الآن تخترق البرمجة أعمق وأعمق في جميع مجالات الحياة. وربما أصبح بفضل الثعبان الشعبي الآن. إذا كان عليك قبل 5 سنوات ، لتحليل البيانات ، استخدام مجموعة كاملة من الأدوات المختلفة: C # لتفريغ (أو أقلام) ، و Excel ، و MatLab ، و SQL ، و "القفز" باستمرار هناك ، والتنظيف ، والتحقق ، والتوفيق بين البيانات. الآن الثعبان ، بفضل عدد كبير من المكتبات والوحدات الممتازة ، في التقريب الأول يحل محل جميع هذه الأدوات بأمان ، وبالتزامن مع SQL ، بشكل عام ، "يمكن لف الجبال".لذا ماذا أفعل. أصبحت مهتمًا بتعلم مثل هذا الثعبان الشعبي. وأفضل طريقة لتعلم شيء ما ، كما تعلمون ، هي الممارسة. كما أنني مهتم بالعقارات. ووجدت مشكلة مثيرة للاهتمام حول العقارات في موسكو: لترتيب أحياء موسكو حسب متوسط تكلفة الإيجار لمتوسط odnushka؟ أيها الآباء ، اعتقدت أن لديك هنا تحديد الموقع الجغرافي ، وتحميله من الموقع ، وتحليل البيانات - وهي مهمة عملية عظيمة.مستوحاة من المقالات الرائعة هنا على حبري (في نهاية المقال سأضيف روابط) ، لنبدأ!المهمة بالنسبة لنا هي أن نذهب من خلال الأدوات الموجودة داخل الثعبان ، وتفكيك التقنية - كيفية حل هذه المشاكل وقضاء الوقت مع المتعة ، وليس فقط مع الفائدة.- كشط سماوي
- إطار بيانات واحد
- معالجة إطار البيانات
- النتائج
- قليلا عن العمل مع البيانات الجغرافية
كشط سماوي
في منتصف مارس 2020 ، كان من الممكن جمع ما يقرب من 9 آلاف اقتراح لاستئجار شقة من غرفة واحدة في موسكو على السماوي ، ويعرض الموقع 54 صفحة. سنعمل مع jupyter-notebook 6.0.1 ، python 3.7. نقوم بتحميل البيانات من الموقع وحفظها في الملفات باستخدام مكتبة الطلبات .حتى لا يحظرنا الموقع ، سنخفي أنفسنا كشخص عن طريق إضافة تأخير في الطلبات وتعيين رأس بحيث يبدو من جانب الموقع شخصًا ذكيًا جدًا يقدم الطلبات من خلال متصفح. لا تنسى التحقق من الاستجابة من الموقع في كل مرة ، وإلا تم اكتشافنا فجأة وحظرنا بالفعل. يمكنك قراءة المزيد والمزيد من التفاصيل حول تجريف مواقع الويب ، على سبيل المثال ، هنا: Web Scraping باستخدام python .من الملائم أيضًا إضافة الديكور لتقييم سرعة وظائفنا وتسجيل الدخول. يسمح لك مستوى الإعداد = logging.INFO بتحديد نوع الرسائل المعروضة في السجل. يمكنك أيضًا تكوين الوحدة النمطية لإخراج السجل إلى ملف نصي ، وهذا بالنسبة لنا غير ضروري.الرمزdef timer(f):
def wrap_timer(*args, **kwargs):
start = time.time()
result = f(*args, **kwargs)
delta = time.time() - start
print (f' {f.__name__} {delta} ')
return result
return wrap_timer
def log(f):
def wrap_log(*args, **kwargs):
logging.info(f" {f.__doc__}")
result = f(*args, **kwargs)
logging.info(f": {result}")
return result
return wrap_log
logging.basicConfig(level=logging.INFO)
@timer
@log
def requests_site(N):
headers = ({'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15'})
pages = [106 + i for i in range(N)]
n = 0
for i in pages:
s = f"https://www.cian.ru/cat.php?deal_type=rent&engine_version=2&page={i}&offer_type=flat®ion=1&room1=1&type=-2"
