrayواستخدامه Array.includes()للتحقق من التوفر ، ولكن هذا أمر زائد تمامًا - ينخفض البحث (على الأقل في الإصدارات السابقة من V8) خطيًا من حجم المصفوفة ، O (N). وفي التطبيقات الحديثة ، على الرغم من كل التحسينات ، تفقد بسرعة 2-3٪.لذلك ، في عصر ما قبل ES6 ، كان التخزين هو الحل التقليدي Object، مع القيم المخزنة كمفاتيح. لكن الجميع حددوا قيم المفاتيح التي يريدها - على سبيل المثال Boolean:var dict = {};
function has(key) {
return dict[key] !== undefined;
}
function add(key) {
dict[key] = true;
}
لكن من الواضح تمامًا أننا نقوم بتخزين الفائض هنا - قيمة المفتاح التي لا يحتاجها أحد. ولكن ماذا لو لم يتم تخزينها على الإطلاق؟ لذلك ظهر الكائن Set .تُظهر الاختبارات أن البحث بمساعدة ما Set.has()يقرب من 20-25٪ أسرع من التحقق الرئيسي ج Object. لكن هذه ليست ميزته الوحيدة. نظرًا لأننا نقوم بتخزين أقل ، فيجب أن نحتاج إلى ذاكرة أقل - وهذا يؤثر بشكل مباشر على الأداء عندما يتعلق الأمر بمئات الآلاف من هذه المفاتيح.لذلك ، Objectحيث يوجد 100 مفتاح UUID في تمثيل نصي ، فإنه يشغل 6216 بايت في الذاكرة :
Setمع نفس المحتويات - 2632 بايت :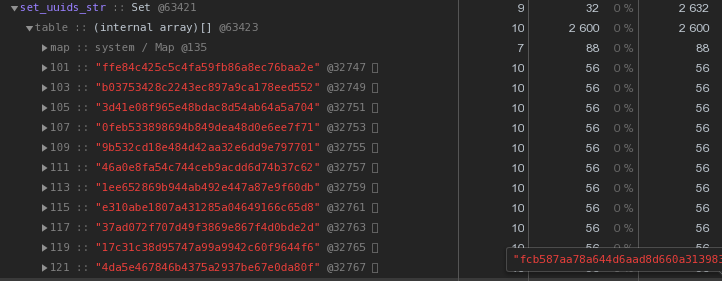 أي أنه
أي أنه Setيعمل بشكل أسرع وفي نفس الوقت يستغرقذاكرة أقل 2.5 مرة - الفائز واضح.نقوم بتحسين تخزين مفاتيح UUID
بشكل عام ، في طبيعة الأنظمة الموزعة ، تعد مفاتيح UUID شائعة جدًا - في VLSI لدينا ، على الأقل ، يتم استخدامها لتحديد المستندات واللوائح في إدارة المستندات الإلكترونية ، والأشخاص في المراسلة ، ...الآن دعونا ننظر بعناية في الصورة أعلاه - كل UUID- المفتاح المخزن في التمثيل السداسي "يكلف" 56 بايت من الذاكرة . ولكن لدينا مئات الآلاف منهم ، لذا فمن المنطقي أن نسأل: "هل من الممكن أن يكون لديك أقل؟"أولاً ، تذكر أن UUID هو معرف 16 بايت. في الأساس جزء من البيانات الثنائية. ولإرسالها عبر البريد الإلكتروني ، على سبيل المثال ، يتم ترميز البيانات الثنائية في base64 - حاول تطبيقها:let str = Buffer.from(uuidstr, 'hex').toString('base64');
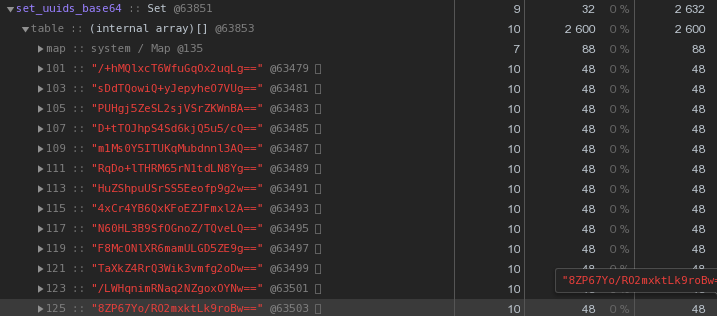 بالفعل 48 بايت لكل منها أفضل ، ولكنها غير كاملة. دعونا نحاول ترجمة التمثيل السداسي العشري مباشرة إلى سلسلة:
بالفعل 48 بايت لكل منها أفضل ، ولكنها غير كاملة. دعونا نحاول ترجمة التمثيل السداسي العشري مباشرة إلى سلسلة:let str = Buffer.from(uuidstr, 'hex').toString('binary');
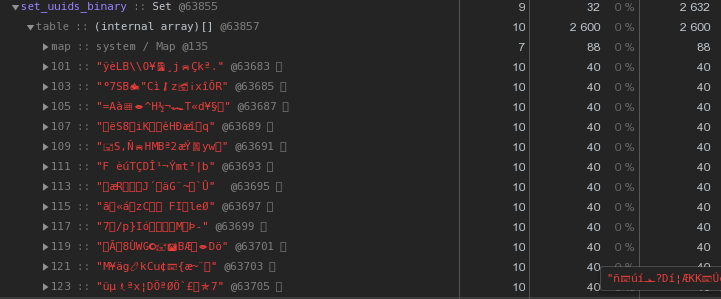 بدلاً من 56 بايت لكل مفتاح - 40 بايت ، توفر 30٪ تقريبًا !
