في كثير من الأحيان ، من خلال خبرتي التي تبلغ 15 عامًا كمطور برامج وقائد فريق ، أواجه نفس الشيء. تتحول البرمجة إلى دين - نادرًا ما يحاول أي شخص إدخال التكنولوجيا بناءً على خيار معقول ، بشكل معقول ، مع مراعاة القيود وإمكانية النقل وتقييم درجة التعلق بالمورد والسعر الحقيقي وآفاق التكنولوجيا وحرية الترخيص. يذهب المطورون إلى المؤتمرات أو يقرأون المنشورات - ابدأ الضجيج ، ولا يتم إطعام مدراء تكنولوجيا المعلومات والمديرين لديهم فقط بحكايات مستقبل مشرق مشرق في الأحداث ، ومختلف الرؤى ، والمبيعات والاستشاريين. وتبين أن التقنيات كانت في المشروع لا تأخذ في الاعتبار راحة التطوير والتنفيذ ، والمتطلبات غير الوظيفية للمشروع ، ولكن لأنه ضجيج ويستخدم google نفسه ،توصي أمازون (على الرغم من أن الشواغر الخاصة بهم تقول أنهم أنفسهم لا يستخدمونها غالبًا) أو أن أعلى قرار اتخذته إدارة الشركة لتطبيق "هذا".
ما يؤثر على اختيار قاعدة البيانات
من وجهة نظري ، عند اختيار قاعدة بيانات ، يجب أن أحل على الأقل المقايضات التالية:- معالجة المعاملات في الوقت الحقيقي أو المعالجة التحليلية عبر الإنترنت
- قابل للتطوير رأسيًا أو أفقيًا
- في حالة القاعدة الموزعة - اتساق البيانات / توافر / مقاومة الفصل (نظرية CAP)
- مخطط بيانات محدد وقيود في قاعدة البيانات أو التخزين لا يتطلب مخطط بيانات
- نموذج البيانات - القيمة الرئيسية أو الهرمية أو الرسم البياني أو الوثيقة أو العلائقية
- منطق المعالجة أقرب ما يكون إلى البيانات أو كل معالجة في التطبيق
- تعمل بشكل رئيسي في ذاكرة الوصول العشوائي أو مع نظام فرعي للقرص
- حل شامل أو متخصص
- نستخدم الخبرة الموجودة في قاعدة بيانات ليست مناسبة بشكل خاص لمتطلبات المشروع أو نطور تجربة جديدة في تدريب مناسب ولكن غير مألوف ، "الدم والعرق" (نفس الشيء لا ينطبق على التطوير فحسب ، بل أيضًا على التشغيل)
- مدمج أو في عملية / شبكة أخرى
- محب أو رجعي
غالبًا ما نحصل على "هدية" للحل المُنفذ:- لغة الاستعلام "الغريبة"
- واجهة برمجة التطبيقات الأصلية الوحيدة للعمل مع قاعدة البيانات ، الأمر الذي سيعقد الانتقال إلى قواعد البيانات الأخرى (تم إنفاق الوقت وجهد الفريق وميزانية المشروع)
- عدم توفر برامج تشغيل لمنصات / لغات / أنظمة تشغيل أخرى
- نقص رموز المصدر ، أوصاف تنسيق البيانات على القرص (أو حظر التراخيص الهندسية العكسية ، خاصة Oracle مع buggy Coherence)
- نمو تكلفة الترخيص سنة بعد سنة
- النظام البيئي الخاص وصعوبة العثور على المتخصصين
- , ,
القياس الأفقي للأنظمة معقد للغاية ويتطلب خبرة الفريق. يعد المطورون ذوو الخبرة مكلفين للغاية في السوق ، والتطبيقات الموزعة أكثر صعوبة في التطوير والتصحيح والاختبار. لذلك ، إذا كان من الممكن تغيير الخادم إلى خادم أكثر قوة وكمية البيانات التي يسمح بها النظام ، فغالبًا ما يفعلون ذلك. الآن يمكن أن تحتوي الخوادم على تيرابايت من ذاكرة الوصول العشوائي ومئات نوى المعالج على متنها. لذلك ، كما لم يحدث من قبل ، يصبح من المهم استخدام جميع موارد الخادم بأكبر قدر ممكن من الكفاءة. تكلفة تراخيص قاعدة البيانات مهمة أيضًا ، وإذا تم بيعها بواسطة نوى المعالج ، فإن ميزانية التشغيل ، حتى مع التحجيم الرأسي ، يمكن أن تكلف بقدر تكلفة برنامج مساحة القوة العظمى. لذلك ، من المهم أن تضع ذلك في الاعتبار حتى لا تتمكن من قياس أداء قاعدة البيانات بسبب التراخيص.من الواضح أنه بمساعدة التسويق سيحاولون إقناعك بأن حل شركة معينة فقط سيحل جميع مشاكلك (لكنهم صامتون بشأن عدد المشاكل الجديدة التي ستظهر). لا توجد قاعدة بيانات مثالية واحدة تناسب الجميع ومناسبة لكل شيء.لذلك في المستقبل المنظور ، سنستمر في دعم العديد من قواعد البيانات المختلفة لمعالجة نفس البيانات لأنواع مختلفة من الاستعلامات في أنظمة مختلفة. لا توجد حلول لنسيج البيانات بدون تخزين مؤقت للبيانات ، لا يمكن مقارنة Data Lake بعد مع قواعد البيانات ذات البنية المتوازية الجماعية من حيث الأداء والاستعلام الأمثل. ستظل بيانات المعاملات مخزنة في PostgreSQL و Oracle و MS Sql Server والاستعلامات التحليلية في Citus و Greenplum و Snowflake و Redshift و Vertica و Impala و Teradata وستدير مستنقعات البيانات الخام في HDFS / S3 / ADLS (Azure) بواسطة Dremio ، Redshift Spectrum ، Apache Spark ، Presto.لكن الحلول المذكورة أعلاه غير مناسبة بشكل سيئ لتحليل بيانات السلاسل الزمنية بوقت استجابة منخفض. وفقًا لشعبيتها في العمل مع بيانات السلاسل الزمنية ، فهي الآن في المفضلة من InfluxDB. في مكانة قاعدة البيانات في الذاكرة ، يحتفظ kdb + و memSQL بأماكنهما.QuestDB
ما الذي يمكن أن يعارض كل حلول QuestDB مفتوحة المصدر هذه بترخيص Apache؟- محاولة لتحقيق أقصى استفادة من الأجهزة لأداء الاستعلامات التحليلية - توجيه وظائف التجميع ، والعمل مع البيانات من خلال ملفات الذاكرة المعينة
- SQL كلغة لاستعلامات DML وعمليات DDL لإدارة بنية قاعدة البيانات
- دعم جداول الانضمام الخاصة بالسلسلة الزمنية DB
- دعم وظائف النافذة والتجميع في SQL
- القدرة على تضمين قاعدة بيانات في تطبيق على JVM
- JVM, ServiceLoader
- Influx DB line protocol (ILP) UDP Telegraf. «What makes QuestDB faster than InfluxDB»
- PostgreSql 11 PostgreSQL: JDBC, ODBC psql
- web - REST endpoint , SQL json
- ,
- zero-GC API, .
