مئات وآلاف ، وفي بعض الخدمات ، ملايين الطوابير ، التي تمر من خلالها كمية كبيرة من البيانات ، تدور تحت غطاء منتجنا. كل هذا يجب معالجته بطريقة سحرية وعدم إطلاق النار عليه. في هذا المنشور ، سأخبرك عن الأساليب المعمارية التي نستخدمها في المنزل ، ولدينا مجموعة تقنية متواضعة إلى حد ما ، وليس لدينا مركز بيانات صغير في "مخزننا".
ما الذي نملكه؟
لذلك ، من ناحية ، لدينا مجموعة تقنية معروفة: Nginx ، PHP ، PostgreSQL ، Redis. من ناحية أخرى ، تحدث عشرات الآلاف من الأحداث في نظامنا كل دقيقة ، ويمكن أن تصل في ذروة ذلك إلى مئات الآلاف من الأحداث. من أجل توضيح ما هي هذه الأحداث وكيف يجب أن نستجيب لها ، سأقوم باستعراض صغير للمنتج ، وبعد ذلك سأخبرك كيف طورنا نظام التشغيل الآلي القائم على الأحداث.ManyChat هي منصة لأتمتة التسويق. يمكن لمالك صفحة Facebook توصيلها بنظامنا الأساسي وتكوين أتمتة التفاعل مع المشتركين (بعبارة أخرى ، إنشاء روبوت للدردشة). تتكون الأتمتة عادة من العديد من سلاسل التفاعلات التي قد لا تكون مترابطة. داخل سلاسل الأتمتة هذه ، يمكن أن تحدث إجراءات معينة مع المشترك ، على سبيل المثال ، تعيين علامة معينة في النظام ، أو تعيين / تغيير قيمة حقل في بطاقة المشترك. تسمح لك هذه البيانات أيضًا بتقسيم الجمهور وبناء تفاعل أكثر صلة مع المشتركين في الصفحة.أراد عملاؤنا فعلاً الأتمتة القائمة على الأحداث - القدرة على تخصيص تنفيذ الإجراء عندما يتم تشغيل حدث معين داخل المشترك (على سبيل المثال ، وضع العلامات).نظرًا لأن حدث المشغل يمكن أن يعمل من سلاسل الأتمتة المختلفة ، فمن المهم أن تكون هناك نقطة واحدة للتكوين لجميع الإجراءات المستندة إلى الأحداث على جانب العميل ، وعلى جانب المعالجة لدينا يجب أن يكون هناك ناقل واحد يعالج تغيير سياق المشترك من نقاط أتمتة مختلفة.في نظامنا ، هناك حافلة مشتركة تمر من خلالها جميع الأحداث التي تحدث مع المشتركين. هذا أكثر من 500 مليون حدث في اليوم. معالجتها دقيقة نوعًا ما - هذا سجل في مستودع البيانات ، بحيث يتمتع مالك الصفحة بفرصة مشاهدة كل ما حدث لمشتركيه تاريخياً.يبدو أنه من أجل تنفيذ نظام قائم على الأحداث ، لدينا بالفعل كل شيء ، ويكفي بالنسبة لنا دمج منطق أعمالنا في معالجة ناقل الحدث المشترك. لكن لدينا متطلبات معينة لنظامنا الجديد:- لا نريد الحصول على أداء متدهور في معالجة ناقل الحدث الرئيسي
- من المهم بالنسبة لنا الحفاظ على ترتيب معالجة الرسائل في النظام الجديد ، حيث قد يكون ذلك مرتبطًا بمنطق الأعمال الخاص بالعميل الذي يقوم بإعداد الأتمتة
- تجنب تأثير الجيران الصاخبين عندما تسد الصفحات النشطة التي بها عدد كبير من المشتركين قائمة الانتظار وتحظر معالجة أحداث الصفحات الصغيرة
إذا قمنا بدمج معالجة منطقنا في معالجة ناقل الحدث المشترك ، فسوف نحصل على تدهور خطير في الأداء ، حيث سيتعين علينا التحقق من كل حدث للتأكد من توافقه مع الأتمتة المكوَّنة. كجزء من إعداد الأتمتة ، يمكن تطبيق فلاتر معينة (على سبيل المثال ، بدء الأتمتة عندما يتم تشغيل حدث فقط للعملاء الإناث الأكبر من 30 عامًا). أي أنه عند معالجة الأحداث في الناقل الرئيسي ، ستتم معالجة كمية كبيرة من الطلبات الإضافية لقاعدة البيانات ، وسيبدأ أيضًا منطق ثقيل إلى حد ما في مقارنة السياق الحالي للمشترك بإعدادات الأتمتة. هذا الخيار لا يناسبنا ، لذلك ذهبنا إلى التفكير أكثر.
