عندما ينتهي عام مثمر آخر ، أريد أن أنظر إلى الوراء ، وأقيم ، وأعرض ما تمكنا من القيام به خلال هذا الوقت. مكتبة #DeepPavlov ، لمدة دقيقة ، عمرها بالفعل عامين ، ويسعدنا أن مجتمعنا ينمو كل يوم.على مدار عام العمل في المكتبة ، حققنا:- زادت تنزيلات المكتبة بنسبة الثلث مقارنة بالعام الماضي. الآن لدى DeepPavlov أكثر من 100 ألف منشأة وأكثر من 10 آلاف منشأة للحاويات.
- ازداد عدد الحلول التجارية بسبب أحدث التقنيات المطبقة في DeepPavlov ، في صناعات مختلفة من البيع بالتجزئة إلى الصناعة.
- تم إصدار الإصدار الأول من وكيل DeepPavlov .
- زاد عدد أعضاء المجتمع النشطين 5 مرات.
- تم اختيار فريقنا من الطلاب الجامعيين وطلاب الدراسات العليا للمشاركة في التحدي الكبير لجائزة Alexa Prize Socialbot 3 .
- أصبحت المكتبة فائزة في المسابقة من شركة Google «بدعم من تحدي TensorFlow».
ما الذي ساعد على تحقيق هذه النتائج ولماذا يعتبر DeepPavlov أفضل مصدر مفتوح لبناء الذكاء الاصطناعي للمحادثة؟ سنقول في مقالتنا.
#DeepPavlov يهدف إلى النتيجة
أصبحت أنظمة الحوار مؤخرًا المعيار للتفاعل بين الإنسان والآلة. يتم استخدام برامج الدردشة الآلية في جميع الصناعات تقريبًا ، مما يبسط التفاعل بين الأشخاص وأجهزة الكمبيوتر. يتم دمجها بسلاسة في مواقع الويب والأنظمة الأساسية للرسائل والأجهزة. تفضل العديد من الشركات اليوم تفويض المهام الروتينية إلى الأنظمة التفاعلية التي يمكنها التعامل مع طلبات المستخدمين المتعددة في نفس الوقت ، مما يوفر تكاليف العمالة.ومع ذلك ، غالبًا ما لا تعرف الشركات من أين تبدأ عند تطوير روبوت لتلبية احتياجات أعمالهم. تاريخياً ، يمكن تقسيم برامج الدردشة الآلية إلى مجموعتين كبيرتين: بناءً على القواعد وعلى أساس البيانات. يعتمد النوع الأول على الأوامر والقوالب المحددة مسبقًا. يجب كتابة كل من هذه الأوامر بواسطة مطور برامج الدردشة باستخدام التعبيرات العادية وتحليل البيانات النصية. في المقابل ، تعتمد روبوتات الدردشة القائمة على البيانات على نماذج التعلم الآلي التي تم تدريبها مسبقًا على بيانات الحوار.مكتبة المصادر المفتوحة - DeepPavlovيقدم حلاً مجانيًا وسهل الاستخدام لبناء أنظمة تفاعلية. يأتي DeepPavlov مع العديد من المكونات المدربة مسبقًا لحل المشكلات المرتبطة بمعالجة اللغة الطبيعية (NLP). يحل DeepPavlov مشاكل مثل: تصنيف النص ، وتصحيح الأخطاء المطبعية ، والتعرف على الكيانات المسماة ، والإجابات على الأسئلة في قاعدة المعرفة وغيرها الكثير. ويمكنك تثبيت DeepPavlov في سطر واحد عن طريق تشغيل:pip install -q deeppavlov
* يسمح لك الإطار بتدريب واختبار النماذج ، بالإضافة إلى تخصيص معلماتها الفائقة. تدعم المكتبة منصات Linux و Windows. يمكنك تجربة هذا ونماذج أخرى في النسخة التجريبية من المكتبة .حاليًا ، تم تحقيق نتائج حديثة في العديد من المهام من خلال استخدام النماذج القائمة على BERT. قام فريق DeepPavlov بدمج BERT في المهام الثلاث التالية: تصنيف النص ، والاعتراف بالكيانات المسماة ، وإجابات الأسئلة. ونتيجة لذلك ، حققنا تحسينات كبيرة في كل هذه المهام.1. نماذج BERT DeepPavlov
