 تحية للجميع!تشارك في اختبار الأداء. وأحب حقًا إعداد المراقبة والاستمتاع بالمقاييس في Grafana . ومعيار تخزين المقاييس في أدوات التحميل هو InfluxDB . في InfluxDB ، يمكنك حفظ المقاييس من الأدوات الشائعة مثل:من خلال العمل باستخدام أدوات اختبار الأداء ومقاييسها ، جمعت مجموعة مختارة من وصفات البرمجة لحزمة Grafana و InfluxDB . أقترح النظر في مشكلة مثيرة للاهتمام تنشأ عندما يكون هناك مقياس بعلامتين أو أكثر. أعتقد أن هذا ليس من غير المألوف. وفي الحالة العامة ، تبدو المهمة كما يلي: حساب المقياس الإجمالي لمجموعة مقسمة إلى مجموعات فرعية .
تحية للجميع!تشارك في اختبار الأداء. وأحب حقًا إعداد المراقبة والاستمتاع بالمقاييس في Grafana . ومعيار تخزين المقاييس في أدوات التحميل هو InfluxDB . في InfluxDB ، يمكنك حفظ المقاييس من الأدوات الشائعة مثل:من خلال العمل باستخدام أدوات اختبار الأداء ومقاييسها ، جمعت مجموعة مختارة من وصفات البرمجة لحزمة Grafana و InfluxDB . أقترح النظر في مشكلة مثيرة للاهتمام تنشأ عندما يكون هناك مقياس بعلامتين أو أكثر. أعتقد أن هذا ليس من غير المألوف. وفي الحالة العامة ، تبدو المهمة كما يلي: حساب المقياس الإجمالي لمجموعة مقسمة إلى مجموعات فرعية .هناك ثلاثة خيارات:
- فقط الكمية المجمعة حسب علامة النوع
- طريق جرافانا. نستخدم مجموعة من القيم
- مجموع الارتفاعات مع استعلام فرعي
كيف بدأ كل شيء
مراقبة JVM MBean باستخدام Jolokia و Telegraf و InfluxDB و Grafana . وتصور مقاييس حول تجمعات الذاكرة - مقدار الذاكرة المخصصة لكل تجمع ذاكرة في HEAP وما بعده.الرسوم البيانية على تجمعات ذاكرة JVM ونشاط جامع القمامة من الساعة 13:00 من اليوم السابق إلى 01:00 من ليلة اليوم الحالي (فترة 12 ساعة). هنا يمكنك أن ترى أن مجمعات الذاكرة مقسمة إلى مجموعتين: HEAP و NON_HEAP . وأن حوالي 17:00 وكان هناك جمع القمامة، وبعد ذلك حجم تجمعات الذاكرة انخفض: لمقاييس جمع على تجمعات الذاكرة، وتحديد الإعدادات التالية في تلغراف ملف التكوين : telegraf.conf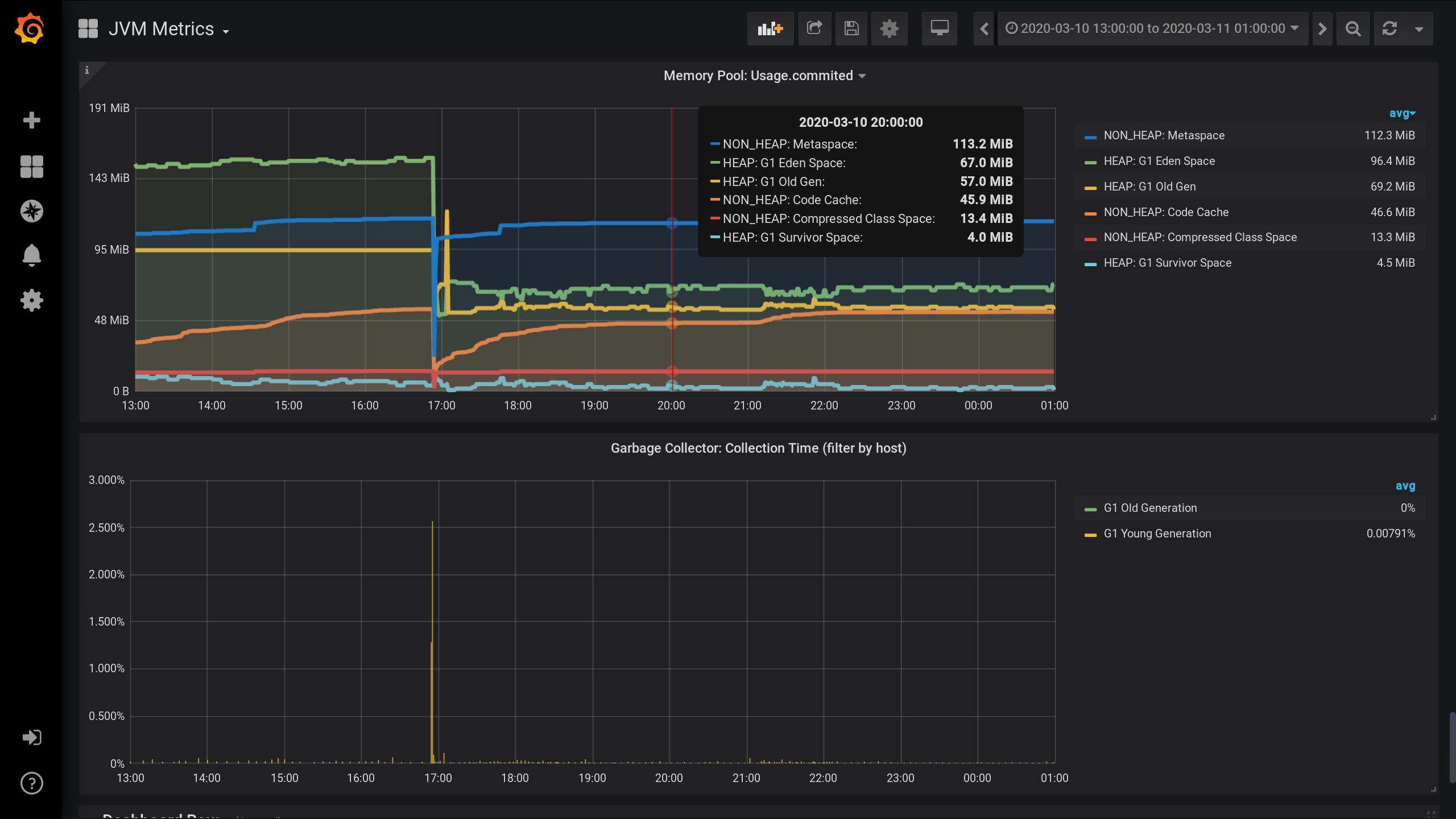
[outputs.influxdb]
urls = ["http://influxdb_server:8086"]
database = "telegraf"
username = "login-InfluxDb"
password = "*****"
retention_policy = "month"
influx_uint_support = false
[agent]
collection_jitter = "2s"
interval = "2s"
precision = "s"
[[inputs.jolokia2_agent]]
username = "login-Jolokia"
password = "*****"
urls = ["http://127.0.0.1:7777/jvm-service"]
[[inputs.jolokia2_agent.metric]]
paths = ["Usage","PeakUsage","CollectionUsage","Type"]
name = "java_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
tag_keys = ["name"]
[[processors.converter]]
[processors.converter.fields]
integer = ["CollectionUsage.*", "PeakUsage.*", "Usage.*"]
tag = ["Type"]
