لم يكن متأكدًا من أنه سمع بشكل صحيح. اعتمد على ذلك كثيرا! ولكن لا تسأل مرة أخرى؟ (ج) بوريس اكونين. العالم كله مسرح.
أثناء العمل على المساعد الصوتي الذي ورد ذكره في المقالة السابقة ، أدركت أنه لا يسعني إلا أن أشارك مكتبة FuzzyWuzzy الجميلة معك .باختصار ، بفضلها ، من الممكن إجراء مقارنة سلسلة غامضة دون أي معاناة.الخطوات الأولى
للبدء ، تحتاج إلى القيام بخطوتين:/ هام! Python الإصدار 2.7 وأعلى /الخطوة 1. التثبيت.افتح سطر الأوامر وأدخل:pip install fuzzywuzzy
اضغط دخول.بعد ذلك ، قم بتثبيت python-Levenshtein بنفس الطريقة لتسريع مطابقة السلسلة بمقدار 3-10 مرات.pip install python-Levenshtein
بعد اكتمال التثبيت ، تكون المكتبة جاهزة للاستيراد.الخطوة 2. الاستيراد في المشروع.from fuzzywuzzy import fuzz
from fuzzywuzzy import process
وظيفي
1. المقارنة الأكثر شيوعًا:a = fuzz.ratio(' ', ' ')
print(a)
إذا قمنا بتغيير زوجين من الأحرف ، فسيحصل الناتج على رقم مختلف.a = fuzz.ratio(' ', ' ')
print(a)
2. المقارنة الجزئية:يبحث هذا النوع من المقارنة في السطر الثاني بأكمله عن تطابق مع السطر الأول ، على سبيل المثال:a = fuzz.partial_ratio(' ', ' !')
print(a)
أوa = fuzz.partial_ratio(' ', ' , ')
print(a)
ولكن يجب أن تتذكر السجل منذ ذلك الحينa = fuzz.partial_ratio(' ', ' , ')
print(a)
3. مقارنةالرمز 1)تتم مقارنة الكلمات فرز فرز الرمز مع بعضها البعض ، بغض النظر عن الحالة أو الترتيبa = fuzz.token_sort_ratio(' ', ' ')
print(a)
a = fuzz.token_sort_ratio(' ', ' ')
print(a)
a = fuzz.token_sort_ratio('1 2 ', '1 2 ')
print(a)
2) نسبة تعيين الرمز المميزهذه المقارنة ، على عكس الماضي ، تساوي السلاسل ، إذا كان اختلافهم هو تكرار الكلمات.a = fuzz.token_set_ratio(' ', ' ')
print(a)
4. مقارنة منتظمة متقدمةفي كثير من الحالات ، من الأنسب استخدام WRatio ، لأنه حساس لحالة الأحرف وعلامات الترقيم (وليس تقسيم السلسلة)a = fuzz.WRatio(' ', '! !')
print(a)
a = fuzz.WRatio(' ', '!, !')
print(a)
5. العمل مع القائمةلمقارنة السطور مع الخطوط من القائمة ، يتم استخدام وحدة العمليةcity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extract("", city, limit=2)
print(a)
إذا كانت هناك حاجة إلى أول واحد فقط في القائمة ، فمن الأفضل استخدام extractOnecity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extractOne("", city)
print(a)
تطبيق
كيف وأين يتم تطبيق كل ما سبق متروك لك ، ولكن هنا مثال من ورقة المصطلح الخاصة بي :
try:
files = os.listdir('C:\\Users\\hartp\\Desktop\\')
filestart = process.extractOne(namerec, files)
if filestart[1] >= 80:
os.startfile('C:\\Users\\hartp\\Desktop\\' + filestart[0])
else:
speak(' ')
except FileNotFoundError:
speak(' ')
دعنا نراجع الرمز ونفهم ما هو. باستخدامالأمر os.listdir ، نحصل على قائمة بجميع الملفات الموجودة في نهاية المسار المحدد (في حالتنا ، إلى سطح المكتب).files = os.listdir('C:\\Users\\hartp\\Desktop\\')
print(files)
التالي هو مقارنة أسطر قائمة الملفات مع اسم الملف المسمى المستخدم (متغير namerec ). أتمنى أن تكون قد لاحظت أن نتيجة الدالة extractOne هي مجموعة من السلسلة والرقم (مؤشر التشابه)مثال من الفصل الأخيرcity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extractOne("", city)
print(a)
.
بناءً على ذلك ، نتحقق من ملف مؤشر التشابه [1]> = 80 ([1] ، نظرًا لأن المجموعة tuple مرقمة من 0 ، كما هو الحال في الصفيف) ، وإذا كان الشرط صحيحًا ، فقم بتشغيل وظيفة os.startfile بملف يسمى filestart [0 ]. خلاف ذلك ، إذا كان مؤشر التشابه أقل من 80 أو حدث خطأ في عدم العثور على الملف ، فإننا نبلغ المستخدم من خلال وظيفة التحدث .جميع الطرق تؤدي إلى ماتان
مخبأة عن الناس الذين يخافون من الرياضيات, , ().
, .
( , ) — , .
S1 i S2 j
S1=vrhk
S2=rhgr
3 :
- : r → v
- : -r
- : rVhgr
:

0 1? ( — «0»), r , r ( , — «1»). v .
rh h, r ( ), , :
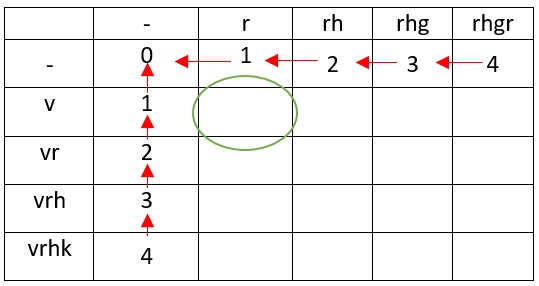
v r ( ).
, — v.
1. ? r , v. r , v, rv. , v v.
v rh
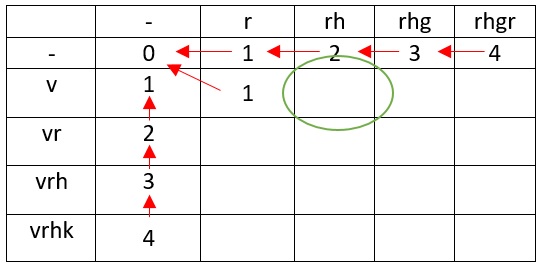
— v h r .
.
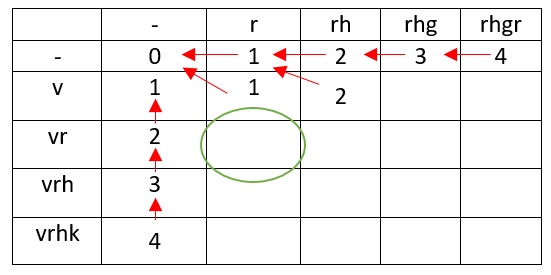
vr r , , , , .
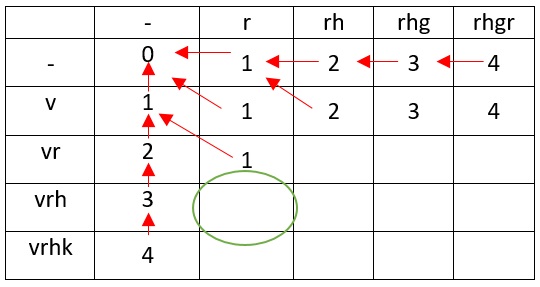
vrh r h ( vr r), 2

vr r vrh rh, , .
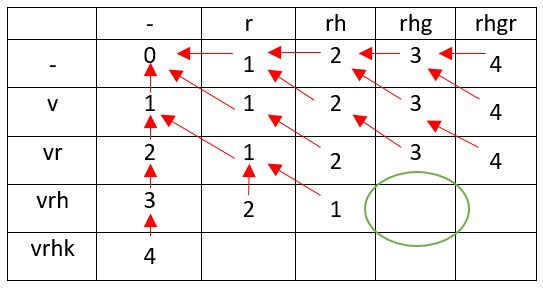
, vrh rhg , , , - ( ).
, , ( ) — vrhk rhgr.
شكرا لكم جميعا على اهتمامكم! آمل أن تكون هذه المقالة مفيدة لشخص ما.