عندما "يكمن" فيسبوك ، يعتقد الناس أن السبب في ذلك هو هجمات القراصنة أو هجمات DDoS ، لكن الأمر ليس كذلك. نتجت جميع "السقوط" خلال السنوات القليلة الماضية عن تغييرات داخلية أو أعطال. من أجل تعليم الموظفين الجدد عدم كسر Facebook مع الأمثلة ، يتم إعطاء جميع الحوادث الكبرى أسماء ، على سبيل المثال ، "Call the Cops" أو "CAPSLOCK". تم تسمية الاسم الأول لأنه عندما سقطت الشبكة الاجتماعية في أحد الأيام ، اتصل المستخدمون بشرطة لوس أنجلوس وطلبوا إصلاحها ، وطلب شريف اليأس على تويتر ألا يزعجهم بهذا الأمر. أثناء الحادث الثاني على أجهزة التخزين المؤقت ، تعطلت واجهة الشبكة ولم ترتفع ، وأعيد تشغيل جميع الأجهزة يدويًا.إلينا لوبانوفايعمل على Facebook منذ 4 سنوات في فريق Web Foundation. يُطلق على أعضاء الفريق مهندسي الإنتاج ويراقبون موثوقية وأداء الواجهة الخلفية بالكامل ، ويضعون Facebook عند تشغيله ، ويكتبون المراقبة والأتمتة لجعل الحياة أسهل لأنفسهم وللآخرين. في مقالة تستند إلى تقرير إلينا عن HighLoad ++ 2019 ، سنوضح كيف يراقب مهندسو الإنتاج الواجهة الخلفية لـ Facebook ، والأدوات التي يستخدمونها ، والتي تتسبب في أعطال كبيرة وكيفية التعامل معها.اسمي إلينا ، قبل حوالي 5 سنوات ، تم استدعائي على Facebook كمطور عادي ، حيث واجهت لأول مرة أنظمة محملة بكثافة - لم يتم تدريس هذا في المعاهد. لا توظف الشركة فريقًا ، بل مكتبًا ، لذلك وصلت إلى لندن ، واخترت فريقًا يراقب عمل facebook.com وكان من بين مهندسي الإنتاج.
في مقالة تستند إلى تقرير إلينا عن HighLoad ++ 2019 ، سنوضح كيف يراقب مهندسو الإنتاج الواجهة الخلفية لـ Facebook ، والأدوات التي يستخدمونها ، والتي تتسبب في أعطال كبيرة وكيفية التعامل معها.اسمي إلينا ، قبل حوالي 5 سنوات ، تم استدعائي على Facebook كمطور عادي ، حيث واجهت لأول مرة أنظمة محملة بكثافة - لم يتم تدريس هذا في المعاهد. لا توظف الشركة فريقًا ، بل مكتبًا ، لذلك وصلت إلى لندن ، واخترت فريقًا يراقب عمل facebook.com وكان من بين مهندسي الإنتاج.مهندسو الإنتاج
للبدء ، سأخبرك بما نقوم به ولماذا يُطلق علينا مهندسي الإنتاج ، وليس SRE مثل Google ، على سبيل المثال.2009. SRE
النموذج القياسي الذي لا يزال يستخدم في العديد من الشركات هو "المطورين - المختبرين - التشغيل". غالبًا ما ينقسمون: يجلسون في طوابق مختلفة ، وأحيانًا في بلدان مختلفة ، ولا يتواصلون مع بعضهم البعض.في عام 2009 ، كان لدى Facebook بالفعل SRE. في Google ، بدأت SRE في وقت سابق ، وهم يعرفون كيفية تحقيق DevOps ، وقد كتبوه في كتابهم " هندسة موثوقية الموقع ". على Facebook في عام 2009 ، لم يكن هناك شيء مثل هذا. تم تسميتنا SRE ، لكننا قمنا بنفس العمل مثل Ops في بقية العالم: العمل اليدوي ، بدون أتمتة ، نشر جميع الخدمات بيديك ، المراقبة بطريقة ما ، الاتصال على كل شيء ، مجموعة من البرامج النصية الصدفة.
على Facebook في عام 2009 ، لم يكن هناك شيء مثل هذا. تم تسميتنا SRE ، لكننا قمنا بنفس العمل مثل Ops في بقية العالم: العمل اليدوي ، بدون أتمتة ، نشر جميع الخدمات بيديك ، المراقبة بطريقة ما ، الاتصال على كل شيء ، مجموعة من البرامج النصية الصدفة.2010. SRO و AppOps
كل هذا لم يتغير ، لأن عدد المستخدمين في ذلك الوقت كان ينمو 3 مرات في السنة ، وازداد عدد الخدمات وفقًا لذلك. في عام 2010 ، تم تقسيم قرار العمليات القوية إلى مجموعتين.المجموعة الأولى هي SRO ، حيث "O" هي "عمليات" ، تعمل في تطوير وأتمتة ومراقبة الموقع.المجموعة الثانية هي AppOps ، تم دمجها في فرق ، كل منها للخدمات الكبيرة. AppOps قريب بالفعل من فكرة DevOps.الانفصال لبعض الوقت أنقذ الجميع.2012. مهندسو الإنتاج
في عام 2012 ، أعادت AppOps تسمية مهندسي الإنتاج ببساطة . بالإضافة إلى الاسم ، لم يتغير شيء ، لكنه أصبح أكثر راحة. عندما تستدعي يختًا ، سيبحر ، ولم نرغب في الإبحار مثل Ops.لا تزال SROs موجودة ، وكان Facebook ينمو ، وكان من الصعب مراقبة جميع الخدمات في وقت واحد. لم يُسمح للشخص الذي تم الاتصال به حتى بالذهاب إلى المرحاض: طلب من شخص ما استبداله ، لأنه كان يحترق باستمرار.2014. إغلاق SRO
في مرحلة ما ، نقلت السلطات الجميع إلى المكالمة. تعني كلمة "الجميع" أن المطورين أيضًا: اكتب رمزك ، ها أنت وأجب عن هذا الرمز!تم دمج مهندسي الإنتاج بالفعل في أهم الفرق للمساعدة ، والباقي خارج الحظ. بدأنا مع فرق كبيرة وفي غضون عامين نقلنا الجميع على Facebook إلى oncall. بين المطورين كان هناك حماس كبير: استقال شخص ، كتب شخص ما منشورات سيئة. لكن كل شيء هدأ ، وفي عام 2014 تم إغلاق SRO لأنه لم تعد هناك حاجة إليها. لذلك نحن نعيش حتى يومنا هذا.كلمة "SRE" في الشركة سيئة السمعة ، لكننا نبدو مثل SRE على Google. هناك اختلافات.- نحن دائما مدمجون في فرق. ليس لدينا بحث SRE بشكل عام ، كما هو الحال في Google ، فهو لكل خدمة بحث على حدة.
- نحن لسنا في المنتجات ، فقط في البنية التحتية التي يديرها المنتج نفسه.
- نحن على اتصال مع المطورين.
- لدينا المزيد من الخبرة في الأنظمة والشبكات ، لذلك نحن نركز على مراقبة وإطفاء الخدمات عندما تحترق بشكل مشرق. نقوم بإصلاح الأخطاء مسبقًا التي قد تؤدي إلى الأعطال والتأثير على بنية الخدمات الجديدة من البداية ، حتى تعمل لاحقًا بسلاسة في الإنتاج.
