تحسبًا لبدء دورة مهندس البيانات ، قمنا بإعداد ترجمة لمادة صغيرة ولكنها مثيرة للاهتمام.
في هذه المقالة ، سأتحدث عن كيفية ضغط الباركيه لمجموعات البيانات الكبيرة في ملف صغير الحجم ، وكيف يمكننا تحقيق عرض نطاق ترددي يتجاوز بكثير عرض النطاق الترددي لدفق I / O باستخدام التزامن (multithreading).أباتشي باركيه: الأفضل في بيانات الانتروبيا المنخفضة
كما يمكنك أن تفهم من مواصفات تنسيق Apache Parquet ، فإنه يحتوي على عدة مستويات من الترميز التي يمكن أن تحقق تخفيضًا كبيرًا في حجم الملف ، من بينها:- ترميز (ضغط) باستخدام قاموس (على غرار الباندا ، طريقة قاطعة لتقديم البيانات ، لكن المفاهيم نفسها مختلفة) ؛
- ضغط صفحات البيانات (Snappy أو Gzip أو LZO أو Brotli) ؛
- تشفير طول التنفيذ (للمؤشرات والفهارس من القاموس) وتعبئة البتات الصحيحة ؛
لتوضيح كيف يعمل هذا ، دعنا نلقي نظرة على مجموعة بيانات:['banana', 'banana', 'banana', 'banana', 'banana', 'banana',
'banana', 'banana', 'apple', 'apple', 'apple']
تستخدم جميع تطبيقات الباركيه تقريبًا القاموس الافتراضي للضغط. وبالتالي ، فإن البيانات المشفرة هي كما يلي:dictionary: ['banana', 'apple']
indices: [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1]
يتم ضغط الفهارس في القاموس أيضًا عن طريق خوارزمية تشفير التكرار:dictionary: ['banana', 'apple']
indices (RLE): [(8, 0), (3, 1)]
باتباع مسار الإرجاع ، يمكنك بسهولة استعادة مجموعة السلاسل الأصلية.في مقالتي السابقة ، أنشأت مجموعة بيانات تضغط جيدًا بهذه الطريقة. عند العمل مع pyarrow، يمكننا تمكين وتعطيل الترميز باستخدام القاموس (الذي يتم تمكينه افتراضيًا) لمعرفة كيف سيؤثر ذلك على حجم الملف:import pyarrow.parquet as pq
pq.write_table(dataset, out_path, use_dictionary=True,
compression='snappy)
تأخذ مجموعة البيانات التي تستهلك 1 جيجابايت (1024 ميجابايت) pandas.DataFrame، مع ضغط Snappy والضغط باستخدام القاموس ، 1.436 ميجابايت فقط ، أي أنه يمكن كتابتها حتى على قرص مرن. بدون الضغط باستخدام القاموس ، سيشغل 44.4 ميغابايت.قراءة متزامنة في الباركيه - CPP باستخدام PyArrow
في تنفيذ Apache Parquet في C ++ - parquet-cpp ، التي وفرناها لـ Python في PyArrow ، تمت إضافة القدرة على قراءة الأعمدة بالتوازي.لتجربة هذه الميزة ، قم بتثبيت PyArrow من Conda -forge :conda install pyarrow -c conda-forge
الآن عند قراءة ملف الباركيه ، يمكنك استخدام الوسيطة nthreads:import pyarrow.parquet as pq
table = pq.read_table(file_path, nthreads=4)
بالنسبة للبيانات ذات الانتروبيا المنخفضة ، يرتبط فك الضغط وفك التشفير بقوة بالمعالج. نظرًا لأن C ++ يقوم بكل العمل بالنسبة لنا ، فلا توجد مشاكل في التزامن GIL ويمكننا تحقيق زيادة كبيرة في السرعة. تعرف على ما تمكنت من تحقيقه من خلال قراءة مجموعة بيانات بسعة 1 غيغابايت في DataFrame من باندا على كمبيوتر محمول رباعي النواة (Xeon E3-1505M ، NVMe SSD):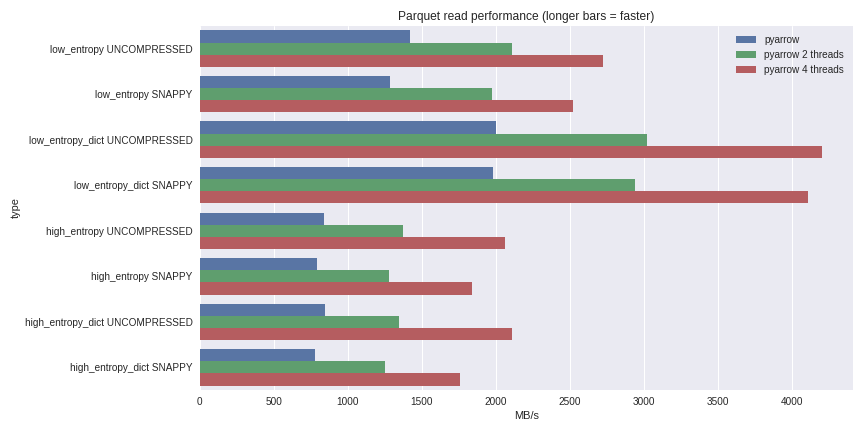 يمكنك رؤية سيناريو القياس الكامل هنا .لقد أدرجت الأداء هنا لكل من حالات الضغط باستخدام القاموس والحالات دون استخدام القاموس. بالنسبة للبيانات ذات الانتروبيا المنخفضة ، على الرغم من حقيقة أن جميع الملفات صغيرة (~ 1.5 ميجابايت باستخدام القواميس و ~ 45 ميجابايت بدون) ، فإن الضغط باستخدام القاموس يؤثر بشكل كبير على الأداء. مع 4 سلاسل ، يرتفع أداء قراءة الباندا إلى 4 جيجابايت / ثانية. هذا أسرع بكثير من تنسيق Feather أو أي شكل آخر أعرفه.
يمكنك رؤية سيناريو القياس الكامل هنا .لقد أدرجت الأداء هنا لكل من حالات الضغط باستخدام القاموس والحالات دون استخدام القاموس. بالنسبة للبيانات ذات الانتروبيا المنخفضة ، على الرغم من حقيقة أن جميع الملفات صغيرة (~ 1.5 ميجابايت باستخدام القواميس و ~ 45 ميجابايت بدون) ، فإن الضغط باستخدام القاموس يؤثر بشكل كبير على الأداء. مع 4 سلاسل ، يرتفع أداء قراءة الباندا إلى 4 جيجابايت / ثانية. هذا أسرع بكثير من تنسيق Feather أو أي شكل آخر أعرفه.استنتاج
مع إصدار الإصدار 1.0 parquet-cpp (Apache Parquet في C ++) ، يمكنك أن ترى بنفسك أداء I / O المتزايد المتاح الآن لمستخدمي Python.نظرًا لأنه يتم تنفيذ جميع الآليات الأساسية في C ++ ، بلغات أخرى (على سبيل المثال ، R) ، يمكنك إنشاء واجهات لـ Apache Arrow (هياكل البيانات العمودية) و parquet-cpp . يُعد ربط Python عبارة عن غلاف خفيف الوزن من مكتبات librow و Libparquet C ++ الأساسية.هذا كل شئ. إذا كنت تريد معرفة المزيد عن دورتنا التدريبية ، قم بالتسجيل ليوم مفتوح ، والذي سيعقد اليوم!