لقد عرفت منذ فترة طويلة موقع Have I Have Pwned (HIBP) . صحيح ، حتى وقت قريب ، لم يكن هناك أبداً. كان لدي دائما كلمتين سر. تم استخدام واحد منهم بشكل متكرر لبريد القمامة واثنين من الحسابات على مواقع غريبة. ولكن كان علي أن أرفض ذلك ، لأنه تم اختراق البريد. ولأكون صادقًا ، أنا ممتن للهاكر لأن هذا الحدث جعلني أراجع كلمات المرور الخاصة بي - الطريقة التي أستخدمها وخزنها.بالطبع ، قمت بتغيير كلمات المرور على جميع الحسابات التي يوجد بها كلمة مرور مخترقة. ثم تساءلت عما إذا كانت كلمة المرور المسربة في قاعدة بيانات HIBP. لم أرغب في إدخال كلمة المرور على الموقع ، لذلك قمت بتنزيل قاعدة البيانات (pwned-passwords-sha1-ordered-by-count-v5) القاعدة مثيرة للإعجاب للغاية. هذا ملف نصي بحجم 22.8 غيغابايت مع مجموعة من تجزئات SHA-1 ، عدد مرات حدوث كلمة المرور مع هذا التجزئة في كل سطر مع عداد. اكتشفت SHA-1 لكلمة مروري المتشققة وحاولت العثور عليها.محتويات
[G] ممثل
لدينا ملف نصي مع تجزئة في كل سطر. ربما يكون أفضل مكان للذهاب هو grep.grep -m 1 '^XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' pwned-passwords-sha1-ordered-by-count-v5.txtكانت كلمة المرور الخاصة بي في أعلى القائمة مع تردد أكثر من 1500 مرة ، لذا فهي سيئة حقًا. تبعا لذلك ، عادت نتائج البحث على الفور تقريبا.ولكن ليس لدى الجميع كلمات مرور ضعيفة. أردت التحقق من الوقت المستغرق للعثور على أسوأ سيناريو - آخر تجزئة في الملف:time grep -m 1 '^4541A1E4605EEBF3F4C166329C18502DF75D348A' pwned-passwords-sha1-ordered-by-count-v5.txtالنتيجة: 33,35s user 23,39s system 41% cpu 2:15,35 totalهذا أمر محزن. بعد كل شيء ، منذ اختراق بريدي ، أردت التحقق من وجود جميع كلمات المرور القديمة والجديدة في قاعدة البيانات. لكن جريب لمدة دقيقتين ببساطة لا يسمح لك بالقيام بذلك بشكل مريح. بالطبع ، يمكنني كتابة نص برمجي وتشغيله والذهاب في نزهة على الأقدام ، ولكن هذا ليس خيارًا. كنت أرغب في إيجاد حل أفضل وتعلم شيء ما.هيكل ثلاثي
كانت الفكرة الأولى هي استخدام بنية بيانات trie. يبدو الهيكل مثاليًا لتخزين تجزئات SHA-1. الأبجدية صغيرة ، وبالتالي فإن العقد ستكون صغيرة ، وكذلك الملف الناتج. ربما تناسبها حتى في ذاكرة الوصول العشوائي؟ يجب أن يكون البحث الأساسي سريعًا جدًا.لذا نفذت هذا الهيكل. ثم أخذ أول 1،000،000 تجزئة من قاعدة البيانات المصدر لبناء الملف الناتج والتحقق مما إذا كان كل شيء في الملف الذي تم إنشاؤه.نعم ، يمكنني العثور على كل شيء في الملف ، لذلك عملت البنية بشكل جيد. كانت المشكلة مختلفة.تم إصدار الملف الناتج بحجم 2283686592B (2.2 جيجابايت). هذا ليس جيدا. دعونا نحسب ونرى ما سيحدث. العقدة هي بنية بسيطة تتكون من ستة عشر قيمًا 32 بت. القيم هي "مؤشرات" إلى العقد التالية برمز تجزئة SHA-1 المحدد. لذلك ، تأخذ عقدة واحدة 16 * 4 بايت = 64 بايت. يبدو أن قليلا؟ ولكن إذا فكرت في الأمر ، فإن العقدة الواحدة تمثل حرفًا واحدًا في التجزئة. وبالتالي ، في أسوأ الحالات ، ستأخذ تجزئة SHA-1 40 * 64 بايت = 2560 بايت. هذا أسوأ بكثير من ، على سبيل المثال ، التمثيل النصي للتجزئة التي تستغرق 40 بايت فقط.يتميز هيكل trie بميزة إعادة استخدام العقد. إذا كان لديك كلمتين aaaو abb، ثم يتم إعادة استخدامها عقدة الأحرف الأولى، لأن الشخصيات هي نفسها - a.دعونا نعود إلى مشكلتنا. دعونا نحسب عدد العقد المخزنة في الملف الناتج: file_size / node_size = 2283686592 / 64 = 35682603الآن دعونا نرى عدد العقد التي سيتم إنشاؤها في أسوأ حالة من مليون تجزئة: 1000000 * 40 = 40000000وبالتالي ، فإن بنية trie تعيد استخدام 40000000 - 35682603 = 4317397العقد فقط ، وهو 10.8 ٪ من السيناريو الأسوأ.بمثل هذه المؤشرات ، سيأخذ الملف الناتج لقاعدة بيانات HIBP بأكملها 1421513361920 بايت (1.02 تيرابايت). ليس لدي ما يكفي من محركات الأقراص الثابتة للتحقق من سرعة البحث الرئيسي.في ذلك اليوم ، اكتشفت أن بنية trie غير مناسبة للبيانات العشوائية نسبيًا.دعونا نبحث عن حل آخر.بحث ثنائي
تحتوي تجزئات SHA-1 على ميزتين جميلتين: يمكن مقارنتهما ببعضهما البعض وجميعهما بنفس الحجم.بفضل هذا ، يمكننا معالجة قاعدة بيانات HIBP الأصلية وإنشاء ملف من قيم SHA-1 المصنفة.ولكن كيف يتم فرز ملف 22 جيجا بايت؟سؤال. لماذا فرز الملف المصدر؟ يقوم HIBP بإرجاع ملف مع سلاسل تم فرزها بالفعل حسب التجزئة.
إجابة. أنا فقط لم أفكر في ذلك. في تلك اللحظة لم أكن أعرف عن الملف الذي تم فرزه.فرز
فرز جميع التجزئة في ذاكرة الوصول العشوائي ليس خيارًا ؛ ليس لدي الكثير من ذاكرة الوصول العشوائي. كان الحل هو:- تقسيم ملف كبير إلى أصغر حجمًا يتناسب مع ذاكرة الوصول العشوائي
- قم بتنزيل البيانات من الملفات الصغيرة ، وفرزها في ذاكرة الوصول العشوائي واكتب مرة أخرى إلى الملفات.
- اجمع كل الملفات الصغيرة والمفروشة في ملف واحد كبير.
باستخدام ملف كبير مفروز ، يمكنك البحث في التجزئة باستخدام بحث ثنائي. الوصول إلى القرص الصلب مهم. دعنا نحسب عدد النتائج المطلوبة في البحث الثنائي: log2(555278657) = 29.0486367039أي 30 نتيجة. لا باس به.في المرحلة الأولى ، يمكن إجراء التحسين. تحويل تجزئات النص إلى بيانات ثنائية. سيؤدي ذلك إلى تقليل حجم البيانات الناتجة إلى النصف: من 22 إلى 11 جيجابايت. غرامة.لماذا الدمج؟
في تلك اللحظة ، أدركت أنه يمكنك القيام بذكاء أكبر. ماذا لو لم تقم بدمج الملفات الصغيرة في ملف واحد كبير ، لكنك قمت بإجراء بحث ثنائي في الملفات الصغيرة التي تم فرزها في ذاكرة الوصول العشوائي؟ تكمن المشكلة في كيفية العثور على الملف المطلوب الذي تبحث فيه عن المفتاح. والحل بسيط جدا. نهج جديد:- أنشئ 256 ملفًا باسم "00" ... "FF".
- عند قراءة التجزئة من ملف كبير ، اكتب التجزئة التي تبدأ بـ "00 .." إلى ملف يسمى "00" ، والتجزئة التي تبدأ بـ "01 .." - إلى ملف "01" وهكذا.
- قم بتنزيل البيانات من الملفات الصغيرة ، وفرزها في ذاكرة الوصول العشوائي واكتب مرة أخرى إلى الملفات.
كل شيء بسيط للغاية. بالإضافة إلى ذلك ، يظهر خيار تحسين آخر. إذا تم تخزين التجزئة في الملف "00" ، فإننا نعلم أنه يبدأ بـ "00". إذا تم تخزين التجزئة في الملف "F2" ، فسيبدأ بالحرف "F2". وبالتالي ، عند كتابة التجزئة إلى الملفات الصغيرة ، يمكننا حذف البايت الأول من كل تجزئة! هذه 5٪ من جميع البيانات. يتم حفظ 555 ميغابايت في المجموع.تماثل
يوفر الفصل في ملفات أصغر فرصة أخرى للتحسين. الملفات مستقلة عن بعضها البعض ، لذلك يمكننا فرزها بالتوازي. نتذكر أن كل معالجاتك تحب التعرق في نفس الوقت ؛)لا تكن لقيط أناني
عندما نفذت الحل المذكور أعلاه ، أدركت أن الآخرين ربما يواجهون مشكلة مماثلة. ربما يقوم العديد من الآخرين أيضًا بتنزيل قاعدة بيانات HIBP والبحث فيها. لذلك قررت مشاركة عملي.قبل ذلك ، قمت مرة أخرى بمراجعة نهجي ووجدت بعض المشاكل التي أود حلها قبل نشر الكود والأدوات على Github.أولاً ، بصفتي مستخدمًا نهائيًا ، لا أريد استخدام أداة تنشئ العديد من الملفات الغريبة بأسماء غريبة ، والتي لا يتضح فيها ما تم تخزينه ، وما إلى ذلك.حسنًا ، يمكن حل ذلك من خلال دمج الملفات "00" .. "FF" في ملف واحد كبير.لسوء الحظ ، فإن وجود ملف واحد كبير للفرز يطرح مشكلة جديدة. ماذا لو كنت أرغب في إدراج تجزئة في هذا الملف؟ تجزئة واحدة فقط. هذا فقط 20 بايت. أوه ، يبدأ التجزئة بـ "000000000 ..". حسنا. دعونا نحرر مساحة لذلك بنقل 11 غيغابايت من التجزئة الأخرى ...أنت تفهم ما هي المشكلة. إدخال البيانات في منتصف الملف ليس أسرع عملية.عيب آخر لهذا النهج هو أنك تحتاج إلى تخزين وحدات البايت الأولى مرة أخرى - فهي 555 ميغابايت من البيانات.وأخيرًا وليس آخرًا ، فإن البحث الثنائي على البيانات المخزنة على محرك الأقراص الثابتة أبطأ بكثير من الوصول إلى ذاكرة الوصول العشوائي. أعني ، هذا هو قراءة القرص 30 مقابل قراءة القرص 0.ب 3
مرة أخرى. ما لدينا وما نريد تحقيقه.لدينا 11 غيغابايت من القيم الثنائية. جميع القيم قابلة للمقارنة ولها نفس الحجم. نريد معرفة ما إذا كان مفتاح معين موجودًا في البيانات المخزنة ، ونريد أيضًا تغيير قاعدة البيانات. ولكي يعمل كل شيء بسرعة.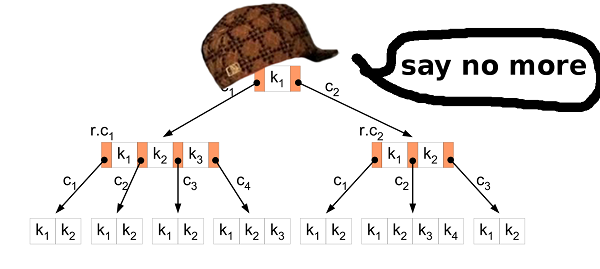 B- شجرة؟ حقتسمح لك شجرة B بتقليل الوصول إلى القرص عند البحث أو التعديل أو ما إلى ذلك. إنها تحتوي على ميزات أكثر بكثير ، لكننا نحتاج إلى هاتين الخاصيتين.
B- شجرة؟ حقتسمح لك شجرة B بتقليل الوصول إلى القرص عند البحث أو التعديل أو ما إلى ذلك. إنها تحتوي على ميزات أكثر بكثير ، لكننا نحتاج إلى هاتين الخاصيتين.ترتيب بالإدراج
الخطوة الأولى هي تحويل البيانات من ملف المصدر HIBP إلى شجرة B. هذا يعني أنك بحاجة إلى استخراج جميع التجزئة بالتساوي وإدخالها في الهيكل. خوارزمية الإدراج المعتادة مناسبة لذلك. ولكن في حالتنا ، يمكنك القيام بعمل أفضل.يعد إدراج الكثير من البيانات الأولية في شجرة B سيناريو معروفًا. لقد اخترع الحكماء نهجًا أفضل لهذا من الإدخال المعتاد. بادئ ذي بدء ، تحتاج إلى فرز البيانات. يمكن القيام بذلك كما هو موضح أعلاه (تقسيم الملف إلى ملفات أصغر وفرزها في ذاكرة الوصول العشوائي). ثم أدخل البيانات في الشجرة.