تحية للجميع. في 26 فبراير ، بدأت الفصول الدراسية في OTUS في مجموعة جديدة في الدورة التدريبية "MS SQL Server Developer" . في هذا الصدد ، أود أن أشارككم منشوري حول وظائف النافذة. بالمناسبة ، في الأسبوع المقبل لا يزال بإمكانك الانضمام إلى المجموعة ؛-).
وظائف النافذة راسخة في ممارستنا ، لكن قلة من الناس يعرفون كيف تعمل إطارات RANGE و ROWS.ربما لهذا السبب هم أقل شيوعًا إلى حد ما. الغرض من هذه المقالة هو تقديم أمثلة للاستخدام بحيث لا يكون لديك بالتأكيد أسئلة "من هو؟" و "كيفية تطبيقه؟". السؤال "لماذا؟" ستبقى المقالة غير مضاءة.دعونا نلقي نظرة على ما هو الإطار وكيفية تحقيق تأثير مماثل باستخدام ORDER By في جملة OVER ().للتوضيح ، سنستخدم جدولًا بسيطًا حتى تتمكن من حساب الأمثلة دون استخدام مترجم. بشكل عام ، أوصي به بشدة - انظر وفكر في ما سيكون نتيجة التنفيذ ، ثم تحقق من نفسك - لذلك ستجد بقع بيضاء في تصور وظائف النافذة ، والتي قد لا تكون واضحة عند قراءة النتائج النهائية.الطاولةCreate table sales
(sales_id INT PRIMARY KEY, sales_dt DATETIME2 DEFAULT GETUTCDATE(), customer_id INT, item_id INT, cnt INT, price_per_item DECIMAL(19,4));
INSERT INTO sales
(sales_id, sales_dt, customer_id, item_id, cnt, price_per_item)
VALUES
(1, '2020-01-10T10:00:00', 100, 200, 2, 30.15),
(2, '2020-01-11T11:00:00', 100, 311, 1, 5.00),
(3, '2020-01-12T14:00:00', 100, 400, 1, 50.00),
(4, '2020-01-12T20:00:00', 100, 311, 5, 5.00),
(5, '2020-01-13T10:00:00', 150, 311, 1, 5.00),
(6, '2020-01-13T11:00:00', 100, 315, 1, 17.00),
(7, '2020-01-14T10:00:00', 150, 200, 2, 30.15),
(8, '2020-01-14T15:00:00', 100, 380, 1, 8.00),
(9, '2020-01-14T18:00:00', 170, 380, 3, 8.00),
(10, '2020-01-15T09:30:00', 100, 311, 1, 5.00),
(11, '2020-01-15T12:45:00', 150, 311, 5, 5.00),
(12, '2020-01-15T21:30:00', 170, 200, 1, 30.15);
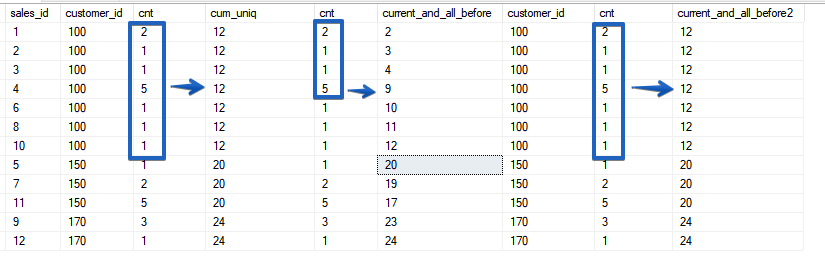
لنبدأ بلحظة بسيطة - الاختلافات في دالة SUM مع الفرز أو بدونهSELECT sales_id, customer_id, count,
SUM(count) OVER () as total,
SUM(count) OVER (ORDER BY customer_id) AS cum,
SUM(count) OVER (ORDER BY customer_id, sales_id) AS cum_uniq
