تحية للجميع. قبل بدء دورة Python Neural Networks ، قمنا بإعداد ترجمة لمواد أخرى مثيرة للاهتمام.
يسعدنا أن
نقدم PyCaret ، وهي مكتبة مفتوحة المصدر للتعلم الآلي في Python لتعلم ونشر النماذج مع المعلم أو بدونه في بيئة منخفضة الكود. يتيح لك PyCaret الانتقال من إعداد البيانات إلى نشر النموذج في بضع ثوانٍ في بيئة الكمبيوتر المحمول التي تختارها.مقارنة بمكتبات التعلم الآلي الأخرى المفتوحة ، تعد PyCaret بديلاً منخفض الكود يمكنه استبدال مئات أسطر التعليمات البرمجية ببضع كلمات فقط. ستزداد سرعة التجارب الأكثر كفاءة بشكل كبير. PyCaret هي في الأساس قشرة Python على العديد من مكتبات التعلم الآلي مثل scikit-learn و XGBoost و Microsoft LightGBM و spaCyواشياء أخرى عديدة.PyCaret بسيطة وسهلة الاستخدام. يتم تخزين جميع العمليات التي تقوم بها PyCaret بشكل تسلسلي في خط أنابيب جاهز تمامًا للنشر. يمكن لـ PyCaret أتمتة كل ذلك ، سواء أكان إضافة قيم مفقودة أو تحويل البيانات الفئوية أو الميزات الهندسية أو تحسين المعلمات الفائقة. لمعرفة المزيد عن PyCaret ، شاهد هذا الفيديو القصير .الشروع في استخدام PyCaret
يمكن تثبيت الإصدار المستقر الأول من PyCaret الإصدار 1.0.0 باستخدام النقطة. استخدم واجهة سطر الأوامر أو بيئة الكمبيوتر الدفتري وقم بتشغيل الأمر أدناه لتثبيت PyCaret.pip install pycaret
إذا كنت تستخدم Azure Notebooks أو Google Colab ، فقم بتشغيل الأمر التالي:!pip install pycaret
عند تثبيت PyCaret ، سيتم تثبيت كل التبعيات تلقائيًا. يمكنك عرض قائمة التبعيات هنا .لا يمكن أن يكون أسهل
