ظهر ضغط الرؤوس القياسية في HTTP / 2 ، لكن نص URI و Cookie و User-Agent يمكن أن يظل عشرات الكيلوبايتات ويتطلب الترميز والبحث ومقارنة السلاسل الفرعية. تصبح المهمة حاسمة إذا كان محلل HTTP يحتاج إلى معالجة حركة المرور الضارة الضخمة. توفر المكتبات القياسية أدوات معالجة سلسلة واسعة النطاق ، لكن سلاسل HTTP لها تفاصيلها الخاصة. لهذه الخصوصية تم تطوير محلل Tempesta FW HTTP. أداؤها أعلى بعدة مرات مقارنة بالحلول الحديثة مفتوحة المصدر ويتجاوز أسرعها.ألكسندر كريزانوفسكي (كريزانوفسكي) مؤسس ومهندس النظام Tempesta Technologies ، خبير في الحوسبة عالية الأداء في Linux / x86-64. سيتحدث ألكسندر عن خصائص هيكل سلاسل HTTP ، ويشرح سبب عدم ملاءمة المكتبات القياسية لمعالجتها ، وتقديم حل Tempesta FW.تحت القطع: كيف يحول HTTP Flood محلل HTTP الخاص بك إلى عنق الزجاجة ، مشاكل x86-64 مع الأخطاء في الفروع ، التخزين المؤقت ونفاد الذاكرة في مهام محلل HTTP النموذجي ، مقارنة FSM مع القفزات المباشرة ، التحسين في دول مجلس التعاون الخليجي ، التجهي التلقائي ، strspn () - و strcasecmp () - مثل الخوارزميات لسلاسل HTTP و SSE و AVX2 وهجمات حقن التصفية باستخدام AVX2.في Tempesta Technologies نقوم بتطوير برامج مخصصة: نحن متخصصون في المجالات المعقدة المتعلقة بالأداء العالي. نحن فخورون بشكل خاص بتطوير جوهر الإصدار الأول من WAF. جدار حماية تطبيق الويب (WAF) هو وكيل HTTP: فهو يتعامل مع تحليل عميق للغاية لحركة مرور HTTP للهجمات (الويب و DDoS). كتبنا الجوهر الأول لذلك.بالإضافة إلى الاستشارات ، نقوم بتطوير Tempesta FW - هذا هو مراقب تسليم التطبيقات (ADC). سنتحدث عنه.مراقب تسليم التطبيقات
مراقب تسليم التطبيقات هو وكيل HTTP مع وظائف محسنة. لكن سأتحدث عن ميزة تتعلق بالأمان - حول تصفية DDoS وهجمات الويب. سأذكر أيضًا القيود ، وسأعرض العمل والوظائف مع أمثلة التعليمات البرمجية.
أداء
تم بناء Tempesta FW في نواة Linux TCP / IP Stack. بفضل هذا وعدد من التحسينات الأخرى ، فهي سريعة جدًا - يمكنها معالجة 1.8 مليون طلب في الثانية على أجهزة رخيصة. هذا أسرع 3 مرات من Nginx في الحمل العلوي وهو سريع أيضًا عند مقارنته بنهج تجاوز النواة.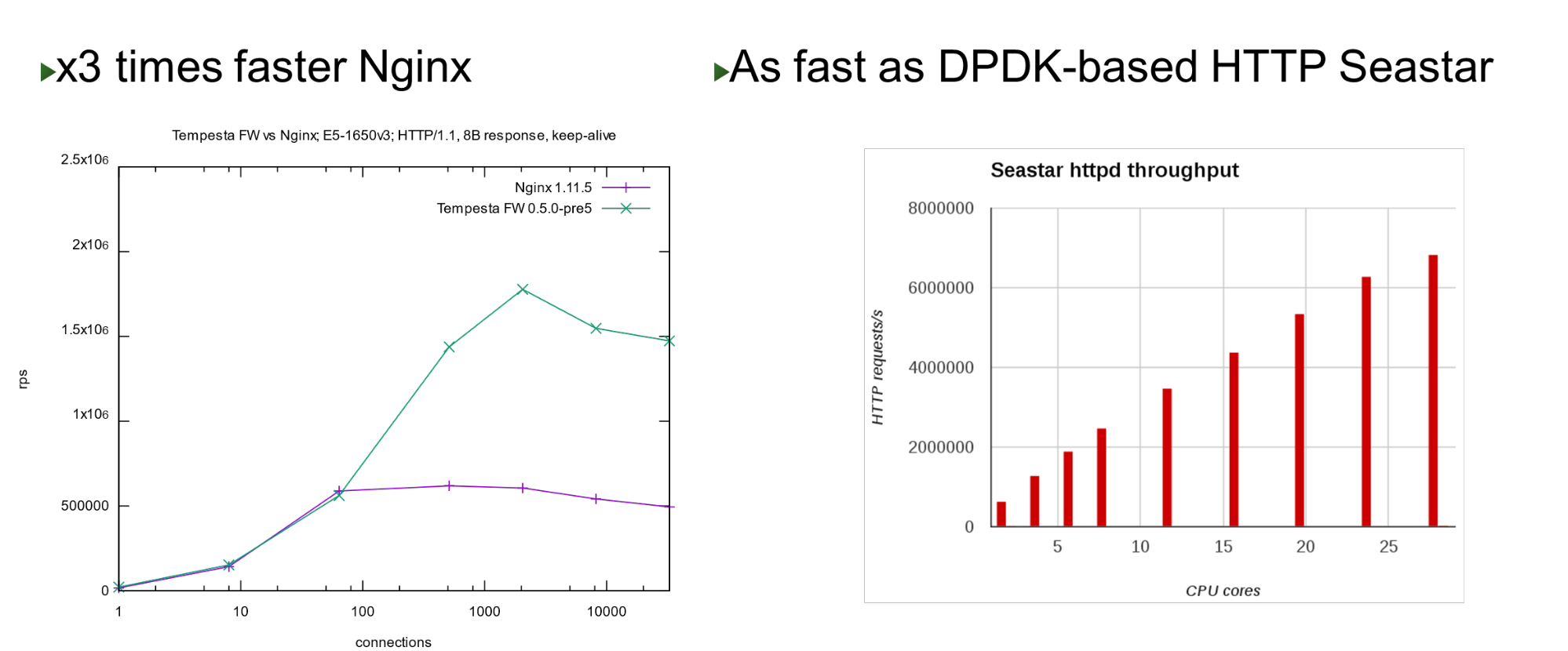 على عدد صغير من النوى ، يظهر أداء مشابهًا لمشروع Seastar ، والذي يستخدم في ScyllaDB (المكتوب في DPDK).
على عدد صغير من النوى ، يظهر أداء مشابهًا لمشروع Seastar ، والذي يستخدم في ScyllaDB (المكتوب في DPDK).مشكلة
ولد المشروع عندما بدأنا العمل على PT AF - في عام 2013. استند WAF هذا إلى أحد برامج تسريع HTTP مفتوحة المصدر الشائعة. تعد Nginx أو HAProxy أو Varnish أو Apache Traffic مسرعات HTTP جيدة: فهي تقدم محتوى جيدًا وذاكرة تخزين مؤقت وتعديلًا ، ولكن لم يتم تصميم أي منها لمعالجة حركة المرور الضخمة والتصفية .لذلك ، اعتقدنا أنه إذا كان هناك جدار حماية على مستوى الشبكة ، فلماذا لا تستمر هذه الفكرة وتندمج في مكدس TCP / IP كجدار حماية على مستوى التطبيق؟ في الواقع ، تبين أن Tempesta FW - مزيج من مسرع HTTP وجدار الحماية .ملاحظة: سيتم استخدام Nginx كمثال في التقرير لأنه خادم ويب بسيط وشائع. بدلاً من ذلك ، قد يكون هناك أي خادم HTTP مفتوح المصدر آخر.HTTP
لنلق نظرة على طلب HTTP الخاص بنا (HTTP / (1، ~ 2))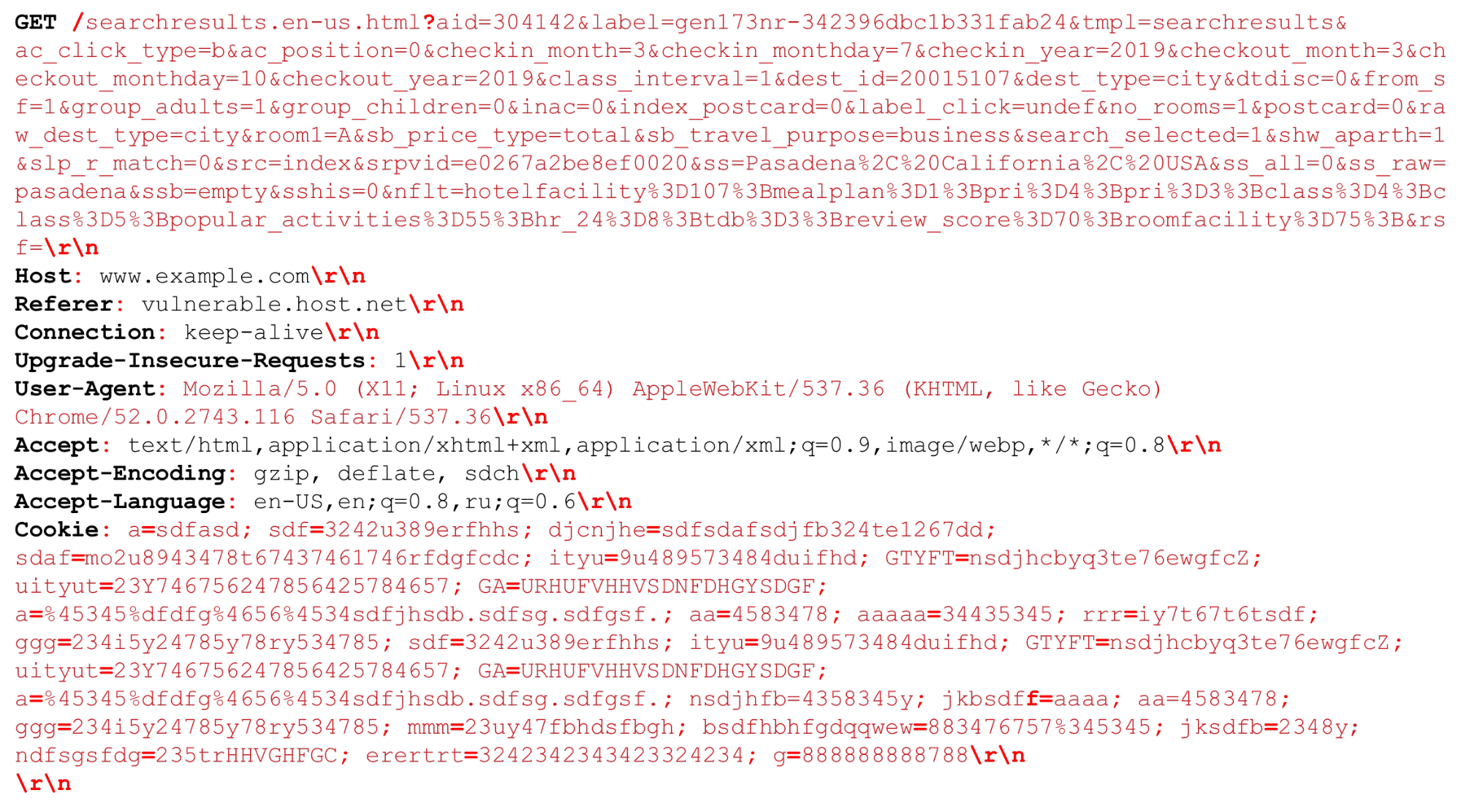 يمكننا الحصول على URI كبير جدًا. يتم تمييز الفواصل المهمة في وقت تحليل HTTP بالخط العريض الأحمر . سأسلط الضوء على الميزات: سلاسل كبيرة من عدة كيلوبايت ، بالإضافة إلى محددات مختلفة ، على سبيل المثال ، "فواصل منقوطة" إضافية نحتاج إلى تحليلها ، أو التسلسل "\ r \ n".كما يجب أن يقال القليل عن HTTP / 2.