BERT لتصنيف النص
يعمل نموذج تصنيف النص القائم على BERT DeepPavlov ، على سبيل المثال ، على حل مشكلة الكشف عن الإهانات. يتضمن النموذج توقع ما إذا كان التعليق المنشور في مناقشة عامة يعتبر مسيئًا لأحد المشاركين. بالنسبة لهذه الحالة ، يتم التصنيف فقط في فئتين: الإهانة وليس الإهانة.يمكن استخدام أي نموذج تم تدريبه مسبقًا للإخراج من خلال واجهة سطر الأوامر (CLI) ومن خلال Python. قبل استخدام النموذج ، تأكد من تثبيت جميع الحزم الضرورية باستخدام الأمر:python -m deeppavlov install insults_kaggle_bert
python -m deeppavlov interact insults_kaggle_bert -d
BERT للتعرف على الكيانات المسماة
بالإضافة إلى نماذج تصنيف النص ، يشتمل DeepPavlov على نموذج قائم على BERT للتعرف على الكيانات المسماة (NER). هذه واحدة من أكثر المهام شيوعًا في البرمجة اللغوية العصبية والنموذج الأكثر استخدامًا في مكتبتنا. في نفس الوقت ، لدى NER العديد من تطبيقات الأعمال. على سبيل المثال ، يمكن للنموذج استخراج معلومات مهمة من السيرة الذاتية لتسهيل عمل متخصصي الموارد البشرية. بالإضافة إلى ذلك ، يمكن استخدام NER لتحديد الكيانات ذات الصلة في طلبات العملاء ، مثل مواصفات المنتج أو أسماء الشركات أو معلومات فرع الشركة.قام فريق DeepPavlov بتدريب نموذج NER في حزمة OntoNotes باللغة الإنجليزية ، والتي تحتوي على 19 نوعًا من الترميز ، بما في ذلك PER (شخص) ، LOC (موقع) ، ORG (منظمة) ، وغيرها الكثير. للتفاعل ، يجب تثبيته باستخدام الأمر:python -m deeppavlov install ner_ontonotes_bert_mult
python -m deeppavlov interact ner_ontonotes_bert_mult [-d]
BERT للإجابة على الأسئلة الإجابة
السياقية على السؤال هي مهمة العثور على إجابة لسؤال في سياق معين (على سبيل المثال ، فقرة من ويكيبيديا) ، حيث تكون الإجابة على كل سؤال جزء سياق. على سبيل المثال ، يشكل الثلاثي من السياق والسؤال والجواب أدناه ثلاثية صحيحة لمهمة الإجابة على السؤال.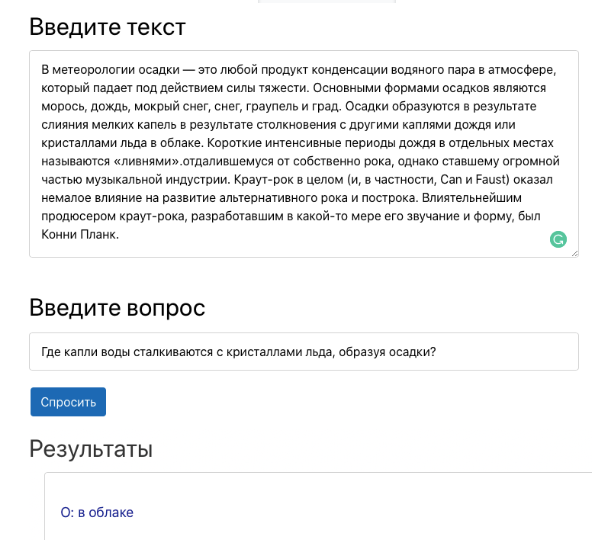 عرض عمل نظام الإجابة على الأسئلة في عرض توضيحي.يمكن لنظام الإجابات على الأسئلة أتمتة العديد من العمليات في الأعمال التجارية. على سبيل المثال ، يمكن أن يساعد هذا أصحاب العمل في الحصول على إجابات بناءً على وثائق الشركة الداخلية. بالإضافة إلى ذلك ، سيساعد النموذج على اختبار قدرة الطلاب على فهم النص في عملية التعلم. في الآونة الأخيرة ، ومع ذلك ، جذبت مهمة الإجابة على الأسئلة على أساس السياق اهتماما كبيرا من العلماء. كانت إحدى نقاط التحول الرئيسية في هذا المجال هي إصدار مجموعة أسئلة ستانفورد (SQuAD). أدت مجموعة بيانات SQuAD إلى طرق لا حصر لها لحل مشكلة نظام الإجابة على الأسئلة. أحد أنجحها هو نموذج DeepPavlov BERT. يتفوق على جميع الآخرين ويؤدي حاليًا إلى نتائج تحد من الخصائص البشرية.لاستخدام نموذج ضمان الجودة القائم على BERT مع DeepPavlov ، يجب:
عرض عمل نظام الإجابة على الأسئلة في عرض توضيحي.يمكن لنظام الإجابات على الأسئلة أتمتة العديد من العمليات في الأعمال التجارية. على سبيل المثال ، يمكن أن يساعد هذا أصحاب العمل في الحصول على إجابات بناءً على وثائق الشركة الداخلية. بالإضافة إلى ذلك ، سيساعد النموذج على اختبار قدرة الطلاب على فهم النص في عملية التعلم. في الآونة الأخيرة ، ومع ذلك ، جذبت مهمة الإجابة على الأسئلة على أساس السياق اهتماما كبيرا من العلماء. كانت إحدى نقاط التحول الرئيسية في هذا المجال هي إصدار مجموعة أسئلة ستانفورد (SQuAD). أدت مجموعة بيانات SQuAD إلى طرق لا حصر لها لحل مشكلة نظام الإجابة على الأسئلة. أحد أنجحها هو نموذج DeepPavlov BERT. يتفوق على جميع الآخرين ويؤدي حاليًا إلى نتائج تحد من الخصائص البشرية.لاستخدام نموذج ضمان الجودة القائم على BERT مع DeepPavlov ، يجب:python -m deeppavlov install squad_bert
python -m deeppavlov interact squad_bert -d
يمكن العثور على المزيد من النماذج في الوثائق . وإذا كنت بحاجة إلى برامج تعليمية حول استخدام مكونات المكتبة ، فابحث عنها في مدونتنا الرسمية .2. DeepPavlov Agent - منصة لإنشاء روبوتات الدردشة متعددة المهام
اليوم ، هناك العديد من الطرق لتطوير العوامل التفاعلية. عند تطوير وكلاء المحادثة ، يتم استخدام البنية المعيارية بشكل أساسي لإجراء حوار مركز يتكشف فيه النص. ومع ذلك ، غالبًا ما يحتاج المستخدم إلى الجمع بين حوار مركز ، على سبيل المثال ، مع وظيفة أخرى - الإجابة على الأسئلة أو البحث عن المعلومات ، بالإضافة إلى الحفاظ على المحادثة. وبالتالي ، فإن وكيل الحوار المثالي هو مساعد شخصي يجمع بين أنواع مختلفة من العوامل ، والتبديل بين وظائفه وشخصياته ، اعتمادًا على المهمة التي يتم استخدامها فيها. في الوقت نفسه ، يجب على الوكيل تجميع معلومات حول جوهره ، وتعديل خوارزمياته لمستخدم معين. من ناحية أخرى ، يجب أن تكون قادرة على التكامل مع الخدمات الخارجية. على سبيل المثال،استعلام عن قواعد البيانات الخارجية ، والحصول على معلومات من هناك ، ومعالجتها ، وتسليط الضوء على المهم وإرساله إلى المستخدم. لحل هذه المشكلة ، في أكتوبر 2019 ، تم إصدار الإصدار الأول من DeepPavlov Agent 1.0 ، وهو نظام أساسي لإنشاء روبوتات الدردشة متعددة المهام. يساعد الوكيل مطوري برامج الدردشة على الإنتاج في تنظيم العديد من نماذج البرمجة اللغوية العصبية في خط أنابيب واحد.اقرأ المزيد عن النظام الأساسي والميزات في الوثائق .3. تنفيذ DeepPavlov NLP SaaS
لتبسيط العمل مع نماذج NLP المدربة مسبقًا من DeepPavlov ، في سبتمبر 2019 ، تم إطلاق خدمة SaaS. يسمح لك DeepPavlov Cloud بتحليل النص ، بالإضافة إلى تخزين المستندات في السحابة. استخدام النماذج، تحتاج إلى مسجل الخدمة والحصول على الرمز في قسم الرموز من حسابك الشخصي. في الوقت الحالي ، تدعم الخدمة العديد من نماذج NLP المدربة مسبقًا باللغة الروسية وهي في طور اختبار النظام.4. المشاركة في DSCT8 أو نظام الحوار المستهدف
فتح استخدام المساعدين الظاهريين مثل Amazon Alexa و Google Assistant فرصًا لتطوير التطبيقات التي تسمح لنا بتبسيط تنفيذ العديد من المهام اليومية ، مثل طلب سيارة أجرة ، وحجز طاولة في مطعم ، والعديد من المهام الأخرى. لحل هذه المشاكل ، يتم استخدام أنظمة الحوار المركزة.تتبع حالة الحوار (DST) هو مكون رئيسي في أنظمة الحوار هذه. DST مسؤولة عن ترجمة التعبيرات في اللغة البشرية إلى تمثيل لغوي للغة ، على وجه الخصوص ، لاستخراج المقاصد وأزواج القيمة الزمنية المقابلة لهدف المستخدم.أثناء مشاركة الفريق في DSTC8تم تطوير نموذج GOLOMB (متتبع حالة الحوار القائم على مهام BERT متعدد المهام الموجه نحو GOaL) - وهو نموذج متعدد المهام موجه نحو الأهداف يستند إلى BERT لتتبع حالة الحوار. للتنبؤ بحالة الحوار ، يحل النموذج العديد من مشاكل التصنيف ومهمة إيجاد سلسلة فرعية. قريبا سوف يظهر هذا النموذج في مكتبة DeepPavlov. في هذه الأثناء ، يمكنك قراءة المقالة الكاملة هنا . عرض الملصق في مؤتمر AAAI-20 في نيويورك (الولايات المتحدة الأمريكية).
عرض الملصق في مؤتمر AAAI-20 في نيويورك (الولايات المتحدة الأمريكية).
5. المشاركة في التحدي الكبير لجائزة اليكسا Socialbot
تم اختيار فريق DeepPavlov ، المكون من الطلاب وطلاب الدراسات العليا في معهد موسكو للفيزياء والتكنولوجيا ، للمشاركة في تحدي اليكسا جائزة Socialbot Grand Challenge 3 - وهي مسابقة دولية مخصصة لتطوير تكنولوجيا الذكاء الاصطناعي للمحادثة. الهدف من المسابقة هو إنشاء روبوت يمكنه التواصل بحرية مع الأشخاص حول الموضوعات ذات الصلة. من بين 375 طلبًا ، اختارت لجنة جائزة Alexa 10 من المتأهلين للتصفيات النهائية ، بما في ذلك فريقنا - DREAM. في الوقت الحالي ، انتقل الفريق إلى ربع نهائي المسابقة ويقاتل للوصول إلى الدور نصف النهائي. يمكنك متابعة الأخبار والتعبير عن فرحتنا على الصفحة الرسمية ، ولا تنسى الاشتراك في تويتر . تكوين فريق Dream Team.
تكوين فريق Dream Team.
6. المشاركة في تحدي TF
كما ذكرنا سابقًا ، يأتي DeepPavlov مع العديد من المكونات المدربة مسبقًا التي تعمل بواسطة TensorFlow و Keras. وفي هذا العام ، فاز فريق DeepPavlov بمسابقة Google Powered by TF Challenge لأفضل مشروع لتعلم الآلة يستخدم مكتبة TensorFlow. من بين أكثر من 600 مشارك في المسابقة ، اختارت Google أفضل خمسة مشاريع ، أحدها مكتبة DeepPavlov. تم تقديم المشروع على مدونة TensorFlow الرسمية . من الجدير بالذكر أن مرونة TensorFlow تسمح لنا بإنشاء أي بنية شبكة عصبية يمكننا التفكير فيها. وبشكل خاص ، نستخدم TensorFlow للتكامل السلس مع النماذج القائمة على BERT.
7. تنمية المجتمع
يتمثل الهدف العالمي لمشروعنا في تمكين المطورين والباحثين في مجال الذكاء الاصطناعي للمحادثة من استخدام الأدوات الأكثر تقدمًا لإنشاء أنظمة تفاعلية من الجيل التالي ، بالإضافة إلى أن يصبح منصة مهمة دوليًا في مجال الذكاء الاصطناعي لتبادل الخبرات وتعليم أحدث التقنيات.لتحقيق ذلك ، الموظفين DeepPavlovإجراء دورات تدريبية مجانية للفصل الدراسي للطلاب والموظفين المشاركين في علوم الكمبيوتر. أحدها الدورة: "التعلم العميق في معالجة اللغات الطبيعية" ، والذي يشمل الندوات وورش العمل. تتضمن الفصول موضوعات مثل: بناء أنظمة الحوار ، وطرق تقييم نظام الحوار مع القدرة على توليد استجابة ، وأطر عمل مختلفة لأنظمة الحوار ، وطرق تقدير مقدار المكافأة بسبب تحسين سياسات الحوار ، وأنواع طلبات المستخدم ، والنظر في نمذجة مكالمات مركز الاتصال. في عام 2020 ، أطلقنا عملية توظيف جديدة وخضع بالفعل 900 طالب وموظف للتدريب مجانًا. يمكنك متابعة الأخبار ومجموعة لهذا وغيرها من الدورات على موقعنا على الانترنت . وإذا فاتك الدورات التدريبية ، ولكنك تريد معرفة المزيد - ثم على موقعناقناة يوتيوب يمكنك دائما العثور عليها في السجل. توفرمكتبة DeepPavlov اليوم مكونات جاهزة للعمل مع الذكاء الاصطناعي للعمل مع النص ، والتي يتم استخدامها في 92 دولة حول العالم. اعتبارًا من فبراير 2020 ، بلغ عدد التنزيلات