بدلاً من 56 بايت لكل مفتاح - 40 بايت ، توفر 30٪ تقريبًا !سيد ، عامل - أين تخزن القواميس؟
بالنظر إلى أن بيانات المفردات من العمال تتقاطع بقوة شديدة ، فقد قمنا بتخزين القواميس وكتابتها في قاعدة البيانات في العملية الرئيسية ، ونقل البيانات من العمال من خلال آلية رسالة IPC .ومع ذلك ، تم إنفاق جزء كبير من وقت السيد على channel.onread- بمعالجة استلام الحزم بمعلومات "القاموس" من العمليات الفرعية: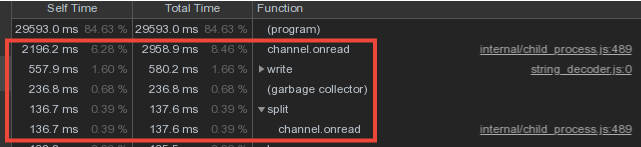
حاجز كتابة مجموعة مزدوجة
الآن دعونا نفكر لثانية - يرسل العمال ويرسلوا سيدهم نفس بيانات المفردات (هذه هي في الأساس قوالب الخطة وهيئات طلب التكرار) ، ويحللها بعرقه و ... لا يفعل شيئًا ، لأنه تم بالفعل إرسالها إلى قاعدة البيانات من قبل !لذا إذا قمنا Set"بحماية" قاعدة البيانات من إعادة التسجيل من المعلم بقاموس ، فلماذا لا نستخدم نفس النهج لـ "حماية" السيد من النقل من العامل؟ .. فيالواقع ، تم ذلك وخفض التكاليف المباشرة لخدمة قناة التبادل ثلاث مرات :
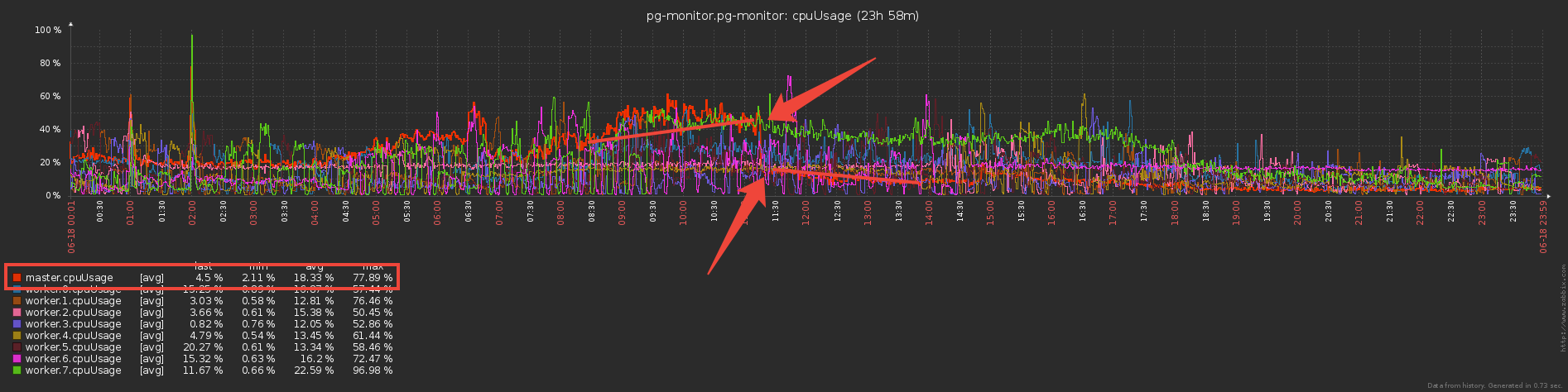 لكن الآن يبدو أن العمال يقومون بمزيد من العمل - تخزين القواميس والتصفية حسبهم؟ أم لا؟ .. في الواقع ، بدأوا في العمل بشكل أقل بكثير ، لأن نقل كميات كبيرة (حتى عبر IPC!) ليس رخيصًا.
لكن الآن يبدو أن العمال يقومون بمزيد من العمل - تخزين القواميس والتصفية حسبهم؟ أم لا؟ .. في الواقع ، بدأوا في العمل بشكل أقل بكثير ، لأن نقل كميات كبيرة (حتى عبر IPC!) ليس رخيصًا.مكافأة جميلة
نظرًا لأن المعالج بدأ الآن في تلقي كمية أقل بكثير من المعلومات ، فقد بدأ في تخصيص ذاكرة أقل بكثير لهذه الحاويات - مما يعني أن الوقت الذي يقضيه في عمل جامع القمامة قد انخفض بشكل كبير ، مما أثر بشكل إيجابي على كمون النظام ككل.يوفر هذا المخطط الحماية ضد الإدخالات المتكررة على مستوى الجامع ، ولكن ماذا لو كان لدينا عدة جامعين؟ الزناد فقط هو الذي سيساعد هنا INSERT ... ON CONFLICT DO NOTHING.تسريع حساب التجزئة
في هندستنا ، تتم معالجة تدفق السجل بالكامل من خادم PostgreSQL واحد من قبل عامل واحد.أي أن خادم واحد هو مهمة واحدة للعامل. في الوقت نفسه ، يتم موازنة تحميل العمال بغرض مهام الخادم بحيث يكون استهلاك وحدة المعالجة المركزية من قبل جميع جامعي العمل هو نفسه تقريبًا. هذا هو مرسل خدمة منفصل."في المتوسط" ، يتعامل كل عامل مع عشرات المهام التي تنتج نفس الحمل الكلي تقريبًا. ومع ذلك ، هناك خوادم تتجاوز بشكل كبير الباقي في عدد إدخالات السجل. وحتى إذا ترك المرسل هذه المهمة هي الوحيدة على العامل ، فإن تنزيلها أعلى بكثير من المهام الأخرى:أزلنا ملف تعريف وحدة المعالجة المركزية لهذا العامل: في الخطوط العليا ، حساب تجزئات MD5. ويتم حسابها حقًا بمبلغ ضخم - لكامل التدفق للأجسام الواردة.
في الخطوط العليا ، حساب تجزئات MD5. ويتم حسابها حقًا بمبلغ ضخم - لكامل التدفق للأجسام الواردة.xxHash
كيفية تحسين هذا الجزء ، باستثناء هذه التجزئة ، لا يمكننا؟قررنا تجربة وظيفة تجزئة أخرى - xxHash ، والتي تنفذ خوارزمية تجزئة غير تشفير سريعة للغاية . والوحدة النمطية لـ Node.js هي xxhash-addon ، والتي تستخدم أحدث مكتبة xxHash 0.7.3 مع خوارزمية XXH3 الجديدة.تحقق من تشغيل كل خيار على مجموعة من الصفوف ذات أطوال مختلفة:const crypto = require('crypto');
const { XXHash3, XXHash64 } = require('xxhash-addon');
const hasher3 = new XXHash3(0xDEADBEAF);
const hasher64 = new XXHash64(0xDEADBEAF);
const buf = Buffer.allocUnsafe(16);
const getBinFromHash = (hash) => buf.fill(hash, 'hex').toString('binary');
const funcs = {
xxhash64 : (str) => hasher64.hash(Buffer.from(str)).toString('binary')
, xxhash3 : (str) => hasher3.hash(Buffer.from(str)).toString('binary')
, md5 : (str) => getBinFromHash(crypto.createHash('md5').update(str).digest('hex'))
};
const check = (hash) => {
let log = [];
let cnt = 10000;
while (cnt--) log.push(crypto.randomBytes(cnt).toString('hex'));
console.time(hash);
log.forEach(funcs[hash]);
console.timeEnd(hash);
};
Object.keys(funcs).forEach(check);
النتائج:xxhash64 : 148.268ms
xxhash3 : 108.337ms
md5 : 317.584ms
