أعلنا منذ شهور قليلة ، أن موقع expl.tensor.ru ، خدمة عامة للتحليل وتصور خطط الاستعلام لـ PostgreSQL.على مدار الماضي ، استخدمته بالفعل أكثر من 6000 مرة ، ولكن إحدى الوظائف المريحة قد تمر دون أن يلاحظها أحد - وهي تلميحات هيكلية تبدو مثل هذا: استمع إليها وستصبح طلباتك "سلسة وحريرية". :)ولكن على محمل الجد ، فإن العديد من المواقف التي تجعل الطلب بطيئًا و "شجاعًا" من حيث الموارد نموذجية ويمكن التعرف عليها من خلال بنية وبيانات الخطة .في هذه الحالة ، لن يضطر كل مطور فردي إلى البحث عن خيار تحسين من تلقاء نفسه ، بالاعتماد فقط على تجربته - يمكننا إخباره بما يحدث هنا ، وما يمكن أن يكون السبب ، وكيفية التعامل مع الحل . وهو ما فعلناه.
استمع إليها وستصبح طلباتك "سلسة وحريرية". :)ولكن على محمل الجد ، فإن العديد من المواقف التي تجعل الطلب بطيئًا و "شجاعًا" من حيث الموارد نموذجية ويمكن التعرف عليها من خلال بنية وبيانات الخطة .في هذه الحالة ، لن يضطر كل مطور فردي إلى البحث عن خيار تحسين من تلقاء نفسه ، بالاعتماد فقط على تجربته - يمكننا إخباره بما يحدث هنا ، وما يمكن أن يكون السبب ، وكيفية التعامل مع الحل . وهو ما فعلناه. دعونا نلقي نظرة فاحصة على هذه الحالات - كيف يتم تحديدها والتوصيات التي تؤدي إليها.للحصول على نظرة أفضل على الموضوع ، يمكنك أولاً الاستماع إلى الكتلة المقابلة من تقريري على PGConf.Russia 2020 ، وبعد ذلك فقط انتقل إلى تحليل مفصل لكل مثال:
دعونا نلقي نظرة فاحصة على هذه الحالات - كيف يتم تحديدها والتوصيات التي تؤدي إليها.للحصول على نظرة أفضل على الموضوع ، يمكنك أولاً الاستماع إلى الكتلة المقابلة من تقريري على PGConf.Russia 2020 ، وبعد ذلك فقط انتقل إلى تحليل مفصل لكل مثال:# 1: فهرس "underorting"
عندما ينشأ
عرض الفاتورة الأخيرة للعميل "LLC Bell".كيفية التعرف
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
التوصيات
استخدم الفهرس المستخدم لفرز الحقول .مثال:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 1
ORDER BY
pk DESC
LIMIT 1;
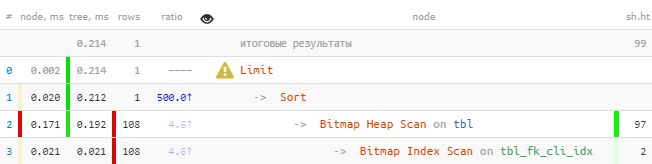 [إلقاء نظرة على Expl.tensor.ru] يمكنكأن تلاحظ على الفور أن الفهرس طرح أكثر من 100 إدخال ، والتي تم فرزها بعد ذلك ، ثم تم ترك واحد فقط.نصلح:
[إلقاء نظرة على Expl.tensor.ru] يمكنكأن تلاحظ على الفور أن الفهرس طرح أكثر من 100 إدخال ، والتي تم فرزها بعد ذلك ، ثم تم ترك واحد فقط.نصلح:DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC);
 [إلقاء نظرة على Expl.tensor.ru]حتى في مثل هذه العينة البدائية - 8.5 مرات أسرع و 33 مرة قراءات أقل . سيكون التأثير أكثر وضوحًا كلما زادت "الحقائق" التي تمتلكها لكل قيمة
[إلقاء نظرة على Expl.tensor.ru]حتى في مثل هذه العينة البدائية - 8.5 مرات أسرع و 33 مرة قراءات أقل . سيكون التأثير أكثر وضوحًا كلما زادت "الحقائق" التي تمتلكها لكل قيمة fk.ألاحظ أن مثل هذا الفهرس سيعمل كـ "بادئة" ليس أسوأ من السابق مع الاستعلامات الأخرى fk، حيث pkلم يكن هناك فرز ولا يوجد (لمزيد من التفاصيل ، راجع مقالتي حول البحث عن فهارس غير فعالة ). على وجه الخصوص ، سيوفر الدعم العادي لمفتاح خارجي صريح في هذا المجال.# 2: تقاطع الفهرس (BitmapAnd)
عندما ينشأ
عرض جميع العقود للعميل LLC Kolokolchik التي أبرمت نيابة عن NAO Buttercup.كيفية التعرف
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index Scan
التوصيات
قم بإنشاء فهرس مركب للحقول من المصدر أو قم بتوسيع أحد الحقول الموجودة من الحقل الثاني.مثال:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org);
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
(fk_org, fk_cli) = (1, 999);
 [انظر إلى شرح ..tensor.ru]صحيح:
[انظر إلى شرح ..tensor.ru]صحيح:DROP INDEX tbl_fk_org_idx;
CREATE INDEX ON tbl(fk_org, fk_cli);
 [إلقاء نظرة على Expl.tensor.ru]هنا المكسب أقل ، لأن Bitmap Heap Scan فعال للغاية في حد ذاته. ولكن لا يزال أسرع 7 مرات وقراءات أقل 2.5 مرة .