response = requests.get(s, headers = headers)
if response.status_code == 200:
name = f'sheets/sheet_{i}.txt'
with open(name, 'w') as f:
f.write(response.text)
n += 1
logging.info(f" {i}")
else:
print(f" {i} response.status_code = {response.status_code}")
time.sleep(np.random.randint(7,13))
return f" {n} "
requests_site(300)
إطار بيانات واحد
لقص
الصفحات ، اختر BeautifulSoup و lxml . نستخدم "حساء جميل" لمجرد اسمها الرائع ، على الرغم من أنهم يقولون أن lxml أسرع.يمكنك القيام بذلك بشكل جميل ، وأخذ قائمة بالملفات من مجلد باستخدام مكتبة نظام التشغيل ، وتصفية الامتدادات التي نحتاجها والانتقال إليها. لكننا سنجعل الأمر أسهل ، لأننا نعرف العدد الدقيق للملفات وأسمائها الدقيقة. ما لم نضيف الزخرفة على شكل شريط التقدم ، باستخدام مكتبة tqdmالرمز
from bs4 import BeautifulSoup
import re
import pandas as pd
from dateutil.parser import parse
from datetime import datetime, date, time
def read_file(filename):
with open(filename) as input_file:
text = input_file.read()
return text
import tqdm
site_texts = []
pages = [1 + i for i in range(309)]
for i in tqdm.tqdm(pages):
name = f'sheets/sheet_{i}.txt'
site_texts.append(read_file(name))
print(f" {len(site_texts)} .")
def parse_tag(tag, tag_value, item):
key = tag
value = "None"
if item.find('div', {'class': tag_value}):
if key == 'link':
value = item.find('div', {'class': tag_value}).find('a').get('href')
elif (key == 'price' or key == 'price_meter'):
value = parse_digits(item.find('div', {'class': tag_value}).text, key)
elif key == 'pub_datetime':
value = parse_date(item.find('div', {'class': tag_value}).text)
else:
value = item.find('div', {'class': tag_value}).text
return key, value
def parse_digits(string, type_digit):
digit = 0
try:
if type_digit == 'flats_counts':
digit = int(re.sub(r" ", "", string[:string.find("")]))
elif type_digit == 'price':
digit = re.sub(r" ", "", re.sub(r"₽", "", string))
elif type_digit == 'price_meter':
digit = re.sub(r" ", "", re.sub(r"₽/²", "", string))
except:
return -1
return digit
def parse_date(string):
now = datetime.strptime("15.03.20 00:00", "%d.%m.%y %H:%M")
s = string
if string.find('') >= 0:
s = "{} {}".format(now.day, now.strftime("%b"))
s = string.replace('', s)
elif string.find('') >= 0:
s = "{} {}".format(now.day - 1, now.strftime("%b"))
s = string.replace('',s)
if (s.find('') > 0):
s = s.replace('','mar')
if (s.find('') > 0):
s = s.replace('','feb')
if (s.find('') > 0):
s = s.replace('','jan')
return parse(s).strftime('%Y-%m-%d %H:%M:%S')
def parse_text(text, index):
tag_table = '_93444fe79c--wrapper--E9jWb'
tag_items = ['_93444fe79c--card--_yguQ', '_93444fe79c--card--_yguQ']
tag_flats_counts = '_93444fe79c--totalOffers--22-FL'
tags = {
'link':('c6e8ba5398--info-section--Sfnx- c6e8ba5398--main-info--oWcMk','undefined c6e8ba5398--main-info--oWcMk'),
'desc': ('c6e8ba5398--title--2CW78','c6e8ba5398--single_title--22TGT', 'c6e8ba5398--subtitle--UTwbQ'),
'price': ('c6e8ba5398--header--1df-X', 'c6e8ba5398--header--1dF9r'),
'price_meter': 'c6e8ba5398--term--3kvtJ',
'metro': 'c6e8ba5398--underground-name--1efZ3',
'pub_datetime': 'c6e8ba5398--absolute--9uFLj',
'address': 'c6e8ba5398--address-links--1tfGW',
'square': ''
}
res = []
flats_counts = 0
soup = BeautifulSoup(text)
if soup.find('div', {'class': tag_flats_counts}):
flats_counts = parse_digits(soup.find('div', {'class': tag_flats_counts}).text, 'flats_counts')
flats_list = soup.find('div', {'class': tag_table})
if flats_list:
items = flats_list.find_all('div', {'class': tag_items})
for i, item in enumerate(items):
d = {'index': index}
index += 1
for tag in tags.keys():
tag_value = tags[tag]
key, value = parse_tag(tag, tag_value, item)
d[key] = value
results[index] = d
return flats_counts, index
from IPython.display import clear_output
sum_flats = 0
index = 0
results = {}
for i, text in enumerate(site_texts):
flats_counts, index = parse_text(text, index)
sum_flats = len(results)
clear_output(wait=True)
print(f" {i + 1} flats = {flats_counts}, {sum_flats} ")
print(f" sum_flats ({sum_flats}) = flats_counts({flats_counts})")
فارق بسيط مثير للاهتمام هو أن الرقم الموضح في أعلى الصفحة ويشير إلى إجمالي عدد الشقق التي تم العثور عليها عند الطلب يختلف من صفحة إلى أخرى. لذلك ، في مثالنا ، يتم فرز هذه العروض البالغ عددها 5.402 بشكل افتراضي ، وتتراوح من 5343 إلى 5402 ، وتنخفض تدريجيًا مع زيادة رقم الصفحة للطلب (ولكن ليس بعدد الإعلانات المعروضة). بالإضافة إلى ذلك ، كان من الممكن الاستمرار في إلغاء تحميل الصفحات بما يتجاوز حدود عدد الصفحات المشار إليها في الموقع. في حالتنا ، تم عرض 54 صفحة فقط على الموقع ، ولكن تمكنا من إلغاء تحميل 309 صفحة ، مع إعلانات قديمة فقط ، ليصبح المجموع 8640 إعلانًا لتأجير الشقق.سيتم ترك تحقيق في هذه الحقيقة خارج نطاق هذه المقالة.معالجة إطار البيانات
لذا ، لدينا إطار بيانات واحد مع بيانات أولية على 8640 عرضًا. سنقوم بإجراء تحليل سطحي لمتوسط الأسعار والمتوسط في المناطق ، وحساب متوسط سعر الإيجار لكل متر مربع من الشقة وتكلفة الشقة في المنطقة "في المتوسط".سننتقل من الافتراضات التالية لدراستنا:- عدم وجود التكرار: جميع الشقق الموجودة هي شقق موجودة بالفعل. في المرحلة الأولى ، قمنا بإلغاء الشقق المتكررة في العنوان والتربيع ، ولكن إذا كانت الشقة تحتوي على تربيع أو عنوان مختلف قليلاً ، فإننا نعتبر هذه الخيارات بمثابة شقق مختلفة.
- — .
— «» ? ( ) , , , , . , , , . «» : . «» ( ) , .
