يسجل الآلاف من المديرين من مكاتب المبيعات في جميع أنحاء البلاد عشرات الآلاف من جهات الاتصال في نظام إدارة علاقات العملاء لدينا كل يوم - حقائق التواصل مع العملاء المحتملين أو الذين يعملون بالفعل معنا. وبالنسبة لهذا العميل ، يجب عليك أولاً العثور عليه ، ويفضل أن يكون ذلك بسرعة كبيرة. وهذا يحدث في الغالب بالاسم.لذلك ، ليس من المستغرب أنه بعد تحليل الطلبات "الثقيلة" مرة أخرى في إحدى قواعد البيانات الأكثر تحميلًا - حساب VLSI الخاص بشركتنا ، وجدت "في الأعلى" طلبًا للبحث "السريع" بالاسم لبطاقات الشركة.علاوة على ذلك ، كشف تحقيق آخر عن مثال مثير للاهتمام للتحسين ثم تدهور الأداء طلب في صقلها اللاحق من قبل العديد من الفرق ، كل منها تصرف فقط من حسن النية.0: ماذا يريد المستخدم
[KDPV من هنا ]ماذا يعني المستخدم عادة عندما يقول البحث "السريع" بالاسم؟ أبدا تقريبا اتضح أن تكون "صادقة" البحث على سلسلة فرعية من نوع ... LIKE '%%'- لأننا عندئذ ليس فقط و ، ولكن حتى حتى الحصول على النتيجة . يشير المستخدم على مستوى الأسرة إلى أنك ستزوده ببحث في بداية كلمة في العنوان وتظهر أكثر صلة بما يبدأ بكلمة تم إدخالها. ونفعل ذلك على الفور تقريبًا - مع إدخال بين السطور.''' '''' '1: تحديد المهمة
وأكثر من ذلك ، لن يدخل الشخص على وجه التحديد ' 'بحيث يكون عليك البحث عن كل بادئة لكلمة. لا ، يسهل على المستخدم الاستجابة لتلميح سريع للكلمة الأخيرة بدلاً من "فقدان" الكلمات السابقة عمداً - انظر كيف يعمل أي محرك بحث.بشكل عام ، فإن صياغة متطلبات المهمة بشكل صحيح هو أكثر من نصف الحل. في بعض الأحيان يمكن أن يؤثر التحليل الدقيق لحالة الاستخدام بشكل كبير على النتيجة .ماذا يفعل المطور المجرد؟1.0: محرك بحث خارجي
أوه ، البحث صعب ، لا أريد أن أفعل أي شيء على الإطلاق - دعنا نعطيه للمطورين! دعهم ينشرون لنا محرك بحث خارجي بالنسبة لقاعدة البيانات: Sphinx ، ElasticSearch ، ...خيار عمل ، وإن كان مضيعة للوقت ، من حيث المزامنة وسرعة التغيير. ولكن ليس في حالتنا ، حيث يتم البحث عن كل عميل فقط في إطار بيانات حسابه. ولدى البيانات تنوع كبير إلى حد ما - وإذا كان المدير قد أدخل البطاقة الآن ' '، فيمكنه بعد 5-10 ثوانٍ أن يتذكر بالفعل أنه نسي الإشارة إلى البريد الإلكتروني هناك ويريد العثور عليه وتصحيحه.لذلك - دعنا نبحث "مباشرة في قاعدة البيانات" . لحسن الحظ ، تتيح لنا PostgreSQL القيام بذلك ، وليس خيارًا واحدًا فقط - سننظر فيها.1.1: سلسلة فرعية "صادقة"