في الخوارزمية المعتادة ، إذا وجدت العقدة الطرفية حيث تريد إدراج القيمة وتم ملؤها ، فإنك تقوم بإنشاء عقدة جديدة (على اليمين) وتوزع القيم بالتساوي بين العقدتين ، اليسرى واليمنى (بالإضافة إلى قيمة واحدة تذهب إلى العقدة الأصلية ولكن هذا ليس مهمًا هنا). باختصار ، دائمًا ما تكون القيم الموجودة في العقدة اليسرى أقل من القيم الموجودة في اليمين. والحقيقة هي أنه عند إدراج البيانات التي تم فرزها ، فأنت تعلم أن القيم الأصغر لن يتم إدراجها بعد الآن في الشجرة ، لذلك لن تذهب المزيد من القيم إلى العقدة اليسرى. العقدة اليسرى تبقى نصف فارغة طوال الوقت. علاوة على ذلك ، إذا قمت بإدخال قيم كافية ، فقد تجد أن العقدة الصحيحة ممتلئة ، لذا تحتاج إلى نقل نصف القيم إلى العقدة اليمنى الجديدة. تبقى العقدة المقسمة نصف فارغة ، كما في الحالة السابقة. إلخ…ونتيجة لذلك ، بعد كل الإدخالات ، تحصل على شجرة تكون فيها نصف العقد تقريبًا فارغة. هذا ليس استخدامًا فعالًا جدًا للمساحة. يمكننا القيام بعمل أفضل.منفصل أم لا؟
في حالة إدراج البيانات المصنفة ، يمكنك إجراء تعديل صغير على خوارزمية الإدراج. إذا كانت العقدة التي تريد لصق القيمة فيها ممتلئة ، فلا تقسمها. ما عليك سوى إنشاء عقدة جديدة وفارغة ولصق القيمة في العقدة الأصلية. بعد ذلك ، عند إدراج القيم التالية (التي تكون أكبر من القيم السابقة) ، تقوم بإدراجها في عقدة جديدة فارغة.للحفاظ على خصائص شجرة B ، بعد كل عمليات الإدراج ، من الضروري فرز العقد في أقصى اليمين في كل طبقة من الشجرة (باستثناء الجذر) وتقسيم قيم هذه العقدة المتطرفة وجارها الأيسر بالتساوي. حتى تحصل على أصغر شجرة ممكنة.خصائص شجرة HIBP
عند تصميم شجرة B ، تحتاج إلى اختيار ترتيبها. يوضح عدد القيم التي يمكن تخزينها في عقدة واحدة ، وكذلك عدد الأطفال الذين يمكن أن يكون للعقدة. من خلال معالجة هذه المعلمة ، يمكننا معالجة ارتفاع الشجرة ، الحجم الثنائي للعقدة ، إلخ.في HIBP ، لدينا 555278657تجزئات. افترض أننا نريد شجرة بارتفاع ثلاثة (لذلك لا نحتاج إلى أكثر من ثلاث عمليات قراءة للتحقق من وجود التجزئة). نحن بحاجة إلى العثور على قيمة M مثل هذا logM(555278657) < 3. اخترت 1024. هذه ليست أصغر قيمة ممكنة ، لكنها تترك إمكانية إدخال المزيد من التجزئة والحفاظ على ارتفاع الشجرة.ملف إلاخراج
حجم ملف HIBP المصدر هو 22.8 جيجا بايت. ملف الإخراج مع شجرة B هو 12.4 غيغابايت. يستغرق الأمر حوالي 11 دقيقة لإنشائه على جهازي (Intel Core i7-6700 ، 3.4 GHz ، 16 GB RAM) ، القرص الصلب (وليس SSD).المعايير
يظهر خيار B-tree نتيجة جيدة:| | الوقت [μs] | ٪ |
| -----------------: | ------------: | ------------: |
| أوكون | 49 | 100 |
| grep '^ hash' | 135'350'000 | 276'224'489 |
| جريب | 135'480'000 | 276'489'795 |
| C ++ سطرا بسطر | 135'720'201 | 276'980'002 |
أوكون - مكتبة و CLI
كما قلت ، أردت مشاركة عملي مع العالم. قمت بتطبيق مكتبة وواجهة سطر أوامر لمعالجة قاعدة بيانات HIBP والبحث بسرعة عن التجزئة. البحث سريع للغاية بحيث يمكن ، على سبيل المثال ، أن يتم دمجه في مدير كلمات المرور وإعطاء ملاحظات للمستخدم في كل مرة يتم الضغط على مفتاح. هناك العديد من الاستخدامات الممكنة.تحتوي المكتبة على واجهة C ، لذلك يمكن استخدامها في كل مكان تقريبًا. CLI هو CLI. يمكنك ببساطة إنشاء وتشغيل (:الرمز موجود في مستودع التخزين الخاص بي .إخلاء المسؤولية: لا توفر okon بعد واجهة لإدخال القيم في شجرة B التي تم إنشاؤها. يمكنه فقط معالجة ملف HIBP ، وإنشاء شجرة B والبحث فيها. تعمل هذه الوظائف بشكل جيد جدًا ، لذلك قررت مشاركة الرمز ومتابعة العمل على الإدخال والوظائف المحتملة الأخرى.الروابط والمناقشة
شكرا للقراءة
(: