تم إعداد ترجمة للمقال قبل بدء دورة التعلم الآلي من OTUS.
مهمة
في هذا الدليل ، نستخدم مجموعة بيانات Bitcoin مقابل USD .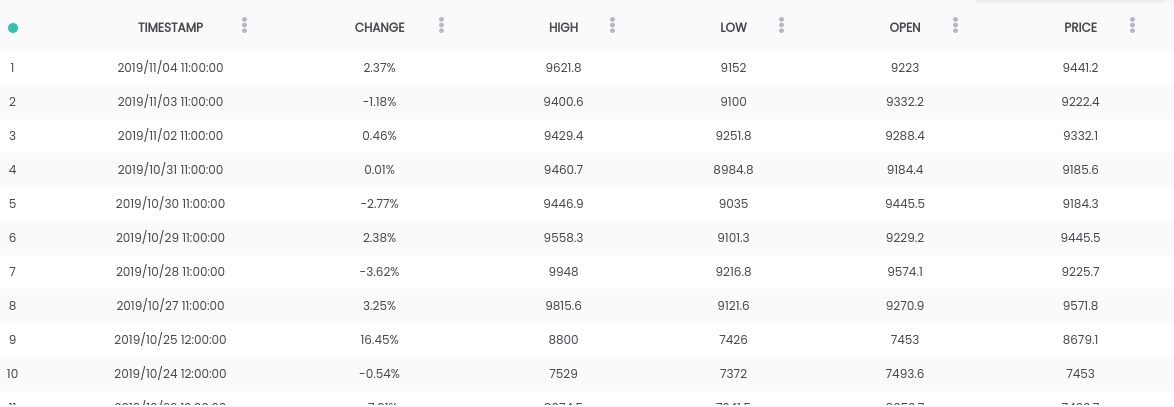 تحتوي مجموعة البيانات المذكورة أعلاه على ملخص يومي للأسعار ، حيث يمثل عمود "التغيير" التغيير في السعر كنسبة مئوية من سعر اليوم السابق ( PRICE ) مقابل الجديد ( OPEN ).الهدف: لتبسيط المهمة ، سنركز على توقع ما إذا كان السعر سيرتفع ( CHANGE> 0 ) أو سينخفض ( CHANGE <0 ) في اليوم التالي. (لذا يمكننا استخدام التوقعات "في الحياة الواقعية").المتطلبات
تحتوي مجموعة البيانات المذكورة أعلاه على ملخص يومي للأسعار ، حيث يمثل عمود "التغيير" التغيير في السعر كنسبة مئوية من سعر اليوم السابق ( PRICE ) مقابل الجديد ( OPEN ).الهدف: لتبسيط المهمة ، سنركز على توقع ما إذا كان السعر سيرتفع ( CHANGE> 0 ) أو سينخفض ( CHANGE <0 ) في اليوم التالي. (لذا يمكننا استخدام التوقعات "في الحياة الواقعية").المتطلبات- يجب تثبيت Python 2.6+ أو 3.1+ على النظام
- تثبيت الباندا ، sklearn و openblender (باستخدام النقطة)
$ pip install pandas OpenBlender scikit-learn
الخطوة 1. احصل على بيانات Bitcoin
للبدء ، دعنا نستورد المكتبات الضرورية:import OpenBlender
import pandas as pd
import json
الآن اسحب البيانات من خلال OpenBlender API .أولاً ، دعنا نحدد المعلمات (في حالتنا ، هذا مجرد معرف مجموعة بيانات البيتكوين ):
parameters = {
'id_dataset':'5d4c3af79516290b01c83f51'
}
ملاحظة: ستحتاج إلى إنشاء حساب على openblender.io (إنه مجاني) وإضافة رمز مميز (ستجده في علامة التبويب "الحساب"):parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51'
}
الآن دعونا نضع البيانات في Dataframe 'df' :
def pullObservationsToDF(parameters):
action = 'API_getObservationsFromDataset'
df = pd.read_json(json.dumps(OpenBlender.call(action,parameters)['sample']), convert_dates=False,convert_axes=False) .sort_values('timestamp', ascending=False)
df.reset_index(drop=True, inplace=True)
return df
df = pullObservationsToDF(parameters)
وانظر إليها: ملاحظة: قد تختلف القيم ، حيث يتم تحديث مجموعة البيانات يوميًا !
ملاحظة: قد تختلف القيم ، حيث يتم تحديث مجموعة البيانات يوميًا !الخطوة 2. إعداد البيانات
بادئ ذي بدء ، نحتاج إلى إنشاء هدف للتنبؤ ، وهو ما إذا كان " التغيير " سيزيد أو ينقص. للقيام بذلك ، أضف 'Success_thr_over': 0 إلى معلمات العتبة المستهدفة:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change', 'success_thr_over': 0}
}
إذا سحبنا البيانات من واجهة برمجة التطبيقات مرة أخرى:df = pullObservationsToDF(parameters)
df.head()
 تم استبدال السمة "CHANGE" بسمة جديدة "change_over_0" ، والتي تصبح 1 إذا كانت "CHANGE" موجبة و 0 إذا لم تكن كذلك. سيكون هذا هدفًا للتعلم الآلي.إذا أردنا أن نتنبأ بملاحظة "الغد" ، فلن نتمكن من استخدام المعلومات من الغد ، لذلك دعونا نضيف تأخيرًا لفترة واحدة.
تم استبدال السمة "CHANGE" بسمة جديدة "change_over_0" ، والتي تصبح 1 إذا كانت "CHANGE" موجبة و 0 إذا لم تكن كذلك. سيكون هذا هدفًا للتعلم الآلي.إذا أردنا أن نتنبأ بملاحظة "الغد" ، فلن نتمكن من استخدام المعلومات من الغد ، لذلك دعونا نضيف تأخيرًا لفترة واحدة.parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change','success_thr_over' : 0},
'lag_target_feature':{'feature':'change_over_0', 'periods' : 1}
}
df = pullObservationsToDF(parameters)
df.head()
 يؤدي هذا ببساطة إلى محاذاة "change_over_0" مع بيانات اليوم (الفترة) السابقة وتغيير اسمه إلى "TARGET_change_over_0" .دعونا نلقي نظرة على التبعية:
يؤدي هذا ببساطة إلى محاذاة "change_over_0" مع بيانات اليوم (الفترة) السابقة وتغيير اسمه إلى "TARGET_change_over_0" .دعونا نلقي نظرة على التبعية:target_variable = 'TARGET_change_over_0'
df = df.dropna()
df.corr()[target_variable].sort_values()
 وهي مستقلة خطياً ومن غير المحتمل أن تكون مفيدة.
وهي مستقلة خطياً ومن غير المحتمل أن تكون مفيدة.الخطوة 3. الحصول على بيانات أخبار الأعمال
بعد البحث عن التبعيات في OpenBlender ، وجدت مجموعة بيانات Fox Business News التي ستساعد في إنشاء توقعات جيدة لهدفنا. نحتاج إلى إيجاد طريقة لتحويل قيم عمود "العنوان" إلى الخصائص العددية من خلال حساب تكرار الكلمات ومجموعات الكلمات في ملخص الأخبار ومقارنتها في الوقت المناسب بمجموعة بيانات البيتكوين الخاصة بنا. إنه أسهل مما يبدو.تحتاج أولا إلى إنشاء TextVectorizer ل 'عنوان' سمة من الأخبار:
نحتاج إلى إيجاد طريقة لتحويل قيم عمود "العنوان" إلى الخصائص العددية من خلال حساب تكرار الكلمات ومجموعات الكلمات في ملخص الأخبار ومقارنتها في الوقت المناسب بمجموعة بيانات البيتكوين الخاصة بنا. إنه أسهل مما يبدو.تحتاج أولا إلى إنشاء TextVectorizer ل 'عنوان' سمة من الأخبار:action = 'API_createTextVectorizer'
vectorizer_parameters = {
'token' : 'your_token',
'name' : 'Fox Business TextVectorizer',
'sources':[{'id_dataset' : '5d571f9e9516293a12ad4f6d',
'features' : ['title']}],
'ngram_range' : {'min' : 1, 'max' : 2},
'language' : 'en',
'remove_stop_words' : 'on',
'min_count_limit' : 2
}
سننشئ ناقلًا ضوئيًا للحصول على جميع العلامات ككلمات رمزية على شكل أرقام. أعلاه ، أشرنا إلى ما يلي:- الاسم : دعونا نسميها "Fox Business TextVectorizer" ؛
- anchor : معرف مجموعة البيانات واسم الخصائص التي سنحتاج إلى استخدامها كمصدر (في حالتنا ، عمود "العنوان" فقط ) ؛
- ngram_range : الحد الأدنى والحد الأقصى لطول مجموعة من الكلمات للترميز ؛
- اللغة : الإنجليزية
- remove_stop_words : لإزالة كلمات التوقف من المصدر ؛
- min_count_limit : الحد الأدنى من التكرار الذي يجب اعتباره رمزًا (نادرًا ما تكون التكرارات الفردية مفيدة).
الآن قم بتشغيل هذا:res = OpenBlender.call(action, vectorizer_parameters)
res
إجابة:{
'message' : 'TextVectorizer created successfully.'
'id_textVectorizer' : '5dc1a404951629331f6359dd',
'num_ngrams': 4270
}
تم إنشاء TextVectorizer ، الذي أنتج 4270 ن-غرام وفقًا لتكويننا . بعد ذلك بقليل سنحتاج إلى المعرف الذي تم إنشاؤه:5dc1a404951629331f6359ddالخطوة 4. موجز الأخبار المتوافقة مع مجموعة بيانات بيتكوين
الآن نحن بحاجة إلى مقارنة ملخص الأخبار وبيانات سعر صرف البيتكوين في الوقت المناسب. بشكل عام ، هذا يعني أنك بحاجة إلى دمج مجموعتين من البيانات باستخدام طابع زمني كمفتاح. دعنا نضيف البيانات المدمجة إلى خيارات استخراج البيانات الأصلية:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'specifications':{'time_interval_size' : 3600*12 }}]
}
أعلاه ، أشرنا إلى ما يلي:- id_blend : معرف textVectorizer الخاص بنا ؛
- blend_type : "text_ts" بحيث تدرك Python أنها مزيج من النص والطابع الزمني ؛
- التقييد : "تنبئي" ، بحيث لا يوجد "خلط" للأخبار من المستقبل مع جميع الملاحظات ، ولكن فقط مع تلك التي تم نشرها في وقت سابق عن الوقت المحدد.
- blend_class : 'closest_observation' ، بحيث تكون "الملاحظات المختلطة" هي الأقرب فقط ؛
- المواصفات : أقصى قدر ممكن من الوقت المنقضي لنقل الملاحظة ، في هذه الحالة 12 ساعة (3600 * 12). هذا يعني أنه سيتم توقع كل ملاحظة على سعر البيتكوين بناءً على أخبار آخر 12 ساعة.
أخيرًا ، نضيف فقط عامل تصفية حسب تاريخ "date_filter" ، بدءًا من 20 أغسطس ، لأنه عندما بدأت Fox News في جمع البيانات ، و "drop_non_numeric" حتى نحصل على أرقام فقط:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'blend_class' : 'closest_observation',
'specifications':{'time_interval_size' : 3600*12 }}],
'date_filter':{'start_date':'2019-08-20T16:59:35.825Z',
'end_date':'2019-11-04T17:59:35.825Z'},
'drop_non_numeric' : 1
}
ملحوظة : أشرت في 4 نوفمبر كـ "end_date" ، لأنه في اليوم الذي كتبت فيه هذا الرمز ، يمكنك تغيير التاريخ.دعنا نحصل على البيانات مرة أخرى:df = pullObservationsToDF(parameters)
print(df.shape)
df.head()
(57 ، 2115) الآن لدينا أكثر من 2000 علامة مع رموز و 57 ملاحظة.
الآن لدينا أكثر من 2000 علامة مع رموز و 57 ملاحظة.الخطوة 5. تطبيق ML على هدف التنبؤ
الآن ، أخيرًا ، لدينا مجموعة بيانات نظيفة ، وتبدو تمامًا كما نحتاجها ، مع تعويض زمني للهدف والبيانات الرقمية المرتبطة بها.دعونا نلقي نظرة على أعلى الارتباطات مع "Target_change_over_0" : الآن لدينا بعض سمات الارتباط. دعونا نقسم مجموعة البيانات إلى تدريب واختبار بترتيب زمني حتى نتمكن من تدريب النموذج في الملاحظات المبكرة والاختبار في الملاحظات اللاحقة.
الآن لدينا بعض سمات الارتباط. دعونا نقسم مجموعة البيانات إلى تدريب واختبار بترتيب زمني حتى نتمكن من تدريب النموذج في الملاحظات المبكرة والاختبار في الملاحظات اللاحقة.X = df.loc[:, df.columns != target_variable].values
y = df.loc[:,[target_variable]].values
div = int(round(len(X) * 0.29))
X_test = X[:div]
y_test = y[:div]
print(X_test.shape)
print(y_test.shape)
X_train = X[div:]
y_train = y[div:]
print(X_train.shape)
print(y_train.shape)
 لدينا 40 ملاحظة للتدريب و 17 للاختبار.الآن نستورد المكتبات الضرورية:
لدينا 40 ملاحظة للتدريب و 17 للاختبار.الآن نستورد المكتبات الضرورية:from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
from sklearn import metrics
الآن ، دعنا نستخدم غابة عشوائية (RandomForest) ونقوم بالتنبؤ:rf = RandomForestRegressor(n_estimators = 1000)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
لتسهيل الأمور ، دعنا نضع التوقعات و y_test في Dataframe:df_res = pd.DataFrame({'y_test':y_test[:,0], 'y_pred':y_pred})
df_res.head()
"y_test"
الحقيقي الخاص بنا هو ثنائي ، لكن توقعاتنا من النوع العائم ، لذلك دعونا نقربها للأعلى ، بافتراض أنه إذا كانت أكبر من 0.5 ، فهذا يعني زيادة في السعر ، وإذا كان أقل من 0.5 - انخفاض.threshold = 0.5
preds = [1 if val > threshold else 0 for val in df_res['y_pred']]
الآن ، من أجل فهم النتائج بشكل أفضل ، نحصل على AUC ومصفوفة الخطأ ومؤشر الدقة:print(roc_auc_score(preds, df_res['y_test']))
print(metrics.confusion_matrix(preds, df_res['y_test']))
print(accuracy_score(preds, df_res['y_test']))
 حصلنا على 64.7 ٪ من التوقعات الصحيحة مع 0.65 AUC.
حصلنا على 64.7 ٪ من التوقعات الصحيحة مع 0.65 AUC.- 9 مرات توقعنا انخفاضًا ، وانخفض السعر (حق) ؛
- 5 مرات توقعنا انخفاضًا ، وارتفع السعر (بشكل غير صحيح) ؛
- 1 مرة توقعنا زيادة ، لكن السعر انخفض بشكل غير صحيح) ؛
- 2 مرات توقعنا زيادة ، وارتفع السعر (صحيح).
تعلم المزيد عن الدورة .