في معالجات Intel x86 الحديثة ، يمكن تقسيم خط الأنابيب إلى جزأين: الواجهة الأمامية والنهاية الخلفية.الواجهة الأمامية مسؤولة عن تحميل الرمز من الذاكرة وفك تشفيرها في العمليات الدقيقة.Back End مسؤولة عن تنفيذ العمليات الدقيقة من Front End. نظرًا لأن هذه العمليات الدقيقة يمكن إجراؤها بواسطة النواة خارج الترتيب ، فإن الطرف الخلفي يضمن أيضًا أن نتيجة هذه العمليات الدقيقة تتوافق تمامًا مع الترتيب الذي يتم فيه إدخال الرمز.في معظم الحالات ، لا يكون للاستخدام غير الفعال لـ Front End'a تأثير ملحوظ على الأداء. يبلغ عرض النطاق الترددي الأقصى لمعظم معالجات Intel 4 عمليات صغيرة في كل دورة ، لذلك ، على سبيل المثال ، بالنسبة إلى كود مرتبط بالذاكرة / L3 ، لن تتمكن وحدة المعالجة المركزية من استخدامه بالكامل.برو بحيرة الجليد جديدة نسبيا, Ice Lake 4 5 . , , .
ومع ذلك ، في بعض الحالات ، يمكن أن يكون الفرق في الأداء كبيرًا جدًا. تحت القطع هو تحليل لتأثير ذاكرة التخزين المؤقت على الأداء.محتوى المقال
- بيئة
- نظرة عامة على معالجات Front End'a Intel
- ذروة تحليل النطاق الترددي µop مخبأ -> IDQ
- مثال
بيئة
لجميع القياسات في هذه المقالة سيتم استخدام i7-8550U Kaby LakeHT / تمكين Ubuntu 18.04/Linux Kernel 5.3.0-45-generic. في هذه الحالة ، يمكن أن تكون مثل هذه البيئة كبيرة ، لأن كل نموذج CPU لديه حدث الأداء الخاص به. على وجه الخصوص ، بالنسبة للمعماريات الدقيقة الأقدم من ساندي بريدج ، فإن بعض الأحداث المستخدمة في المستقبل ببساطة لا معنى لها.نظرة عامة على معالجات Front End'a Intel
منظمة خط التجميع رفيع المستوى هي معلومات متاحة للجمهور ويتم نشرها في وثائق Intel الرسمية حول تحسين البرامج . يمكن العثور على وصف أكثر تفصيلاً لبعض الميزات التي تم حذفها من الوثائق الرسمية في مصادر أخرى مرموقة ، مثل Agner Fog أو Travis Downs . لذا ، على سبيل المثال ، يبدو مخطط خط التجميع لـ Skylake في وثائق Intel كما يلي: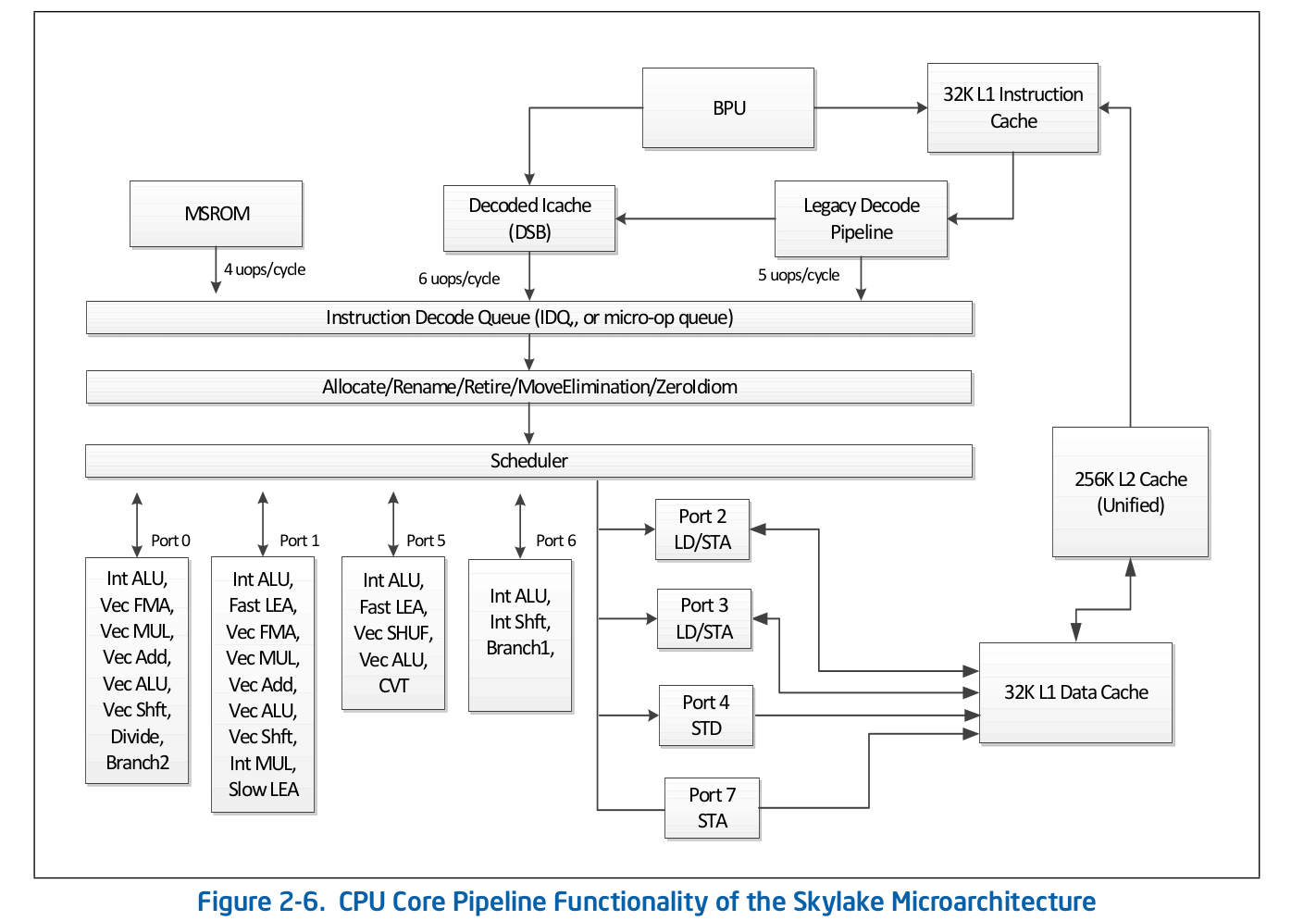 دعنا نلقي نظرة فاحصة على الجزء العلوي من هذا المخطط - الواجهة الأمامية.
دعنا نلقي نظرة فاحصة على الجزء العلوي من هذا المخطط - الواجهة الأمامية. يعتبر Legacy Decode Pipeline مسؤولًا عن فك تشفير الشفرة في العمليات الدقيقة. وتتكون من المكونات التالية:
يعتبر Legacy Decode Pipeline مسؤولًا عن فك تشفير الشفرة في العمليات الدقيقة. وتتكون من المكونات التالية:- وحدة جلب التعليمات - IFU
- مخبأ تعليمات المستوى الأول - L1i
- ذاكرة التخزين المؤقت لعنوان ترجمة سجل التعليمات - ITLB
- استاذ مدرب
- تعليمات ما قبل فك الشفرة
- قائمة انتظار التعليمات التي تم فك تشفيرها مسبقًا
- أجهزة فك تشفير التعليمات قبل التشغيل الجزئي