- ( )
- 64 Windows, Linux, OSX, ARM Linux FreeBSD
- , open source,
عندما تكون قاعدة البيانات هذه مفيدة لك - إذا كنت تقوم بتطوير أنظمة مالية على JVM بوقت استجابة منخفض وتحتاج إلى حل لتحليلات البيانات في ذاكرة الوصول العشوائي. كبديل لـ kdb + بسبب تكلفة التراخيص. إذا جمعت المقاييس وفقًا لبروتوكول Influx / Telegraf ، إلا أن أداء وسهولة الاستخدام مع InfluxDB غير مرضٍ. إذا كان مشروعك يعمل على JVM وتحتاج إلى قاعدة بيانات مدمجة لتخزين المقاييس أو بيانات التطبيق التي يتم إضافتها فقط وعدم تحديثها.الإصدار الجديد 4.2.0 مع دعم لتعليمات SIMD تسبب في موجة من التعليقات على Reddit . لكي يشارك المعجبون في منافسة المعرفة بالأجهزة الحديثة وبرمجتها الفعالة ، أوصي بالتحدث إلى مؤلف قاعدة البيانات (bluestreak01) في التعليقات!عمليات SIMD
أجرى
فريق المشروع اختبارًا على البيانات الاصطناعية وقارنوا QuestDB 4.2.0 مع kdb 4.0 لتجميع مليار قيمة ، باستخدام تعليمات SIMD للمعالجات.على منصة Intel 8850H: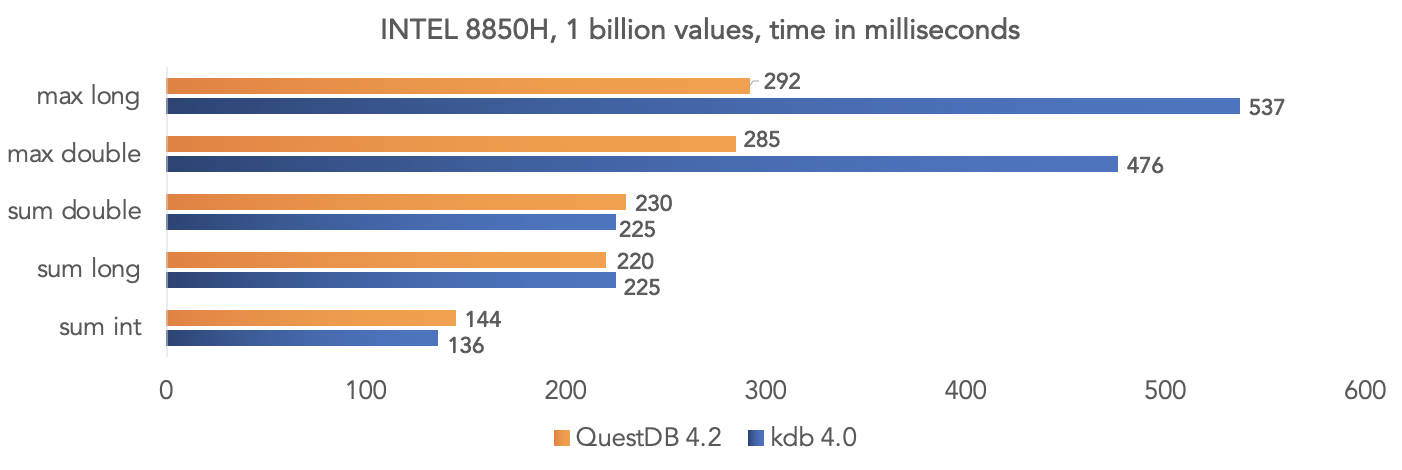 على منصة AMD Ryzen 3900X:
على منصة AMD Ryzen 3900X: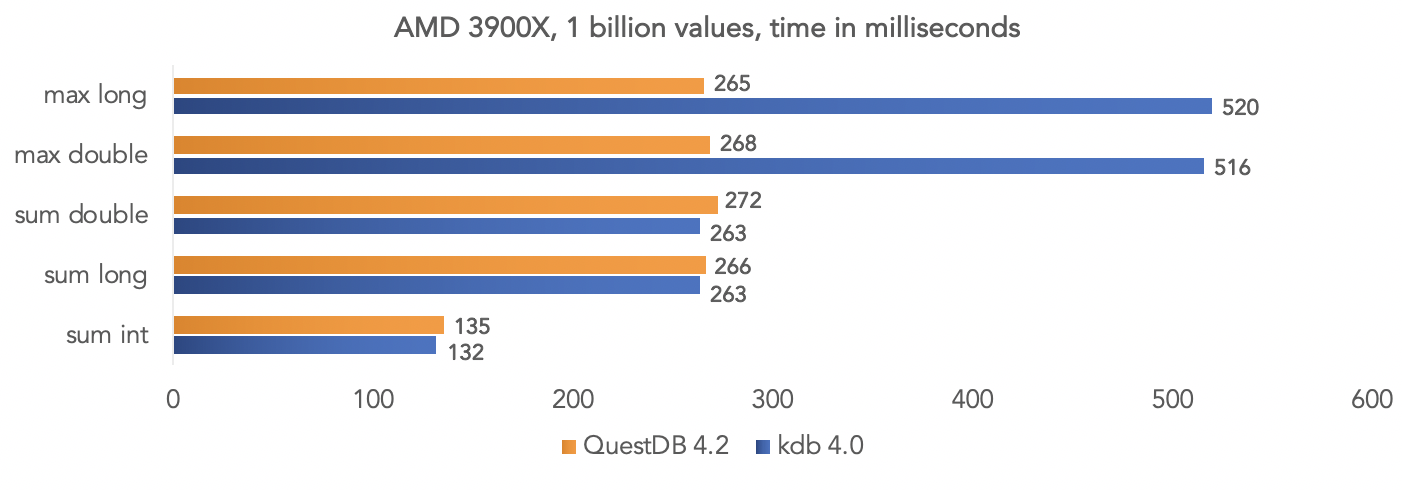 من الواضح أن هذه كلها اختبارات في "فراغ" ، ولكن يمكنك مقارنة بياناتك إذا كان مشروعك يستخدم kdb ومشاركة النتائج مع المجتمع.
من الواضح أن هذه كلها اختبارات في "فراغ" ، ولكن يمكنك مقارنة بياناتك إذا كان مشروعك يستخدم kdb ومشاركة النتائج مع المجتمع.تشغيل صورة قاعدة بيانات عامل الميناء
يتم نشر قاعدة البيانات على dockerhub مع كل إصدار. يتم وصف المزيد من التفاصيل في وثائق المشروع .احصل على صورة QuestDB:docker pull questdb/questdb
أطلقنا:docker run --rm -it -p 9000:9000 -p 8812:8812 questdb/questdb
بعد ذلك ، يمكنك الاتصال باستخدام بروتوكول PostgreSQL للمنفذ 8812 ، تتوفر وحدة تحكم الويب على المنفذ 9000.وصول Jdbc
اعتمادًا على مشروعنا ، نضيف برنامج تشغيل PostrgreSQL jdbc org.postgresql: postgresql: 42.2.12 ، لهذا الاختبار ، أستخدم وحدة QuestDB الخاصة بحاويات الاختبار . الاختبار متاح على جيثب مع نص البناء:import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import static org.assertj.core.api.Assertions.*;
public class QuestDbDriverTest {
@Test
void containerIsUpTestByJdbcInvocation() throws Exception {
try (Connection connection = DriverManager.getConnection("jdbc:tc:questdb:///?user=admin&password=quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
يؤدي تشغيل عامل الإرساء إلى زيادة النفقات العامة ، ويمكن تجنب ذلك بمجرد تنفيذ org.questdb: core: jar: 4.2.0 كاعتماد على المشروع وتشغيل io.questdb.ServerMain:import io.questdb.ServerMain;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.Statement;
public class QuestDbJdbcTest {
@Test
void embeddedServerStartTest(@TempDir Path tempDir) throws Exception{
ServerMain.main(new String[]{"-d", tempDir.toString()});
try (DriverManager.getConnection("jdbc:postgresql://localhost:8812/", "admin", "quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
التضمين في تطبيق جافا
ولكن هذه هي أسرع طريقة للعمل مع قاعدة البيانات باستخدام واجهة برمجة تطبيقات java inprocess:import io.questdb.cairo.CairoEngine;
import io.questdb.cairo.DefaultCairoConfiguration;
import io.questdb.griffin.CompiledQuery;
import io.questdb.griffin.SqlCompiler;
import io.questdb.griffin.SqlExecutionContextImpl;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
public class TruncateExecuteTest {
@Test
void truncate(@TempDir Path tempDir) throws Exception{
SqlExecutionContextImpl executionContext = new SqlExecutionContextImpl();
DefaultCairoConfiguration configuration = new DefaultCairoConfiguration(tempDir.toAbsolutePath().toString());
try (CairoEngine engine = new CairoEngine(configuration)) {
try (SqlCompiler compiler = new SqlCompiler(engine)) {
CompiledQuery createTable = compiler.compile("create table tr_table(id long,name string)", executionContext);
compiler.compile("truncate table tr_table", executionContext);
}
}
}
}
وحدة تحكم الويب
يتضمن المشروع وحدة تحكم ويب للاستعلام عن QuestDB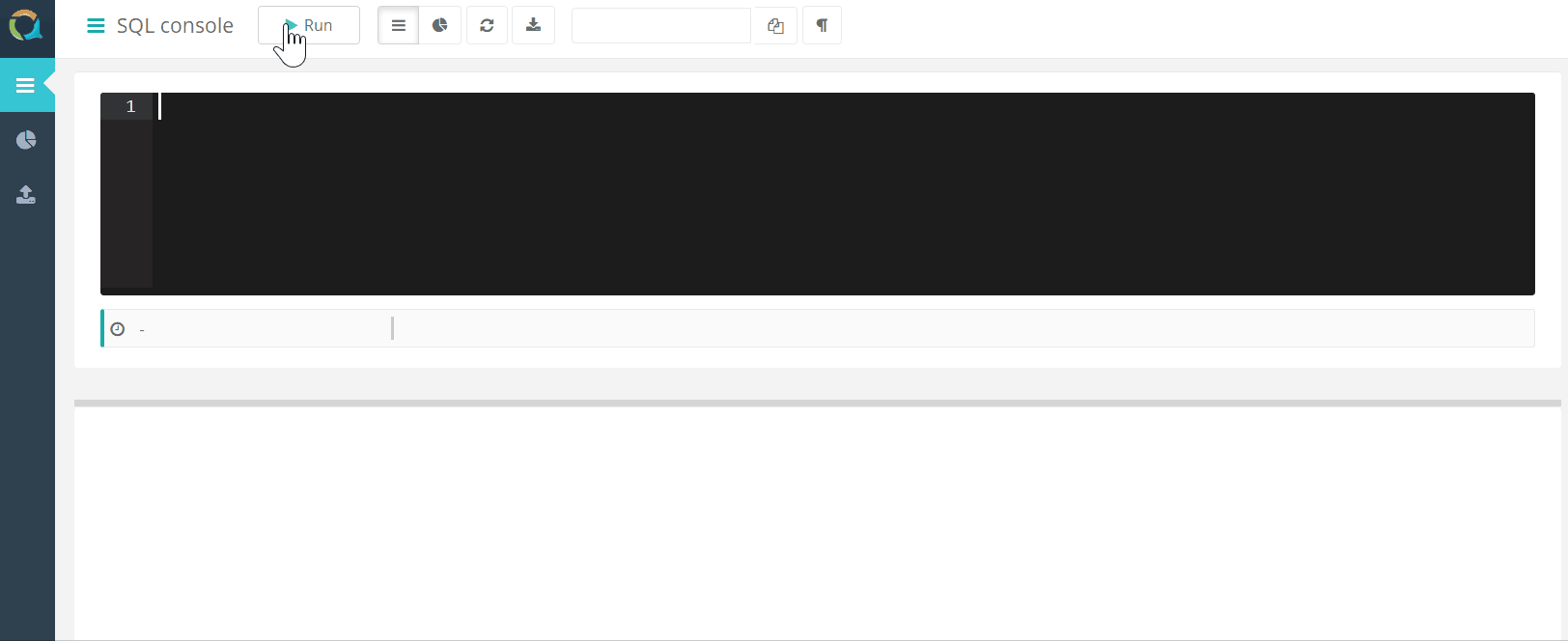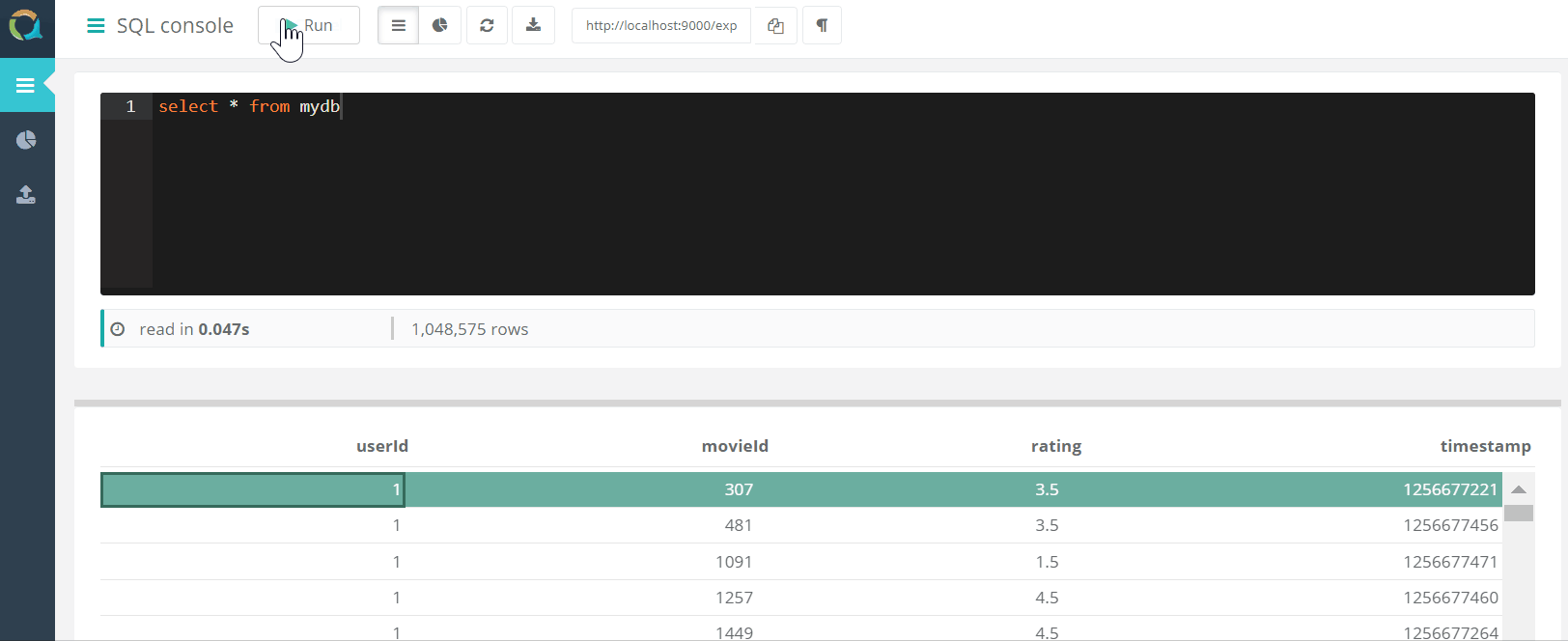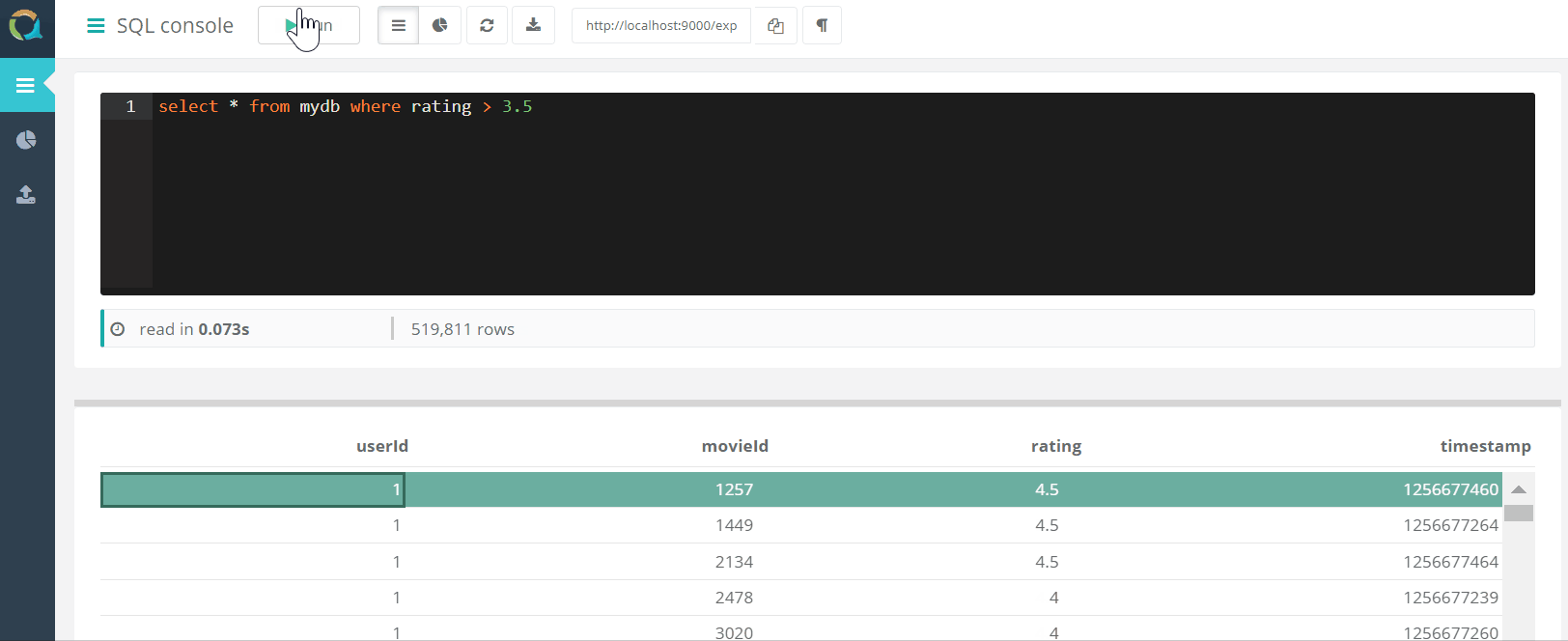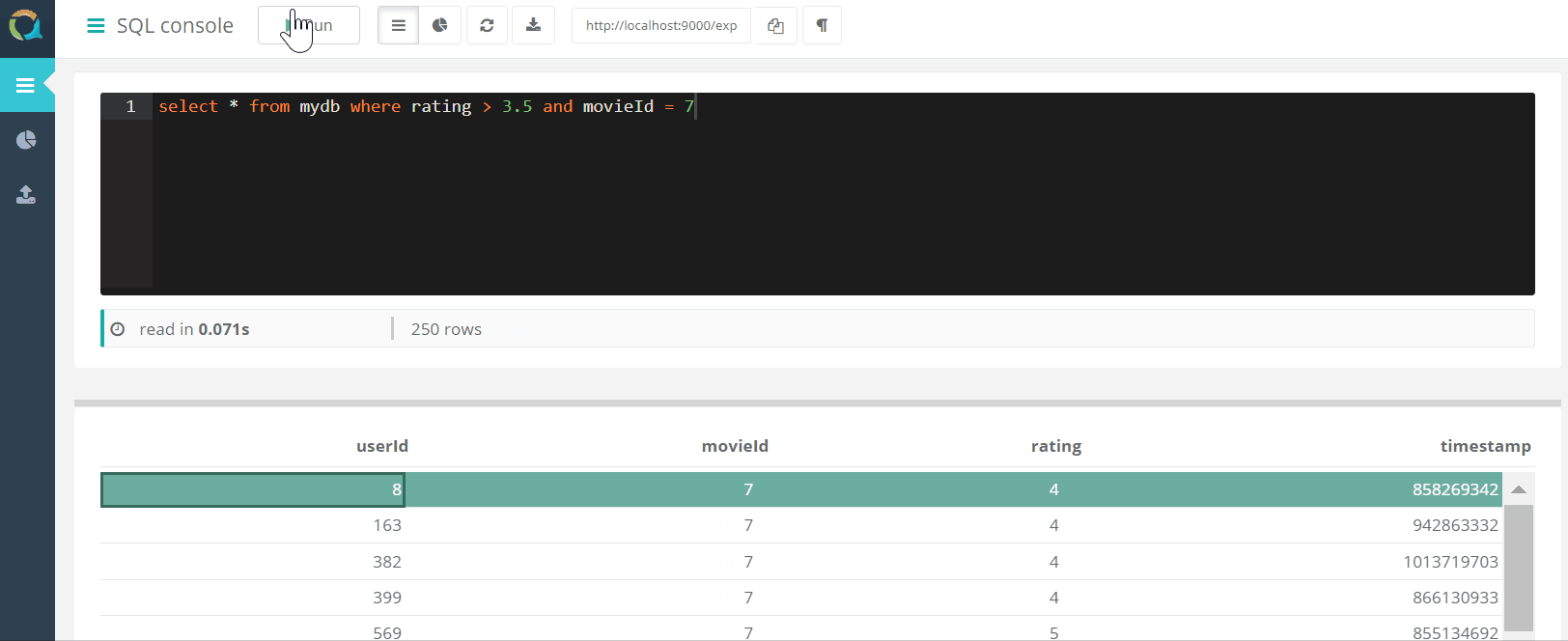 وتنزيل البيانات إلى قاعدة بيانات بتنسيق csv من خلال متصفح.
وتنزيل البيانات إلى قاعدة بيانات بتنسيق csv من خلال متصفح.
هل تحتاج إلى قاعدة بيانات أخرى؟
هذا المشروع صغير ولا يزال يفتقر إلى بعض ميزات الشركة ، ولكنه يتطور بسرعة كبيرة ويعمل العديد من المساهمين بنشاط في المشروع. لقد كنت أتابع QuestDB منذ أغسطس الماضي وطورت بعض الملحقات لهذا المشروع ( دالة jdbc و osquery ) ، ودمجت هذا المشروع أيضًا مع حاويات الاختبار. أحاول الآن حل مشاكلي الحالية في Dremio من خلال تحميل البيانات الإضافية وتقسيم البيانات والمعاملات المطولة إلى مصادر البيانات في الإنتاج باستخدام QuestDB واستكمالها بوظائف تصدير البيانات. أخطط لتبادل خبرتي في المنشورات التالية. يرشو لي بشكل خاص أنه يمكنني تصحيح وظائفي وقاعدة بياناتي على المنصة التي اعتدت عليها ، وكتابة اختبارات الوحدة التي تعمل بسرعة الضوء.أنت تقرر كمطور متمرس. مرة أخرى ، QuestDB ليس بديلاً لقواعد بيانات OLTP - PostgreSQL أو Oracle أو MS Sql Server أو DB2 أو حتى استبدال H2 للاختباراتفي JVM. هذه قاعدة بيانات قوية متخصصة مفتوحة المصدر تدعم بروتوكولات شبكة PostgreSQL و Influx / Telegraf. إذا كان سيناريو الاستخدام الخاص بك يناسب الميزات التي يتم تنفيذها فيه والسيناريو الرئيسي لاستخدام قاعدة بيانات الأعمدة ، فإن الاختيار له ما يبرره!