مرحبا ، هابروجيتلي! أثناء طباعة أخبارنا في دار الطباعة ، والمكتب في مكان بعيد ، قررنا مشاركة مقتطف من كتاب Paul and Harvey Daytel "Python: Intelligence: Intelligence، Big Data and Cloud Computing"دراسة حالة: التعلم الآلي بدون معلم ، الجزء 2 - متوسط التكتل K
في هذا القسم ، ربما يتم تقديم أبسط خوارزميات التعلم الآلي بدون معلم - التجميع باستخدام طريقة k المتوسطة. تحلل الخوارزمية العينات غير المصنفة وتحاول دمجها في مجموعات. دعونا نوضح أن k في "k يعني طريقة" يمثل عدد المجموعات التي من المفترض أن يتم تقسيم البيانات.توزع الخوارزمية العينات على عدد محدد سلفًا من العناقيد باستخدام مقاييس المسافة المشابهة لتلك الموجودة في خوارزمية التجميع لأقرب جيران. يتم تجميع كل عنقود حول محور مركزي - النقطة المركزية للكتلة. في البداية ، تقوم الخوارزمية باختيار k centroids عشوائية من بين عينات مجموعة البيانات ، وبعد ذلك يتم توزيع العينات المتبقية بين العناقيد ذات أقرب centroid. بعد ذلك ، يتم إجراء إعادة حساب تكرارية للنقرات المركزية ، ويتم إعادة توزيع العينات بين العناقيد ، حتى يتم تقليل المسافة من النقط المئوية المعينة إلى العينات المدرجة في مجموعتها إلى أدنى حد. نتيجة للخوارزمية ، يتم إنشاء مجموعة من التسميات أحادية البعد التي تحدد المجموعة التي تنتمي إليها كل عينة ، بالإضافة إلى صفيف ثنائي الأبعاد من النقط المركزية التي تمثل مركز كل عنقود.مجموعة بيانات إيريس
سنعمل مع مجموعة بيانات Iris الشهيرة والمضمنة في scikit-learn. غالبًا ما يتم تحليل هذه المجموعة أثناء التصنيف والتجميع. على الرغم من تسمية مجموعة البيانات ، لن نستخدم هذه التسميات لتوضيح التجميع. سيتم استخدام الملصقات لتحديد مدى جودة مجموعات الخوارزمية المتوسطة للعينات.مجموعة بيانات Iris هي مجموعة بيانات لعبة لأنها تتكون من 150 عينة فقط وأربع سمات. تصف مجموعة البيانات 50 عينة من ثلاثة أنواع من زهور القزحية - Iris setosa و Iris versicolor و Iris virginica (انظر الصور أدناه). خصائص العينات: طول فص الفصوص الخارجي (طول السيبال) ، عرض فص الفصوص الخارجي (عرض السيبال) ، طول فص الفصيص الداخلي (طول البتلة) وعرض فص الفصص الداخلي (عرض البتلة) ، مقاسة بالسنتيمترات.14.7.1. تنزيل مجموعة بيانات Iris
ابدأ تشغيل IPython باستخدام الأمر ipython --matplotlib ، ثم استخدم وظيفة load_iris في وحدة sklearn.datasets النمطية للحصول على كائن Bunch مع مجموعة البيانات:In [1]: from sklearn.datasets import load_iris
In [2]: iris = load_iris()
تشير سمة DESCR الخاصة بكائن المجموعة إلى أن مجموعة البيانات تتكون من 150 عددًا من الأمثلة ، يحتوي كل منها على أربعة عدد من السمات. لا توجد قيم مفقودة في مجموعة البيانات. يتم تصنيف العينات حسب الأعداد الصحيحة 0 و 1 و 2 ، والتي تمثل Iris setosa و Iris versicolor و Iris virginica ، على التوالي. نتجاهل التسميات ونعهد بتحديد فئات العينات إلى خوارزمية التجميع باستخدام طريقة الوسائل k. معلومات DESCR الرئيسية بالخط العريض:In [3]: print(iris.DESCR)
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
...