[إلقاء نظرة على Expl.tensor.ru]هنا المكسب أقل ، لأن Bitmap Heap Scan فعال للغاية في حد ذاته. ولكن لا يزال أسرع 7 مرات وقراءات أقل 2.5 مرة .رقم 3: تجميع الفهرس (BitmapOr)
عندما ينشأ
اعرض أول 20 تطبيقًا "خاصًا" أو غير مخصص للمعالجة وأولويتها.كيفية التعرف
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index Scan
التوصيات
استخدم UNION [ALL] لدمج الاستعلامات الفرعية لكل من مجموعات شروط OR.مثال:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own;
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR
fk_own IS NULL
ORDER BY
pk
, (fk_own = 1) DESC
LIMIT 20;
 [انظر إلى شرح ..tensor.ru]صحيح:
[انظر إلى شرح ..tensor.ru]صحيح:(
SELECT
*
FROM
tbl
WHERE
fk_own = 1
ORDER BY
pk
LIMIT 20
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL
ORDER BY
pk
LIMIT 20
)
LIMIT 20;
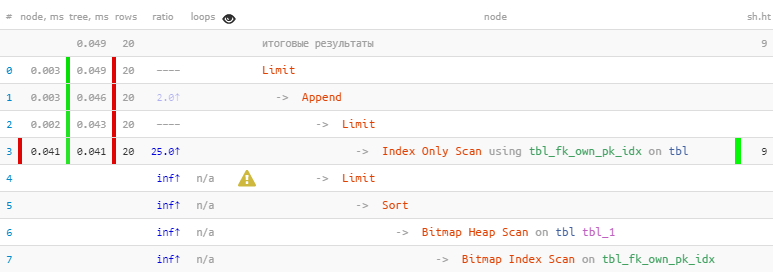 [إلقاء نظرة على expl.tensor.ru] استفدنامن حقيقة أنه تم استلام جميع السجلات العشرين المطلوبة على الفور في الكتلة الأولى ، لذلك لم يتم إجراء السجل الثاني ، مع فحص الصورة النقطية "الأكثر تكلفة" - ونتيجة لذلك ، أسرع 22 مرة ، في قراءات أقل 44 مرة !
[إلقاء نظرة على expl.tensor.ru] استفدنامن حقيقة أنه تم استلام جميع السجلات العشرين المطلوبة على الفور في الكتلة الأولى ، لذلك لم يتم إجراء السجل الثاني ، مع فحص الصورة النقطية "الأكثر تكلفة" - ونتيجة لذلك ، أسرع 22 مرة ، في قراءات أقل 44 مرة !يمكن العثور على قصة أكثر تفصيلاً حول طريقة التحسين هذه باستخدام أمثلة محددة في مقالات PostgreSQL Antipatterns: JOIN و OR الضارة و PostgreSQL Antipatterns: حكاية حول التحسين التكراري للبحث بالاسم ، أو "التحسين هناك والعودة" .
يتم النظر في نسخة معممة من التحديد المرتبط بعدة مفاتيح (وليس فقط من خلال كون / كونت / NULL) في مقالة SQL HowTo: نكتب حلقة متكررة مباشرة في الاستعلام ، أو "Elementary three-way" .
# 4: قراءة الكثير من غير الضروري
عندما ينشأ
كقاعدة ، ينشأ إذا كنت تريد "ربط مرشح آخر" لطلب موجود."وليس لديك نفس الشيء ، ولكن بأزرار اللؤلؤ ؟" فيلم "يد الماس"
على سبيل المثال ، عند تعديل المهمة أعلاه ، اعرض أول 20 تطبيقًا "حرجًا" أقدم للمعالجة ، بغض النظر عن الغرض منها.كيفية التعرف
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × rows < RRbF -- >80%
&& loops × RRbF > 100 -- 100
التوصيات
قم بإنشاء فهرس مخصص [more] باستخدام عبارة WHERE أو قم بتضمين حقول إضافية في الفهرس.إذا كان شرط الفلتر "ثابتًا" لمهامك - أي أنه لا يتضمن توسيع قائمة القيم في المستقبل - فمن الأفضل استخدام فهرس WHERE. تتناسب الحالات المنطقية / التعدادية المختلفة بشكل جيد مع هذه الفئة.
إذا كان شرط المرشح يمكن أن يأخذ قيمًا مختلفة ، فمن الأفضل توسيع الفهرس بهذه الحقول - كما هو الحال مع BitmapAnd أعلاه.
مثال:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own
, (random() < 1::real/50) critical;
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20;
 [انظر إلى شرح ..tensor.ru]صحيح:
[انظر إلى شرح ..tensor.ru]صحيح:CREATE INDEX ON tbl(pk)
WHERE critical;
 [انظر إلى expl.tensor.ru]كما ترون ، اختفى التصفية تمامًا من الخطة ، وأصبح الطلب أسرع 5 مرات .
[انظر إلى expl.tensor.ru]كما ترون ، اختفى التصفية تمامًا من الخطة ، وأصبح الطلب أسرع 5 مرات .رقم 5: طاولة متفرقة
عندما ينشأ
محاولات مختلفة لإنشاء قائمة انتظار خاصة بها لمهام المعالجة عندما يؤدي عدد كبير من تحديثات / حذف السجلات على الجدول إلى حالة عدد كبير من السجلات "الميتة".كيفية التعرف
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
التوصيات
قم يدويًا بتنفيذ VACUUM [FULL] يدويًا أو حقق اختبار فراغ تلقائي تلقائيًا من خلال ضبط معلماته بدقة ، بما في ذلك جدول معين .في معظم الحالات ، تحدث هذه المشكلات بسبب الاستعلامات غير المنظمة بشكل جيد عند الاتصال من منطق الأعمال ، مثل تلك التي تمت مناقشتها في PostgreSQL Antipatterns: محاربة جحافل "القتلى" .
ولكن عليك أن تفهم أنه حتى VACUUM FULL قد لا يساعد دائمًا. في مثل هذه الحالات ، يجب أن تتعرف على الخوارزمية من مقالة DBA: عندما يمر VACUUM ، نقوم بتنظيف الجدول يدويًا .
# 6: القراءة من منتصف الفهرس
عندما ينشأ
يبدو أنهم لم يقرؤوا كثيرًا ، وكلهم حسب الفهرس ، ولم يقوموا بتصفية أي شيء إضافي - ولكن على أي حال ، تمت قراءة صفحات أكثر بكثير مما نود.كيفية التعرف
-> Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
التوصيات
انظر عن كثب إلى بنية الفهرس المستخدم والمجالات الرئيسية المحددة في الطلب - على الأرجح ، لم يتم تحديد جزء من الفهرس . على الأرجح ، سيكون عليك إنشاء فهرس مشابه ، ولكن بدون حقول البادئة أو معرفة كيفية التكرار فوق قيمها .مثال:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org, fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 999
LIMIT 20;
 [انظر إلى expl.tensor.ru]يبدو أن كل شيء على ما يرام ، حتى حسب الفهرس ، ولكن بشكل مثير للريبة - لكل سجل من السجلات العشرين التي كان علي قراءتها ، اضطررت إلى طرح 4 صفحات من البيانات ، 32 كيلوبايت لكل سجل - أليس غامقًا؟ نعم ، واسم المؤشر موحي. نصلح:
[انظر إلى expl.tensor.ru]يبدو أن كل شيء على ما يرام ، حتى حسب الفهرس ، ولكن بشكل مثير للريبة - لكل سجل من السجلات العشرين التي كان علي قراءتها ، اضطررت إلى طرح 4 صفحات من البيانات ، 32 كيلوبايت لكل سجل - أليس غامقًا؟ نعم ، واسم المؤشر موحي. نصلح:tbl_fk_org_fk_cli_idxCREATE INDEX ON tbl(fk_cli);
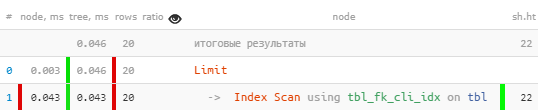 [انظر إلى شرح.tensor.ru]فجأة - أسرع 10 مرات وأقل 4 مرات من القراءة !
