تم إعداد ترجمة المقال خاصة لطلاب الدورة التدريبية "قواعد البيانات" .
ما قد لا تعرفه عن sysbench إنشاء عدد عشوائي منSysbench هو أداة شائعة لاختبار الأداء. كتبه بيتر زايتسيف في الأصل في أوائل العقد الأول من القرن الحالي وأصبح المعيار الفعلي للاختبار والقياس. وهو مدعوم حاليًا بواسطة Alexei Kopytov ويتم نشره على Github في .ومع ذلك ، لاحظت أنه على الرغم من توزيعه الواسع ، هناك لحظات غير مألوفة للكثيرين في مجال sysbench. على سبيل المثال ، القدرة على تعديل اختبارات MySQL بسهولة باستخدام Lua أو تكوين معلمات مولد الأرقام العشوائية.عن ماذا تتحدث هذه المقالة؟
لقد كتبت هذه المقالة لإظهار مدى سهولة تخصيص sysbench لمتطلباتك. هناك العديد من الطرق لتوسيع وظائف sysbench ، وأحدها تكوين تكوين معرفات عشوائية (معرفات).بشكل افتراضي ، يأتي sysbench مع خمسة خيارات مختلفة لتوليد أرقام عشوائية. ولكن في كثير من الأحيان (في الواقع ، تقريبًا أبدًا) ، لا يتم الإشارة إلى أي منها بشكل صريح ، وحتى في كثير من الأحيان يمكنك رؤية معلمات الجيل (للخيارات حيث تكون متاحة).إذا كان لديك سؤال: "ولماذا أنا مهتم بذلك؟ بعد كل شيء ، القيم الافتراضية مناسبة تمامًا ، "ثم تم تصميم هذا المنشور لمساعدتك على فهم لماذا لا يكون هذا هو الحال دائمًا.لنبدأ
ما هي طرق إنشاء أرقام عشوائية في sysbench؟ يتم تنفيذ ما يلي حاليًا (يمكنك رؤيتها بسهولة من خلال خيار --help):- خاص (توزيع خاص)
- Gaussian (توزيع Gaussian)
- باريتو (توزيع باريتو)
- Zipfian (توزيع Zipf)
- موحد (توزيع موحد)
افتراضيًا ، يتم استخدام Special مع المعلمات التالية:rand-spec-iter = 12 - عدد التكرارات لتوزيع خاصrand-spec-pct = 1 - النسبة المئوية لكامل المدى الذي تقع فيه القيم "الخاصة" مع توزيع خاصrand-spec-res = 75 - النسبة المئوية للقيم "الخاصة" للاستخدام في توزيع خاص
نظرًا لأنني أحب الاختبارات والنصوص البرمجية البسيطة وسهلة النسخ ، سيتم جمع جميع البيانات اللاحقة باستخدام أوامر sysbench التالية:- sysbench ./src/lua/oltp_read.lua -mysql_storage_engine = innodb –db-driver = mysql –tables = 10 –table_size = 100 Prepared
- sysbench ./src/lua/oltp_read_write.lua –db-driver=mysql –tables=10 –table_size=100 –skip_trx=off –report-interval=1 –mysql-ignore-errors=all –mysql_storage_engine=innodb –auto_inc=on –histogram –stats_format=csv –db-ps-mode=disable –threads=10 –time=60 –rand-type=XXX run
لا تتردد في تجربة نفسك. يمكن العثور على وصف وبيانات البرنامج النصي هنا .لماذا يستخدم sysbench مولد رقم عشوائي؟ أحد الأغراض هو إنشاء معرفات سيتم استخدامها في الاستعلامات. لذلك ، في مثالنا ، سيتم إنشاء أرقام بين 1 و 100 ، مع الأخذ بعين الاعتبار إنشاء 10 جداول مع 100 صف في كل منها.ماذا لو قمت بتشغيل sysbench كما هو موضح أعلاه وقمت بتغيير نوع العلامة فقط؟لقد قمت بتشغيل هذا البرنامج النصي واستخدمت السجل العام لجمع وتحليل تكرار قيم المعرفات التي تم إنشاؤها. هنا هو النتيجة:خاص الموحدة
الموحدة Zipfian
Zipfian باريتو
باريتو التمويه
التمويه ويمكن أن نرى أن هذه المسائل المعلمة، أليس كذلك؟ بعد كل شيء ، sysbench يفعل بالضبط ما كنا نتوقعه منه.دعونا نلقي نظرة فاحصة على كل توزيعات.
ويمكن أن نرى أن هذه المسائل المعلمة، أليس كذلك؟ بعد كل شيء ، sysbench يفعل بالضبط ما كنا نتوقعه منه.دعونا نلقي نظرة فاحصة على كل توزيعات.مميز
يتم استخدام Special بشكل افتراضي ، لذلك إذا لم تحدد نوع rand ، فسيستخدم sysbench خاصًا. يستخدم Special عددًا محدودًا جدًا من قيم المعرفات. في مثالنا ، يمكننا أن نرى أن القيم 50-51 تستخدم بشكل أساسي ، والقيم المتبقية بين 44-56 نادرة للغاية ، بينما لا يتم استخدام القيم الأخرى عمليًا. يرجى ملاحظة أن القيم المحددة تقع في منتصف النطاق المتاح من 1-100.في هذه الحالة ، تبلغ الذروة حوالي معرفين يمثلان 2 ٪ من العينة. إذا قمت بزيادة عدد التسجيلات إلى مليون ، ستبقى الذروة ، ولكنها ستكون عند 7493 ، وهو ما يمثل 0.74 ٪ من العينة. نظرًا لأن هذا سيكون أكثر تقييدًا ، فمن المرجح أن يكون عدد الصفحات أكثر من صفحة واحدة.موحد (توزيع موحد)
كما يقول الاسم ، إذا استخدمنا Uniform ، فسيتم استخدام جميع القيم للمعرف ، وسيكون التوزيع ... منتظمًا.Zipfian (توزيع Zipf)
توزيع Zipf ، الذي يطلق عليه أحيانًا توزيع زيتا ، هو توزيع منفصل شائع الاستخدام في اللغويات والتأمين ونمذجة الأحداث النادرة. في هذه الحالة ، سيستخدم sysbench الأرقام التي تبدأ بالأصغر (1) ويقلل بسرعة كبيرة من تكرار الاستخدام ، والانتقال إلى أعداد أكبر.باريتو (باريتو)
باريتو يطبق قاعدة "80-20" . في هذه الحالة ، سيتم تلطيخ المعرفات التي تم إنشاؤها بشكل أقل وستكون أكثر تركيزًا في شريحة صغيرة. في مثالنا ، كان لـ 52٪ من جميع المعرّفات قيمة 1 ، وكانت 73٪ من القيم في أول 10 أرقام.Gaussian (توزيع Gaussian)
التوزيع الغوسي (التوزيع الطبيعي) معروف ومألوف . يتم استخدامه بشكل رئيسي في الإحصائيات والتنبؤ حول عامل مركزي. في هذه الحالة ، يتم توزيع المعرّفات المستخدمة على طول المنحنى على شكل جرس ، بدءًا من متوسط القيمة ، وتنخفض ببطء إلى الحواف.ماذا يكون النقطة من هذا؟
كل من الخيارات المذكورة أعلاه له استخدامه الخاص ويمكن تجميعه حسب الغرض. باريتو وتركيز خاص على النقاط الساخنة. في هذه الحالة ، يستخدم التطبيق نفس الصفحة / البيانات مرارًا وتكرارًا. قد يكون هذا ما نحتاجه ، ولكن يجب أن نفهم ما نقوم به وألا نرتكب أخطاء هنا.على سبيل المثال ، إذا اختبرنا أداء ضغط صفحة InnoDB أثناء القراءة ، فينبغي تجنب استخدام القيمة الافتراضية الخاصة أو Pareto. إذا كان لدينا مجموعة بيانات سعة 1 تيرابايت ومخزن مؤقت سعة 30 جيجا بايت ، وطلبنا نفس الصفحة عدة مرات ، فستتم قراءة هذه الصفحة بالفعل من القرص وستكون متاحة غير مضغوطة في الذاكرة.باختصار ، مثل هذا الاختبار هو مضيعة للوقت والجهد.نفس الشيء إذا كنا بحاجة إلى التحقق من أداء التسجيل. كتابة نفس الصفحة مرارًا وتكرارًا ليس الخيار الأفضل.ماذا عن اختبار الأداء؟مرة أخرى ، نريد اختبار الأداء ، ولكن لأي حالة؟ من المهم أن نفهم أن طريقة توليد أرقام عشوائية تؤثر بشكل كبير على نتائج الاختبار. ويمكن أن يؤدي "التخلف عن الدفع الجيد بما يكفي" إلى استنتاجات خاطئة.توضح الرسوم البيانية التالية أوقات استجابة مختلفة اعتمادًا على نوع الراند (نوع الاختبار والوقت والمعلمات الإضافية وعدد الخيوط متشابهة في كل مكان).من نوع إلى نوع ، تختلف التأخيرات اختلافًا كبيرًا: هنا كنت أقرأ وأكتب ، وتم أخذ البيانات من مخطط الأداء (
هنا كنت أقرأ وأكتب ، وتم أخذ البيانات من مخطط الأداء (sys.schema_table_statistics) كما هو متوقع ، يستغرق Pareto و Special وقتًا أطول بكثير من الآخرين ، مما يتسبب في أن يعاني النظام (MySQL-InnoDB) بشكل مصطنع من المنافسة في "نقطة ساخنة" واحدة.لا يؤثر تغيير نوع الراند على التأخير فحسب ، بل يؤثر أيضًا على عدد الصفوف التي تمت معالجتها ، كما هو موضح في مخطط الأداء.