وفي Grafana ، أنشأت طلبًا إلى InfluxDB لعرض القيمة القصوى للمقياس في الرسوم البيانية Usage.Committedلفترة زمنية بخطوة $granularity(1 م) وتم تجميعها حسب Typeعلامتين (HEAP أو NON_HEAP) و name(Metaspace، G1 Old Gen، ...): نفس الطلب في شكل نصي ، مع الأخذ في الاعتبار جميع متغيرات Grafana (انتبه إلى الهروب من القيم المتغيرة باستخدام - وهذا مهم حتى يعمل الاستعلام بشكل صحيح):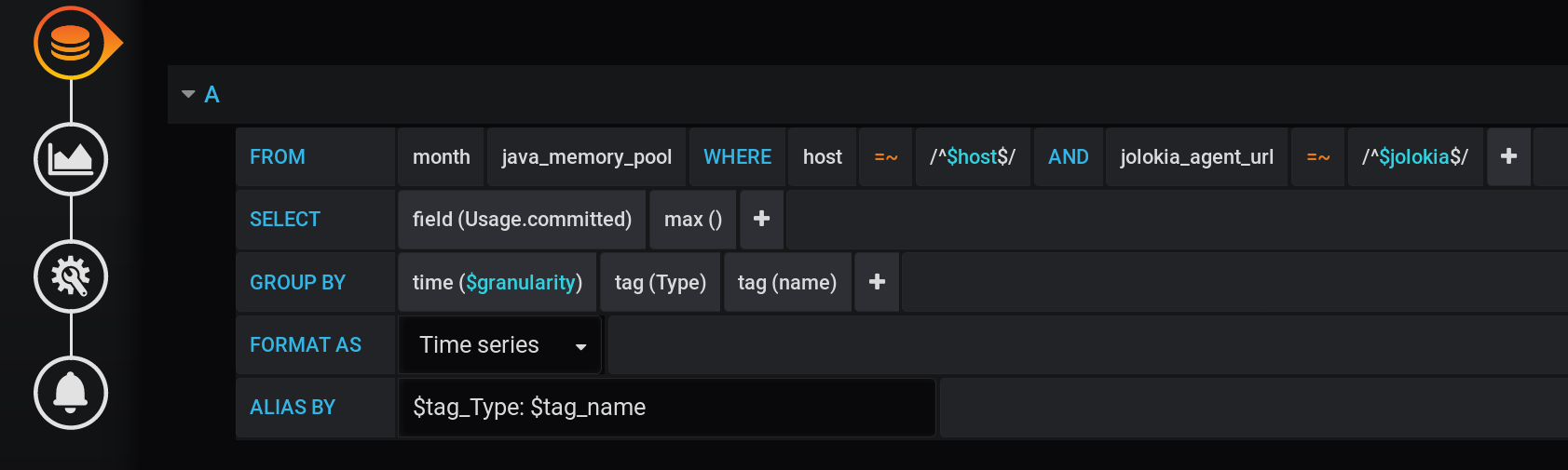
:regexSELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type", "name", time($granularity)
نفس الاستعلام في شكل نصي ، مع مراعاة القيم المحددة لمتغيرات جرافانا :SELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^serverName$/ AND
jolokia_agent_url =~ /^http:\/\/127\.0\.0\.1:7777\/jvm-service$/ AND
time >= 1583834400000ms and time <= 1583877600000ms
GROUP BY
"Type", "name", time(1m)
التجميع حسب الوقت GROUP BY time($granularity)أو GROUP BY time(1m)يستخدم لتقليل عدد النقاط على الرسم البياني. لفترة زمنية تبلغ 12 ساعة وخطوة تجميع مدتها دقيقة واحدة ، نحصل على: 12 × 60 = 720 مرة أو 721 نقطة (النقطة الأخيرة بقيمة فارغة).تذكر أن 721 هو العدد المتوقع للنقاط استجابة لطلبات InfluxDB بالإعدادات الحالية للفاصل الزمني (12 ساعة) وخطوة التجميع (دقيقة واحدة).
تجمع
ذاكرة NON_HEAP: Metaspace (أزرق) في الصدارة في استهلاك الذاكرة في الساعة 20:00. ووفقًا لـ HEAP: G1 Old Gen (أصفر) ، كانت هناك زيادة محلية صغيرة في الساعة 17:03. وفي تمام الساعة 20:00 ، في المجموع ، غادرت جميع تجمعات NON_HEAP 172.5 MiB (113.2 + 45.9 + 13.4) ، وتجمعات HEAP 128 MiB (67 + 57 + 4).
تذكر قيم 20:00: تجمعات NON_HEAP 172.5 MiB ، وتجمعات HEAP 128 MiB . سنركز على هذه القيم في المستقبل.
في سياق النوع : الاسم ، حصلنا على قيمة المقياس بسهولة.في سياق علامة الاسم فقط ، من السهل أيضًا الحصول على قيمة المقياس ، نظرًا لأن جميع أسماء تجمعات الذاكرة فريدة ، ويكفي ترك تجميع النتائج بالاسم فقط .يبقى السؤال: كيف يمكن الحصول على الحجم المخصص لجميع تجمعات HEAP وجميع تجمعات NON_HEAP في المجموع؟
1. فقط الكمية المجمعة حسب علامة النوع
1.1. تم تجميع المجموع حسب العلامة
الحل الأول الذي قد يتبادر إلى الذهن هو تجميع القيم حسب علامة النوع وحساب مجموع القيم في كل مجموعة. سيبدو مثل هذا الاستعلام كما يلي: تمثيل نصي لطلب حساب المجموع تم تجميعه حسب علامة النوع مع جميع متغيرات Grafana :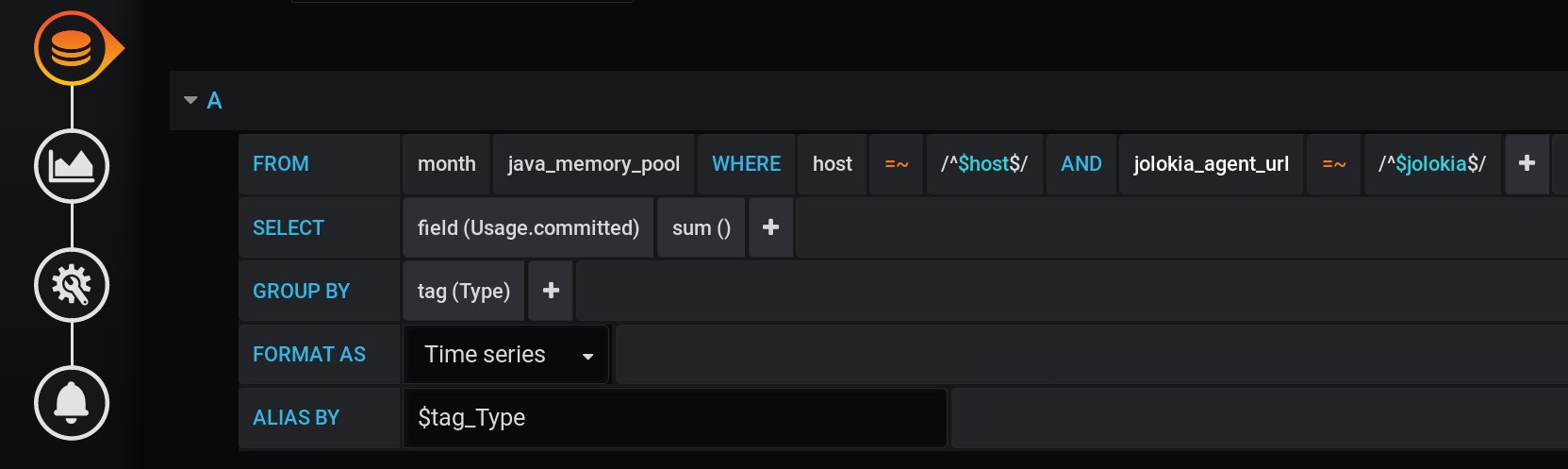
SELECT sum("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type"
هذا استعلام صالح ، لكنه سيعرض نقطتين فقط: سيتم حساب المجموع بالتجميع فقط بواسطة علامة النوع بقيمتين (HEAP و NON_HEAP). لن نرى حتى الجدول الزمني. ستكون هناك نقطتان مستقلتان بقيمة إجمالية كبيرة (أكثر من 3 تيرابايت): هذا المبلغ غير مناسب ، هناك حاجة إلى تقسيم الفواصل الزمنية.
1.2. المبلغ مجمَّع حسب العلامة في الدقيقة
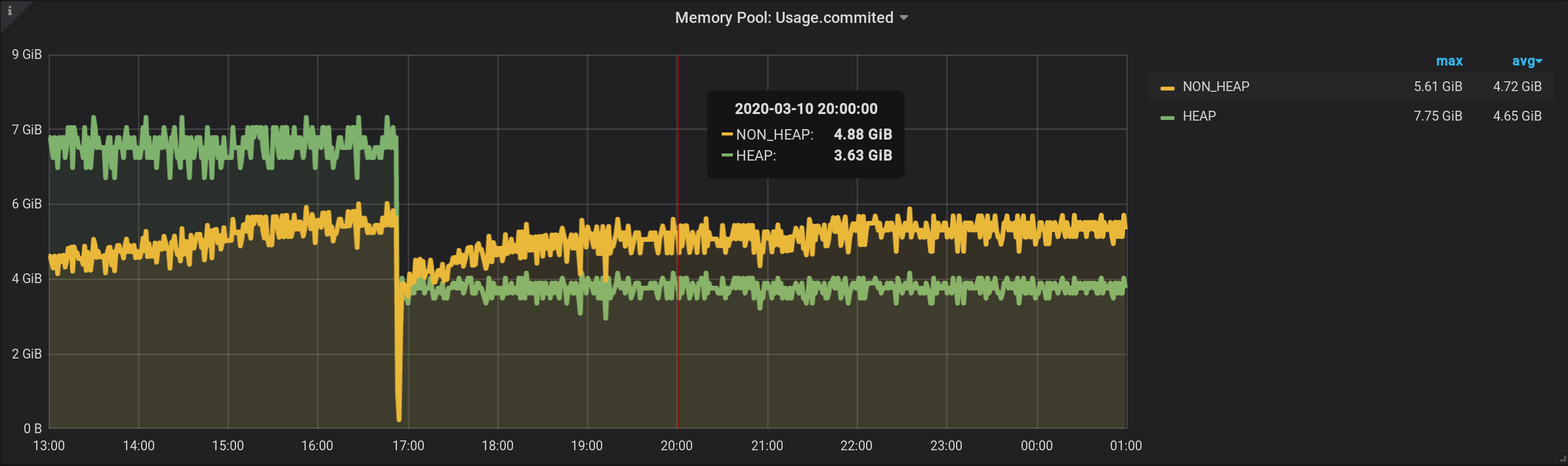
في الاستعلام الأصلي ، قمنا بتجميع المقاييس حسب فترة تفصيل $ مخصصة . لنقم بالتجميع الآن بفاصل زمني مخصص.وأضاف أن هذا الاستعلام سيظهر GROUP BY time($granularity): نحصل على قيم متضخمة ، بدلاً من 172.5 ميغابايت بواسطة NON_HEAP نرى 4.88 غيغابايت: نظرًا لإرسال المقاييس إلى InfluxDB مرة واحدة كل ثانيتين (انظر telegraf.conf أعلاه) ، فإن مجموع القراءات في دقيقة واحدة لن يعطي المبلغ في الوقت الحاضر ، ومجموع ثلاثين من هذه المبالغ. لا يمكننا تقسيم النتيجة على ثابت 30 أيضًا. نظرًا لأن دقة $ هي معلمة ، يمكن تعيينها على دقيقة واحدة و 10 دقائق. وستتغير قيمة المبلغ.
1.3. تم تجميع العلامة في الثانية
من أجل الحصول على قيمة المقياس بشكل صحيح لكثافة مجموعة المقاييس الحالية (ثانيتان) ، تحتاج إلى حساب المبلغ لفترة زمنية لا تتجاوز كثافة مجموعة المقاييس.دعونا نحاول عرض الإحصائيات مع تجميع في ثوان. أضف إلى GROUP BYالتجميع time(1s): مع مثل هذه الدقة الصغيرة ، نحصل على عدد كبير من النقاط لفاصلنا الزمني 12 ساعة (12 ساعة * 60 دقيقة * 60 ثانية = 43،200 فواصل ، 43،201 نقطة لكل سطر ، وآخرها فارغ): 43،201 نقطة في كل سطر من الرسم البياني. هناك العديد من النقاط التي ستشكل InfluxDB استجابة لفترة طويلة ، وستستغرق Grafana استجابة أطول ، ثم سيقوم المتصفح برسم هذا العدد الضخم من النقاط لفترة طويلة.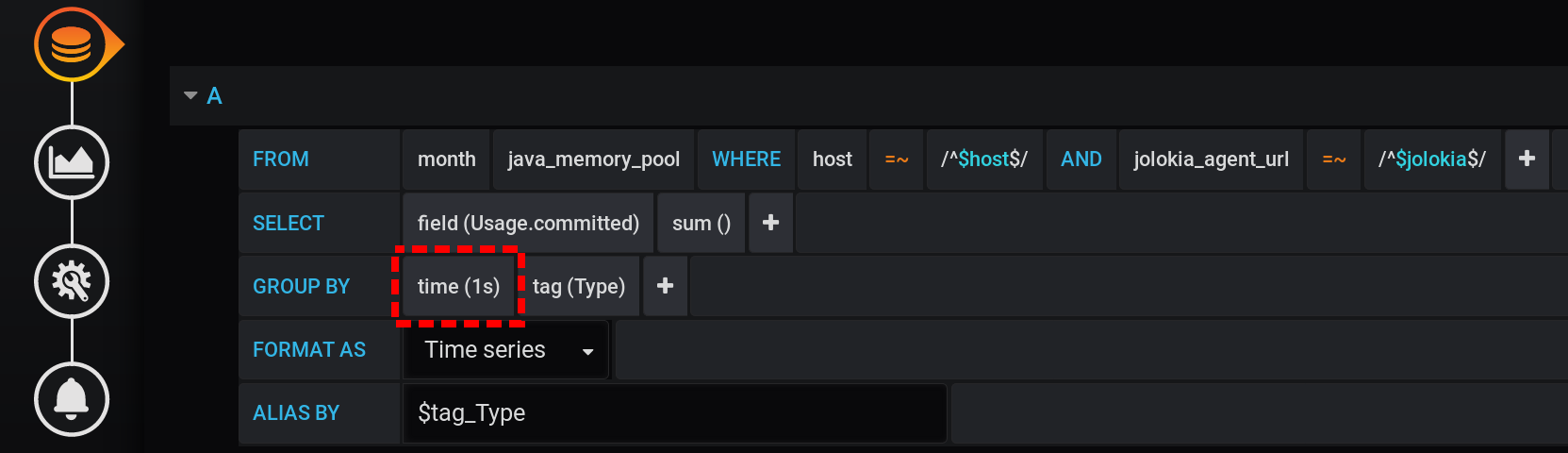
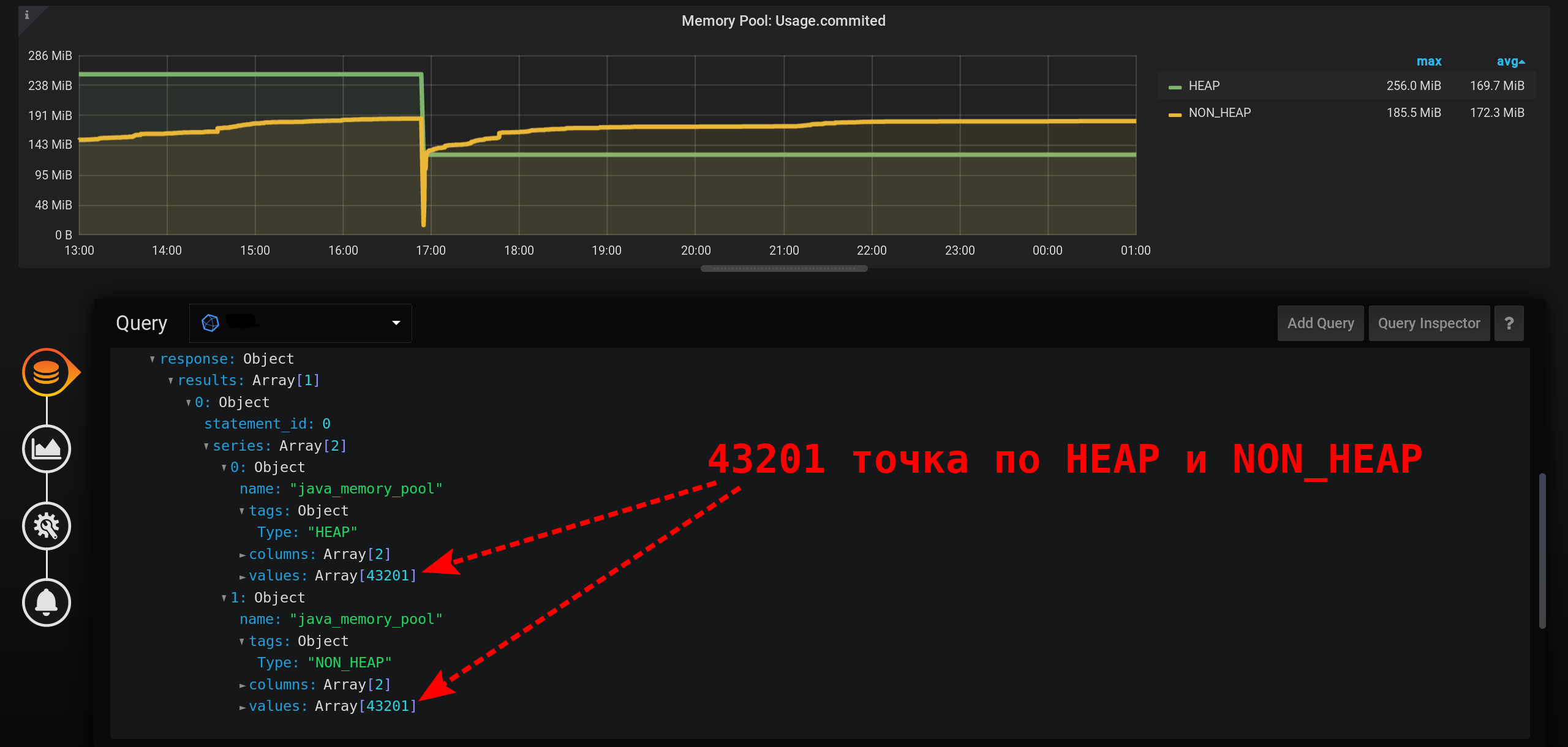 وليس في كل ثانية هناك نقاط: تم جمع المقاييس كل ثانيتين ، والتجميع في كل ثانية ، مما يعني أن كل نقطة ثانية ستكون فارغة. لرؤية خط متجانس ، قم بتكوين اتصال القيم غير الفارغة. خلاف ذلك ، لن نرى الرسوم البيانية: في السابق ، كان Grafana بحيث علق المتصفح أثناء رسم عدد كبير من النقاط. الآن نسخة Grafana لديها القدرة على رسم عدة عشرات الآلاف من النقاط: المتصفح ببساطة يتخطى بعضها ، يرسم رسمًا بيانيًا باستخدام البيانات الضعيفة. لكن الرسم البياني تم صقله. يتم عرض المرتفعات كمتوسطات عالية.