تجول
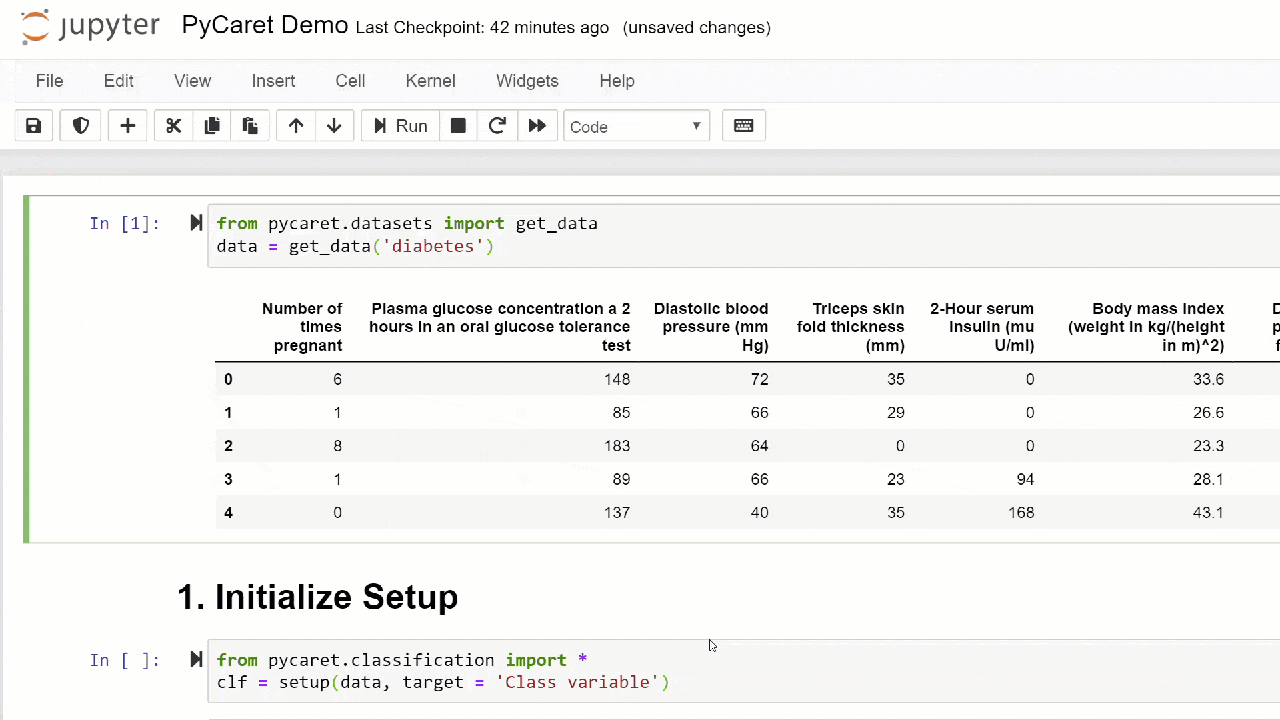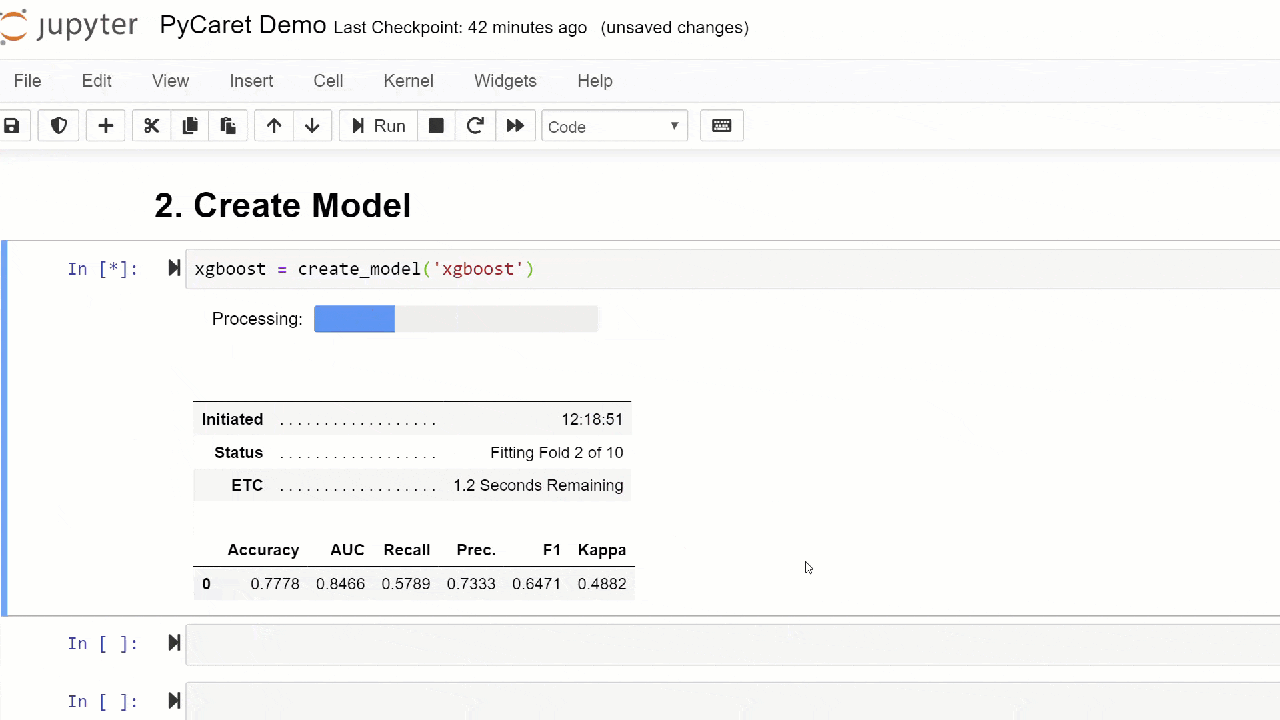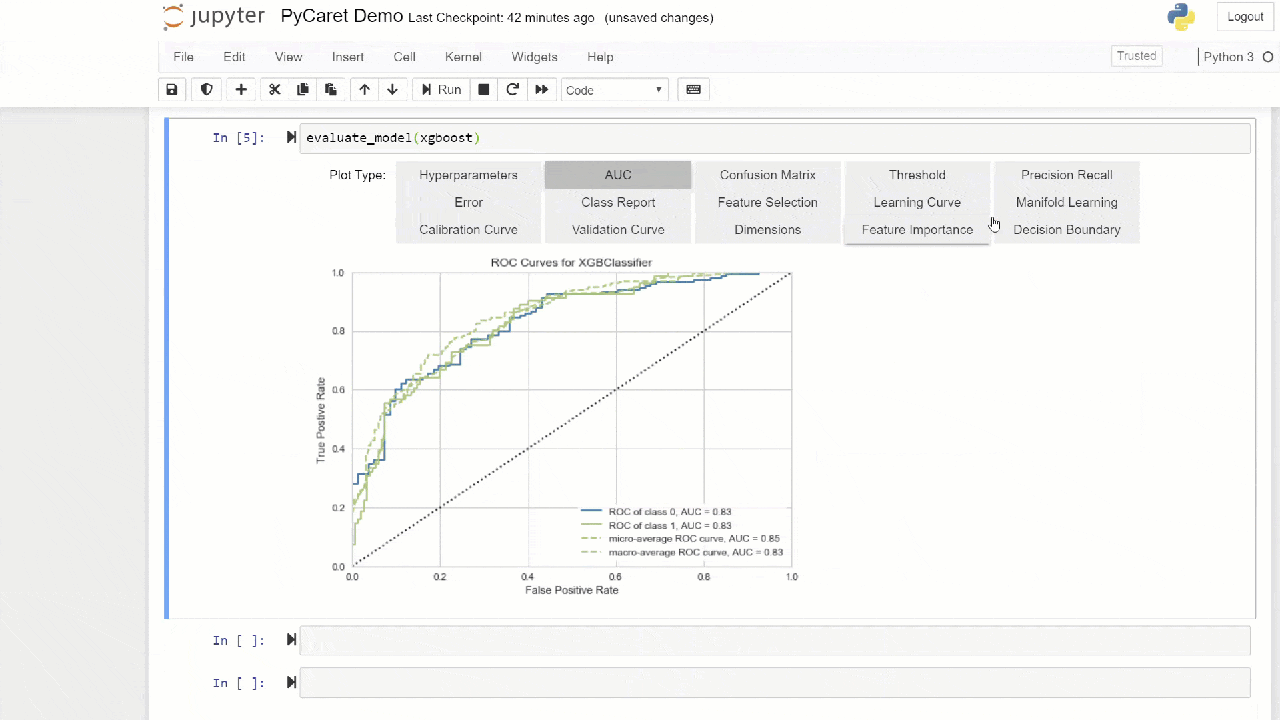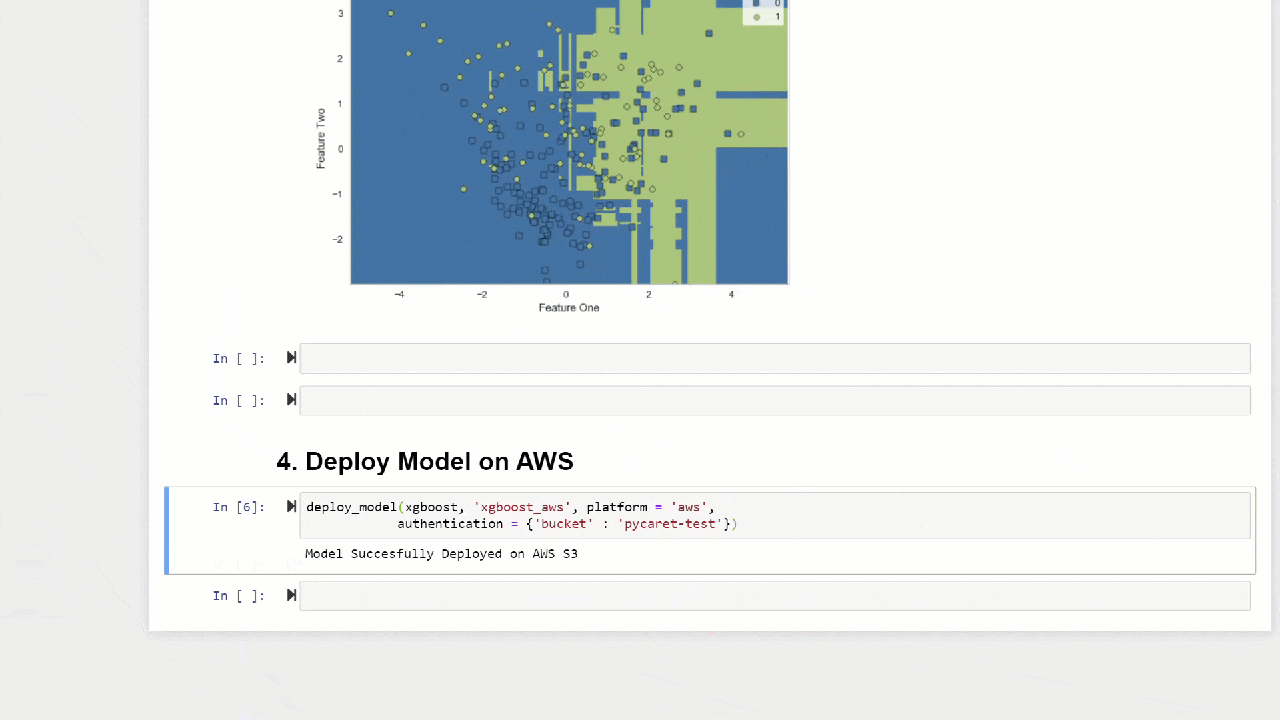
1. الحصول على البياناتفي هذه الإرشادات التفصيلية ، سنستخدم مجموعة بيانات لمرضى السكري ، وهدفنا هو التنبؤ بنتيجة المريض (في ثنائي 0 أو 1) بناءً على عدة عوامل مثل الضغط ومستوى الأنسولين في الدم والعمر ، إلخ. . مجموعة البيانات هذه متاحة في مستودع PyCaret GitHub . أسهل طريقة لاستيراد مجموعة البيانات مباشرة من المستودع هي استخدام الوظيفة get_dataمن الوحدات pycaret.datasets.from pycaret.datasets import get_data
diabetes = get_data('diabetes')
 PyCaret يمكن أن تعمل مباشرة مع الباندا2 إطارات البيانات . إعداد البيئةأي تجربة مع تعلم الآلة في PyCaret تبدأ مع وضع البيئة عن طريق استيراد حدة اللازمة وتهيئة
PyCaret يمكن أن تعمل مباشرة مع الباندا2 إطارات البيانات . إعداد البيئةأي تجربة مع تعلم الآلة في PyCaret تبدأ مع وضع البيئة عن طريق استيراد حدة اللازمة وتهيئة setup(). الوحدة النمطية التي سيتم استخدامها في هذا المثال هي pycaret.classification .بعد استيراد الوحدة النمطية ، يتم setup()تهيئتها من خلال تحديد إطار البيانات ( "مرض السكري" ) ومتغير الهدف ( "متغير الفئة" ).from pycaret.classification import *
exp1 = setup(diabetes, target = 'Class variable')
 تتم جميع المعالجة المسبقة في