يمكننا الحصول على URI كبير جدًا. يتم تمييز الفواصل المهمة في وقت تحليل HTTP بالخط العريض الأحمر . سأسلط الضوء على الميزات: سلاسل كبيرة من عدة كيلوبايت ، بالإضافة إلى محددات مختلفة ، على سبيل المثال ، "فواصل منقوطة" إضافية نحتاج إلى تحليلها ، أو التسلسل "\ r \ n".كما يجب أن يقال القليل عن HTTP / 2.ميزات HTTP / 2
HTTP / 2 عبارة عن مزيج من السلاسل والبيانات الثنائية . يتعلق هذا المزيج بتحسين عرض النطاق الترددي للاتصال بدلاً من توفير موارد الخادم.يستخدم HTTP / 2 في HPACK جدولاً ديناميكيًا . لم يتم تحسين الطلب الأول من العميل ، وهو ليس في الجدول. يجب عليك تحليلها حتى يتم إضافتها إلى الجدول. إذا وصل إليك HTTP / 2 DDoS ، فستكون هذه هي الحالة. في الحالة العادية ، يعد HTTP / 2 بروتوكولًا ثنائيًا ، ولكنك ما زلت بحاجة إلى تحليل النص: أسماء رؤوس النصوص والبيانات.ترميز هوفمان. هذا ترميز بسيط ، لكن Huffman يصعب برمجته بسرعة للضغط: ترميز Huffman يتخطى حدود البايت ، لا يمكنك استخدام ملحقات المتجه وتحتاج إلى تجاوز وحدات البايت. لن تتمكن من معالجة البيانات بسرعة في 32 أو 16 بايت.يمكن أن تكون ملفات تعريف الارتباط ، وكيل المستخدم ، المُحيل ، عناوين URI كبيرة جدًا . أولاً ، قم بإزالة Huffman ، ثم أرسله إلى محلل HTTP العادي ، كما هو الحال في HTTP / 1. على الرغم من أن RFC يسمح به ، إلا أنه لا يوصى بضغط ملفات تعريف الارتباط ، لأن هذه بيانات سرية - لا يجب عليك إعطاء المهاجم معلومات حول حجمها.معالجة HTTP بطيئة . تقوم كافة خوادم HTTP أولاً بفك تشفير HTTP / 2 ثم إرسال هذه الأسطر إلى محلل HTTP / 1 الذي يستخدمه HTTP / 1 بالفعل.ما هي المشكلة في تحليل HTTP / 1؟- تحتاج إلى برمجة جهاز الدولة بسرعة.
- تحتاج إلى معالجة الخطوط المتتالية بسرعة.
تستهدف حركة المرور الضارة الجزء الأبطأ (الأضعف) من العملية. لذلك ، إذا أردنا عمل مرشح ، يجب علينا الانتباه إلى الأجزاء البطيئة حتى تعمل أيضًا بسرعة.ملف Nginx الشخصي
دعونا نلقي نظرة على ملف تعريف nginx تحت تدفق HTTP. قم بتعطيل سجل الوصول بحيث لا يتباطأ نظام الملفات. عند طلب صفحة فهرس عادية ، يرتفع المحلل في الأعلى.اليسار - "ملف تعريف مسطح". ومن المثير للاهتمام أن المكان الأكثر سخونة فيه ليس أثقل بكثير من التالي ، وبعد ذلك ينحدر الملف الشخصي بسلاسة. هذا يعني ، على سبيل المثال ، أن تحسين الوظيفة الأولى مرتين لن يساعد على تحسين الأداء بشكل كبير. هذا هو السبب في أننا لم نحسن نفس Nginx ، لكننا قمنا بمشروع جديد سيحسن أداء الذيل الكامل للملف الشخصي.كيف يتم ترميز موزعي HTTP العاديين
عادة لدينا حلقة ( while) تعمل على طول الخط ، ومتغيرين: الحالة ( state) والبيانات الحالية ( str_ptr).ندخل الدورة (1) ونلقي نظرة على الحالة الحالية (التحقق من الحالة). نمر إلى البيانات المستلمة (الرمز 'b') وننفذ بعض المنطق. ننتقل إلى الحالة الثانية (2). انتقل إلى النهاية
انتقل إلى النهاية switch(3) - وهذا هو الانتقال الثاني بالنسبة لبداية الكود الخاص بنا ، وربما الفشل الثاني في ذاكرة التخزين المؤقت للإرشادات. ثم نذهب إلى البداية while(4) ، نأكل الحرف التالي ...... ونبحث مرة أخرى عن الحالة في التعليمات بالداخل
ونبحث مرة أخرى عن الحالة في التعليمات بالداخل case 2:.عندما تم تعيين stateقيمة للمتغير بالفعل2، يمكننا فقط الذهاب إلى التعليمات التالية. ولكن بدلاً من ذلك ، صعدوا مرة أخرى ونزلوا مرة أخرى. نحن "نقطع الدوائر" بالكود بدلاً من النزول. لا يقوم المحللون العاديون ، على سبيل المثال ، Ragel بإنشاء محلل بتحولات مباشرة.
Nginx HTTP Parser
بضع كلمات حول محلل nginx وبيئته.يعمل Nginx مع واجهة برمجة تطبيقات المقبس العادية - يتم نسخ البيانات التي تنتقل إلى المحول إلى مساحة المستخدم. ونتيجة لذلك ، لدينا جزء كبير من البيانات التي نبحث فيها عما نحتاج إليه.يستخدم Nginx خوارزمية تعمل في مسارين: أولاً يبحث عن الطول ، ثم يتحقق. في الخطوة الأولى ، يمسح السلسلة بحثًا عن الرموز المميزة ، ويبحث عن الرمز الأول ("التجربة"). في الثانية ، يتم التحقق من نهاية الطلب ( Get) ويبدأ switch، وفقًا لحجم الرمز المميز.for (p = b->pos; p < b->last; p++) {
...
switch (state) {
...
case sw_method:
if (ch == ' ') {
m = r->request_start;
switch (p - m) {
case 3:
if (ngx_str3_cmp(m, 'G', 'E', 'T', ' ')) {
...
}
if ((ch < 'A' || ch > 'Z') && ch != '_' && ch != '-')
return NGX_HTTP_PARSE_INVALID_METHOD;
break;
...
"Get" موجود دائمًا في نفس مجموعة البيانات . يعمل Tempesta FW مع نسخة صفرية. هذا يعني أن البيانات يمكن أن تأتي بحجم عشوائي تمامًا: 1 بايت أو 1000 بايت لكل منهما. هذه "الآلية" لا تناسبنا.دعونا نرى كيف يعمل switchفي دول مجلس التعاون الخليجي.مجلس التعاون الخليجي
جدول البحث . على اليسار مثال نموذجي على التعداد: ابدأ بـ 0 ، ثم التسميات المتتالية ، و 26 ثوابت ، ثم بعض التعليمات البرمجية التي تعالجها كلها. على اليمين هو الرمز الذي يولده المترجم. أولاً ، قارن المتغير
أولاً ، قارن المتغير stateفي سجل EAX بالثابت. بعد ذلك ، نقدم جميع التسميات في شكل صفيف متسلسل من مؤشرات 8 بايت (جدول البحث). في هذه التعليمات نقوم بتمرير الإزاحة في هذا المصفوفة - وهو عبارة عن عملية مزدوجة للإشارة من المؤشرات. أسفل اليمين هو الرمز الذي بدّلنا إليه من هذا الجدول.اتضح أن الإشارة المزدوجة للذاكرة: إذا تلقينا بيانات سرية ، فعندئذٍ بالبايت نجد العنوان في المصفوفة وننتقل إلى هذا المؤشر. من المهم أن تعرف أنه في الحياة لا يزال أسوأ مما هو عليه في المثال - بالنسبة لجدول البحث الذي يولده المترجميكون الرمز أكثر تعقيدًا في حالة وجود نص برمجي لهجوم Spectre.بحث ثنائي . الحالة التالية switchليست مع الثوابت المتسلسلة ، ولكن مع الثوابت التعسفية. الرمز هو نفسه ، ولكن الآن لا يمكن لدول مجلس التعاون الخليجي تجميع مثل هذا الصفيف الكبير واستخدام الثوابت مثل فهرس الصفيف. ينتقل إلى البحث الثنائي. على اليمين نرى مقارنة تسلسلية ، والانتقال إلى العنوان واستمرار المقارنة - البحث الثنائي عن طريق الكود.Nginx HTTP محلل. دعونا نرى ما هو nginx آلة الدولة. يحتوي على 9 كيلوبايت من التعليمات البرمجية - وهذا أقل بثلاث مرات من ذاكرة التخزين المؤقت للمستوى الأول على الجهاز الذي تم إطلاق المعايير عليه (كما هو الحال في معظم معالجات x86-64).
