مرحبا عزيزي المشتركين! ربما تعرف بالفعل أننا أطلقنا دورة جديدة بعنوان "رؤية الكمبيوتر" ، والتي ستبدأ دروسها في الأيام القادمة. تحسبًا لبدء الفصول الدراسية ، قمنا بإعداد ترجمة أخرى مثيرة للاهتمام للانغماس في عالم السيرة الذاتية.
هوايتي تلعب ألعاب الطاولة ، وبما أنني مألوفة قليلاً للشبكات العصبية التلافيفية ، فقد قررت إنشاء تطبيق يمكنه التغلب على شخص في لعبة ورق. أردت إنشاء نموذج من البداية باستخدام مجموعة البيانات الخاصة بي ومعرفة مدى نجاحه في العمل مع مجموعة بيانات صغيرة. قررت أن أبدأ مع لعبة Dobble البسيطة (المعروفة أيضًا باسم Spot it!).إذا كنت لا تعرف ما هو Dobble ، فسأذكر بإيجاز قواعد اللعبة: Dobble هي لعبة بسيطة للتعرف على الأنماط حيث يحاول اللاعبون العثور على صورة مصورة في وقت واحد على بطاقتين. تحتوي كل بطاقة في لعبة Dobble الأصلية على ثمانية أحرف مختلفة ، وبطاقات مختلفة بأحجام مختلفة. تحتوي أي بطاقتين على رمز مشترك واحد فقط. إذا وجدت الرمز أولاً ، فاختر بطاقة. عندما تنتهي مجموعة البطاقات 55 ، فإن البطاقة التي تحتوي على أكبر عدد من البطاقات تفوز. جربها بنفسك: ما هو الرمز الشائع لهاتين البطاقتين؟
جربها بنفسك: ما هو الرمز الشائع لهاتين البطاقتين؟من أين نبدأ؟
الخطوة الأولى في حل أي مهمة لتحليل البيانات هي جمع البيانات. لقد التقطت ست صور لكل بطاقة على الهاتف. في المجموع تحولت 330 صورة. أربعة منهم ترى أدناه. قد تسأل ، هل يكفي هذا لإنشاء شبكة عصبية تلافيفية جيدة؟ سنعود إلى هذا!
معالجة الصورة
حسنًا ، البيانات التي لدينا ، ما هي الخطوة التالية؟ ربما يكون الجزء الأكثر أهمية على طريق النجاح: معالجة الصور. نحن بحاجة للحصول على شخصيات من كل صورة. تنتظرنا بعض الصعوبات هنا. في الصور أعلاه ، من الملاحظ أن بعض الشخصيات أكثر صعوبة في التمييز من غيرها: رجل الثلج والشبح (في الصورة الثالثة) وإبرة (في الرابع) من الألوان الفاتحة ، والبقع (في الصورة الثانية) وعلامة التعجب (في الصورة الرابعة) تتكون من عدة أجزاء . لمعالجة الأحرف الخفيفة ، سنضيف التباين. بعد ذلك سنقوم بتغيير حجم الصورة وحفظها.أضف التباين
لإضافة تباين ، نستخدم مساحة اللون Lab. L هو الخفة ، a هو المكون اللوني في النطاق من الأخضر إلى أرجواني ، و b هو المكون اللوني في النطاق من الأزرق إلى الأصفر. يمكننا بسهولة استخراج هذه المكونات باستخدام OpenCV :import cv2
import imutils
imgname = 'picture1'
image = cv2.imread(f’{imgname}.jpg’)
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
 من اليسار إلى اليمين: الصورة الأصلية ومكون الإضاءة ومكون أ ومكون بالآن نضيف تباينًا إلى مكون الإضاءة ونقوم مرة أخرى بدمج جميع المكونات معًا وتحويلها إلى صورة عادية:
من اليسار إلى اليمين: الصورة الأصلية ومكون الإضاءة ومكون أ ومكون بالآن نضيف تباينًا إلى مكون الإضاءة ونقوم مرة أخرى بدمج جميع المكونات معًا وتحويلها إلى صورة عادية:clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
cl = clahe.apply(l)
limg = cv2.merge((cl,a,b))
final = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)
 من اليسار إلى اليمين: الصورة الأصلية ومكون الخفة والصورة ذات التباين العالي والصورة تم تحويلها إلى RGB
من اليسار إلى اليمين: الصورة الأصلية ومكون الخفة والصورة ذات التباين العالي والصورة تم تحويلها إلى RGBتغيير الحجم
الآن قم بتغيير حجم الصورة واحفظها:resized = cv2.resize(final, (800, 800))
# save the image
cv2.imwrite(f'{imgname}processed.jpg', blurred)
منجز!التعرف على البطاقة والشخصية
الآن بعد معالجة الصورة ، يمكننا الكشف عن بطاقة في الصورة. باستخدام OpenCV نبحث عن الخطوط الخارجية. ثم نقوم بتحويل الصورة إلى نغمات نصفية ، ونختار قيمة العتبة (في حالتنا 190) لإنشاء صورة بالأبيض والأسود والبحث عن مسار. الرمز:image = cv2.imread(f’{imgname}processed.jpg’)
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 190, 255, cv2.THRESH_BINARY)[1]
# find contours
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
output = image.copy()
# draw contours on image
for c in cnts:
cv2.drawContours(output, [c], -1, (255, 0, 0), 3)
 تم تحويل الصورة المعالجة إلى نغمات نصفية باستخدام العتبة وتحديدالخطوط الخارجية إذا قمنا بفرز الخطوط الخارجية حسب المنطقة ، فسوف نجد الكفاف الذي يحتوي على أكبر مساحة - ستكون هذه بطاقتنا. لاستخراج الأحرف ، يمكننا إنشاء خلفية بيضاء.
تم تحويل الصورة المعالجة إلى نغمات نصفية باستخدام العتبة وتحديدالخطوط الخارجية إذا قمنا بفرز الخطوط الخارجية حسب المنطقة ، فسوف نجد الكفاف الذي يحتوي على أكبر مساحة - ستكون هذه بطاقتنا. لاستخراج الأحرف ، يمكننا إنشاء خلفية بيضاء.# sort by area, grab the biggest one
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
# create mask with the biggest contour
mask = np.zeros(gray.shape,np.uint8)
mask = cv2.drawContours(mask, [cnts], -1, 255, cv2.FILLED)
# card in foreground
fg_masked = cv2.bitwise_and(image, image, mask=mask)
# white background (use inverted mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
# combine back- and foreground
final = cv2.bitwise_or(fg_masked, bk_masked)
 القناع ، الخلفية ، الصورة الأمامية ، الصورة النهائيةالآن حان الوقت للتعرف على الحروف! يمكننا استخدام الصورة الناتجة لاكتشاف الخطوط الخارجية عليها مرة أخرى ، هذه الخطوط ستكون رموزًا. إذا قمنا بإنشاء مربع حول كل رمز ، يمكننا استخراج هذه المنطقة. الرمز هنا أطول قليلاً:
القناع ، الخلفية ، الصورة الأمامية ، الصورة النهائيةالآن حان الوقت للتعرف على الحروف! يمكننا استخدام الصورة الناتجة لاكتشاف الخطوط الخارجية عليها مرة أخرى ، هذه الخطوط ستكون رموزًا. إذا قمنا بإنشاء مربع حول كل رمز ، يمكننا استخراج هذه المنطقة. الرمز هنا أطول قليلاً:
gray = cv2.cvtColor(final, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 195, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.bitwise_not(thresh)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:10]
i = 0
for c in cnts:
if cv2.contourArea(c) > 1000:
mask = np.zeros(gray.shape, np.uint8)
mask = cv2.drawContours(mask, [c], -1, 255, cv2.FILLED)
fg_masked = cv2.bitwise_and(image, image, mask=mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
finalcont = cv2.bitwise_or(fg_masked, bk_masked)
output = finalcont.copy()
x,y,w,h = cv2.boundingRect(c)
if w < h:
x += int((w-h)/2)
w = h
else:
y += int((h-w)/2)
h = w
roi = finalcont[y:y+h, x:x+w]
roi = cv2.resize(roi, (400,400))
cv2.imwrite(f"{imgname}_icon{i}.jpg", roi)
i += 1
 صورة بالأبيض والأسود (عتبة) ، الخطوط العريضة المكتشفة ، رمز شبح ورمز قلب (يتم استخراج الأحرف بالأقنعة)
صورة بالأبيض والأسود (عتبة) ، الخطوط العريضة المكتشفة ، رمز شبح ورمز قلب (يتم استخراج الأحرف بالأقنعة)فرز الأحرف
والآن أكثر مملة! تحتاج إلى فرز الشخصيات. ستحتاج إلى أدلة القطار والاختبار والتحقق ، 57 دليلاً لكل منها (لدينا 57 حرفًا مختلفًا في المجموع). هيكل المجلد كما يلي:symbols
├── test
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
├── train
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
└── validation
├── anchor
├── apple
│ ...