التحقق من عدد العينات والميزات والقيم المستهدفة
يمكن العثور على عدد الأنماط والسمات في سمة الشكل لصفيف البيانات ، ويمكن العثور على عدد القيم الهدف في سمة الشكل للصفيف الهدف:In [4]: iris.data.shape
Out[4]: (150, 4)
In [5]: iris.target.shape
Out[5]: (150,)
يحتوي الصفيف target_names على أسماء التسميات الرقمية للصفيف. هدف التعبير - dtype = '<U10' يعني أن عناصره عبارة عن سلاسل بطول 10 أحرف كحد أقصى:In [6]: iris.target_names
Out[6]: array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
يحتوي الصفيف feature_names على قائمة بأسماء السلاسل لكل عمود في صفيف البيانات:In [7]: iris.feature_names
Out[7]:
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
14.7.2. أبحاث Iris Dataset: إحصائيات وصفية في Pandas
نستخدم مجموعة DataFrame لفحص مجموعة بيانات Iris. كما هو الحال مع مجموعة بيانات California Housing ، قمنا بتعيين معلمات pandas لتنسيق إخراج العمود:In [8]: import pandas as pd
In [9]: pd.set_option('max_columns', 5)
In [10]: pd.set_option('display.width', None)
قم بإنشاء مجموعة DataFrame بمحتويات مصفوفة البيانات ، باستخدام محتويات مصفوفة feature_names كأسماء أعمدة:In [11]: iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
ثم أضف عمودًا باسم العرض لكل عينة من العينات. يستخدم تحويل القائمة في المقتطف التالي كل قيمة في الصفيف الهدف للبحث عن الاسم المقابل في صفيف target_names:In [12]: iris_df['species'] = [iris.target_names[i] for i in iris.target]
سنستخدم الباندا لتحديد عينات عديدة. كما كان من قبل ، إذا خرج pandas \ إلى يمين اسم العمود ، فهذا يعني أن الأعمدة التي سيتم عرضها أدناه تظل في الإخراج:In [13]: iris_df.head()
Out[13]:
sepal length (cm) sepal width (cm) petal length (cm) \
0 5.1 3.5 1.4
1 4.9 3.0 1.4
2 4.7 3.2 1.3
3 4.6 3.1 1.5
4 5.0 3.6 1.4
petal width (cm) species
0 0.2 setosa
1 0.2 setosa
2 0.2 setosa
3 0.2 setosa
4 0.2 setosa
نحسب بعض مؤشرات الإحصاء الوصفي للأعمدة الرقمية:In [14]: pd.set_option('precision', 2)
In [15]: iris_df.describe()
Out[15]:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
count 150.00 150.00 150.00 150.00
mean 5.84 3.06 3.76 1.20
std 0.83 0.44 1.77 0.76
min 4.30 2.00 1.00 0.10
25% 5.10 2.80 1.60 0.30
50% 5.80 3.00 4.35 1.30
75% 6.40 3.30 5.10 1.80
max 7.90 4.40 6.90 2.50