على اليمين نرى مقارنة تسلسلية ، والانتقال إلى العنوان واستمرار المقارنة - البحث الثنائي عن طريق الكود.Nginx HTTP محلل. دعونا نرى ما هو nginx آلة الدولة. يحتوي على 9 كيلوبايت من التعليمات البرمجية - وهذا أقل بثلاث مرات من ذاكرة التخزين المؤقت للمستوى الأول على الجهاز الذي تم إطلاق المعايير عليه (كما هو الحال في معظم معالجات x86-64).$ nm -S /opt/nginx-1.11.5/sbin/nginx
| grep http_parse | cut -d' ' -f 2
| perl -le '$a += hex($_) while (<>); print $a'
9220
$ getconf LEVEL1_ICACHE_SIZE
32768
$ grep -c 'case sw_' src/http/ngx_http_parse.c
84
محلل رأس nginx ngx_http_parse_header_line ()هو رمز مميز بسيط. لا تفعل شيئًا مع قيم الرؤوس وأسمائها ، ولكنها ببساطة تضع الرموز المميزة لرؤوس HTTP في التجزئة. إذا كنت بحاجة إلى أي قيمة رأس ، فافحص جدول الرأس وكرر التحليل.يجب علينا التحقق بدقة من أسماء وقيم الرؤوس لأسباب أمنية .Tempesta FW: التحقق من صحة سلسلة سلاسل HTTP
إن جهاز الحالة الخاص بنا عبارة عن ترتيب بحجم أكبر: نقوم بالتحقق من صحة رأس RFC وعلى الفور ، في المحلل ، نعالج كل شيء تقريبًا. إذا كان nginx يحتوي على 80 ولاية ، فلدينا 520 ، وهناك المزيد منها. إذا سافرنا switch، فسيكون ذلك أكبر بعشر مرات.لدينا نسخة خالية من الإدخال / الإخراج - يمكن أن تؤدي قطع من أحجام مختلفة إلى قطع البيانات في أماكن مختلفة. قطع مختلفة يمكن أن تقطع بياناتنا. في I / O نسخة الصفر ، على سبيل المثال ، يمكن أن يحدث "GET" (نادرًا) مثل "GET" و "GE" و "T" أو "G" و "E" و "T" ، لذلك تحتاج إلى تخزين الحالة بين أجزاء البيانات . نزيل عمليا تكاليف I / O ، ولكن في الملف الشخصي يطير - كل شيء سيئ. محلل HTTP الكبير هو واحد من أكثر الأماكن أهمية في المشروع.$ grep -c '__FSM_STATE\|__FSM_TX\|__FSM_METH_MOVE\|__TFW_HTTP_PARSE_' http_parser.c
520
7.64% [tempesta_fw] [k] tfw_http_parse_req
2.79% [e1000] [k] e1000_xmit_frame
2.32% [tempesta_fw] [k] __tfw_strspn_simd
2.31% [tempesta_fw] [k] __tfw_http_msg_add_str_data
1.60% [tempesta_fw] [k] __new_pgfrag
1.58% [kernel] [k] skb_release_data
1.55% [tempesta_fw] [k] __str_grow_tree
1.41% [kernel] [k] __inet_lookup_established
1.35% [tempesta_fw] [k] tfw_cache_do_action
1.35% [tempesta_fw] [k] __tfw_strcmpspn
ماذا تفعل لتحسين هذا الوضع؟الإحالات المباشرة FSM
أول شيء نقوم به هو عدم استخدام حلقة ، ولكن الانتقالات المباشرة بواسطة التسميات ( go to) . مولدات محلل عادي مثل راجل تفعل ذلك. نقوم بتشفير كل ولاية من دولنا مع تسمية في
نقوم بتشفير كل ولاية من دولنا مع تسمية في switchواسم في C بنفس الاسم . في كل مرة نريد الذهاب ، نجد ملصقًا switchأو نصل إلى نفس الحالة مباشرة من الرمز. في المرة الأولى التي نمر فيها switch، وبعد ذلك ننتقل مباشرة إلى الملصق المطلوب.العيب : عندما نريد التبديل إلى الحالة التالية ، يجب أن نقيم على الفور ما إذا كان لا يزال لدينا بيانات متاحة (لأن نسخة الإدخال / الإخراج صفر). حالة الجسمforيتم نسخه إلى كل ولاية: بدلاً من شرط واحد في FSM عادي مدفوع بالتبديل ، لدينا 500 منهم وفقًا لعدد الحالات. إنشاء رمز لكل ولاية ليست كبيرة.في حالة آلات الحالة الكبيرة ، بالنسبة للداخل forالكبير switch، تكرر GTC أيضًا الشرط forعدة مرات داخل الكود.استبدلها بانتقالات switchمباشرة. التحسين التالي هو أننا لا نستخدمه switchوننتقل إلى الانتقال السريع إلى العناوين الوصفية المحفوظة. نريد الانتقال فورًا إلى النقطة المطلوبة بمجرد إدخال الوظيفة. يتيح لك دول مجلس التعاون الخليجي القيام بذلك. دول مجلس التعاون الخليجي لديها امتداد قياسي قد يساعد. نأخذ اسم التصنيف (هنا هو
دول مجلس التعاون الخليجي لديها امتداد قياسي قد يساعد. نأخذ اسم التصنيف (هنا هو from) ونعين عنوانه لبعض المتغيرات C عبر علامة العطف المزدوجة (&&). الآن يمكننا أن نجعل تعليمات القفز المباشرjmpإلى عنوان هذا التصنيف مع goto.دعنا نرى ما يأتي منه.أداء التحويل المباشر
في عدد قليل من الحالات ، يكون مولد رمز الانتقال المباشر أبطأ قليلاً من المعتاد switch. ولكن بالنسبة للآلات الكبيرة ، تتضاعف الإنتاجية. إذا كانت آلة الحالة صغيرة ، فمن الأفضل استخدام الآلة المعتادة switch.$ grep -m 2 'model name\|bugs' /proc/cpuinfo
model name : Intel(R) Core(TM) i7-6500U CPU @ 2.50GHz
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf
$ gcc --version|head -1
gcc (GCC) 8.2.1 20181105 (Red Hat 8.2.1-5)
States Switch-driven automaton Goto-driven automaton
7 header_line: 139ms header_line: 156ms
27 request_line: 210ms request_line: 186ms
406 big_header_line: 1406ms goto_big_header_line: 727ms
ملاحظة: كود Tempesta أكثر تعقيدًا من الأمثلة. يحتوي GitHub على جميع المعايير حتى تتمكن من رؤية كل شيء بالتفصيل. رمز المحلل الأصلي متاح على الرابط (محلل HTTP الرئيسي). بالإضافة إلى ذلك ، في Tempesta FW هناك محللات أصغر تستخدم FSM بشكل أسهل.لماذا قد تكون التحولات المباشرة أبطأ
في جهاز الدولة ، نمر بالكثير من التعليمات البرمجية ، لذلك (المتوقع) سيكون هناك الكثير من الأخطاء الفادحة. دعونا نجري "التنميط" وفقًا لتنبؤات أخطاء الفروع:perf record -e branch-misses -g ./http_benchmark
406 states: switch - 38% on switch(),
direct jumps - 13% on header value parsing
7,27 states: switch - <18% switch(), up to 40% for()
direct jumps – up to 46% on header & URI parsing
على جهاز كبير مع 406 حالة ، نقضي 38٪ من وقت معالجة التحولات في switch. على جهاز الدولة مع التحولات المباشرة ، يتم تحليل النقاط الساخنة. يتضمن تحليل سلسلة في كل حالة التحقق من حالة نهاية السلسلة: الحالة forفي جهاز الحالة قيد التشغيل switch.perf stat -e L1-icache-load-misses ./http_benchmark
Switch-driven automaton Goto-driven automaton
big FSM code size: 29156 49202
L1-icache-load-misses: 4M 2M
بعد ذلك ، نلقي نظرة على ملف تعريف نوعي آلة الحالة من خلال أحداث ذاكرة التخزين المؤقت للتعليمات L1 المفقودة - ما يقرب من 30 كيلو بايت switchو 50 كيلو بايت للقفزات المباشرة (أكثر من ذاكرة التخزين المؤقت لإرشادات المستوى الأول).يبدو أنه في حالة عدم احتواء ذاكرة التخزين المؤقت ، فيجب أن يكون هناك الكثير من أخطاء التخزين المؤقت لجهاز مثل هذه. ولكن لا ، هم أقل مرتين. ذلك لأن ذاكرة التخزين المؤقت تعمل بشكل أفضل: نحن نعمل مع الرمز بشكل تسلسلي ونستطيع سحب البيانات من ذاكرة التخزين المؤقت القديمة.المترجم يغير ترتيب الكود
عندما نقوم ببرمجة كود جهاز الحالة go to، لدينا أولاً الحالات التي سيتم استدعاؤها أولاً عند استلام البيانات: طريقة HTTP ، و URI ، ثم رؤوس HTTP. يبدو منطقيًا أنه سيتم تحميل الكود في ذاكرة التخزين المؤقت للمعالج بالتسلسل ، من الأعلى إلى الأسفل ، تمامًا أثناء استعراض البيانات. لكن هذا خطأ تماما. إذا نظرت إلى رمز المجمع ، سترى أشياء مذهلة. على اليسار هو ما نحن المبرمج: علينا أولا تحليل الأساليب
على اليسار هو ما نحن المبرمج: علينا أولا تحليل الأساليب GETو POSTثم أدناه في مكان ما حتى الآن طريقة المحتمل UNLOCK. لذلك ، نتوقع رؤية التحليل GETوفي بداية المجمع POST، ثم UNLOCK. لكن كل شيء هو عكس ذلك تمامًا: GETفي المنتصف POSTوفي النهاية وما UNLOCKفوق.هذا لأن المترجم لا يفهم كيف تأتي البيانات إلينا. يقوم بتوزيع الكود حسب صورته للكود الجميل. حتى يتمكن من ترتيب الكود بالترتيب الصحيح ، يجب علينا استخدام حاجز المترجم .حاجز المترجم عبارة عن دمية تجميع لن يتم من خلالها إعادة ترتيب المترجم. ببساطة عن طريق وضع مثل هذه الحواجز ، قمنا بتحسين الإنتاجية بنسبة 4٪ .STATE(sw_method) {
...