└── zebra
سوف يستغرق الأمر بعض الوقت لوضع الأحرف المستخرجة (أكثر من 2500 قطعة) في الدلائل الضرورية! لديّ رمز لإنشاء مجلدات فرعية ومجموعة اختبار ومجموعة أدوات للتحقق على GitHub . ربما في المرة القادمة ، من الأفضل إجراء الفرز بناءً على خوارزمية التجميع ...تدريب الشبكة العصبية التلافيفية
بعد الجزء الممل ، تأتي المتعة مرة أخرى! حان الوقت لإنشاء شبكة عصبية تلافيفية وتدريبها. يمكنك العثور على معلومات حول الشبكات العصبية التلافيفية هنا .معمارية النموذج
لدينا مهمة التصنيف متعدد الفئات مع تسمية واحدة. لكل حرف نحتاج تسمية واحدة. هذا هو السبب في أننا سنحتاج إلى وظيفة لتنشيط طبقة softmax الإخراج مع 57 عقدًا و interropy الفصلي كدالة خسارة.بنية النموذج النهائي هي كما يلي:
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(400, 400, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(57, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
زيادة البيانات
لتحسين الأداء ، استخدمت زيادة البيانات. زيادة البيانات هي عملية زيادة حجم وتنوع البيانات المدخلة. يمكن القيام بذلك عن طريق تدوير الصور الموجودة وتحويلها وقياسها واقتصاصها وقلبها. يمكن لشركة Keras زيادة البيانات بسهولة:
train_dir = 'symbols/train'
validation_dir = 'symbols/validation'
test_dir = 'symbols/test'
train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.1, zoom_range=0.1, horizontal_flip=True, vertical_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
إذا كنت مهتمًا ، فإن الشبح المعزز يبدو مثل هذا: الصورة الأصلية للشبح على اليسار ، الأشباح المعززة في جميع الصور الأخرى
الصورة الأصلية للشبح على اليسار ، الأشباح المعززة في جميع الصور الأخرىتدريب نموذجي
فلنقم بتدريب النموذج ، وحفظه لاستخدامه في التنبؤات ، والتحقق من النتائج.history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)
model.save('models/model.h5')
 توقعات مثالية!
توقعات مثالية!النتائج
النموذج الأساسي الذي تدربت عليه بدون زيادة البيانات والتسرب ومع طبقات أقل. أعطى هذا النموذج النتائج التالية: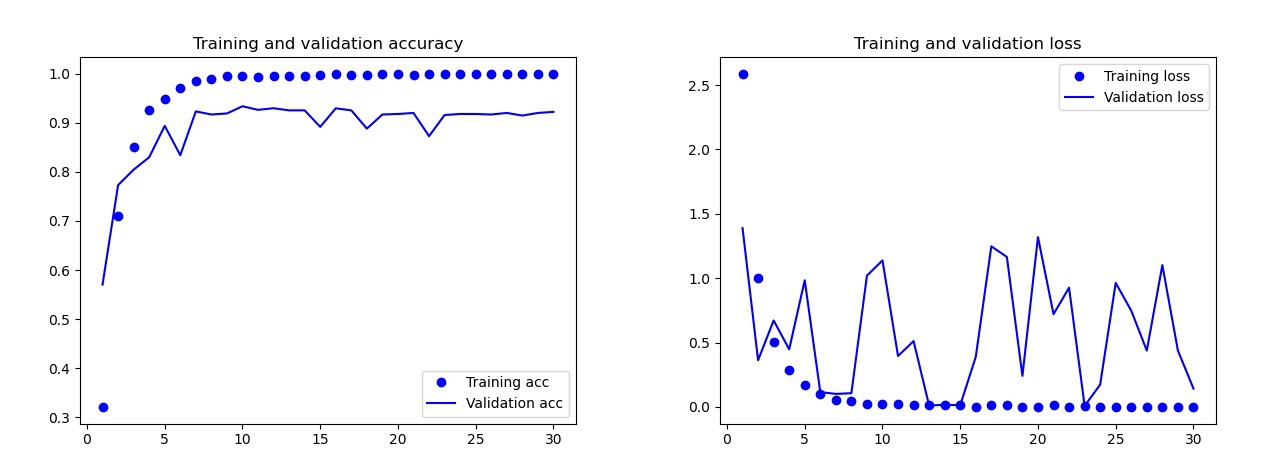 نتائج النموذج الأساسيبالعين المجردة ، من الواضح أن هذا النموذج قد تم إعادة تدريبه. نتائج النسخة النهائية من النموذج (الكود معروض في الأقسام السابقة) أفضل بكثير. على الرسم البياني أدناه يمكنك رؤية الدقة والخسائر أثناء التدريب وعلى مجموعة التحقق.