FROM sales
ORDER BY customer_id, sales_id;
 دعونا نلقي نظرة على أشعل النار الأول غير الواضح ، كيف تعتقد كم عدد المطورين سيعتقدون أن نائب الرئيس و cum_uniq متماثلان عند قراءة الكود؟ فكر قليلا؟ ربما ، ولكن لأنه هنا واضح ، وهو واضح جدًا عند قراءة الكود في التطبيق ، وحتى مع عدم التفرد غير الواضح في حقل الفرز.الآن افتح نافذتنا الرائعة.النافذة ، أو بالأحرى الإطار نوعان من ROWS و RANGE ، تعرف على ROWS أولاً.خيارات تقييد الإطار:
دعونا نلقي نظرة على أشعل النار الأول غير الواضح ، كيف تعتقد كم عدد المطورين سيعتقدون أن نائب الرئيس و cum_uniq متماثلان عند قراءة الكود؟ فكر قليلا؟ ربما ، ولكن لأنه هنا واضح ، وهو واضح جدًا عند قراءة الكود في التطبيق ، وحتى مع عدم التفرد غير الواضح في حقل الفرز.الآن افتح نافذتنا الرائعة.النافذة ، أو بالأحرى الإطار نوعان من ROWS و RANGE ، تعرف على ROWS أولاً.خيارات تقييد الإطار:- كل شيء قبل الصف / النطاق الحالي والقيمة الفعلية للصف الحالي
بين سابقة غير مسبوقة
بين سابقة غير مقيدة وحالية
- الصف / النطاق الحالي وكل شيء بعد ذلك
بين الصفوف الحالية والمتابعة غير المقيدة - تحديد عدد الأسطر قبل وبعد تضمين (غير مدعوم لـ RANGE)
بين N و N التالية
بين ROWWEN الحاليين و N التالية
بين N السابقة والسابقة ROW
لكن دعنا نرى الإطار في العمل.نفتح "النافذة" على الخط الحالي وكل ما سبق ، من أجل وظيفة SUM ، كما ترى ، يتزامن هذا مع تصنيف ASCSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY customer_id, sales_id;
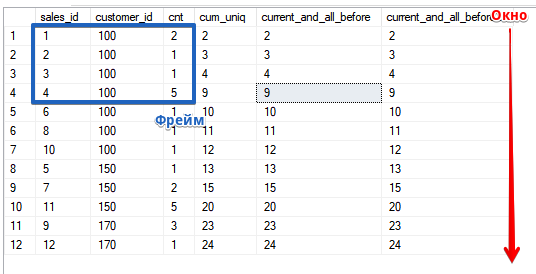 في الوقت نفسه ، أود أن أذكرك بأن ترتيب الفرز في النافذة (في بند OVER ()) لا يرتبط بترتيب الفرز في الاستعلام نفسه ، في المثال هو نفسه من أجل تبسيط الحساب إذا قررت التحقق من الحساب وفهمك لكيفية عمل الوظيفة
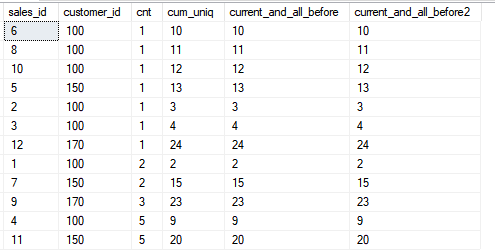
في الوقت نفسه ، أود أن أذكرك بأن ترتيب الفرز في النافذة (في بند OVER ()) لا يرتبط بترتيب الفرز في الاستعلام نفسه ، في المثال هو نفسه من أجل تبسيط الحساب إذا قررت التحقق من الحساب وفهمك لكيفية عمل الوظيفةSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY cnt;
 الآن دعونا نلقي نظرة على وظيفة الإطار عندما نقوم بتضمين جميع الأسطر اللاحقة.
الآن دعونا نلقي نظرة على وظيفة الإطار عندما نقوم بتضمين جميع الأسطر اللاحقة.SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_frame,
SUM(cnt) OVER (ORDER BY customer_id DESC, sales_id DESC) AS current_and_all_order_desc
FROM sales
ORDER BY customer_id, sales_id;
 كما ترى هنا ، يمكنك أيضًا الحصول على نفس النتيجة لوظيفة مجمعة ، إذا كنت تستخدم الفرز العكسي - لكن ROWS أكثر استقرارًا بعض الشيء ، لأنه إذا لم تكن حقول الفرز الخاصة بك فريدة ، فيمكنك الحصول على مفاجأة في شكل نفس القيم.وأخيرًا ، خيار لم يعد من الممكن تقليده من خلال الأنواع ، عندما نحدد عددًا معينًا من الخطوط التي يجب تضمينها في الإطار
كما ترى هنا ، يمكنك أيضًا الحصول على نفس النتيجة لوظيفة مجمعة ، إذا كنت تستخدم الفرز العكسي - لكن ROWS أكثر استقرارًا بعض الشيء ، لأنه إذا لم تكن حقول الفرز الخاصة بك فريدة ، فيمكنك الحصول على مفاجأة في شكل نفس القيم.وأخيرًا ، خيار لم يعد من الممكن تقليده من خلال الأنواع ، عندما نحدد عددًا معينًا من الخطوط التي يجب تضمينها في الإطارSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS before_and_current,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS current_and_1_next,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) AS before2_and_2_next
FROM sales
ORDER BY customer_id, sales_id;
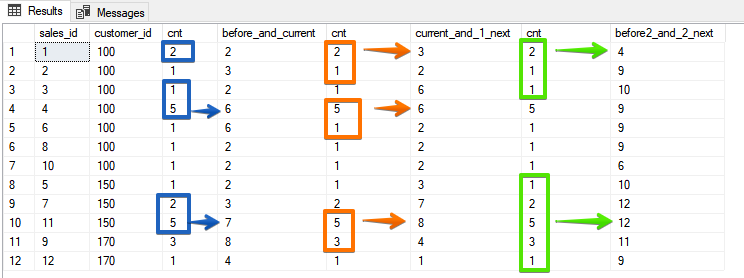 في هذا الخيار ، أشرت بالفعل على وجه التحديد إلى الخطوط الموجودة في النطاق ، وفي رأيي ، أنها أكثر وضوحًا من النتائج.
في هذا الخيار ، أشرت بالفعل على وجه التحديد إلى الخطوط الموجودة في النطاق ، وفي رأيي ، أنها أكثر وضوحًا من النتائج.الفرق بين ROWS و RANGE
الفرق هو أن ROWS تعمل على التوالي و RANGE على نطاق. صحيح ، هذا واضح من الاسم ، لكنه يفسر القليل في الممارسة؟لنلق نظرة على الصورة (المصدر في أسفل المقالة)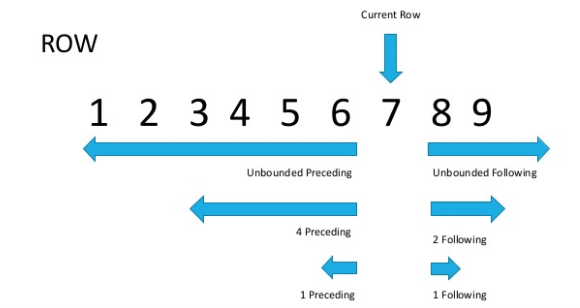
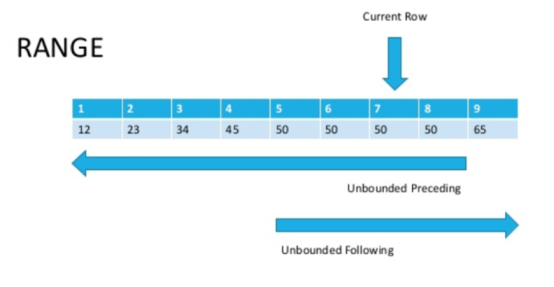 الآن ، إذا نظرنا بعناية ، سيصبح من الواضح أن الصفوف التي لها نفس قيمة معلمة الفرز تسمى النطاق.كما ذكرنا سابقًا ، يقتصر ROWS على سلسلة ، بينما يلتقط RANGE النطاق الكامل للقيم المطابقة التي تحددها في وظيفة النافذة ORDER BY.
