شرط نموذجي لتنفيذ CI / CD في Kubernetes: يجب أن يكون التطبيق قادرًا على التوقف عن قبول طلبات العملاء الجديدة قبل التوقف ، والأهم من ذلك ، إكمال الطلبات الحالية بنجاح. يسمح لك الامتثال لهذا الشرط بعدم تحقيق أي وقت تعطل أثناء النشر. ومع ذلك ، حتى عند استخدام الحزم الشائعة جدًا (مثل NGINX و PHP-FPM) ، قد تواجه صعوبات تؤدي إلى زيادة في الأخطاء مع كل عملية نشر ...
يسمح لك الامتثال لهذا الشرط بعدم تحقيق أي وقت تعطل أثناء النشر. ومع ذلك ، حتى عند استخدام الحزم الشائعة جدًا (مثل NGINX و PHP-FPM) ، قد تواجه صعوبات تؤدي إلى زيادة في الأخطاء مع كل عملية نشر ...نظرية. كيف يعيش جراب
لقد نشرنا هذه المقالة بالفعل بالتفصيل حول دورة حياة الكبسولة . في سياق هذا الموضوع ، نحن مهتمون بما يلي: في اللحظة التي يدخل فيها البود إلى حالة الإنهاء ، يتوقف إرسال الطلبات الجديدة إليه ( تتم إزالة الجراب من قائمة نقاط النهاية للخدمة). وبالتالي ، لتجنب توقف العمل أثناء النشر ، من جانبنا ، يكفي حل مشكلة إيقاف التطبيق بشكل صحيح.يجب أن نتذكر أيضًا أن فترة السماح هي 30 ثانية بشكل افتراضي : بعد ذلك ، سيتم إنهاء الكود ويجب أن يتمكن التطبيق من معالجة جميع الطلبات قبل هذه الفترة. ملحوظة: على الرغم من أن أي طلب يتم تشغيله لأكثر من 5-10 ثوانٍ يمثل مشكلة بالفعل ، ولن يساعده الإغلاق الرشيق بعد الآن ...لفهم أفضل لما يحدث عندما تنتهي pod من عملها ، يكفي دراسة المخطط التالي: A1 ، B1 - الحصول على تغييرات حول حالة
A1 ، B1 - الحصول على تغييرات حول حالة
الجزء الفرعي A2: إرسال SIGTERM
B2 - إزالة pod من نقاط النهاية
B3 - الحصول على التغييرات (تغيرت قائمة نقاط النهاية)
B4 - تحديث قواعد iptablesملاحظة: لا يتم إزالة pod endpod وإرسال SIGTERM بالتسلسل ، ولكن بالتوازي. ونظرًا لحقيقة أن Ingress لا تتلقى قائمة محدثة بنقاط النهاية على الفور ، سيتم إرسال الطلبات الجديدة من العملاء إلى pod ، مما سيؤدي إلى حدوث 500 خطأ أثناء إنهاء pod( ترجمنا مواد أكثر تفصيلاً حول هذا الموضوع ) . أنت بحاجة إلى حل هذه المشكلة بالطرق التالية:- إرسال رؤوس الاتصال: استجابة قريبة (إذا كانت تتعلق بتطبيق HTTP).
- إذا لم تكن هناك طريقة لإجراء تغييرات على الرمز ، فإن المقالة تصف حلاً سيسمح لك بمعالجة الطلبات حتى نهاية الفترة الرشيقة.