تتم جميع المعالجة المسبقة في setup(). باستخدام أكثر من 20 وظيفة لإعداد البيانات قبل التعلم الآلي ، تقوم PyCaret بإنشاء خط أنابيب للتحويلات استنادًا إلى المعلمات المحددة في الوظيفة setup(). يقوم تلقائيًا ببناء جميع التبعيات في خط الأنابيب ، لذلك لا تحتاج إلى التحكم يدويًا في التنفيذ المتسلسل للتحويلات في اختبار أو مجموعة بيانات جديدة (غير مرئية).يمكن نقل خط أنابيب PyCaret بسهولة من بيئة إلى أخرى أو نشره في الإنتاج. فيما يلي يمكنك التعرف على ميزات المعالجة المسبقة التي كانت متاحة في PyCaret منذ الإصدار الأول. خطوات المعالجة المسبقة للبيانات إلزامية للتعلم الآلي ، مثل إضافة القيم المفقودة ، ومتغيرات جودة التشفير ، وتسميات التشفير (نعم أو لا إلى 1 أو 0) وتقسيم اختبار القطار ، يتم تنفيذها تلقائيًا أثناء التهيئة
خطوات المعالجة المسبقة للبيانات إلزامية للتعلم الآلي ، مثل إضافة القيم المفقودة ، ومتغيرات جودة التشفير ، وتسميات التشفير (نعم أو لا إلى 1 أو 0) وتقسيم اختبار القطار ، يتم تنفيذها تلقائيًا أثناء التهيئة setup(). يمكنك معرفة المزيد عن ميزات المعالجة المسبقة في PyCaret هنا .3. مقارنة النماذجهذه هي الخطوة الأولى التي يوصى بتنفيذها عند العمل مع تدريب المعلمين ( التصنيف أو الانحدار ). تقوم هذه الوظيفة بتدريب جميع النماذج في مكتبة النماذج وتقارن المؤشر المقدر مع بعضها البعض باستخدام التحقق المتبادل للكتل K (10 كتل افتراضيًا). تستخدم المؤشرات المقدرة على النحو التالي:- من أجل التصنيف: الدقة ، الجامعة الأمريكية ، استدعاء ، الدقة ، F1 ، كابا
- للتراجع: MAE ، MSE ، RMSE ، R2 ، RMSLE ، MAPE
