مع المعالجة المعقدة لمجموعات البيانات الكبيرة ( عمليات ETL المختلفة : عمليات الاستيراد والتحويلات والمزامنة مع مصدر خارجي) ، غالبًا ما يكون من الضروري "التذكر" مؤقتًا ومعالجة شيء ضخم على الفور .عادة ما تبدو المهمة النموذجية من هذا النوع شيئًا مثل هذا: "هنا قام قسم المحاسبة بتحميل آخر مدفوعات مستلمة من البنك العميل ، نحتاج إلى تحميلها بسرعة إلى موقع الويب وربطها بالحسابات"ولكن عندما يبدأ قياس حجم هذا "شيء" بمئات الميجابايت ، والخدمة يجب أن يستمر هذا في العمل مع القاعدة في وضع 24 × 7 ، فهناك العديد من الآثار الجانبية التي ستدمر حياتك.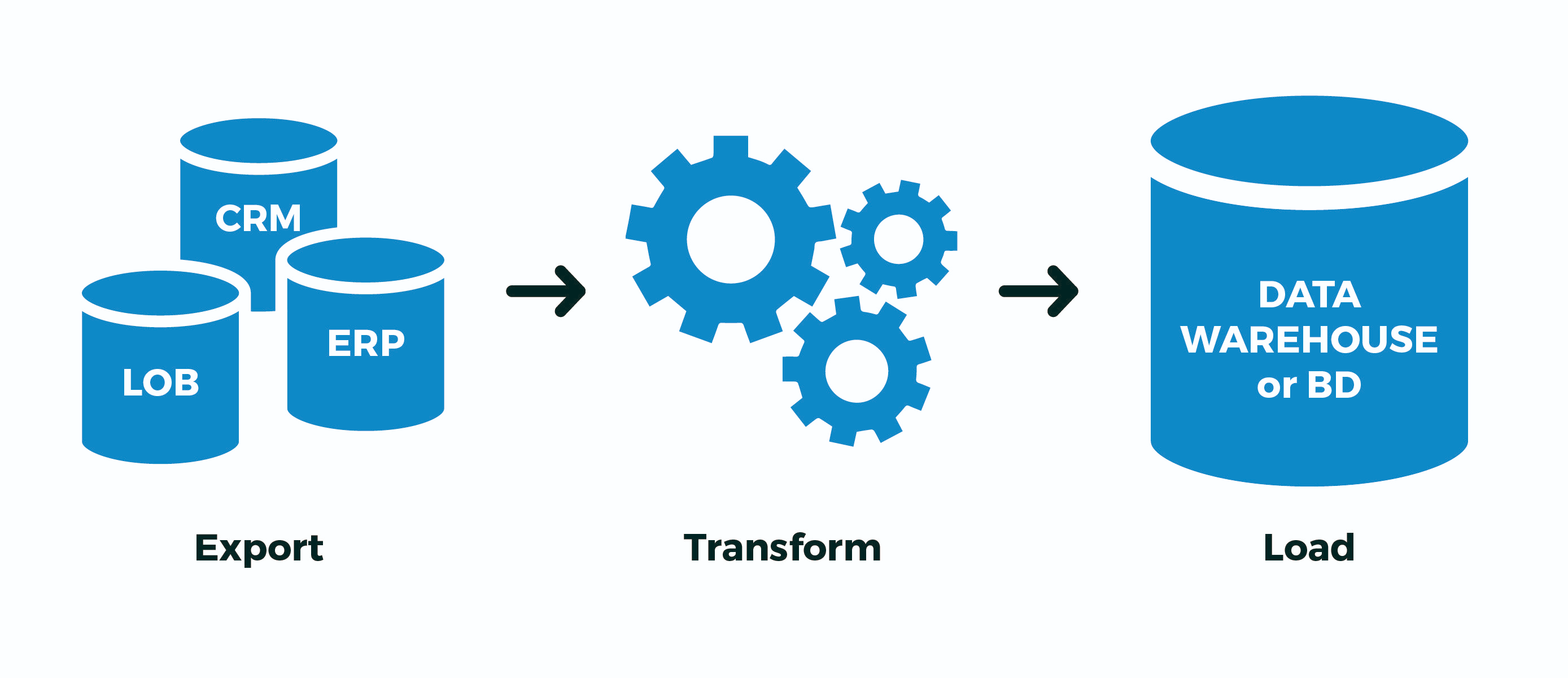 للتعامل معها في PostgreSQL (وليس فقط فيها) ، يمكنك استخدام بعض خيارات التحسين التي ستسمح لك بمعالجة أسرع وبموارد أقل.
