لا تحتاج Pandas إلى مقدمة: اليوم هي الأداة الرئيسية لتحليل البيانات في Python. أنا أعمل كأخصائي تحليل بيانات ، وعلى الرغم من أنني أستخدم الباندا كل يوم ، إلا أنني لا أتفاجأ أبدًا بتنوع وظائف هذه المكتبة. في هذه المقالة ، أود أن أتحدث عن خمس وظائف الباندا غير المعروفة التي تعلمتها مؤخرًا وتستخدمها الآن بشكل منتج.للمبتدئين: Pandas هي مجموعة أدوات عالية الأداء لتحليل البيانات في Python مع هياكل بيانات بسيطة ومريحة. يأتي الاسم من مفهوم "بيانات اللوحة" ، وهو مصطلح اقتصادي يشير إلى البيانات الخاصة بملاحظات الموضوعات نفسها على مدار فترات زمنية مختلفة.هنا يمكنك تنزيل Jupyter Notebook مع أمثلة من المقالة.1. نطاقات التواريخ [نطاقات التواريخ]
غالبًا ما تحتاج إلى تحديد نطاقات زمنية عند طلب البيانات من واجهة برمجة تطبيقات أو قاعدة بيانات خارجية. لن يتركنا الباندا في ورطة. بالنسبة لهذه الحالات فقط ، توجد وظيفة data_range ، والتي تُرجع مجموعة من التواريخ التي تم زيادة عدد الأيام ، والأشهر ، والسنوات ، وما إلى ذلك.لنفترض أننا بحاجة إلى نطاق زمني حسب اليوم:date_from = "2019-01-01"
date_to = "2019-01-12"
date_range = pd.date_range(date_from, date_to, freq="D")
date_range
 سنقوم بتحويل المتولد من
سنقوم بتحويل المتولد من date_rangeأزواج التواريخ "من" و "إلى" ، والتي يمكن نقلها إلى الوظيفة المقابلة.for i, (date_from, date_to) in enumerate(zip(date_range[:-1], date_range[1:]), 1):
date_from = date_from.date().isoformat()
date_to = date_to.date().isoformat()
print("%d. date_from: %s, date_to: %s" % (i, date_from, date_to))
1. date_from: 2019-01-01, date_to: 2019-01-02
2. date_from: 2019-01-02, date_to: 2019-01-03
3. date_from: 2019-01-03, date_to: 2019-01-04
4. date_from: 2019-01-04, date_to: 2019-01-05
5. date_from: 2019-01-05, date_to: 2019-01-06
6. date_from: 2019-01-06, date_to: 2019-01-07
7. date_from: 2019-01-07, date_to: 2019-01-08
8. date_from: 2019-01-08, date_to: 2019-01-09
9. date_from: 2019-01-09, date_to: 2019-01-10
10. date_from: 2019-01-10, date_to: 2019-01-11
11. date_from: 2019-01-11, date_to: 2019-01-12
2. الدمج مع مؤشر المصدر [الدمج مع المؤشر]
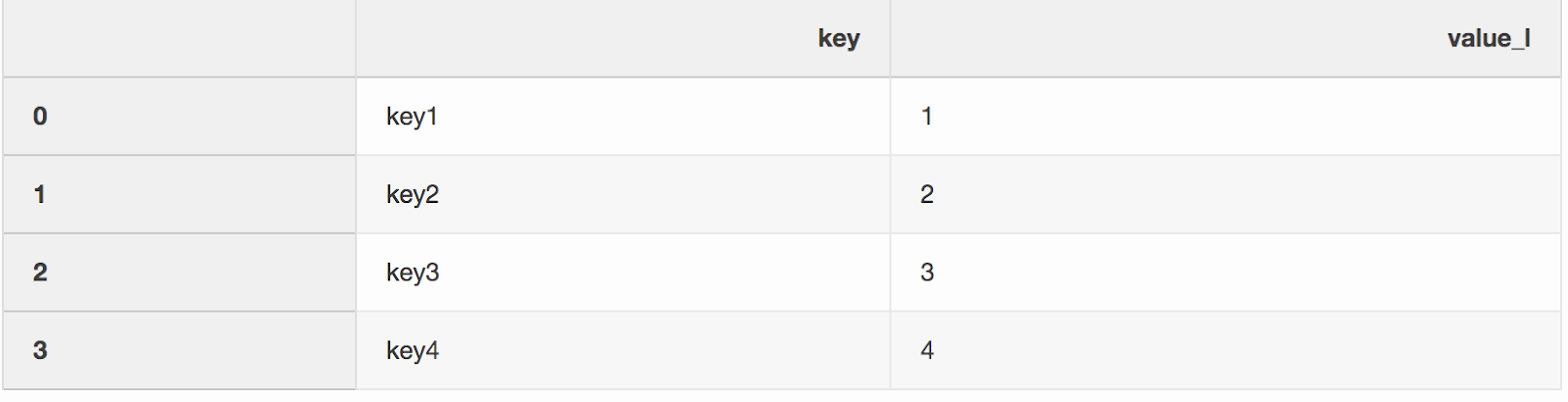
من الغريب أن يكون دمج مجموعتي بيانات هو عملية دمج مجموعتي بيانات في واحدة تم تعيين صفوفهما بناءً على الأعمدة أو الخصائص المشتركة.واحدة من الحجج إلى دالة الدمج ، التي فاتني بطريقة أو بأخرى ، هي indicator. يضيف "المؤشر" عمودًا _mergeإلى DataFrame يوضح من أين جاء الصف أو من اليسار أو اليمين أو كل من إطارات البيانات. _mergeيمكن أن يكون العمود مفيدًا جدًا عند العمل مع مجموعات بيانات كبيرة للتحقق من صحة الدمج.left = pd.DataFrame({"key": ["key1", "key2", "key3", "key4"], "value_l": [1, 2, 3, 4]})
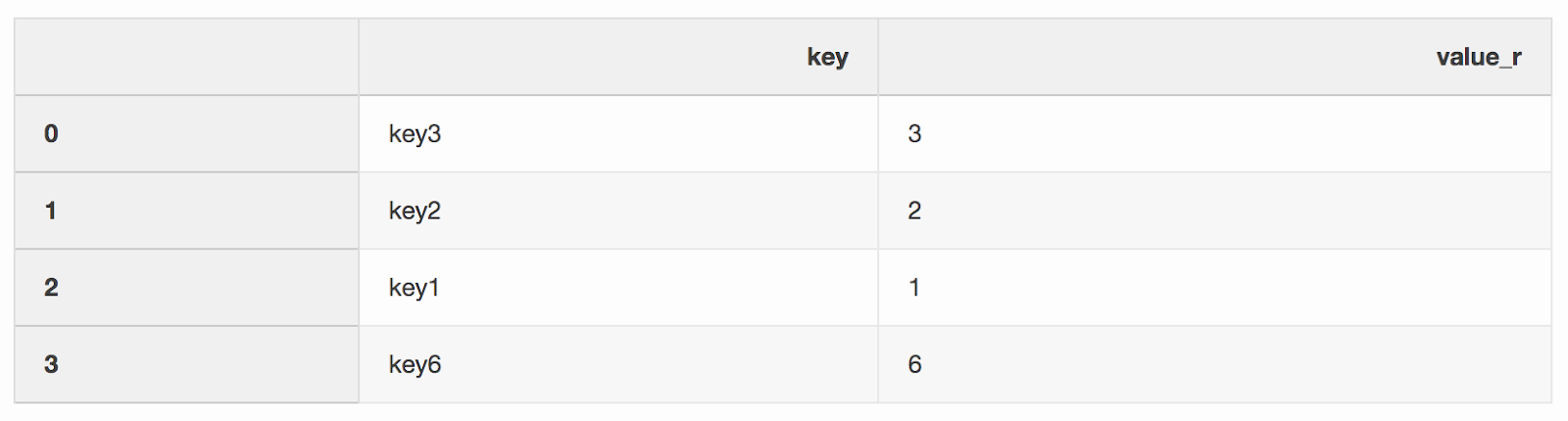
right = pd.DataFrame({"key": ["key3", "key2", "key1", "key6"], "value_r": [3, 2, 1, 6]})
df_merge = left.merge(right, on='key', how='left', indicator=True)
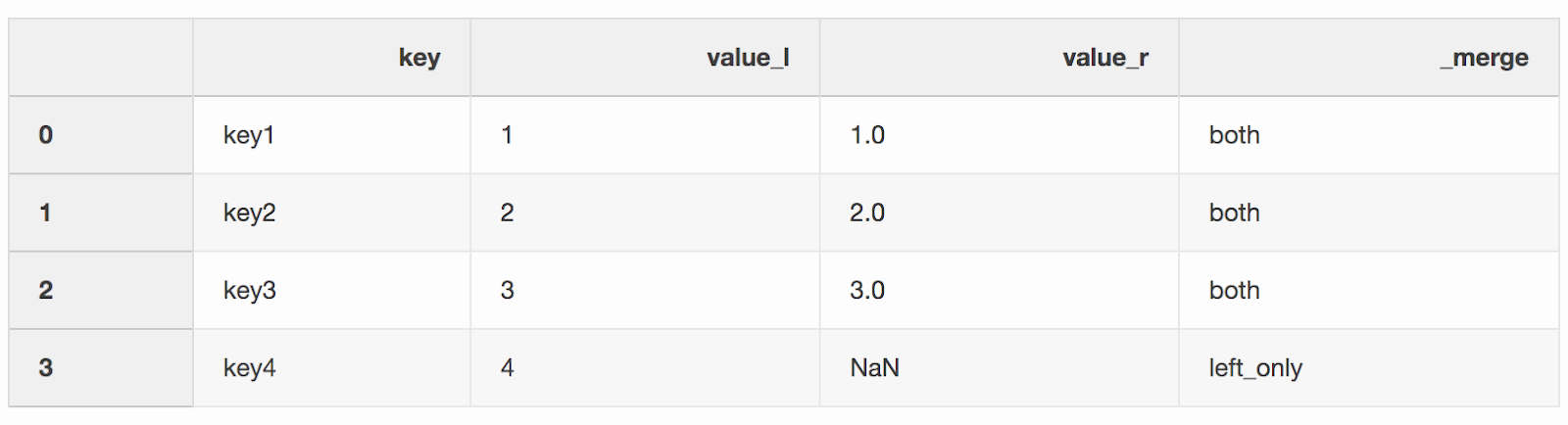
_mergeيمكن استخدام العمود للتحقق مما إذا تم أخذ العدد الصحيح للصفوف مع البيانات من كل من DataFrames.df_merge._merge.value_counts()
both 3
left_only 1
right_only 0
Name: _merge, dtype: int64
3. الدمج بأقرب قيمة [الدمج الأقرب]
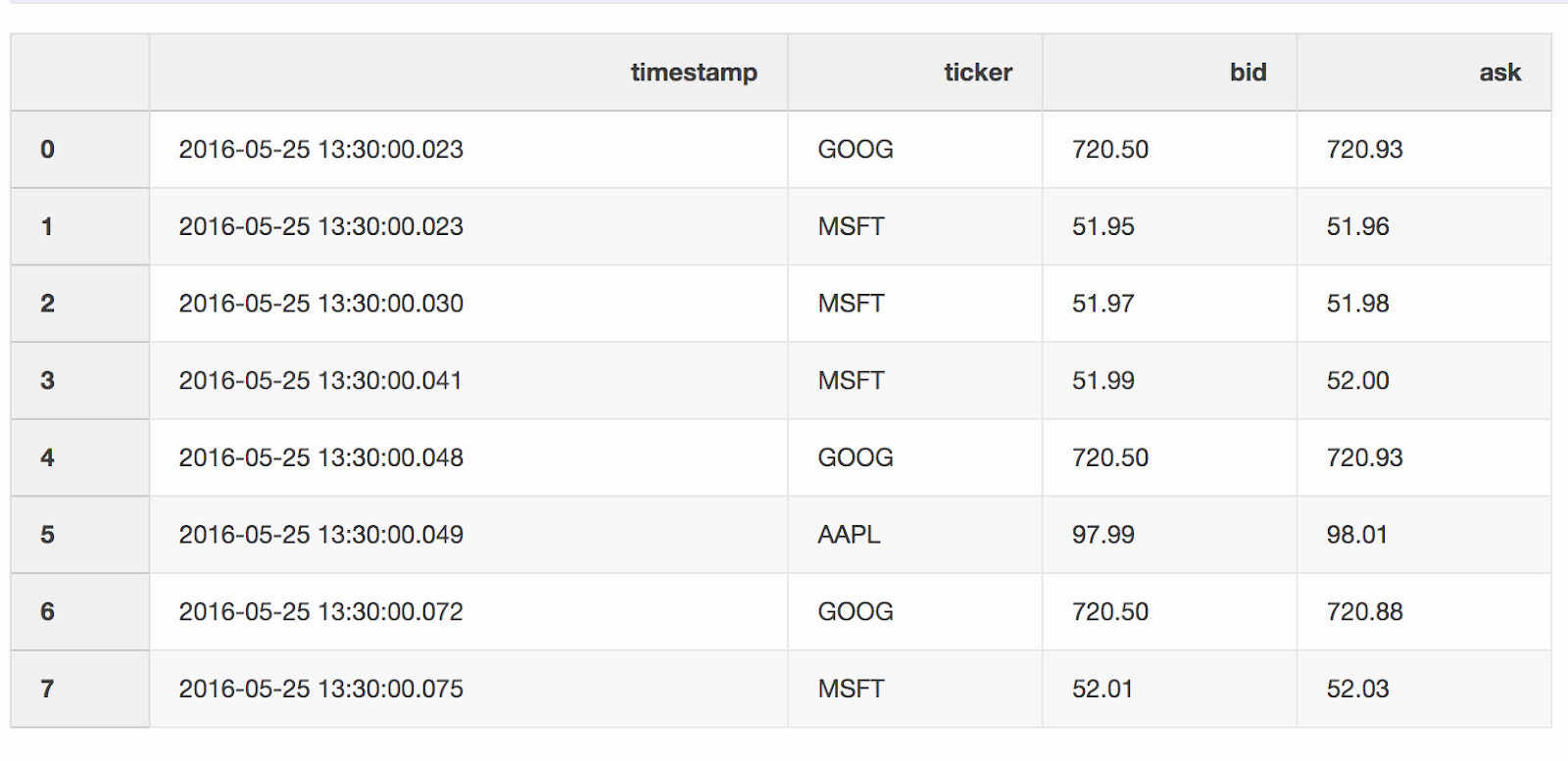
عند العمل مع البيانات المالية ، مثل العملات المشفرة والأوراق المالية ، قد يكون من الضروري مقارنة عروض الأسعار (تغيرات الأسعار) بالمعاملات. لنفترض أننا نريد دمج كل صفقة مع عرض أسعار تم تحديثه قبل بضع ثوانٍ من التجارة. تحتوي Pandas على وظيفة merge_asofيمكن من خلالها دمج DataFrames بأقرب قيمة رئيسية ( timestampفي حالتنا). مجموعات البيانات مع الاقتباسات والصفقات مأخوذة من مثال الباندا .يحتوي DataFrame quotes("عروض الأسعار") على تغيرات أسعار الأسهم المختلفة. كقاعدة عامة ، هناك اقتباسات أكثر بكثير من الصفقات.quotes = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.023", "MSFT", 51.95, 51.96],
["2016-05-25 13:30:00.030", "MSFT", 51.97, 51.98],
["2016-05-25 13:30:00.041", "MSFT", 51.99, 52.00],
["2016-05-25 13:30:00.048", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.049", "AAPL", 97.99, 98.01],
["2016-05-25 13:30:00.072", "GOOG", 720.50, 720.88],
["2016-05-25 13:30:00.075", "MSFT", 52.01, 52.03],
],
columns=["timestamp", "ticker", "bid", "ask"],
)
quotes['timestamp'] = pd.to_datetime(quotes['timestamp'])
tradesيحتوي DataFrame على صفقات للأسهم المختلفة.trades = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "MSFT", 51.95, 75],
["2016-05-25 13:30:00.038", "MSFT", 51.95, 155],
["2016-05-25 13:30:00.048", "GOOG", 720.77, 100],
["2016-05-25 13:30:00.048", "GOOG", 720.92, 100],
["2016-05-25 13:30:00.048", "AAPL", 98.00, 100],
],
columns=["timestamp", "ticker", "price", "quantity"],
)
trades['timestamp'] = pd.to_datetime(trades['timestamp'])
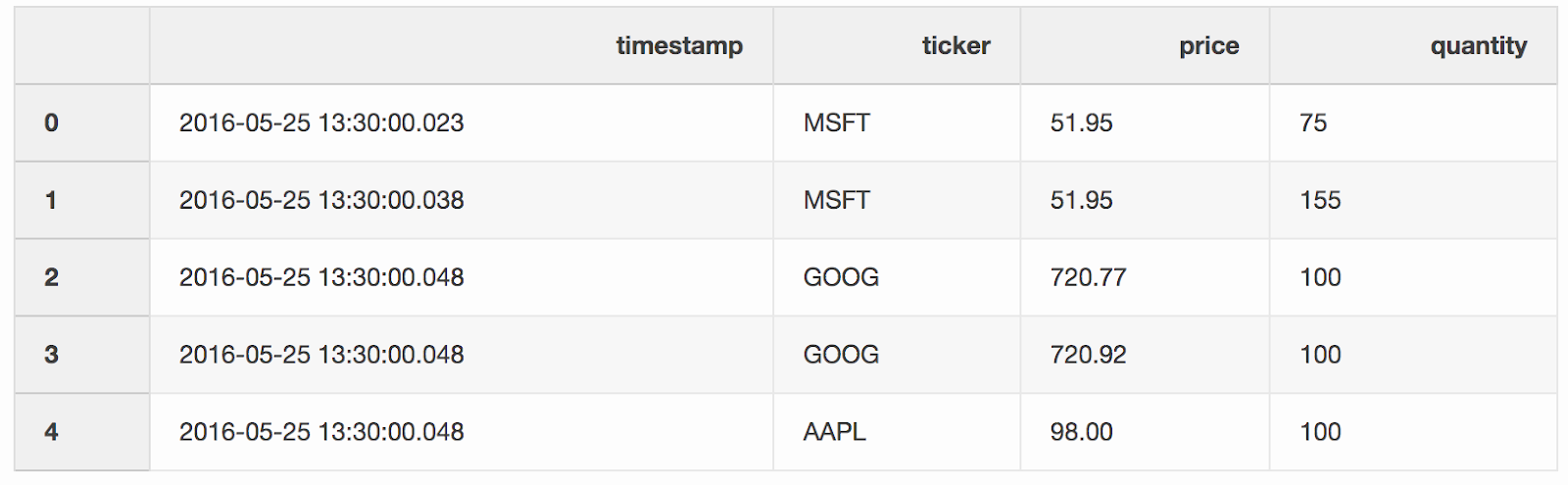 نقوم بدمج المعاملات وعروض الأسعار بواسطة المؤشرات (أداة مسعرة ، مثل الأسهم) ، شريطة أن يكون
نقوم بدمج المعاملات وعروض الأسعار بواسطة المؤشرات (أداة مسعرة ، مثل الأسهم) ، شريطة أن يكون timestampآخر عرض أسعار أقل بـ 10 مللي ثانية من المعاملة. إذا ظهر عرض الأسعار قبل المعاملة لأكثر من 10 مللي ثانية ، فإن العرض (السعر الذي يكون المشتري جاهزًا للدفع) والسؤال (السعر الذي يكون البائع جاهزًا لبيعه) لهذا العرض سيكون null(مؤشر AAPL في هذا المثال).pd.merge_asof(trades, quotes, on="timestamp", by='ticker', tolerance=pd.Timedelta('10ms'), direction='backward')

4. إنشاء تقرير Excel
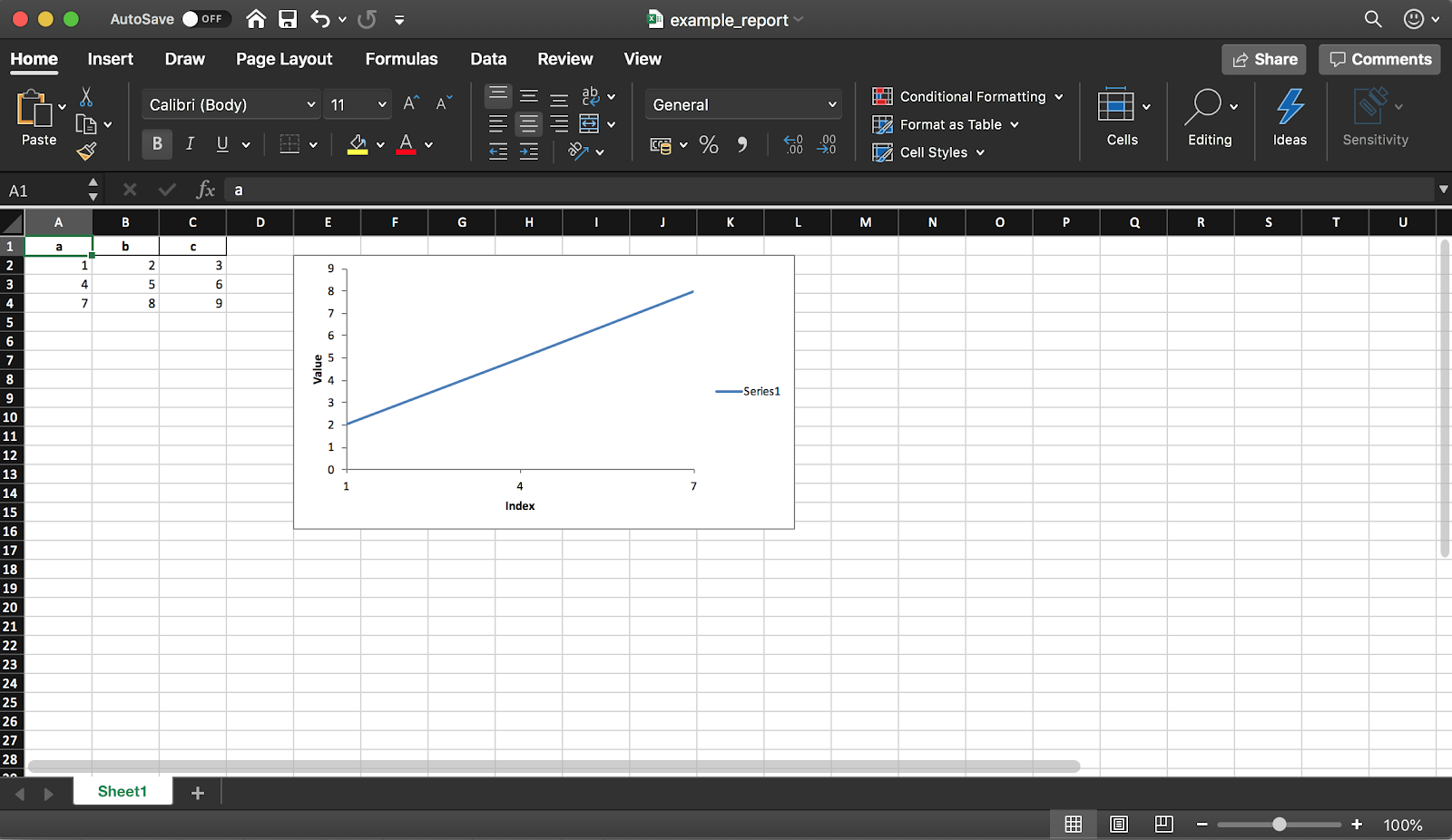 يسمح لك Pandas (مع مكتبة XlsxWriter) بإنشاء تقرير Excel من DataFrame. هذا يوفر لك الكثير من الوقت - لا مزيد من تصدير DataFrame إلى CSV والتنسيق اليدوي إلى Excel. جميع أنواع الرسوم البيانية ، إلخ متوفرة أيضا .
يسمح لك Pandas (مع مكتبة XlsxWriter) بإنشاء تقرير Excel من DataFrame. هذا يوفر لك الكثير من الوقت - لا مزيد من تصدير DataFrame إلى CSV والتنسيق اليدوي إلى Excel. جميع أنواع الرسوم البيانية ، إلخ متوفرة أيضا .df = pd.DataFrame(pd.np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=["a", "b", "c"])
ينشئ مقتطف الرمز أدناه جدولًا بتنسيق Excel. uncomment السطر لحفظه في ملف writer.save().report_name = 'example_report.xlsx'
sheet_name = 'Sheet1'
writer = pd.ExcelWriter(report_name, engine='xlsxwriter')
df.to_excel(writer, sheet_name=sheet_name, index=False)
كما ذكرنا سابقًا ، باستخدام المكتبة ، يمكنك أيضًا إضافة مخططات إلى التقرير. تحتاج إلى تعيين نوع المخطط (الخطي في مثالنا) ونطاق البيانات الخاص به (يجب أن يكون نطاق البيانات في جدول Excel).
workbook = writer.book
worksheet = writer.sheets[sheet_name]
chart = workbook.add_chart({'type': 'line'})
chart.add_series({
'categories': [sheet_name, 1, 0, 3, 0],
'values': [sheet_name, 1, 1, 3, 1],
})
chart.set_x_axis({'name': 'Index', 'position_axis': 'on_tick'})
chart.set_y_axis({'name': 'Value', 'major_gridlines': {'visible': False}})
worksheet.insert_chart('E2', chart)
writer.save()
5. توفير مساحة القرص
عادة ما يترك العمل على عدد كبير من مشاريع تحليل البيانات علامة في شكل كمية كبيرة من البيانات المعالجة من تجارب مختلفة. تمتلئ SSD على الكمبيوتر المحمول بسرعة كبيرة. يسمح لك Pandas بضغط البيانات أثناء حفظ البيانات على القرص ثم قراءتها مرة أخرى من تنسيق مضغوط.إنشاء إطار DataFrame كبير بأرقام عشوائية.df = pd.DataFrame(pd.np.random.randn(50000,300))
 إذا قمت بحفظه كملف CSV ، فسوف يستهلك الملف 300 ميجابايت تقريبًا على محرك الأقراص الثابتة.
إذا قمت بحفظه كملف CSV ، فسوف يستهلك الملف 300 ميجابايت تقريبًا على محرك الأقراص الثابتة.df.to_csv('random_data.csv', index=False)
compression='gzip'تقلل إحدى الوسيطات حجم الملف إلى 136 ميغابايت.df.to_csv('random_data.gz', compression='gzip', index=False)
تتم قراءة الملف المضغوط بنفس طريقة قراءة الملف العادي ، لذلك لا نفقد أي وظيفة.df = pd.read_csv('random_data.gz')
استنتاج
زادت هذه الحيل الصغيرة من إنتاجية عملي اليومي مع الباندا. آمل أن تكون قد تعلمت من هذه المقالة حول بعض الميزات المفيدة التي ستساعدك على أن تصبح أكثر إنتاجية أيضًا.ما هي خدعتك المفضلة مع الباندا؟