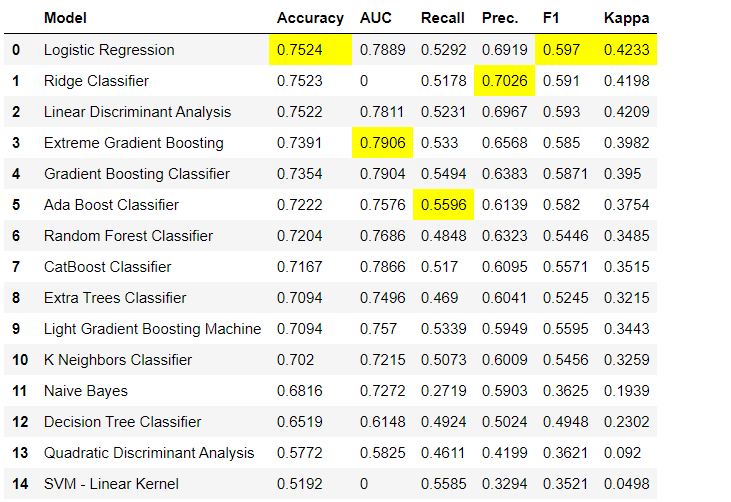 بشكل افتراضي ، يتم تقييم المقاييس باستخدام التحقق المتبادل عبر 10 كتل. يمكن تغيير عدد الكتل عن طريق تغيير قيمة المعلمة
بشكل افتراضي ، يتم تقييم المقاييس باستخدام التحقق المتبادل عبر 10 كتل. يمكن تغيير عدد الكتل عن طريق تغيير قيمة المعلمة fold.يتم فرز الجدول الافتراضي حسب "الدقة" من أعلى قيمة إلى أدنى قيمة. يمكن أيضًا تغيير ترتيب الفرز باستخدام الخيار sort.4. إنشاء نموذجإنشاء نموذج في أي وحدة PyCaret بسيط للغاية بحيث تحتاج فقط إلى كتابته create_model. تأخذ الوظيفة معلمة واحدة عند الإدخال ، أي تم تمرير اسم النموذج كسلسلة. تقوم هذه الوظيفة بإرجاع جدول يحتوي على درجات تم التحقق منها بشكل متقاطع وكائن نموذج مدرب.adaboost = create_model('ada')
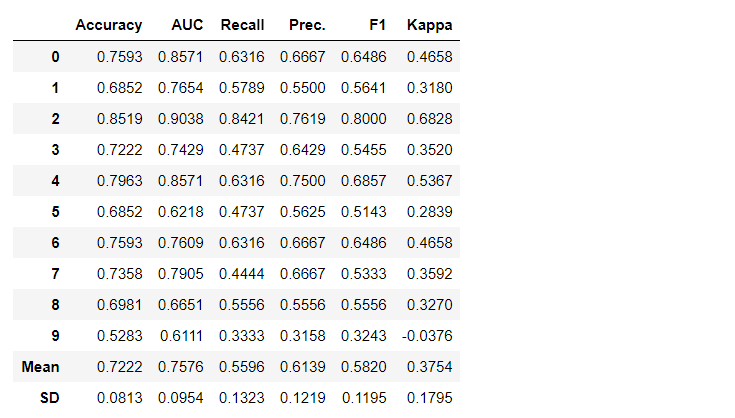 يقوم المتغير "adaboost" بتخزين كائن النموذج المدرّب ، الذي يُرجع وظيفة
يقوم المتغير "adaboost" بتخزين كائن النموذج المدرّب ، الذي يُرجع وظيفة create_model، تحت غطاء المحرك ، وهي مُقيِّم للتعلم والتعلم. يمكن الحصول على سمات المصدر للكائن المدرب باستخدام الوظيفة period ( . )بعد المتغير. يمكنك العثور على مثال للاستخدام أدناه. يحتوي PyCaret على أكثر من 60 خوارزمية مفتوحة المصدر جاهزة للاستخدام. يمكن العثور على قائمة كاملة بالمقيّمين / النماذج المتاحة في PyCaret هنا .5. إعداد النموذجيتم
يحتوي PyCaret على أكثر من 60 خوارزمية مفتوحة المصدر جاهزة للاستخدام. يمكن العثور على قائمة كاملة بالمقيّمين / النماذج المتاحة في PyCaret هنا .5. إعداد النموذجيتم tune_modelاستخدام الوظيفة لتكوين المعلمات الفائقة لنموذج التعلم الآلي تلقائيًا. يستخدم PyCaretrandom grid searchفي مساحة بحث محددة. تقوم الدالة بإرجاع جدول يحتوي على تقديرات تم التحقق من صحتها وجسم لنموذج مدرب.tuned_adaboost = tune_model('ada')