تنظيم سلسلة من الطوابير
نظرًا لأن منطق أعمالنا المرتبط بالنظام المستند إلى الأحداث يمكن فصله بشكل جيد جدًا عن منطق معالجة الأحداث من الناقل الرئيسي ، فإننا نقرر وضع أنواع الأحداث التي نحتاجها من الناقل المشترك في قائمة انتظار منفصلة لمزيد من المعالجة في دفق بيانات منفصل. وبالتالي ، فإننا نزيل المشكلة المرتبطة بتدهور الأداء في معالجة ناقل الحدث الرئيسي.في نفس المرحلة ، نقرر ما سيكون من الرائع نقل الأحداث إلى قائمة الانتظار المتتالية التالية لوضع هذه الأحداث في قوائم انتظار منفصلة لكل روبوت. وبالتالي ، فإن عزل نشاط كل بوت مع إطار دورها ، والذي يسمح لنا بحل المشكلة المرتبطة بتأثير الجيران الصاخبين.يبدو مخطط تدفق البيانات لدينا الآن كما يلي: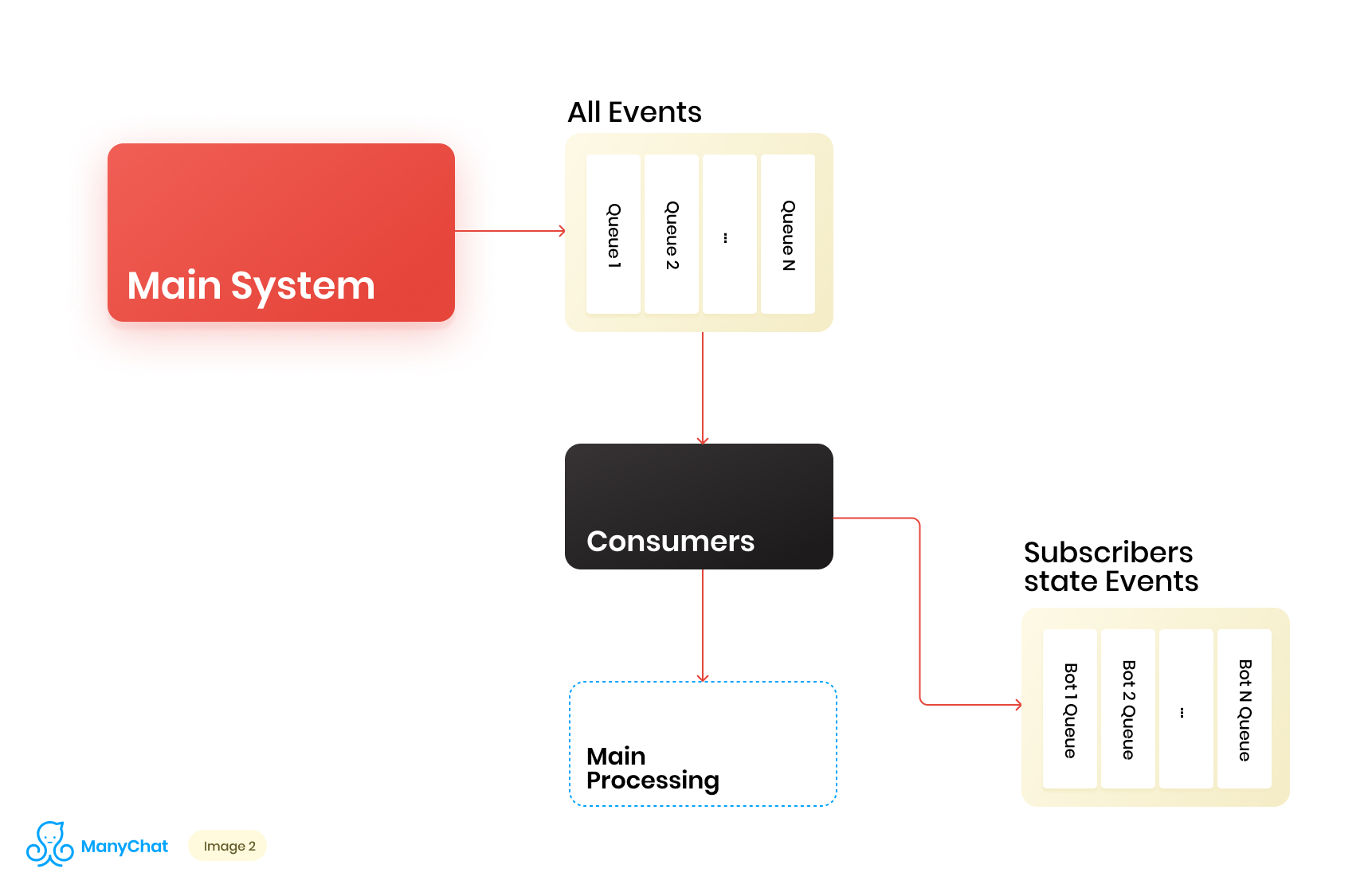 ومع ذلك ، لكي يعمل هذا المخطط ، نحتاج إلى حل مشكلة معالجة قوائم الانتظار الجديدة.هناك أكثر من مليون صفحة متصلة (روبوتات) على نظامنا الأساسي ، مما يعني أنه من المحتمل أن نحصل على حوالي مليون قائمة انتظار في مخططنا ، فقط على مستوى الطبقة القائمة