فكر في كل جزء من أجزاء خط أنابيب فك الترميز القديم بشكل فردي.وحدة إحضار التعليمات.وهو مسؤول عن تحميل الشفرة ، والتشفير المسبق (تحديد طول التعليمات والخصائص مثل "ما إذا كانت التعليمات فرعًا") وتسليم التعليمات التي تم فك تشفيرها مسبقًا إلى قائمة الانتظار.مخبأ تعليمات المستوى الأول - L1iلتنزيل الكود ، يستخدم IFU L1i ، وذاكرة التخزين المؤقت للإرشادات من المستوى الأول ، و L2 / LLC ، وذاكرة التخزين المؤقت من المستوى الثاني ، وذاكرة التخزين المؤقت ذات المستوى الأعلى ، الشائعة في التعليمات البرمجية والبيانات. يتم التنزيل في قطع 16 بايت ، محاذاة أيضًا 16 بايت. عندما يتم تحميل الجزء التالي من الرمز المكون من 16 بايت بالترتيب ، يتم إجراء مكالمة إلى L1i ، وإذا لم يتم العثور على السطر المقابل ، يتم إجراء البحث في L2 ، وفي حالة الفشل ، في LLC وذاكرة. قبل Skylake LLC ، كانت ذاكرة التخزين المؤقت شاملة - يجب احتواء كل سطر في L1 (i / d) و L2 في LLC. وهكذا ، فإن شركة LLC "علمت" بجميع الخطوط في جميع النوى ، وفي حالة عدم وجود شركة ذات مسؤولية محدودة ، كان من المعروف ما إذا كانت ذاكرة التخزين المؤقت في نوى أخرى تحتوي على الخط المطلوب في الحالة المعدلة ، مما يعني أنه يمكن تحميل هذا الخط من قلب آخر. أصبحت Skylake LLC مخبأ غير شامل للضحايا L2 ، ولكن تم زيادة حجم L2 4 مرات. لا أدري، لا أعرفما إذا كانت L2 شاملة بالنسبة إلى L1i. لام 2غير شامل فيما يتعلق L1d.ترجمة عناوين التعليمات المنطقية - ITLBقبل تنزيل البيانات من ذاكرة التخزين المؤقت ، يجب عليك البحث عن السطر المقابل. ل nمخابئ النقابي -way ، يمكن كل سطر يكون في nأماكن مختلفة في ذاكرة التخزين المؤقت نفسها. لتحديد المواضع المحتملة في ذاكرة التخزين المؤقت ، يتم استخدام الفهرس (عادة ما يكون عدد قليل من أجزاء أقل من العنوان). لتحديد ما إذا كان السطر يطابق العنوان الذي نحتاجه ، يتم استخدام علامة (باقي العنوان). العناوين التي يجب استخدامها: فعلي أو منطقي - تعتمد على تنفيذ ذاكرة التخزين المؤقت. يتطلب استخدام العناوين الفعلية ترجمة العنوان. لترجمة العنوان ، يتم استخدام مخزن مؤقت لـ TLB ، والذي يخزن مؤقتًا نتائج جولات الصفحة ، وبالتالي تقليل التأخير في تلقي عنوان فعلي من عنوان منطقي في المكالمات اللاحقة. للحصول على التعليمات ، يوجد مخزن التعليمات المؤقت لـ TLB الخاص به ، والذي يقع بشكل منفصل عن Data TLB. يحتوي قلب وحدة المعالجة المركزية أيضًا على TLB من المستوى الثاني شائع في التعليمات البرمجية والبيانات - STLB. ما إذا كان STLB شاملاً غير معروف بالنسبة لي (يشاع أنه ليس ذاكرة تخزين مؤقت شاملة للضحايا بالنسبة لـ D / I TLB). استخدام تعليمات الجلب المسبق