 يوم جيد يا اصدقاء!تشرح هذه المقالة بعض المفاهيم من نظرية الموسيقى التي تعمل عليها Web Audio API (WAA). بمعرفة هذه المفاهيم ، يمكنك اتخاذ قرارات مستنيرة عند تصميم الصوت في تطبيق. لن تجعلك هذه المقالة مهندس صوت متمرسًا ، ولكنها ستساعدك على فهم سبب عمل WAA بالطريقة التي تعمل بها.
يوم جيد يا اصدقاء!تشرح هذه المقالة بعض المفاهيم من نظرية الموسيقى التي تعمل عليها Web Audio API (WAA). بمعرفة هذه المفاهيم ، يمكنك اتخاذ قرارات مستنيرة عند تصميم الصوت في تطبيق. لن تجعلك هذه المقالة مهندس صوت متمرسًا ، ولكنها ستساعدك على فهم سبب عمل WAA بالطريقة التي تعمل بها.دارة سمعية
جوهر WAA هو إجراء بعض العمليات بالصوت داخل سياق صوتي. تم تصميم واجهة برمجة التطبيقات هذه خصيصًا للتوجيه المعياري. العمليات الأساسية مع الصوت هي العقد الصوتية ، المترابطة وتشكيل رسم تخطيطي للتوجيه (الرسم البياني للتوجيه الصوتي). تتم معالجة عدة مصادر - مع أنواع مختلفة من القنوات - في سياق واحد. يوفر هذا التصميم المعياري المرونة اللازمة لإنشاء وظائف معقدة ذات تأثيرات ديناميكية.يتم توصيل العقد الصوتية من خلال المدخلات والمخرجات ، وتشكل سلسلة تبدأ من مصدر واحد أو أكثر ، تمر عبر عقد واحد أو أكثر ، وتنتهي عند الوجهة. من حيث المبدأ ، يمكنك الاستغناء عن وجهة ، على سبيل المثال ، إذا كنا نريد فقط تصور بعض البيانات الصوتية. يبدو سير عمل صوت الويب النموذجي كالتالي:- قم بإنشاء سياق صوتي
- داخل السياق ، قم بإنشاء مصادر - مثل <audio> أو مذبذب (مولد صوت) أو دفق
- قم بإنشاء عقد تأثير مثل تردد ، مرشح biquad ، panner أو ضاغط
- حدد وجهة للصوت ، مثل مكبرات الصوت على كمبيوتر المستخدم
- إنشاء اتصال بين المصادر من خلال التأثيرات على وجهة

تعيين القناة
غالبًا ما يتم الإشارة إلى عدد القنوات الصوتية المتاحة بتنسيق رقمي ، على سبيل المثال ، 2.0 أو 5.1. وهذا ما يسمى تسمية القناة. يشير الرقم الأول إلى النطاق الكامل للترددات التي تتضمنها الإشارة. يشير الرقم الثاني إلى عدد القنوات المحجوزة لمخرجات تأثير التردد المنخفض - مضخمات الصوت .يتكون كل إدخال أو إخراج من قناة واحدة أو أكثر مبنية وفقًا لدائرة صوتية معينة. هناك العديد من تراكيب القنوات المنفصلة مثل مونو ، ستريو ، كواد ، 5.1 ، إلخ.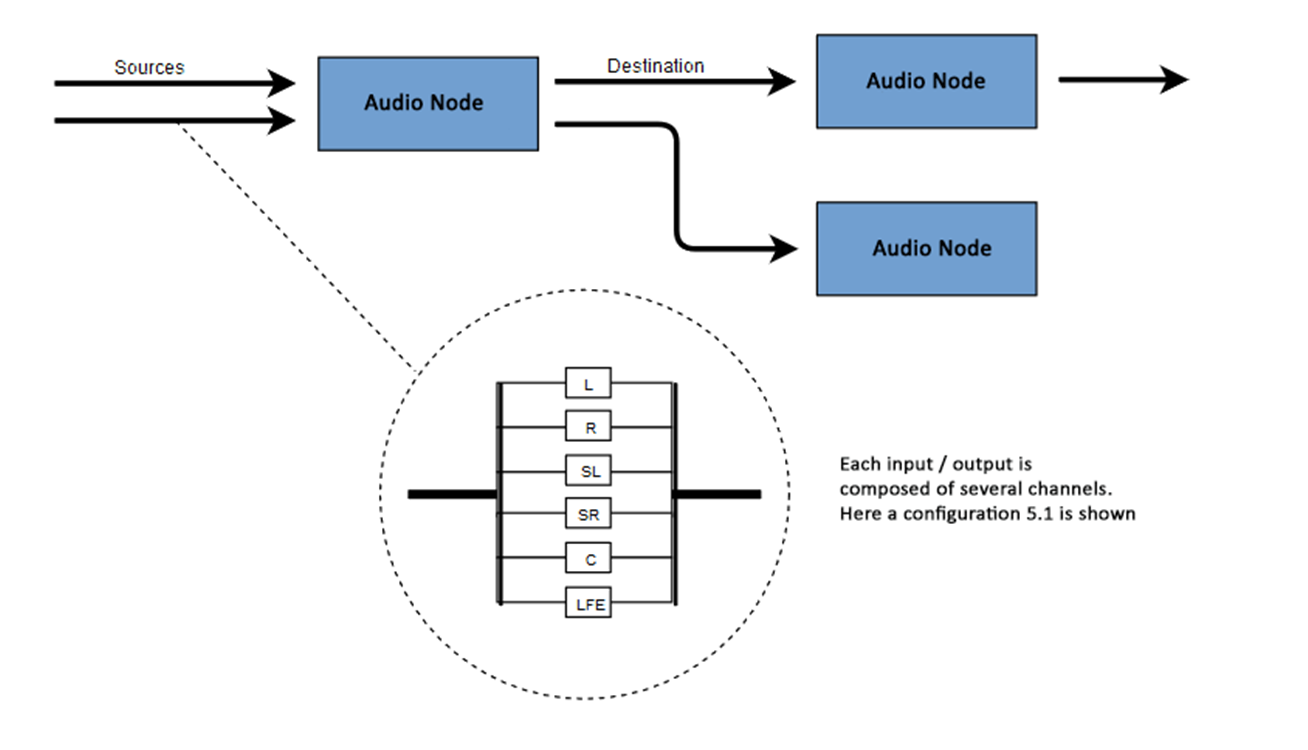 يمكن الحصول على مصادر الصوت بطرق عديدة. قد يكون الصوت:
يمكن الحصول على مصادر الصوت بطرق عديدة. قد يكون الصوت:- تم إنشاؤها بواسطة JavaScript من خلال عقدة صوتية (مثل مذبذب)
- تم إنشاؤها من البيانات الأولية باستخدام PCM (تعديل رمز النبض)
- مشتقة من عناصر وسائط HTML (مثل <video> أو <audio>)
- مشتقة من دفق وسائط WebRTC (مثل كاميرا الويب أو الميكروفون)
البيانات الصوتية: ما هو موجود في العينة
أخذ العينات يعني تحويل إشارة مستمرة إلى إشارة منفصلة (مقسمة) (تناظرية إلى رقمية). بمعنى آخر ، يتم تحويل موجة صوتية مستمرة ، مثل حفلة موسيقية حية ، إلى سلسلة من العينات ، والتي تسمح للكمبيوتر بمعالجة الصوت في كتل منفصلة.المخزن الصوتي: الإطارات والعينات والقنوات
يقبل AudioBuffer عدد القنوات كمعلمات (1 للأحادية ، 2 للاستريو ، وما إلى ذلك) ، الطول - عدد إطارات العينة داخل المخزن المؤقت ، وتردد أخذ العينات - عدد الإطارات في الثانية.العينة عبارة عن قيمة عائمة بسيطة 32 بت (float32) ، وهي قيمة دفق الصوت في نقطة زمنية معينة وفي قناة معينة (يسار أو يمين ، إلخ). إطار أو إطار عينة هو مجموعة من القيم لجميع القنوات التي تم إعادة إنتاجها في وقت معين: جميع عينات جميع القنوات التي تم استنساخها في نفس الوقت (اثنان للاستريو ، وستة لـ 5.1 ، إلخ).معدل أخذ العينات هو عدد العينات (أو الإطارات ، حيث يتم تشغيل جميع العينات في إطار في وقت واحد) ، يتم عرضها في ثانية واحدة ، مقيسة بالهرتز (هرتز). كلما زاد التردد ، كانت جودة الصوت أفضل.دعونا نلقي نظرة على المخازن المؤقتة أحادية وستيريو ، كل ثانية واحدة طويلة ، مستنسخة بتردد 44100 هرتز:- سيحتوي المخزن المؤقت الأحادي على 44100 عينة و 44100 إطارًا. قيمة الخاصية "length" هي 44100
- سيحتوي المخزن المؤقت الاستريو على 88،200 عينة ، ولكن أيضًا 44،100 إطار. قيمة الخاصية "length" هي 44100 - الطول يساوي عدد الإطارات
 عندما يبدأ تشغيل المخزن المؤقت ، نسمع أولاً الإطار الموجود في أقصى اليسار من العينة ، ثم أقرب الإطار الأيمن ، إلخ. في حالة الاستريو ، نسمع القناتين في وقت واحد. الإطارات النموذجية مستقلة عن عدد القنوات وتوفر الفرصة للمعالجة الصوتية الدقيقة للغاية.ملاحظة: للحصول على الوقت بالثواني من عدد الإطارات ، من الضروري تقسيم عدد الإطارات حسب معدل أخذ العينات. للحصول على عدد الإطارات من عدد العينات ، قسّم الأخيرة على عدد القنوات.مثال:
عندما يبدأ تشغيل المخزن المؤقت ، نسمع أولاً الإطار الموجود في أقصى اليسار من العينة ، ثم أقرب الإطار الأيمن ، إلخ. في حالة الاستريو ، نسمع القناتين في وقت واحد. الإطارات النموذجية مستقلة عن عدد القنوات وتوفر الفرصة للمعالجة الصوتية الدقيقة للغاية.ملاحظة: للحصول على الوقت بالثواني من عدد الإطارات ، من الضروري تقسيم عدد الإطارات حسب معدل أخذ العينات. للحصول على عدد الإطارات من عدد العينات ، قسّم الأخيرة على عدد القنوات.مثال:let context = new AudioContext()
let buffer = context.createBuffer(2, 22050, 44100)
ملاحظة: في الصوت الرقمي ، 44100 هرتز أو 44.1 كيلوهرتز هو تردد أخذ العينات القياسي. لكن لماذا 44.1 كيلو هرتز؟أولاً ، لأن نطاق الترددات المسموعة (الترددات التي يمكن تمييزها عن طريق الأذن البشرية) يختلف من 20 إلى 20000 هرتز. وفقًا لنظرية Kotelnikov ، يجب أن يكون تردد أخذ العينات أكثر من ضعف أعلى تردد في طيف الإشارة. لذلك ، يجب أن يكون تردد أخذ العينات أكبر من kHz 40.ثانيًا ، يجب ترشيح الإشارات باستخدام مرشح تمرير منخفض.قبل أخذ العينات ، وإلا سيكون هناك تداخل في "ذيول" طيفي (تبديل التردد ، إخفاء التردد ، التعرج) وسيتم تشويه شكل الإشارة المعاد بناؤها. من الناحية المثالية ، يجب أن يمر مرشح تمرير منخفض ترددات أقل من kHz 20 (بدون توهين) وأن يسقط ترددات أعلى من kHz 20. من الناحية العملية ، يلزم وجود بعض نطاق الانتقال (بين نطاق التمرير ونطاق الكبت) ، حيث يتم تخفيف الترددات جزئيًا. الطريقة الأسهل والأكثر اقتصادية للقيام بذلك هي استخدام عامل تصفية ضد التغيير. بالنسبة لتردد أخذ العينات البالغ 44.1 كيلوهرتز ، يكون نطاق الانتقال 2.05 كيلوهرتز.في المثال أعلاه ، نحصل على مخزن ستريو بقناتين ، يتم إعادة إنتاجهما في سياق صوتي بتردد 44100 هرتز (قياسي) ، 0.5 ثانية طويلة (22050 إطارًا / 44100 هرتز = 0.5 ثانية).let context = new AudioContext()
let buffer = context.createBuffer(1, 22050, 22050)
في هذه الحالة ، نحصل على مخزن مؤقت أحادي بقناة واحدة ، يتم إعادة إنتاجه في سياق صوتي بتردد 44100 هرتز ، وسيتفوق على 44100 هرتز (وزيادة الإطارات إلى 44100) ، وطول ثانية واحدة (44100 إطار / 44100 هرتز = 1 ثانية).ملاحظة: إعادة التشكيل الصوتي ("إعادة التشكيل") تشبه إلى حد كبير تغيير حجم الصور ("تغيير الحجم"). لنفترض أن لدينا صورة 16 × 16 ، لكننا نريد ملء هذه المنطقة بحجم 32 × 32. نقوم بتغيير الحجم. ستكون النتيجة أقل جودة (قد تكون ضبابية أو ممزقة اعتمادًا على خوارزمية الزوم) ، لكنها تعمل. الصوت المعاد تشكيله هو نفس الشيء: نحن نوفر مساحة ، ولكن من الناحية العملية من غير المحتمل أن تحقق صوتًا عالي الجودة.مخازن عازلة ومخططة
تستخدم WAA تنسيق المخزن المؤقت المستوي. تتفاعل القناتان اليمنى واليسرى على النحو التالي:LLLLLLLLLLLLLLLLRRRRRRRRRRRRRRRR ( , 16 )
في هذه الحالة ، تعمل كل قناة بشكل مستقل عن القنوات الأخرى.البديل هو استخدام تنسيق بديل:LRLRLRLRLRLRLRLRLRLRLRLRLRLRLRLR ( , 16 )
غالبًا ما يستخدم هذا التنسيق لفك تشفير MP3.تستخدم WAA التنسيق المستوي فقط ، لأنها مناسبة بشكل أفضل للمعالجة الصوتية. يتم تحويل التنسيق المستوي إلى التناوب عند إرسال البيانات إلى بطاقة الصوت للتشغيل. عند فك تشفير ملفات MP3 ، يتم تحويل المعكوس.قنوات الصوت
تحتوي المخازن المؤقتة المختلفة على عدد مختلف من القنوات: بدءًا من الأحادي البسيط (قناة واحدة) والاستريو (القنوات اليسرى واليمنى) إلى مجموعات أكثر تعقيدًا ، مثل رباعية و 5.1 مع عدد مختلف من العينات في كل قناة ، مما يوفر صوتًا أكثر ثراءً (أكثر ثراء). عادة ما يتم تمثيل القنوات بالاختصارات:الخلط الأعلى والخلط السفلي
عندما لا يتطابق عدد القنوات عند الإدخال والإخراج ، قم بتطبيق الخلط لأعلى أو لأسفل. يتم التحكم في المزج بواسطة خاصية AudioNode.channelInterpretation:التصور
يعتمد التمثيل البصري على استلام البيانات الصوتية الناتجة ، مثل البيانات حول السعة أو التردد ، ومعالجتها اللاحقة باستخدام أي تقنية رسومية. WAA لديها AnalyzerNode لا تشوه الإشارة التي تمر عبرها. في نفس الوقت ، يمكنه استخراج البيانات من الصوت ونقلها ، على سبيل المثال ، إلى & ltcanvas>.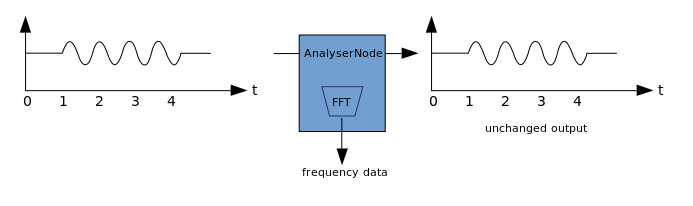 يمكن استخدام الطرق التالية لاستخراج البيانات:
يمكن استخدام الطرق التالية لاستخراج البيانات:- AnalyzerNode.getFloatByteFrequencyData () - نسخ بيانات التردد الحالية إلى Float32Array
- AnalyzerNode.getByteFrequencyData () - ينسخ بيانات التردد الحالية إلى Uint8Array (صفيف بايت غير موقع)
- AnalyserNode.getFloatTimeDomainData() — Float32Array
- AnalyserNode.getByteTimeDomainData() — Uint8Array
يتيح لك مقطع الصوت المكاني (الذي يتم معالجته بواسطة PannerNode و AudioListener) محاكاة موضع الإشارة واتجاهها عند نقطة معينة في الفضاء ، بالإضافة إلى موضع المستمع.يتم وصف موقف بانر باستخدام الإحداثيات الديكارتية اليمنى. للحركة ، يتم استخدام ناقل السرعة اللازم لإنشاء تأثير دوبلر ؛ للاتجاه ، يتم استخدام مخروط الاتجاهية. يمكن أن يكون هذا المخروط كبيرًا جدًا في حالة مصادر الصوت متعددة الاتجاهات. يتم وصف موضع المستمع على النحو التالي: الحركة - باستخدام متجه السرعة والاتجاه حيث يكون رأس المستمع - باستخدام متجهين اتجاهيين ، أمامي وأعلى. يتم الالتقاط أعلى رأس وأنف المستمع بزاوية قائمة.
يتم وصف موضع المستمع على النحو التالي: الحركة - باستخدام متجه السرعة والاتجاه حيث يكون رأس المستمع - باستخدام متجهين اتجاهيين ، أمامي وأعلى. يتم الالتقاط أعلى رأس وأنف المستمع بزاوية قائمة.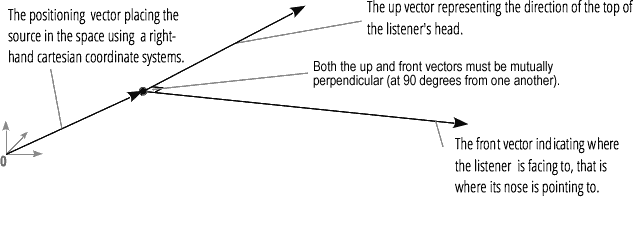
تقاطع وتفرع
يصف الاتصال العملية التي يتلقى خلالها ChannelMergerNode العديد من مصادر الإدخال الأحادية ويدمجها في إشارة خرج متعددة القنوات.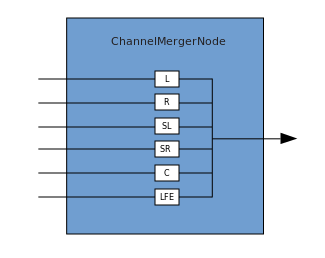 التفرع هو العملية العكسية (تنفذ من خلال ChannelSplitterNode).
التفرع هو العملية العكسية (تنفذ من خلال ChannelSplitterNode).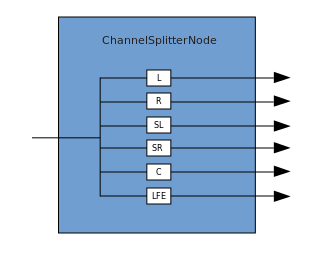 يمكن العثور على مثال للعمل مع WAA هنا . كود المصدر للمثال هنا . إليك مقالة حول كيفية عمل كل شيء.شكرآ لك على أهتمامك.
يمكن العثور على مثال للعمل مع WAA هنا . كود المصدر للمثال هنا . إليك مقالة حول كيفية عمل كل شيء.شكرآ لك على أهتمامك.