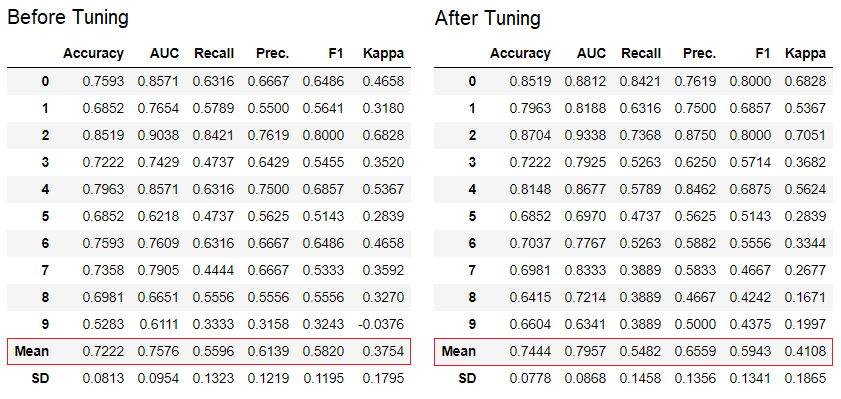 يمكن استخدام الوظيفة
يمكن استخدام الوظيفة tune_modelفي وحدات التعلم غير المدرس مثل pycaret.nlp و pycaret.clustering و pycaret.anomaly مع وحدات تعلم المعلم. على سبيل المثال ، يمكن استخدام وحدة البرمجة اللغوية العصبية في PyCaret لضبط المعلمة من number of topicsخلال تقييم دالة موضوعية أو وظيفة خسارة من نموذج مع مدرس ، مثل "الدقة" أو "R2".6. مجموعة من النماذجيتم ensemble_modelاستخدام الوظيفة لإنشاء مجموعة من النماذج المدربة. عند الإدخال ، يستغرق الأمر معلمة واحدة - كائن النموذج المدرب. تقوم الدالة بإرجاع جدول يحتوي على تقديرات تم التحقق من صحتها وجسم لنموذج مدرب.
dt = create_model('dt')
dt_bagged = ensemble_model(dt)
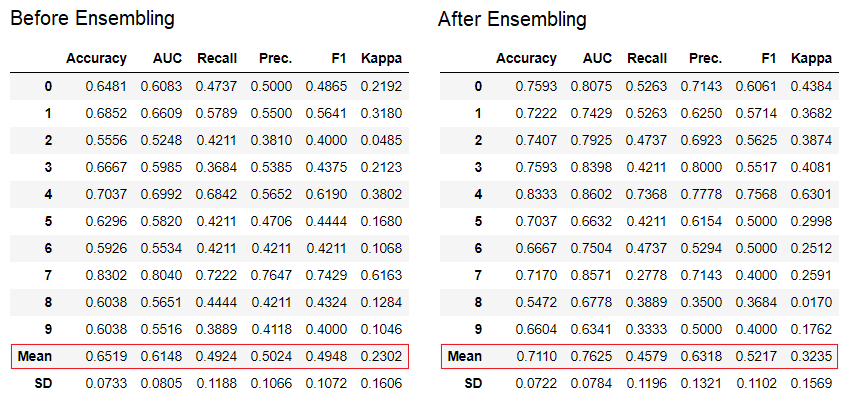 يتم استخدام طريقة "التعبئة" عند إنشاء المجموعة بشكل افتراضي ، ويمكن تغييرها إلى "تعزيز" باستخدام المعلمة
يتم استخدام طريقة "التعبئة" عند إنشاء المجموعة بشكل افتراضي ، ويمكن تغييرها إلى "تعزيز" باستخدام المعلمة methodفي الوظيفة ensemble_model.كما يوفر PyCaret وظائف blend_modelsو stack_models للجمع بين عدة نماذج المدربين.7. تصور النموذج:يمكنك تقييم الأداء وتشخيص نموذج التعلم الآلي المدرب باستخدام الوظيفة plot_model. يأخذ في شكل النموذج المدرب ونوع الرسم البياني في شكل سلسلة.