للتعامل معها في PostgreSQL (وليس فقط فيها) ، يمكنك استخدام بعض خيارات التحسين التي ستسمح لك بمعالجة أسرع وبموارد أقل.1. أين تشحن؟
أولاً ، دعنا نقرر أين يمكننا تحميل البيانات التي نريد "معالجتها".1.1. الجداول المؤقتة (الجدول المؤقت)
من حيث المبدأ ، بالنسبة لـ PostgreSQL ، فإن المؤقتات هي نفس الجداول مثل أي جداول أخرى. لذلك ، الخرافات مثل "كل شيء مخزّن هناك فقط في الذاكرة ، ولكن يمكن أن تنتهي" غير صحيحة . ولكن هناك العديد من الاختلافات المهمة.مساحة الاسم الخاصة لكل اتصال بقاعدة البيانات
إذا حاول اتصالان القيام بهما في نفس الوقت CREATE TABLE x، فمن المؤكد أن شخصًا ما سيحصل على خطأ في كائنات DB غير الفريدة .ولكن إذا حاول كلاهما التنفيذ ، فسيقوم كلاهما بتنفيذ ذلك عادةً ، وسيتلقى كل منهما نسخته الخاصة من الجدول. ولن يكون هناك شيء مشترك بينهما.CREATE TEMPORARY TABLE x"التدمير الذاتي" مع قطع الاتصال
عند إغلاق الاتصال ، يتم حذف جميع الجداول المؤقتة تلقائيًا ، لذلك DROP TABLE xلا معنى في التنفيذ "يدويًا" ، باستثناء ...إذا كنت تعمل من خلال pgbouncer في وضع المعاملة ، تستمر قاعدة البيانات في افتراض أن هذا الاتصال لا يزال نشطًا ، وهذا المؤقت الجدول لا يزال موجودا.لذلك ، ستؤدي محاولة إعادة إنشائه ، من اتصال آخر إلى pgbouncer ، إلى حدوث خطأ. ولكن يمكن التحايل على هذا من خلال الاستفادة . صحيح أنه من الأفضل عدم القيام بذلك تمامًا ، لأنه عندها يمكنك "فجأة" معرفة البيانات المتبقية من "المالك السابق" هناك. بدلاً من ذلك ، من الأفضل بكثير قراءة الدليل ، ومعرفة أنه عند إنشاء الجدول ، هناك فرصة للإضافةCREATE TEMPORARY TABLE IF NOT EXISTS xON COMMIT DROP - عند اكتمال المعاملة ، سيتم حذف الجدول تلقائيًا.عدم التكرار
لأنه ينتمي صلة معينة فقط ، لا يتم نسخ الجداول المؤقتة. ولكن هذا يلغي الحاجة إلى مضاعفة كتابة البيانات في كومة + WAL ، لذا فإن INSERT / UPDATE / DELETE أسرع بكثير فيه.ولكن نظرًا لأن الجدول المؤقت لا يزال جدولًا "شبه عادي" ، فلا يمكن إنشاؤه على النسخة المتماثلة أيضًا. على الأقل في الوقت الحالي ، على الرغم من أن التصحيح المطابق كان موجودًا لفترة طويلة.1.2. جداول غير مسجلة (جدول غير مسجل)
ولكن ماذا تفعل ، على سبيل المثال ، إذا كان لديك نوع من عملية ETL المرهقة التي لا يمكن تنفيذها في معاملة واحدة ، ولا يزال لديك pgbouncer في وضع المعاملة ؟ ..أو أن تدفق البيانات كبير جدًا بحيث لا يوجد نطاق ترددي كاف لكل اتصال من قاعدة البيانات (قراءة ، عملية واحدة على وحدة المعالجة المركزية)؟ ..أو جزء من العمليات يذهب بشكل غير متزامن في اتصالات مختلفة؟ ..هناك خيار واحد فقط - إنشاء جدول غير مؤقت بشكل مؤقت . التورية ، نعم. بمعنى آخر:- إنشاء جداول "له" بأسماء عشوائية إلى أقصى حد حتى لا تتقاطع مع أي شخص
