اسمي بافيل باركهومينكو ، وأنا مطور ML. في هذه المقالة ، أود أن أتحدث عن تصميم خدمة Yandex.Zen ومشاركة التحسينات التقنية التي سمح إدخالها بزيادة جودة التوصيات. من المنشور سوف تتعلم كيفية العثور على الأكثر ملاءمة للمستخدم من بين ملايين المستندات في بضع ثوانٍ فقط ؛ كيفية إجراء التحلل المستمر لمصفوفة كبيرة (تتكون من ملايين الأعمدة وعشرات الملايين من الصفوف) بحيث تتلقى المستندات الجديدة ناقلها في عشرات الدقائق ؛ كيفية إعادة استخدام تحليل مصفوفة مقالة المستخدم للحصول على تمثيل متجه جيد للفيديو. تحتوي قاعدة بيانات التوصيات الخاصة بنا على ملايين المستندات ذات التنسيقات المختلفة: مقالات نصية تم إنشاؤها على منصتنا وتم أخذها من مواقع خارجية ومقاطع فيديو وسرد ومشاركات قصيرة. يرتبط تطوير هذه الخدمة بعدد كبير من التحديات التقنية. هنا بعض منهم:
تحتوي قاعدة بيانات التوصيات الخاصة بنا على ملايين المستندات ذات التنسيقات المختلفة: مقالات نصية تم إنشاؤها على منصتنا وتم أخذها من مواقع خارجية ومقاطع فيديو وسرد ومشاركات قصيرة. يرتبط تطوير هذه الخدمة بعدد كبير من التحديات التقنية. هنا بعض منهم:- المهام الحسابية المنفصلة: قم بتنفيذ جميع العمليات الثقيلة دون اتصال بالإنترنت ، وفي الوقت الفعلي لا تنفذ إلا التطبيق السريع للنماذج حتى تكون مسؤولًا عن 100-200 مللي ثانية.
- النظر بسرعة في إجراءات المستخدم. لهذا ، من الضروري أن يتم تسليم جميع الأحداث على الفور إلى المُوصي وأن تؤثر على نتائج النماذج.
- اصنع الشريط بحيث يتكيف المستخدمون الجدد بسرعة مع سلوكهم. يجب أن يشعر الأشخاص الذين دخلوا النظام للتو أن ملاحظاتهم تؤثر على التوصيات.
- افهم بسرعة من الذي يوصي بمقالة جديدة.
- استجب بسرعة للظهور المستمر لمحتوى جديد. يتم نشر عشرات الآلاف من المقالات كل يوم ، والعديد منها لها عمر محدود (مثل الأخبار). هذا هو اختلافهم عن الأفلام والموسيقى وغيرها من إنشاء المحتوى طويل الأمد والمكلفة.
- نقل المعرفة من مجال المجال إلى آخر. إذا كان نظام التوصيات يحتوي على نماذج مدربة للمقالات النصية وقمنا بإضافة فيديو إليه ، فيمكنك إعادة استخدام النماذج الموجودة بحيث يتم ترتيب النوع الجديد من المحتوى بشكل أفضل.