إن استدعاء طريقة الوصف في عمود "الأنواع" يؤكد أنه يحتوي على ثلاث قيم فريدة. نحن نعلم مقدمًا أن البيانات تتكون من ثلاث فئات ، تنتمي إليها العينات ، على الرغم من أن التعلم الآلي بدون معلم ليس هذا هو الحال دائمًا.In [16]: iris_df['species'].describe()
Out[16]:
count 150
unique 3
top setosa
freq 50
Name: species, dtype: object
14.7.3. تصور مجموعة البيانات Pairplot
سنقوم بتصور الخصائص في مجموعة البيانات هذه. تتمثل إحدى طرق استخراج المعلومات حول بياناتك في معرفة كيفية ارتباط السمات ببعضها البعض. تحتوي مجموعة البيانات على أربع سمات. لن نتمكن من بناء رسم تخطيطي لمطابقة سمة واحدة مع ثلاث أخرى في مخطط واحد. ومع ذلك ، من الممكن إنشاء رسم تخطيطي يتم فيه تقديم المراسلات بين الخاصيتين. يستخدم الجزء [20] وظيفة pairplot في مكتبة Seaborn لإنشاء جدول من المخططات التي يتم فيها تعيين كل ميزة لأحد الميزات الأخرى:In [17]: import seaborn as sns
In [18]: sns.set(font_scale=1.1)
In [19]: sns.set_style('whitegrid')
In [20]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4],
...: hue='species')
...:
الحجج الرئيسية:- مجموعة DataFrame مع مجموعة بيانات مرسومة على مخطط ؛
- vars - تسلسل بأسماء المتغيرات المرسومة على الرسم البياني. بالنسبة لمجموعة DataFrame ، تحتوي على أسماء الأعمدة. في هذه الحالة ، يتم استخدام الأعمدة الأربعة الأولى من DataFrame ، والتي تمثل طول (عرض) الإزاحة الخارجية وطول (عرض) الإزاحة الداخلية ، على التوالي ؛
- الصبغة هي عمود من مجموعة DataFrame يستخدم لتحديد ألوان البيانات المرسومة على الرسم البياني. في هذه الحالة ، يتم تلوين البيانات اعتمادًا على نوع القزحية.
تقوم المكالمة الزوجية السابقة ببناء جدول الرسم البياني 4 × 4 التالي: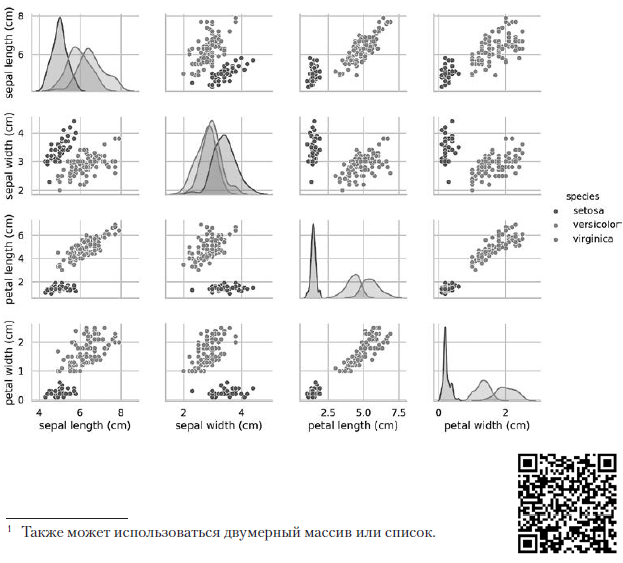 توضح المخططات على القطر المؤدي من أعلى اليسار إلى الزاوية اليمنى السفلية توزيع السمة المعروضة في هذا العمود مع مجموعة من القيم (من اليسار إلى اليمين) وعدد العينات التي تحتوي على هذه القيم (من أعلى إلى أسفل) . خذ توزيع طول المحيط الخارجي:
توضح المخططات على القطر المؤدي من أعلى اليسار إلى الزاوية اليمنى السفلية توزيع السمة المعروضة في هذا العمود مع مجموعة من القيم (من اليسار إلى اليمين) وعدد العينات التي تحتوي على هذه القيم (من أعلى إلى أسفل) . خذ توزيع طول المحيط الخارجي: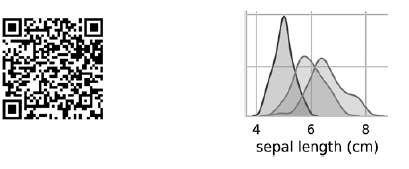 تشير أعلى منطقة مظللة إلى أن نطاق طول الفص المحيط الخارجي (على طول المحور x) للأنواع Iris setosa هو حوالي 4-6 سم ، وبالنسبة لمعظم عينات القزحية ، تقع القيم في منتصف هذا النطاق (حوالي 5 سم). تشير المنطقة المظللة أقصى اليمين إلى أن نطاق طول الفص المحيط الخارجي (على طول المحور x) للأنواع القزحية البكر العذراء هو حوالي 4-8.5 سم ، وبالنسبة لمعظم عينات قزحية فرجينيا ، تتراوح القيم بين 6 و 7 سم.