MATCH(NGX_HTTP_GET, "GET ");
MATCH(NGX_HTTP_POST, "POST");
__asm__ __volatile__("": : :"memory");
...
METH_MOVE(Req_MethU, 'N', Req_MethUn);
METH_MOVE(Req_MethUn, 'L', Req_MethUnl);
METH_MOVE(Req_MethUnl, 'O', Req_MethUnlo);
METH_MOVE(Req_MethUnlo, 'C', Req_MethUnloc);
METH_MOVE_finish(Req_MethUnloc, 'K', NGX_HTTP_UNLOCK)
اكتب الرمز بطريقتك الخاصة
نظرًا لأن المترجم لا يقوم بترتيب البيانات كما نريد ، فسوف نقوم بالتحسين الموجه لملف التعريف (التحسين تحت سيطرة المحلل). التحسين الموجّه للملف الشخصي (PGO) هو إجمالي عدد العينات ، وليس سلسلة من المكالمات. على سبيل المثال ، يتلقى معرّف الموارد المنتظم (URI) عينات أكثر من تحليل الطريقة ، لذلك سيضع رمز معالجة معرّف الموارد المنتظم قبل معالجة الطريقة.كيف تعمل؟ سنقوم بكتابة الكود ، وتشغيل المعايير عليه ، وإعطاء نتيجة التنميط للمترجم ، وسوف يولد الكود الأمثل لأحمالنا. لكن المشكلة تكمن في أنها تقوم ببساطة بتجميع الأجزاء الأكثر سخونة من التعليمات البرمجية ، ولكنها لا تتبع تبعية الوقت. إذا كان أكبر URI في التحميل ، فسيكون هذا هو المكان الأكثر سخونة. سيرتفع URI إلى أعلى الوظيفة ، ولن يظهر PGO أن اسم الطريقة موجود دائمًا قبل URI. وفقا لذلك ، لا يعمل PGO.Req_Method: {
if (likely(PI(p) == CHAR4_INT('G', 'E', 'T', ' '))) {
...
goto Req_Uri;
}
if (likely(PI(p) == CHAR4_INT('P', 'O', 'S', 'T'))) {
...
goto Req_UriSpace;
}
goto Req_Meth_SlowPath;
}
...
Req_Uri:
...
Req_Meth_SlowPath:
...
ماذا يعمل؟likely/ unlikely وحدات الماكرو (لرمز kernel Linux ، تتوفر الجوهر الخليجي في مساحة المستخدم __builtin_expect()). يقولون أي رمز لوضع أقرب. على سبيل المثال ، تشير التقارير المحتملة إلى أن هيئة الطلب يجب أن تكون متأخرة مباشرة if. ثم الجلب المسبق للرمز (الجلب المسبق للمعالج) سيحدد هذا الرمز وكل شيء سيكون سريعًا. تظهر الصورة بداية طريقة التحليل والنهاية والحاجز. لم نتوقع رؤية الرمز خلف الحاجز. يبدو أن هذا لا ينبغي أن يكون - لقد وضعنا حاجزًا.لكن ماذا يحدث في الواقع؟ يرى المترجم
تظهر الصورة بداية طريقة التحليل والنهاية والحاجز. لم نتوقع رؤية الرمز خلف الحاجز. يبدو أن هذا لا ينبغي أن يكون - لقد وضعنا حاجزًا.لكن ماذا يحدث في الواقع؟ يرى المترجم likelyالشرط - من المرجح أن ندخل نص الشرط وهناك سننتقل إلى قفزة غير مشروطة إلى الملصقReq_Uri. اتضح أن الكود الموجود بعد حالتنا لا يتم معالجته في "المسار الساخن". يقوم المترجم بنقل الكود تحت الملصق if، على الرغم من الحاجز ، لأنه تم استيفاء شرط الكود الساخن.لهذا لم يكن، دول مجلس التعاون الخليجي له ملحق: سمات hotو coldللتسميات. يقولون أي ملصق ساخن (على الأرجح) وأيهما بارد (أقل احتمالًا). هنا نتفق على ما هو
هنا نتفق على ما هو GETأكثر احتمالا POSTونتركه له likely. تحت هذه الحالة ، ترتفع معالجة URI ، POSTوتذهب أدناه. تبقى جميع الرموز الأخرى للجهاز الأقل احتمالًا أدناه لأن الملصق بارد.غامض -O3
دعونا ننظر إلى تحسين المترجم. أول شيء يتبادر إلى الذهن هو عدم استخدام O2 ، ولكن O3 - يجب أن يكون أسرع. لكن الأمر ليس كذلك - في بعض الأحيان يولد O3 رمزًا أسوأ. O3 عبارة عن مجموعة من بعض التحسينات . إذا أضفناها إلى O2 بشكل منفصل ، نحصل على خيارات مختلفة: بعض التحسينات تساعد ، وبعض التدخل. بالنسبة إلى رمزنا المحدد ، نختار فقط التحسينات التي تنشئ الشفرة بشكل أفضل. نترك أفضل نتيجة - هنا 1،820 ثانية بالنسبة لـ 1،838 و 1،858.يتم تمييز بعض الخيارات باللون الأخضر - وهذا هو التصور التلقائي.
O3 عبارة عن مجموعة من بعض التحسينات . إذا أضفناها إلى O2 بشكل منفصل ، نحصل على خيارات مختلفة: بعض التحسينات تساعد ، وبعض التدخل. بالنسبة إلى رمزنا المحدد ، نختار فقط التحسينات التي تنشئ الشفرة بشكل أفضل. نترك أفضل نتيجة - هنا 1،820 ثانية بالنسبة لـ 1،838 و 1،858.يتم تمييز بعض الخيارات باللون الأخضر - وهذا هو التصور التلقائي.التطبيب الذاتي
مثال على دورة من دليل دول مجلس التعاون الخليجي .int a[256], b[256], c[256];
void foo () {
for (int i = 0; i < 256; i++)
a[i] = b[i] + c[i];
}
إذا كان لدينا صفيف متغير يتكرر ، يمكننا تحسين الدورة - تتحلل إلى متجهات. بشكل افتراضي ، يتم تمكين التخصيص التلقائي عند المستوى الثالث من التحسين -O3 : يقوم GCC بإنشاء رمز متجه حيث يمكنه. ولكن لا يمكن توجيه جميع التعليمات البرمجية تلقائيًا (حتى لو كانت متجهة من حيث المبدأ).يمكننا تمكين خيار دول مجلس التعاون الخليجي -fopt-info-vec-all، والذي يوضح ما تم نقله وما هو ليس كذلك. نحصل على أنه بالنسبة لمعيارنا لا يوجد شيء متجه ، ولكن لا يزال الرمز يسوء. لذلك ، لا يعمل ناقل البيانات دائمًا: في بعض الأحيان يبطئ الرمز. ولكن يمكننا دائمًا رؤية ما تم نقله وما لا يتم إيقافه ، وإيقاف تشغيل التحويل ، إذا لزم الأمر.المحاذاة: كيفية مقارنة السلاسل مع GET؟
نقوم باختراق صغير ، كما هو الحال في nginx: نحن لا نقوم بتحليل الخطوط بالبايت ، ولكننا نحسب intونقارن الخطوط معهم.#define CHAR4_INT(a, b, c, d) ((d << 24) | (c << 16) | (b << 8) | a)
if (p == CHAR4_INT('G', 'E', 'T', ' ')))
نحن نعلم أنه إذا intلم يتم محاذاة ، فإنه يتباطأ 2-3 مرات. كتبنا معيارًا صغيرًا يثبت ذلك.$ ./int_align
Unaligned access = 6.20482
Aligned access = 2.87012
Read four bytes = 2.45249
ثم حاول المحاذاة int. سننظر إذا تمت intمحاذاة العنوان int، فسنقارنه بالبايت إن لم يكن. (((long)(p) & 3)
? ((unsigned int)((p)[0]) | ((unsigned int)((p)[1]) << 8)
| ((unsigned int)((p)[2]) << 16) | ((unsigned int)((p)[3]) << 24))
: *(unsigned int *)(p));
ولكن اتضح أن هذا النهج يعمل بشكل أسوأ:full request line: no difference
method only: unaligned - 214ms
aligned - 231ms
bytes - 216ms
باختصار: هناك فرق بين الرمز القياسي المعزول وغير القابل للتحسين ورمز المحلل اللغوي المضمن ، والذي يفقد التحسين بسبب الكمية الكبيرة من التعليمات البرمجية. لم يكن هناك عقوبة في التنميط.ملاحظة: يمكن قراءة مناقشة تفصيلية حول سبب حدوث ذلك في مهمتنا على GitHub .لماذا تعتبر سلاسل HTTP مهمة بالنسبة لنا؟
على سبيل المثال ، يعد هذا عنوان URI عادي: إذا كنت صعب الإرضاء بما فيه الكفاية حول الفندق ، فانتقل إلى الحجز وقم بتعيين بعض الفلاتر ، واحصل على URI بأكثر من كيلوبايت.إنجن إكس لديه آلة توزيع واسعة النطاق إلى حد ما على
إذا كنت صعب الإرضاء بما فيه الكفاية حول الفندق ، فانتقل إلى الحجز وقم بتعيين بعض الفلاتر ، واحصل على URI بأكثر من كيلوبايت.إنجن إكس لديه آلة توزيع واسعة النطاق إلى حد ما على switch/ case. لا يعمل بسرعة كبيرة. بالإضافة إلى ذلك ، في حالة Tempesta FW ، لا نحتاج إلى تحليل URI فحسب ، بل أيضًا فحصه للحقن.case sw_check_uri:
if (usual[ch >> 5] & (1U << (ch & 0x1f)))
break;
switch (ch) {
case '/':
r->uri_ext = NULL;
state = sw_after_slash_in_uri;
break;
case '.':
r->uri_ext = p + 1;
break;
case ' ':
r->uri_end = p;
state = sw_check_uri_http_09;
break;
case CR:
r->uri_end = p;
r->http_minor = 9;
state = sw_almost_done;
break;
case LF:
r->uri_end = p;
r->http_minor = 9;
goto done;
case '%':
r->quoted_uri = 1;
...