- استخراج : سكب البيانات من مصدر خارجي فيها
- التحويل : محولة ومعبأة في حقول ربط رئيسية
- تحميل : سكب البيانات النهائية في الجداول الهدف
- حذف جداول "بلدي"
والآن - ذبابة في المرهم. في الواقع ، تتم جميع عمليات الكتابة في PostgreSQL مرتين - أولاً في WAL ، ثم في نص الجدول / الفهرس. ويتم كل هذا لدعم ACID والرؤية الصحيحة للبيانات بين COMMITالمتداخلة و ROLLBACKالمعاملات المتداخلة.لكننا لا نحتاج هذا! لدينا العملية برمتها أو نجحت ، أم لا . لا يهم عدد المعاملات الوسيطة التي يحتوي عليها - نحن لسنا مهتمين "بمواصلة العملية من الوسط" ، خاصة عندما لا يكون واضحًا أين كانت.لهذا ، قدم مطورو PostgreSQL الإصدار 9.1 مثل الجداول غير المسجلة (UNLOGGED) :. , , (. 29), . , ; . , . , , .
باختصار ، سيكون أسرع بكثير ، ولكن إذا "تعطل" خادم قاعدة البيانات - سيكون غير سار. ولكن كم مرة يحدث هذا ، وهل تعرف عملية ETL الخاصة بك كيفية تعديلها بشكل صحيح "من الوسط" بعد "تنشيط" قاعدة البيانات؟ ..إذا لم يكن الأمر كذلك ، والحالة أعلاه مشابهة لحالتك - استخدم UNLOGGED، ولكن لا تقم أبدًا بتضمين هذه السمة على الجداول الحقيقية البيانات التي أنت عزيزي.1.3. في الالتزام {حذف الصفوف | قطرة}
يسمح هذا التصميم عند إنشاء جدول لتعيين السلوك التلقائي عند انتهاء المعاملة.حول كتبت بالفعل أعلاه ، فإنه يولد ، ولكن الوضع أكثر إثارة للاهتمام - هنا يتم إنشاؤه . نظرًا لأن البنية التحتية الكاملة لتخزين الوصف التعريفي للجدول المؤقت هي نفسها تمامًا مثل المعتادة ، فإن الإنشاء المستمر وحذف الجداول المؤقتة يؤدي إلى "تورم" قوي لجداول النظام pg_class ، pg_attribute ، pg_attrdef ، pg_depend ، ... الآن تخيل أن لديك عامل على الخط الاتصال بقاعدة البيانات ، التي تفتح كل ثانية معاملة جديدة ، وإنشاء وتعبئة ومعالجة وحذف الجدول المؤقت ... سوف تتراكم القمامة في جداول النظام بشكل زائد ، وهذا هو فرامل إضافية أثناء كل عملية.ON COMMIT DROPDROP TABLEON COMMIT DELETE ROWSTRUNCATE TABLEبشكل عام ، لا تفعل! في هذه الحالة ، يكون CREATE TEMPORARY TABLE x ... ON COMMIT DELETE ROWSإخراجها من دورة المعاملة أكثر فاعلية بكثير - ثم بحلول بداية كل معاملة جديدة سيكون الجدول موجودًا بالفعل (حفظ المكالمة CREATE) ، ولكنه سيكون فارغًا ، وذلك بفضل TRUNCATE(حفظنا المكالمة أيضًا) في نهاية المعاملة السابقة.1.4. مثل ... بما في ذلك ...