adaboost = create_model('ada')
plot_model(adaboost, plot = 'auc')
plot_model(adaboost, plot = 'boundary')
plot_model(adaboost, plot = 'pr')
plot_model(adaboost, plot = 'vc')
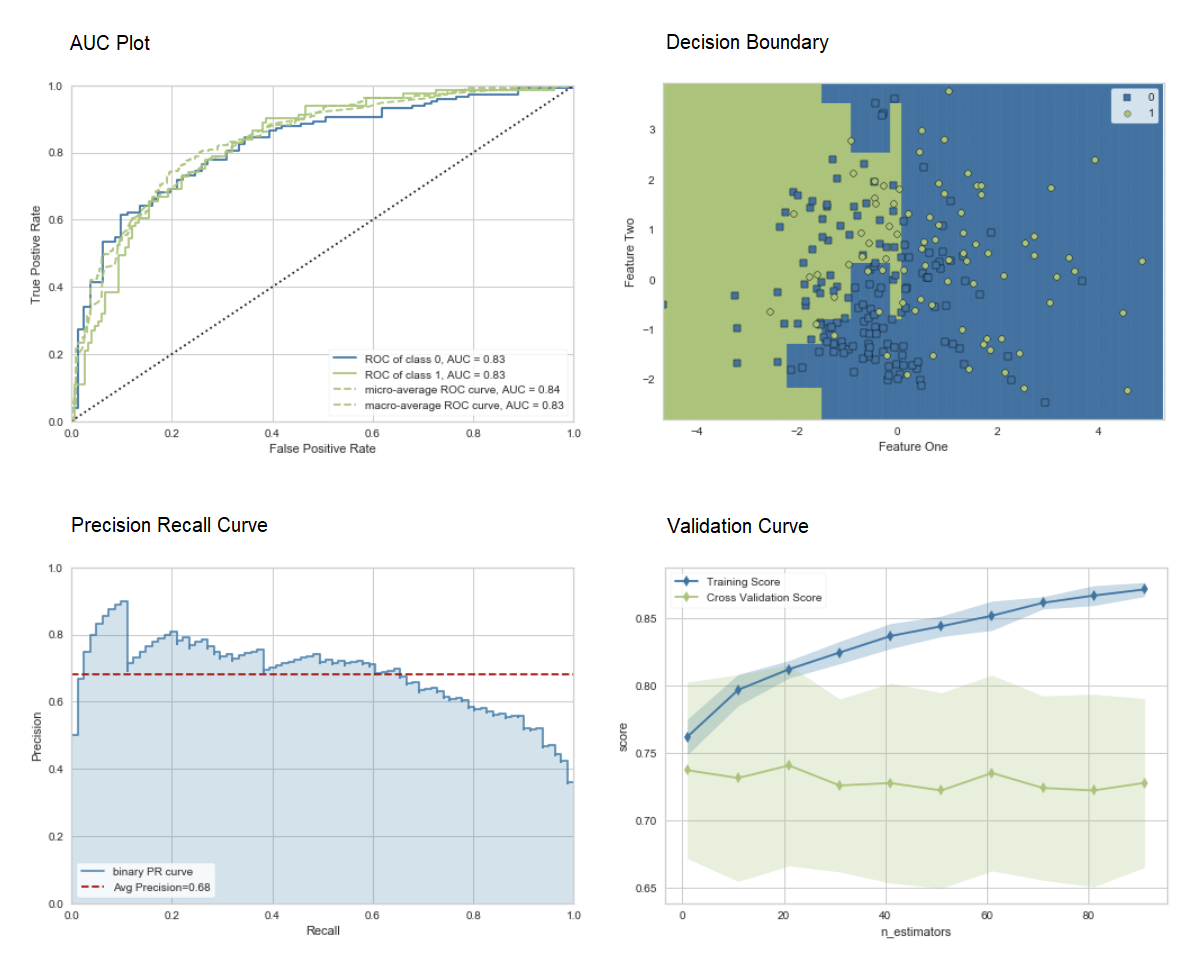 هنا يمكنك معرفة المزيد عن التصور في PyCaret.يمكنك أيضًا استخدام الوظيفة
هنا يمكنك معرفة المزيد عن التصور في PyCaret.يمكنك أيضًا استخدام الوظيفة evaluate_modelلرؤية الرسوم البيانية باستخدام واجهة مستخدم الكمبيوتر الدفتري. يمكن استخدام الوظيفة
الوظيفة plot_modelفي الوحدة النمطية pycaret.nlpلتصور مجموعة النصوص والنماذج المواضيعية الدلالية. هنا يمكنك معرفة المزيد عنها.8. تفسير النموذجعندما تكون البيانات غير خطية ، والتي تحدث في الحياة الواقعية في كثير من الأحيان ، نرى دائمًا أن النماذج الشبيهة بالأشجار تعمل بشكل أفضل بكثير من النماذج الغوسية البسيطة. ومع ذلك ، هذا بسبب فقدان قابلية التفسير ، لأن نماذج الأشجار لا توفر معاملات بسيطة ، مثل النماذج الخطية. تقوم PyCaret بتنفيذ SHAP (SHPley الإضافات التخطيط ) باستخدام دالة interpret_model.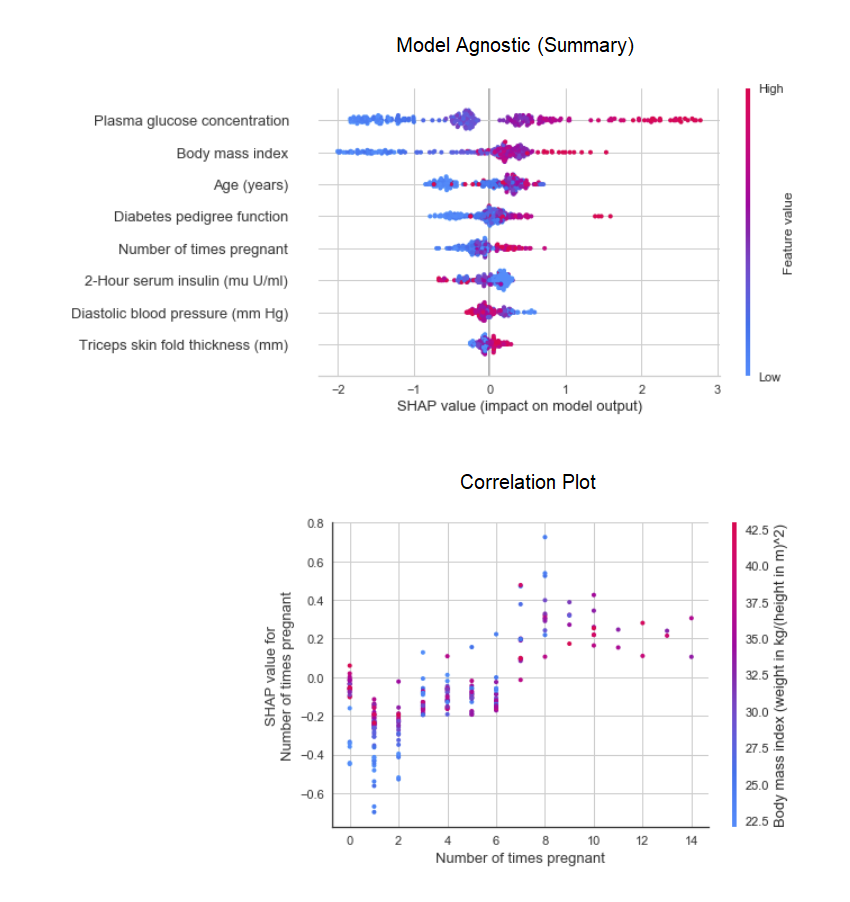 يمكن تقدير تفسير نقطة بيانات معينة في مجموعة بيانات اختبار باستخدام الرسم البياني "السبب". في المثال أدناه ، نختبر المثيل الأول في مجموعة بيانات الاختبار.
يمكن تقدير تفسير نقطة بيانات معينة في مجموعة بيانات اختبار باستخدام الرسم البياني "السبب". في المثال أدناه ، نختبر المثيل الأول في مجموعة بيانات الاختبار. 9. النموذج التنبئيحتى هذه اللحظة ، كانت النتائج التي حصلنا عليها مبنية على التحقق المتقاطع بواسطة كتل K على مجموعة بيانات التدريب (70٪ بشكل افتراضي). من أجل الاطلاع على التوقعات وأداء النموذج في مجموعة بيانات الاختبار / الانتظار ، يتم استخدام وظيفة
