 (الصورة مأخوذة من هنا )
(الصورة مأخوذة من هنا )
نود أن نخبرك اليوم بمهمة المعالجة اللاحقة لنتائج التعرف على الحقول النصية بناءً على معرفة مسبقة بالحقل. في وقت سابق ، كتبنا بالفعل عن طريقة تصحيح المجال على أساس Trigrams ، والتي تسمح لك بتصحيح بعض أخطاء التعرف على الكلمات المكتوبة باللغات الطبيعية. ومع ذلك ، فإن جزءًا كبيرًا من المستندات المهمة ، بما في ذلك وثائق الهوية ، هي حقول ذات طبيعة مختلفة - التواريخ والأرقام ورموز VIN للسيارات وأرقام TIN و SNILS والمناطق القابلة للقراءة آليًامع المجموع الاختباري والمزيد. على الرغم من أنه لا يمكن أن تُنسب إلى حقول اللغة الطبيعية ، إلا أن هذه الحقول غالبًا ما تحتوي على بعض النماذج اللغوية ، ضمنيًا في بعض الأحيان ، مما يعني أنه يمكن أيضًا تطبيق بعض خوارزميات التصحيح عليها. في هذا المنشور ، سنناقش آليتين لنتائج ما بعد المعالجة التي يمكن استخدامها لعدد كبير من المستندات وأنواع الحقول.يمكن تقسيم النموذج اللغوي للحقل بشكل مشروط إلى ثلاثة مكونات:- بناء الجملة : القواعد التي تحكم هيكل تمثيل حقل النص. مثال: يتم تمثيل حقل "تاريخ انتهاء صلاحية المستند" في منطقة قابلة للقراءة آليًا على هيئة سبعة أرقام "DDDDDDD".
- : , . : “ ” - – , 3- 4- – , 5- 6- – , 7- – .
- : , . : “ ” , , “ ”.
الحصول على معلومات حول البنية الدلالية والنحوية للوثيقة والمجال المعترف به ، يمكنك بناء خوارزمية متخصصة لمعالجة ما بعد نتيجة الاعتراف. ومع ذلك ، مع الأخذ في الاعتبار الحاجة إلى دعم وتطوير أنظمة التعرف وتعقيد تطورها ، من المثير للاهتمام النظر في الأساليب والأدوات "العالمية" التي تسمح ، بأقل جهد (من المطورين) ، ببناء خوارزمية جيدة إلى حد ما بعد المعالجة تعمل مع فئة واسعة الوثائق والحقول. سيتم توحيد منهجية إعداد ودعم مثل هذه الخوارزمية ، ولن يكون سوى نموذج اللغة مكونًا متغيرًا في بنية الخوارزمية.تجدر الإشارة إلى أن المعالجة اللاحقة لنتائج التعرف على حقل النص ليست مفيدة دائمًا ، بل وأحيانًا ضارة: إذا كان لديك وحدة التعرف على السطور جيدة إلى حد ما وكنت تعمل في أنظمة حرجة مع وثائق تعريف ، فإن نوعًا ما من المعالجة اللاحقة من الأفضل تقليل النتائج وتحقيقها "كما هي" ، أو مراقبة أي تغييرات بوضوح وإبلاغ العميل بها. ومع ذلك ، في كثير من الحالات ، عندما يُعرف أن المستند صالح ، وأن نموذج اللغة للحقل موثوق به ، فإن استخدام خوارزميات ما بعد المعالجة يمكن أن يزيد بشكل كبير من جودة التعرف النهائية.لذا ، ستناقش المقالة طريقتين للمعالجة اللاحقة ، تدعي العالمية. يعتمد الأول على المحولات المحدودة المرجحة ، ويتطلب وصفًا لنموذج اللغة في شكل آلة حالة محدودة ، ليس سهل الاستخدام للغاية ، ولكنه أكثر عالمية. أما الطريقة الثانية فهي أسهل في الاستخدام وأكثر فاعلية ، وتتطلب فقط كتابة دالة للتحقق من صحة قيمة الحقل ، ولكن لها أيضًا عدد من العيوب.طريقة المرسل النهائي الموزون
تم وصف نموذج جميل وعام إلى حد ما يسمح لك ببناء خوارزمية عالمية لنتائج التعرف بعد المعالجة في هذا العمل . يعتمد النموذج على بنية بيانات محولات الحالة المحدودة الموزونة (WFST).WFSTs عبارة عن تعميم لآليات الحالة المحدودة المرجحة - إذا كان جهاز الحالة المحدودة المرجحة يشفر بعض اللغة المرجحة  (أي مجموعة مرجحة من الخطوط فوق أبجدية معينة
(أي مجموعة مرجحة من الخطوط فوق أبجدية معينة  ) ، ثم يرمز WFST خريطة مرجحة للغة
) ، ثم يرمز WFST خريطة مرجحة للغة  فوق الأبجدية
فوق الأبجدية  إلى لغة
إلى لغة  فوق الأبجدية
فوق الأبجدية  . تقوم آلة الحالة المحدودة المرجحة ، التي تأخذ خيطًا
. تقوم آلة الحالة المحدودة المرجحة ، التي تأخذ خيطًا  على الأبجدية ، بتعيين وزن معين لها
على الأبجدية ، بتعيين وزن معين لها  ، في حين أن WFST ، تأخذ سلسلة
، في حين أن WFST ، تأخذ سلسلة فوق الأبجدية ، يربطها مجموعة من أزواج (ربما لانهائية)
فوق الأبجدية ، يربطها مجموعة من أزواج (ربما لانهائية)  ، حيث
، حيث  يوجد الخط فوق الأبجدية الذي يتم تحويل الخط إليه ،
يوجد الخط فوق الأبجدية الذي يتم تحويل الخط إليه ،  وهو وزن هذا التحويل. يتميز كل انتقال للمحول بحالتين (يتم الانتقال بينهما) ، وحروف الإدخال (من الأبجدية ) ، وحروف الإخراج (من الأبجدية ) ووزن الانتقال. يعتبر الحرف الفارغ (سلسلة فارغة) عنصرًا لكل من الأبجدية. وزن السلسلة
وهو وزن هذا التحويل. يتميز كل انتقال للمحول بحالتين (يتم الانتقال بينهما) ، وحروف الإدخال (من الأبجدية ) ، وحروف الإخراج (من الأبجدية ) ووزن الانتقال. يعتبر الحرف الفارغ (سلسلة فارغة) عنصرًا لكل من الأبجدية. وزن السلسلة  إلى سلسلة التحويل
إلى سلسلة التحويل  هو مجموع منتجات أوزان الانتقال على طول جميع المسارات التي تشكل سلسلة أحرف الإدخال فيها السلسلة ، وسلسلة أحرف الإخراج تشكل السلسلة، والتي تنقل المحول من الحالة الأولية إلى إحدى المحطات الطرفية.يتم تحديد عملية التكوين عبر WFST ، والتي تعتمد عليها طريقة المعالجة اللاحقة. فلتعط محولين
هو مجموع منتجات أوزان الانتقال على طول جميع المسارات التي تشكل سلسلة أحرف الإدخال فيها السلسلة ، وسلسلة أحرف الإخراج تشكل السلسلة، والتي تنقل المحول من الحالة الأولية إلى إحدى المحطات الطرفية.يتم تحديد عملية التكوين عبر WFST ، والتي تعتمد عليها طريقة المعالجة اللاحقة. فلتعط محولين  و
و  ، و تحويل خط أعلاه
، و تحويل خط أعلاه  إلى خط أعلاه
إلى خط أعلاه  مع الوزن
مع الوزن  ، و تحويل أكثر من خط
، و تحويل أكثر من خط  أعلاه
أعلاه  مع الوزن
مع الوزن  . ثم يقوم المحول
. ثم يقوم المحول  ، الذي يسمى تكوين المحولات ، بتحويل السلسلة إلى سلسلة بوزن
، الذي يسمى تكوين المحولات ، بتحويل السلسلة إلى سلسلة بوزن . إن تكوين المحولات عملية مكلفة حسابياً ، ولكن يمكن حسابها بتكاليف - يمكن بناء حالات وتحولات محول الطاقة الناتج في الوقت الذي تحتاج فيه إلى الوصول إليه.تعتمد خوارزمية المعالجة اللاحقة لنتائج التعرف على WFST على ثلاثة مصادر رئيسية للمعلومات -
. إن تكوين المحولات عملية مكلفة حسابياً ، ولكن يمكن حسابها بتكاليف - يمكن بناء حالات وتحولات محول الطاقة الناتج في الوقت الذي تحتاج فيه إلى الوصول إليه.تعتمد خوارزمية المعالجة اللاحقة لنتائج التعرف على WFST على ثلاثة مصادر رئيسية للمعلومات -  نموذج الفرضية ، ونموذج الخطأ ،
نموذج الفرضية ، ونموذج الخطأ ،  ونموذج اللغة
ونموذج اللغة  . يتم تقديم جميع النماذج الثلاثة في شكل محولات الطاقة النهائية المرجحة:
. يتم تقديم جميع النماذج الثلاثة في شكل محولات الطاقة النهائية المرجحة:- ( WFST – , ), , . ,
 , ():
, ():  ,
,  –
–  - ,
- ,  – () .
– () .  - , :
- , :  - ,
- ,  - – ,
- – ,  -
-  -
-  . - , . , .
. - , . , .
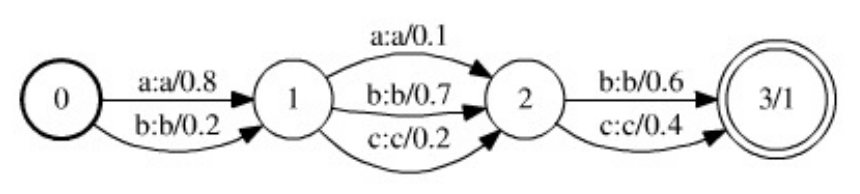
. 1. , WFST ( ). .
- , , . WFST ( ). . , .
- . .. , ( ).
بعد تحديد نموذج الفرضيات والأخطاء ونموذج اللغة ، يمكن الآن طرح مهمة نتائج التعرف بعد المعالجة على النحو التالي: النظر في تكوين جميع النماذج الثلاثة  (من حيث تكوين WFST). يقوم المحول
(من حيث تكوين WFST). يقوم المحول  بترميز جميع التحويلات الممكنة للسلاسل من نموذج الفرضية إلى سلاسل من نموذج اللغة ، وتطبيق التحولات المشفرة في نموذج الخطأ إلى السلاسل . علاوة على ذلك ، فإن وزن مثل هذا التحول يتضمن وزن الفرضية الأصلية ، ووزن التحول ، ووزن السلسلة الناتجة (في حالة نموذج اللغة المرجحة). وفقًا لذلك ، في مثل هذا النموذج ، تتوافق المعالجة اللاحقة المثلى لنتيجة التعرف مع المسار الأمثل (من حيث الوزن) في المحولترجمتها من البداية إلى إحدى الدول النهائية. سوف يتوافق خط الإدخال على طول هذا المسار مع الفرضية الأولية المحددة ، وخط الإخراج إلى نتيجة التعرف المصححة. يمكن البحث عن المسار الأمثل باستخدام الخوارزميات للعثور على أقصر المسارات في الرسوم البيانية الموجهة.مزايا هذا النهج هي العمومية والمرونة. يمكن توسيع نموذج الخطأ ، على سبيل المثال ، بسهولة بطريقة تأخذ في الحذف عمليات حذف وإضافات الأحرف (لهذا ، يجدر فقط إضافة انتقالات بإخراج فارغ أو رمز إدخال ، على التوالي ، إلى نموذج الخطأ). ومع ذلك ، فإن هذا النموذج له عيوب كبيرة. أولاً ، يجب تقديم نموذج اللغة هنا كمحول محدود محدد الوزن. بالنسبة للغات المعقدة ، يمكن أن يتحول مثل هذا الأوتوماتيكي إلى مرهق إلى حد ما ، وفي حالة تغيير أو تحسين نموذج اللغة ، سيكون من الضروري إعادة بنائه. وتجدر الإشارة أيضًا إلى أن تكوين المحولات الثلاثة نتيجة لذلك ، كقاعدة عامة ، محول طاقة أكبر ،ويتم حساب هذه التركيبة في كل مرة تبدأ فيها مرحلة ما بعد المعالجة نتيجة تمييز واحدة. نظرًا لحجم التكوين ، يجب إجراء البحث عن المسار الأمثل في الممارسة بأساليب الكشف ، مثل البحث * A.باستخدام نموذج التحقق من القواعد النحوية ، من الممكن إنشاء نموذج أبسط لمهمة نتائج التعرف بعد المعالجة ، والتي لن تكون عامة مثل النموذج القائم على WFST ، ولكن يمكن توسيعها بسهولة وسهولة تنفيذها.التدقيق النحوي هو زوج
بترميز جميع التحويلات الممكنة للسلاسل من نموذج الفرضية إلى سلاسل من نموذج اللغة ، وتطبيق التحولات المشفرة في نموذج الخطأ إلى السلاسل . علاوة على ذلك ، فإن وزن مثل هذا التحول يتضمن وزن الفرضية الأصلية ، ووزن التحول ، ووزن السلسلة الناتجة (في حالة نموذج اللغة المرجحة). وفقًا لذلك ، في مثل هذا النموذج ، تتوافق المعالجة اللاحقة المثلى لنتيجة التعرف مع المسار الأمثل (من حيث الوزن) في المحولترجمتها من البداية إلى إحدى الدول النهائية. سوف يتوافق خط الإدخال على طول هذا المسار مع الفرضية الأولية المحددة ، وخط الإخراج إلى نتيجة التعرف المصححة. يمكن البحث عن المسار الأمثل باستخدام الخوارزميات للعثور على أقصر المسارات في الرسوم البيانية الموجهة.مزايا هذا النهج هي العمومية والمرونة. يمكن توسيع نموذج الخطأ ، على سبيل المثال ، بسهولة بطريقة تأخذ في الحذف عمليات حذف وإضافات الأحرف (لهذا ، يجدر فقط إضافة انتقالات بإخراج فارغ أو رمز إدخال ، على التوالي ، إلى نموذج الخطأ). ومع ذلك ، فإن هذا النموذج له عيوب كبيرة. أولاً ، يجب تقديم نموذج اللغة هنا كمحول محدود محدد الوزن. بالنسبة للغات المعقدة ، يمكن أن يتحول مثل هذا الأوتوماتيكي إلى مرهق إلى حد ما ، وفي حالة تغيير أو تحسين نموذج اللغة ، سيكون من الضروري إعادة بنائه. وتجدر الإشارة أيضًا إلى أن تكوين المحولات الثلاثة نتيجة لذلك ، كقاعدة عامة ، محول طاقة أكبر ،ويتم حساب هذه التركيبة في كل مرة تبدأ فيها مرحلة ما بعد المعالجة نتيجة تمييز واحدة. نظرًا لحجم التكوين ، يجب إجراء البحث عن المسار الأمثل في الممارسة بأساليب الكشف ، مثل البحث * A.باستخدام نموذج التحقق من القواعد النحوية ، من الممكن إنشاء نموذج أبسط لمهمة نتائج التعرف بعد المعالجة ، والتي لن تكون عامة مثل النموذج القائم على WFST ، ولكن يمكن توسيعها بسهولة وسهولة تنفيذها.التدقيق النحوي هو زوج  ، حيث توجد الأبجدية ،
، حيث توجد الأبجدية ،  وهو مسند لقبول سلسلة على الأبجدية ، أي
وهو مسند لقبول سلسلة على الأبجدية ، أي  . يقوم التدقيق النحوي بتشفير لغة معينة فوق الأبجدية كما يلي:
. يقوم التدقيق النحوي بتشفير لغة معينة فوق الأبجدية كما يلي:  ينتمي السطر إلى اللغة إذا كان للمسند قيمة حقيقية في هذا السطر. تجدر الإشارة إلى أن تدقيق القواعد هو طريقة أكثر عمومية لتمثيل نموذج اللغة من آلة الحالة. في الواقع ، أي لغة تمثل آلة الدولة المحدودة، يمكن تمثيلها في شكل قواعد تدقيق (مع المسند
ينتمي السطر إلى اللغة إذا كان للمسند قيمة حقيقية في هذا السطر. تجدر الإشارة إلى أن تدقيق القواعد هو طريقة أكثر عمومية لتمثيل نموذج اللغة من آلة الحالة. في الواقع ، أي لغة تمثل آلة الدولة المحدودة، يمكن تمثيلها في شكل قواعد تدقيق (مع المسند  ، أين
، أين  هي مجموعة الخطوط المقبولة من قبل الأوتوماتيكي . ومع ذلك ، لا يمكن تمثيل جميع اللغات التي يمكن تمثيلها على أنها تدقيق نحوي كآلية محدودة في الحالة العامة (على سبيل المثال ، لغة كلمات ذات طول غير محدود فوق الأبجدية
هي مجموعة الخطوط المقبولة من قبل الأوتوماتيكي . ومع ذلك ، لا يمكن تمثيل جميع اللغات التي يمكن تمثيلها على أنها تدقيق نحوي كآلية محدودة في الحالة العامة (على سبيل المثال ، لغة كلمات ذات طول غير محدود فوق الأبجدية  ، حيث يكون عدد الأحرف
، حيث يكون عدد الأحرف  أكبر من عدد الأحرف
أكبر من عدد الأحرف  .)السماح بإعطاء نتيجة التعرف (نموذج الفرضية) كتسلسل من الخلايا(كما في القسم السابق). للراحة ، نفترض أن كل خلية تحتوي على بدائل K وأن جميع التقديرات البديلة تأخذ قيمة إيجابية. يعتبر تقييم (وزن) السلسلة ناتجًا لتصنيفات كل حرف من أحرف هذه السلسلة. إذا تم تحديد نموذج اللغة في شكل تدقيق نحوي ، فيمكن صياغة مشكلة ما بعد المعالجة كمشكلة تحسين (تكبير) منفصلة على مجموعة من عناصر التحكم
.)السماح بإعطاء نتيجة التعرف (نموذج الفرضية) كتسلسل من الخلايا(كما في القسم السابق). للراحة ، نفترض أن كل خلية تحتوي على بدائل K وأن جميع التقديرات البديلة تأخذ قيمة إيجابية. يعتبر تقييم (وزن) السلسلة ناتجًا لتصنيفات كل حرف من أحرف هذه السلسلة. إذا تم تحديد نموذج اللغة في شكل تدقيق نحوي ، فيمكن صياغة مشكلة ما بعد المعالجة كمشكلة تحسين (تكبير) منفصلة على مجموعة من عناصر التحكم  (مجموعة من جميع خطوط الطول فوق الأبجدية ) مع تقدير المقبولية ووظيفية
(مجموعة من جميع خطوط الطول فوق الأبجدية ) مع تقدير المقبولية ووظيفية  ، أين
، أين  هو تقدير الرمز
هو تقدير الرمز  في خلية إيث .يمكن حل أي مشكلة تحسين منفصلة (أي ، مع مجموعة محدودة من عناصر التحكم) باستخدام تعداد كامل لعناصر التحكم. تتكرر الخوارزمية الموصوفة بكفاءة فوق عناصر التحكم (الصفوف) بترتيب تنازلي للقيمة الوظيفية حتى يقبل صدق الصلاحية القيمة الحقيقية. قمنا بتعيين
في خلية إيث .يمكن حل أي مشكلة تحسين منفصلة (أي ، مع مجموعة محدودة من عناصر التحكم) باستخدام تعداد كامل لعناصر التحكم. تتكرر الخوارزمية الموصوفة بكفاءة فوق عناصر التحكم (الصفوف) بترتيب تنازلي للقيمة الوظيفية حتى يقبل صدق الصلاحية القيمة الحقيقية. قمنا بتعيين  الحد الأقصى لعدد التكرارات للخوارزمية ، أي الحد الأقصى لعدد الصفوف مع أقصى تقدير يتم حساب المسند عليه.أولا، فإننا سوف فرز البدائل بترتيب تنازلي من التقديرات، وسوف نزيد من افتراض أن عدم المساواة
الحد الأقصى لعدد التكرارات للخوارزمية ، أي الحد الأقصى لعدد الصفوف مع أقصى تقدير يتم حساب المسند عليه.أولا، فإننا سوف فرز البدائل بترتيب تنازلي من التقديرات، وسوف نزيد من افتراض أن عدم المساواة  ل هو الصحيح لأية خلية
ل هو الصحيح لأية خلية  . سيكون الموقف هو تسلسل المؤشرات
. سيكون الموقف هو تسلسل المؤشرات  المقابلة للصف
المقابلة للصف . تقييم المنصب ، أي قيمة وظيفية في هذا الموقف، النظر في تقييم بدائل المنتج المقابلة لمؤشرات المدرجة في موقف:
. تقييم المنصب ، أي قيمة وظيفية في هذا الموقف، النظر في تقييم بدائل المنتج المقابلة لمؤشرات المدرجة في موقف:  . لتخزين المواقف ، تحتاج إلى بنية بيانات PositionBase ، والتي تسمح لك بإضافة مواقع جديدة (مع الحصول على عناوينها) ، والحصول على الموضع في العنوان والتحقق مما إذا كان الموضع المحدد مضافًا إلى قاعدة البيانات.في عملية إدراج المراكز ، سنحدد مركزًا غير مرئي بأعلى تصنيف ، ثم نضيف إلى قائمة الانتظار للنظر في PositionQue جميع المراكز التي يمكن الحصول عليها من المركز الحالي عن طريق إضافة واحد إلى واحد من المؤشرات المدرجة في المركز. ستتضمن قائمة الانتظار للنظر PositionQueue ثلاث مرات
. لتخزين المواقف ، تحتاج إلى بنية بيانات PositionBase ، والتي تسمح لك بإضافة مواقع جديدة (مع الحصول على عناوينها) ، والحصول على الموضع في العنوان والتحقق مما إذا كان الموضع المحدد مضافًا إلى قاعدة البيانات.في عملية إدراج المراكز ، سنحدد مركزًا غير مرئي بأعلى تصنيف ، ثم نضيف إلى قائمة الانتظار للنظر في PositionQue جميع المراكز التي يمكن الحصول عليها من المركز الحالي عن طريق إضافة واحد إلى واحد من المؤشرات المدرجة في المركز. ستتضمن قائمة الانتظار للنظر PositionQueue ثلاث مرات  ، حيث
، حيث - تقدير للموقف لم تتم
- تقدير للموقف لم تتم  مراجعته ، - عنوان الموضع المعروض في PositionBase الذي تم الحصول على هذا الموضع منه