للمكتبة 100.000 ألف ، واكتسبت ديناميكيات التركيبات زخمًا. بالإضافة إلى ذلك ، نفذت أكثر من 30 شركة في روسيا بالفعل وتستخدم الحلول المعتمدة على DeepPavlov بنجاح. هذا يدل على أن هذه الحلول تحظى بشعبية كبيرة في جميع أنحاء العالم.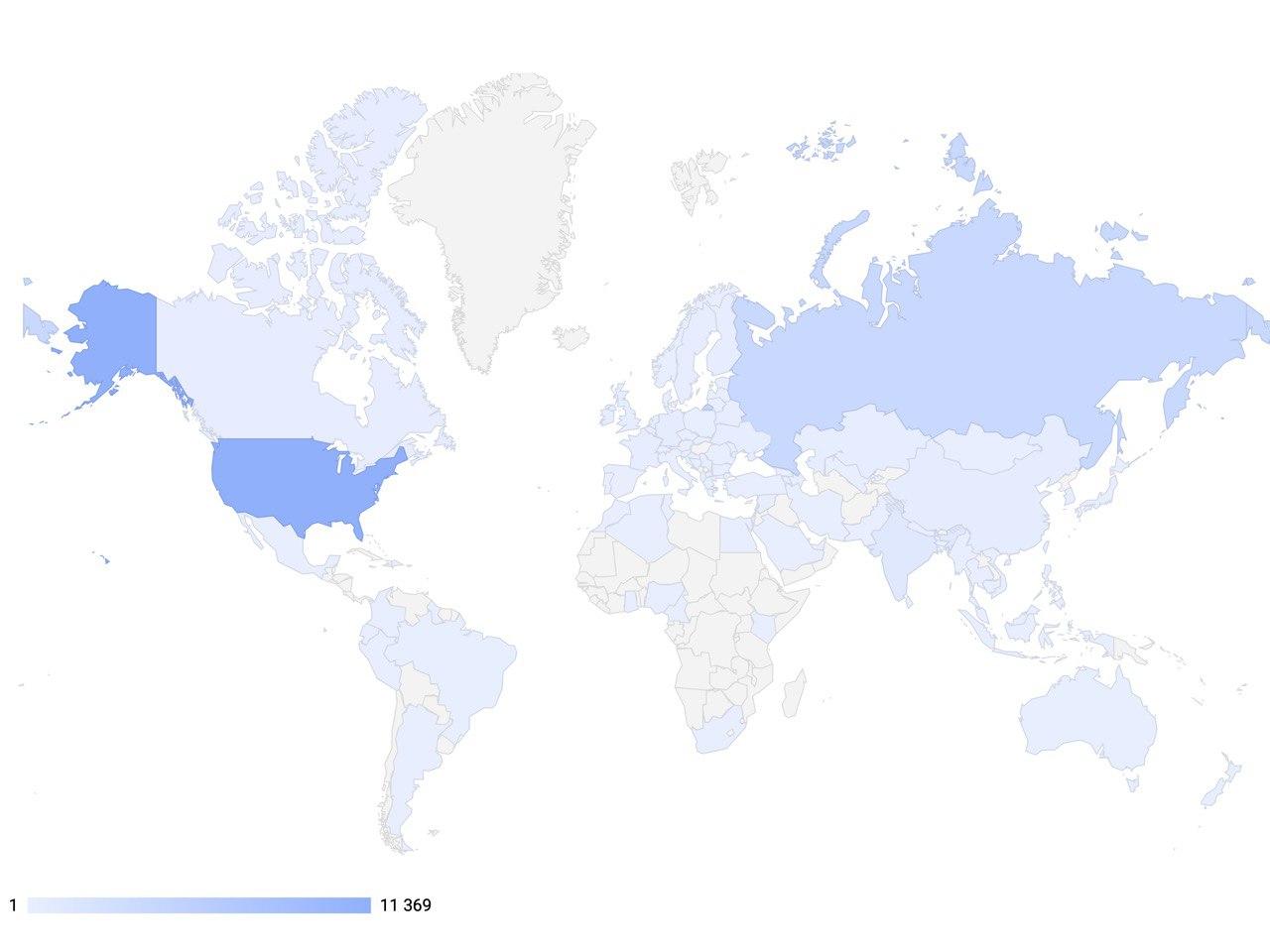
ماذا بعد؟
يسعدنا مشاركة نجاحاتنا معك ، لذلك قمنا بإعداد حدث لمجتمعنا. نريد مشاركة الخبرة والمعرفة من مشاريع الإنتاج الحقيقية حول كيفية إنشاء أفضل مساعدي الذكاء الاصطناعي. انضم إلى اجتماع المستخدمين والمطورين في مكتبة DeepPavlov المفتوحة في 28 فبراير للتحدث عن الذكاء الاصطناعي وتطبيقاته ، وكذلك مقابلة أعضاء آخرين في المجتمع. سيُعقد الحدث كجزء من أسبوع الذكاء الاصطناعي من 25 إلى 28 فبراير. نحن في انتظار كل من يستخدم DeepPavlov أو يريد التعرف على التكنولوجيا الخاصة بنا.يمكن العثور على جميع المعلومات حول المتحدثين والبرنامج على الموقع ، مطلوب التسجيل لحضور الحدث.تاريخ الانضمام: DeepPavlov 2 سنة
ستستمر صناعة الذكاء الاصطناعي في التطور ، ونعتقد أن DeepPavlov ستصبح تقنية متقدمة يستخدمها كل مطور لفهم اللغة الطبيعية. في العام المقبل ، سنعمل على مضاعفة مجتمعنا ، وزيادة أدوات المصادر المفتوحة ، وتحسين أبحاث التعلم الآلي. ولا تنس أن DeepPavlov لديه منتدى - اطرح أسئلتك فيما يتعلق بالمكتبة والنماذج. شكرا للانتباه!