نتائج النموذج الأساسيبالعين المجردة ، من الواضح أن هذا النموذج قد تم إعادة تدريبه. نتائج النسخة النهائية من النموذج (الكود معروض في الأقسام السابقة) أفضل بكثير. على الرسم البياني أدناه يمكنك رؤية الدقة والخسائر أثناء التدريب وعلى مجموعة التحقق. نتائج النموذج النهائي:في مجموعة الاختبار ، ارتكب هذا النموذج خطأ واحدًا فقط ، اعترف بالقنبلة على أنها قطرة. قررت البقاء على هذا النموذج ، كانت الدقة في مجموعة الاختبار 0.995.
نتائج النموذج النهائي:في مجموعة الاختبار ، ارتكب هذا النموذج خطأ واحدًا فقط ، اعترف بالقنبلة على أنها قطرة. قررت البقاء على هذا النموذج ، كانت الدقة في مجموعة الاختبار 0.995.التعرف على رمز مشترك على بطاقتين
الآن يمكنك البدء في البحث عن الرموز الشائعة على بطاقتين. نستخدم صورتين ، سنقوم بعمل تنبؤات لكل صورة على حدة ونستخدم تقاطع المجموعات لمعرفة الرمز الموجود على كلتا البطاقتين. لدينا 3 خيارات عمل:- حدث خطأ أثناء التنبؤ: لم يتم العثور على أحرف مشتركة.
- يوجد رمز واحد عند التقاطع (يمكن أن يكون التنبؤ صحيحًا أو خطأ).
- هناك أكثر من حرف عند التقاطع. في هذه الحالة ، أختار الرمز ذو الاحتمال الأعلى (متوسط كلا التنبؤين).
رمز للتنبؤ كل مجموعة على الصورتين في الكتالوج الأكاذيب مع جيثب الصورة " main.py.وهنا النتائج:
استنتاج
أليس هذا هو النموذج المثالي؟ للاسف لا. عندما التقطت صورًا جديدة للبطاقات وأعطيتها نماذج للتنبؤ ، كانت هناك بعض المشاكل مع رجل الثلج. في بعض الأحيان يتعرف على العين أو الحمار الوحشي كرجل ثلج! ونتيجة لذلك ، كانت النتائج أحيانًا غريبة: حسنًا ، أين رجل الثلج هنا؟هل هذا النموذج أفضل من الإنسان؟ اعتمادًا على ما نحتاج إليه: يتعرف الأشخاص بشكل مثالي ، ولكن النموذج يقوم بذلك بشكل أسرع! لاحظت الوقت الذي يتأقلم فيه الكمبيوتر: أعطيت مجموعة من 55 بطاقة وكان عليّ الحصول على رمز مشترك لكل مجموعة من بطاقتين. في المجموع ، هذه 1485 مجموعة. قام الكمبيوتر بذلك في أقل من 140 ثانية. لقد ارتكب بعض الأخطاء ، لكنه بالتأكيد سيتغلب على أي شخص عندما يتعلق الأمر بالسرعة!
حسنًا ، أين رجل الثلج هنا؟هل هذا النموذج أفضل من الإنسان؟ اعتمادًا على ما نحتاج إليه: يتعرف الأشخاص بشكل مثالي ، ولكن النموذج يقوم بذلك بشكل أسرع! لاحظت الوقت الذي يتأقلم فيه الكمبيوتر: أعطيت مجموعة من 55 بطاقة وكان عليّ الحصول على رمز مشترك لكل مجموعة من بطاقتين. في المجموع ، هذه 1485 مجموعة. قام الكمبيوتر بذلك في أقل من 140 ثانية. لقد ارتكب بعض الأخطاء ، لكنه بالتأكيد سيتغلب على أي شخص عندما يتعلق الأمر بالسرعة! لا أعتقد أن إنشاء نموذج عمل 100٪ أمر صعب. يمكن تحقيق ذلك من خلال التدريب على النقل. لفهم ما يفعله النموذج ، يمكننا تصور طبقات لصورة الاختبار. يمكنك فعلها في المرة القادمة!
لا أعتقد أن إنشاء نموذج عمل 100٪ أمر صعب. يمكن تحقيق ذلك من خلال التدريب على النقل. لفهم ما يفعله النموذج ، يمكننا تصور طبقات لصورة الاختبار. يمكنك فعلها في المرة القادمة!
تعرف على المزيد حول الدورة واجتاز اختبار القبول