سنحتاج إلى:price_per_month - الإيجار الشهري فيميدان روبل - منطقةأوكروج - المنطقة ، في هذه الدراسة ، العنوان الكامل غير مهم بالنسبة لناprice_meter - سعر الإيجار لكل متر مربعالرمزdf['price_per_month'] = df['price'].str.strip('/.').astype(int)
new_desc = df["desc"].str.split(",", n = 3, expand = True)
df["square"]= new_desc[1].str.strip(' ²').astype(int)
df["floor"]= new_desc[2]
new_address = df['address'].str.split(',', n = 3, expand = True)
df['okrug'] = new_address[1].str.strip(" ")
df['price_per_meter'] = (df['price_per_month'] / df['square']).round(2)
df = df.drop(['index','metro', 'price_meter','link', 'price','desc','address','pub_datetime','floor'], axis='columns')
الآن سنهتم بالانبعاثات يدويًا وفقًا للجداول الزمنية. لتصور البيانات، دعونا ننظر ثلاث مكتبات: matplotlib ، سيبورن و plotly .الرسوم البيانية للبيانات . يتيح لك Matplotlib عرض جميع الرسوم البيانية لمجموعات البيانات التي تهمنا بسرعة وسهولة ، ولا نحتاج إلى المزيد. يتم حذف الشكل أدناه ، الذي لا يمكن بموجبه تقديم اقتراح واحد في Mitino كتقييم نوعي للشقة المتوسطة. صورة أخرى مثيرة للاهتمام في Okrug الإدارية الجنوبية: غالبية العروض (أكثر من 500 وحدة) بقيمة إيجار أقل من 1000 روبل ، وزيادة في العروض (ما يقرب من 300 وحدة) بمقدار 1700 روبل لكل متر مربع. في المستقبل ، يمكنك معرفة سبب حدوث ذلك - البحث في مؤشرات أخرى لهذه الشقق.سطر واحد فقط من الكود يعطي الرسوم البيانية هناك لمجموعات البيانات المجمعة:hists = df['price_per_meter'].hist(by=df['okrug'], figsize=(16, 14), color = "tab:blue", grid = True)
 مبعثر القيم . قدم أدناه الرسوم البيانية باستخدام المكتبات الثلاث. يكون سطح البحر افتراضيًا أكثر جمالًا وإشراقًا ، ولكنه يتيح لك عرض القيم على الفور عند تحريك الماوس ، وهو أمر مريح للغاية بالنسبة لنا لتحديد قيم "القيم المتطرفة" التي سنحذفها.ماتبلوتليب
مبعثر القيم . قدم أدناه الرسوم البيانية باستخدام المكتبات الثلاث. يكون سطح البحر افتراضيًا أكثر جمالًا وإشراقًا ، ولكنه يتيح لك عرض القيم على الفور عند تحريك الماوس ، وهو أمر مريح للغاية بالنسبة لنا لتحديد قيم "القيم المتطرفة" التي سنحذفها.ماتبلوتليبfig, axes = plt.subplots(nrows=4,ncols=3,figsize=(15,15))
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
axes = axes.flatten()
axes[i].scatter(group['price_per_meter'],group['square'], color ='blue')
axes[i].set_title(name)
axes[i].set(xlabel=' 1 ..', ylabel=', 2')
fig.tight_layout()
 مركب بحري
مركب بحريsns.pairplot(vars=["price_per_meter","square"], data=df_copy, hue="okrug", height=5)
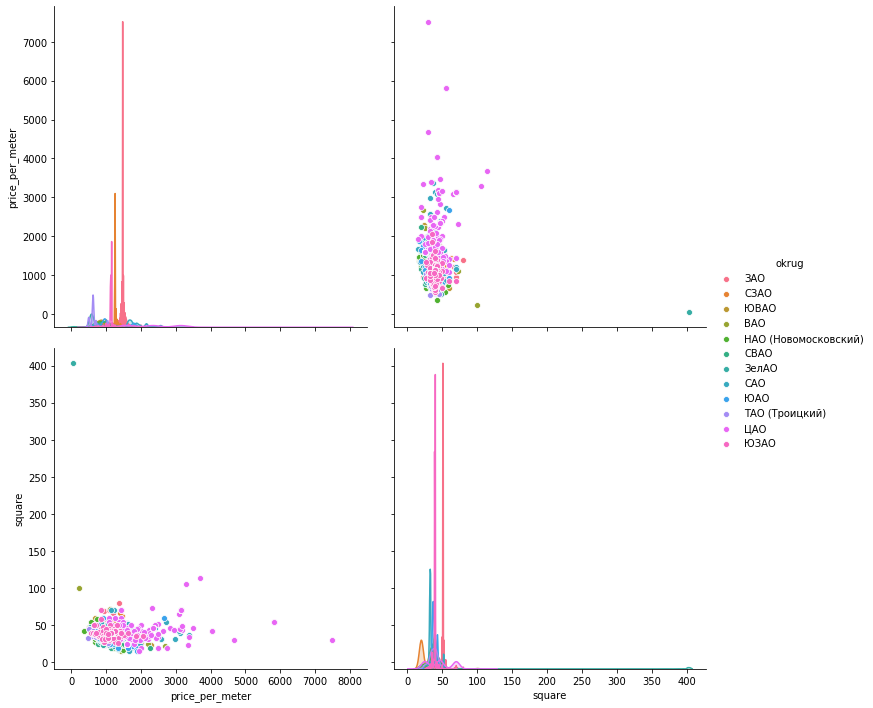 مؤامرةأعتقد أنه سيكون هناك مثال كاف لمنطقة واحدة.