URI آخر: /redir_lang.jsp؟lang=foobar٪0d٪0aContent-Length:٪200٪0d٪0a٪ 0d٪ 0aHTTP / 1.1٪ 20200٪ 20OK٪ 0d٪ 0aContent-Type:٪ 20text /html٪ 0d٪ 0aContent -الطول:٪ 2019٪ 0d٪ 0a٪ 0d٪ 0aShazam </html>.يبدو أن الأول ، ولكن لديه حقنة. سيكون عليك أن تحفر بعمق كافٍ لفهم ذلك.دعنا نجري اختبارًا : خذ URI الأول ، اطعم wrk ، اضبطه على nginx وشاهد أن تحليل nginx يصبح ساخنًا جدًا. إذا كان من الواضح في استعلام الفهرس العادي السابق أن المحلل اللغوي موجود بالفعل في الجزء العلوي ، فإنه هنا يصبح أكثر سخونة.
إذا كان من الواضح في استعلام الفهرس العادي السابق أن المحلل اللغوي موجود بالفعل في الجزء العلوي ، فإنه هنا يصبح أكثر سخونة.8.62% nginx [.] ngx_http_parse_request_line
2.52% nginx [.] ngx_http_parse_header_line
1.42% nginx [.] ngx_palloc
0.90% [kernel] [k] copy_user_enhanced_fast_string
0.85% nginx [.] ngx_strstrn
0.78% libc-2.24.so [.] _int_malloc
0.69% nginx [.] ngx_hash_find
0.66% [kernel] [k] tcp_recvmsg
ما المميز في سلاسل HTTP؟ هناك فواصل مختلفة ' : 'و ' , '، وحتى نهاية السطور، التي يمكن أن تكون إما مزدوجة البايت \r\nأو بايت واحد \n، والتي نوقشت في البداية. لا يوجد إنهاء 0 لخطوط C - لأسباب أمنية نريد أن نتحقق بدقة أكبر مما يأتي إلينا. لدينا وظيفتان قياسيتان تساعدان في المحلل اللغوي.strspn: يتحقق من الأبجدية ، والأحرف المتاحة في سلسلة ، ويجمع ديناميكيًا أبجدية صالحة ، على الرغم من أنه معروف في مرحلة تجميع البرنامج.strcasecmp(). ليست هناك حاجة إلى حالة تحويل مقارنة xمع Foo:. في معظم الحالات strcasecmp()، يُطلب فقط الامتثال / عدم الامتثال ، ولا تحتاج إلى معرفة الموضع في السطر.
يعملون ببطء. دعونا نرى المعايير ونفهم ما هو الخطأ فيها.محللات سريعة
هناك العديد من المحللين.إن Nginx هو أبسط محلل ومحلل. وهو يتحقق بدقة من توافق RFC. هناك أيضًا محللات PicoHTTPParser (H2O) و Cloudflare. يعالجون البيانات بشكل أسرع ، لكنهم قد يتخطون الأحرف التي لا يسمح بها RFC.PCMESTRI. يستخدم المحللون عدة طرق مختلفة. الأول هو تعليمة PCMESTRI المستخدمة في محلل Pico.نضع نطاقات في التعليمات. للأسف ، يمكننا تحميل 16 حرفًا أو 8 نطاقات. إذا كان النطاق يتكون من حرف واحد فقط - كرر فقط. بسبب هذا القيد ، لا يستطيع المحلل اللغوي Pico التحقق بشكل كامل من توافق RFC ، لأن RFC لديه أكثر من 8 نطاقات في هذا الموقع. نقوم بتحميل الأبجدية في السجل ، وتحميل السلسلة وتنفيذ التعليمات. عند الخروج ، نرى بسرعة ما إذا كانت هناك مصادفة أم لا.AVX2 - منهج CloudFlare. المحلل CloudFlare ، باستخدام AVX2 ، يعالج 32 بايت من سلسلة في وقت واحد ، بدلاً من 16 بايت مع محلل Pico. التحليل أفضل في CloudFlare لأنه تم نقله إلى AVX2.
نقوم بتحميل الأبجدية في السجل ، وتحميل السلسلة وتنفيذ التعليمات. عند الخروج ، نرى بسرعة ما إذا كانت هناك مصادفة أم لا.AVX2 - منهج CloudFlare. المحلل CloudFlare ، باستخدام AVX2 ، يعالج 32 بايت من سلسلة في وقت واحد ، بدلاً من 16 بايت مع محلل Pico. التحليل أفضل في CloudFlare لأنه تم نقله إلى AVX2. نتحقق من جميع الأحرف في مسافة في جدول ASCII ، وجميع الأحرف أكبر من 128 ونأخذ النطاق بينها. كود بسيط سريع.قارن بين PCMESTRI و AVX2. بالنسبة لنا ، الحد الحالي هو 1500. هذا هو الحد الأقصى لحجم الحزمة التي تأتي إلينا. نرى أن كود AVX2 على البيانات الضخمة أسرع بكثير من محلل Pico. لكنه يعمل بشكل أبطأ على البيانات الصغيرة ، لأن التعليمات أثقل في AVX2.
نتحقق من جميع الأحرف في مسافة في جدول ASCII ، وجميع الأحرف أكبر من 128 ونأخذ النطاق بينها. كود بسيط سريع.قارن بين PCMESTRI و AVX2. بالنسبة لنا ، الحد الحالي هو 1500. هذا هو الحد الأقصى لحجم الحزمة التي تأتي إلينا. نرى أن كود AVX2 على البيانات الضخمة أسرع بكثير من محلل Pico. لكنه يعمل بشكل أبطأ على البيانات الصغيرة ، لأن التعليمات أثقل في AVX2. قابلة للمقارنة
قابلة للمقارنةstrspn. إذا قررنا الاستخدام strspn، فإن الأمور تزداد سوءًا ، خاصة على البيانات الضخمة. في المحلل "القتالية" لا يمكن استخدامها strspn.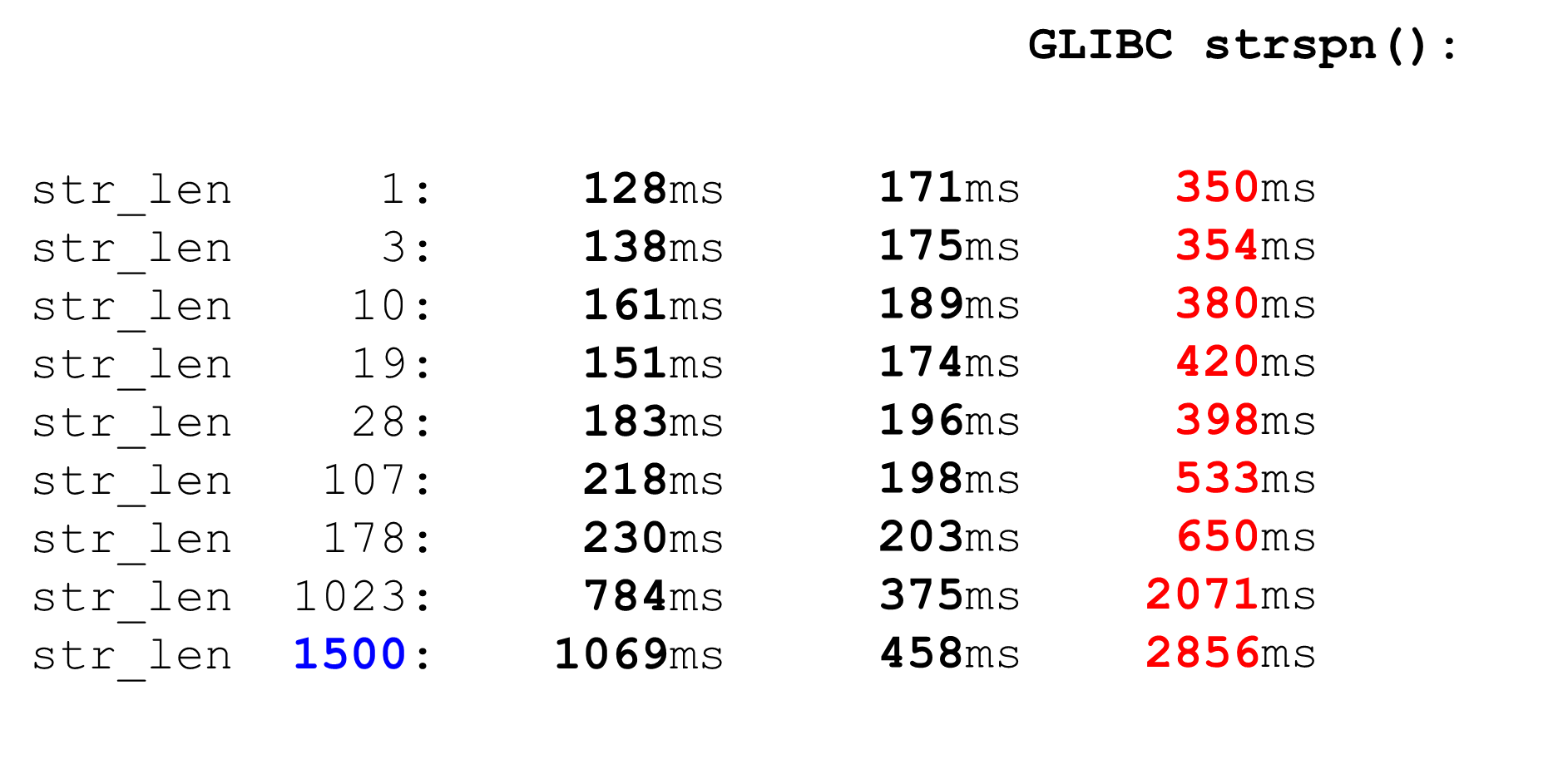
مُطابق Tempesta أسرع وأكثر دقة
محلل السرعة لدينا هو مثل هذين. على البيانات الصغيرة ، إنه سريع مثل محلل Pico ، على CloudFlare الشبيه. ومع ذلك ، فإنه لا يتخطى الأحرف غير الصالحة. كيف يتم ترتيب المحلل؟ نحدد ، بصفتنا nginx ، صفيفًا من وحدات البايت ونتحقق من بيانات الإدخال بواسطتها - وهذا هو مقدمة الوظيفة. هنا نعمل فقط مع فترات قصيرة ، نستخدمه
كيف يتم ترتيب المحلل؟ نحدد ، بصفتنا nginx ، صفيفًا من وحدات البايت ونتحقق من بيانات الإدخال بواسطتها - وهذا هو مقدمة الوظيفة. هنا نعمل فقط مع فترات قصيرة ، نستخدمه likelyلأن سوء تقدير الفروع يكون أكثر إيلامًا للخطوط القصيرة منه للخطوط الطويلة. نحن نأخذ هذا الكود. لدينا حد 4 بسبب السطر الأخير - يجب أن نكتب شرطًا قويًا إلى حد ما. إذا قمنا بمعالجة أكثر من 4 بايت ، فسيكون الشرط أكثر صعوبة والرمز أبطأ.static const unsigned char uri_a[] __attribute__((aligned(64))) = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
if (likely(len <= 4)) {
switch (len) {
case 0:
return 0;
case 4:
c3 = uri_a[s[3]];
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
return (c0 & c1) == 0 ? c0 : 2 + (c2 ? c2 + c3 : 0);
}
حلقة رئيسية وذيل كبير. في دورة المعالجة الرئيسية ، نقسم البيانات: إذا كانت طويلة بما فيه الكفاية ، نقوم بمعالجة 128 أو 64 أو 32 أو 16 بايت لكل منها. من المنطقي معالجة 128 لكل منها: في موازاة ذلك ، نستخدم العديد من قنوات المعالج (العديد من خطوط الأنابيب) والمعالج الفائق.for ( ; unlikely(s + 128 <= end); s += 128) {
n = match_symbols_mask128_c(__C.URI_BM, s);
if (n < 128)
return s - (unsigned char *)str + n;
}
if (unlikely(s + 64 <= end)) {
n = match_symbols_mask64_c(__C.URI_BM, s);
if (n < 64)
return s - (unsigned char *)str + n;
s += 64;
}
if (unlikely(s + 32 <= end)) {
n = match_symbols_mask32_c(__C.URI_BM, s);
if (n < 32)
return s - (unsigned char *)str + n;
s += 32;
}
if (unlikely(s + 16 <= end)) {
n = match_symbols_mask16_c(__C.URI_BM128, s);
if (n < 16)
return s - (unsigned char *)str + n;
s += 16;
}
ذيل. تشبه نهاية الوظيفة البداية. إذا كان لدينا أقل من 16 بايت ، فإننا نعالج 4 بايت في حلقة ، ثم لا يزيد عن 3 بايت في النهاية.while (s + 4 <= end) {
c0 = uri_a[s[0]];
c1 = uri_a[s[1]];
c2 = uri_a[s[2]];
c3 = uri_a[s[3]];
if (!(c0 & c1 & c2 & c3)) {
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + (c2 ? c2 + c3 : 0);
}
s += 4;
}
c0 = c1 = c2 = 0;
switch (end - s) {
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + c2;
نقوم بتحميل أقنعة وبيانات البت - هذه هي الخوارزمية الرئيسية للهيكل الرئيسي للوظيفة. نقدم جدول ASCII (كما في الصورة) مع 16 صفًا و 8 أعمدة. أولاً ، نقوم بتشفير صفوف الجدول في السجل الأول لـ BM URI: الصف الأول والثاني.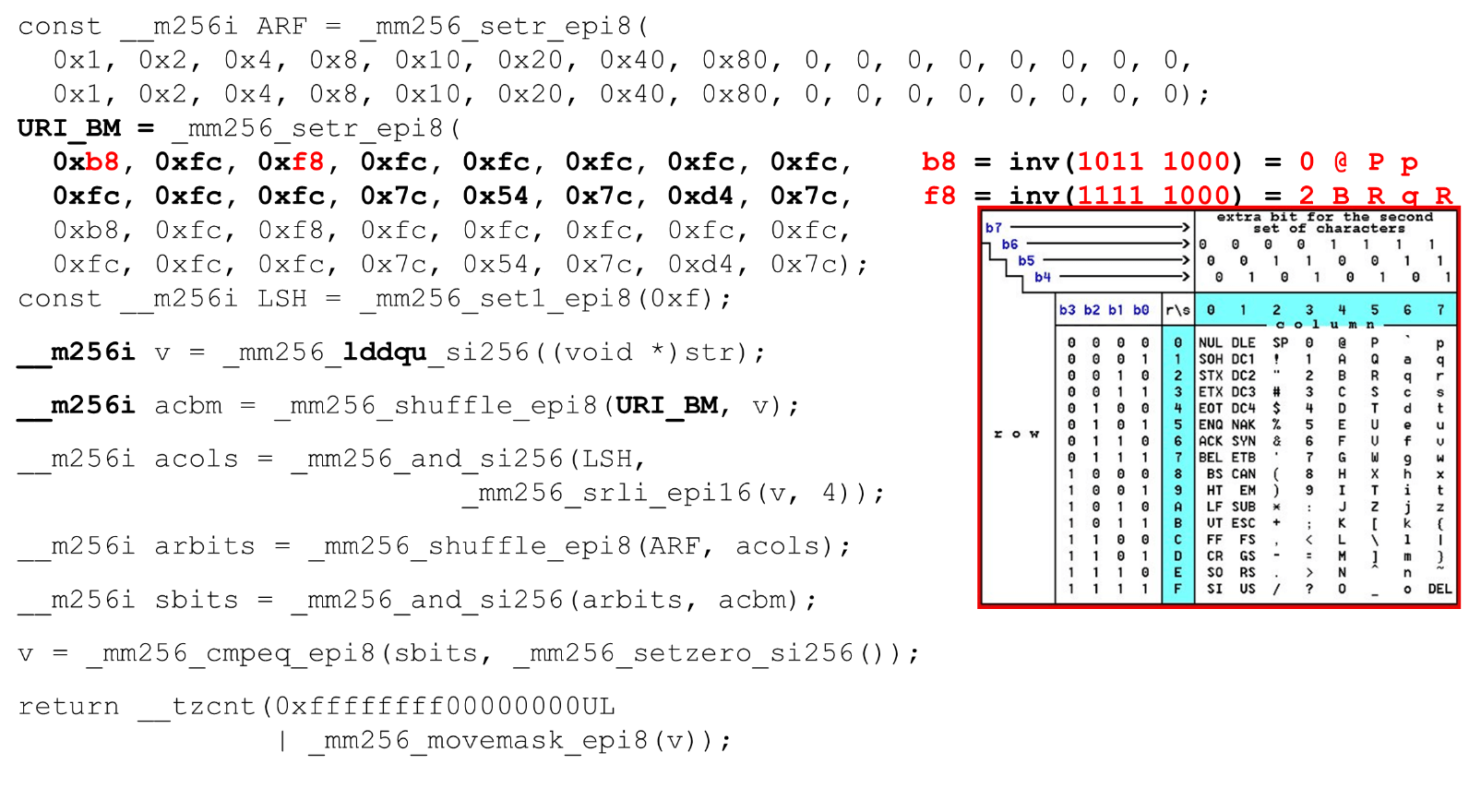 الرموز الفعلية التي نسمح بها هي
الرموز الفعلية التي نسمح بها هي 0 @ P pو 2 B R q R. يتم ترميز على النحو التالي: b8 = inv(1011 1000) = 0 @ P p، f8 = inv(1111 1000) = 2 B R q R.نقوم بالترميز بالترتيب العكسي: نبدأ عند 0 ، ولا يُسمح بشخصية الخدمة الأولى ، ثم الوحدات هي المسموح بها.تعيين أقنعة بت ASCII. على سبيل المثال ، يأتي السطر "pr": الحرف الأول من السطر الأول هو ASCII ، والثاني من السطر الثاني. نقوم بتشغيل عبارة تبديل عشوائي ، والتي تقوم بخلط صفوف الجدول المشفرة وفقًا لترتيب هذه الأحرف في الإدخال. معرّف العمود للإدخال. بعد ذلك ، نضع أعمدة جدول ASCII في سجل مختلف. ثم "نعبر" سجلات الأعمدة والصفوف ، ونحصل على مراسلات: شخصيتنا أم لا.نظرًا لأن الأعمدة هي أهم 4 بت من البايت ، فإننا ننتقل إلى اليسار. يحتوي AVX على إزاحة 2 بايت فقط ، لذا قم أولاً بتحويل البايت ، ثم n مع القناع الخاص بنا للحصول على وحدات البت الهامة فقط.
معرّف العمود للإدخال. بعد ذلك ، نضع أعمدة جدول ASCII في سجل مختلف. ثم "نعبر" سجلات الأعمدة والصفوف ، ونحصل على مراسلات: شخصيتنا أم لا.نظرًا لأن الأعمدة هي أهم 4 بت من البايت ، فإننا ننتقل إلى اليسار. يحتوي AVX على إزاحة 2 بايت فقط ، لذا قم أولاً بتحويل البايت ، ثم n مع القناع الخاص بنا للحصول على وحدات البت الهامة فقط. ترتيب أعمدة ASCII قم بتشغيل الترتيب العشوائي الثاني ، انقل العمود إلى المواضع المطلوبة. في كلتا الحالتين ، البايت المدخل من العمود الأخير ، لذلك في الموضع الأول والثاني نحصل على نفس العمود.
ترتيب أعمدة ASCII قم بتشغيل الترتيب العشوائي الثاني ، انقل العمود إلى المواضع المطلوبة. في كلتا الحالتين ، البايت المدخل من العمود الأخير ، لذلك في الموضع الأول والثاني نحصل على نفس العمود.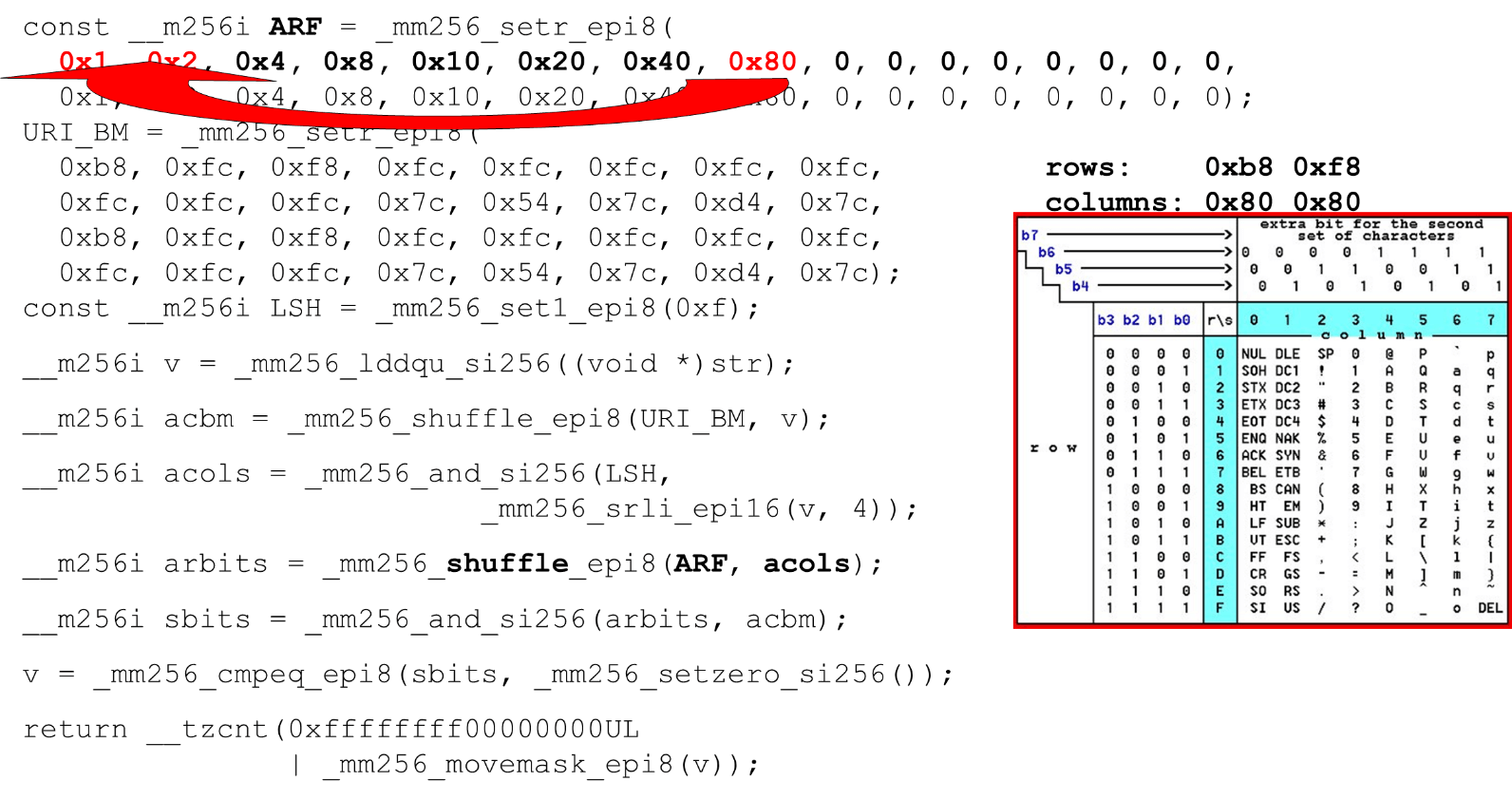 تقاطع الأعمدة وصفوف الأقنعة . نقوم
تقاطع الأعمدة وصفوف الأقنعة . نقوم and("بتقاطع" الأعمدة مع الأعمدة) ونحصل على أن بيانات الإدخال صالحة - النتيجةandمن تقاطع الأعمدة والصفوف ليس صفرًا. احسب عدد الأصفار في النهاية. نجمعها كلها من المتجه ونعيدها
احسب عدد الأصفار في النهاية. نجمعها كلها من المتجه ونعيدها intإلى المخرجات - بكل بساطة.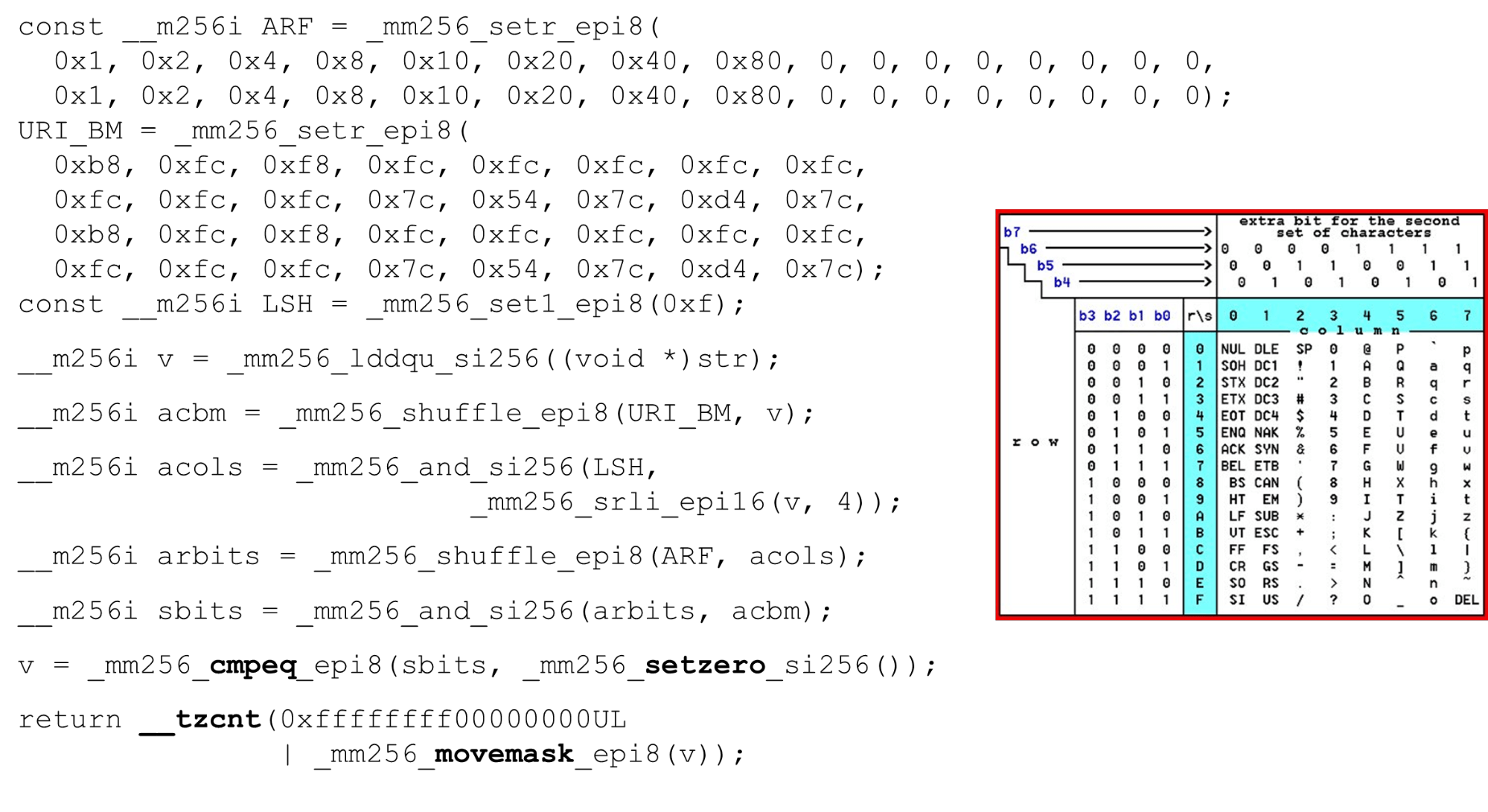 تخصيص الحروف الهجائية. من خلال العمل مع جدول ASCII ، نحصل على ميزة رخيصة: نستخدم جداول ثابتة ، ولكن لا شيء يمنع من سؤال المستخدم عن الأبجدية المتاحة لعناوين URL وأسماء وقيم الرؤوس المختلفة. يستخدم طلب HTTP URI والرأس 8 أحرف أبجدية (زائد أو ناقص) لتحليل طلب HTTP واحد. يمكن تحميل هذه الجداول في نفس الرمز ومقارنتها في أبجدية واحدة محددة من قبل المستخدم ، معرف URI صالح. إذا لم يكن الأمر كذلك ، فهو مختلف.
تخصيص الحروف الهجائية. من خلال العمل مع جدول ASCII ، نحصل على ميزة رخيصة: نستخدم جداول ثابتة ، ولكن لا شيء يمنع من سؤال المستخدم عن الأبجدية المتاحة لعناوين URL وأسماء وقيم الرؤوس المختلفة. يستخدم طلب HTTP URI والرأس 8 أحرف أبجدية (زائد أو ناقص) لتحليل طلب HTTP واحد. يمكن تحميل هذه الجداول في نفس الرمز ومقارنتها في أبجدية واحدة محددة من قبل المستخدم ، معرف URI صالح. إذا لم يكن الأمر كذلك ، فهو مختلف.الهجمات
بعض الحالات التي قد يكون فيها هذا مفيدًا.هجوم SSRF مع BlackHat'17 ("عصر جديد من SSRF"): http://foo@evil.com:80@google.com/- رمز علامة غير مرجح. في بعض التطبيقات يتم استخدامه ، في البعض الآخر لا. ولكن إذا كنت لا تستخدمه ، فيمكنك استبعاده من الأبجدية الصالحة وسيتم حظر الهجوم.RCE الهجوم: «الفعلي هو إجراء هجمات حقن أمر مثل»، BSides'16: User-Agent: ...;echo NAELBD$((26+58))$echo(echo NAELBD)NAELBD.... يعد User-Agent رأسًا ثابتًا ، ولكن هناك حالات هجوم RCE عندما يأتي البعض shellبشخصيات غير نمطية لـ User-Agent. نحن نحمي أنفسنا باستثناء علامة الدولار.الكتابة فوق المسار النسبي . الحالة الأخيرة هي ما كان لدى Google في عام 2016. جاءت الأقواس المتعرجة ، النقطتين ، إلى URI .../gallery?q=%0a{}*{background:red}/..//apis/howto_guide.html. هذه أحرف غير محتملة يمكن استبعادها من الأبجدية.strcasecmp ()
هذا رمز تافه إلى حد ما. قارنا أيضًا سلاسل من 32 بايت ، صفين لكل منهما.__m256i CASE = _mm256_set1_epi8(0x20);
__m256i A = _mm256_set1_epi8('A' – 0x80);
__m256i D = _mm256_set1_epi8('Z' - 'A' + 1 – 0x80);
__m256i sub = _mm256_sub_epi8(str1, A);
__m256i cmp_r = _mm256_cmpgt_epi8(D, sub);
__m256i lc = _mm256_and_si256(cmp_r, CASE);
__m256i vl = _mm256_or_si256(str1, lc);
__m256i eq = _mm256_cmpeq_epi8(vl, str2);
return ~_mm256_movemask_epi8(eq);
نعطي التسجيل سطر واحد فقط ، لأنه في الثانية قمنا ببرمجة الثوابت في المحلل اللغوي لدينا في الحالة الصغيرة. نظرًا لأن لدينا مقارنات مهمة ، فإننا نطرح 128 من كل بايت (خدعة من Hacker's Delight).نقارن أيضًا نطاق حرف صالح: سواء كان بإمكاننا التسجيل في هذه السلسلة أم لا ، هل هو حرف أم لا. في وقت التحقق من ذلك ، بدلاً من مقارنتين من a إلى z ، يمكننا استخدام مقارنة واحدة فقط (خدعة من Hacker's Delight) والانتقال إلى ثابت.strcasecmp الأداء ()
Tempesta أسرع بكثير من GLIBC ، حتى الإصدار الجديد (18 أو 19). strcasecmp()يستخدم الرمز أيضًا AVX ، ولكن ليس الإصدار الثاني. AVX2 أسرع ، لذلك Tempesta لديه رمز أسرع.
نواة لينكس FPU
نستخدم ملحقات معالج المتجه - وهي متوفرة في النواة. تتم معالجة تعليمات المتجه بواسطة وحدة معالج FPU. هذه ليست وحدة المعالج الرئيسية ، وليست السجلات الرئيسية ، ولكنها كبيرة جدًا.لذلك ، هناك تحسين في Linux. إذا انتقلنا من النواة إلى مساحة المستخدم والعودة ، فلن نحفظ سياق سجلات FPU (XMM ، YMM ، ZMM): نغير سياق سجلات وحدة المعالج الرئيسية فقط. من المفترض أن نواة نظام التشغيل لا تعمل مع الامتداد المتجه للمعالج. ولكن إذا كنت في حاجة إليها، على سبيل المثال، يمكن تشفير يفعل ذلك، ولكن الحاجة إلى استخدام fpu_beginو fpu_endلحفظ واستعادة سياق السجل FPU:__kernel_fpu_begin_bh();
memcpy_avx(dst, src, n);
__kernel_fpu_end_bh();
هذه وحدات ماكرو أصلية تقوم بحفظ واستعادة حالة وحدة المعالج ، وهي المسؤولة عن تسجيلات المتجهات. هذه موارد بطيئة إلى حد ما.AVX و SSE
قبل معايير حفظ سياق FPU واستعادته ، هناك بضع كلمات حول عمليات ناقلات الأمراض. لماذا يكون من المنطقي في بعض الأحيان العمل مع المجمع؟ في بعض الأحيان ، يُنشئ GCC رمزًا دون المستوى الأمثل. المشكلة هي أنه في طرازات المعالجات القديمة ، هناك عقوبة كبيرة من الانتقال من SSE إلى AVX. يحتوي دول مجلس التعاون الخليجي على مفتاح جديد vzeroupper- استخدمه حتى لا يولد هذه التعليمات vzeroupper، مما يمسح السجلات ويزيل هذه العقوبة.لا تحتاج إلى استخدام هذه التعليمات إلا إذا كنت تعمل مع رمز قديم تم تجميعه لـ SSE من قبل طرف ثالث. هذه ليست قضيتنا ويمكننا التخلص من هذه التعليمات بأمان.FPU
لدينا ناقل تلقائي في المعالج. هذا يعني أنه في أي رمز مساحة مستخدم ستكون هناك عمليات متجه. تستخدم أي عمليتين في النظام ملحقات معالج المتجه. عندما تنتقل العملية إلى النواة والعودة ، لا تضيع وقتك في توفير واستعادة حالة ناقل المعالج. ولكن إذا قمت بالتبديل من مساحة مستخدم إلى أخرى (تبديل السياق) ، فبالإضافة إلى حقيقة أن ذاكرة التخزين المؤقت من المستوى الأول معطلة هناك ، فإن وحدة تبديل السياق في FPU تبدأ / تنتهي أيضًا بشكل سيئ. العملية مكلفة للغاية - علامة قياس مصغرة.في المقاييس الدقيقة ، كل شيء دائمًا ما يكون مثيرًا ، لكن العملية مكلفة للغاية. لذلك ، في مساحة المستخدم ، قم بتبديل السياق لفترة طويلة. في النواة ، ليس لدينا تبديل السياق ، لذلك كل شيء سريع. نقوم بحفظ واستعادة معالج المتجه مرة واحدة فقط لمجموعة كبيرة بما فيه الكفاية من الحزم.
تستخدم أي عمليتين في النظام ملحقات معالج المتجه. عندما تنتقل العملية إلى النواة والعودة ، لا تضيع وقتك في توفير واستعادة حالة ناقل المعالج. ولكن إذا قمت بالتبديل من مساحة مستخدم إلى أخرى (تبديل السياق) ، فبالإضافة إلى حقيقة أن ذاكرة التخزين المؤقت من المستوى الأول معطلة هناك ، فإن وحدة تبديل السياق في FPU تبدأ / تنتهي أيضًا بشكل سيئ. العملية مكلفة للغاية - علامة قياس مصغرة.في المقاييس الدقيقة ، كل شيء دائمًا ما يكون مثيرًا ، لكن العملية مكلفة للغاية. لذلك ، في مساحة المستخدم ، قم بتبديل السياق لفترة طويلة. في النواة ، ليس لدينا تبديل السياق ، لذلك كل شيء سريع. نقوم بحفظ واستعادة معالج المتجه مرة واحدة فقط لمجموعة كبيرة بما فيه الكفاية من الحزم.إنتبوكاليبس
في البداية ، عرضت خيار جدول بحث لتحسين رمز التبديل: عملية طويلة ، تعداد ، تجميع جدول التبديل في صفيف واتبع الإشارة المزدوجة للمؤشر الذي يقفز فوق هذا الصفيف. هذا سيناريو لهجوم شبح يستغل تنفيذ المضاربة.لدى Google مقال جيد حول كيفية ترتيب عملية إعادة الإشارة المزدوجة للمؤشرات في المجمعات الحديثة في الوقت الحالي (منذ بداية 2018). لا يعمل بشكل جيد للغاية. إذا تم تخزين بعض العناوين سابقًا في السجل وذهبنا إلى هذا العنوان ، فلدينا الآن رمز مختلف.jmp *%r11
call l1
l0: pause
lfence
jmp l0
l1: mov %r11, (%rsp)
ret
كيف يعمل؟ نقوم "باستدعاء" الوظيفة على l1 ، وتذهب العملية إلى هذا التصنيف ونقوم باختراق: كما لو أننا نعود من وظيفة (وهي ليست كذلك) ، لكننا نعيد كتابة عنوان الإرجاع. عندما نقوم بالتعليمات call، نضع عنوان الإرجاع ، والعنوان الحالي على المكدس ، ونعيد كتابته بالمحتويات الضرورية للتسجيل وننتقل إلى l1. لكن المعالج ، عندما يعمل الجالب المسبق ، يرى أن هناك وظيفة ، ثم حاجزًا. وفقًا لذلك ، سيكون كل شيء بطيئًا - فهو يرمي الجلب المسبق ونتخلص من ضعف Spectre. الرمز بطيء ، ينخفض الأداء بنسبة 15٪.الهجوم التالي نسبيًا هو Meltdown.. وهي مخصصة لعمليات مساحة المستخدم فقط. من المؤلم جدًا قراءة ذاكرة kernel من مساحة المستخدم. يتم منع الهجوم من خلال Kernel Pate Table Isolation (KPTI) ، والذي يتم تجميعه في نواة جديدة بشكل افتراضي. لكن KPTI باهظ الثمن للغاية ، يصل إلى تدهور أداء 30-40٪ ( كما يقاس بواسطة MariaDB ).ويرجع ذلك إلى حقيقة أنه لم يعد لديك تحسين TLB كسول: يتم فصل مساحة عنوان kernel والمعالج تمامًا في جداول صفحات مختلفة (قبل ذلك ، ظل TLB الكسول يرسم مساحة kernel إلى جدول الصفحات لكل عملية). هذا مؤلم لمساحة المستخدم ، ولكن ليس لـ Tempesta FW ، الذي يعمل تمامًا في النواة.بعض الروابط المفيدة:Saint HighLoad++ . , 6 -- ( , Saint HighLoad++) , web .
PHP Russia: 13 , . — KnowledgeConf, ++ TechLead Conf — . , , .