كما هو متوقع ، كان xxhash3 أسرع بكثير من MD5 !يبقى للتحقق من مقاومة التصادمات. يتم إنشاء أقسام جداول القواميس لنا كل يوم ، لذا خارج حدود اليوم يمكننا السماح بأمان بتقاطع التجزئة.ولكن فقط في حالة تحققنا بهامش في فترة ثلاثة أيام - ليس نزاعًا واحدًا يناسبنا أكثر من اللازم.استبدال التجزئة
ولكن لا يمكننا ببساطة أخذ وتبادل حقول UUID القديمة في جداول القاموس لتجزئة جديدة ، لأن كل من قاعدة البيانات والواجهة الأمامية تنتظر استمرار الكائنات في التعرف عليها بواسطة UUID.لذلك ، سنضيف ذاكرة تخزين مؤقت أخرى إلى المُجمِّع - من أجل MD5 المحسوب بالفعل. الآن ستكون خريطة ، حيث المفاتيح هي xxhash3 ، القيم هي MD5. بالنسبة للخطوط المتطابقة ، لا نعيد سرد MD5 "باهظ الثمن" مرة أخرى ، ولكن نأخذه من ذاكرة التخزين المؤقت:const getHashFromBin = (bin) => Buffer.from(bin, 'binary').toString('hex');
const dictmd5 = new Map();
const getmd5 = (data) => {
const hash = xxhash(data);
let md5hash = dictmd5.get(hash);
if (!md5hash) {
md5hash = md5(data);
dictmd5.set(hash, getBinFromHash(md5hash));
return md5hash;
}
return getHashFromBin(md5hash);
};
نزيل الملف الشخصي - لقد قل جزء الوقت المخصص لعمليات تجزئة الحوسبة بشكل ملحوظ ، في صحتك! لذا نحسب الآن xxhash3 ، ثم تحقق من ذاكرة التخزين المؤقت MD5 واحصل على MD5 المطلوب ، ثم تحقق من ذاكرة التخزين المؤقت للقاموس - إذا لم يكن هذا MD5 موجودًا ، فقم بإرساله إلى قاعدة البيانات للكتابة.هناك عدد كبير جدًا من عمليات التحقق ... لماذا تحقق من ذاكرة التخزين المؤقت للقاموس إذا قمت بالفعل بفحص ذاكرة التخزين المؤقت MD5؟ اتضح أن جميع ذاكرة التخزين المؤقت في القاموس لم تعد هناك حاجة إليها وأنه يكفي وجود ذاكرة تخزين مؤقت واحدة فقط - بالنسبة إلى MD5 ، والتي سيتم من خلالها إجراء جميع العمليات الأساسية:
لذا نحسب الآن xxhash3 ، ثم تحقق من ذاكرة التخزين المؤقت MD5 واحصل على MD5 المطلوب ، ثم تحقق من ذاكرة التخزين المؤقت للقاموس - إذا لم يكن هذا MD5 موجودًا ، فقم بإرساله إلى قاعدة البيانات للكتابة.هناك عدد كبير جدًا من عمليات التحقق ... لماذا تحقق من ذاكرة التخزين المؤقت للقاموس إذا قمت بالفعل بفحص ذاكرة التخزين المؤقت MD5؟ اتضح أن جميع ذاكرة التخزين المؤقت في القاموس لم تعد هناك حاجة إليها وأنه يكفي وجود ذاكرة تخزين مؤقت واحدة فقط - بالنسبة إلى MD5 ، والتي سيتم من خلالها إجراء جميع العمليات الأساسية: ونتيجة لذلك ، استبدلنا الاختيار في العديد من قواميس "الكائن" بذاكرة تخزين مؤقت MD5 واحدة ، والعملية التي تستهلك موارد كثيرة لحساب MD5 هي يتم تنفيذ Hash للإدخالات الجديدة فقط ، وذلك باستخدام xxhash الأكثر كفاءة للتدفق الوارد.شكراكيلور للمساعدة في إعداد المقال.
ونتيجة لذلك ، استبدلنا الاختيار في العديد من قواميس "الكائن" بذاكرة تخزين مؤقت MD5 واحدة ، والعملية التي تستهلك موارد كثيرة لحساب MD5 هي يتم تنفيذ Hash للإدخالات الجديدة فقط ، وذلك باستخدام xxhash الأكثر كفاءة للتدفق الوارد.شكراكيلور للمساعدة في إعداد المقال.