المراقبة
إنه الأهم. كيف نفعل ذلك؟ مثل الجميع: بدون السحر الأسود ، في منزلهم. لكن الشيطان ، كالعادة ، سيخبرك عنهم بالتفصيل.فوق
لنبدأ من الأسفل. الجميع يعرف TOP في Linux ، ونستخدم ATOP ، حيث يكون "A" "متقدمًا" - مراقب أداء النظام. الفائدة الرئيسية من ATOP هي أنه يخزن السجل: يمكنك تكوينه لحفظ اللقطات على القرص. يعمل ATOP على جميع الأجهزة كل 5 ثوانٍ.في ما يلي مثال لخادم يقوم بتشغيل الواجهة الخلفية لـ PHP لموقع facebook.com. لقد كتبنا الجهاز الظاهري الخاص بنا لتنفيذ كود PHP ، ويسمى HHVM (الآلة الافتراضية HipHop). وفقًا للمقاييس المُصدرة ، وجدنا أن العديد من الأجهزة لم تعالج طلبًا واحدًا تقريبًا في دقيقة واحدة. دعونا نرى لماذا ، فتح ATOP 30 ثانية قبل تعليقه. يمكن ملاحظة أنه مع مشاكل المعالج ، فإننا نحمله كثيرًا. هناك أيضًا مشكلة في الذاكرة ، حيث لا يتبقى سوى 1.5 غيغابايت في ذاكرة التخزين المؤقت ، وبعد 5 ثوانٍ فقط 800 ميغابايت.
يمكن ملاحظة أنه مع مشاكل المعالج ، فإننا نحمله كثيرًا. هناك أيضًا مشكلة في الذاكرة ، حيث لا يتبقى سوى 1.5 غيغابايت في ذاكرة التخزين المؤقت ، وبعد 5 ثوانٍ فقط 800 ميغابايت. بعد 5 ثوانٍ أخرى ، يتم تحرير وحدة المعالجة المركزية ، ولا يتم تنفيذ أي شيء. يقول ATOP انظر إلى المحصلة النهائية ، نكتب إلى القرص ، ولكن ماذا؟ تبين أننا نكتب مبادلة.
بعد 5 ثوانٍ أخرى ، يتم تحرير وحدة المعالجة المركزية ، ولا يتم تنفيذ أي شيء. يقول ATOP انظر إلى المحصلة النهائية ، نكتب إلى القرص ، ولكن ماذا؟ تبين أننا نكتب مبادلة. من يفعل هذا؟ العمليات التي تم أخذها من الذاكرة 0.5 جيجا بايت وتم تبديلها. في مكانهم جاءت عمليتان مشبوهتان في Python ، يمكن اعتبارهما بعد ذلك سطر أوامر.
من يفعل هذا؟ العمليات التي تم أخذها من الذاكرة 0.5 جيجا بايت وتم تبديلها. في مكانهم جاءت عمليتان مشبوهتان في Python ، يمكن اعتبارهما بعد ذلك سطر أوامر.
ATOP جميل ، نستخدمه باستمرار.
إذا لم يكن لديك ، أوصي بشدة باستخدامه. لا تخف من القيادة ، يأكل ATOP فقط 200-300 ميجابايت في اليوم كل 5 ثوان.Malloc HTTP
إلى جزر البهاما والحوادث الكبيرة ، نعطي أسماء. هناك خطأ واحد مرتبط بـ ATOP يسمى Malloc HTTP. ظهرنا لأول مرة مع ATOP والجهد.نحن نستخدم Thrift في كل مكان باعتباره RPC. في الإصدارات الأولى من المحلل اللغوي ، كان هناك خطأ مذهل يعمل على النحو التالي: وصلت رسالة يكون فيها أول 4 بايت حجم البيانات ، ثم البيانات نفسها ، والبايت الأولى تضاف إلى الرسالة التالية.ولكن مرة واحدة من البرامج بدلا من أن يذهب إلى الخدمة والتوفير، ذهبت إلى HTTP، وتلقت ردا «على HTTP باد طلب»: HTTP/1.1 400.بعد أن أخذ HTTP وخصص باستخدام malloc HTTP عدد البايت.Thrift message
HTTP/1.1 400
"HTTP" == 0x48545450
لا بأس ، لدينا تجاوزات ، دعنا نخصص المزيد من الذاكرة! خصصنا مع malloc ، وحتى نكتب ونقرأ هناك ، لن يعطونا ذاكرة حقيقية.لكنها لم تكن هناك! إذا أردنا الشوكة ، فسيرجع الشوكة خطأ - لا توجد ذاكرة كافية.malloc("HTTP")
pid = fork(); // errno = ENOMEM
لكن لماذا ، هل هناك ذاكرة؟ من خلال فهم الكتيبات ، وجدنا أن كل شيء بسيط للغاية: التكوين الحالي المفرط هو أنه استدلال سحري ، وتقرر النواة نفسها متى وعندما لا:malloc("HTTP")
pid = fork(); // errno = ENOMEM
// 0: heuristic overcommit
vm.overcommit_memory = 0
بالنسبة لعملية العمل ، يعد هذا أمرًا طبيعيًا ، يمكنك اختيار malloc حتى السل ، ولكن لعملية جديدة - لا. وكان جزءًا من المراقبة فينا مرتبطًا بحقيقة أن العملية الرئيسية تفرع نصوصًا صغيرة لجمع البيانات. ونتيجة لذلك ، تعطل جزء المراقبة الخاص بنا ، لأنه لم يعد بإمكاننا الشوكة.FB303
FB303 هو نظام المراقبة الأساسي لدينا. تم تسميته على اسم مركب باس عام 1982. المبدأ بسيط ، لذلك لا يزال يعمل: كل خدمة تنفذ واجهة Thrift getCounters.
المبدأ بسيط ، لذلك لا يزال يعمل: كل خدمة تنفذ واجهة Thrift getCounters.Service FacebookService {
map<string, i64> getCounters()
}
في الواقع ، لا ينفذها ، لأن المكتبات مكتوبة بالفعل ، كل شيء يتم في التعليمات البرمجية incrementأو set.incrementCounter(string& key);
setCounter(string& key, int64_t value);
ونتيجة لذلك ، تصدر كل خدمة عدادات على المنفذ الذي تسجله باستخدام Service Discovery. فيما يلي مثال على آلة تقوم بتوليد موجز أخبار وتقوم بتصدير حوالي 5.5 ألف زوج (سلسلة ، رقم): الذاكرة ، الإنتاج ، أي شيء. تقوم كل آلة بتشغيل عملية ثنائية تمر عبر جميع الخدمات الموجودة ، وتقوم بجمع هذه العدادات ووضعها في التخزين.هذا هو شكل واجهة المستخدم الرسومية للتخزين .
تقوم كل آلة بتشغيل عملية ثنائية تمر عبر جميع الخدمات الموجودة ، وتقوم بجمع هذه العدادات ووضعها في التخزين.هذا هو شكل واجهة المستخدم الرسومية للتخزين . تشبه إلى حد بعيد بروميثيوس وجرافانا ، لكنها ليست كذلك. كان أول إدخال FB303 على GitHub في عام 2009 ، و Prometheus في عام 2012. هذا شرح لجميع منتجات Facebook "محلية الصنع": لقد فعلناها عندما لم يكن هناك شيء طبيعي في Open Source.على سبيل المثال ، يوجد بحث عن أسماء العدادات.
تشبه إلى حد بعيد بروميثيوس وجرافانا ، لكنها ليست كذلك. كان أول إدخال FB303 على GitHub في عام 2009 ، و Prometheus في عام 2012. هذا شرح لجميع منتجات Facebook "محلية الصنع": لقد فعلناها عندما لم يكن هناك شيء طبيعي في Open Source.على سبيل المثال ، يوجد بحث عن أسماء العدادات. تبدو الرسوم البيانية نفسها شيء من هذا القبيل.
تبدو الرسوم البيانية نفسها شيء من هذا القبيل. صورة من المجموعة الداخلية التي ننشر فيها رسومات جميلة.هناك فرق مهم بين مجموعة المراقبة الخاصة بنا و Prometheus و Grafana هو أننا نخزن البيانات إلى الأبد . سيعيد رصدنا إعادة اختبار البيانات ، وبعد أسبوعين سيكون لدينا نقطة واحدة لكل 5 دقائق ، وبعد عام لكل ساعة. لذلك ، يمكن تخزينها كثيرًا. تلقائيا لم يتم تكوين هذا في أي مكان.ولكن إذا تحدثنا عن ميزات مراقبة Facebook ، فسوف أصفها بكلمة إنجليزية واحدة "إمكانية المراقبة " .
