 الصورة التي تراها مأخوذة من موقع DeepMind وتعرض 57 لعبة حقق فيها أحدث عامل تطوير ( 57) ( مراجعة مقالة حبري ) نجاحًا. لم يتم أخذ الرقم 57 نفسه من السقف - تم اختيار العديد من الألعاب بالضبط في عام 2012 لتصبح نوعًا من المعايير بين مطوري الذكاء الاصطناعي لألعاب Atari ، وبعد ذلك يقيس العديد من الباحثين إنجازاتهم في مجموعة البيانات هذه.في هذا المنشور ، سأحاول إلقاء نظرة على هذه الإنجازات من زوايا مختلفة من أجل تقييم قيمتها للمهام التطبيقية ، وتبرير لماذا لا أعتقد أن هذا هو المستقبل. وحذرت من أنه سيكون هناك العديد من الصور تحت القطع.في الرابط أعلاه ، يكتب المطورون الأشياء الصحيحة قائلين ذلك
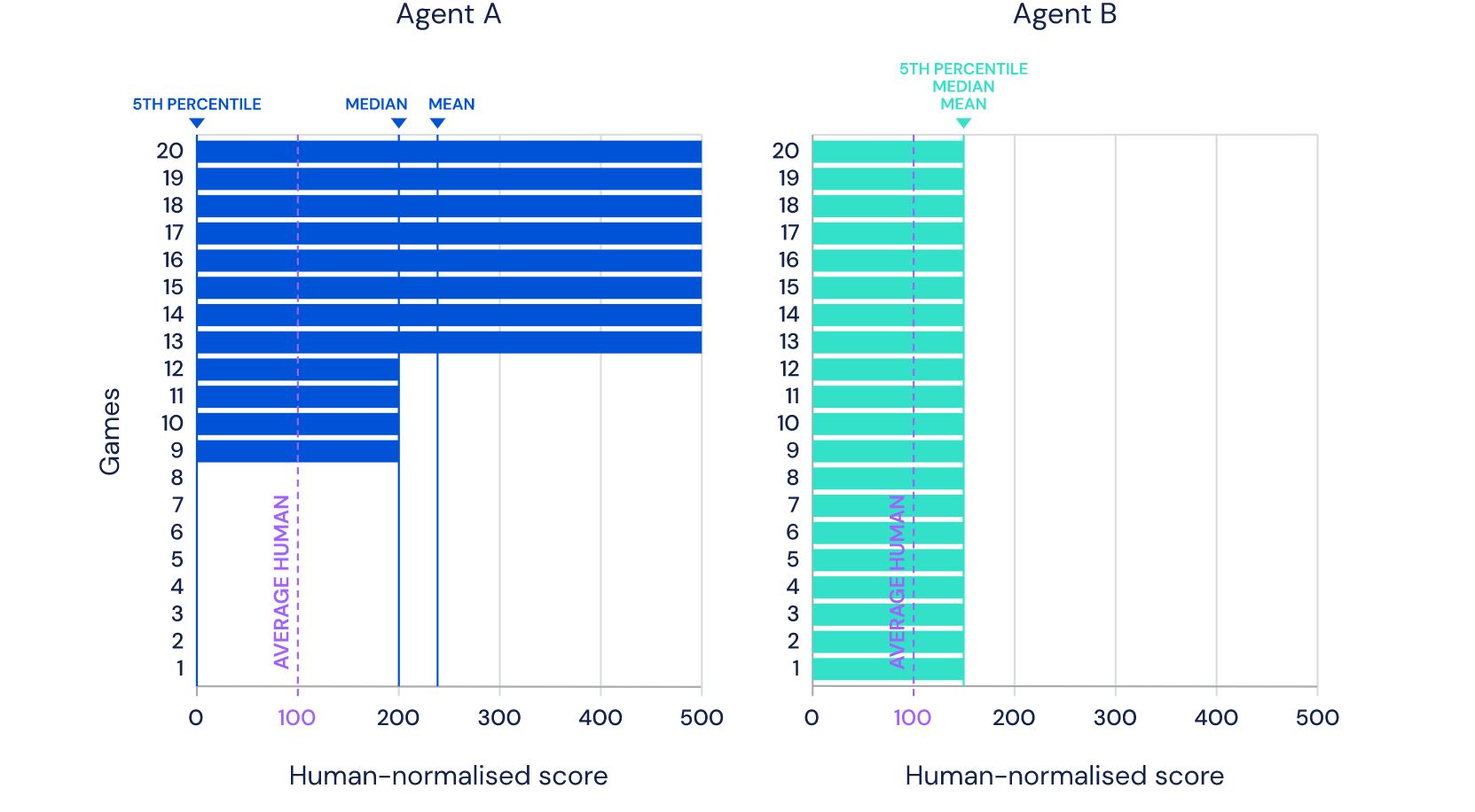
الصورة التي تراها مأخوذة من موقع DeepMind وتعرض 57 لعبة حقق فيها أحدث عامل تطوير ( 57) ( مراجعة مقالة حبري ) نجاحًا. لم يتم أخذ الرقم 57 نفسه من السقف - تم اختيار العديد من الألعاب بالضبط في عام 2012 لتصبح نوعًا من المعايير بين مطوري الذكاء الاصطناعي لألعاب Atari ، وبعد ذلك يقيس العديد من الباحثين إنجازاتهم في مجموعة البيانات هذه.في هذا المنشور ، سأحاول إلقاء نظرة على هذه الإنجازات من زوايا مختلفة من أجل تقييم قيمتها للمهام التطبيقية ، وتبرير لماذا لا أعتقد أن هذا هو المستقبل. وحذرت من أنه سيكون هناك العديد من الصور تحت القطع.في الرابط أعلاه ، يكتب المطورون الأشياء الصحيحة قائلين ذلكلذلك على الرغم من زيادة متوسط الدرجات ، حتى الآن ، فإن عدد الألعاب البشرية المذكورة أعلاه لم يرتفع. كمثال توضيحي ، ضع في اعتبارك معيارًا يتكون من عشرين مهمة. افترض أن الوكيل A حصل على درجة 500٪ في ثماني مهام ، و 200٪ في أربع مهام ، و 0٪ في ثماني مهام (المتوسط = 240٪ ، الوسيط = 200٪) ، بينما حصل الوكيل B على درجة 150٪ في جميع المهام ( يعني = متوسط = 150٪). في المتوسط ، يؤدي العامل A أداءً أفضل من العامل B. ومع ذلك ، يمتلك العامل B قدرة أكثر عمومية: فهو يحصل على أداء على المستوى البشري في مهام أكثر من العامل A.