مؤامرةأعتقد أنه سيكون هناك مثال كاف لمنطقة واحدة.import plotly.express as px
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
fig = px.scatter(group, x="price_per_meter", y="square", facet_col="okrug",
width=400, height=400)
fig.update_layout(
margin=dict(l=20, r=20, t=20, b=20),
paper_bgcolor="LightSteelBlue",
)
fig.show()
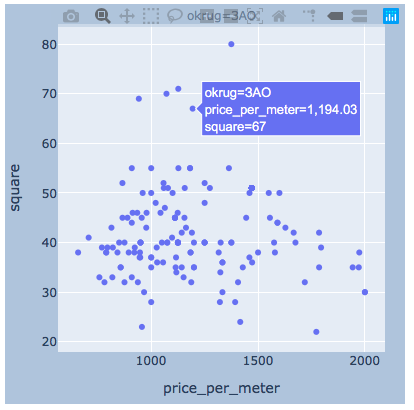
النتائج
لذا ، بعد تنظيف البيانات وإزالة الانبعاثات بخبرة ، لدينا 8602 عرضًا "نظيفًا".بعد ذلك ، نحسب الإحصائيات الرئيسية وفقًا للبيانات: متوسط ، متوسط ، انحراف معياري ، نحصل على التصنيف التالي لمقاطعات موسكو حيث ينخفض متوسط تكلفة الإيجار لمتوسط شقة: يمكنك رسم رسوم بيانية جميلة بمقارنة ، على سبيل المثال ، متوسط الأسعار ومتوسط في المنطقة:
يمكنك رسم رسوم بيانية جميلة بمقارنة ، على سبيل المثال ، متوسط الأسعار ومتوسط في المنطقة: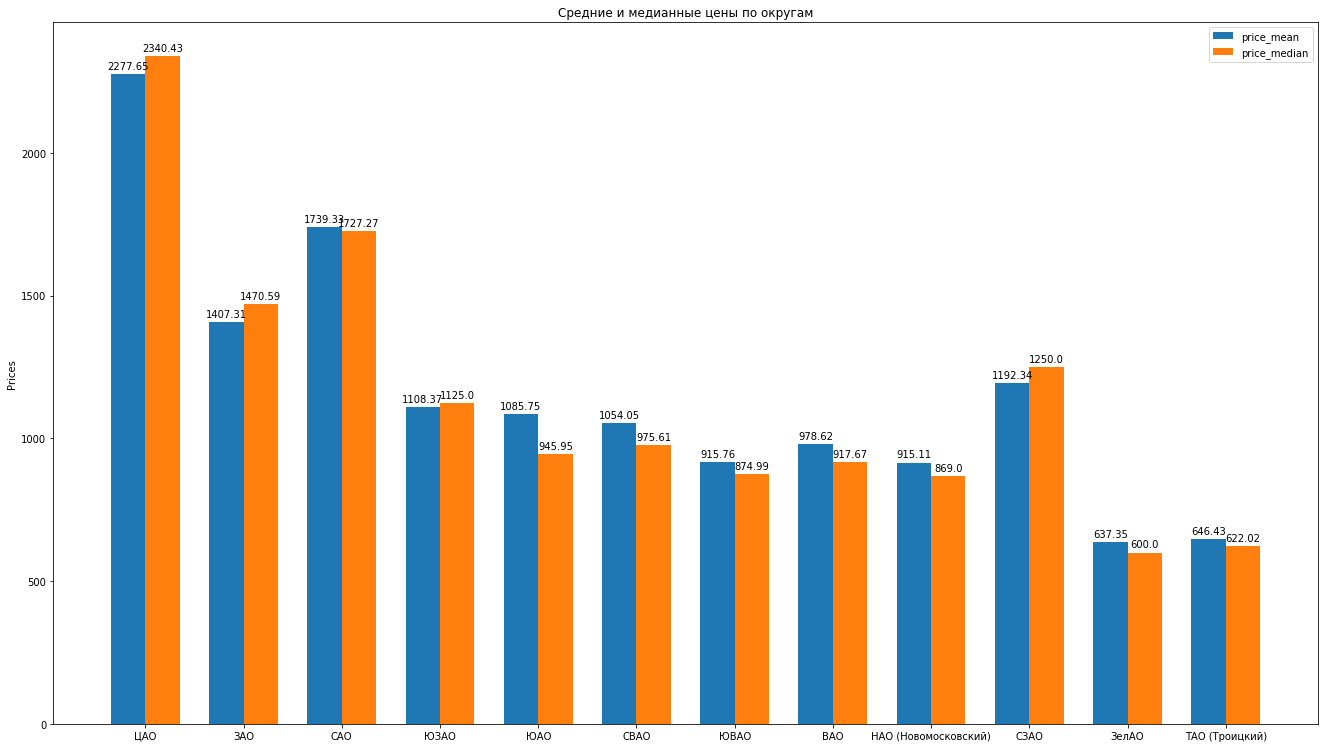 ماذا يمكن أن نقول عن هيكل مقترحات تأجير الشقق على أساس البيانات:
ماذا يمكن أن نقول عن هيكل مقترحات تأجير الشقق على أساس البيانات:- , , , . “” , ( ). , , , , , , “” . , , .