9. النموذج التنبئيحتى هذه اللحظة ، كانت النتائج التي حصلنا عليها مبنية على التحقق المتقاطع بواسطة كتل K على مجموعة بيانات التدريب (70٪ بشكل افتراضي). من أجل الاطلاع على التوقعات وأداء النموذج في مجموعة بيانات الاختبار / الانتظار ، يتم استخدام وظيفة predict_model.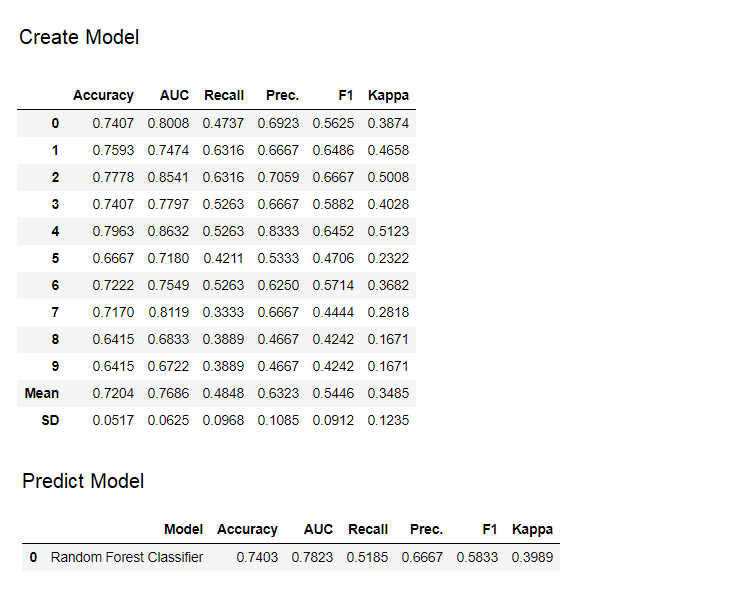 تُستخدم الوظيفة
تُستخدم الوظيفة predict_modelللتنبؤ بمجموعة بيانات غير مرئية. الآن سنستخدم نفس مجموعة البيانات التي استخدمناها للتدريب ، كبديل لمجموعة البيانات الجديدة غير المرئية. في الممارسة العمليةpredict_modelسيتم استخدامه بشكل متكرر ، في كل مرة على مجموعة بيانات جديدة غير مرئية. وظيفة
وظيفة predict_modelيمكن أن تجعل التوقعات لسلسلة متتابعة من النماذج التي يمكن إنشاؤها باستخدام stack_models و ظائف create_stacknet . يمكن أنتقوم الوظيفة predict_modelأيضًا بعمل تنبؤات مباشرة للنماذج المستضافة على AWS S3 باستخدام وظيفة loy_model .10. نشر نموذجإحدى طرق استخدام النماذج المدربة لإنشاء تنبؤات لمجموعة بيانات جديدة هي استخدام الوظيفةpredict_modelفي نفس الكمبيوتر المحمول / IDE حيث تم تدريب النموذج. ومع ذلك ، يعد توليد توقعات لمجموعة بيانات جديدة (غير مرئية) عملية تكرارية. اعتمادًا على حالة الاستخدام ، يمكن أن يختلف تكرار التوقعات من التوقعات في الوقت الفعلي إلى التنبؤات المجمعة. deploy_modelتتيح لك الوظيفة في PyCaret نشر خط الأنابيب بالكامل ، بما في ذلك النموذج المدرب في السحابة من بيئة الكمبيوتر المحمول.deploy_model(model = rf, model_name = 'rf_aws', platform = 'aws',
authentication = {'bucket' : 'pycaret-test'})
11. حفظ النموذج / حفظ التجربة