وليس في كل ثانية هناك نقاط: تم جمع المقاييس كل ثانيتين ، والتجميع في كل ثانية ، مما يعني أن كل نقطة ثانية ستكون فارغة. لرؤية خط متجانس ، قم بتكوين اتصال القيم غير الفارغة. خلاف ذلك ، لن نرى الرسوم البيانية: في السابق ، كان Grafana بحيث علق المتصفح أثناء رسم عدد كبير من النقاط. الآن نسخة Grafana لديها القدرة على رسم عدة عشرات الآلاف من النقاط: المتصفح ببساطة يتخطى بعضها ، يرسم رسمًا بيانيًا باستخدام البيانات الضعيفة. لكن الرسم البياني تم صقله. يتم عرض المرتفعات كمتوسطات عالية.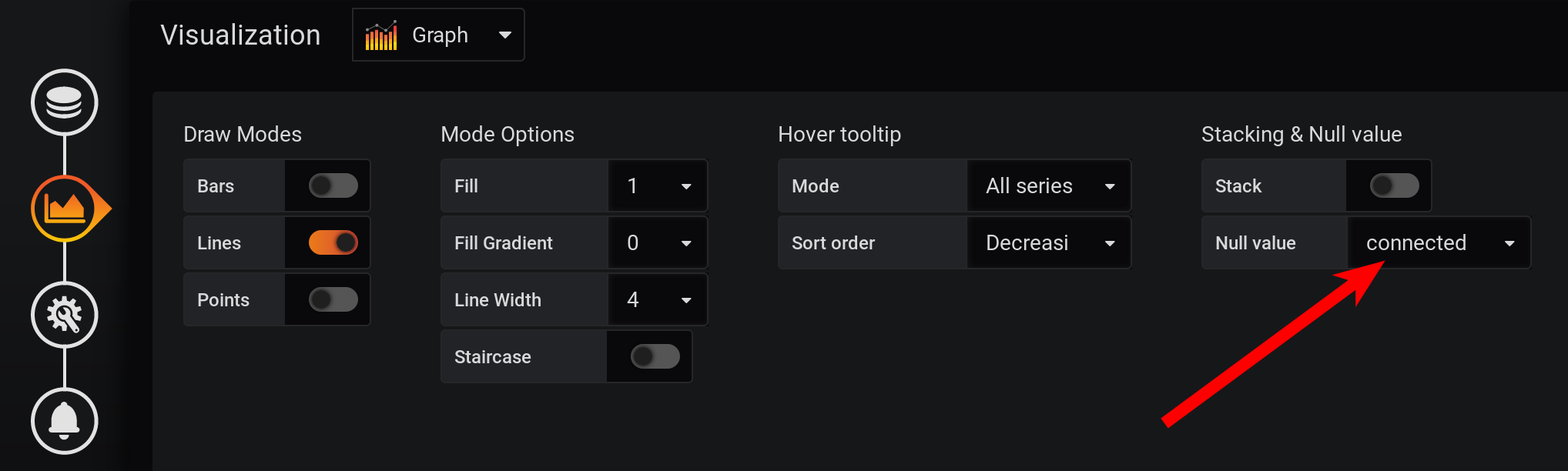 ونتيجة لذلك ، يوجد رسم بياني ، يتم عرضه بدقة ، ويتم حساب المقاييس في الساعة 20:00 بشكل صحيح ، ويتم حساب المقاييس في وسيلة إيضاح الرسم البياني بشكل صحيح. لكن الرسم البياني سلس: لا يمكن رؤية الرشقات عليه بدقة تبلغ ثانية واحدة. على وجه الخصوص ، اختفى ارتفاع HEAP في الساعة 17:03 من المخطط ، مخطط HEAP سلس للغاية: سيظهر ناقص في الأداء بشكل واضح على مدى فترة زمنية أطول. إذا حاولت إنشاء رسم بياني في شهر (720 ساعة) وليس في 12 ساعة ، فسيتم تجميد كل شيء بمثل هذه الدقة الصغيرة (ثانية واحدة) ، سيكون هناك العديد من النقاط. وهناك ناقص في حالة عدم وجود قمم ، مفارقة - نظرًا للدقة العالية في الحصول على المقاييس ، نحصل على دقة منخفضة لعرضها .
ونتيجة لذلك ، يوجد رسم بياني ، يتم عرضه بدقة ، ويتم حساب المقاييس في الساعة 20:00 بشكل صحيح ، ويتم حساب المقاييس في وسيلة إيضاح الرسم البياني بشكل صحيح. لكن الرسم البياني سلس: لا يمكن رؤية الرشقات عليه بدقة تبلغ ثانية واحدة. على وجه الخصوص ، اختفى ارتفاع HEAP في الساعة 17:03 من المخطط ، مخطط HEAP سلس للغاية: سيظهر ناقص في الأداء بشكل واضح على مدى فترة زمنية أطول. إذا حاولت إنشاء رسم بياني في شهر (720 ساعة) وليس في 12 ساعة ، فسيتم تجميد كل شيء بمثل هذه الدقة الصغيرة (ثانية واحدة) ، سيكون هناك العديد من النقاط. وهناك ناقص في حالة عدم وجود قمم ، مفارقة - نظرًا للدقة العالية في الحصول على المقاييس ، نحصل على دقة منخفضة لعرضها .
2. طريق جرافانا. نستخدم مجموعة من القيم
لم يكن من الممكن إنشاء حل
بسيط ومنتج مع InfluxDB ومصمم استعلام Grafana . سنحاول فقط استخدام أدوات Grafana لتلخيص المقاييس المعروضة في المخطط الأصلي. ونعم هذا ممكن!2.1. ما عليك سوى جعل تلميح أداة التحويم / القيمة المكدسة: تراكمية
وسوف نترك طلب لاختيار المقاييس دون تغيير، وهو نفس في قسم "كيف بدأ كل شيء": سيتم تجميع القياسات عن طريق نوع و اسم . لكننا سنعرض فقط علامة Type في أسماء الرسوم البيانية : وفي إعدادات التمثيل البصري ، سنقوم بتجميع المقاييس حسب مكدسات Grafana : أولاً ، أضف فصل علامتين إلى مجموعتين مختلفتين A و B ، بحيث لا تتقاطع قيمهما: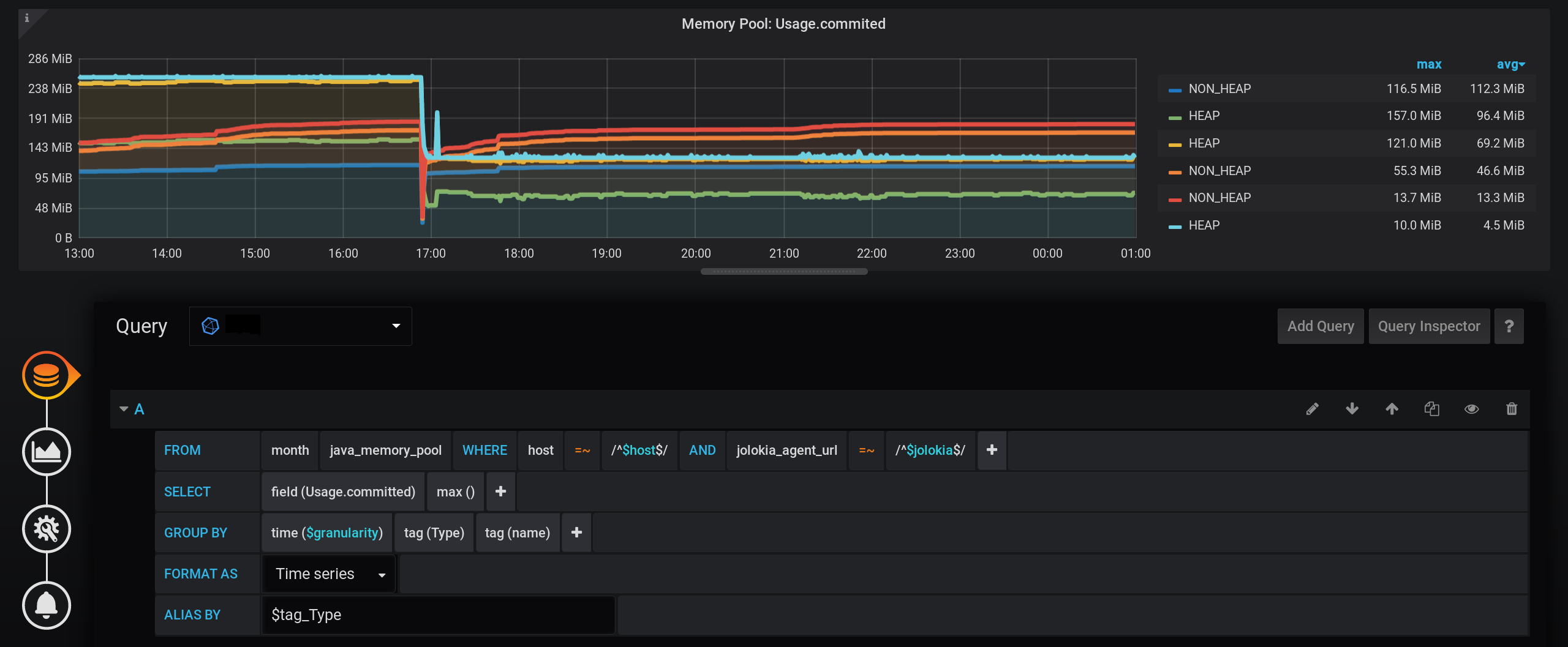
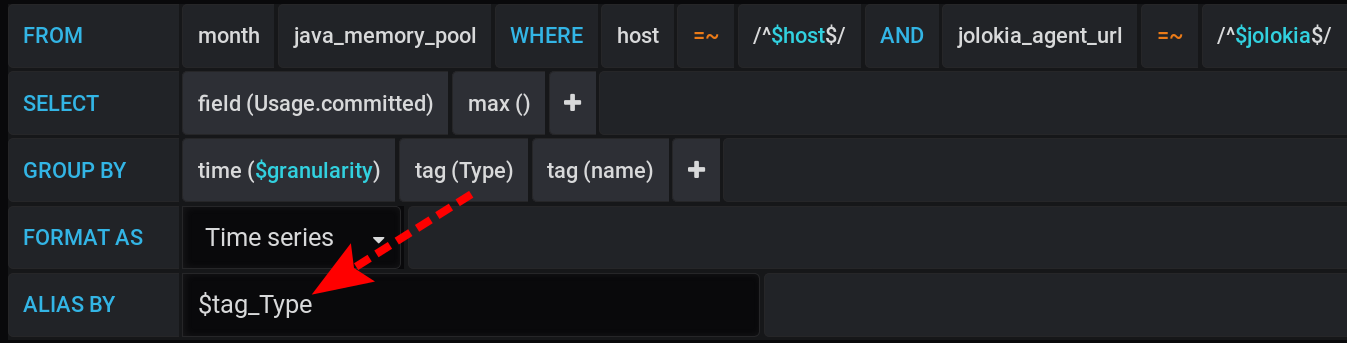
- إضافة تجاوز سلسلة / HEAP / المكدس : أ
- إضافة تجاوز السلسلة / NON_HEAP / المكدس : ب
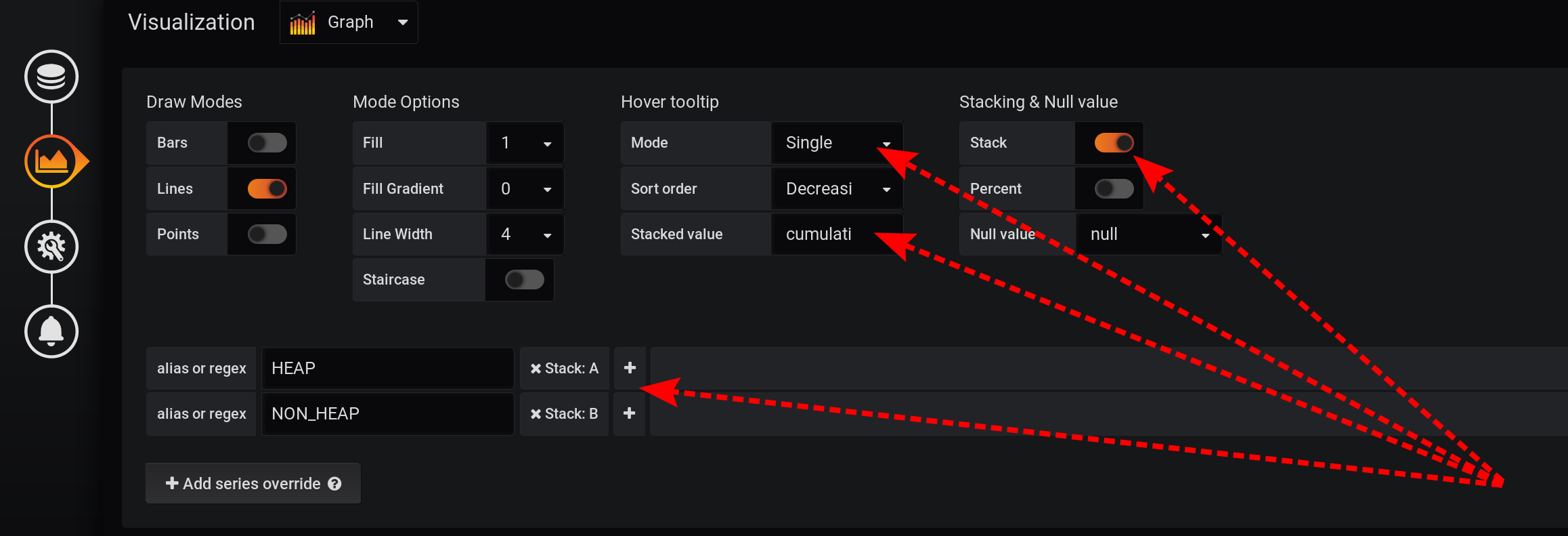
ثم قم بتكوين تصور المقاييس لعرض القيم الإجمالية في تلميح مع الرسوم البيانية:- التراص والقيمة الفارغة / التراص : قيد التشغيل
- تلميح أداة التمرير / القيمة المكدسة : تراكمية
- تلميح / وضع التمرير : واحد
نظرًا للميزات المختلفة لـ Grafana ، فأنت بحاجة إلى تنفيذ الإجراءات بهذا الترتيب. إذا قمت بتغيير ترتيب الإجراءات أو تركت بعض الحقول بالإعدادات الافتراضية ، فلن يعمل شيء ما:- Stack A B Stacking & Null value / Stack: On, ;
- Hover tooltip / Mode , Single, Hover tooltip .
والآن ، نرى العديد من الخطوط ، لأنفسنا. لكن! إذا قمت بالتمرير فوق أعلى NON_HEAP ، فسوف يعرض تلميح الأدوات مجموع قيم جميع NON_HEAPs . يعتبر المبلغ صحيحًا ، يعني Grafana بالفعل أنه : وإذا قمت بالتحويم فوق المخطط العلوي باسم HEAP ، فسنرى المبلغ بواسطة HEAP . يتم عرض الرسم البياني بشكل صحيح. حتى ارتفاع HEAP في الساعة 17:03 مرئي: رسميًا ، تم الانتهاء من المهمة. ولكن هناك سلبيات - يتم عرض الكثير من الرسوم البيانية الإضافية. تحتاج إلى الحصول على المؤشر لأعلىها. وفي وسيلة الإيضاح للرسم البياني ، لا يتم عرض القيم التراكمية ، ولكن يتم عرض القيم الفردية ، لذلك أصبحت وسيلة الإيضاح عديمة الفائدة.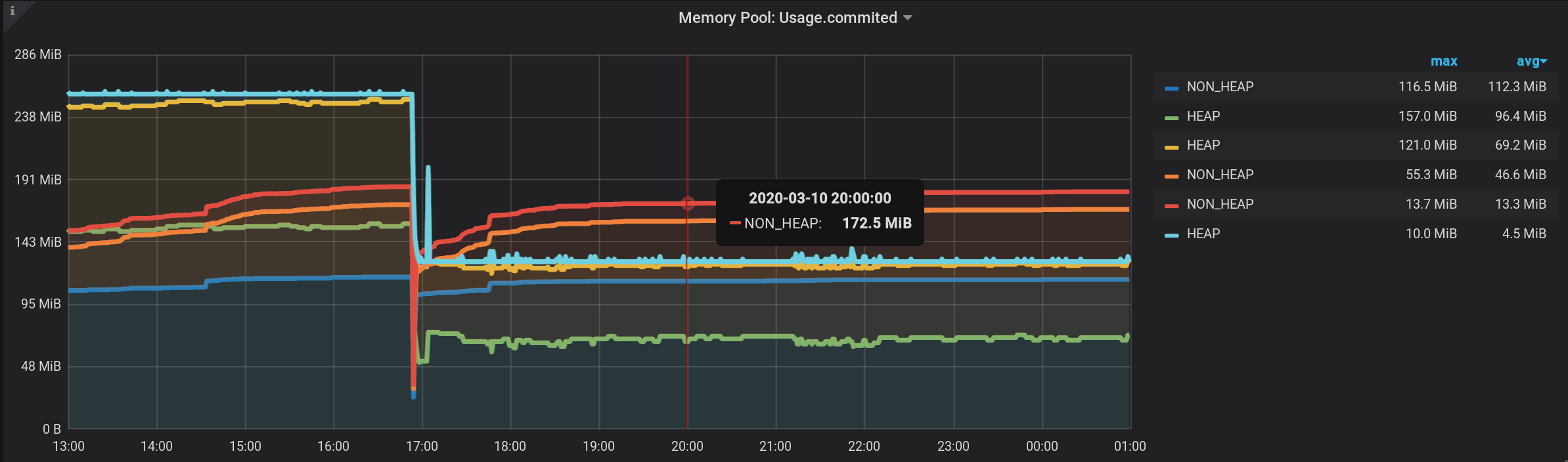
2.2. قيمة مكدسة: تراكمية مع إخفاء خطوط وسيطة
دعنا نصلح الطرح الأول من الحل السابق: تأكد من عدم عرض الرسوم البيانية الإضافية.لهذا:- أضف مقاييس جديدة باسم مختلف وقيمة 0 إلى النتائج.
- أضف مقاييس جديدة إلى Stack A و Stack B إلى أعلى المكدس.
- إخفاء من الشاشة - الأسطر الأصلية لـ HEAP و NON_HEAP .
نضيف سلسلتين جديدتين بعد الطلب الرئيسي: الطلب B لاستلام سلسلة بقيم 0 واسم [NON_HEAP] والطلب C لاستلام سلسلة بقيم 0 واسم [HEAP] . للحصول على 0 ، نأخذ القيمة الأولى لحقل "Usage.committed" في كل مجموعة زمنية ونطرحها : أولاً ("Usage.committed") - أولاً ("Usage.committed") - نحصل على 0 مستقرة. يتم تغيير أسماء الرسوم البيانية دون فقدان المعنى نظرًا للأقواس المربعة: [NON_HEAP] و [HEAP] : يتم دمج [HEAP] و HEAP في Stack A ، وكذلك إخفاء جميع HEAP . [NON_HEAP]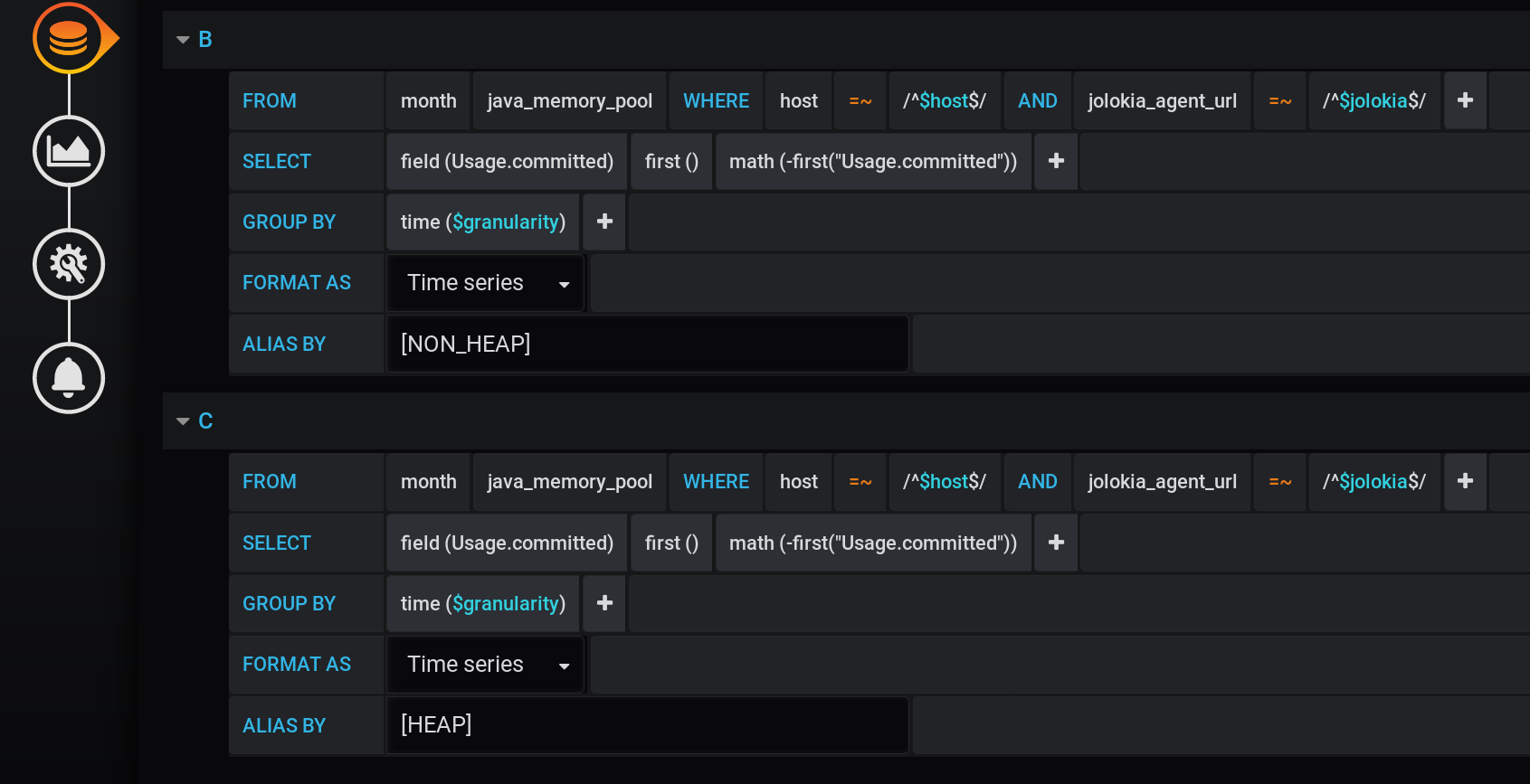 و الجمع بين NON_HEAP في كومة B و اخفاء NON_HEAP : الحصول على
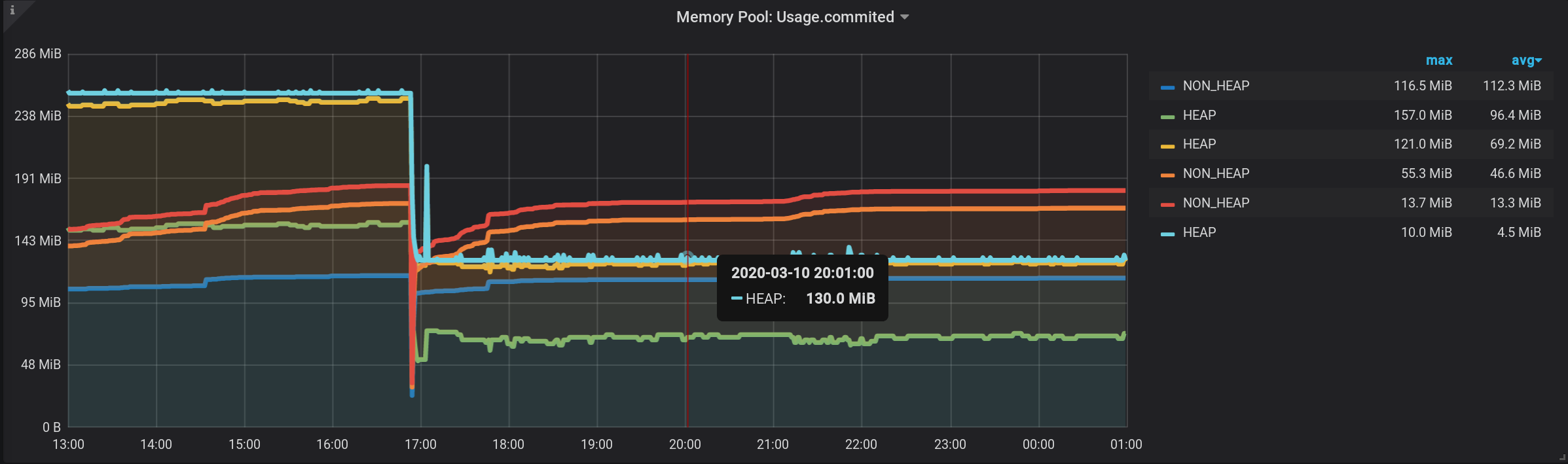
المبلغ الصحيح من قبل [NON_HEAP] في تلميح الأدوات عندما تحوم فوق الرسم البياني: الحصول على المبلغ الصحيح من [هيب] في تلميح الأدوات عندما تحوم فوق الرسم البياني. وحتى كل الرشقات مرئية: ويتم تشكيل الجدول بسرعة. لكن الأسطورة تعرض دائمًا 0 ، أصبحت الأسطورة عديمة الفائدة. كل شيء يعمل! تجاوز صحيح من خلال مداخن جرافانا . ولهذا السبب تمت إضافة المقالة إلى فئة البرمجة غير الطبيعية .
و الجمع بين NON_HEAP في كومة B و اخفاء NON_HEAP : الحصول على