للبرنامجprefetcht1يمكنك سحب الخط مع الرمز الموجود في L2 ، ومع ذلك ، سيتم سحب سجل TLB المقابل لأعلى فقط في DTLB. إذا لم يكن STLB شاملاً ، فعندما تبحث عن هذا السطر الذي يحتوي على الرمز في ذاكرة التخزين المؤقت ، ستحصل على ITLB الآنسة -> STLB miss -> مشي الصفحة (في الواقع ، الأمر ليس بهذه البساطة ، لأن النواة يمكن أن تبدأ مشي صفحة مضاربة قبل حدوثها تفوت TLB). كما تثني وثائق Intel على استخدام البادئات SW المسبقة للتعليمات البرمجية ، دليل تحسين برامج Intel / 2.5.5.4:يُقصد من الجلب المسبق الذي يتم التحكم فيه بواسطة البرنامج الجلب المسبق للبيانات ، ولكن ليس من أجل الجلب المسبق للكود.
ومع ذلك ، ذكر Travis D. أن هذا الجلب المسبق يمكن أن يكون فعالًا للغاية (وعلى الأرجح هو) ، ولكن حتى الآن هذا ليس واضحًا بالنسبة لي ومن أجل أن يقتنع بهذا ، سأحتاج إلى فحص هذه المشكلة بشكل منفصل.استاذ مدربيحدث تحميل البيانات في ذاكرة التخزين المؤقت (L1d / i ، L2 ، إلخ) عند الوصول إلى موقع ذاكرة غير مخزنة مؤقتًا. ومع ذلك ، إذا حدث هذا فقط في ظل هذه الظروف ، فعندئذٍ سنحصل على استخدام غير فعال لعرض النطاق الترددي المؤقت. على سبيل المثال ، على Sandy Bridge لعمليات قراءة L1d - 2 ، اكتب 1 16 بايت لكل دورة ؛ بالنسبة لعملية قراءة L1i - 1 لـ 16 بايت ، لم يتم تحديد صبيب الكتابة في الوثائق ، كما لم يتم العثور على Agner Fog. لحل هذه المشكلة ، هناك أجهزة الجلب المسبق للأجهزة التي يمكنها تحديد نمط الوصول إلى الذاكرة وسحب الخطوط الضرورية إلى ذاكرة التخزين المؤقت قبل أن يعالجها الرمز بالفعل. تحدد وثائق Intel 4 الجلب المسبق: 2 لـ L1d ، 2 لـ L2:- L1 DCU - خطوط ذاكرة التخزين المؤقت التسلسلية البادئة. قراءة فقط للأمام
- L1 IP — (. 0x5555555545a0, 0x5555555545b0, 0x5555555545c0, ...), , ,
- L2 Spatial — L2 -, 128-. LLC
- L2 Streamer — . L1 DCU «». LLC
لا تصف وثائق Intel مبدأ مقدم الحماية L1i. كل ما هو معروف هو أن وحدة التنبؤ بالفروع (BPU) ضالعة في هذه العملية ، دليل تحسين برامج Intel / 2.6.2: لا يرى Agner Fog أيضًا أي تفاصيل.يتم تعريف الجلب المسبق للرمز في L2 / LLC بشكل صريح فقط لـ Streamer. دليل التحسين / 2.5.5.4 تحديد البيانات:
لا يرى Agner Fog أيضًا أي تفاصيل.يتم تعريف الجلب المسبق للرمز في L2 / LLC بشكل صريح فقط لـ Streamer. دليل التحسين / 2.5.5.4 تحديد البيانات:غاسل : يراقب هذا الجلب المسبق طلبات القراءة من ذاكرة التخزين المؤقت L1 للتسلسل التصاعدي والتنازلي للعناوين. تتضمن طلبات القراءة التي يتم مراقبتها طلبات L1 DCache التي تم بدءها من خلال عمليات التحميل والتخزين ومن خلال أجهزة الجلب المسبق للأجهزة وطلبات L1 ICache لجلب التعليمات البرمجية.