صورة من المجموعة الداخلية التي ننشر فيها رسومات جميلة.هناك فرق مهم بين مجموعة المراقبة الخاصة بنا و Prometheus و Grafana هو أننا نخزن البيانات إلى الأبد . سيعيد رصدنا إعادة اختبار البيانات ، وبعد أسبوعين سيكون لدينا نقطة واحدة لكل 5 دقائق ، وبعد عام لكل ساعة. لذلك ، يمكن تخزينها كثيرًا. تلقائيا لم يتم تكوين هذا في أي مكان.ولكن إذا تحدثنا عن ميزات مراقبة Facebook ، فسوف أصفها بكلمة إنجليزية واحدة "إمكانية المراقبة " .الملاحظة
هناك "صندوق أسود" ، هناك "صندوق أبيض" ، ولدينا "صندوق" زجاجي شفاف. هذا يعني أنه عندما نكتب التعليمات البرمجية ، نكتب كل ما هو ممكن في السجلات ، وليس بشكل انتقائي. يتم ضبط أخذ العينات جيدًا في كل مكان ، لذا فإن الواجهة الخلفية للتخزين والعدادات وكل شيء آخر تعيش بشكل جيد.في الوقت نفسه ، يمكننا إنشاء لوحات العدادات بالفعل على العدادات الموجودة. في حالة دراسة لوحات العدادات هذه ، ليست هذه هي نقطة النهاية بعشرة رسوم بيانية ، ولكنها أولية ، ننتقل منها إلى واجهة المستخدم الخاصة بنا ونجد كل ما هو ممكن.الغوص
هذه هي ذروة فكرة قابلية الملاحظة. هذا هو مكدس ELK الخاص بنا. المبدأ هو نفسه: نكتب في JSON بدون مخطط محدد ، ثم نطلب في شكل جدول ، أو سلسلة زمنية من البيانات ، أو 10 خيارات تصور إضافية.تسجل سكوبا في ترتيب مئات غيغابايت في الثانية. يتم طلب كل شيء بسرعة كبيرة ، لأنه ليس من البلاستيك ، وكل شيء في الذاكرة على الأجهزة القوية. نعم ، إنفاق المال على ذلك ، ولكن كم هو رائع!على سبيل المثال ، أسفل واجهة مستخدم Scuba ، يتم فتح أحد الجداول الأكثر شيوعًا فيه ، حيث يكتب جميع عملاء جميع خدمات Thrift سجلات. يوضح الرسم البياني أنه في النهاية ، حدث خطأ في الخدمة. لمعرفة التأخير ، انتقل إلى قائمة العدادات ، حدد التأخير ، التجميع ، انقر فوق "غوص".
يوضح الرسم البياني أنه في النهاية ، حدث خطأ في الخدمة. لمعرفة التأخير ، انتقل إلى قائمة العدادات ، حدد التأخير ، التجميع ، انقر فوق "غوص". الجواب يأتي في ثانيتين.
الجواب يأتي في ثانيتين.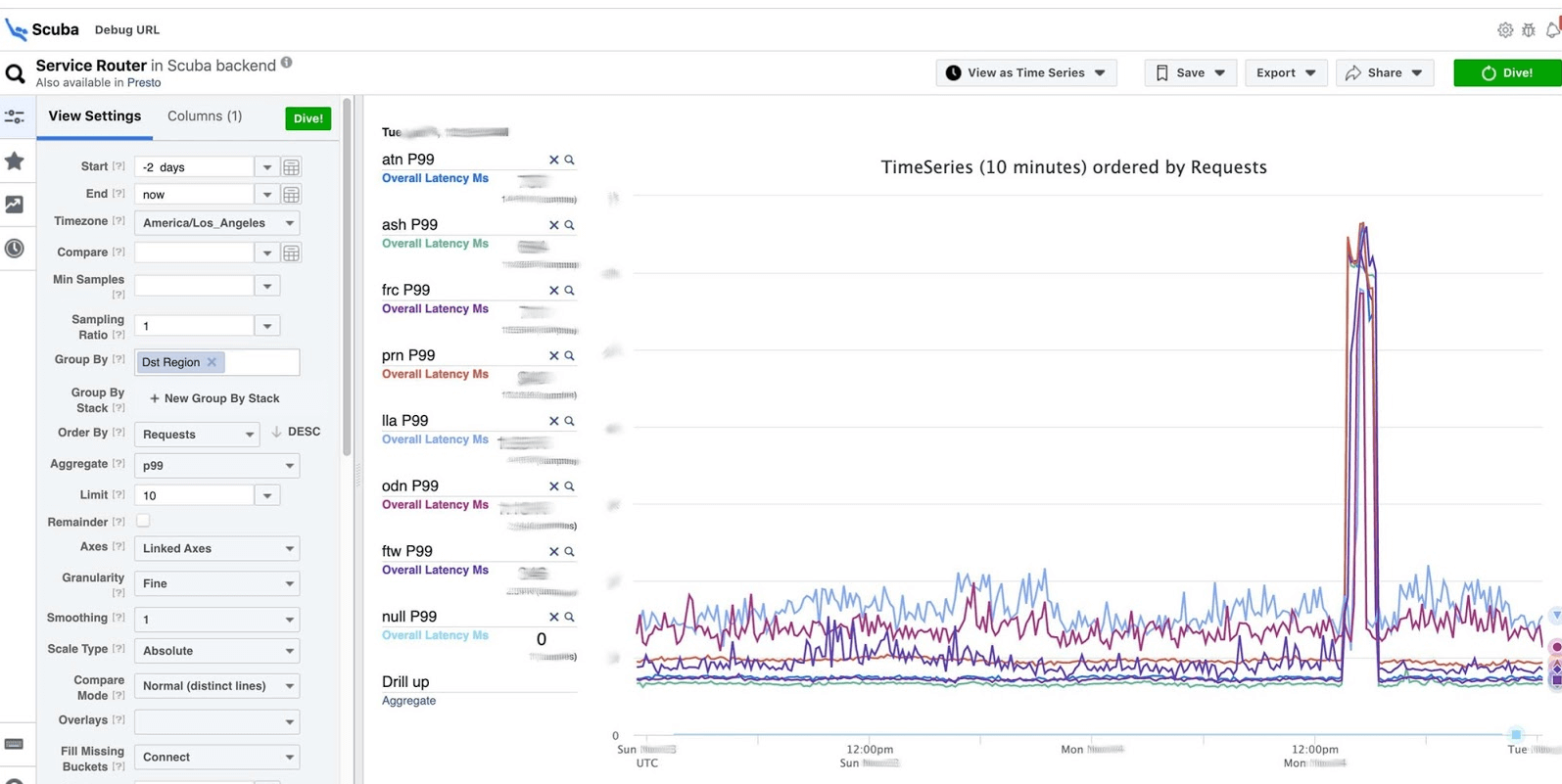 يمكن ملاحظة أنه في تلك اللحظة حدث شيء وزاد التأخير بشكل ملحوظ. لمعرفة المزيد ، يمكنك التجميع حسب معلمات مختلفة.هناك المئات من هذه الجداول.
يمكن ملاحظة أنه في تلك اللحظة حدث شيء وزاد التأخير بشكل ملحوظ. لمعرفة المزيد ، يمكنك التجميع حسب معلمات مختلفة.هناك المئات من هذه الجداول.- جدول يعرض إصدارات الملفات الثنائية ، الحزم ، مقدار الذاكرة المستهلكة على ملايين الأجهزة. على كل مضيف ، يتم إجراء PS مرة واحدة في الساعة وإرسالها إلى Scuba.
- يتم إرسال جميع dmesg ، كل مقالب الذاكرة ، إلى جداول أخرى. نقوم بتشغيل Perf مرة واحدة كل 10 دقائق على كل جهاز ، حتى نعرف آثار المكدس التي نمتلكها على النواة وما يمكن لوحدة المعالجة المركزية العالمية تحميله.
تصحيح PHP
يوفر Scuba أيضًا خلفية لأداة تصحيح أخطاء PHP الأساسية. يكتب الآلاف من المهندسين رمز PHP ، وبطريقة ما تحتاج إلى حفظ المستودع العالمي من الأشياء السيئة.كيف يعمل؟ يكتب PHP أيضًا تتبع المكدس لكل سجل. لا يستطيع Scuba (بحثنا المطاطي) ببساطة استيعاب تتبع المكدس من جميع السجلات من جميع الأجهزة. قبل وضع السجل في Scuba ، نقوم بتحويل تتبع المكدس إلى تجزئة ، ونأخذها بالتجزئة ونحفظها فقط. يتم إرسال آثار المكدس نفسها إلى Memcached. بعد ذلك ، في الأداة الداخلية ، يمكنك سحب تتبع مكدس محدد من Memcached بسرعة كافية. التمثيل البصري مع تجميع التجزئة من السجلات وتتبعات المكدس.نقوم بتصحيح الكود باستخدام طريقة مطابقة الأنماط : افتح Scuba ، انظر كيف يبدو الرسم البياني للأخطاء.
التمثيل البصري مع تجميع التجزئة من السجلات وتتبعات المكدس.نقوم بتصحيح الكود باستخدام طريقة مطابقة الأنماط : افتح Scuba ، انظر كيف يبدو الرسم البياني للأخطاء.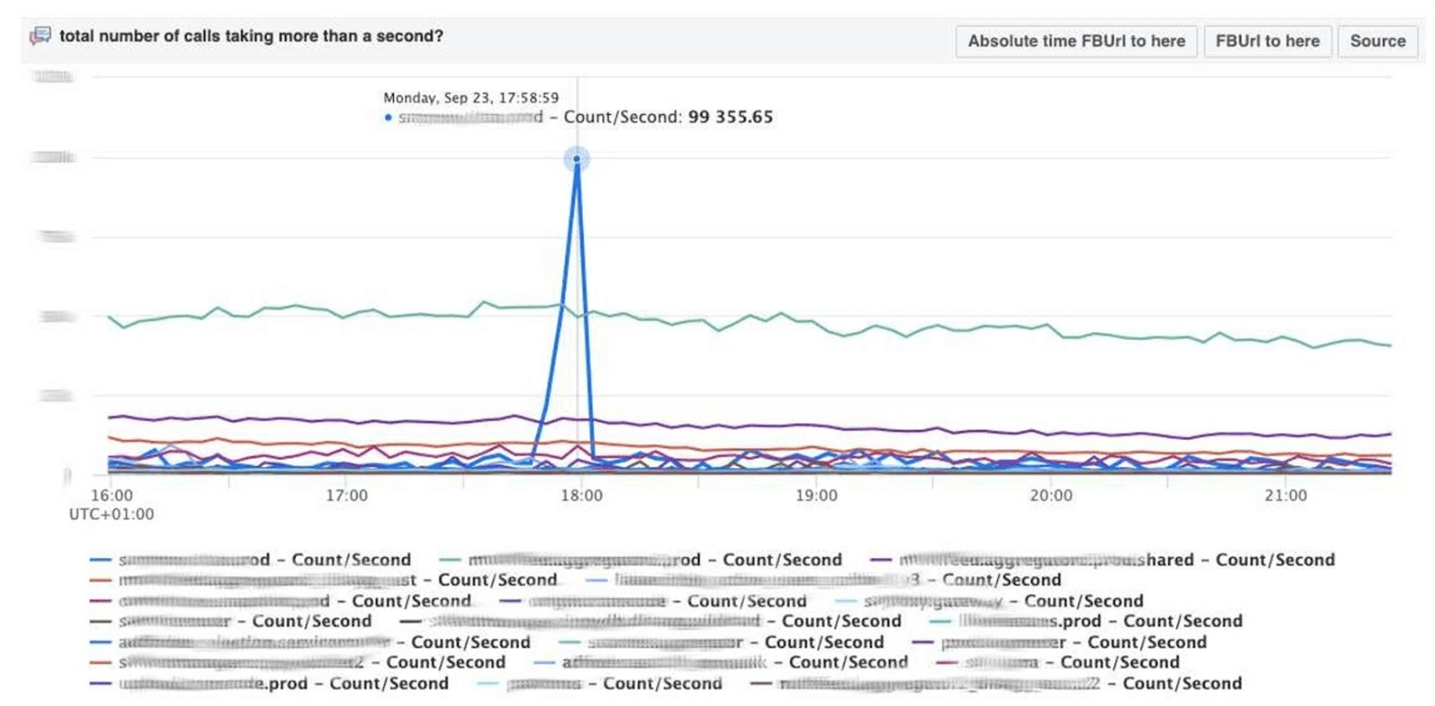 نذهب إلى LogView ، هناك أخطاء مجمعة بالفعل من خلال تتبعات المكدس.
نذهب إلى LogView ، هناك أخطاء مجمعة بالفعل من خلال تتبعات المكدس. يتم تحميل تتبع المكدس من Memcached ، وبالفعل يمكنك العثور على فرق (الالتزام في مستودع PHP) ، والذي تم نشره في نفس الوقت تقريبًا ، ثم استعادته. يمكن لأي شخص التراجع والالتزام معنا ، ولا يلزم الحصول على أذونات لهذا الغرض.
يتم تحميل تتبع المكدس من Memcached ، وبالفعل يمكنك العثور على فرق (الالتزام في مستودع PHP) ، والذي تم نشره في نفس الوقت تقريبًا ، ثم استعادته. يمكن لأي شخص التراجع والالتزام معنا ، ولا يلزم الحصول على أذونات لهذا الغرض.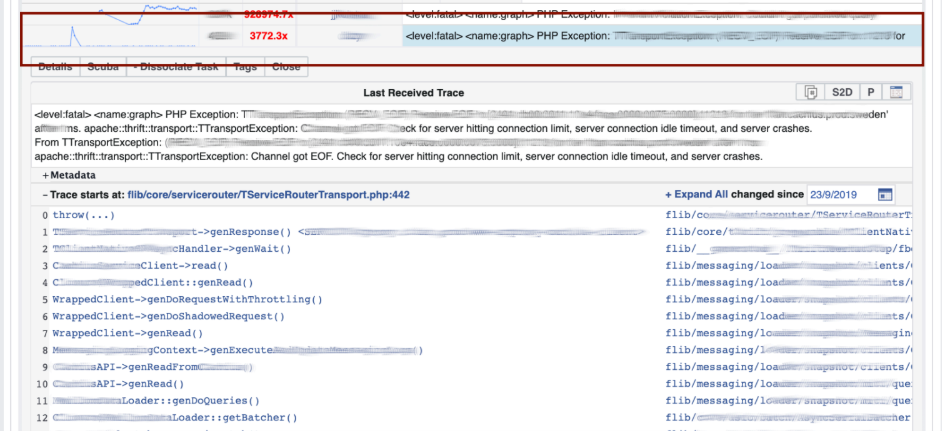
لوحات المعلومات
سأنهي موضوع المراقبة باستخدام لوحات العدادات. لدينا القليل منهم - مؤشران فقط لكل ثلاثة مؤشرات. لوحة القيادة نفسها غير عادية إلى حد ما. أود أن أتحدث عنه أكثر. أدناه لوحة قيادة قياسية مع مجموعة من الرسوم البيانية.لسوء الحظ ، الأمر ليس بهذه البساطة معه. والحقيقة هي أن الخط الأرجواني على رسم بياني واحد هو نفس الخدمة التي يتوافق معها الخط الأزرق على الرسم البياني الآخر ، ويمكن أن يكون الرسم البياني الآخر في يوم وآخر في الشهر.نستخدم لوحة القيادة الخاصة بنا على أساس التكعيبية - مكتبة JS مفتوحة المصدر. تمت كتابته في Square وتم إصداره بموجب ترخيص Apache. لديهم دعم مدمج للجرافيت والمكعب. ولكن من السهل التوسع ، وهو ما فعلناه.تظهر لوحة القيادة أدناه يوم واحد بكسل واحد في الدقيقة. كل خط منطقة: مراكز البيانات القريبة. يعرضون عدد السجلات التي تكتبها الواجهة الخلفية لـ Facebook بالبايت في الثانية. فيما يلي التعليقات التوضيحية للفرق في أمريكا لمعرفة ما قمنا بالفعل بإصلاحه مما حدث خلال اليوم. من السهل البحث عن الارتباط في هذه الصورة.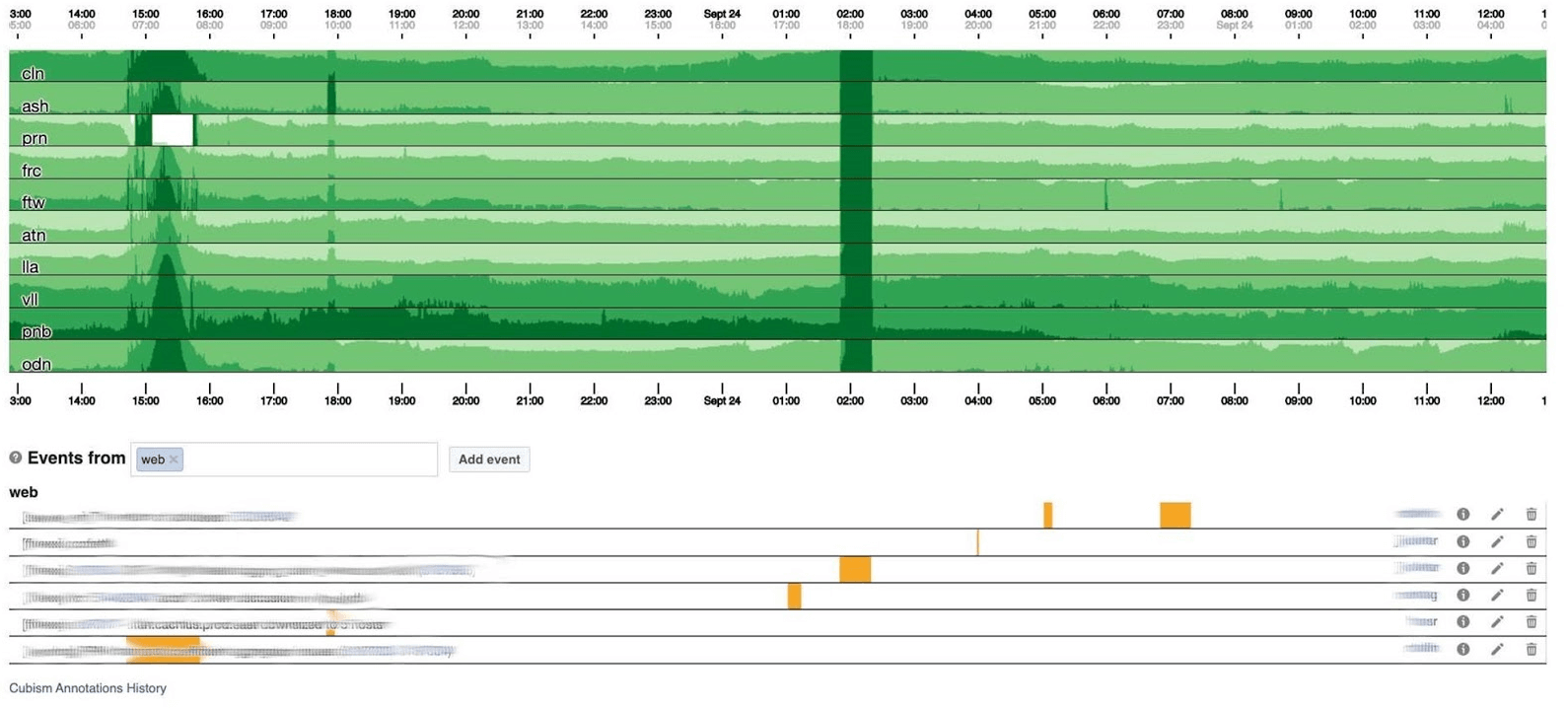 فيما يلي عدد الأخطاء 500. ما يهم على اليسار لا يهم المستخدمين ، ومن الواضح أنهم لم يعجبهم الشريط الأخضر الداكن في المركز.
فيما يلي عدد الأخطاء 500. ما يهم على اليسار لا يهم المستخدمين ، ومن الواضح أنهم لم يعجبهم الشريط الأخضر الداكن في المركز.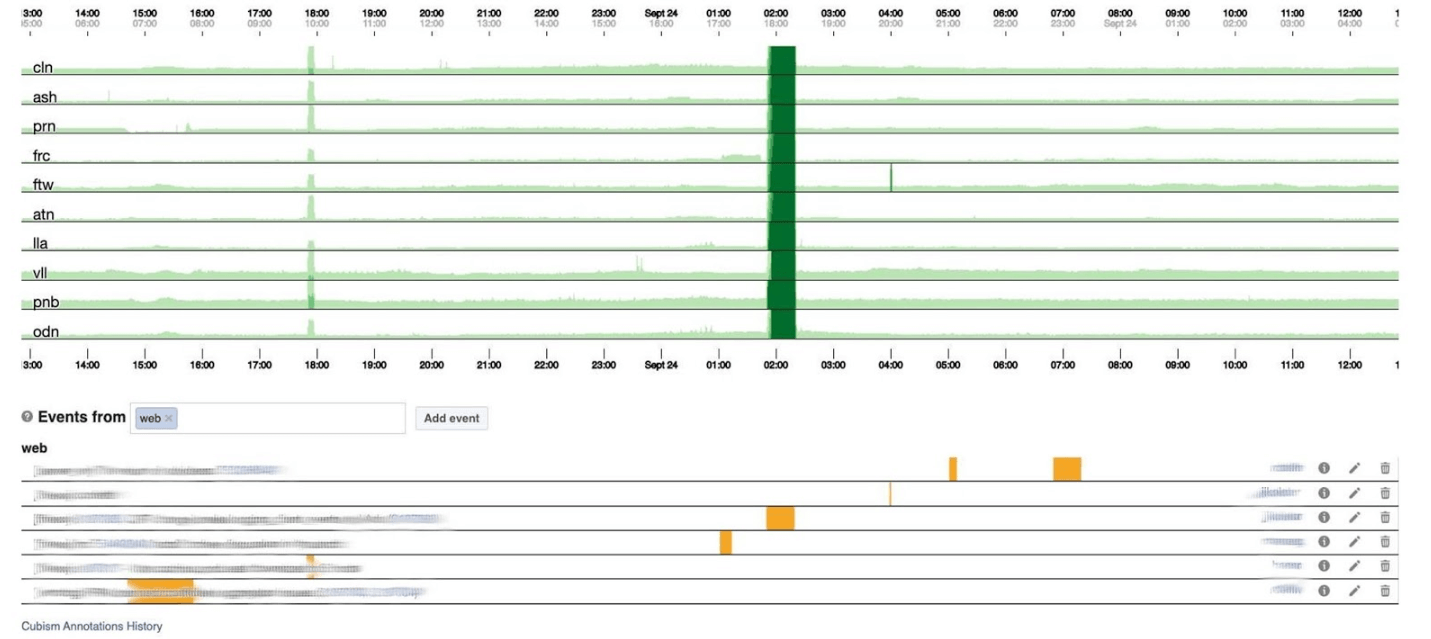 التالي هو الكمون المئوي 99. في الوقت نفسه ، كما في الرسم البياني أعلاه ، يمكن ملاحظة أن زمن الوصول قد انخفض. لإرجاع خطأ ، ليس من الضروري قضاء الكثير من الوقت.
التالي هو الكمون المئوي 99. في الوقت نفسه ، كما في الرسم البياني أعلاه ، يمكن ملاحظة أن زمن الوصول قد انخفض. لإرجاع خطأ ، ليس من الضروري قضاء الكثير من الوقت.
كيف تعمل
على رسم بياني يبلغ ارتفاعه 120 بكسل ، كل شيء مرئي. ولكن لا يمكن وضع العديد من هذه على لوحة تحكم واحدة ، لذلك سنضغط على الرقم 30. لسوء الحظ ، عندها نحصل على نوع من أفعى الأفعى. دعونا نعود ونرى ماذا تفعل التكعيبية بها. يكسر الرسم البياني إلى 4 أجزاء: الأعلى ، والأغمق ، ثم ينهار.
لسوء الحظ ، عندها نحصل على نوع من أفعى الأفعى. دعونا نعود ونرى ماذا تفعل التكعيبية بها. يكسر الرسم البياني إلى 4 أجزاء: الأعلى ، والأغمق ، ثم ينهار. الآن لدينا نفس الجدول الزمني كما كان من قبل ، ولكن كل شيء واضح للعيان: كلما كان اللون الأخضر الداكن أكثر سوءًا. الآن أصبح من الواضح أكثر ما يحدث.على اليسار يمكنك رؤية الموجة وهي ترتفع ، وفي الوسط ، حيث تكون خضراء داكنة ، كل شيء سيء للغاية.
الآن لدينا نفس الجدول الزمني كما كان من قبل ، ولكن كل شيء واضح للعيان: كلما كان اللون الأخضر الداكن أكثر سوءًا. الآن أصبح من الواضح أكثر ما يحدث.على اليسار يمكنك رؤية الموجة وهي ترتفع ، وفي الوسط ، حيث تكون خضراء داكنة ، كل شيء سيء للغاية.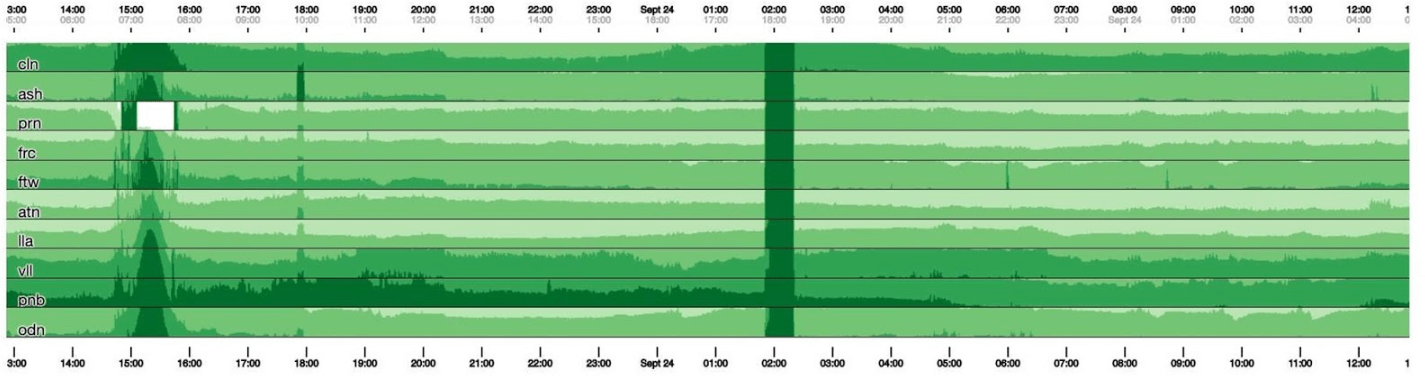 التكعيبية هي البداية فقط. هناك حاجة إلى التصور ، من أجل فهم ما إذا كان كل شيء سيئًا الآن أم لا. لكل جدول ، توجد لوحات تحكم تحتوي بالفعل على رسوم بيانية تفصيلية.
التكعيبية هي البداية فقط. هناك حاجة إلى التصور ، من أجل فهم ما إذا كان كل شيء سيئًا الآن أم لا. لكل جدول ، توجد لوحات تحكم تحتوي بالفعل على رسوم بيانية تفصيلية. تساعد المراقبة في حد ذاتها على فهم حالة النظام والاستجابة في حالة حدوث كسر. على Facebook ، يجب أن يكون كل موظف في oncall قادرًا على إصلاح كل شيء. إذا كان يحترق بشكل ساطع ، فسيتم تشغيل كل شيء ، ولكن بشكل خاص مهندسي الإنتاج الذين لديهم خبرة مسؤول النظام ، لأنهم يعرفون كيفية حل المشكلة بسرعة.
تساعد المراقبة في حد ذاتها على فهم حالة النظام والاستجابة في حالة حدوث كسر. على Facebook ، يجب أن يكون كل موظف في oncall قادرًا على إصلاح كل شيء. إذا كان يحترق بشكل ساطع ، فسيتم تشغيل كل شيء ، ولكن بشكل خاص مهندسي الإنتاج الذين لديهم خبرة مسؤول النظام ، لأنهم يعرفون كيفية حل المشكلة بسرعة.عندما وضع الفيسبوك
في بعض الأحيان تحدث الحوادث ، ويكذب الفيسبوك. غالبًا ما يعتقد الناس أن Facebook يكذب بسبب هجمات DDoS أو المتسللين الذين هاجموا ، ولكن لم يحدث ذلك منذ 5 سنوات. السبب كان دائما مهندسينا. إنهم ليسوا متعمدين: الأنظمة معقدة للغاية ويمكن أن تتعطل حيث لا تنتظر.نعطي أسماء لجميع الحوادث الكبرى بحيث يكون من المناسب ذكرها وإخبار الوافدين الجدد عنها حتى لا تتكرر الأخطاء في المستقبل. البطل بأسم أطرف هو حادثة Call the Cops . اتصل الناس بشرطة لوس أنجلوس وطلبوا إصلاح Facebook لأنه كان يكذب. لقد سئم شريف لوس أنجلوس منه لدرجة أنه غرد: "من فضلك لا تتصل بنا!" نحن لسنا مسؤولين عن ذلك! " كان الحادث المفضل لدي الذي شاركت فيه يسمى CAPSLOCK.. من المثير للاهتمام أنه يظهر أن أي شيء يمكن أن يحدث. وهذا ما حدث. انها عنوان obychnyyIP:
كان الحادث المفضل لدي الذي شاركت فيه يسمى CAPSLOCK.. من المثير للاهتمام أنه يظهر أن أي شيء يمكن أن يحدث. وهذا ما حدث. انها عنوان obychnyyIP: fd3b:5679:92eb:9ce4::1.يستخدم Facebook الشيف لتخصيص نظام التشغيل. يقوم مخزون الخدمة بتخزين تكوين المضيف في قاعدة البيانات الخاصة به ، ويتلقى الشيف ملف تكوين من الخدمة. بمجرد أن قامت الخدمة بتغيير نسختها ، بدأت في قراءة عناوين IP من قاعدة البيانات على الفور بتنسيق MySQL ووضعها في ملف. هو مكتوب العنوان الجديد الآن في العاصمة: FD3B:5679:92EB:9CE4::1.ينظر شيف إلى الملف الجديد ويرى أن عنوان IP قد "تغير" لأنه يقارن ، ليس في شكل ثنائي ، ولكن بسلسلة. عنوان IP هو "جديد" ، مما يعني أنك بحاجة إلى خفض الواجهة ورفع الواجهة. على كل ملايين السيارات في 15 دقيقة ، تعطلت الواجهة وصعدت.يبدو أن الأمر على ما يرام - فقد انخفضت السعة بينما كانت الشبكة ملقاة على بعض الأجهزة. ولكن تم فتح خطأ فجأة في برنامج تشغيل الشبكة لبطاقات الشبكة المخصصة لدينا: عند بدء التشغيل ، كانت تتطلب 0.5 غيغابايت من الذاكرة الفعلية المتسلسلة. على أجهزة التخزين المؤقت ، اختفت تلك 0.5 غيغابايت بينما قمنا بخفض الواجهة ورفعها. لذلك ، على أجهزة التخزين المؤقت ، تعطلت واجهة الشبكة ولم ترتفع ، ولا شيء يعمل بدون ذاكرة التخزين المؤقت. جلسنا وأعدنا تشغيل هذه الآلات بأيدينا. كان ممتعا.بوابة مدير الحوادث
عندما "يحرق" فيسبوك ، يُطلب منه تنظيم عمل "فرقة الإطفاء" ، والأهم من ذلك ، فهم مكان حرقها ، لأنه في شركة ضخمة يمكن أن "تحرق رائحة" في مكان ما ، ولكن المشكلة ستكون في مكان آخر. تساعدنا أداة واجهة المستخدم المسماة Incident Manager Portal في ذلك . كتبه مهندسو الإنتاج ، وهو مفتوح للجميع. بمجرد حدوث شيء ما ، نبدأ حادثة هناك: الاسم ، البداية ، الوصف.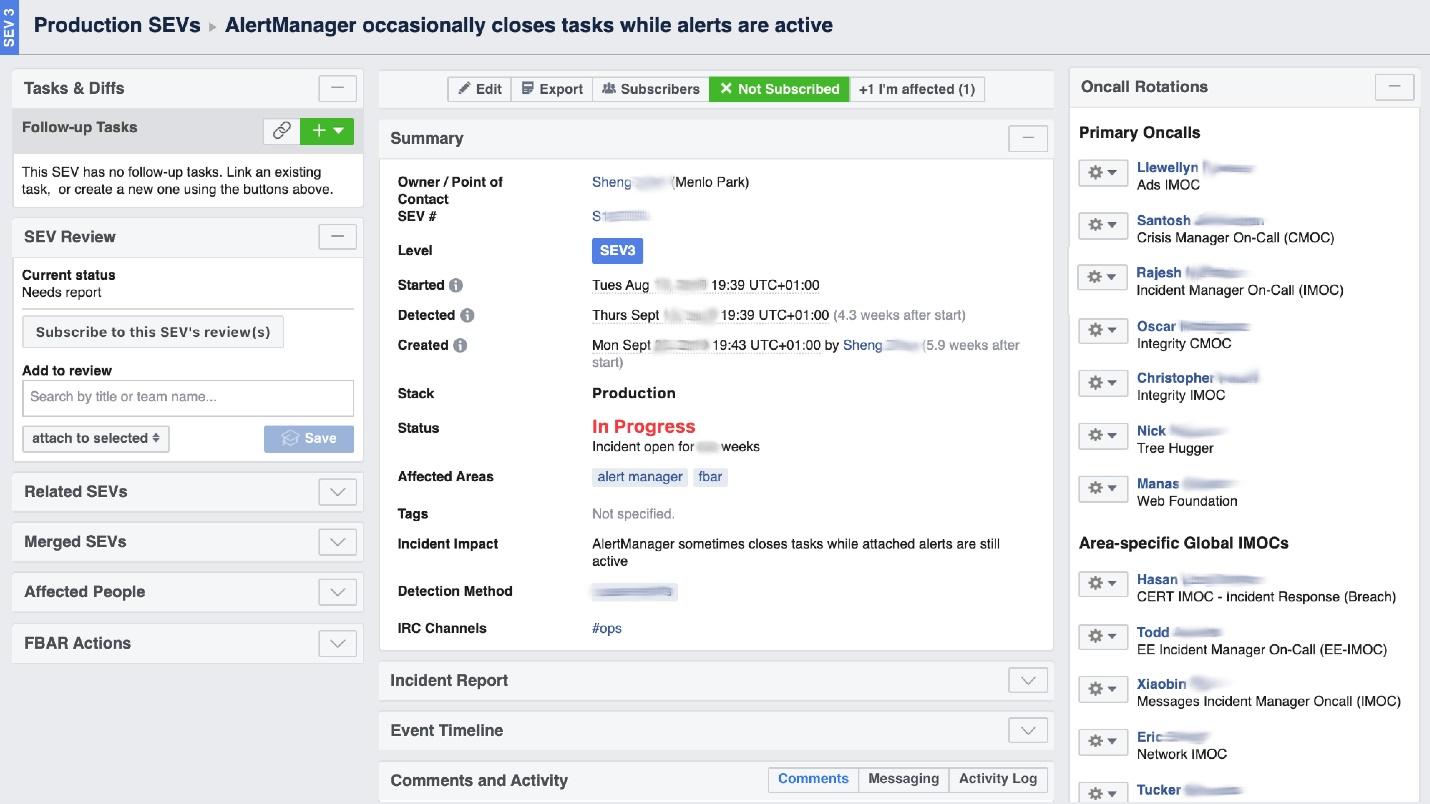 لدينا شخص مدرب بشكل خاص - مدير الحوادث عند الطلب (IMOC). هذه ليست وظيفة دائمة ؛ يتغير المديرون بانتظام. في حالة الحرائق الكبيرة ، تقوم IMOC بتنظيم وتنسيق الأشخاص للإصلاح ، ولكن ليس عليهم إصلاحها بأنفسهم. بمجرد حدوث حادثة ذات مستوى عالٍ من الخطر ، تتلقى IMOC رسائل SMS وتبدأ في المساعدة في تنظيم كل شيء. في نظام كبير ، لا يمكن الاستغناء عن هؤلاء الناس.
لدينا شخص مدرب بشكل خاص - مدير الحوادث عند الطلب (IMOC). هذه ليست وظيفة دائمة ؛ يتغير المديرون بانتظام. في حالة الحرائق الكبيرة ، تقوم IMOC بتنظيم وتنسيق الأشخاص للإصلاح ، ولكن ليس عليهم إصلاحها بأنفسهم. بمجرد حدوث حادثة ذات مستوى عالٍ من الخطر ، تتلقى IMOC رسائل SMS وتبدأ في المساعدة في تنظيم كل شيء. في نظام كبير ، لا يمكن الاستغناء عن هؤلاء الناس.الوقاية
Facebook ليس شائعًا جدًا. في معظم الأحيان لا نقوم بإخماد الحرائق ولا نعيد تشغيل أجهزة التخزين المؤقت ، ولكننا نقوم بإصلاح الأخطاء مسبقًا ، وإذا أمكن ، للجميع في وقت واحد.بمجرد العثور على "مشكلة قائمة الانتظار" وإصلاحها. يزداد عدد الطلبات بنسبة 50٪ ، والأخطاء بنسبة 100٪ ، لأنه لا يوجد أي شخص يتم تقييده مقدمًا ، خاصة في الخدمات الصغيرة.لقد اكتشفنا مثالاً للعديد من الخدمات وحددنا نموذجًا سلوكيًا تقريبًا.- تحت الحمل العادي ، يصل الطلب ، تتم معالجته وإعادته إلى العميل.
- مع وجود حمولة عالية ، تنتظر الطلبات في قائمة الانتظار لأن جميع سلاسل عمليات معالجة الطلبات مشغولة. التأخير يزداد ، لكن كل شيء على ما يرام حتى الآن.
- الخط ينمو ، الحمل يزداد. في مرحلة ما ، ينتهي كل شيء ينفذه الخادم على العميل بانتهاء مهلة الاستجابة ، وينتهي خطأ العميل. عند هذه النقطة ، يمكن ببساطة التخلص من نتيجة الخادم.
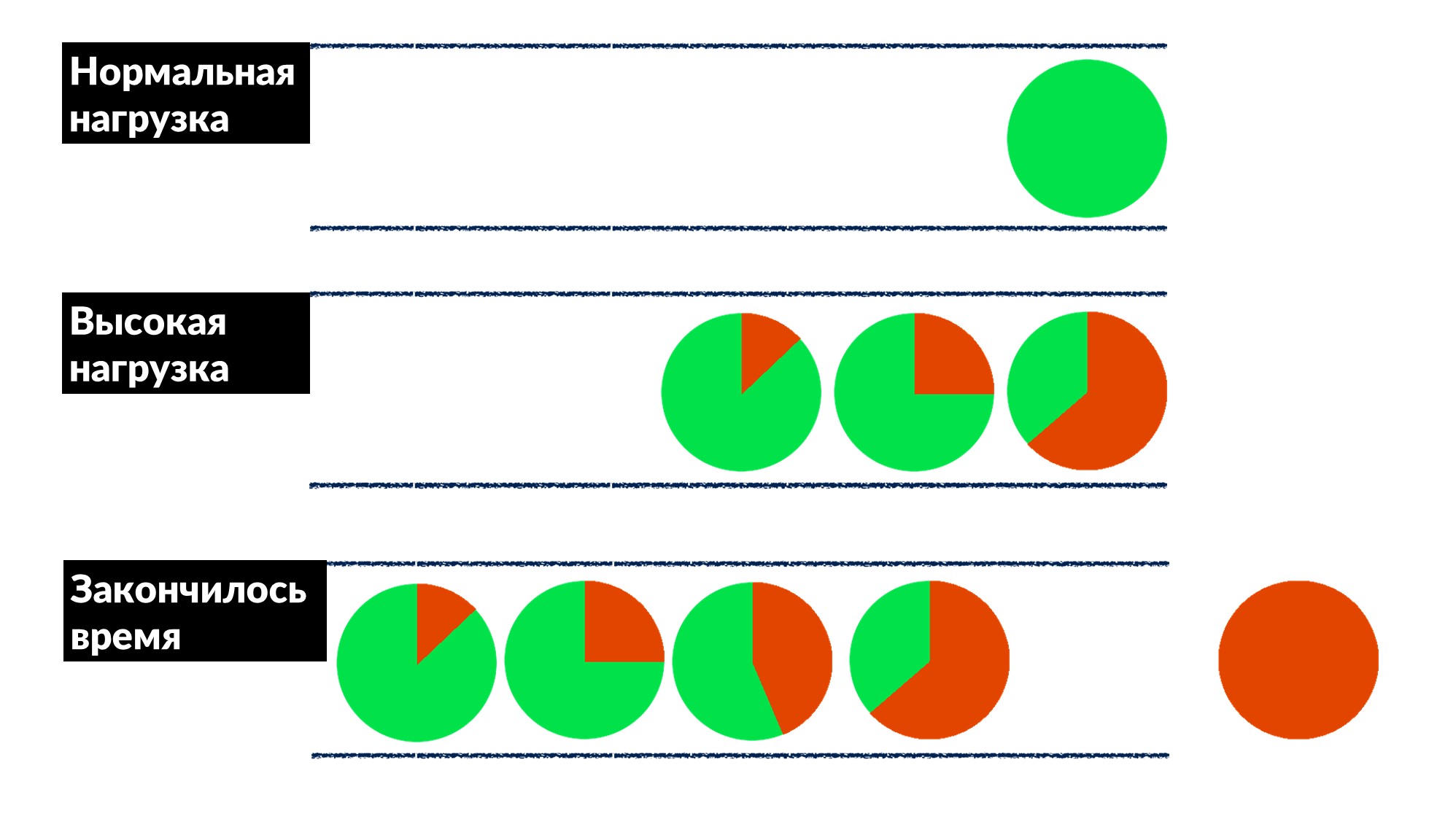 تم تحديد مهلة العميل باللون الأحمر.ويكرر العميل مرة أخرى! اتضح أن جميع الطلبات التي نقوم بتنفيذها يتم طرحها في سلة المهملات ولم يعد هناك من يحتاجها.كيف تحل هذه المشكلة للجميع دفعة واحدة؟ أدخل حد مهلة الطابور. إذا كان الطلب في قائمة الانتظار أكثر مما هو متوقع ، فإننا نتخلص منه ولا نعالجه على الخادم ، ولا نهدر وحدة المعالجة المركزية عليه. نحصل على لعبة صادقة: نتخلص من كل شيء لا يمكننا معالجته وكل شيء يمكننا - معالجته.جعل القيد من الممكن ، مع زيادة الحمل بنسبة 50 ٪ فوق الحد الأقصى ، الاستمرار في معالجة 66 ٪ من الطلبات وتلقي 33 ٪ فقط من الأخطاء. قام مطورو إطار عمل Dispatch بتطبيق ذلك على جانب الخادم ، ونحن ، مهندسي الإنتاج ، قمنا بتسوية مهلة 100 مللي ثانية في قائمة الانتظار للجميع برفق. لذلك حصلت جميع الخدمات على الفور على اختناق أساسي رخيص.
تم تحديد مهلة العميل باللون الأحمر.ويكرر العميل مرة أخرى! اتضح أن جميع الطلبات التي نقوم بتنفيذها يتم طرحها في سلة المهملات ولم يعد هناك من يحتاجها.كيف تحل هذه المشكلة للجميع دفعة واحدة؟ أدخل حد مهلة الطابور. إذا كان الطلب في قائمة الانتظار أكثر مما هو متوقع ، فإننا نتخلص منه ولا نعالجه على الخادم ، ولا نهدر وحدة المعالجة المركزية عليه. نحصل على لعبة صادقة: نتخلص من كل شيء لا يمكننا معالجته وكل شيء يمكننا - معالجته.جعل القيد من الممكن ، مع زيادة الحمل بنسبة 50 ٪ فوق الحد الأقصى ، الاستمرار في معالجة 66 ٪ من الطلبات وتلقي 33 ٪ فقط من الأخطاء. قام مطورو إطار عمل Dispatch بتطبيق ذلك على جانب الخادم ، ونحن ، مهندسي الإنتاج ، قمنا بتسوية مهلة 100 مللي ثانية في قائمة الانتظار للجميع برفق. لذلك حصلت جميع الخدمات على الفور على اختناق أساسي رخيص.أدوات
تقول إيديولوجية SRE أنه إذا كان لديك أسطول كبير من السيارات ومجموعة من الخدمات ولا علاقة ليديك ، فأنت بحاجة إلى الأتمتة. لذلك ، نصف الوقت نكتب التعليمات البرمجية ونبني أدوات.- دمج التكعيبية في النظام.
- FBAR هو "فرس عمل" يأتي ويصلح ، لذلك لا أحد يقلق بشأن سيارة واحدة مكسورة. هذه هي المهمة الرئيسية لـ FBAR ، ولكن لديها الآن المزيد من المهام.
- Coredumper ، الذي كتبناه مع زميلين . تراقب الكتل على جميع الأجهزة وتسقطها في مكان واحد إلى جانب آثار المكدس مع جميع معلومات المضيف: أين تقع ، وكيفية العثور على الحجم. ولكن الأهم من ذلك ، أن تتبعات المكدس تذهب مجانًا ، بدون بدء تشغيل GDB باستخدام برامج BPF.
استطلاعات
آخر شيء نقوم به هو التحدث مع الناس وإجراء مقابلات معهم. يبدو لنا أن هذا مهم للغاية.استطلاع واحد مفيد حول الموثوقية. نسأل عن تشغيل الخدمات بالفعل في الاقتباسات الرئيسية من الاستبيان الخاص بنا:"يجب أن تكون المسؤولية الأساسية عن برنامج النظام هي مواصلة التشغيل. يجب النظر إلى تقديم الخدمة على أنه أثر جانبي مفيد لاستمرار العملية »
هذا يعني أن الواجب الرئيسي للنظام هو الاستمرار في العمل ، وحقيقة أنه يقدم نوعًا من الخدمة هو مكافأة إضافية.الاستطلاعات هي فقط للخدمات المتوسطة ، الكبيرة منها نفسها تفهم. نعطي استبيانًا نسأل فيه الأشياء الأساسية عن الهندسة المعمارية ، SLO ، الاختبار ، على سبيل المثال.- "ماذا يحدث إذا حصل نظامك على 10٪ من الحمل؟" عندما يفكر الناس: "ولكن في الحقيقة ، ماذا؟" - تظهر الأفكار ، ويحكم الكثير منها أنظمتها. في السابق ، لم يفكروا في ذلك ، ولكن بعد السؤال هناك سبب.
- "من هو أول من يلاحظ عادة مشاكل في خدمتك - أنت أم مستخدميك؟" يبدأ المطورون في التذكر عند حدوث ذلك و: "... ربما تحتاج إلى إضافة تنبيهات."
- "ما هو أكبر ألم في وجهك؟" هذا أمر غير معتاد للمطورين ، وخاصة للمطورين الجدد. يقولون على الفور: "لدينا العديد من التنبيهات! دعونا نقوم بتنظيفها وإزالة تلك التي ليست كذلك. "
- "ما مدى تكرار إصداراتك؟" يتذكرون أولاً أنهم يطلقون سراحهم بأيديهم ، ثم يكون لديهم نشر مخصص خاص بهم.
لا يوجد ترميز في الاستبيان ؛ فهو موحد ويتغير كل ستة أشهر. هذا مستند من صفحتين نساعد في ملئه في غضون 2-3 أسابيع. ثم نرتب مسيرة لمدة ساعتين ونجد حلولًا للعديد من الآلام. تعمل هذه الأداة البسيطة بشكل جيد معنا ويمكن أن تساعدك.6-7 Saint HighLoad++, . (, , ).
telegram- . !