بعد التدريب ، يمكن حفظ خط الأنابيب بالكامل الذي يحتوي على جميع تحويلات المعالجة المسبقة وجسم النموذج المدرب في ملف مخلل ثنائي.
adaboost = create_model('ada')
save_model(adaboost, model_name = 'ada_for_deployment')
 يمكنك أيضًا حفظ التجربة بأكملها ، التي تحتوي على جميع المخرجات المتوسطة ، كملف ثنائي واحد.save_experiment (EXPERIMENT_NAME = 'my_first_experiment')
يمكنك أيضًا حفظ التجربة بأكملها ، التي تحتوي على جميع المخرجات المتوسطة ، كملف ثنائي واحد.save_experiment (EXPERIMENT_NAME = 'my_first_experiment') يمكنك تحميل النماذج والتجارب حفظها باستخدام وظائف
يمكنك تحميل النماذج والتجارب حفظها باستخدام وظائف load_modelو load_experimentالمتاحة من جميع وحدات PyCaret.12. الدليل التاليفي الدليل التالي ، سنوضح كيفية استخدام نموذج التعلم الآلي المدرب في Power BI لإنشاء تنبؤات مجمعة في بيئة إنتاج حقيقية.يمكنك أيضًا قراءة دفاتر الملاحظات للمبتدئين في الوحدات التالية:ما هو خط التطوير؟
نحن نعمل بنشاط لتحسين PyCaret. يتضمن خط التطوير القادم الخاص بنا وحدة جديدة للتنبؤ بالسلسلة الزمنية ، وتكامل TensorFlow ، وتحسينات كبيرة في قابلية التوسع PyCaret. إذا كنت ترغب في مشاركة ملاحظاتك ومساعدتنا على التحسين ، يمكنك ملء نموذج على الموقع أو ترك تعليق على صفحتنا على GitHub أو LinkedIn .هل تريد معرفة المزيد عن وحدة معينة؟
بدءًا من الإصدار الأول ، يحتوي PyCaret 1.0.0 على الوحدات التالية المتاحة للاستخدام. اتبع الروابط أدناه للتعرف على وثائق وأمثلة العمل.التصنيفالانحدارالتجميعشذوذ البحثمعالجة النص الطبيعي (NLP)تدريب القواعد المشتركةروابط مهمة
إذا كنت تحب PyCaret ، ضعنا ️ على GitHub.لمعرفة المزيد عن PyCaret ، يمكنك متابعتنا على LinkedIn و Youtube .
تعلم المزيد عن الدورة.