بالنسبة إلى الجلب المسبق المكاني ، فمن الواضح أنه لم يتم توضيح ذلك:الجلب المسبق المكاني: يسعى هذا الجلب المسبق إلى إكمال كل خط ذاكرة تخزين مؤقت يتم جلبه إلى ذاكرة التخزين المؤقت L2 باستخدام خط الزوج الذي يكمله إلى مقطع محاذي 128 بايت.
ولكن يمكن التحقق من ذلك. يمكن إيقاف كل من هذه الجلب المسبق باستخدام MSR 0x1A4، كما هو موضح في دليل السجلات الخاصة بالنموذج .حول MSR 0x1A4MSR L2 Spatial L1i. . , LLC. L2 Streamer 2.5 .
Linux msr , msr . $ sudo wrmsr -p 1 0x1a4 1 L2 Streamer 1.
تعليمات ما قبل وحدة فك التشفيربعد تحميل الكود التالي المكون من 16 بايت ، تقع في تعليمات ما قبل وحدة التشفير. وتتمثل مهمتها في تحديد طول التعليمات ، وفك تشفير البادئات ، وتحديد ما إذا كانت التعليمات المقابلة فرعًا (على الأرجح لا يزال هناك العديد من الخصائص المختلفة ، ولكن الوثائق المتعلقة بها صامتة). دليل تحسين برامج Intel / 2.6.2.2:The predecode unit accepts the sixteen bytes from the instruction cache or prefetch buffers and carries out the following tasks:
- Determine the length of the instructions
- Decode all prefixes associated with instructions
- Mark various properties of instructions for the decoders (for example, “is branch.”)
خط من التعليمات التي تم فك تشفيرها مسبقًا.من IFU ، تتم إضافة التعليمات إلى قائمة انتظار التعليمات المشفرة مسبقًا. ظهرت قائمة الانتظار هذه منذ Nehalem ، وفقًا لوثائق Intel ، يبلغ حجمها 18 تعليمات. يذكر Agner Fog أيضًا أن قائمة الانتظار هذه لا تحتوي على أكثر من 64 بايت.أيضًا في Core2 ، تم استخدام قائمة الانتظار هذه كذاكرة تخزين مؤقت للحلقة. إذا كانت جميع العمليات الدقيقة من الدورة في قائمة الانتظار ، فيمكن في بعض الحالات تجنب تكلفة التحميل والتشفير المسبق. يمكن أن يكشف كاشف تيار الحلقة (LSD) الإرشادات الموجودة بالفعل في قائمة الانتظار حتى تشير BPU إلى انتهاء الدورة. لدى Agner Fog عدد من الملاحظات المثيرة للاهتمام بخصوص LSD على Core2:- يتكون من 4 أسطر 16 بايت
- سرعة نقل قصوى تصل إلى 32 بايت من التعليمات البرمجية لكل دورة
بدءًا من Sandy Bridge ، تم نقل ذاكرة التخزين المؤقت الحلقي هذه من قائمة انتظار التعليمات التي تم فك تشفيرها مسبقًا إلى IDQ.أجهزة فك التشفير للتعليمات التي تم فك تشفيرها مسبقًا في التشغيل الدقيقمن قائمة انتظار التعليمات التي تم فك تشفيرها مسبقًا ، يتم إرسال التعليمات البرمجية إلى فك التشفير في التشغيل الدقيق. أجهزة فك التشفير مسؤولة عن فك التشفير - هناك 4 في المجموع. وفقًا لوثائق Intel ، يمكن لأحد أجهزة فك التشفير فك تشفير التعليمات التي تتكون من 4 عمليات دقيقة أو أقل. الباقي يفك تشفير التعليمات التي تتكون من عملية دقيقة واحدة (تنصهر ميكرو / ماكرو) ، دليل تحسين برامج Intel / 2.5.2.1:There are four decoding units that decode instruction into micro-ops. The first can decode all IA-32 and Intel 64 instructions up to four micro-ops in size. The remaining three decoding units handle single-micro-op instructions. All four decoding units support the common cases of single micro-op flows including micro-fusion and macro-fusion.
التعليمات التي تم فك تشفيرها في عدد كبير من العمليات الدقيقة (مثل مندوب movsb المستخدم في تنفيذ memcpy في libc على أحجام معينة من الذاكرة المنسوخة) تأتي من جهاز التسلسل الصغير (MS ROM). عرض نطاق الذروة لجهاز التسلسل هو 4 عمليات دقيقة لكل دورة.كما ترى في الرسم التخطيطي لخط التجميع ، يمكن لخط أنابيب فك الترميز القديم فك تشفير ما يصل إلى 5 عمليات دقيقة لكل دورة على Skylake. في برودويل وكبار السن ، كانت ذروة إنتاجية خط أنابيب Legacy Decode Pipeline 4 عمليات دقيقة لكل دورة.ذاكرة التخزين المؤقت الصغيرةبعد فك تشفير التعليمات في العمليات الدقيقة ، من خط أنابيب فك الترميز القديم ، تقع في قائمة انتظار العمليات الدقيقة الخاصة - قائمة انتظار فك تشفير التعليمات (IDQ) ، بالإضافة إلى ما يسمى ذاكرة التخزين المؤقت الصغيرة (Decoded ICache ، µop cache). تم إدخال ذاكرة التخزين المؤقت الصغيرة في الأصل في Sandy Bridge ويتم استخدامها لتجنب جلب التعليمات وفك تشفيرها في العمليات الدقيقة ، وبالتالي زيادة الإنتاجية لتقديم العمليات الدقيقة في IDQ - حتى 6 لكل دورة. بعد الدخول إلى IDQ ، تذهب العمليات الدقيقة إلى النهاية الخلفية للتنفيذ مع إنتاجية قصوى تبلغ 4 عمليات دقيقة في كل دورة.وفقًا لوثائق Intel ، تتكون ذاكرة التخزين المؤقت الصغيرة من 32 مجموعة ، تحتوي كل مجموعة على 8 أسطر ، ويمكن لكل سطر تخزين مؤقت يصل إلى 6 عمليات ميكرو (تنصهر مايكرو / ماكرو) ، مما يسمح بذاكرة تخزين مؤقت إجمالية تصل إلى 32 * 8 * 6 = 1536 عملية مايكرو . يحدث التخزين المؤقت في Microoperation بدرجة دقة 32 بايت ، أي لا يمكن أن تقع العمليات الدقيقة التي تتبع تعليمات من مناطق 32 بايت مختلفة في سطر واحد. ومع ذلك ، يمكن أن تتوافق حتى 3 خطوط ذاكرة تخزين مؤقت مختلفة مع منطقة واحدة من 32 بايت. وبالتالي ، يمكن أن تتوافق حتى 18 عملية صغيرة في ذاكرة التخزين المؤقت µop مع كل منطقة 32 بايت.دليل تحسين برامج Intel / 2.5.5.2The Decoded ICache consists of 32 sets. Each set contains eight Ways. Each Way can hold up to six micro-ops. The Decoded ICache can ideally hold up to 1536 micro-ops. The following are some of the rules how the Decoded ICache is filled with micro-ops:
- ll micro-ops in a Way represent instructions which are statically contiguous in the code and have their EIPs within the same aligned 32-byte region.
- Up to three Ways may be dedicated to the same 32-byte aligned chunk, allowing a total of 18 micro-ops to be cached per 32-byte region of the original IA program.
- A multi micro-op instruction cannot be split across Ways.
- Up to two branches are allowed per Way.
- An instruction which turns on the MSROM consumes an entire Way.
- A non-conditional branch is the last micro-op in a Way.
- Micro-fused micro-ops (load+op and stores) are kept as one micro-op.
- A pair of macro-fused instructions is kept as one micro-op.
- Instructions with 64-bit immediate require two slots to hold the immediate.
يشير Agner Fog أيضًا إلى أنه يمكن تنزيل العمليات الدقيقة ذات الخط الواحد فقط لكل دورة (غير مذكورة صراحةً في وثائق Intel ، على الرغم من أنه يمكن التحقق منها بسهولة يدويًا).µop cache --> IDQ
في بعض الحالات ، من الملائم جدًا استخدام nopأطوال 1 بايت لدراسة سلوك الواجهة الأمامية . في الوقت نفسه ، يمكننا التأكد من أننا نحقق في الواجهة الأمامية ، وليس في كشك الموارد في النهاية الخلفية ، لأي سبب. والحقيقة هي أنه nopبالإضافة إلى التعليمات الأخرى ، يتم فك تشفيرها في خط أنابيب فك الترميز القديم ، ويتم خلطها في ذاكرة التخزين المؤقت µop وإرسالها إلى IDQ. علاوة على ذلك nop، بالإضافة إلى تعليمات أخرى ، تأخذ النهاية. الفرق الكبير هو أن الموارد الموجودة على النهاية الخلفية nopتستخدم فقط إعادة ترتيب المخزن المؤقت ولا تتطلب فتحة في محطة الحجز (الملقب المجدول). وبالتالي ، فور دخول Reorder Buffer ، يصبح nopجاهزًا للتقاعد ، والذي سيتم تنفيذه وفقًا للترتيب الوارد في رمز البرنامج.لاختبار الإنتاجية ، أعلن عن وظيفةvoid test_decoded_icache(size_t iteration_count);
مع التنفيذ على nasm:align 32
test_decoded_icache:
;nop', 0 23
dec rdi
ja test_decoded_icache
ret
jaلم يتم اختياره عن طريق الصدفة. jaو decاستخدام الأعلام المختلفة - jaيقرأ من CFو ZF، decلا تسجيل في CF، ماكرو حتى الانصهار لا ينطبق. يتم ذلك فقط من أجل الراحة في حساب العمليات الدقيقة في دورة - كل تعليمات تقابل عملية دقيقة واحدة.للقياسات ، نحتاج إلى أحداث الأداء التالية:1. uops_issued.any- يُستخدم لحساب العمليات الدقيقة التي تأخذها Renamer من IDQ.يوثق دليل برمجة نظام Intel هذا الحدث باعتباره عدد العمليات الدقيقة التي تضعها Renamer في محطة الحجز:تحسب عدد عمليات التشغيل التي يصدرها جدول تخصيص الموارد (RAT) لمحطة الحجز (RS).
لا يرتبط هذا الوصف تمامًا بالقيم التي يمكن الحصول عليها من التجارب. على وجه الخصوص ، nopيقعون في هذا المنضدة ، على الرغم من حقيقة أنهم ليسوا بحاجة إليها على الإطلاق في محطة الحجز.2. uops_retired.retire_slots- العدد الإجمالي للعمليات الدقيقة المتقاعدة مع مراعاة الانصهار الجزئي / الكلي3. uops_retired.stall_cycles- عدد القراد الذي لم يكن هناك عملية صغيرة متقاعدة واحدة4. resource_stalls.any- عدد القراد من الناقل الخامل بسبب عدم إمكانية الوصول إلى أي من الموارد الخلفيةفي دليل تحسين برامج Intel / B .4.1 هناك رسم تخطيطي للمحتوى يميز الأحداث الموصوفة أعلاه: 5.
5. idq.all_dsb_cycles_4_uops- عدد دورات الساعة التي تم تسليم 4 تعليمات (أو أكثر) من ذاكرة التخزين المؤقت µop.حقيقة أن هذا المقياس يأخذ في الاعتبار تسليم أكثر من 4 عمليات دقيقة في كل دورة لم يتم وصفها في وثائق Intel ، ولكنها تتوافق جيدًا مع التجارب.6. idq.all_dsb_cycles_any_uops- عدد القياسات التي تم من أجلها إجراء عملية دقيقة واحدة على الأقل.7. idq.dsb_cycles- العدد الإجمالي للمقاييس التي تم فيها التسليم من µop cache8. idq_uops_not_delivered.cycles_le_N_uop_deliv.core- عدد المقاييس التي قامت Renamer بإجراء عملية دقيقة واحدة Nأو أقل ولم يكن هناك فترة توقف في الجانب الخلفي ، N- 1 ، 2 ، 3.نتخذها للبحث iteration_count = 1 << 31. نبدأ تحليل ما يحدث في وحدة المعالجة المركزية من خلال فحص عدد العمليات الدقيقة ، أولاً ، عن طريق قياس متوسط عرض نطاق التقاعد ، أي uops_retired.retire_slots/uops_retired.total_cycle: ما يلفت انتباهك على الفور هو هبوط معدل التقاعد عند دورة بحجم 7 عمليات دقيقة. من أجل فهم ماهيتها ، دعنا نفكر في كيفية متوسط معدل تسليم ذاكرة التخزين المؤقت μop -
ما يلفت انتباهك على الفور هو هبوط معدل التقاعد عند دورة بحجم 7 عمليات دقيقة. من أجل فهم ماهيتها ، دعنا نفكر في كيفية متوسط معدل تسليم ذاكرة التخزين المؤقت μop - idq.all_dsb_cycles_any_uops / idq.dsb_cycles: وكيفية ربط العدد الإجمالي لدورات الساعة والدورات التي يتم تسليم ذاكرة التخزين المؤقت μop لها في IDQ:
وكيفية ربط العدد الإجمالي لدورات الساعة والدورات التي يتم تسليم ذاكرة التخزين المؤقت μop لها في IDQ: وبالتالي يمكن ملاحظة أن دورة 6 عمليات صغيرة لدينا فعالة µop استخدام عرض النطاق الترددي المؤقت - 6 عمليات صغيرة لكل دورة. نظرًا لحقيقة أن Renamer لا يمكنها أن تأخذ قدر ما توفره ذاكرة التخزين المؤقت µop ، فإن جزءًا من دورات التخزين المؤقت µop لا يقدم أي شيء ، وهو ما يمكن رؤيته بوضوح في الرسم البياني السابق.مع دورة من 7 عمليات دقيقة ، نحصل على انخفاض حاد في صبيب ذاكرة التخزين المؤقت µop - 3.5 عملية دقيقة في كل دورة. في الوقت نفسه ، كما يمكن رؤيته من الرسم البياني السابق ، تعمل ذاكرة التخزين المؤقت µop باستمرار. وهكذا ، مع دورة من 7 عمليات دقيقة ، نحصل على استخدام غير فعال لذاكرة التخزين المؤقت bandop لعرض النطاق الترددي. والحقيقة هي أنه ، كما ذكرنا سابقًا ، يمكن أن توفر ذاكرة التخزين المؤقت µop لكل دورة عمليات دقيقة من سطر واحد فقط. في حالة العمليات الدقيقة 7 - أول 6 تقع في سطر واحد ، والباقي 7 - في آخر. وبهذه الطريقة نحصل على 7 عمليات دقيقة لكل دورتين أو 3.5 عمليات دقيقة لكل دورة.الآن دعونا نلقي نظرة على كيفية أخذ Renamer للعمليات الدقيقة من IDQ. لهذا نحتاج
وبالتالي يمكن ملاحظة أن دورة 6 عمليات صغيرة لدينا فعالة µop استخدام عرض النطاق الترددي المؤقت - 6 عمليات صغيرة لكل دورة. نظرًا لحقيقة أن Renamer لا يمكنها أن تأخذ قدر ما توفره ذاكرة التخزين المؤقت µop ، فإن جزءًا من دورات التخزين المؤقت µop لا يقدم أي شيء ، وهو ما يمكن رؤيته بوضوح في الرسم البياني السابق.مع دورة من 7 عمليات دقيقة ، نحصل على انخفاض حاد في صبيب ذاكرة التخزين المؤقت µop - 3.5 عملية دقيقة في كل دورة. في الوقت نفسه ، كما يمكن رؤيته من الرسم البياني السابق ، تعمل ذاكرة التخزين المؤقت µop باستمرار. وهكذا ، مع دورة من 7 عمليات دقيقة ، نحصل على استخدام غير فعال لذاكرة التخزين المؤقت bandop لعرض النطاق الترددي. والحقيقة هي أنه ، كما ذكرنا سابقًا ، يمكن أن توفر ذاكرة التخزين المؤقت µop لكل دورة عمليات دقيقة من سطر واحد فقط. في حالة العمليات الدقيقة 7 - أول 6 تقع في سطر واحد ، والباقي 7 - في آخر. وبهذه الطريقة نحصل على 7 عمليات دقيقة لكل دورتين أو 3.5 عمليات دقيقة لكل دورة.الآن دعونا نلقي نظرة على كيفية أخذ Renamer للعمليات الدقيقة من IDQ. لهذا نحتاج idq_uops_not_delivered.coreو idq_uops_not_delivered.cycles_le_N_uop_deliv.core: قد تلاحظ أنه مع 7 عمليات دقيقة ، تستغرق 3 عمليات دقيقة فقط في كل مرة نصف دورات Renamer. من هنا نحصل على معدل تقاعد بمعدل 3.5 عمليات دقيقة لكل دورة.يمكن رؤية نقطة أخرى مثيرة للاهتمام تتعلق بهذا المثال إذا نظرنا في الإنتاجية الفعالة للتقاعد. أولئك. لا تفكر
قد تلاحظ أنه مع 7 عمليات دقيقة ، تستغرق 3 عمليات دقيقة فقط في كل مرة نصف دورات Renamer. من هنا نحصل على معدل تقاعد بمعدل 3.5 عمليات دقيقة لكل دورة.يمكن رؤية نقطة أخرى مثيرة للاهتمام تتعلق بهذا المثال إذا نظرنا في الإنتاجية الفعالة للتقاعد. أولئك. لا تفكر uops_retired.stall_cycles: يمكن ملاحظة أنه مع 7 عمليات مجهرية ، يتم تنفيذ كل 7 مقاييس للتقاعد لـ 4 عمليات مجهرية ، وكل مقياس ثامن يكون خاملاً مع عدم وجود عمليات مجهرية متقاعدة (كشك التقاعد). بعد إجراء سلسلة من التجارب ، كان من الممكن اكتشاف أن مثل هذا السلوك لوحظ دائمًا خلال 7 عمليات دقيقة ، بغض النظر عن تخطيطها 1-6 ، 6-1 ، 2-5 ، 5-2 ، 3-4 ، 4-3. لا أعرف لماذا هذا هو الحال بالضبط ، وليس ، على سبيل المثال ، يتم إجراء تقاعد 3 عمليات دقيقة في دورة ساعة واحدة ، و 4 في الدورة التالية. ذكر Agner Fog أن انتقالات الفروع لا يمكنها استخدام سوى جزء من فتحات محطة التقاعد. ربما هذا التقييد هو سبب هذا السلوك التقاعد.
يمكن ملاحظة أنه مع 7 عمليات مجهرية ، يتم تنفيذ كل 7 مقاييس للتقاعد لـ 4 عمليات مجهرية ، وكل مقياس ثامن يكون خاملاً مع عدم وجود عمليات مجهرية متقاعدة (كشك التقاعد). بعد إجراء سلسلة من التجارب ، كان من الممكن اكتشاف أن مثل هذا السلوك لوحظ دائمًا خلال 7 عمليات دقيقة ، بغض النظر عن تخطيطها 1-6 ، 6-1 ، 2-5 ، 5-2 ، 3-4 ، 4-3. لا أعرف لماذا هذا هو الحال بالضبط ، وليس ، على سبيل المثال ، يتم إجراء تقاعد 3 عمليات دقيقة في دورة ساعة واحدة ، و 4 في الدورة التالية. ذكر Agner Fog أن انتقالات الفروع لا يمكنها استخدام سوى جزء من فتحات محطة التقاعد. ربما هذا التقييد هو سبب هذا السلوك التقاعد.مثال
لفهم ما إذا كان كل هذا له تأثير عمليًا ، ضع في اعتبارك المثال التالي الأكثر عملية قليلاً من nops:يتم إعطاء صفيفين unsigned. من الضروري تجميع مجموع الوسائل الحسابية لكل فهرس وكتابته في المصفوفة الثالثة.قد يبدو تنفيذ المثال كما يلي:
static unsigned arr1[] = { ... };
static unsigned arr2[] = { ... };
static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
int main(void){
unsigned out[sizeof arr1 / sizeof(unsigned)];
for(size_t i = 0; i < 4096 * 4096; i++){
arithmetic_mean(arr1, arr2, out, sizeof arr1 / sizeof(unsigned));
}
}
ترجمة مع أعلام دول مجلس التعاون الخليجي-Werror
-Wextra
-Wall
-pedantic
-Wno-stack-protector
-g3
-O3
-Wno-unused-result
-Wno-unused-parameter
من الواضح أن الوظيفة arithmetic_meanلن تكون موجودة في الكود وسيتم إدراجها مباشرة في main:(gdb) disas main
Dump of assembler code for function main:
#...
0x00000000000005dc <+60>: nop DWORD PTR [rax+0x0]
0x00000000000005e0 <+64>: mov edx,DWORD PTR [rdi+rax*4]
0x00000000000005e3 <+67>: add edx,DWORD PTR [r8+rax*4]
0x00000000000005e7 <+71>: shr edx,1
0x00000000000005e9 <+73>: add ecx,edx
0x00000000000005eb <+75>: mov DWORD PTR [rsi+rax*4],ecx
0x00000000000005ee <+78>: add rax,0x1
0x00000000000005f2 <+82>: cmp rax,0x80
0x00000000000005f8 <+88>: jne 0x5e0 <main+64>
0x00000000000005fa <+90>: sub r9,0x1
0x00000000000005fe <+94>: jne 0x5d8 <main+56>
#...
لاحظ أن المترجم قام بمحاذاة كود الحلقة إلى 32 بايت ( nop DWORD PTR [rax+0x0]) ، وهو بالضبط ما نحتاجه. بعد التأكد من عدم وجود resource_stalls.anyنهاية خلفية (يتم إجراء جميع القياسات مع مراعاة ذاكرة التخزين المؤقت L1d ساخنة) ، يمكننا البدء في النظر في العدادات المرتبطة بالتسليم إلى IDQ: Performance counter stats for './test_decoded_icache':
2 273 343 251 idq.all_dsb_cycles_4_uops (15,94%)
4 458 322 025 idq.all_dsb_cycles_any_uops (16,26%)
15 473 065 238 idq.dsb_uops (16,59%)
4 358 690 532 idq.dsb_cycles (16,91%)
2 528 373 243 idq_uops_not_delivered.core (16,93%)
73 728 040 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,93%)
107 262 304 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,93%)
108 454 043 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,65%)
2 248 557 762 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,32%)
2 385 493 805 idq_uops_not_delivered.cycles_fe_was_ok (16,00%)
15 147 004 678 uops_retired.retire_slots
4 724 790 623 uops_retired.total_cycles
1,228684264 seconds time elapsed
لاحظ أن سوء تقاعد التقاعد في هذه الحالة = 15147004678/4724790623 = 3.20585733562 ، وأن 3 عمليات دقيقة فقط تأخذ نصف ساعات Renamer.الآن أضف الترويج العرقي اليدوي إلى التنفيذ:static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
if(sz & 2){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
تبدو عدادات الأداء الناتجة مثل:Performance counter stats for './test_decoded_icache':
2 152 818 549 idq.all_dsb_cycles_4_uops (14,79%)
3 207 203 856 idq.all_dsb_cycles_any_uops (15,25%)
12 855 932 240 idq.dsb_uops (15,70%)
3 184 814 613 idq.dsb_cycles (16,15%)
24 946 367 idq_uops_not_delivered.core (16,24%)
3 011 119 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,24%)
5 239 222 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,24%)
7 373 563 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,24%)
7 837 764 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,24%)
3 418 529 799 idq_uops_not_delivered.cycles_fe_was_ok (16,24%)
3 444 833 440 uops_retired.total_cycles (18,18%)
13 037 919 196 uops_retired.retire_slots (18,17%)
0,871040207 seconds time elapsed
في هذه الحالة ، لدينا عرض نطاق تقاعد = 13037919196/3444833440 = 3.78477491672 ، بالإضافة إلى الاستخدام الفعال لعرض النطاق الترددي Renamer.وبالتالي ، لم نتخلص فقط من تفرع واحد وعملية زيادة واحدة في حلقة ، ولكن أيضًا قمنا بزيادة معدل نقل بيانات التقاعد باستخدام الاستخدام الفعال لصبيب ذاكرة التخزين المؤقت الصغيرة ، والتي أعطت زيادة بنسبة 28 ٪ في الأداء.لاحظ أن الانخفاض في فرع واحد وعملية الزيادة فقط يعطي زيادة في الأداء بمعدل 9٪.ملاحظة صغيرة
على وحدة المعالجة المركزية التي تم استخدامها لإجراء هذه التجارب ، يتم إيقاف تشغيل LSD. يبدو أن LSD يمكنها التعامل مع مثل هذه الحالة. بالنسبة لوحدات المعالجة المركزية مع تمكين LSD ، يجب التحقق من هذه الحالات بشكل منفصل.