نحن نتمسك بكلمة "سلسلة فرعية". ولكن بالضبط للبحث عن الفهرس بواسطة السلاسل الفرعية (وحتى بالتعبيرات العادية!) هناك وحدة ممتازة pg_trgm ! عندها فقط سيكون من الضروري الفرز بشكل صحيح.دعنا نحاول أن نأخذ لوحة من أجل بساطة النموذج:CREATE TABLE firms(
id
serial
PRIMARY KEY
, name
text
);
نملأ 7.8 مليون سجل للمنظمات والفهرس الحقيقيين:CREATE EXTENSION pg_trgm;
CREATE INDEX ON firms USING gin(lower(name) gin_trgm_ops);
دعونا نبحث عن أول 10 إدخالات للبحث بين السطور:SELECT
*
FROM
firms
WHERE
lower(name) ~ ('(^|\s)' || '')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
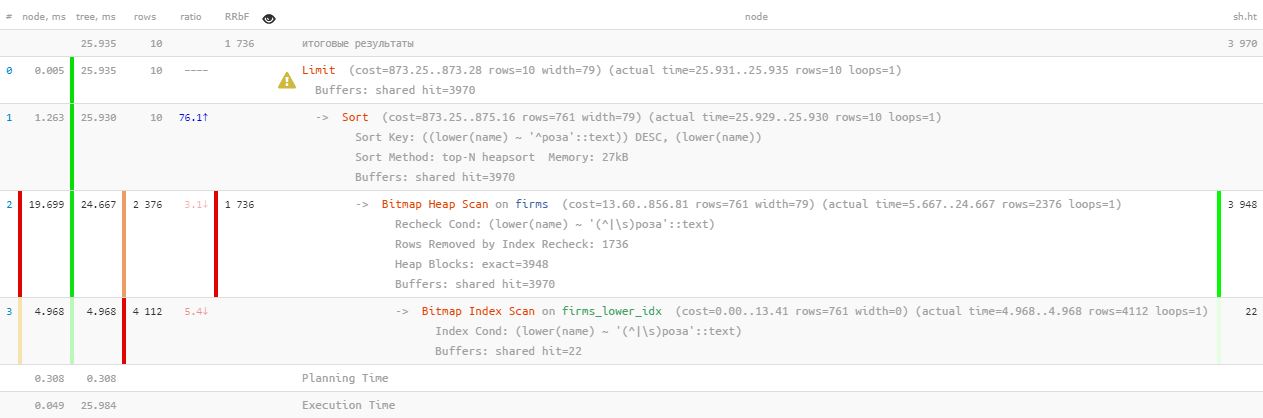 [إلقاء نظرة على Expl.tensor.ru]حسنًا ، هذا ... 26 مللي ثانية و 31 ميغابايت من البيانات المقروءة وأكثر من 1.7 ألف سجل مُصفى - لـ 10 أشخاص. النفقات العامة مرتفعة للغاية ، هل من الممكن أن تكون أكثر كفاءة بطريقة ما؟
[إلقاء نظرة على Expl.tensor.ru]حسنًا ، هذا ... 26 مللي ثانية و 31 ميغابايت من البيانات المقروءة وأكثر من 1.7 ألف سجل مُصفى - لـ 10 أشخاص. النفقات العامة مرتفعة للغاية ، هل من الممكن أن تكون أكثر كفاءة بطريقة ما؟1.2: البحث عن نص؟ إنه FTS!
في الواقع ، يوفر PostgreSQL آلية قوية جدًا للبحث عن النص الكامل (بحث النص الكامل) ، بما في ذلك القدرة على إضافة البادئة إلى البحث. خيار رائع ، حتى الملحقات لا تحتاج إلى تثبيت! لنجرب:CREATE INDEX ON firms USING gin(to_tsvector('simple'::regconfig, lower(name)));
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
 [إلقاء نظرة على Expl.tensor.ru]هنا ساعدنا موازاة تنفيذ الاستعلام قليلاً ، مما قلل الوقت بمقدار النصف إلى 11 مللي ثانية . نعم ، وكان علينا أن نقرأ أقل 1.5 مرة - 20 ميغابايت فقط . وهنا ، كلما كان أصغر كلما كان ذلك أفضل ، لأنه كلما زاد المبلغ الذي نطرحه ، زادت فرص فقدان ذاكرة التخزين المؤقت ، وكل صفحة بيانات إضافية تتم قراءتها من القرص هي "مكبح" محتمل للطلب.