نظرية. كيف تنهي NGINX و PHP-FPM عملياتهما
Nginx
لنبدأ بـ NGINX ، لأن كل شيء أصبح أكثر أو أقل وضوحًا معها. منغمسًا في النظرية ، نتعلم أن NGINX لديها عملية رئيسية واحدة والعديد من "العمال" - هذه عمليات تابعة تعالج طلبات العملاء. يتم توفير ميزة ملائمة: استخدام الأمر nginx -s <SIGNAL>لإنهاء العمليات إما في وضع إيقاف التشغيل السريع أو في إيقاف تشغيل رشيق. من الواضح أننا مهتمون بالتحديد بالخيار الأخير.ثم كل شيء بسيط: تحتاج إلى إضافة أمر إلى خطاف preStop الذي سيرسل إشارة حول إيقاف التشغيل الآمن . يمكن القيام بذلك في النشر ، في كتلة الحاوية: lifecycle:
preStop:
exec:
command:
- /usr/sbin/nginx
- -s
- quit
الآن ، في الوقت الذي يكمل فيه البود عمله في سجلات حاويات NGINX ، سنرى ما يلي:2018/01/25 13:58:31 [notice] 1#1: signal 3 (SIGQUIT) received, shutting down
2018/01/25 13:58:31 [notice] 11#11: gracefully shutting down
وهذا سيعني ما نحتاجه: تنتظر NGINX إتمام الاستعلامات ، ثم تقتل العملية. ومع ذلك ، سيتم مناقشة مشكلة شائعة أدناه ، لأنه ، حتى إذا كان هناك أمر ، لا nginx -s quitتكتمل العملية بشكل صحيح.وفي هذه المرحلة انتهينا من NGINX: على الأقل يمكنك أن تفهم من السجلات أن كل شيء يعمل كما ينبغي.ماذا عن PHP-FPM؟ كيف يتعامل مع الاغلاق الرشيق؟ دعنا نحصل على حق.PHP-FPM
في حالة PHP-FPM ، معلومات أقل قليلاً. إذا ركزت على الدليل الرسمي لـ PHP-FPM ، فسيخبرك أنه يتم تلقي إشارات POSIX التالية:SIGINT، SIGTERM- إيقاف التشغيل السريع.SIGQUIT - إغلاق رشيق (ما نحتاجه).
بقية الإشارات في هذه المشكلة ليست مطلوبة ، لذلك ، تم حذف تحليلها. لإكمال العملية بشكل صحيح ، ستحتاج إلى كتابة خطاف preStop التالي: lifecycle:
preStop:
exec:
command:
- /bin/kill
- -SIGQUIT
- "1"
للوهلة الأولى ، هذا هو كل ما هو مطلوب لإجراء إغلاق رشيق في كلتا الحاويتين. ومع ذلك ، فإن المهمة أكثر تعقيدًا مما تبدو عليه. بعد ذلك ، فحصنا حالتين لم ينجح فيه الإغلاق الرشيق وتسبب في عدم إمكانية الوصول إلى المشروع على المدى القصير أثناء النشر.ممارسة. مشاكل محتملة مع إغلاق رشيق
Nginx
بادئ ذي بدء ، من المفيد أن نتذكر: بالإضافة إلى تنفيذ الأمر ، nginx -s quitهناك خطوة أخرى يجب الانتباه إليها. واجهتنا مشكلة عندما أرسلت NGINX بدلاً من إشارة SIGQUIT SIGTERM على أي حال ، والتي لم تكتمل الطلبات بشكل صحيح. يمكن العثور على حالات مماثلة ، على سبيل المثال ، هنا . للأسف ، لم نتمكن من تحديد سبب محدد لهذا السلوك: كان هناك شك في إصدار NGINX ، ولكن لم يتم تأكيده. كانت الأعراض أنه في سجلات حاوية NGINX لوحظت الرسائل "مأخذ مفتوح رقم 10 اليسار في اتصال 5" ، وبعد ذلك توقف الجراب.يمكننا ملاحظة مثل هذه المشكلة ، على سبيل المثال ، من خلال الإجابات على Ingress التي نحتاجها: مؤشرات رمز الحالة في وقت النشرفي هذه الحالة ، نحصل فقط على رمز الخطأ 503 من Ingress نفسها: لا يمكنها الوصول إلى حاوية NGINX ، لأنها لم تعد متاحة. إذا نظرت إلى سجلات الحاوية باستخدام NGINX ، فستحتوي على ما يلي:
مؤشرات رمز الحالة في وقت النشرفي هذه الحالة ، نحصل فقط على رمز الخطأ 503 من Ingress نفسها: لا يمكنها الوصول إلى حاوية NGINX ، لأنها لم تعد متاحة. إذا نظرت إلى سجلات الحاوية باستخدام NGINX ، فستحتوي على ما يلي:[alert] 13939#0: *154 open socket #3 left in connection 16
[alert] 13939#0: *168 open socket #6 left in connection 13
بعد تغيير إشارة التوقف ، تبدأ الحاوية في التوقف بشكل صحيح: وهذا مؤكد من خلال حقيقة أن خطأ 503 لم يعد ملاحظًا.إذا واجهت مشكلة مماثلة ، فمن المنطقي معرفة أي إشارة توقف يتم استخدامها في الحاوية وكيف يبدو خطاف preStop بالضبط. من الممكن أن السبب يكمن بالضبط في ذلك.PHP-FPM ... والمزيد
يتم وصف مشكلة PHP-FPM بشكل تافه: فهي لا تنتظر اكتمال العمليات الفرعية ، وتنهيها ، بسبب وجود 502 خطأ أثناء النشر والعمليات الأخرى. ومنذ عام 2005 كانت هناك عدة رسائل خطأ على bugs.php.net (على سبيل المثال، هنا و هنا ) التي تصف هذه المشكلة. ولكن ربما لن ترى أي شيء في السجلات: ستعلن PHP-FPM عن اكتمال عمليتها دون أي أخطاء أو إشعارات من جهات خارجية.تجدر الإشارة إلى أن المشكلة نفسها قد تعتمد ، إلى حد أقل أو أكبر ، على التطبيق نفسه وقد لا تظهر ، على سبيل المثال ، في المراقبة. إذا كنت لا تزال تواجهه ، فحينئذٍ يتبادر إلى الذهن حل بديل بسيط: أضف خطاف preStop باستخدامsleep(30). سيسمح لك بإكمال جميع الطلبات التي كانت من قبل (نحن لا نقبل طلبات جديدة ، حيث إن الجراب موجود بالفعل في حالة الإنهاء ) ، وبعد 30 ثانية سينتهي الجراب نفسه بإشارة SIGTERM.اتضح أنه lifecycleبالنسبة للحاوية ستبدو كما يلي: lifecycle:
preStop:
exec:
command:
- /bin/sleep
- "30"
ومع ذلك ، نظرًا لمؤشر 30 ثانية ، sleepسنقوم بزيادة وقت النشر بشكل ملحوظ ، حيث سيتم إنهاء كل جراب لمدة 30 ثانية على الأقل ، وهو أمر سيئ. ما الذي يمكن عمله بهذا؟دعونا ننتقل إلى الطرف المسؤول عن التنفيذ المباشر للتطبيق. في حالتنا ، هذه هي PHP-FPM ، والتي لا تراقب بشكل افتراضي تنفيذ العمليات التابعة لها : يتم إنهاء العملية الرئيسية على الفور. يمكن تغيير هذا السلوك باستخدام توجيه process_control_timeoutيحدد الحدود الزمنية لانتظار الإشارات من المعلم من خلال العمليات الفرعية. إذا قمت بتعيين القيمة إلى 20 ثانية ، فسوف يغطي هذا معظم الطلبات التي يتم تشغيلها في الحاوية ، وبعد اكتمالها ، سيتم إيقاف العملية الرئيسية.مع هذه المعرفة ، سنعود إلى مشكلتنا الأخيرة. كما سبق ذكره ، فإن Kubernetes ليست منصة متجانسة: يستغرق بعض الوقت للتفاعل بين مكوناتها المختلفة. هذا صحيح بشكل خاص عندما ننظر في عمل Ingresss والمكونات الأخرى ذات الصلة ، لأنه بسبب هذا التأخير في وقت النشر ، من السهل الحصول على زيادة قدرها 500 خطأ. على سبيل المثال ، قد يحدث خطأ في مرحلة إرسال طلب إلى المنبع ، ولكن "الفجوة الزمنية" للتفاعل بين المكونات قصيرة نوعًا ما - أقل من ثانية.لذلك ، بالاقتران مع التوجيه المذكور أعلاه process_control_timeout، يمكن استخدام البناء التالي من أجل lifecycle:lifecycle:
preStop:
exec:
command: ["/bin/bash","-c","/bin/sleep 1; kill -QUIT 1"]
في هذه الحالة ، نحن نعوض التأخير من قبل الفريق sleepولا نزيد من وقت النشر بشكل ملحوظ: هل هناك فرق ملحوظ بين 30 ثانية وواحدة؟ .. في الواقع ، يتم الاعتناء بـ "الوظيفة الرئيسية" process_control_timeout، ولكن يتم lifecycleاستخدامها فقط كـ "شبكة أمان" في حالة التأخير.بشكل عام ، فإن السلوك الموصوف والحل البديل المقابل ليس فقط PHP-FPM . قد تنشأ حالة مماثلة بطريقة أو بأخرى عند استخدام لغات / أطر أخرى. إذا لم تتمكن من إصلاح إيقاف التشغيل الآمن بطرق أخرى - على سبيل المثال ، أعد كتابة الشفرة بحيث يعالج التطبيق إشارات الإنهاء بشكل صحيح - يمكنك استخدام الطريقة الموضحة. قد لا يكون أجمل ، لكنه يعمل.ممارسة. حمل الاختبار للتحقق من أداء جراب
اختبار الحمل هو إحدى الطرق للتحقق من كيفية عمل الحاوية ، لأن هذا الإجراء يجعلك أقرب إلى ظروف القتال الحقيقية عندما يزور المستخدمون الموقع. يمكنك استخدام Yandex.Tank لاختبار التوصيات أعلاه : فهو يغطي جميع احتياجاتنا بشكل مثالي. فيما يلي نصائح وحيل للاختبار بشكل واضح - بفضل الرسوم البيانية لـ Grafana و Yandex.Tank نفسها - مثال من تجربتنا.أهم شيء هنا هو التحقق من التغييرات في المراحل.. بعد إضافة إصلاح جديد ، قم بتشغيل الاختبار ومعرفة ما إذا كانت النتائج قد تغيرت مقارنة بالإطلاق السابق. خلاف ذلك ، سيكون من الصعب تحديد حلول غير فعالة ، وفي المستقبل يمكنك فقط إلحاق الضرر (على سبيل المثال ، زيادة وقت النشر).تحذير آخر - انظر إلى سجلات الحاوية أثناء إنهائها. هل يتم تسجيل معلومات إيقاف التشغيل الممتازة هناك؟ هل هناك أي أخطاء في السجلات عند الوصول إلى الموارد الأخرى (على سبيل المثال ، حاوية PHP-FPM المجاورة)؟ أخطاء التطبيق نفسه (كما في حالة NGINX الموصوفة أعلاه)؟ آمل أن تساعد المعلومات التمهيدية الواردة في هذه المقالة على فهم ما يحدث للحاوية بشكل أفضل أثناء إنهائها.لذلك ، تم إجراء أول اختبار تجريبي بدون lifecycleأو بدون توجيهات إضافية لخادم التطبيق (process_control_timeoutفي PHP-FPM). كان الغرض من هذا الاختبار هو تحديد العدد التقريبي للأخطاء (وما إذا كانت موجودة على الإطلاق). أيضًا ، من المعلومات الإضافية ، يجب أن يكون معروفًا أن متوسط وقت النشر لكل موقد كان حوالي 5-10 ثوانٍ لحالة الاستعداد الكامل. النتائج هي كما يلي: تظهر بقعة من أخطاء 502 على لوحة معلومات Yandex.Tank ، والتي حدثت في وقت النشر واستمرت لمدة تصل إلى 5 ثوانٍ. من المفترض أن هذا أنهى الطلبات الحالية للجراب القديم عندما تم إنهاؤه. بعد ذلك ، ظهرت 503 أخطاء ، والتي نتجت عن حاوية NGINX متوقفة ، والتي تم فصلها أيضًا بسبب الواجهة الخلفية (بسبب عدم تمكن Ingress من الاتصال بها).دعونا نرى كيف
تظهر بقعة من أخطاء 502 على لوحة معلومات Yandex.Tank ، والتي حدثت في وقت النشر واستمرت لمدة تصل إلى 5 ثوانٍ. من المفترض أن هذا أنهى الطلبات الحالية للجراب القديم عندما تم إنهاؤه. بعد ذلك ، ظهرت 503 أخطاء ، والتي نتجت عن حاوية NGINX متوقفة ، والتي تم فصلها أيضًا بسبب الواجهة الخلفية (بسبب عدم تمكن Ingress من الاتصال بها).دعونا نرى كيفprocess_control_timeoutفي PHP-FPM ستساعدنا في انتظار اكتمال العمليات الفرعية ، أي إصلاح مثل هذه الأخطاء. النشر المتكرر باستخدام هذا التوجيه: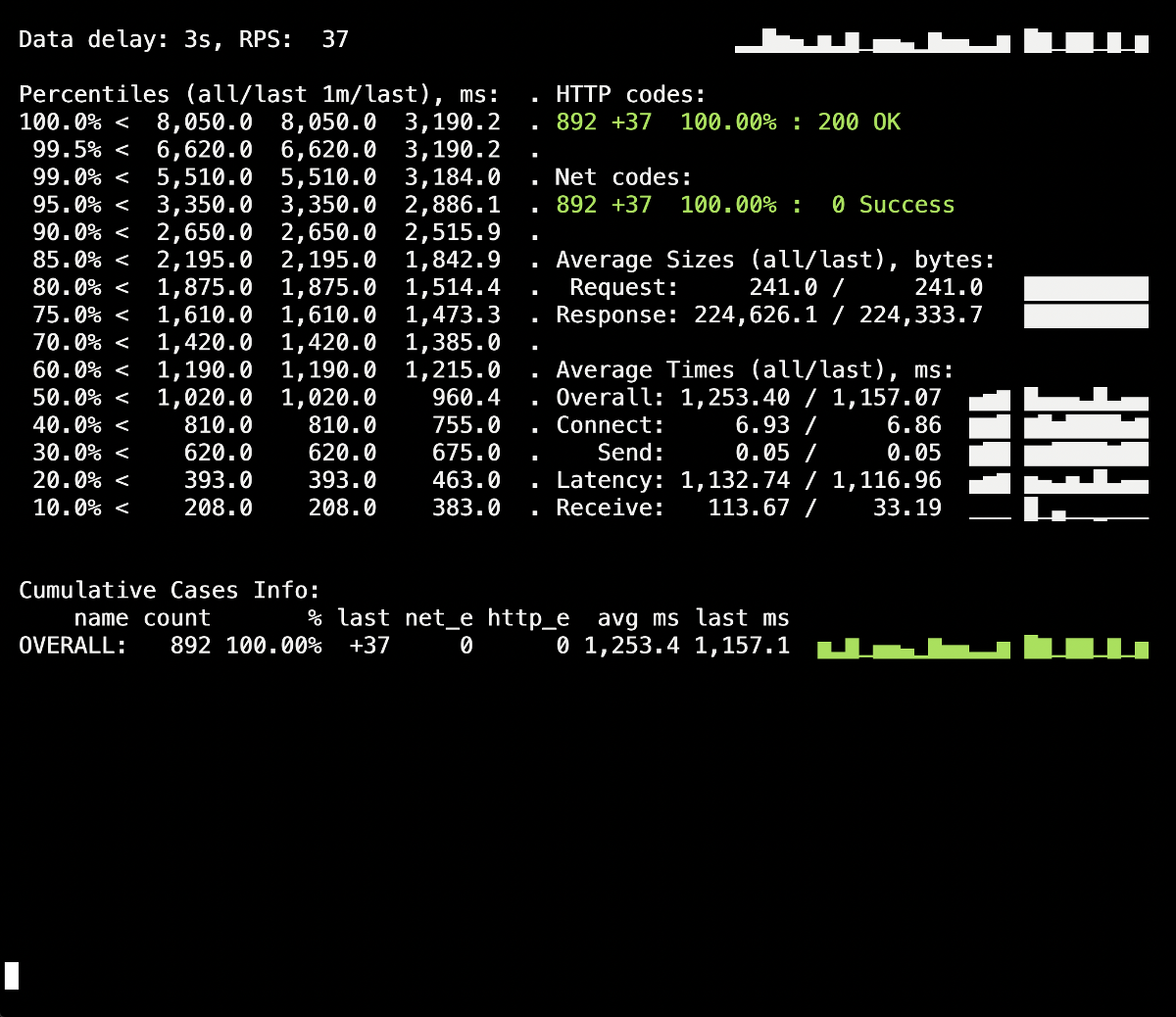 لم يعد هناك المزيد من الأخطاء أثناء نشر 500s! النشر ناجح ، يعمل الإغلاق الرشيق.ومع ذلك ، يجدر تذكر اللحظة مع حاويات Ingress ، وهي نسبة صغيرة من الأخطاء التي يمكن أن نقع فيها بسبب الفارق الزمني. لتجنبها ، يبقى إضافة البناء مع
لم يعد هناك المزيد من الأخطاء أثناء نشر 500s! النشر ناجح ، يعمل الإغلاق الرشيق.ومع ذلك ، يجدر تذكر اللحظة مع حاويات Ingress ، وهي نسبة صغيرة من الأخطاء التي يمكن أن نقع فيها بسبب الفارق الزمني. لتجنبها ، يبقى إضافة البناء مع sleepوتكرار النشر. ومع ذلك ، في حالتنا الخاصة ، لم تكن هناك تغييرات مرئية (لا توجد أخطاء مرة أخرى).استنتاج
لإكمال العملية بشكل صحيح ، نتوقع السلوك التالي من التطبيق:- انتظر بضع ثوانٍ ، ثم توقف عن قبول الاتصالات الجديدة.
- انتظر حتى تكتمل جميع الطلبات وتغلق جميع الاتصالات المستمرة التي لا تنفذ الطلبات.
- أكمل عمليتك.
ومع ذلك ، لا يمكن لجميع التطبيقات العمل بهذه الطريقة. أحد حلول المشكلة في حقائق Kubernetes هو:- إضافة خطاف قبل الإيقاف ينتظر بضع ثوانٍ
- دراسة ملف تكوين الواجهة الخلفية للمعلمات ذات الصلة.
يسمح لنا مثال NGINX بفهم أنه حتى التطبيق الذي يجب عليه في البداية معالجة الإشارات بشكل صحيح للإنجاز قد لا يفعل ذلك ، لذلك من المهم التحقق من وجود 500 خطأ أثناء نشر التطبيق. كما يسمح لك بالنظر إلى المشكلة على نطاق أوسع وعدم التركيز على جراب أو حاوية منفصلة ، ولكن انظر إلى البنية التحتية بأكملها ككل.يمكن استخدام Yandex.Tank كأداة اختبار بالاقتران مع أي نظام مراقبة (في حالتنا ، تم أخذ البيانات من Grafana مع خلفية في شكل Prometheus للاختبار). تظهر مشاكل الإغلاق الرشيق بوضوح تحت الأحمال الثقيلة التي يمكن أن يولدها المعيار ، وتساعد المراقبة على تحليل الموقف بمزيد من التفاصيل أثناء الاختبار أو بعده.الرد على التعليقات على المقال: من الجدير بالذكر أن المشكلات والحلول موصوفة هنا فيما يتعلق بـ NGINX Ingress. بالنسبة للحالات الأخرى ، هناك حلول أخرى ، ربما ، سنأخذها بعين الاعتبار في المواد التالية من الدورة.ملاحظة
أخرى من دورة النصائح والحيل K8s: