
تسارع التقدم في تعلُم الآلة لمعالجة اللغات الطبيعية بشكل ملحوظ على مدار السنوات القليلة الماضية. تركت النماذج مختبرات الأبحاث وأصبحت أساسًا للمنتجات الرقمية الرائدة. من الأمثلة الجيدة على ذلك الإعلان الأخير بأن نموذج BERT أصبح المكون الرئيسي وراء بحث Google . تعتقد Google أن هذه الخطوة (أي إدخال نموذج متقدم لفهم اللغة الطبيعية في محرك البحث) تمثل "أكبر اختراق في السنوات الخمس الماضية وواحدة من أهمها في تاريخ محركات البحث".
هذه المقالة هي دليل بسيط لاستخدام أحد إصدارات BERT لتصنيف الجمل. المثال الذي فحصناه بسيط بما يكفي للتعرف على النموذج لأول مرة ومتقدم بدرجة كافية لإثبات المفاهيم الأساسية.
بالإضافة إلى هذه المقالة ، تم إعداد جهاز كمبيوتر محمول يمكن عرضه في المستودع أو تشغيله في Colab .
البيانات: SST2
في مثالنا ، سنستخدم مجموعة بيانات SST2 التي تحتوي على اقتراحات من مراجعات الأفلام ، كل منها له علامة موجبة (قيمة 1) أو سلبية (قيمة 0):

النماذج: تصنيف الجملة
– , ( , ) 1 ( ), 0 ( ). :

:
, , 768. , .
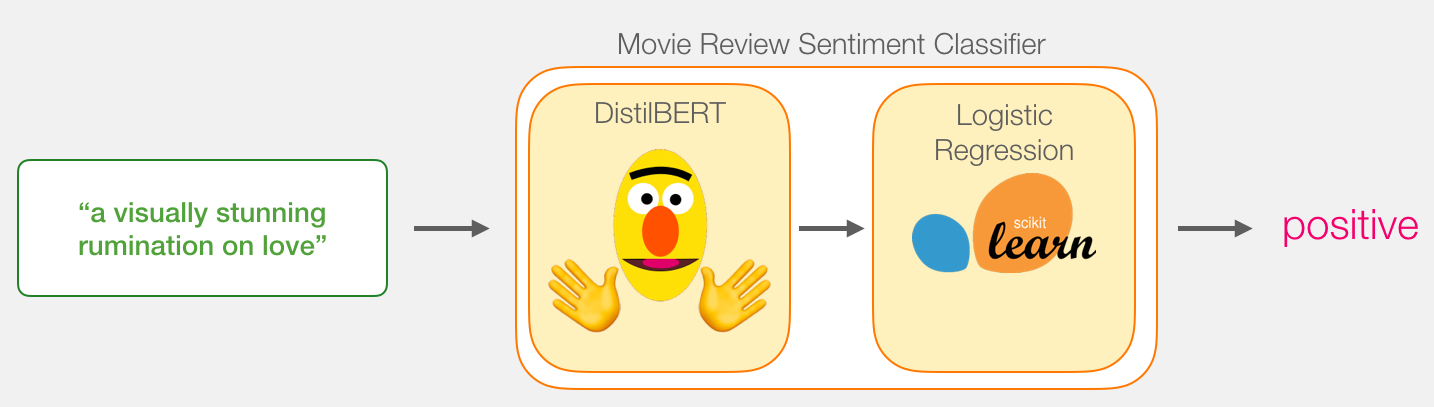
, BERT, ELMO ( NLP ): ( [CLS]).
, , . DistilBERT', . , , «» BERT', . , , BERT , [CLS] . , , . , , BERT .
transformers DistilBERT', .
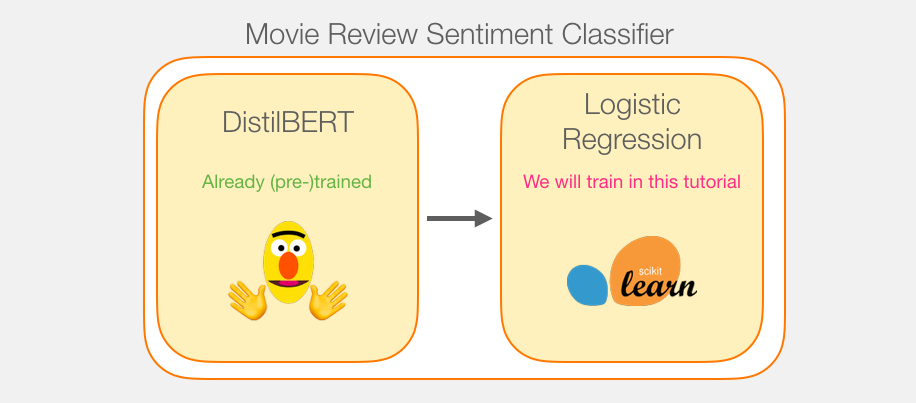
, . DistilBERT' 2 .

DistilBERT'. Scikit Learn. , , :
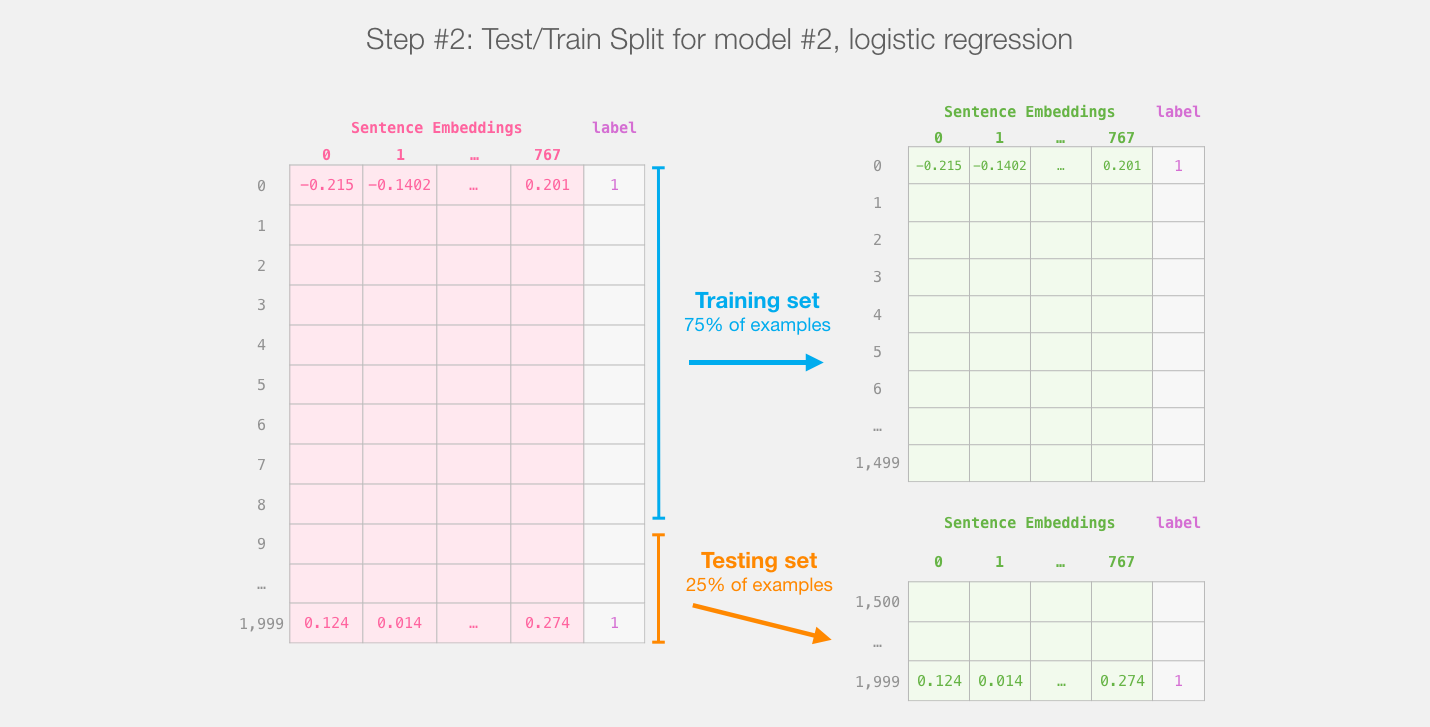
distilBERT' ( #1) , ( #2). , sklearn , , 75% ,
:

, , , .
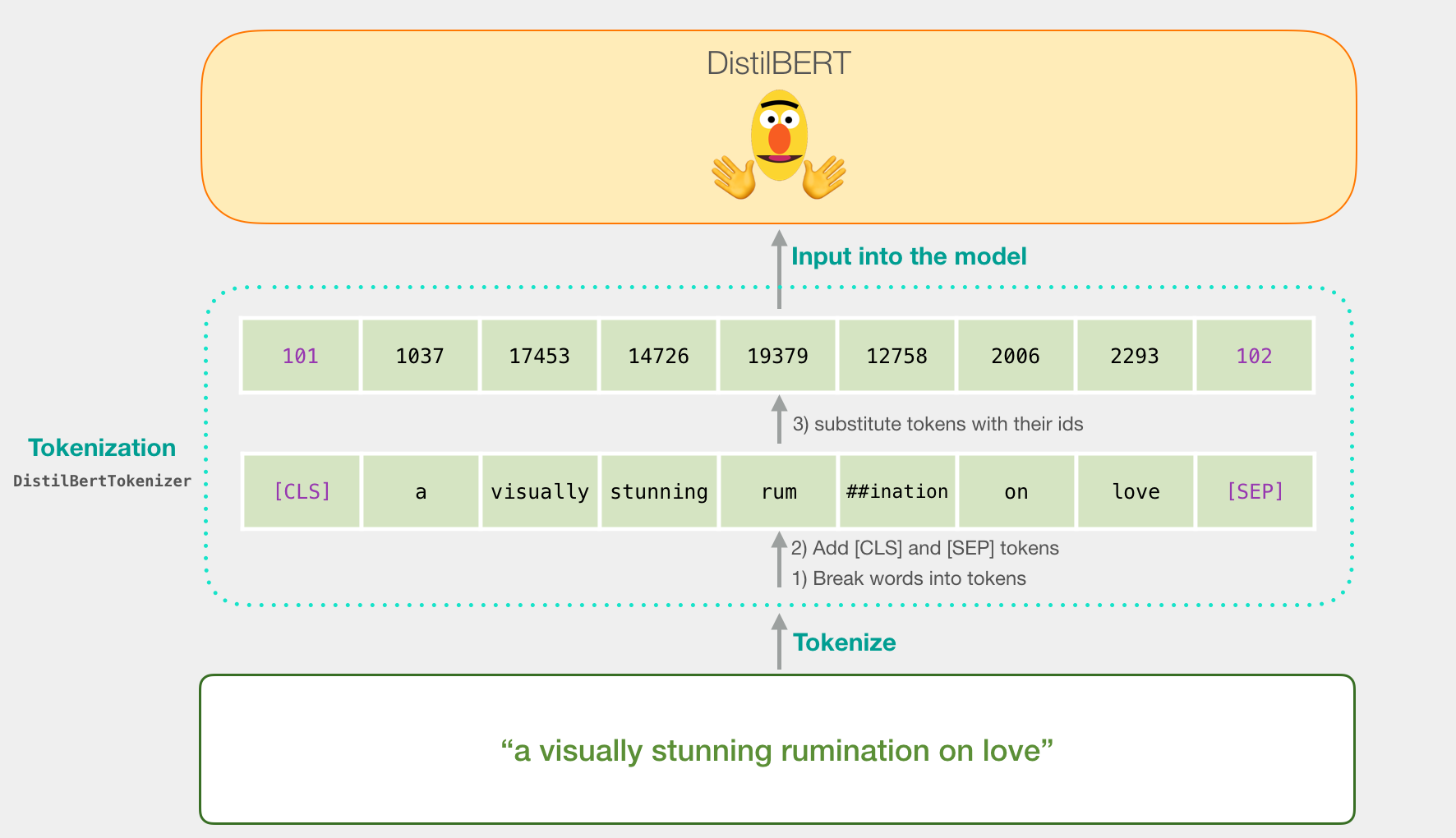
«a visually stunning rumination on love». BERT' , . , ( [CLS] [SEP] ).

, . Word2vec .

:
tokenizer.encode("a visually stunning rumination on love", add_special_tokens=True)
DistilBERT'.
BERT, ELMO ( NLP ), :
DistilBERT
DistilBERT' , BERT'. , 768 .
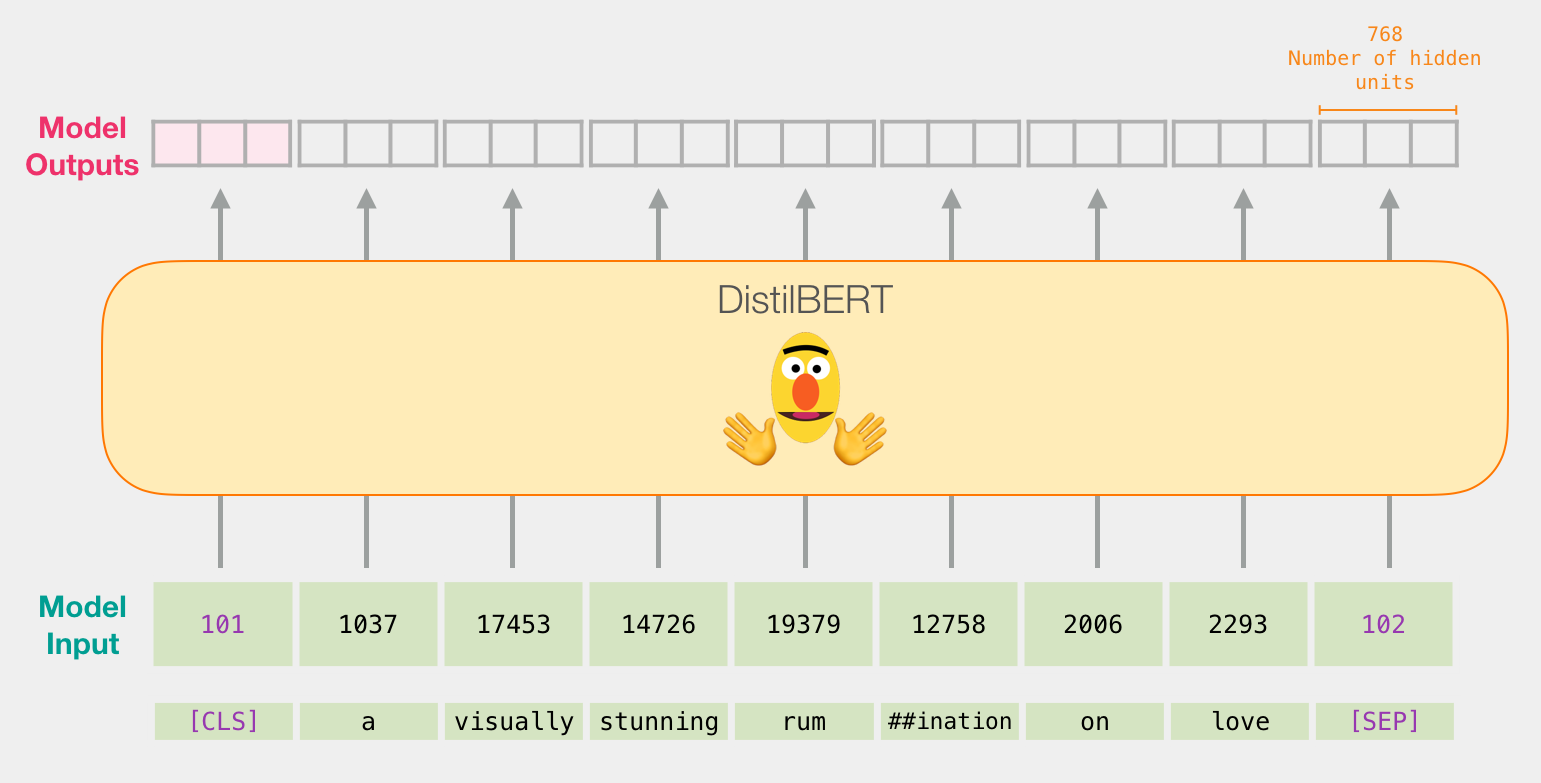
, , ( [CLS] ). .
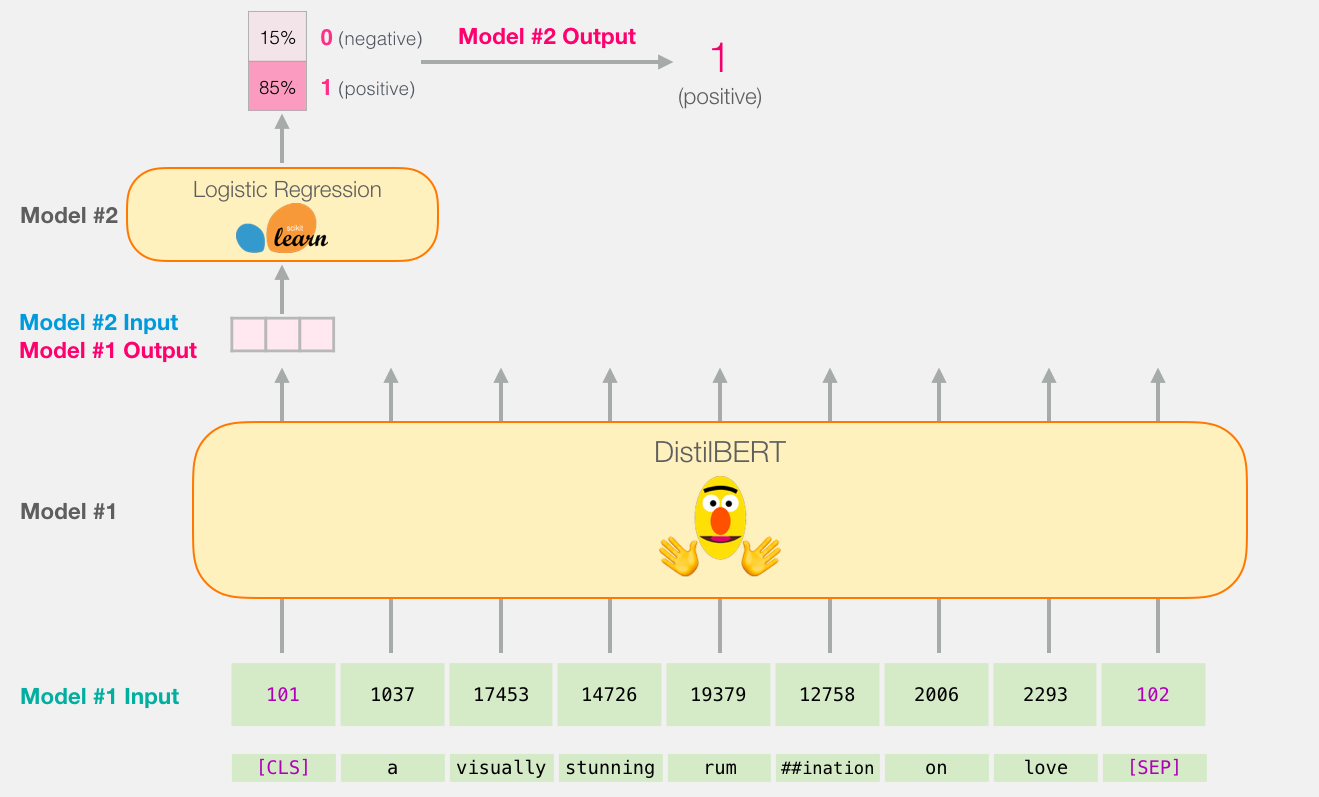
, , . :
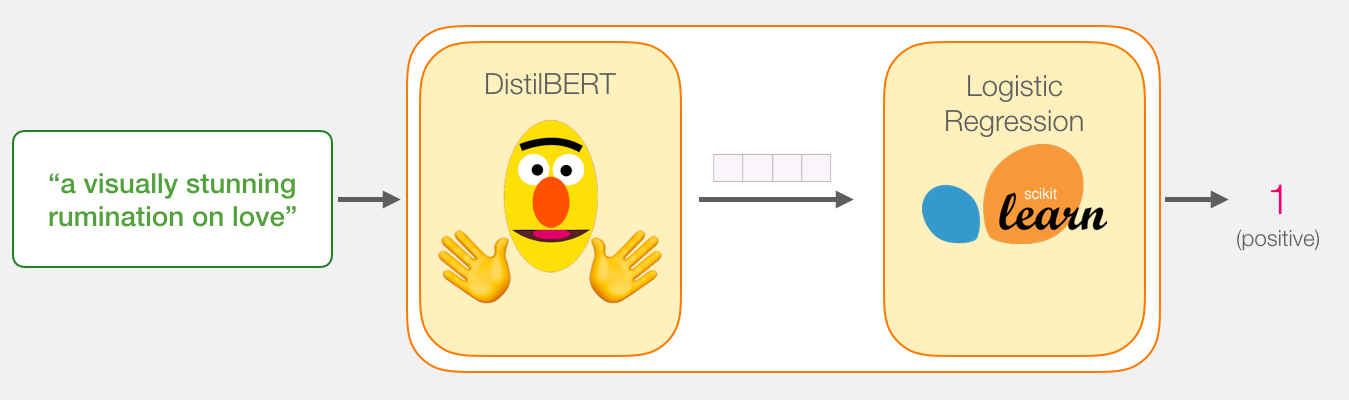
, .
. Colab github.
:
import numpy as np
import pandas as pd
import torch
import transformers as ppb
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
github, pandas:
df = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv', delimiter='\t', header=None)
df.head() , 5 , :
df.head()

DistilBERT
model_class, tokenizer_class, pretrained_weights = (ppb.DistilBertModel, ppb.DistilBertTokenizer, 'distilbert-base-uncased')
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
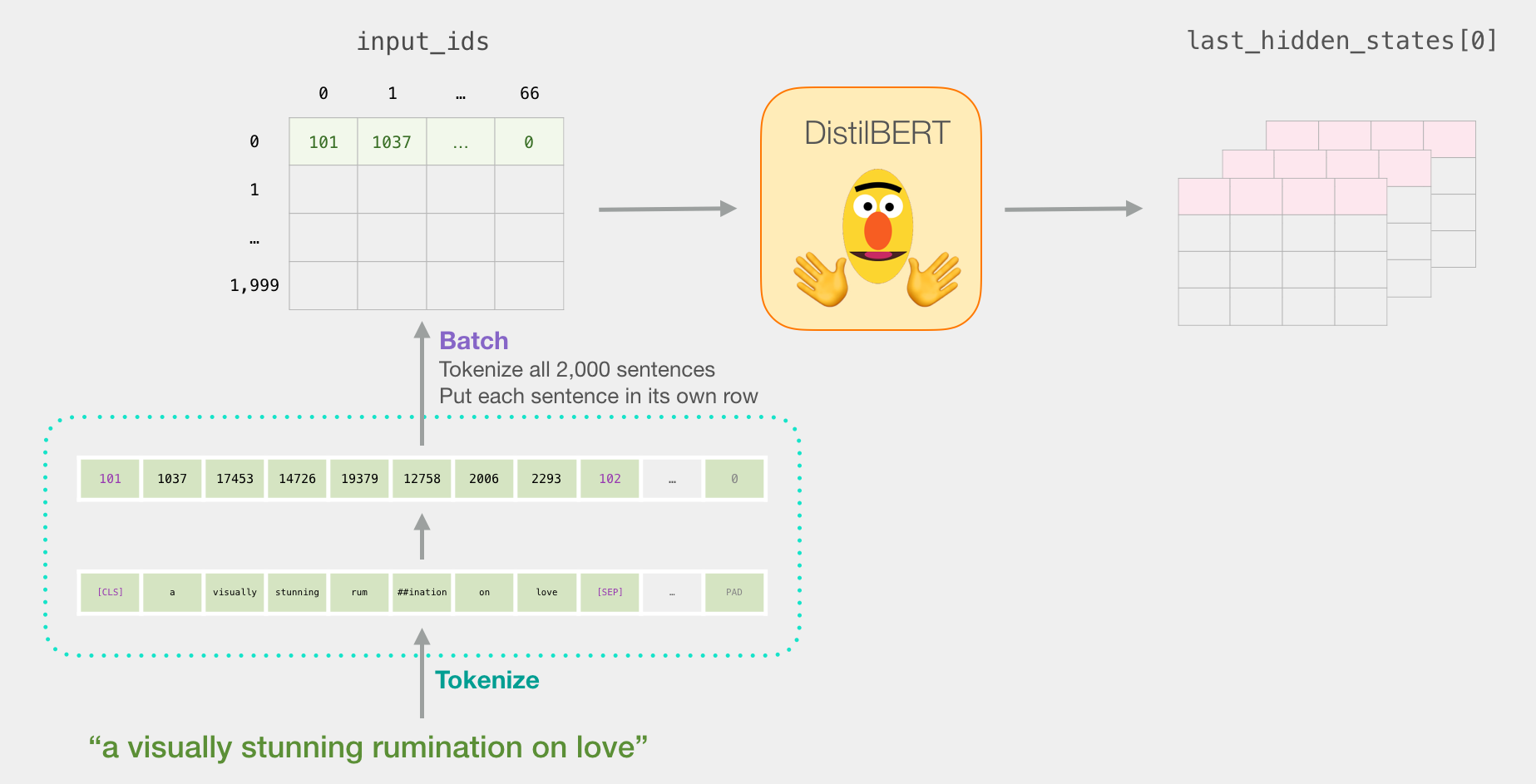
. , , . . ( , 2000).
tokenized = df[0].apply((lambda x: tokenizer.encode(x, add_special_tokens=True)))
.