ذكرت في البداية أن إحدى حالات الاستخدام النموذجي للجداول المؤقتة هي أنواع مختلفة من عمليات الاستيراد - ويقوم المطور بتعبئ لصق ولصق قائمة حقول الجدول الهدف في الإعلان المؤقت له ...ولكن الكسل هو محرك التقدم! لذلك ، يمكن أن يكون إنشاء جدول جديد "على النموذج" أسهل بكثير:CREATE TEMPORARY TABLE import_table(
LIKE target_table
);
نظرًا لأنه يمكنك بعد ذلك إضافة الكثير من البيانات إلى هذا الجدول ، فلن تكون عمليات البحث عليه سريعة أبدًا. ولكن هناك حل تقليدي ضد هذا - فهارس! ونعم ، يمكن أن يحتوي الجدول المؤقت أيضًا على فهارس .نظرًا لأنه غالبًا ما تتزامن المؤشرات المطلوبة مع مؤشرات الجدول الهدف ، يمكنك ببساطة الكتابة . إذا كنت بحاجة أيضًا إلى -القيم (على سبيل المثال ، لملء قيم المفتاح الأساسي) ، يمكنك استخدامها . حسنًا ، أو ببساطة - - ستنسخ الإعدادات الافتراضية والفهارس والقيود ... ولكن هنا تحتاج إلى فهم أنه إذا قمت بإنشاء جدول استيراد على الفور باستخدام الفهارس ، فسيتم ملء البيانات لفترة أطولLIKE target_table INCLUDING INDEXESDEFAULTLIKE target_table INCLUDING DEFAULTSLIKE target_table INCLUDING ALLمما لو قمت بملء كل شيء أولاً ، ثم قم بتدوير المؤشرات - انظر كمثال على كيفية قيام pg_dump بذلك .الكل في الكل ، RTFM !2. كيف تكتب؟
سأقول ببساطة - استخدم COPYتيار بدلاً من "حزم" INSERT، تسارع في بعض الأحيان . يمكنك حتى مباشرة من ملف تم إنشاؤه مسبقًا.3. كيفية التعامل معها؟
لذا ، دع المقدمة تبدو مثل هذا:- لديك في قاعدة البيانات الخاصة بك لوحة مع بيانات العميل لسجلات 1M
- كل يوم يرسل لك العميل "صورة" كاملة جديدة
- من التجربة ، تعلم أنه لا يتغير أكثر من 10 آلاف سجل من وقت لآخر
مثال كلاسيكي على مثل هذا الموقف هو قاعدة بيانات KLADR - هناك الكثير من العناوين ، ولكن في كل تحميل أسبوعي للتغييرات (إعادة تسمية المستوطنات ، اتحادات الشوارع ، ظهور منازل جديدة) هناك عدد قليل جدًا حتى على الصعيد الوطني.3.1. خوارزمية التزامن الكامل
من أجل البساطة ، دعنا نقول أنك لا تحتاج حتى إلى إعادة هيكلة البيانات - ما عليك سوى إحضار الجدول في الشكل الصحيح ، وهو:- حذف كل ما لم يعد
- تحديث كل ما كان بالفعل ، وتحتاج إلى التحديث
- إدراج كل ما لم يكن
لماذا يستحق هذا الأمر القيام بعمليات؟ لأن هذه هي الطريقة التي ينمو بها حجم الجدول إلى الحد الأدنى ( تذكر MVCC! ).حذف من التوقيت الصيفي
لا ، بالطبع ، يمكنك القيام بعمليتين فقط:- حذف (
DELETE) على الإطلاق - لصق كل شيء من صورة جديدة
ولكن في نفس الوقت ، وبفضل MVCC ، سيزداد حجم الطاولة مرتين بالضبط ! احصل على + 1 مليون صورة في الجدول بسبب تحديث 10K - فائض للغاية ...اقتطاع التوقيت الصيفي
يعرف مطور أكثر خبرة أنه يمكن تنظيف اللوحة بأكملها بثمن بخس:- امسح (
TRUNCATE) الجدول بأكمله - لصق كل شيء من صورة جديدة
الطريقة فعالة ، وأحيانًا تكون قابلة للتطبيق تمامًا ، ولكن هناك مشكلة ... سنملأ مليون سجل ، لذلك لا يمكننا أن نترك الجدول فارغًا طوال هذا الوقت (كما سيحدث دون الالتفاف في معاملة واحدة).مما يعني:- نبدأ صفقة طويلة
TRUNCATEيفرض AccessExclusive -Lock- نقوم بالإدراج لفترة طويلة ، ولا يمكن لأي شخص آخر في هذا الوقت حتى
SELECT
شيء سيء ...جدول تغيير ... إعادة تسمية ... / جدول إسقاط ...
كخيار ، املأ كل شيء في جدول جديد منفصل ، ثم أعد تسميته إلى الجدول القديم. زوجان من الأشياء الصغيرة السيئة:- حصريًا أيضًا ، وإن كان أقل بكثير من الوقت
- يتم إعادة تعيين جميع خطط / إحصائيات الاستعلام في هذا الجدول ، فمن الضروري قيادة ANALYZE
- كسر جميع المفاتيح الخارجية (FK) على الطاولة
كان هناك تصحيح WIP من Simon Riggs ، الذي اقترح إجراء ALTERعملية لاستبدال نص الجدول على مستوى الملف ، دون لمس الإحصائيات و FK ، لكنه لم يجمع النصاب القانوني.حذف ، تحديث ، إدراج
لذا ، نتوقف عند إصدار غير محجوب لثلاث عمليات. ما يقرب من ثلاثة ... كيف نفعل ذلك بشكل أكثر فعالية؟
BEGIN;
CREATE TEMPORARY TABLE tmp(
LIKE dst INCLUDING INDEXES
) ON COMMIT DROP;
COPY tmp FROM STDIN;
DELETE FROM
dst D
USING
dst X
LEFT JOIN
tmp Y
USING(pk1, pk2)
WHERE
(D.pk1, D.pk2) = (X.pk1, X.pk2) AND
Y IS NOT DISTINCT FROM NULL;
UPDATE
dst D
SET
(f1, f2, f3) = (T.f1, T.f2, T.f3)
FROM
tmp T
WHERE
(D.pk1, D.pk2) = (T.pk1, T.pk2) AND
(D.f1, D.f2, D.f3) IS DISTINCT FROM (T.f1, T.f2, T.f3);
INSERT INTO
dst
SELECT
T.*
FROM
tmp T
LEFT JOIN
dst D
USING(pk1, pk2)
WHERE
D IS NOT DISTINCT FROM NULL;
COMMIT;
3.2. استيراد ما بعد المعالجة
في نفس KLADRE ، يجب تشغيل جميع السجلات التي تم تغييرها بشكل إضافي من خلال المعالجة اللاحقة - تطبيع الكلمات الرئيسية وتسليط الضوء عليها وإحضارها إلى الهياكل الضرورية. ولكن كيف تعرف ما الذي تغير بالضبط ، دون تعقيد رمز المزامنة ، بشكل مثالي دون لمسه على الإطلاق؟إذا كانت العملية الخاصة بك فقط لديها حق الوصول للكتابة في وقت المزامنة ، فيمكنك استخدام مشغل يقوم بجمع جميع التغييرات لنا:
CREATE TABLE kladr(...);
CREATE TABLE kladr_house(...);
CREATE TABLE kladr$log(
ro kladr,
rn kladr
);
CREATE TABLE kladr_house$log(
ro kladr_house,
rn kladr_house
);
CREATE OR REPLACE FUNCTION diff$log() RETURNS trigger AS $$
DECLARE
dst varchar = TG_TABLE_NAME || '$log';
stmt text = '';
BEGIN
IF TG_OP = 'UPDATE' THEN
IF NEW IS NOT DISTINCT FROM OLD THEN
RETURN NEW;
END IF;
END IF;
stmt = 'INSERT INTO ' || dst::text || '(ro,rn)VALUES(';
CASE TG_OP
WHEN 'INSERT' THEN
EXECUTE stmt || 'NULL,$1)' USING NEW;
WHEN 'UPDATE' THEN
EXECUTE stmt || '$1,$2)' USING OLD, NEW;
WHEN 'DELETE' THEN
EXECUTE stmt || '$1,NULL)' USING OLD;
END CASE;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
الآن يمكننا فرض مشغلات (أو تمكين من خلال ALTER TABLE ... ENABLE TRIGGER ...) قبل بدء المزامنة :CREATE TRIGGER log
AFTER INSERT OR UPDATE OR DELETE
ON kladr
FOR EACH ROW
EXECUTE PROCEDURE diff$log();
CREATE TRIGGER log
AFTER INSERT OR UPDATE OR DELETE
ON kladr_house
FOR EACH ROW
EXECUTE PROCEDURE diff$log();
وبعد ذلك بهدوء من جداول السجلات ، نقوم باستخراج جميع التغييرات التي نحتاجها وتشغيلها من خلال معالجات إضافية.3.3. استيراد المجموعات ذات الصلة
أعلاه ، نظرنا في الحالات التي تتزامن فيها هياكل بيانات المصدر والمستقبل. ولكن ماذا لو كان للتنزيل من نظام خارجي تنسيق مختلف عن هيكل التخزين في قاعدة البيانات الخاصة بنا؟خذ مساحة التخزين للعملاء وحساباتهم كمثال ، الخيار الكلاسيكي متعدد الأطراف:CREATE TABLE client(
client_id
serial
PRIMARY KEY
, inn
varchar
UNIQUE
, name
varchar
);
CREATE TABLE invoice(
invoice_id
serial
PRIMARY KEY
, client_id
integer
REFERENCES client(client_id)
, number
varchar
, dt
date
, sum
numeric(32,2)
);
لكن التفريغ من مصدر خارجي يأتي إلينا في شكل "الكل في واحد":CREATE TEMPORARY TABLE invoice_import(
client_inn
varchar
, client_name
varchar
, invoice_number
varchar
, invoice_dt
date
, invoice_sum
numeric(32,2)
);
من الواضح أنه يمكن تكرار بيانات العملاء بهذه الطريقة ، والسجل الرئيسي هو "الحساب":0123456789;;A-01;2020-03-16;1000.00
9876543210;;A-02;2020-03-16;666.00
0123456789;;B-03;2020-03-16;9999.00
بالنسبة للنموذج ، ما عليك سوى إدخال بيانات الاختبار الخاصة بنا ، ولكن تذكر - COPYبكفاءة أكبر!INSERT INTO invoice_import
VALUES
('0123456789', '', 'A-01', '2020-03-16', 1000.00)
, ('9876543210', '', 'A-02', '2020-03-16', 666.00)
, ('0123456789', '', 'B-03', '2020-03-16', 9999.00);
أولاً ، نختار تلك "التخفيضات" التي تشير إليها "وقائعنا". في حالتنا ، تشير الحسابات إلى العملاء:CREATE TEMPORARY TABLE client_import AS
SELECT DISTINCT ON(client_inn)
client_inn inn
, client_name "name"
FROM
invoice_import;
لربط الحسابات بالأرقام التعريفية للعملاء بشكل صحيح ، نحتاج أولاً إلى اكتشاف أو إنشاء هذه المعرّفات. أضف الحقول لهم:ALTER TABLE invoice_import ADD COLUMN client_id integer;
ALTER TABLE client_import ADD COLUMN client_id integer;
سنستخدم طريقة مزامنة الجداول مع التصحيح الصغير الموضح أعلاه - لن نقوم بتحديث أو حذف أي شيء في الجدول الهدف ، لأن استيراد العملاء هو "إلحاق فقط":
UPDATE
client_import T
SET
client_id = D.client_id
FROM
client D
WHERE
T.inn = D.inn;
WITH ins AS (
INSERT INTO client(
inn
, name
)
SELECT
inn
, name
FROM
client_import
WHERE
client_id IS NULL
RETURNING *
)
UPDATE
client_import T
SET
client_id = D.client_id
FROM
ins D
WHERE
T.inn = D.inn;
UPDATE
invoice_import T
SET
client_id = D.client_id
FROM
client_import D
WHERE
T.client_inn = D.inn;
في الواقع ، كل شيء - invoice_importالآن ملأنا في مجال الاتصال client_idالذي سنقوم بإدخال الحساب به.