الآن ، إذا نظرنا بعناية ، سيصبح من الواضح أن الصفوف التي لها نفس قيمة معلمة الفرز تسمى النطاق.كما ذكرنا سابقًا ، يقتصر ROWS على سلسلة ، بينما يلتقط RANGE النطاق الكامل للقيم المطابقة التي تحددها في وظيفة النافذة ORDER BY.SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, sales_id;
 ROWS - تعمل دائمًا بخط معين ، حتى لو لم يكن الفرز فريدًا ، لكن RANGE يجمع فقط النقاط في نطاقات مع القيم المطابقة لحقول الفرز. وبهذا المعنى ، فإن الوظيفة تشبه إلى حد كبير سلوك دالة SUM () مع الفرز حسب حقل غير فريد. دعونا نرى مثالاً آخر.
ROWS - تعمل دائمًا بخط معين ، حتى لو لم يكن الفرز فريدًا ، لكن RANGE يجمع فقط النقاط في نطاقات مع القيم المطابقة لحقول الفرز. وبهذا المعنى ، فإن الوظيفة تشبه إلى حد كبير سلوك دالة SUM () مع الفرز حسب حقل غير فريد. دعونا نرى مثالاً آخر.SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item;
 يوجد بالفعل حقلين ونطاق يتم تحديدهما من خلال نطاق بقيم متطابقة لكلا الحقلين.والخيار هو عندما ندرج في الحساب جميع الأسطر اللاحقة من السطر الحالي ، والتي في حالة دالة SUM تتزامن مع القيمة التي يمكن الحصول عليها باستخدام الفرز العكسي:
يوجد بالفعل حقلين ونطاق يتم تحديدهما من خلال نطاق بقيم متطابقة لكلا الحقلين.والخيار هو عندما ندرج في الحساب جميع الأسطر اللاحقة من السطر الحالي ، والتي في حالة دالة SUM تتزامن مع القيمة التي يمكن الحصول عليها باستخدام الفرز العكسي:SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id DESC, price_per_item DESC) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item, sales_id desc;
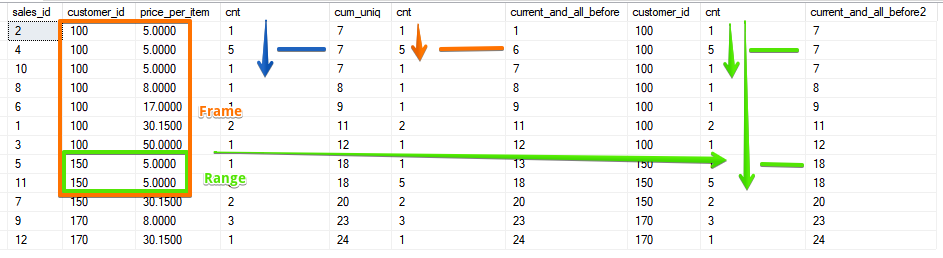 كما ترى ، تلتقط RANGE مرة أخرى النطاق الكامل للأزواج المتطابقة.على الرغم من حقيقة أن وظيفة ROWS و RANGE ليست جديدة في كل مرة ، إلا أن هناك تساؤلات حول كيفية استخدامها. آمل أن تكون هذه المقالة قد أضافت فهمًا لكيفية اختلاف ROWS و RANGE ، والآن لن تشك في هذه الحالة التي تحتاج إلى هذا الإطار أو ذاك.مصدر توضيحي RANGE حول الاختلافووظائف ROWS في النافذة مع Mark SQL Server 2016 ، يكون Mark Tabladilloفي الوقت المناسب للدورة
كما ترى ، تلتقط RANGE مرة أخرى النطاق الكامل للأزواج المتطابقة.على الرغم من حقيقة أن وظيفة ROWS و RANGE ليست جديدة في كل مرة ، إلا أن هناك تساؤلات حول كيفية استخدامها. آمل أن تكون هذه المقالة قد أضافت فهمًا لكيفية اختلاف ROWS و RANGE ، والآن لن تشك في هذه الحالة التي تحتاج إلى هذا الإطار أو ذاك.مصدر توضيحي RANGE حول الاختلافووظائف ROWS في النافذة مع Mark SQL Server 2016 ، يكون Mark Tabladilloفي الوقت المناسب للدورة