[إلقاء نظرة على Expl.tensor.ru]هنا ساعدنا موازاة تنفيذ الاستعلام قليلاً ، مما قلل الوقت بمقدار النصف إلى 11 مللي ثانية . نعم ، وكان علينا أن نقرأ أقل 1.5 مرة - 20 ميغابايت فقط . وهنا ، كلما كان أصغر كلما كان ذلك أفضل ، لأنه كلما زاد المبلغ الذي نطرحه ، زادت فرص فقدان ذاكرة التخزين المؤقت ، وكل صفحة بيانات إضافية تتم قراءتها من القرص هي "مكبح" محتمل للطلب.1.3: هل مازلت ترغب؟
الطلب السابق جيد للجميع ، ولكن فقط إذا قمت بسحبه مائة ألف مرة في اليوم ، فسيتم تشغيل 2 تيرابايت من البيانات المقروءة. في أحسن الأحوال - من الذاكرة ، ولكن إذا لم تكن محظوظًا ، فمن القرص. لذا دعنا نجعله أصغر.تذكر أن المستخدم يريد أن يرى أولاً "يبدأ بـ ..." . لذلك هذا هو في شكله النقي ل بحث بادئة مع text_pattern_ops! وفقط إذا كنا "غير كافيين" حتى 10 سجلات مطلوبة ، فسوف نضطر لقراءتها باستخدام بحث FTS:CREATE INDEX ON firms(lower(name) text_pattern_ops);
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
LIMIT 10;
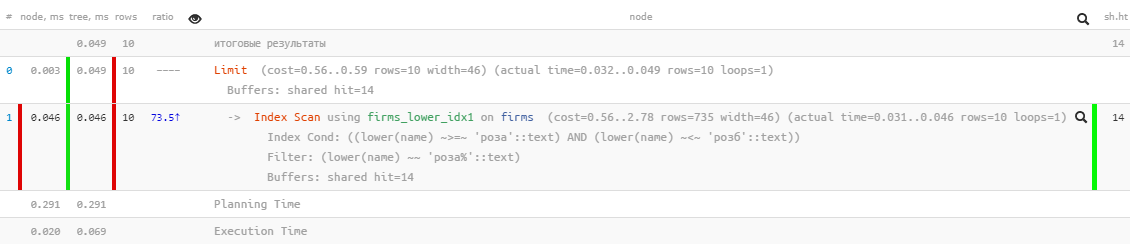 [انظر إلى شرح.tensor.ru]أداء ممتاز - فقط 0.05 مللي ثانية وقراءة تزيد قليلاً عن 100 كيلوبايت ! فقط نسينا الفرز حسب الاسم حتى لا يضيع المستخدم في النتائج:
[انظر إلى شرح.tensor.ru]أداء ممتاز - فقط 0.05 مللي ثانية وقراءة تزيد قليلاً عن 100 كيلوبايت ! فقط نسينا الفرز حسب الاسم حتى لا يضيع المستخدم في النتائج:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name)
LIMIT 10;
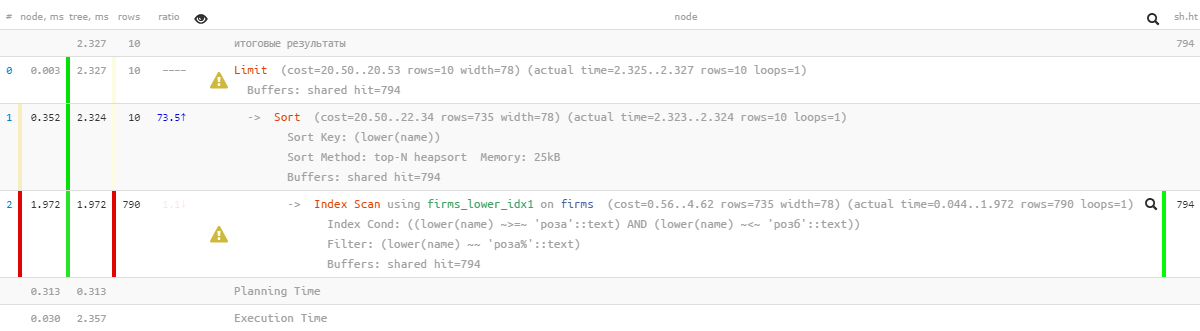 [انظر إلى شرح.tensor.ru]أوه ، لم يعد هناك شيء جميل جدًا - يبدو أن هناك فهرسًا ، ولكن فرز الذباب تجاوزه ... بالطبع ، هو بالفعل أكثر فعالية عدة مرات من الإصدار السابق ، ولكن ...
