بمجرد أن أصبح من المثير للاهتمام الموضوعات التي سيبرزها LDA (التنسيب الكامن لـ Dirichlet) على مواد "Live Journal". كما يقولون ، هناك اهتمام - لا توجد مشكلة.بالنسبة للمبتدئين ، قليلاً عن LDA على الأصابع ، لن ندخل في التفاصيل الرياضية (أي شخص مهتم - يقرأ). لذا ، LDA - هي واحدة من الخوارزميات الأكثر شيوعًا لموضوعات النمذجة. كل مستند (سواء كان مقالًا أو كتابًا أو أي مصدر آخر للبيانات النصية) هو مزيج من المواضيع ، وكل موضوع هو مزيج من الكلمات.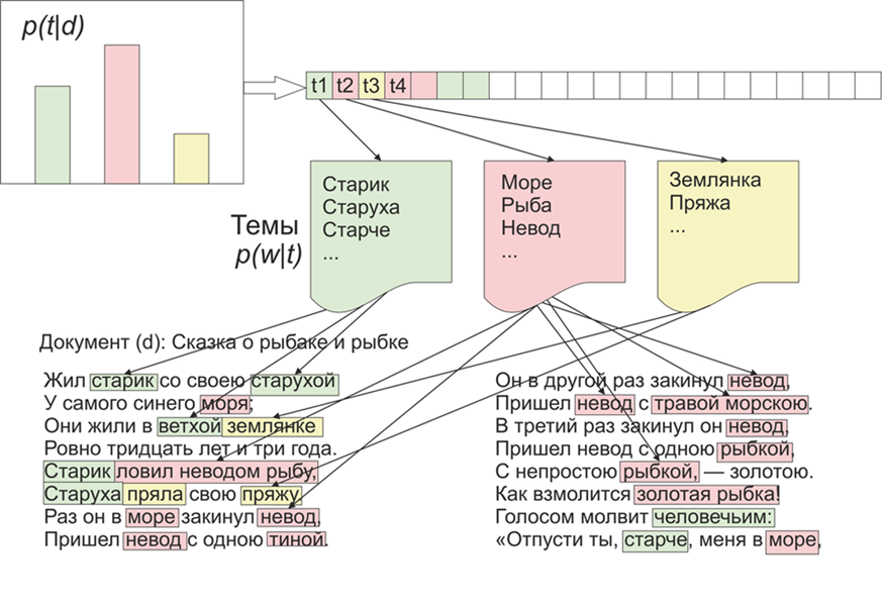 الصورة مأخوذة من ويكيبيدياوبالتالي ، فإن مهمة LDA هي العثور على مجموعات من الكلمات التي تشكل مواضيع من مجموعة من المستندات. بعد ذلك ، استنادًا إلى الموضوعات ، يمكنك تجميع النصوص أو تسليط الضوء على الكلمات الرئيسية.تم تلقي حوالي 1800 مقالة من موقع LifeJournal ، وتم تحويلها جميعًا إلى تنسيق jsonl، وسأترك المقالات غير النظيفة على قرص Yandex . سنقوم ببعض التنظيف والتطبيع للبيانات: التخلص من التعليقات ، وحذف كلمات التوقف (القائمة مع شفرة المصدر متاحة على github) ، سنقوم بإحضار جميع الكلمات إلى التهجئة الصغيرة ، وسنزيل علامات الترقيم والكلمات التي تحتوي على 3 أحرف أو أقل. لكن إحدى عمليات المعالجة الأولية الرئيسية: حذف الكلمات التي تتكرر كثيرًا ، من حيث المبدأ ، يمكن أن يقتصر على حذف الكلمات المتوقفة فقط ، ولكن بعد ذلك سيتم تضمين الكلمات المستخدمة غالبًا في جميع الموضوعات تقريبًا مع احتمال كبير. في هذه الحالة ، سيكون من الممكن ما بعد المعالجة وحذف مثل هذه الكلمات. الخيار لك.
الصورة مأخوذة من ويكيبيدياوبالتالي ، فإن مهمة LDA هي العثور على مجموعات من الكلمات التي تشكل مواضيع من مجموعة من المستندات. بعد ذلك ، استنادًا إلى الموضوعات ، يمكنك تجميع النصوص أو تسليط الضوء على الكلمات الرئيسية.تم تلقي حوالي 1800 مقالة من موقع LifeJournal ، وتم تحويلها جميعًا إلى تنسيق jsonl، وسأترك المقالات غير النظيفة على قرص Yandex . سنقوم ببعض التنظيف والتطبيع للبيانات: التخلص من التعليقات ، وحذف كلمات التوقف (القائمة مع شفرة المصدر متاحة على github) ، سنقوم بإحضار جميع الكلمات إلى التهجئة الصغيرة ، وسنزيل علامات الترقيم والكلمات التي تحتوي على 3 أحرف أو أقل. لكن إحدى عمليات المعالجة الأولية الرئيسية: حذف الكلمات التي تتكرر كثيرًا ، من حيث المبدأ ، يمكن أن يقتصر على حذف الكلمات المتوقفة فقط ، ولكن بعد ذلك سيتم تضمين الكلمات المستخدمة غالبًا في جميع الموضوعات تقريبًا مع احتمال كبير. في هذه الحالة ، سيكون من الممكن ما بعد المعالجة وحذف مثل هذه الكلمات. الخيار لك.stop=open('stop.txt')
stop_words=[]
for line in stop:
stop_words.append(line)
for i in range(0,len(stop_words)):
stop_words[i]=stop_words[i][:-1]
texts=[re.split( r' [\w\.\&\?!,_\-#)(:;*%$№"\@]* ' ,texts[i])[0].replace("\n","") for i in range(0,len(texts))]
texts=[test_re(line) for line in texts]
texts=[t.lower() for t in texts]
texts = [[word for word in document.split() if word not in stop_words] for document in texts]
texts=[[word for word in document if len(word)>=3]for document in texts]
بعد ذلك ، نحضر جميع الكلمات إلى الشكل العادي: لهذا نستخدم مكتبة pymorphy2 ، والتي يمكن تثبيتها عبر النقطة.morph = pymorphy2.MorphAnalyzer()
for i in range(0,len(texts)):
for j in range(0,len(texts[i])):
texts[i][j] = morph.parse(texts[i][j])[0].normal_form
نعم ، سنفقد معلومات حول شكل الكلمات ، ولكن في هذا السياق ، نحن مهتمون أكثر بتوافق الكلمات مع بعضها البعض. هذا هو المكان الذي تكتمل فيه المعالجة المسبقة ، فهي ليست كاملة ، ولكنها كافية لمعرفة كيفية عمل خوارزمية LDA.علاوة على ذلك ، يمكن حذف النقطة المذكورة أعلاه ، من حيث المبدأ ، ولكن في رأيي ، فإن النتائج أكثر ملاءمة ، مرة أخرى ، ما هي العتبة التي ستقررها ، على سبيل المثال ، يمكنك بناء وظيفة تعتمد على متوسط طول المستندات وعددها :counter = collections.Counter()
for t in texts:
for r in t:
counter[r]+=1
limit = len(texts)/5
too_common = [w for w in counter if counter[w] > limit]
too_common=set(too_common)
texts = [[word for word in document if word not in too_common] for document in texts]
دعنا ننتقل مباشرة إلى تدريب النموذج ، لهذا نحتاج إلى تثبيت مكتبة gensim ، التي تحتوي على مجموعة من الكعك البارد. تحتاج أولاً إلى ترميز جميع الكلمات ، وستعملها وظيفة القاموس من أجلنا ، ثم سنستبدل الكلمات بمعادلاتها العددية. النسخة التي تم التعليق عليها من مكالمة LDA أطول ، حيث يتم تحديثها بعد كل مستند ، يمكنك اللعب بالإعدادات وتحديد الخيار المناسب.texts=preposition_text_for_lda(my_r)
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10)
بعد عمل البرنامج ، يمكن عرض المواضيع باستخدام الأمرlda.show_topic(i,topn=30)
، حيث i هو رقم الموضوع ، و topn هو عدد الكلمات في الموضوع المراد عرضها.الآن مكافأة صغيرة لتصور الموضوعات ، لهذا تحتاج إلى تثبيت مكتبة wordcloud (مثل الأدوات المساعدة المماثلة موجودة أيضًا في matplotlib). يصور هذا الرمز السمات ويحفظها في المجلد الحالي.from wordcloud import WordCloud, STOPWORDS
for i in range(0,10):
a=lda.show_topic(i,topn=30)
wordcloud = WordCloud(
relative_scaling = 1.0,
stopwords = too_common
).generate_from_frequencies(dict(a))
wordcloud.to_file('society'+str(i)+'.png')
وأخيرًا ، بعض الأمثلة على الموضوعات التي تلقيتها:
 التجربة ويمكنك الحصول على نتائج أكثر فائدة.
التجربة ويمكنك الحصول على نتائج أكثر فائدة.