في الرسوم البيانية الأخرى ، يعرض العمود مخططات البيانات المبعثرة للخصائص الأخرى المتعلقة بالخاصية على طول المحور س. في العمود الأول ، في المخططات الثلاثة الأولى ، يُظهر المحور y عرض النصاب الخارجي ، وطول النصاب الداخلي ، وعرض النصاب الداخلي على التوالي ، ويُظهر المحور x طول النصاب الخارجي.عند تنفيذ هذا الرمز ، تظهر صورة ملونة على الشاشة ، تظهر العلاقة بين أنواع مختلفة من القزحيات على مستوى الأحرف الفردية. من المثير للاهتمام ، في جميع الرسوم البيانية ، يتم فصل النقاط الزرقاء لـ Iris setosa بوضوح عن النقاط البرتقالية والخضراء للأنواع الأخرى ؛ هذا يشير إلى أن Iris setosa هي بالفعل فئة منفصلة. يمكنك أيضًا ملاحظة أنه يمكن الخلط بين النوعين الآخرين في بعض الأحيان ، كما يتضح من النقاط البرتقالية والخضراء المتداخلة. على سبيل المثال ، يوضح الرسم البياني الخاص بعرض وطول الفص المحيط الخارجي أن نقاط القزحية المبرقشة ومزيج القزحية البكر. هذا يشير إلى أنه في حالة توفر القياسات فقط للفص المحيط الخارجي ، فسيكون من الصعب التمييز بين هذين النوعين.
تشير أعلى منطقة مظللة إلى أن نطاق طول الفص المحيط الخارجي (على طول المحور x) للأنواع Iris setosa هو حوالي 4-6 سم ، وبالنسبة لمعظم عينات القزحية ، تقع القيم في منتصف هذا النطاق (حوالي 5 سم). تشير المنطقة المظللة أقصى اليمين إلى أن نطاق طول الفص المحيط الخارجي (على طول المحور x) للأنواع القزحية البكر العذراء هو حوالي 4-8.5 سم ، وبالنسبة لمعظم عينات قزحية فرجينيا ، تتراوح القيم بين 6 و 7 سم.في الرسوم البيانية الأخرى ، يعرض العمود مخططات البيانات المبعثرة للخصائص الأخرى المتعلقة بالخاصية على طول المحور س. في العمود الأول ، في المخططات الثلاثة الأولى ، يُظهر المحور y عرض النصاب الخارجي ، وطول النصاب الداخلي ، وعرض النصاب الداخلي على التوالي ، ويُظهر المحور x طول النصاب الخارجي.عند تنفيذ هذا الرمز ، تظهر صورة ملونة على الشاشة ، تظهر العلاقة بين أنواع مختلفة من القزحيات على مستوى الأحرف الفردية. من المثير للاهتمام ، في جميع الرسوم البيانية ، يتم فصل النقاط الزرقاء لـ Iris setosa بوضوح عن النقاط البرتقالية والخضراء للأنواع الأخرى ؛ هذا يشير إلى أن Iris setosa هي بالفعل فئة منفصلة. يمكنك أيضًا ملاحظة أنه يمكن الخلط بين النوعين الآخرين في بعض الأحيان ، كما يتضح من النقاط البرتقالية والخضراء المتداخلة. على سبيل المثال ، يوضح الرسم البياني الخاص بعرض وطول الفص المحيط الخارجي أن نقاط القزحية المبرقشة ومزيج القزحية البكر. هذا يشير إلى أنه في حالة توفر القياسات فقط للفص المحيط الخارجي ، فسيكون من الصعب التمييز بين هذين النوعين.ينتج عن زوج الإخراج الناتج لون واحد
إذا قمت بإزالة وسيطة hue key ، فإن وظيفة pairplot تستخدم لونًا واحدًا فقط لإخراج جميع البيانات ، لأنها لا تعرف كيفية التمييز بين طرق العرض في الإخراج:In [21]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4])
كما يتبين من الرسم البياني التالي ، في هذه الحالة ، فإن المخططات على القطر هي رسوم بيانية مع توزيعات جميع قيم هذه السمة ، بغض النظر عن النوع. عند دراسة الرسوم البيانية ، قد يبدو أن هناك مجموعتان فقط ، على الرغم من أننا نعلم أن مجموعة البيانات تحتوي على ثلاثة أنواع. إذا لم يكن عدد المجموعات معروفًا مسبقًا ، فيمكنك الاتصال بخبير في مجال الموضوع يكون على دراية جيدة بالبيانات. قد يعرف الخبير أن هناك ثلاثة أنواع من البيانات في مجموعة البيانات ؛ يمكن أن تكون هذه المعلومات مفيدة عند إجراء التعلم الآلي باستخدام البيانات.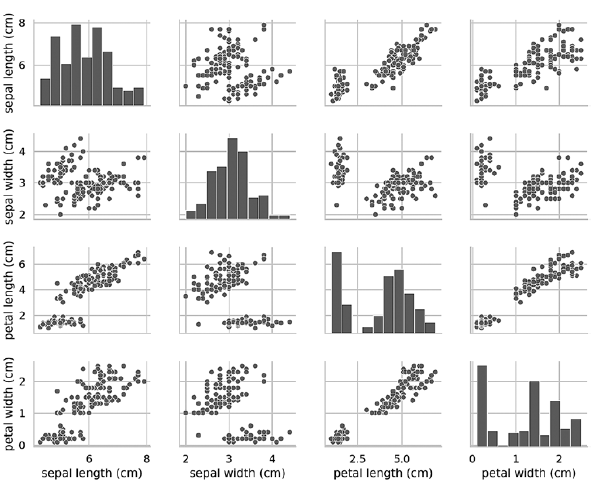 تعمل الرسوم البيانية لـ Pairplot بشكل جيد مع عدد صغير من الميزات أو مجموعة فرعية من الميزات بحيث يكون عدد الصفوف والأعمدة محدودًا ، ومع عدد صغير نسبيًا من الأنماط بحيث تكون نقاط البيانات مرئية. مع نمو عدد الميزات والأنماط ، تصبح المخططات المبعثرة للبيانات صغيرة جدًا بحيث لا يمكن قراءة البيانات. في مجموعات البيانات الكبيرة ، يمكنك رسم مجموعة فرعية من الميزات على الرسم البياني ، واختيارًا ، مجموعة فرعية مختارة عشوائيًا من الأنماط للحصول على فكرة عن البيانات.»يمكن العثور على مزيد من المعلومات حول الكتاب وشراؤها على موقع الناشر على الويب
تعمل الرسوم البيانية لـ Pairplot بشكل جيد مع عدد صغير من الميزات أو مجموعة فرعية من الميزات بحيث يكون عدد الصفوف والأعمدة محدودًا ، ومع عدد صغير نسبيًا من الأنماط بحيث تكون نقاط البيانات مرئية. مع نمو عدد الميزات والأنماط ، تصبح المخططات المبعثرة للبيانات صغيرة جدًا بحيث لا يمكن قراءة البيانات. في مجموعات البيانات الكبيرة ، يمكنك رسم مجموعة فرعية من الميزات على الرسم البياني ، واختيارًا ، مجموعة فرعية مختارة عشوائيًا من الأنماط للحصول على فكرة عن البيانات.»يمكن العثور على مزيد من المعلومات حول الكتاب وشراؤها على موقع الناشر على الويب