[انظر إلى شرح.tensor.ru]فجأة - أسرع 10 مرات وأقل 4 مرات من القراءة !يمكن الاطلاع على أمثلة أخرى لحالات الاستخدام غير الفعال للفهارس في مقالة DBA: Find Useless Indexes .
رقم 7: CTE × CTE
عندما ينشأ
في الاستعلام قمنا بكتابة CTEs "الدهون" من جداول مختلفة ، ثم قررنا القيام بها فيما بينها JOIN.الحالة ذات صلة بالإصدارات أدناه v12 أو الطلبات من WITH MATERIALIZED.كيفية التعرف
-> CTE Scan
&& loops > 10
&& loops × (rows + RRbF) > 10000
-- CTE
التوصيات
قم بتحليل الطلب بعناية - هل CTE مطلوب هنا على الإطلاق ؟ إذا كان كل نفس الشيء ، فقم بتطبيق "تمزق" في hstore / json وفقًا للنموذج الموضح في PostgreSQL Antipatterns: اضغط على القاموس باستخدام JOIN الثقيل .رقم 8: التبديل إلى القرص (درجة الحرارة المكتوبة)
عندما ينشأ
المعالجة لمرة واحدة (الفرز أو التفرد) لعدد كبير من السجلات لا تتناسب مع الذاكرة المخصصة لذلك.كيفية التعرف
-> *
&& temp written > 0
التوصيات
إذا كانت كمية الذاكرة المستخدمة بواسطة العملية لا تتجاوز إلى حد كبير القيمة المحددة لمعلمة work_mem ، فمن الجدير تعديلها. يمكنك على الفور في التكوين للجميع ، ولكن يمكنك من خلال SET [LOCAL]طلب / معاملة معينة.مثال:SHOW work_mem;
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1;
 [انظر إلى شرح ..tensor.ru]صحيح:
[انظر إلى شرح ..tensor.ru]صحيح:SET work_mem = '128MB';
 [انظر إلى شرح.tensor.ru]لأسباب واضحة ، إذا تم استخدام الذاكرة فقط ، وليس القرص ، فسيتم تنفيذ الطلب بشكل أسرع. في الوقت نفسه ، تتم أيضًا إزالة جزء من الحمل من محرك الأقراص الثابتة.ولكن عليك أن تفهم أن تخصيص قدر كبير من الذاكرة لا يعمل دائمًا أيضًا - فلن يكون كافيًا للجميع.
[انظر إلى شرح.tensor.ru]لأسباب واضحة ، إذا تم استخدام الذاكرة فقط ، وليس القرص ، فسيتم تنفيذ الطلب بشكل أسرع. في الوقت نفسه ، تتم أيضًا إزالة جزء من الحمل من محرك الأقراص الثابتة.ولكن عليك أن تفهم أن تخصيص قدر كبير من الذاكرة لا يعمل دائمًا أيضًا - فلن يكون كافيًا للجميع.رقم 9: إحصائيات غير ذات صلة
عندما ينشأ
سكبوا الكثير في وقت واحد في قاعدة البيانات ، لكنهم لم يتمكنوا من طردهم ANALYZE.كيفية التعرف
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10
التوصيات
افعل نفس الشيء ANALYZE.يتم وصف هذا الموقف بمزيد من التفاصيل في PostgreSQL Antipatterns: الإحصائيات في كل مكان .
رقم 10: "حدث خطأ ما"
عندما ينشأ
كان هناك توقع بقفل مفروض بواسطة طلب منافس ، أو لم يكن هناك ما يكفي من موارد أجهزة CPU / hypervisor.كيفية التعرف
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- ,
التوصيات
استخدم نظامًا خارجيًا لمراقبة الخادم بحثًا عن الأقفال أو استهلاك الموارد بشكل غير طبيعي. معلومات عن نسختنا من تنظيم هذه العملية لمئات الخوادم، تحدثنا بالفعل هنا و هنا .