 وهو ما يعني على الأصابع أنه قبل أن يتم قياس الجميع في ترتيب "المتوسط" ، ويلوحون بالحالات التي يصعب على الكمبيوتر استخدامها ، ولكنهم الآن تناولوها فقط. وبالتالي ، فقد حققوا تفوقًا حقيقيًا على الإنسان ، ولم يحققوا نتائج فائقة في الحالات الصديقة للكمبيوتر.لكن دعونا نلقي نظرة على المشكلة على الصعيد العالمي لفهم ما إذا كان الأمر كذلك. ما هو تفاعل DeepMind AI مع لعبة فيديوستشير العلامة النجمية فيما بعد إلى الكيانات التي تم الحصول عليها بواسطة خوارزمية تم إنشاؤها ليس بمساعدة الذكاء الاصطناعي ، ولكن بمساعدة رأي الخبراء.قبل تفكيك الدائرة ، لنلق نظرة على نهج بديل:
وهو ما يعني على الأصابع أنه قبل أن يتم قياس الجميع في ترتيب "المتوسط" ، ويلوحون بالحالات التي يصعب على الكمبيوتر استخدامها ، ولكنهم الآن تناولوها فقط. وبالتالي ، فقد حققوا تفوقًا حقيقيًا على الإنسان ، ولم يحققوا نتائج فائقة في الحالات الصديقة للكمبيوتر.لكن دعونا نلقي نظرة على المشكلة على الصعيد العالمي لفهم ما إذا كان الأمر كذلك. ما هو تفاعل DeepMind AI مع لعبة فيديوستشير العلامة النجمية فيما بعد إلى الكيانات التي تم الحصول عليها بواسطة خوارزمية تم إنشاؤها ليس بمساعدة الذكاء الاصطناعي ، ولكن بمساعدة رأي الخبراء.قبل تفكيك الدائرة ، لنلق نظرة على نهج بديل:ملخص الفيديو- + ,

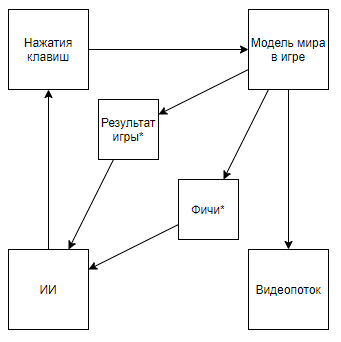 يصبح المخطط هكذا. وإذا صعدت على قناة المؤلف ، فيمكنك العثور على تطبيقه على الألعاب القديمة. بتغيير المخطط إلى هذا المخطط ، نصل إلى استنتاج مفاده أن سرعة وفعالية التدريب تتزايد بأوامر من الحجم ، ولكن في الوقت نفسه ، تصبح القيمة العلمية والهندسية لإنجازات هذه الرحلة قريبة من 0 (ونعم ، أنا لا تأخذ في الاعتبار قيمة التعميم).يمكننا أن نفترض أن النقطة الأساسية هي أن الفيديو تم طرحه من خط الأنابيب ، ولكن ضع في اعتبارك المخطط التالي (أنا متأكد من أن شخصًا ما نفذ شيئًا مشابهًا ، ولكن لا يوجد رابط في متناول اليد):والذي يتم تنفيذه عندما يكتب خبير يعرف الميزات الضرورية محلل دفق الفيديو الذي يحسب الميزات باستخدام وحدات البكسل الرئيسية.أو حتى مثل هذا المخطط:حيث يتم تدريب AI1 أولاً على استخراج الميزات التي اختارها خبير من الفيديو.ثم يتم تعليم AI2 من خلال الميزات المستخرجة من دفق الفيديو باستخدام AI1. لذلك حصلنا على مخطط:
يصبح المخطط هكذا. وإذا صعدت على قناة المؤلف ، فيمكنك العثور على تطبيقه على الألعاب القديمة. بتغيير المخطط إلى هذا المخطط ، نصل إلى استنتاج مفاده أن سرعة وفعالية التدريب تتزايد بأوامر من الحجم ، ولكن في الوقت نفسه ، تصبح القيمة العلمية والهندسية لإنجازات هذه الرحلة قريبة من 0 (ونعم ، أنا لا تأخذ في الاعتبار قيمة التعميم).يمكننا أن نفترض أن النقطة الأساسية هي أن الفيديو تم طرحه من خط الأنابيب ، ولكن ضع في اعتبارك المخطط التالي (أنا متأكد من أن شخصًا ما نفذ شيئًا مشابهًا ، ولكن لا يوجد رابط في متناول اليد):والذي يتم تنفيذه عندما يكتب خبير يعرف الميزات الضرورية محلل دفق الفيديو الذي يحسب الميزات باستخدام وحدات البكسل الرئيسية.أو حتى مثل هذا المخطط:حيث يتم تدريب AI1 أولاً على استخراج الميزات التي اختارها خبير من الفيديو.ثم يتم تعليم AI2 من خلال الميزات المستخرجة من دفق الفيديو باستخدام AI1. لذلك حصلنا على مخطط:- يستخدم دفق فيديو ، وليس لديه وصول مباشر إلى نموذج العالم.
- لا تعتمد على موزعي دفق الفيديو كتبه خبير
- سيتم تدريبه في بعض الأحيان أسهل وأكثر كفاءة من تطوير DeepMind
لكن ... نأتي إلى نفس الشيء. مثل هذا التنفيذ ، مرة أخرى ، لن يكون له قيمة علمية ولا قيمة هندسية في سياق التطبيق على الألعاب القديمة ، لأن AI1 هي مهمة بدائية طويلة الأمد للغاية وخوارزميات معالجة الصور الحديثة ، ويتم أيضًا إنشاء AI2 بسرعة شديدة وبساطة ، والتي يؤكد مؤلف الفيديو أعلاه .إذن ، ما هي قيمة خوارزميات DeepMind لألعاب Atari؟ سأحاول أن ألخص: القيمة هي ذلكخوارزميات DeepMind قادرة على العثور على استراتيجية السلوك الأمثل للألعاب ذات النموذج البدائي لعالم MM في الظروف التي يتم فيها تمثيل حالة العالم النموذج S (MM ، t) مع تشوهات كبيرة بواسطة وظيفة تشويه معينة F (S (MM، t)) ، فقط يمكن تقييم جودة القرارات المتخذة دالة تتلقى تسلسل قيم F (S (MM، t)) وتفاعلات الخوارزمية ، وهذا التسلسل غير معروف الطول (يمكن أن تنتهي اللعبة بعدد مختلف من الخطوات) ، ولكن يمكنك تكرار التجربة لعدد لا نهائي من المرات .توقع القضايا, . S(MM, t) , , . F(S(MM, t)) , .