على الحدث. من وجهة نظر فنية ، هذا ليس مخيفا بالنسبة لنا. بصفتنا خادم قائمة الانتظار ، نستخدم Redis مع أنواع البيانات القياسية الخاصة به ، مثل LIST و SORTED SET وغيرها. وهذا يعني أن كل قائمة انتظار هي بنية البيانات القياسية لـ Redis في ذاكرة الوصول العشوائي ، والتي يمكن إنشاؤها أو حذفها بسرعة ، مما يسمح لنا بتشغيل عدد كبير من قوائم الانتظار في نظامنا بسهولة ومرونة. سأتحدث بعمق أكثر عن استخدام Redis كخادم قائمة انتظار مع تفاصيل فنية في منشور منفصل ، ولكن الآن دعنا نعود إلى هندستنا.من الواضح أن لكل روبوت نشاطًا مختلفًا ، وأن احتمال الحصول على مليون طابور في حالة "الحاجة إلى المعالجة الآن" صغير للغاية. ولكن في وقت ما ، من الممكن أن يكون لدينا عشرات الآلاف من قوائم الانتظار النشطة التي تتطلب معالجة. عدد قوائم الانتظار هذه يتغير باستمرار. تتغير قوائم الانتظار نفسها أيضًا ، ويتم طرح بعضها تمامًا وحذفه ، ويتم إنشاء بعضها ديناميكيًا وملئه بأحداث للمعالجة. وبناءً على ذلك ، نحتاج إلى التوصل إلى طريقة فعالة للتعامل معها.
ومع ذلك ، لكي يعمل هذا المخطط ، نحتاج إلى حل مشكلة معالجة قوائم الانتظار الجديدة.هناك أكثر من مليون صفحة متصلة (روبوتات) على نظامنا الأساسي ، مما يعني أنه من المحتمل أن نحصل على حوالي مليون قائمة انتظار في مخططنا ، فقط على مستوى الطبقة القائمة على الحدث. من وجهة نظر فنية ، هذا ليس مخيفا بالنسبة لنا. بصفتنا خادم قائمة الانتظار ، نستخدم Redis مع أنواع البيانات القياسية الخاصة به ، مثل LIST و SORTED SET وغيرها. وهذا يعني أن كل قائمة انتظار هي بنية البيانات القياسية لـ Redis في ذاكرة الوصول العشوائي ، والتي يمكن إنشاؤها أو حذفها بسرعة ، مما يسمح لنا بتشغيل عدد كبير من قوائم الانتظار في نظامنا بسهولة ومرونة. سأتحدث بعمق أكثر عن استخدام Redis كخادم قائمة انتظار مع تفاصيل فنية في منشور منفصل ، ولكن الآن دعنا نعود إلى هندستنا.من الواضح أن لكل روبوت نشاطًا مختلفًا ، وأن احتمال الحصول على مليون طابور في حالة "الحاجة إلى المعالجة الآن" صغير للغاية. ولكن في وقت ما ، من الممكن أن يكون لدينا عشرات الآلاف من قوائم الانتظار النشطة التي تتطلب معالجة. عدد قوائم الانتظار هذه يتغير باستمرار. تتغير قوائم الانتظار نفسها أيضًا ، ويتم طرح بعضها تمامًا وحذفه ، ويتم إنشاء بعضها ديناميكيًا وملئه بأحداث للمعالجة. وبناءً على ذلك ، نحتاج إلى التوصل إلى طريقة فعالة للتعامل معها.معالجة مجموعة ضخمة من قوائم الانتظار
لذا لدينا مجموعة من الطوابير. في كل نقطة زمنية ، قد يكون هناك مبلغ عشوائي. من الشروط المهمة لمعالجة كل قائمة انتظار ، والتي تم ذكرها في بداية مشاركته ، أنه يجب معالجة الأحداث داخل كل صفحة بشكل متسلسل. وهذا يعني أنه في وقت ما ، لا يمكن معالجة كل قائمة انتظار من قبل أكثر من عامل لتجنب المشاكل التنافسية.ولكن جعل نسبة قوائم الانتظار إلى معالجات 1: 1 مهمة مشكوك فيها. عدد قوائم الانتظار يتغير باستمرار ، صعودا وهبوطا. عدد المعالجات قيد التشغيل ليس كذلك أيضًا ، على الأقل لدينا قيود من جانب نظام التشغيل والأجهزة ، ولا نريد أن يقف العمال في وضع الخمول في طوابير فارغة. لحل مشكلة التفاعل بين المعالجات وقوائم الانتظار ، قمنا بتطبيق نظام robin الدائري لمعالجة قائمة انتظارنا.وهنا جاء خط التحكم لمساعدتنا. عندما يتم إعادة توجيه الحدث من الناقل المشترك إلى قائمة الانتظار القائمة على الحدث لروبوت معين ، نضع أيضًا معرف قائمة انتظار الروبوت هذه في قائمة انتظار التحكم. يخزن قائمة انتظار التحكم فقط معرفات قوائم الانتظار الموجودة في التجمع والتي تحتاج إلى معالجتها. يتم تخزين القيم الفريدة فقط في قائمة انتظار التحكم ، أي أنه سيتم تخزين نفس معرف قائمة انتظار الروبوت في قائمة انتظار التحكم مرة واحدة فقط ، بغض النظر عن عدد مرات كتابتها هناك. على Redis ، يتم تنفيذ ذلك باستخدام بنية بيانات SORTED SET.علاوة على ذلك ، يمكننا تمييز عدد معين من العمال ، كل منهم سيحصل من قائمة انتظار التحكم على معرفه لقائمة انتظار البوت للمعالجة. وبالتالي ، سيقوم كل عامل بمعالجة القطعة بشكل مستقل من قائمة الانتظار المخصصة له ، بعد معالجة القطعة ، يعيد معرف قائمة الانتظار المعالجة إلى عنصر التحكم ، وبالتالي يعيدها إلى روبن مستدير. الشيء الرئيسي هو عدم نسيان تزويد الشيء كله بأقفال ، بحيث لا يستطيع عاملان معالجة نفس قائمة انتظار البوت بالتوازي. هذا الوضع ممكن إذا دخل مُعرِّف برنامج التتبُّع إلى قائمة انتظار التحكم عندما يكون العامل قيد المعالجة بالفعل. بالنسبة للأقفال ، نستخدم أيضًا Redis كمفتاح: مخزن القيمة مع TTL.عندما نأخذ مهمة بمعرف قائمة انتظار بوت من قائمة انتظار التحكم ، نضع قفل TTL على قائمة الانتظار المأخوذة ونبدأ في معالجتها. إذا أخذ المستهلك الآخر المهمة مع قائمة الانتظار التي تتم معالجتها بالفعل من قائمة انتظار التحكم ، فلن يتمكن من القفل ، وإعادة المهمة إلى قائمة انتظار التحكم وتلقي المهمة التالية. بعد معالجة المستهلك لقائمة انتظار الروبوت ، يزيل القفل ويذهب إلى قائمة انتظار التحكم للمهمة التالية.المخطط النهائي هو كما يلي:
عندما يتم إعادة توجيه الحدث من الناقل المشترك إلى قائمة الانتظار القائمة على الحدث لروبوت معين ، نضع أيضًا معرف قائمة انتظار الروبوت هذه في قائمة انتظار التحكم. يخزن قائمة انتظار التحكم فقط معرفات قوائم الانتظار الموجودة في التجمع والتي تحتاج إلى معالجتها. يتم تخزين القيم الفريدة فقط في قائمة انتظار التحكم ، أي أنه سيتم تخزين نفس معرف قائمة انتظار الروبوت في قائمة انتظار التحكم مرة واحدة فقط ، بغض النظر عن عدد مرات كتابتها هناك. على Redis ، يتم تنفيذ ذلك باستخدام بنية بيانات SORTED SET.علاوة على ذلك ، يمكننا تمييز عدد معين من العمال ، كل منهم سيحصل من قائمة انتظار التحكم على معرفه لقائمة انتظار البوت للمعالجة. وبالتالي ، سيقوم كل عامل بمعالجة القطعة بشكل مستقل من قائمة الانتظار المخصصة له ، بعد معالجة القطعة ، يعيد معرف قائمة الانتظار المعالجة إلى عنصر التحكم ، وبالتالي يعيدها إلى روبن مستدير. الشيء الرئيسي هو عدم نسيان تزويد الشيء كله بأقفال ، بحيث لا يستطيع عاملان معالجة نفس قائمة انتظار البوت بالتوازي. هذا الوضع ممكن إذا دخل مُعرِّف برنامج التتبُّع إلى قائمة انتظار التحكم عندما يكون العامل قيد المعالجة بالفعل. بالنسبة للأقفال ، نستخدم أيضًا Redis كمفتاح: مخزن القيمة مع TTL.عندما نأخذ مهمة بمعرف قائمة انتظار بوت من قائمة انتظار التحكم ، نضع قفل TTL على قائمة الانتظار المأخوذة ونبدأ في معالجتها. إذا أخذ المستهلك الآخر المهمة مع قائمة الانتظار التي تتم معالجتها بالفعل من قائمة انتظار التحكم ، فلن يتمكن من القفل ، وإعادة المهمة إلى قائمة انتظار التحكم وتلقي المهمة التالية. بعد معالجة المستهلك لقائمة انتظار الروبوت ، يزيل القفل ويذهب إلى قائمة انتظار التحكم للمهمة التالية.المخطط النهائي هو كما يلي: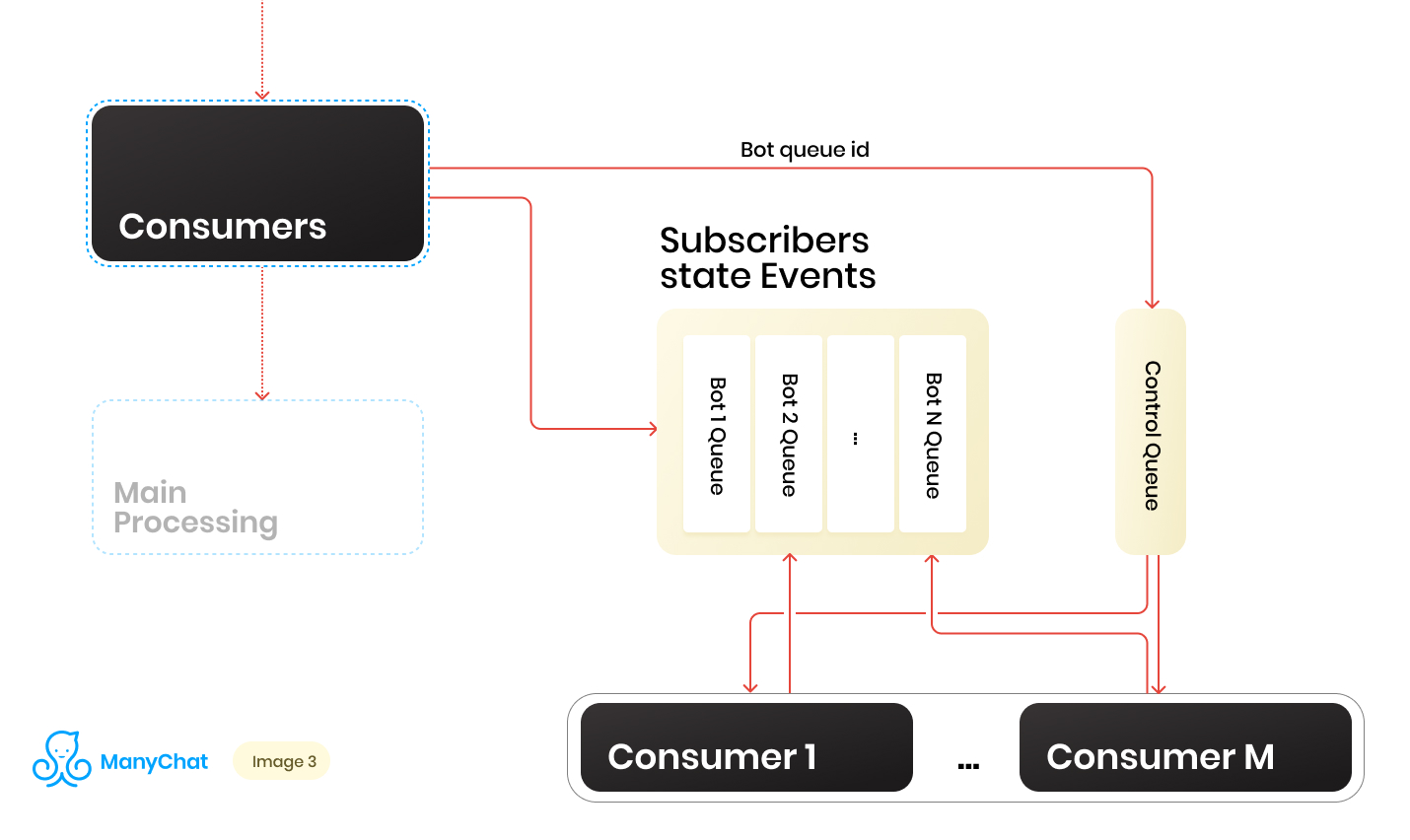 نتيجة لذلك ، مع المخطط الحالي ، قمنا بحل المشاكل الرئيسية المحددة:
نتيجة لذلك ، مع المخطط الحالي ، قمنا بحل المشاكل الرئيسية المحددة:- تدهور الأداء في ناقل الحدث الرئيسي
- انتهاك معالجة الحدث
- تأثير الجيران الصاخبين
كيف تتعامل مع الحمل الديناميكي؟
يعمل المخطط ، ولكن لدينا فيه عدد ثابت من المستهلكين لعدد ديناميكي من قوائم الانتظار. من الواضح ، مع هذا النهج ، سوف نتراجع في معالجة قوائم الانتظار في كل مرة يزيد فيها عددهم بشكل حاد. يبدو أنه سيكون من اللطيف أن يبدأ عمالنا أو يطفئوا ديناميكيًا عند الحاجة. سيكون من الجيد أيضًا أن لا يؤدي ذلك إلى تعقيد عملية طرح التعليمات البرمجية الجديدة إلى حد كبير. في مثل هذه اللحظات ، تشعر الأيدي بحكة شديدة للذهاب وكتابة مدير العمليات الخاص بك. فعلنا ذلك في المستقبل ، لكن هذه القصة مختلفة.التفكير ، قررنا ، لماذا لا تستخدم مرة أخرى جميع الأدوات المألوفة والمألوفة. لذلك حصلنا على واجهة برمجة التطبيقات الداخلية الخاصة بنا ، والتي عملت على حزمة قياسية من NGINX + PHP-FPM. ونتيجة لذلك ، يمكننا استبدال مجموعتنا الثابتة من العمال بواجهات برمجة التطبيقات ، والسماح لـ NGINX + PHP-FPM بحل وإدارة العمال بأنفسنا ، ويكفي أن يكون لدينا بين قائمة انتظار التحكم وواجهة برمجة التطبيقات الداخلية لدينا مستهلك واحد فقط للتحكم ، والذي سيرسل معرفات قائمة الانتظار إلى واجهة برمجة التطبيقات لدينا المعالجة ، وستتم معالجة قائمة الانتظار نفسها في العامل الذي تثيره PHP-FPM.كان المخطط الجديد على النحو التالي: يبدو جميلًا ، لكن عميل التحكم لدينا يعمل في سلسلة واحدة ، وتعمل واجهة برمجة التطبيقات لدينا بشكل متزامن. وهذا يعني أن المستهلك سيعلق في كل مرة أثناء قيام PHP-FPM بطحن قائمة انتظار. هذا لا يناسبنا.