المبلغ الصحيح من قبل [NON_HEAP] في تلميح الأدوات عندما تحوم فوق الرسم البياني: الحصول على المبلغ الصحيح من [هيب] في تلميح الأدوات عندما تحوم فوق الرسم البياني. وحتى كل الرشقات مرئية: ويتم تشكيل الجدول بسرعة. لكن الأسطورة تعرض دائمًا 0 ، أصبحت الأسطورة عديمة الفائدة. كل شيء يعمل! تجاوز صحيح من خلال مداخن جرافانا . ولهذا السبب تمت إضافة المقالة إلى فئة البرمجة غير الطبيعية .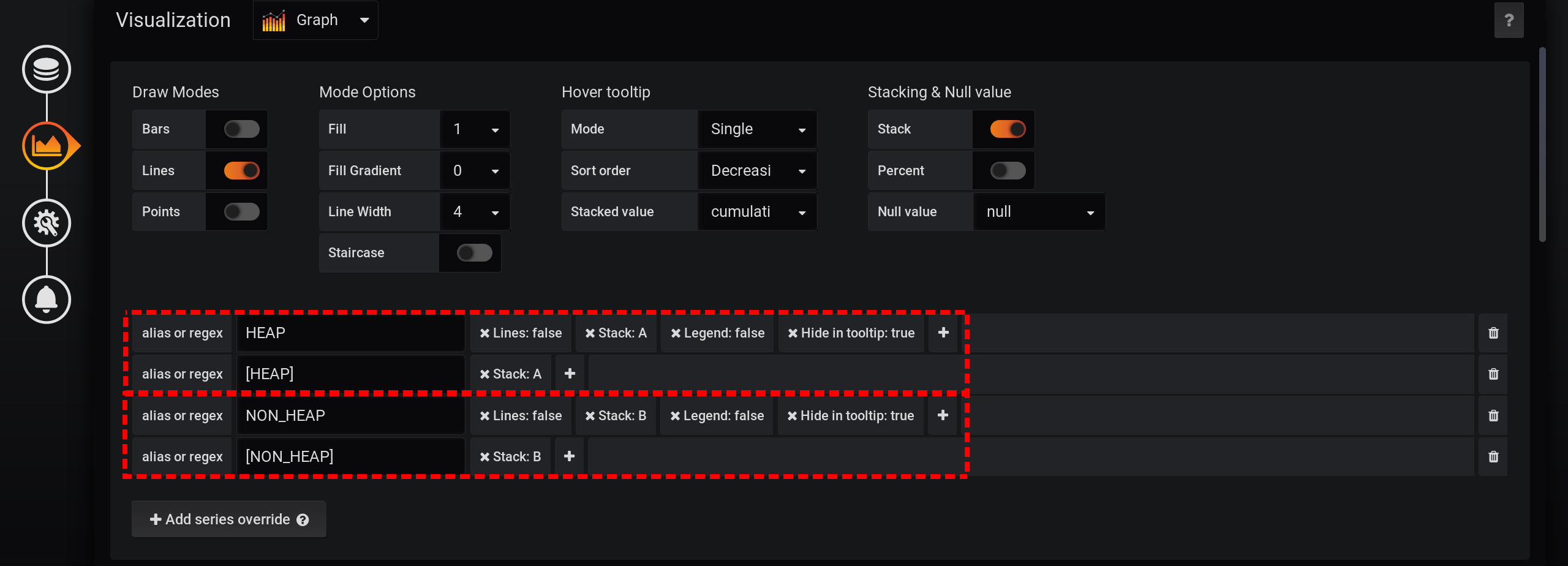


3. مجموع الارتفاعات في الاستعلام الفرعي
نظرًا لأننا قد شرعنا بالفعل في مسار البرمجة غير الطبيعية مع مجموعة من Grafana و InfluxDB ، فلنستمر . دعونا نجعل InfluxDB يُرجع عددًا صغيرًا من النقاط ويجعل الأسطورة تظهر.3.1 مجموع الزيادات في المجموع التراكمي للحد الأقصى
دعونا نتعمق في إمكانيات InfluxDB . في السابق ، غالبًا ما كنت أساعد عن طريق أخذ مشتق المبلغ التراكمي ، لذلك سنحاول تطبيق هذا النهج الآن. دعنا ننتقل إلى وضع التحرير اليدوي للطلبات: لنقم بتقديم مثل هذا الطلب:
SELECT sum("U") FROM (
SELECT non_negative_difference(cumulative_sum(max("Usage.committed"))) AS "U"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
GROUP BY "Type", time($granularity)
هنا يتم أخذ القيمة القصوى للقياس في مجموعة من الوقت ومجموع هذه القيم من لحظة بدء المرجعية، التي تم تجميعها حسب نوع و اسم علامات . ونتيجة لذلك ، في كل لحظة من الوقت ، سيكون هناك مجموع لجميع المؤشرات حسب النوع ( HEAP أو NON_HEAP ) مع الفصل حسب اسم التجمع ، ولكن لا يتم جمع 30 قيمة ، كما كان الحال في الإصدار 1.2 ، ولكن واحدًا فقط هو الحد الأقصى.وإذا أخذنا non_negative_difference الزيادة من مثل هذا المبلغ التراكمي للخطوة الأخيرة، فإننا سوف تحصل على قيمة مجموع كل حمامات البيانات التي تم تجميعها حسب نوع و اسم علامات في الوقت الذي يبدأ الفاصل الزمني.الآن ، للحصول على المبلغ عن طريق العلامة فقطاكتب ، بدون تجميع حسب علامة الاسم ، تحتاج إلى تقديم طلب من المستوى الأعلى مع معلمات تجميع مماثلة ، ولكن بدون تجميع حسب الاسم .نتيجة لمثل هذا الاستعلام المعقد ، نحصل على مجموع جميع الأنواع.جدول مثالي. يتم حساب مجموع الحد الأقصى بشكل صحيح. هناك وسيلة إيضاح بقيم صحيحة غير صفرية. في تلميح الأدوات ، يمكنك عرض جميع المقاييس ، وليس فقط مفرد. يتم عرض رشقات HEAP حتى : شيء واحد ولكن - اتضح أن الطلب صعب: مجموع الزيادة في مجموع القيم القصوى التراكمية مع تغيير في مستوى التجميع.
3.2 مجموع الارتفاعات مع تغيير في مستوى التجميع
هل يمكنك القيام بشيء أبسط من الإصدار 3.1؟ صندوق Pandora مفتوح بالفعل ، تحولنا إلى وضع تحرير الاستعلام اليدوي.هناك شك في أن تلقي زيادة من المبلغ التراكمي يؤدي إلى تأثير صفر - واحد يطفئ الآخر. تخلص من الاختلاف non_negative_sif (cumulative_sum (...)) .تبسيط الطلب.نترك ببساطة مجموع الحد الأقصى ، مع انخفاض في مستوى التجميع:SELECT sum("A")
FROM (
SELECT max("Usage.committed") as "A"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
WHERE $timeFilter
GROUP BY time($granularity), "Type"
هذا استعلام بسيط وسريع يقوم بإرجاع 721 نقطة فقط لكل سلسلة في 12 ساعة ، عندما يتم تجميعها بالدقائق: 12 (ساعات) * 60 (دقائق) = 720 فواصل زمنية ، 721 نقطة (آخر فارغة). يرجى ملاحظة أن فلتر الوقت مكرر. إنه في الاستعلام الفرعي وفي طلب التجميع: بدون $ timeFilter ، في طلب التجميع الخارجي ، لن يكون عدد النقاط المرتجعة 721 في 12 ساعة ، بل أكثر. نظرًا لأن الاستعلام الفرعي تم تجميعه للفاصل الزمني من ... إلى ، فإن تجميع طلب خارجي بدون عامل تصفية سيكون للفاصل الزمني من ... الآن . وإذا تم تحديد فاصل زمني في Grafana لا يدوم X- ساعات (وليس هذا إلى = الآن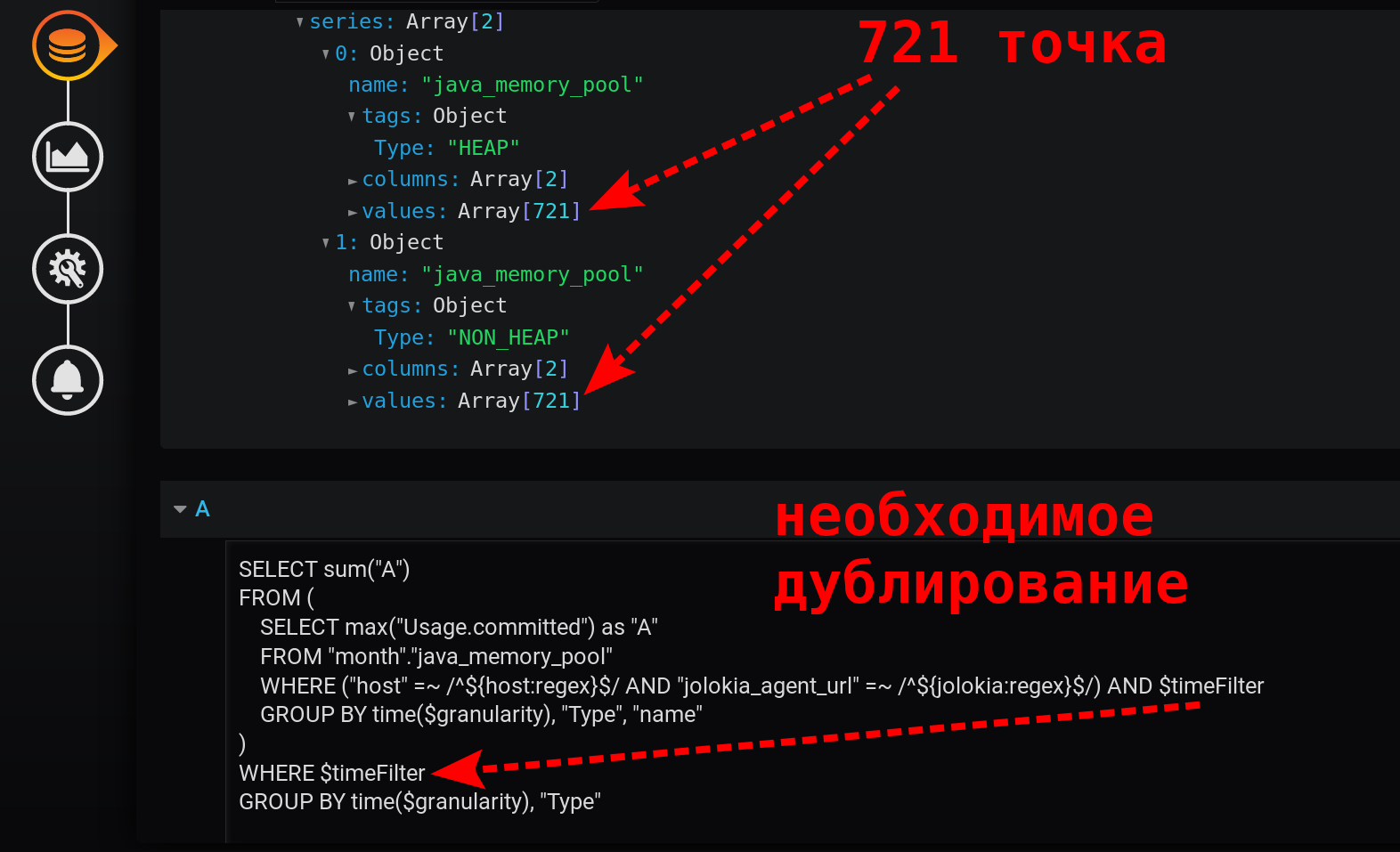 ) ، ولكن للفاصل الزمني من الماضي ( إلى < الآن ) ، ستظهر نقاط فارغة ذات قيمة فارغة في نهاية التحديد.تبين أن الرسم البياني الناتج بسيط وسريع وصحيح. مع وسيلة إيضاح تعرض مقاييس الملخص. مع تلميح لخطوط متعددة في وقت واحد. وأيضًا مع عرض جميع رشقات القيم: تم تحقيق النتيجة!
) ، ولكن للفاصل الزمني من الماضي ( إلى < الآن ) ، ستظهر نقاط فارغة ذات قيمة فارغة في نهاية التحديد.تبين أن الرسم البياني الناتج بسيط وسريع وصحيح. مع وسيلة إيضاح تعرض مقاييس الملخص. مع تلميح لخطوط متعددة في وقت واحد. وأيضًا مع عرض جميع رشقات القيم: تم تحقيق النتيجة!المراجع (بدلاً من المراجع)
توزيعات الأدوات المستخدمة في المقالة:وثائق حول إمكانيات الأدوات المستخدمة في المقالة:في مزيج من Grafana و InfluxDB يحتاج إلى أن تكون معروفة جيدا للمهندسين اختبار الأداء. وفي هذه الحزمة ، تعتبر العديد من المهام البسيطة مثيرة للاهتمام للغاية ، ولا يمكن حلها دائمًا من خلال طرق البرمجة العادية.في بعض الأحيان قد تكون هناك حاجة إلى مهارات البرمجة غير طبيعية مع Grafana الميزات والدقيقة من InfluxDB الاستعلام اللغة .في المقالة ، تم أخذ أربع خطوات في الاعتبار لتنفيذ تلخيص المقياس مع التجميع حسب علامة واحدة ، ولكن يحتوي على العديد من العلامات. كانت المهمة مثيرة للاهتمام. وهناك العديد من هذه المهام.أقوم بإعداد تقرير عن التفاصيل الدقيقة للبرمجة مع Grafana و InfluxDB. سوف أنشر بشكل دوري مواد حول هذا الموضوع. في غضون ذلك ، سأكون سعيدًا بأسئلتك حول المقالة الحالية.