الآن دعنا نحاول تقييم قابلية تطبيق مثل هذه القيمة لحل مشكلات العالم الحقيقي التي ترتبط بطريقة ما بالأدوات ، أي أنها تمثل حالة حقيقية مع تشوهات كبيرة ، مما يعني أن البيئة تستجيب لأفعال الوكيل ، وتعطي تقييمًا فقط بعد سلسلة طويلة من القرارات ، و ومع ذلك ، فإنها تسمح بتنفيذ التجربة عدة مرات.للوهلة الأولى ، يبدو أن التطبيق المثير للاهتمام هو لعبة في البورصة. حتى تلميحات Google ، بخيانتها على أنها التلميح الوحيد باستخدام العالم الحقيقي ، تشير إلى أن الموضوع ساخن.سأشير على الفور إلى نقطة مهمة - يمكن تقريبًا تقريبًا تقريبًا جميع الطرق لتحليل السوق (دون احتساب الأساليب التي تحلل الأشياء الواقعية ، مثل وقوف السيارات أمام محلات السوبر ماركت والأخبار وإشارات الأسهم على Twitter) إلى نوعين. النوع الأول هو نهج تمثل السوق كسلسلة زمنية. الثانية ، كتيار من التطبيقات.بطريقة ما يرى أنصار النهج الأول النوع في السوق لكن الفرق الأساسي ليس في البيانات المستخدمة ، ولكن في الحقيقة ، كقاعدة ، فإن أولئك الذين يحللون السوق ، كسلسلة زمنية ، يهملون تأثيرهم على السوق ، معتقدين أنه ، على فترات يومية ، لن تؤثر معاملاتهم على الديناميكيات الإضافية للسوق. في حين أن مؤيدي النهج الثاني يمكن أن يهملوا ، معتقدين أن حجمهم غير ذي أهمية فيما يتعلق بسيولة السوق ، ويعتبرون السوق بمثابة نظام تغذية مرتدة ، معتقدين أن أفعالهم تؤثر على سلوك اللاعبين الآخرين (على سبيل المثال ، البحث والمناهج المتعلقة بالتنفيذ الأمثل للطلبات الكبيرة ، صنع السوق ، التداول عالي التردد).بعد استعراض نتائج البحث ، من الواضح أن جميع المقالات والمشاركات المخصصة للتداول باستخدام التدريب التعزيزي (الموضوع الأقرب إلى نجاحات DeepMind) مخصصة للنهج الأول. لكن يُطرح سؤال معقول حول تناسب التناسب مع المشكلة.أولاً ، لنرسم مخططًا مشابهًا لألعاب Atari.الواقع الموضوعي, . , , , , — . , , . , , , , , . , .
يبدو أن كل شيء يقع بشكل جميل. وأظن أن هذا التشابه يسخن الضجيج أيضًا. لكن ماذا لو أوضحنا المخطط قليلاً: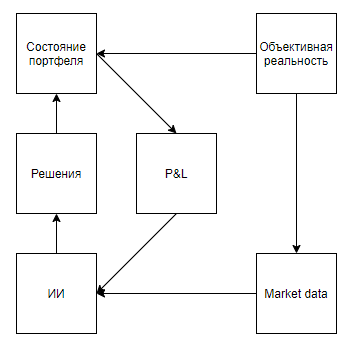
توقع مسألة العينات المولدة ذاتيا, , , . , , . , , . , , , , , .
النهج الثاني (مع تدفق من التطبيقات) يبدو أكثر واعدة. ما يسمى الزجاجغالبًا ما تكون مليئة بتطبيقات الروبوتات التي تبحث عن أجزاء من النسبة المئوية من السعر ، وتتنافس في مكان في قائمة الانتظار ، وغالبًا ما تنشئ تطبيقات فقط لإظهار الطلب أو العرض ، وتثير روبوتات أخرى لإجراءات غير مؤاتية. يبدو ، إذا كنت تحلم ، أنه إذا قمت بإنشاء محاكي للتبادل وقمت بوضع روبوتات HFT فيه ، والتي ، مع اتخاذ مليارات القرارات ، ستتعلم ذاتيًا ، وتلعب مع استنساخها ، وبالتالي تطور استراتيجية مثالية تأخذ في الاعتبار جميع الاستراتيجيات المضادة المثلى ... من المؤسف أنه في حالة حدوث شيء من هذا القبيل ، فإن حوالي 5 أشخاص حول العالم سيكتشفون ذلك - مبادئ العمل للمتداولين ذوي التردد العالي توحي بالسرية المطلقة ، ورفض نشر حتى نتائج غير ناجحة لترك الأعداء فرصة للمضي قدمًا.أعتقد أنه لا يستحق التركيز بشكل خاص على استحالة تطبيق مثل هذه الأساليب في التسويق والموارد البشرية والمبيعات والإدارة وغيرها من المجالات التي يكون فيها الكائن شخصًا ، لأنه من أجل التطبيق الصحيح ، من الضروري تمكين الذكاء الاصطناعي من إجراء الملايين ، أو حتى مليارات التجارب. وحتى إذا كان لدى العديد من الشركات مليون تفاعل مع كائن حيث يمكن للذكاء الاصطناعي اتخاذ قرار (اختيار لافتة لإظهارها للعميل المحتمل بناءً على ملفه الشخصي ، وقرار فصل موظف) ، فلن يحصل أي شخص على مليون تجربة بنفس الشيء الكائن ، وهو بالضبط ما هو مطلوب للتطبيق عالي الجودة. ولكن ما يستحق التركيز عليه هو مكافحة الاحتيال والأمن السيبراني.لا أعلم ، لحسن الحظ أو لسوء الحظ ، ولكن في العالم الحديث ، تستند العديد من العلاقات الاقتصادية على توفير قيمة صغيرة دون التزامات مقابل توقع قيمة كبيرة في المستقبل - مما يؤدي إلى العديد من مصادر الهدية المجانية واحتمال الاحتيال.أمثلة:- أول رحلة مجانية في مجمعات سيارات الأجرة
- دفعات 70 دولارًا لتكلفة الاكتساب في المقامرة للاعب الذي جلب 5 دولارات
- اختبار 300 دولار من مزودي الخدمات السحابية والفترات التجريبية
علاوة على ذلك ، فإن الاحتيال في النظام الاقتصادي الحديث مدعوم بدرجة منخفضة من الحماية لمعاملات بطاقات الائتمان ، لأن التجار غالبًا ما يرفضون عن قصد نفس 3D الآمن لتبسيط تجربة المستخدم. وبالتالي ، بالنسبة لمشتري البطاقات المسروقة مقابل نسبة صغيرة من رصيدهم ، يمكن استكمال هذه القائمة إلى أجل غير مسمى تقريبًا.تكمن المشكلة الرئيسية في مكافحة مثل هذه الحالات في عدم القدرة على تجميع مجموعة بيانات ذات حجم كافٍ -٪ من عمليات الاحتيال أقل من 1-6 أوامر من النسبة المئوية للعمليات الجيدة اعتمادًا على الأعمال. هناك أيضًا مشكلة في مرونة المبتدئين ، والتي تتجاوز بسهولة الخوارزميات الثابتة ، والتكيف مع أنظمة مكافحة الاحتيال التي تم تدريبها على الخبرة السابقة.ويبدو أن الأمر هنا. ستسمح لك الخوارزميات مثل Agent57 التي تم إطلاقها في وضع الحماية بإنشاء المحتال المثالي ، وتحديث مهاراته باستمرار ، وفي نفس الوقت حل المشكلة العكسية - حافظ على الخوارزمية لتحديدها محدثة. ولكن هناك تحذير واحد. الفوز ضد نموذج العالم المضمن في ألعاب Atari ليس على الإطلاق هو الفوز من نظام مكافحة الاحتيال المدرب بالفعل على أساس سلوك الملايين من اللاعبين ، والكثير من الإجراءات مع الاحتيال لا تتناسب مع العديد من الإجراءات للاعب في لعبة قديمة. على سبيل المثال ، حتى إجراء بسيط مثل إدخال تسجيل الدخول في نموذج التسجيل يحمل بالفعل مليارات الخيارات للقيام بذلك. بدءًا من وكيل المستخدم الذي سيتم نقله إلى الخادم ، وانتهاءً بعدد الميلي ثانية التي تنتظر بين إدخال حرفَي تسجيل الدخول الثاني والثالث ...بشكل عام ، أرى كل شيء بطريقة أو بأخرى. قاتمة جدا. وآمل حقًا أن أكون مخطئًا ، وفي مكان ما لم آخذ شيئًا في الاعتبار في النموذج. سأكون ممتنا إذا رأيت أمثلة مضادة في التعليقات.