يبدو جميلًا ، لكن عميل التحكم لدينا يعمل في سلسلة واحدة ، وتعمل واجهة برمجة التطبيقات لدينا بشكل متزامن. وهذا يعني أن المستهلك سيعلق في كل مرة أثناء قيام PHP-FPM بطحن قائمة انتظار. هذا لا يناسبنا.جعل API الخاص بنا غير متزامن
ولكن ماذا لو كان بإمكاننا إرسال المهمة إلى واجهة برمجة التطبيقات الخاصة بنا ، والسماح لها بدراسة منطق العمل هناك ، وسيتبع عميل التحكم لدينا المهمة التالية في قائمة انتظار التحكم ، وبعد ذلك سيتم سحبها مرة أخرى إلى واجهة برمجة التطبيقات ، وما إلى ذلك. سيتم التنفيذ قبل الانتهاء من سرد طلبك.يستغرق التنفيذ بضعة أسطر من التعليمات البرمجية ، ويظهر إثبات المفهوم كما يلي:class Api {
public function actionDoSomething()
{
$data = $_POST;
$this->dropFPMSession();
}
protected function dropFPMSession()
{
ignore_user_abort(true);
ob_end_flush();
flush();
@session_write_close();
fastcgi_finish_request();
}
}
في طريقة dropFPMSession () ، نقطع الاتصال مع العميل ، ونعطيه استجابة 200 ، وبعد ذلك يمكننا تنفيذ أي منطق ثقيل في المعالجة اللاحقة. العميل في حالتنا هو المستهلك التحكم. من المهم بالنسبة له أن ينثر المهام بسرعة من قائمة انتظار التحكم إلى المعالجة على API وأن يعرف أن المهمة وصلت إلى API.باستخدام هذا النهج ، أزلنا مجموعة من الصداع المرتبط بالتحكم الديناميكي للمستهلكين وتحجيمهم التلقائي.قابلة للتحجيم
ونتيجة لذلك ، بدأت بنية نظامنا الفرعي تتكون من ثلاث طبقات: طبقة البيانات والعمليات وواجهة برمجة التطبيقات الداخلية. في نفس الوقت ، تمر المعلومات عبر جميع تدفقات البيانات حول أي روبوت ينتمي إليه الحدث / المهمة التي تمت معالجتها. من الواضح أنه يمكننا استخدام معرف المفتاح / الروبوت الخاص بنا للتجزئة ، مع الاستمرار في توسيع نطاق نظامنا أفقيًا.إذا تخيلنا أن هندستنا كوحدة صلبة ، فستبدو كما يلي: بعد زيادة عدد هذه الوحدات ، يمكننا وضع موازن رفيع أمامها ، مما سيؤدي إلى تشتيت الأحداث / المهام في الوحدات الضرورية ، اعتمادًا على مفتاح المشاركة.
أن هندستنا كوحدة صلبة ، فستبدو كما يلي: بعد زيادة عدد هذه الوحدات ، يمكننا وضع موازن رفيع أمامها ، مما سيؤدي إلى تشتيت الأحداث / المهام في الوحدات الضرورية ، اعتمادًا على مفتاح المشاركة. وبالتالي ، نحصل على هامش كبير للتحجيم الأفقي لنظامنا.عند تنفيذ منطق الأعمال ، يجب ألا تنسى مفهوم سلامة الخيط ، وإلا يمكنك الحصول على نتائج غير متوقعة.وقد تم استخدام مثل هذا المخطط مع سلاسل متتالية من قوائم الانتظار وإزالة منطق الأعمال الثقيلة في المعالجة غير المتزامنة في عدة أجزاء من النظام لأكثر من عامين. ازداد الحمل خلال هذا الوقت لكل نظام فرعي عشرات المرات ، ويسمح لنا التنفيذ المقترح بالتوسع بسهولة وسرعة. في الوقت نفسه ، نواصل العمل على المكدس الرئيسي لدينا ، دون توسيعه بأدوات / لغات جديدة وبدون زيادة ، وبالتالي زيادة مقدمة ودعم الأدوات الجديدة.
وبالتالي ، نحصل على هامش كبير للتحجيم الأفقي لنظامنا.عند تنفيذ منطق الأعمال ، يجب ألا تنسى مفهوم سلامة الخيط ، وإلا يمكنك الحصول على نتائج غير متوقعة.وقد تم استخدام مثل هذا المخطط مع سلاسل متتالية من قوائم الانتظار وإزالة منطق الأعمال الثقيلة في المعالجة غير المتزامنة في عدة أجزاء من النظام لأكثر من عامين. ازداد الحمل خلال هذا الوقت لكل نظام فرعي عشرات المرات ، ويسمح لنا التنفيذ المقترح بالتوسع بسهولة وسرعة. في الوقت نفسه ، نواصل العمل على المكدس الرئيسي لدينا ، دون توسيعه بأدوات / لغات جديدة وبدون زيادة ، وبالتالي زيادة مقدمة ودعم الأدوات الجديدة.