[انظر إلى شرح.tensor.ru]أوه ، لم يعد هناك شيء جميل جدًا - يبدو أن هناك فهرسًا ، ولكن فرز الذباب تجاوزه ... بالطبع ، هو بالفعل أكثر فعالية عدة مرات من الإصدار السابق ، ولكن ...1.4: "تعديل بملف"
ولكن هناك فهرس يسمح لك بالبحث حسب النطاق ، ومن الطبيعي استخدام الفرز - btree العادي !CREATE INDEX ON firms(lower(name));
يجب فقط "تجميعه يدويًا" لطلب الحصول عليه:SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10;
 [إلقاء نظرة على Expl.tensor.ru]رائع - تظل كل من أعمال الفرز واستهلاك الموارد "مجهرية" ، وأكثر كفاءة بآلاف المرات من FTS "النقي" ! يبقى أن نجمع في طلب واحد:
[إلقاء نظرة على Expl.tensor.ru]رائع - تظل كل من أعمال الفرز واستهلاك الموارد "مجهرية" ، وأكثر كفاءة بآلاف المرات من FTS "النقي" ! يبقى أن نجمع في طلب واحد:(
SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*') AND
lower(name) NOT LIKE ('' || '%')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10
)
LIMIT 10;
ألاحظ أن الاستعلام الفرعي الثاني يتم تنفيذه فقط إذا أرجع الأول أقل منLIMIT عدد الصفوف المتوقعة قبل الأخير . لقد كتبت بالفعل عن طريقة تحسين الاستعلام هذه .لذا نعم ، لدينا الآن btree و gin على الطاولة في نفس الوقت ، ولكن اتضح إحصائيًا أن أقل من 10 ٪ من الطلبات تصل إلى الكتلة الثانية . أي ، مع هذه القيود النموذجية المعروفة للمهمة ، تمكنا من تقليل إجمالي استهلاك موارد الخادم بما يقرب من ألف مرة!1.5 *: الاستغناء عن الملف
أعلاه LIKEتم منعنا من استخدام النوع الخاطئ. ولكن يمكن "تعيينه على المسار الصحيح" عن طريق تحديد عبارة الاستخدام:يعني الافتراضي ASC. بالإضافة إلى ذلك ، يمكنك تحديد اسم عامل فرز محدد في جملة USING. يجب أن يكون عامل الفرز عضوًا أقل من أو أكبر من عائلة معينة من عوامل تشغيل B-tree. ASCعادة ما يعادلها USING <و DESCتعادل عادة USING >.
في حالتنا ، "أقل" هو ~<~:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name) USING ~<~
LIMIT 10;
 [انظر إلى شرح.tensor.ru]
[انظر إلى شرح.tensor.ru]2: كيف "تعكر" الطلبات
الآن نترك طلبنا "للإصرار" لمدة نصف عام أو عام ، ومما يثير الدهشة أننا نجدها مرة أخرى "في الأعلى" بمؤشرات "الضخ" اليومي للذاكرة ( الضرب المشترك للمخازن المؤقتة ) في 5.5 تيرابايت - أي أكثر مما كانت عليه في الأصل.لا ، بالطبع ، نما عملنا ، وزاد الحمل ، ولكن ليس كثيرًا! لذلك هناك شيء قذر هنا - فلنتعرف عليه.2.1: ولادة الترحيل
في مرحلة ما ، أراد فريق تطوير آخر أن يجعل من الممكن "القفز" إلى التسجيل من بحث منخفض سريع بنفس النتائج ، ولكن مع توسيع النتائج. وما التسجيل بدون التنقل الصفحة؟ دعونا المسمار!( ... LIMIT <N> + 10)
UNION ALL
( ... LIMIT <N> + 10)
LIMIT 10 OFFSET <N>;
الآن أصبح من الممكن دون جهد للمطور لإظهار سجل نتائج البحث مع تحميل "نوع الصفحة".بالطبع ، في الواقع ، لكل صفحة من البيانات التالية ، تتم قراءة المزيد والمزيد (كل الوقت السابق ، الذي نتجاهله ، بالإضافة إلى "الذيل" المطلوب) - أي أن هذا مضاد مضاد للالتباس. وسيكون من الأصح بدء البحث في التكرار التالي من المفتاح المخزن في الواجهة ، ولكن حوله - مرة أخرى.2.2: تريد الغريبة
في مرحلة ما ، أراد المطور تنويع التحديد الناتج ببيانات من جدول آخر ، ولهذا الغرض تم إرسال الطلب السابق بأكمله إلى CTE:WITH q AS (
...
LIMIT <N> + 10
)
SELECT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
وحتى مع ذلك - ليس سيئًا ، لأنه يتم حساب استعلام فرعي فقط لـ 10 سجلات مرتجعة ، إن لم يكن ...2.3: متميز بلا معنى ولا رحمة
في مكان ما في عملية مثل هذا التطور ، فقدت NOT LIKEحالة من طلب البحث الفرعي الثاني . من الواضح أنه بعد ذلك UNION ALLبدأت بإرجاع بعض السجلات مرتين - تم العثور عليها أولاً في بداية السطر ، ثم مرة أخرى - في بداية الكلمة الأولى من هذا السطر. في الحد ، يمكن أن تتطابق جميع سجلات الاستعلام الفرعي الثاني مع سجلات الأول.ماذا يفعل المطور بدلا من البحث عن سبب؟ .. لا شك!- ضعف حجم العينات الأصلية
- ضع DISTINCT بحيث نحصل على أمثلة واحدة فقط لكل صف
WITH q AS (
( ... LIMIT <2 * N> + 10)
UNION ALL
( ... LIMIT <2 * N> + 10)
LIMIT <2 * N> + 10
)
SELECT DISTINCT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
أي أنه من الواضح أن النتيجة ، في النهاية ، هي نفسها تمامًا ، لكن فرصة "التحليق" إلى استعلام CTE الثاني أصبحت أعلى بكثير ، ومن دون ذلك ، من الواضح أنها تقرأ أكثر .لكن هذا ليس الشيء الأكثر حزنا. نظرًا لأن المطوِّر طلب مني DISTINCTعدم التحديد بشكل محدد ، ولكن فورًا من خلال جميع حقول السجل ، فإن حقل الاستعلام الفرعي - نتيجة الاستعلام الفرعي - قد وصل إلى هناك تلقائيًا. الآن ، من أجل التنفيذ DISTINCT، كان على قاعدة البيانات تنفيذ ليس 10 استعلامات فرعية ، ولكن كل <2 * N> + 10 !2.4: التعاون قبل كل شيء!
لذلك ، عاش المطورون - لم يزعجوا أنفسهم ، لأنهم في السجل "تم إصلاحهم" إلى قيم N المهمة مع تباطؤ مزمن في استقبال كل "صفحة" تالية.حتى وصل إليهم مطورون من قسم آخر ، ولم يرغبوا في استخدام مثل هذه الطريقة المريحة للبحث التكراري - أي أننا نأخذ قطعة من عينة ما ، ونرشحها بشروط إضافية ، ونرسم النتيجة ، ثم القطعة التالية (التي يتم تحقيقها في حالتنا عن طريق زيادة N) ، وهكذا حتى نملأ الشاشة.بشكل عام ، في العينة التي تم التقاطها N وصلت القيم إلى ما يقرب من 17 ألفًا ، وخلال 24 ساعة فقط تم تنفيذ 4K على الأقل من هذه الطلبات "في السلسلة". تم مسح آخر منهم بجرأة بالفعل1 غيغابايت من الذاكرة عند كل تكرار ...