مراجعته ، - عنوان الموضع المعروض في PositionBase الذي تم الحصول على هذا الموضع منه  - - فهرس عنصر الموضع بالعنوان الذي تمت زيادته بواحد للحصول على هذا الموضع. سيتطلب تحديد موضع قائمة انتظار PositionQueue بنية بيانات تسمح لك بإضافة ثلاثية أخرى ، وكذلك استرداد ثلاثية بأقصى تصنيف .عند التكرار الأول للخوارزمية ، من الضروري النظر في الموضع
- - فهرس عنصر الموضع بالعنوان الذي تمت زيادته بواحد للحصول على هذا الموضع. سيتطلب تحديد موضع قائمة انتظار PositionQueue بنية بيانات تسمح لك بإضافة ثلاثية أخرى ، وكذلك استرداد ثلاثية بأقصى تصنيف .عند التكرار الأول للخوارزمية ، من الضروري النظر في الموضع  بأقصى تقدير. إذا أخذ المسند القيمة الحقيقية على الخط المقابل لهذا الموضع ، فإن الخوارزمية تنتهي. خلاف ذلك ، تتم إضافة الموقف إلى PositionBase ، وفييضيف PositionQueue كل ثلاث مرات للعرض
بأقصى تقدير. إذا أخذ المسند القيمة الحقيقية على الخط المقابل لهذا الموضع ، فإن الخوارزمية تنتهي. خلاف ذلك ، تتم إضافة الموقف إلى PositionBase ، وفييضيف PositionQueue كل ثلاث مرات للعرض  ، للجميع
، للجميع  ، حيث
، حيث  يوجد عنوان موضع البدء في PositionBase . في كل تكرار لاحق للخوارزمية ، يتم استخراج الثلاثي مع القيمة القصوى للتقدير من PositionQueue ، يتم استعادة الموضع المعني إلى عنوان الموضع الأصلي والفهرس . إذا تمت إضافة الموضع بالفعل إلى قاعدة البيانات الخاصة بمواضع PositionBase المدروسة ، يتم تخطيها ويتم استخراج الثلاثة التالية مع القيمة القصوى للتقدير من PositionQueue . خلاف ذلك ، يتم التحقق من القيمة الأصلية على السطر المقابل للموقف . إذا المسنديأخذ القيمة الحقيقية على هذا الخط ، ثم تنتهي الخوارزمية. إذا لم يقبل المسند القيمة الحقيقية على هذا السطر ، فسيتم إضافة السطر إلى PositionBase (مع تعيين العنوان
يوجد عنوان موضع البدء في PositionBase . في كل تكرار لاحق للخوارزمية ، يتم استخراج الثلاثي مع القيمة القصوى للتقدير من PositionQueue ، يتم استعادة الموضع المعني إلى عنوان الموضع الأصلي والفهرس . إذا تمت إضافة الموضع بالفعل إلى قاعدة البيانات الخاصة بمواضع PositionBase المدروسة ، يتم تخطيها ويتم استخراج الثلاثة التالية مع القيمة القصوى للتقدير من PositionQueue . خلاف ذلك ، يتم التحقق من القيمة الأصلية على السطر المقابل للموقف . إذا المسنديأخذ القيمة الحقيقية على هذا الخط ، ثم تنتهي الخوارزمية. إذا لم يقبل المسند القيمة الحقيقية على هذا السطر ، فسيتم إضافة السطر إلى PositionBase (مع تعيين العنوان  ) ، تتم إضافة جميع المواضع المشتقة إلى قائمة انتظار PositionQue ، ويستمر التكرار التالي.
) ، تتم إضافة جميع المواضع المشتقة إلى قائمة انتظار PositionQue ، ويستمر التكرار التالي.FindSuitableString(M, N, K, P, C[1], ..., C[N]):
i : 1 ... N:
C[i]
( )
PositionBase PositionQueue
S_1 = {1, 1, 1, ..., 1}
P(S_1):
: S_1,
( )
S_1 PositionBase R(S_1)
i : 1 ... N:
K > 1, :
<Q * q[i][2] / q[i][1], R(S_1), i> PositionQueue
( )
( )
PositionBase M:
PositionQueue:
PositionQueue <Q, R, I> Q
S_from = PositionBase R
S_curr = {S_from[1], S_from[2], ..., S_from[I] + 1, ..., S_from[N]}
S_curr PositionBase:
:
S_curr PositionBase R(S_curr)
( )
P(S_curr):
: S_curr,
( )
i : 1 ... N:
K > S_curr[i]:
<Q * q[i][S_curr[i] + 1] / q[i][S_curr[i]],
R(S_curr),
i> PositionQueue
( )
( )
( )
( )
M
لاحظ أنه خلال التكرارات سيتم التحقق من المسند أكثر من مرة ، ولن يكون هناك المزيد من الإضافات إلى PositionBase ، وإضافة إلى PositionQueue ، والاستخراج من PositionQueue ، وكذلك البحث في PositionBase لن يحدث أكثر من  مرة واحدة. إذا كان تطبيق PositionQueue يستخدم "مجموعة" من بنية البيانات ، وبالنسبة للمؤسسة PositionBase باستخدام بنية البيانات "Bor" ، فإن تعقيد الخوارزمية هو
مرة واحدة. إذا كان تطبيق PositionQueue يستخدم "مجموعة" من بنية البيانات ، وبالنسبة للمؤسسة PositionBase باستخدام بنية البيانات "Bor" ، فإن تعقيد الخوارزمية هو  ، حيث
، حيث  - اختبار trudoemost يتنبأ بطول الخط .ربما يكون العيب الأكثر أهمية للخوارزمية بناءً على التدقيق النحوي هو أنه لا يمكن معالجة الفرضيات ذات الأطوال المختلفة (التي قد تنشأ بسبب أخطاء التقسيم : فقدان أو حدوث أحرف إضافية ، لصق الحروف والقطع ، وما إلى ذلك) ، في حين يمكن ترميز التغييرات في الفرضيات مثل "حذف حرف" أو "إضافة حرف" أو حتى "استبدال حرف بزوج" في نموذج الخطأ في الخوارزمية القائمة على WFST.ومع ذلك ، فإن السرعة وسهولة الاستخدام (عند العمل مع نوع جديد من الحقول تحتاج فقط إلى منح الخوارزمية الوصول إلى وظيفة التحقق من القيمة) تجعل الطريقة المستندة إلى فحص القواعد النحوية أداة قوية جدًا في ترسانة مطور أنظمة التعرف على المستندات. نستخدم هذا النهج لعدد كبير من المجالات المختلفة ، مثل التواريخ المختلفة ، ورقم البطاقة المصرفية (المسند - التحقق من رمز القمر ) ، وحقول مناطق المستندات التي يمكن قراءتها آليًا مع المجموع الاختباري ، والعديد من المجالات الأخرى.
- اختبار trudoemost يتنبأ بطول الخط .ربما يكون العيب الأكثر أهمية للخوارزمية بناءً على التدقيق النحوي هو أنه لا يمكن معالجة الفرضيات ذات الأطوال المختلفة (التي قد تنشأ بسبب أخطاء التقسيم : فقدان أو حدوث أحرف إضافية ، لصق الحروف والقطع ، وما إلى ذلك) ، في حين يمكن ترميز التغييرات في الفرضيات مثل "حذف حرف" أو "إضافة حرف" أو حتى "استبدال حرف بزوج" في نموذج الخطأ في الخوارزمية القائمة على WFST.ومع ذلك ، فإن السرعة وسهولة الاستخدام (عند العمل مع نوع جديد من الحقول تحتاج فقط إلى منح الخوارزمية الوصول إلى وظيفة التحقق من القيمة) تجعل الطريقة المستندة إلى فحص القواعد النحوية أداة قوية جدًا في ترسانة مطور أنظمة التعرف على المستندات. نستخدم هذا النهج لعدد كبير من المجالات المختلفة ، مثل التواريخ المختلفة ، ورقم البطاقة المصرفية (المسند - التحقق من رمز القمر ) ، وحقول مناطق المستندات التي يمكن قراءتها آليًا مع المجموع الاختباري ، والعديد من المجالات الأخرى.
تم إعداد المنشور على أساس المقالة : خوارزمية عالمية لنتائج التعرف على ما بعد المعالجة على أساس التحقق من القواعد النحوية. ك. بولاتوف ، دي بي نيكولايف ، ف. بوستنيكوف. وقائع ISA RAS ، المجلد .65 ، رقم 4 ، 2015 ، ص 68-73.