سأقول لك كيف قمنا بحل هذه المشاكل.اختيار المرشح
كيف يتم تقليل مجموعة الوثائق قيد النظر في آلاف المرات ، دون الإضرار عمليًا بجودة التصنيف؟لنفترض أننا قمنا بتدريب الكثير من نماذج ML ، وقمنا بإنشاء السمات بناءً عليها ، وقمنا بتدريب نموذج آخر يقوم بتصنيف المستندات للمستخدم. سيكون كل شيء على ما يرام ، ولكن لا يمكنك فقط أخذ جميع الإشارات لجميع المستندات واحتسابها في الوقت الفعلي ، إذا كان هناك الملايين من هذه المستندات ، ويجب تصميم التوصيات في 100-200 مللي ثانية. تتمثل المهمة في الاختيار من بين ملايين مجموعة فرعية معينة سيتم تصنيفها للمستخدم. تسمى هذه الخطوة بشكل عام اختيار المرشح. لديها العديد من المتطلبات. أولاً ، يجب أن يتم الاختيار بسرعة كبيرة ، بحيث يبقى أكبر قدر ممكن من الوقت في الترتيب نفسه. ثانيًا ، من خلال تقليل عدد المستندات للترتيب بشكل كبير ، يجب أن نحافظ على المستندات ذات الصلة بالمستخدم بشكل كامل قدر الإمكان.تطور مبدأ اختيار المرشحين لدينا تطوريًا ، وفي الوقت الحالي وصلنا إلى مخطط متعدد المراحل: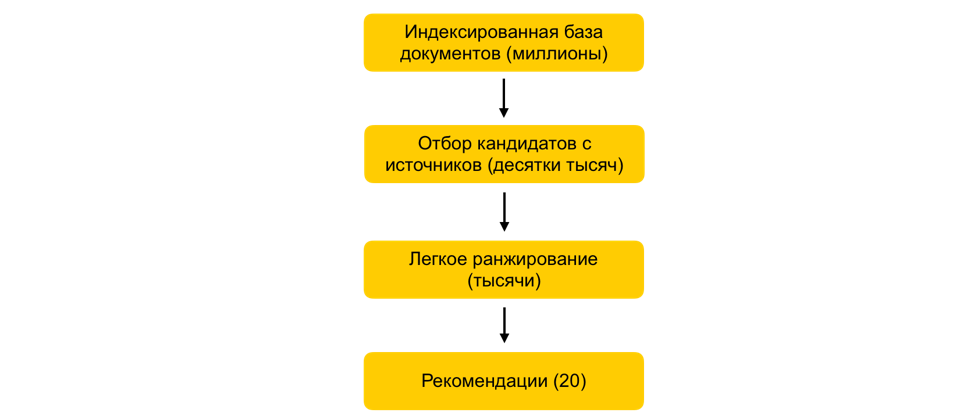 أولاً ، يتم تقسيم جميع المستندات إلى مجموعات ، ويتم أخذ المستندات الأكثر شيوعًا من كل مجموعة. يمكن أن تكون المجموعات مواقع ومواضيع ومجموعات. لكل مستخدم ، بناءً على قصته ، يتم اختيار المجموعات الأقرب إليه ويتم أخذ أفضل المستندات منه بالفعل. نستخدم أيضًا فهرس kNN لتحديد المستندات الأقرب للمستخدم في الوقت الفعلي. هناك عدة طرق لإنشاء فهرس kNN ، لدينا أفضل HNSW المكتسبة(الرسوم البيانية للعالم الصغير المتسلسل الهرمي). هذا نموذج هرمي يسمح لك بالعثور على أقرب نواقل للمستخدم من قاعدة بيانات المليون في بضع ثوان. في السابق ، كنا نقوم بفهرسة قاعدة بياناتنا الكاملة من المستندات في وضع عدم الاتصال. نظرًا لأن البحث في الفهرس يعمل بسرعة كبيرة ، إذا كان هناك العديد من عمليات التضمين القوية ، فيمكنك إنشاء العديد من الفهارس (فهرس واحد لكل تضمين) والوصول إلى كل منها في الوقت الفعلي.لا يزال لدينا عشرات الآلاف من المستندات لكل مستخدم. لا يزال هذا كثيرًا لاحتساب جميع السمات ، لذلك في هذه المرحلة نطبق التصنيف السهل - نموذج تصنيف ثقيل خفيف الوزن مع سمات أقل. تتمثل المهمة في التنبؤ بالمستندات التي سيحتوي عليها النموذج الثقيل في الأعلى. سيتم استخدام المستندات ذات أعلى تنبؤ في النموذج الثقيل ، أي في المرحلة الأخيرة من التصنيف. يسمح هذا النهج لعشرات المللي ثانية بتقليص قاعدة بيانات المستندات التي ينظر فيها المستخدم من ملايين إلى آلاف.
أولاً ، يتم تقسيم جميع المستندات إلى مجموعات ، ويتم أخذ المستندات الأكثر شيوعًا من كل مجموعة. يمكن أن تكون المجموعات مواقع ومواضيع ومجموعات. لكل مستخدم ، بناءً على قصته ، يتم اختيار المجموعات الأقرب إليه ويتم أخذ أفضل المستندات منه بالفعل. نستخدم أيضًا فهرس kNN لتحديد المستندات الأقرب للمستخدم في الوقت الفعلي. هناك عدة طرق لإنشاء فهرس kNN ، لدينا أفضل HNSW المكتسبة(الرسوم البيانية للعالم الصغير المتسلسل الهرمي). هذا نموذج هرمي يسمح لك بالعثور على أقرب نواقل للمستخدم من قاعدة بيانات المليون في بضع ثوان. في السابق ، كنا نقوم بفهرسة قاعدة بياناتنا الكاملة من المستندات في وضع عدم الاتصال. نظرًا لأن البحث في الفهرس يعمل بسرعة كبيرة ، إذا كان هناك العديد من عمليات التضمين القوية ، فيمكنك إنشاء العديد من الفهارس (فهرس واحد لكل تضمين) والوصول إلى كل منها في الوقت الفعلي.لا يزال لدينا عشرات الآلاف من المستندات لكل مستخدم. لا يزال هذا كثيرًا لاحتساب جميع السمات ، لذلك في هذه المرحلة نطبق التصنيف السهل - نموذج تصنيف ثقيل خفيف الوزن مع سمات أقل. تتمثل المهمة في التنبؤ بالمستندات التي سيحتوي عليها النموذج الثقيل في الأعلى. سيتم استخدام المستندات ذات أعلى تنبؤ في النموذج الثقيل ، أي في المرحلة الأخيرة من التصنيف. يسمح هذا النهج لعشرات المللي ثانية بتقليص قاعدة بيانات المستندات التي ينظر فيها المستخدم من ملايين إلى آلاف.خطوة ALS في وقت التشغيل
كيف تأخذ في الاعتبار تعليقات المستخدم فورًا بعد النقرة؟عامل مهم في التوصيات هو وقت الاستجابة لتعليقات المستخدم. هذا مهم بشكل خاص للمستخدمين الجدد: عندما يبدأ شخص ما للتو في استخدام نظام التوصيات ، فإنه يتلقى دفقًا غير مخصص من المستندات لمواضيع مختلفة. بمجرد أن يقوم بالنقرة الأولى ، يجب أن تأخذ هذا في الاعتبار على الفور وأن تتكيف مع اهتماماته. إذا تم حساب جميع العوامل في وضع عدم الاتصال ، فستصبح استجابة النظام السريعة مستحيلة بسبب التأخير. لذلك تحتاج إلى معالجة إجراءات المستخدم في الوقت الحقيقي. لهذه الأغراض ، نستخدم خطوة ALS في وقت التشغيل لبناء تمثيل متجهي للمستخدم.افترض أن لدينا تمثيل متجه لجميع المستندات. على سبيل المثال ، يمكننا البناء في وضع عدم الاتصال بناءً على تضمين نص المقالة باستخدام ELMo أو BERT أو نماذج تعلم الآلة الأخرى. كيف يمكن للمرء الحصول على تمثيل متجه للمستخدمين في نفس المساحة بناءً على تفاعلهم في النظام؟المبدأ العام لتكوين وتحلل مصفوفة وثيقة المستخدمm n . . m x n: , — . , ́ , . (, , ) - — , 1, –1.
: P (m x d) Q (d x n), d — ( ). d- ( — P, — Q). . , , .

واحدة من الطرق الممكنة لتحلل المصفوفة هي ALS (المربعات الصغرى المتناوبة). سنقوم بتحسين وظيفة الخسارة التالية:
هنا r ui هو تفاعل المستخدم u مع المستند i ، q i هو متجه المستند i ، p u هو ناقل المستخدم u.ثم يتم العثور على متجه المستخدم الأمثل من وجهة نظر متوسط الخطأ التربيعي (لناقلات المستندات الثابتة) بشكل تحليلي عن طريق حل الانحدار الخطي المقابل.وهذا ما يسمى بخطوة ALS. وتتكون خوارزمية ALS نفسها من حقيقة أننا نقوم بالتناوب بإصلاح أحد المصفوفات (المستخدمون والمقالات) وتحديث الآخر ، وإيجاد الحل الأمثل.لحسن الحظ ، يعد العثور على تمثيل متجه المستخدم عملية سريعة إلى حد ما يمكن إجراؤها في وقت التشغيل باستخدام تعليمات المتجه. تتيح لك هذه الخدعة أن تأخذ في الاعتبار على الفور ملاحظات المستخدم في الترتيب. يمكن استخدام نفس التضمين في فهرس kNN لتحسين اختيار المرشحين.التصفية التعاونية الموزعة
كيف يتم عمل معامل المصفوفة الموزعة بشكل متزايد والعثور بسرعة على تمثيل متجه للمقالات الجديدة؟المحتوى ليس المصدر الوحيد لإشارات التوصيات. المعلومات التعاونية مصدر مهم آخر. تقليديا يمكن الحصول على علامات جيدة في الترتيب من تحلل مصفوفة وثيقة المستخدم. ولكن عند محاولة القيام بهذا التحلل ، واجهنا مشاكل:1. لدينا ملايين المستندات وعشرات الملايين من المستخدمين. المصفوفة لا تتناسب تمامًا مع جهاز واحد ، وسيكون التحلل طويلًا جدًا.2. معظم محتوى النظام له عمر قصير: تظل المستندات ذات صلة لبضع ساعات فقط. لذلك ، من الضروري إنشاء تمثيل المتجه الخاص بهم في أسرع وقت ممكن.3. إذا قمت ببناء التحلل مباشرة بعد نشر المستند ، فلن يكون لدى عدد كاف من المستخدمين الوقت لتقييمه. لذلك ، من المرجح ألا يكون تمثيل ناقلات المرض جيدًا.4. إذا أعجب المستخدم أو لم يعجبه ، فلن نتمكن من أخذ ذلك في الاعتبار على الفور في التوسع.لحل هذه المشاكل ، قمنا بتطبيق تحليل موزّع لمصفوفة مستند المستخدم مع تحديث تدريجي متكرر. كيف تعمل بالضبط؟لنفترض أن لدينا مجموعة من آلات N (N في المئات) ونريد إجراء تحليل موزع للمصفوفة عليها ، والتي لا تتناسب مع جهاز واحد. والسؤال هو كيفية إجراء هذا التحلل بحيث ، من ناحية ، هناك بيانات كافية على كل جهاز ، ومن ناحية أخرى ، بحيث تكون الحسابات مستقلة؟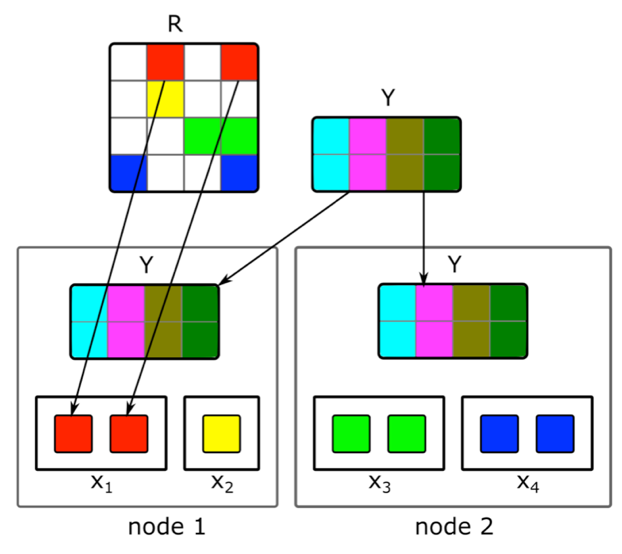 سوف نستخدم خوارزمية تحليل ALS الموضحة أعلاه. ضع في اعتبارك كيفية تنفيذ خطوة ALS واحدة بطريقة موزعة - ستكون بقية الخطوات متشابهة. لنفترض أن لدينا مصفوفة ثابتة من المستندات ونريد إنشاء مصفوفة من المستخدمين. للقيام بذلك ، نقسمها إلى أجزاء N في صفوف ، كل جزء سيحتوي على نفس العدد تقريبًا من الصفوف. سنرسل إلى كل آلة خلايا غير فارغة من الأسطر المقابلة ، بالإضافة إلى مصفوفة لتضمين المستندات (بالكامل). نظرًا لأنها ليست كبيرة جدًا ، وعادة ما تكون مصفوفة مستندات المستخدم قليلة جدًا ، فستناسب هذه البيانات على جهاز عادي.يمكن تكرار هذه الحيلة لعدة عصور حتى يتقارب النموذج ، مما يؤدي إلى تغيير المصفوفة الثابتة بالتناوب. ولكن حتى ذلك الحين ، يمكن أن يستمر تحلل المصفوفة عدة ساعات. وهذا لا يحل مشكلة الحاجة إلى تلقي عمليات تضمين المستندات الجديدة بسرعة وتحديث عمليات تضمين تلك التي كانت بها معلومات قليلة عند بناء النموذج.ساعدنا إدخال تحديث تدريجي سريع للنموذج. لنفترض أن لدينا نموذجًا مدربًا حاليًا. منذ تدريبها ، ظهرت مقالات جديدة تفاعل معها مستخدمونا ، وكذلك مقالات لم يكن لها تفاعل كبير مع التدريب. لتضمين مثل هذه المقالات بسرعة ، نستخدم عمليات تضمين المستخدم التي تم الحصول عليها أثناء التدريب الكبير الأول للنموذج ونتخذ خطوة ALS واحدة لحساب مصفوفة المستندات مع مصفوفة ثابتة من المستخدمين. يسمح لك هذا بتلقي عمليات التضمين بسرعة كبيرة - في غضون بضع دقائق بعد نشر المستند - وغالبًا ما يتم تحديث عمليات تضمين المستندات الجديدة.من أجل مراعاة الإجراءات البشرية فورًا للتوصيات ، لا نستخدم في وقت التشغيل عمليات تضمين المستخدم المستلمة في وضع عدم الاتصال. بدلاً من ذلك ، نتخذ خطوة ALS ونحصل على متجه المستخدم الحالي.
سوف نستخدم خوارزمية تحليل ALS الموضحة أعلاه. ضع في اعتبارك كيفية تنفيذ خطوة ALS واحدة بطريقة موزعة - ستكون بقية الخطوات متشابهة. لنفترض أن لدينا مصفوفة ثابتة من المستندات ونريد إنشاء مصفوفة من المستخدمين. للقيام بذلك ، نقسمها إلى أجزاء N في صفوف ، كل جزء سيحتوي على نفس العدد تقريبًا من الصفوف. سنرسل إلى كل آلة خلايا غير فارغة من الأسطر المقابلة ، بالإضافة إلى مصفوفة لتضمين المستندات (بالكامل). نظرًا لأنها ليست كبيرة جدًا ، وعادة ما تكون مصفوفة مستندات المستخدم قليلة جدًا ، فستناسب هذه البيانات على جهاز عادي.يمكن تكرار هذه الحيلة لعدة عصور حتى يتقارب النموذج ، مما يؤدي إلى تغيير المصفوفة الثابتة بالتناوب. ولكن حتى ذلك الحين ، يمكن أن يستمر تحلل المصفوفة عدة ساعات. وهذا لا يحل مشكلة الحاجة إلى تلقي عمليات تضمين المستندات الجديدة بسرعة وتحديث عمليات تضمين تلك التي كانت بها معلومات قليلة عند بناء النموذج.ساعدنا إدخال تحديث تدريجي سريع للنموذج. لنفترض أن لدينا نموذجًا مدربًا حاليًا. منذ تدريبها ، ظهرت مقالات جديدة تفاعل معها مستخدمونا ، وكذلك مقالات لم يكن لها تفاعل كبير مع التدريب. لتضمين مثل هذه المقالات بسرعة ، نستخدم عمليات تضمين المستخدم التي تم الحصول عليها أثناء التدريب الكبير الأول للنموذج ونتخذ خطوة ALS واحدة لحساب مصفوفة المستندات مع مصفوفة ثابتة من المستخدمين. يسمح لك هذا بتلقي عمليات التضمين بسرعة كبيرة - في غضون بضع دقائق بعد نشر المستند - وغالبًا ما يتم تحديث عمليات تضمين المستندات الجديدة.من أجل مراعاة الإجراءات البشرية فورًا للتوصيات ، لا نستخدم في وقت التشغيل عمليات تضمين المستخدم المستلمة في وضع عدم الاتصال. بدلاً من ذلك ، نتخذ خطوة ALS ونحصل على متجه المستخدم الحالي.نقل إلى منطقة مجال أخرى
كيفية استخدام ملاحظات المستخدم على المقالات النصية لبناء تمثيل متجهي للفيديو؟في البداية ، أوصينا بمقالات نصية فقط ، لذلك تركز العديد من الخوارزميات على هذا النوع من المحتوى. ولكن عند إضافة محتوى من نوع مختلف ، واجهنا الحاجة إلى تكييف النماذج. كيف تمكنا من حل هذه المشكلة باستخدام مثال الفيديو؟ خيار واحد هو إعادة تدريب جميع النماذج من نقطة الصفر. لكن هذه فترة طويلة ، بالإضافة إلى ذلك ، تتطلب بعض الخوارزميات حجم عينة التدريب ، التي لم تعد بعد بالكمية المناسبة لنوع جديد من المحتوى في اللحظات الأولى من حياتها على الخدمة.ذهبنا في الاتجاه الآخر وأعدنا استخدام النماذج النصية للفيديو. في إنشاء تمثيلات متجهة للفيديو ، ساعدتنا نفس الحيلة مع ALS. أخذنا تمثيلًا متجهًا للمستخدمين بناءً على المقالات النصية واتخذنا خطوة ALS باستخدام معلومات حول مشاهدات الفيديو. لذلك حصلنا بسهولة على تمثيل متجه للفيديو. وفي وقت التشغيل ، نقوم ببساطة بحساب القرب بين متجه المستخدم الذي تم الحصول عليه من المقالات النصية وناقلات الفيديو.استنتاج
إن تطوير جوهر نظام التوصية في الوقت الحقيقي محفوف بالعديد من المهام. من الضروري معالجة البيانات بسرعة وتطبيق طرق ML لاستخدام هذه البيانات بشكل فعال ؛ بناء أنظمة موزعة معقدة قادرة على معالجة إشارات المستخدم ووحدات المحتوى الجديدة في الحد الأدنى من الوقت ؛ والعديد من المهام الأخرى.في النظام الحالي ، الذي وصفته الجهاز ، تزداد جودة التوصيات للمستخدم مع نشاطه ومدة الخدمة. ولكن بالطبع ، تكمن الصعوبة الرئيسية هنا: من الصعب على النظام أن يفهم على الفور مصالح شخص لم يتفاعل مع المحتوى كثيرًا. تحسين التوصيات للمستخدمين الجدد هو شاغلنا الرئيسي. سنستمر في تحسين الخوارزميات حتى يتم إدخال المحتوى ذي الصلة بالشخص بشكل أسرع ولا يظهر غير ذي صلة.