مرحبًا عزيزي خابروفيت ، في هذا المثال الصغير ، أريد أن أوضح كيف يمكنك تحليل صفحة ، يتم تحميل البيانات باستخدام أدوات جافا سكريبت. علاوة على ذلك ، حتى إذا كان من السهل حفظ الصفحة في هذا المثال ، فلا يزال بإمكانك تحليل جميع الصور اللازمة منها بسبب هذه الأدوات. في هذه الحالة، وأنا استخدم الموقع cian.ru باعتبارها سبيل المثال ، والتي لديها قناعاتها المعهد ، والتي لن تستخدم، بدلا من ذلك وسوف تستخدم السيلينيوم. أنا لا أعمل في cian.ru ، أنا فقط استخدم هذا الموقع كمثال. الكود الموجود في المحلل اللغوي بسيط ومصمم للمبتدئين.
مقدمة قصيرة - عندما نظرت في وقت فراغي في أمثلة للإصلاحات على cian.ru ، اعتقدت أنه سيكون من الجيد حفظ الصور التي أحببتها ، ولكن حفظها يدويًا سيكون وقتًا طويلاً ، إلى جانب هذه ليست طريقتنا ، لذلك قررت كتابة هذا محلل.
كتب محلل في python3 من توزيع اناكوندا ، السيلينيوم و chromedriver ثنائي I تثبيتها بشكل منفصل من هذه الروابط. (وبالطبع يجب تثبيت متصفح Google Chrome على النظام )
أدناه هو رمز المحلل الكامل ، ثم سأقوم بتحليل النقاط الرئيسية بشكل منفصل.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
import chromedriver_binary
import urllib
import time
print('start...')
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
i = 0
while True:
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
i += 1
print(i, url)
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
time.sleep(2)
print('done.')
https://www.cian.ru/sale/flat/222059642/ . driver get. , Headless Chrome, .. webdriver.Chrome() --headless, , , chrome_options , .
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
, , , .. "next".
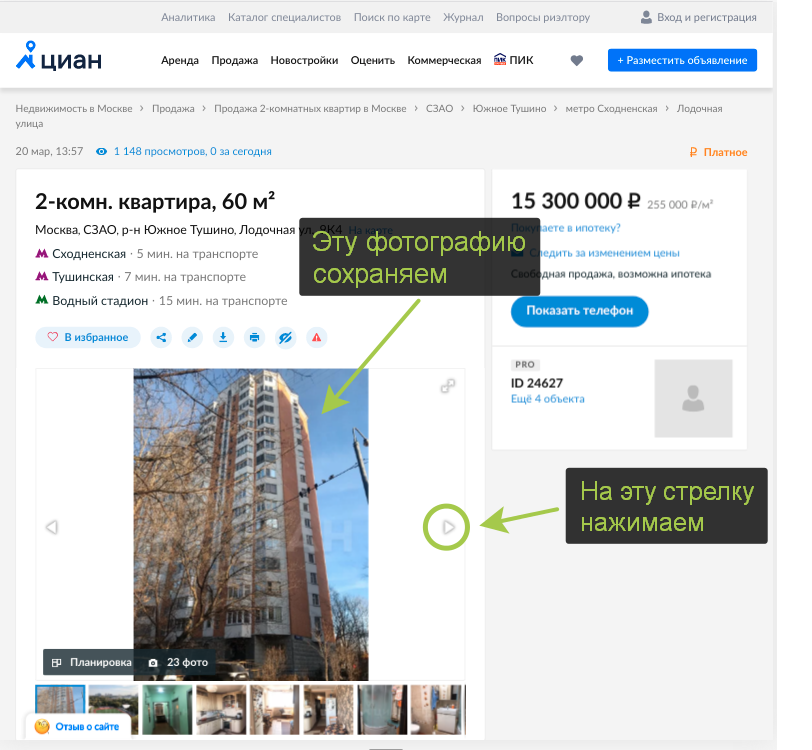
url , try/except NoSuchElementException, , Selenium .
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
.
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
urllib.
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
, . ( Selenium)
time.sleep(2)
Selenium, , , - .
.