( Series/DataFrame pandas) . DistilBERT , 0 (padding). , ( , Python).
, /, BERT':

DistilBERT'
DistilBERT.
input_ids = torch.tensor(np.array(padded))
with torch.no_grad():
last_hidden_states = model(input_ids)
last_hidden_states DistilBERT', ( , , DistilBERT). , 2000 (.. 2000 ), 66 ( 2000 ), 278 ( DistilBERT).

BERT'
3-d . :
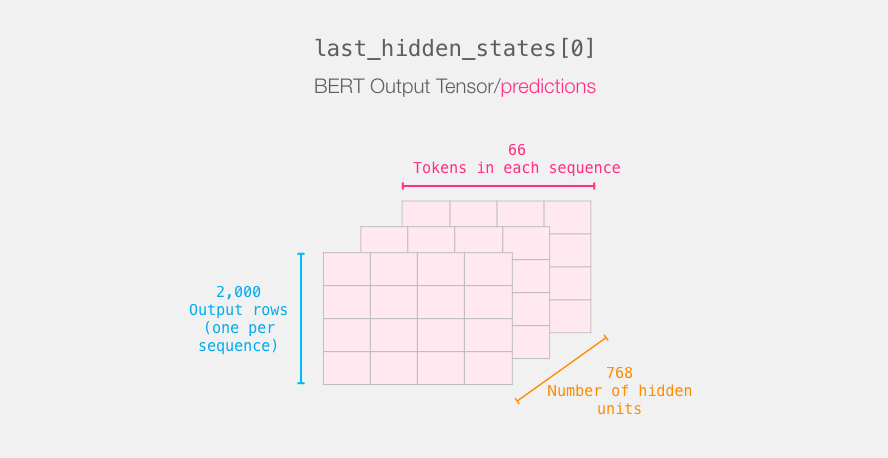
. :
BERT' [CLS]. .

, 3d , 2d :
features = last_hidden_states[0][:,0,:].numpy()
features 2d numpy, .

, BERT'
, BERT', , . 768 , .

, . BERT' [CLS] ( #0), (. ). , – , BERT/DistilBERT
, , .
labels = df[1]
train_features, test_features, train_labels, test_labels = train_test_split(features, labels)
:
.
lr_clf = LogisticRegression()
lr_clf.fit(train_features, train_labels)
, .
lr_clf.score(test_features, test_labels)
, (accuracy) – 81%.
: – 96.8. DistilBERT , – , . BERT , ( downstream task). DistilBERT' 90.7. BERT' 94.9.
Colab.
هذا كل شئ! حدث معرفة أولى جيدة. والخطوة التالية هي الرجوع إلى الوثائق ومحاولة الضبط بنفسك. يمكنك أيضًا الرجوع قليلاً والانتقال من distilBERT إلى BERT ومعرفة كيفية عملها.
بفضل Clément Delangue و Victor Sanh وفريق Huggingface الذين قدموا تعليقات حول الإصدارات السابقة من هذا الدليل.
المؤلفون