 بالنظر إلى كل ما سبق ، من المهم فهم ما نحاول تقييمه واختباره.إذا كان هدفي هو اختبار أداء النظام على جميع المستويات ، فقد أفضّل استخدام Uniform ، الذي سيحمّل مجموعة / خادم قاعدة البيانات / النظام بشكل متساوٍ ويزيد من توزيع القراءة / التحميل / الكتابة بالتساوي.إذا كانت وظيفتي هي العمل مع النقاط الساخنة ، فربما يكون Pareto و Special هما الخيار الصحيح.ولكن لا تستخدم القيم الافتراضية بشكل أعمى. قد تناسبك ، ولكن غالبًا ما تكون مخصصة للحالات القصوى. في تجربتي ، يمكنك غالبًا ضبط الإعدادات للحصول على النتيجة التي تحتاجها.على سبيل المثال ، تريد استخدام القيم في المنتصف من خلال توسيع الفاصل الزمني بحيث لا يكون هناك ذروة حادة (خاصة بشكل افتراضي) أو جرس (Gaussian).يمكنك تكوين خاص للحصول على شيء مثل هذا:
بالنظر إلى كل ما سبق ، من المهم فهم ما نحاول تقييمه واختباره.إذا كان هدفي هو اختبار أداء النظام على جميع المستويات ، فقد أفضّل استخدام Uniform ، الذي سيحمّل مجموعة / خادم قاعدة البيانات / النظام بشكل متساوٍ ويزيد من توزيع القراءة / التحميل / الكتابة بالتساوي.إذا كانت وظيفتي هي العمل مع النقاط الساخنة ، فربما يكون Pareto و Special هما الخيار الصحيح.ولكن لا تستخدم القيم الافتراضية بشكل أعمى. قد تناسبك ، ولكن غالبًا ما تكون مخصصة للحالات القصوى. في تجربتي ، يمكنك غالبًا ضبط الإعدادات للحصول على النتيجة التي تحتاجها.على سبيل المثال ، تريد استخدام القيم في المنتصف من خلال توسيع الفاصل الزمني بحيث لا يكون هناك ذروة حادة (خاصة بشكل افتراضي) أو جرس (Gaussian).يمكنك تكوين خاص للحصول على شيء مثل هذا: في هذه الحالة ، لا تزال المعرفات في مكان قريب ، وهناك منافسة. لكن تأثير "نقطة فعالة" واحدة أقل ، وبالتالي فإن الصراعات المحتملة ستكون الآن مع العديد من المعرّفات ، والتي يمكن أن تكون ، على عدد السجلات في الصفحة ، على عدة صفحات.مثال آخر هو التقسيم. على سبيل المثال ، كيف يمكنك التحقق من كيفية عمل نظامك مع الأقسام ، مع التركيز على أحدث البيانات ، وأرشفة القديمة؟سهل! تذكر مخطط توزيع باريتو؟ يمكنك تغييره حسب احتياجاتك.