- . . « ». , «» — . . . , , , , , - , , . . .
- , “” , . , , — .
فصل منفصل ومثير للاهتمام ورائع بشكل لا يصدق هو موضوع البيانات الجغرافية ، عرض بياناتنا فيما يتعلق بالخريطة. يمكنك البحث بالتفصيل والتفاصيل ، على سبيل المثال ، في المقالات التالية:تصور نتائج الانتخابات في موسكو على خريطة في Jupyter NotebookLikbez على إسقاطات رسم الخرائط مع صورOpenStreetMap كمصدر للبيانات الجغرافيةباختصار ، OpenStreetMap هو كل شيء لدينا ، الأدوات المناسبة هي: geopandas ، cartoframes (يقولون أنها بالفعل بالفعل مات؟) و folium ، الذي سنستخدمه .إليك ما ستبدو عليه بياناتنا على خريطة تفاعلية.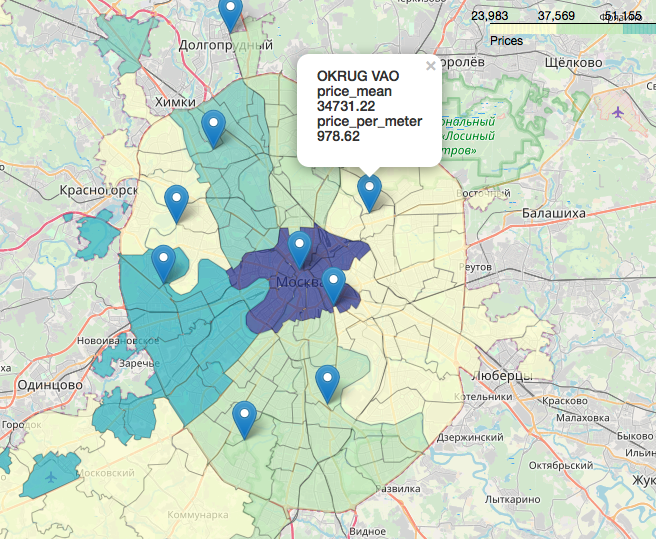 المواد التي تبين أنها مفيدة في العمل على المقال:أتمنى أن تكون مهتمًا مثلي.شكرا لقرائتك. النقد البناء مرحب به.يتم نشر المصادر ومجموعات البيانات على جيثب هنا .
المواد التي تبين أنها مفيدة في العمل على المقال:أتمنى أن تكون مهتمًا مثلي.شكرا لقرائتك. النقد البناء مرحب به.يتم نشر المصادر ومجموعات البيانات على جيثب هنا .