في هذه الحالة ، لا تزال المعرفات في مكان قريب ، وهناك منافسة. لكن تأثير "نقطة فعالة" واحدة أقل ، وبالتالي فإن الصراعات المحتملة ستكون الآن مع العديد من المعرّفات ، والتي يمكن أن تكون ، على عدد السجلات في الصفحة ، على عدة صفحات.مثال آخر هو التقسيم. على سبيل المثال ، كيف يمكنك التحقق من كيفية عمل نظامك مع الأقسام ، مع التركيز على أحدث البيانات ، وأرشفة القديمة؟سهل! تذكر مخطط توزيع باريتو؟ يمكنك تغييره حسب احتياجاتك. من خلال تحديد قيمة -rand-pareto ، يمكنك الحصول على ما تريده بالضبط من خلال تركيز sysbench على قيم المعرفات الكبيرة.يمكن أيضًا إعداد Zipfian ، وعلى الرغم من أنه لا يمكنك الحصول على انعكاس ، كما هو الحال مع Pareto ، يمكنك التبديل بسهولة من ذروة على قيمة واحدة إلى توزيع أكثر عدلاً. من الأمثلة الجيدة ما يلي:
من خلال تحديد قيمة -rand-pareto ، يمكنك الحصول على ما تريده بالضبط من خلال تركيز sysbench على قيم المعرفات الكبيرة.يمكن أيضًا إعداد Zipfian ، وعلى الرغم من أنه لا يمكنك الحصول على انعكاس ، كما هو الحال مع Pareto ، يمكنك التبديل بسهولة من ذروة على قيمة واحدة إلى توزيع أكثر عدلاً. من الأمثلة الجيدة ما يلي: آخر شيء يجب أخذه في الاعتبار ، ويبدو لي أن هذه أشياء واضحة ، ولكن من الأفضل أن نقول بدلاً من عدم القول أنه عند تغيير معلمات توليد الأرقام العشوائية ، سيتغير الأداء.مقارنة وقت الاستجابة:
آخر شيء يجب أخذه في الاعتبار ، ويبدو لي أن هذه أشياء واضحة ، ولكن من الأفضل أن نقول بدلاً من عدم القول أنه عند تغيير معلمات توليد الأرقام العشوائية ، سيتغير الأداء.مقارنة وقت الاستجابة: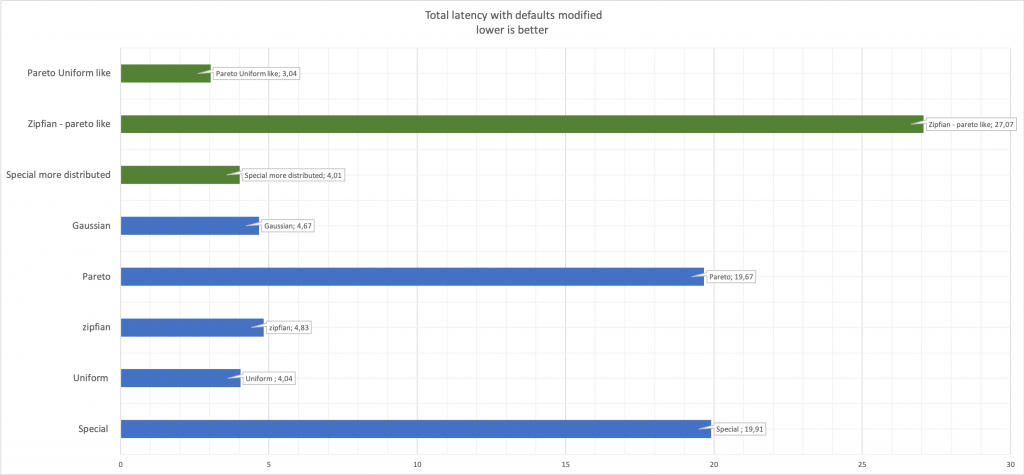 هنا ، يظهر اللون الأخضر القيم المتغيرة مقارنة باللون الأزرق الأصلي.
هنا ، يظهر اللون الأخضر القيم المتغيرة مقارنة باللون الأزرق الأصلي.
الموجودات
في هذه المرحلة ، يجب أن تفهم بالفعل مدى سهولة إعداد توليد الأرقام العشوائي في sysbench ، ومدى فائدة ذلك بالنسبة لك. ضع في اعتبارك أن ما سبق ينطبق على أي مكالمات ، على سبيل المثال ، عند استخدام sysbench.rand.default:local function get_id()
return sysbench.rand.default(1, sysbench.opt.table_size)
End
بالنظر إلى ذلك ، لا تنسخ الرمز من دون تفكير من مقالات الأشخاص الآخرين ، ولكن فكر مليًا في ما تحتاجه وكيفية تحقيق ذلك.قبل إجراء الاختبارات ، تحقق من خيارات توليد الأرقام العشوائية للتأكد من أنها مناسبة ومناسبة لاحتياجاتك. لتبسيط حياتي ، أستخدم هذا الاختبار البسيط . يعرض هذا الاختبار معلومات توزيع معرف واضحة للغاية.نصيحتي هي أنه يجب عليك فهم احتياجاتك وإجراء الاختبار / القياس بشكل صحيح.المراجع
بادئ ذي بدء ، هذا هو sysbench نفسه .مقالات عن Zipfian:باريتو:مقالة بيركونا حول كيفية كتابة البرامج النصية الخاصة بك في sysbenchجميع المواد المستخدمة في هذه المقالة موجودة على GitHub .
→ تعرف على المزيد حول الدورة