في هذه المقالة ، سأتحدث عن بعض الحيل البسيطة المفيدة عند العمل مع البيانات التي لا تتناسب مع الجهاز المحلي ، ولكنها لا تزال صغيرة جدًا بحيث لا يمكن تسميتها كبيرة. بعد تشبيه اللغة الإنجليزية (كبير ولكن ليس كبيرًا) ، سوف نسمي هذه البيانات سميكة. نحن نتحدث عن أحجام الوحدات وعشرات الجيجابايت.[إخلاء المسؤولية] إذا كنت تحب SQL ، فإن كل شيء مكتوب أدناه يمكن أن يتسبب في أن تكون لديك مشاعر سلبية مشرقة ، وعلى الأرجح ، يوجد في هولندا 49262 تسلا ، 427 منهم من سيارات الأجرة ، من الأفضل عدم قراءة المزيد [/ إخلاء المسؤولية]. كانت نقطة البداية عبارة عن مقالة على المحور مع وصف لمجموعة بيانات مثيرة للاهتمام - قائمة كاملة من المركبات المسجلة في هولندا ، 14 مليون خط ، كل شيء من جرارات الشاحنات إلى الدراجات الكهربائية بسرعات أعلى من 25 كم / ساعة.المجموعة مثيرة للاهتمام ، تأخذ 7 جيجا بايت ، يمكنك تنزيلها على موقع المنظمة المسؤولة.لقد حذرت محاولة دفع البيانات كما هي في الباندا لتصفية وتنظيفها في إخفاق (حذرت السادة من فرسان SQL!). سقطت الباندا من نقص الذاكرة على سطح المكتب مع 8 غيغابايت. مع القليل من إراقة الدماء ، يمكن حل السؤال إذا كنت تتذكر أن الباندا يمكنها قراءة ملفات csv في قطع متوسطة الحجم. يتم تحديد حجم الجزء في الصفوف بواسطة المعلمة chunksize.لتوضيح العمل ، نكتب وظيفة بسيطة تقدم طلبًا وتحدد عدد سيارات تسلا إجمالاً ونسبة تلك التي تعمل في سيارات الأجرة. بدون حيل مع قراءة جزء ، يأكل مثل هذا الطلب أولاً الذاكرة بالكامل ، ثم يعاني لفترة طويلة ، وفي النهاية يسقط المنحدر.مع القراءة المجزأة ، ستبدو وظيفتنا على النحو التالي:
كانت نقطة البداية عبارة عن مقالة على المحور مع وصف لمجموعة بيانات مثيرة للاهتمام - قائمة كاملة من المركبات المسجلة في هولندا ، 14 مليون خط ، كل شيء من جرارات الشاحنات إلى الدراجات الكهربائية بسرعات أعلى من 25 كم / ساعة.المجموعة مثيرة للاهتمام ، تأخذ 7 جيجا بايت ، يمكنك تنزيلها على موقع المنظمة المسؤولة.لقد حذرت محاولة دفع البيانات كما هي في الباندا لتصفية وتنظيفها في إخفاق (حذرت السادة من فرسان SQL!). سقطت الباندا من نقص الذاكرة على سطح المكتب مع 8 غيغابايت. مع القليل من إراقة الدماء ، يمكن حل السؤال إذا كنت تتذكر أن الباندا يمكنها قراءة ملفات csv في قطع متوسطة الحجم. يتم تحديد حجم الجزء في الصفوف بواسطة المعلمة chunksize.لتوضيح العمل ، نكتب وظيفة بسيطة تقدم طلبًا وتحدد عدد سيارات تسلا إجمالاً ونسبة تلك التي تعمل في سيارات الأجرة. بدون حيل مع قراءة جزء ، يأكل مثل هذا الطلب أولاً الذاكرة بالكامل ، ثم يعاني لفترة طويلة ، وفي النهاية يسقط المنحدر.مع القراءة المجزأة ، ستبدو وظيفتنا على النحو التالي:def pandas_chunky_query():
print('reading csv file with pandas in chunks')
filtered_chunk_list=[]
for chunk in pd.read_csv('C:\Open_data\RDW_full.CSV', chunksize=1E+6):
filtered_chunk=chunk[chunk['Merk'].isin(['TESLA MOTORS','TESLA'])]
filtered_chunk_list.append(filtered_chunk)
model_df = pd.concat(filtered_chunk_list)
print(model_df['Taxi indicator'].value_counts())
من خلال تحديد مليون سطر معقول تمامًا ، يمكنك تنفيذ الاستعلام في 1:46 واستخدام 1965 M من الذاكرة في ذروتها. جميع الأرقام لسطح المكتب البكم مع شيء قديم ، ثمانية النواة حوالي 8 جيجا بايت من الذاكرة وتحت ويندوز السابع.
 إذا قمت بتغيير chunksize ، فإن ذروة استهلاك الذاكرة يتبعه حرفياً ، فإن وقت التنفيذ لا يتغير كثيرًا. بالنسبة لخطوط 0.5 M ، يستغرق الطلب 1:44 و 1063 ميجابايت ، لـ 2M 1:53 و 3762 ميجابايت.السرعة ليست مرضية للغاية ، بل أقل إرضاءً هو أن قراءة الملف في أجزاء تجبرك على الكتابة المعدلة لهذه الوظيفة ، والعمل مع قوائم الأجزاء التي يجب جمعها بعد ذلك في إطار بيانات. أيضًا ، تنسيق csv نفسه ليس سعيدًا جدًا ، والذي يشغل مساحة كبيرة ويتم قراءته ببطء.نظرًا لأنه يمكننا دفع البيانات إلى منحدر ، يمكن استخدام تنسيق Apachev أكثر إحكامًا للتخزينباركيه حيث يوجد ضغط ، وبفضل مخطط البيانات ، يكون قراءته أسرع بكثير عند قراءته. ومنحدر قادر تمامًا على العمل معه. فقط الآن لا يمكن قراءتها في شظايا. ماذا أفعل؟- دعونا نلهو ، خذ
إذا قمت بتغيير chunksize ، فإن ذروة استهلاك الذاكرة يتبعه حرفياً ، فإن وقت التنفيذ لا يتغير كثيرًا. بالنسبة لخطوط 0.5 M ، يستغرق الطلب 1:44 و 1063 ميجابايت ، لـ 2M 1:53 و 3762 ميجابايت.السرعة ليست مرضية للغاية ، بل أقل إرضاءً هو أن قراءة الملف في أجزاء تجبرك على الكتابة المعدلة لهذه الوظيفة ، والعمل مع قوائم الأجزاء التي يجب جمعها بعد ذلك في إطار بيانات. أيضًا ، تنسيق csv نفسه ليس سعيدًا جدًا ، والذي يشغل مساحة كبيرة ويتم قراءته ببطء.نظرًا لأنه يمكننا دفع البيانات إلى منحدر ، يمكن استخدام تنسيق Apachev أكثر إحكامًا للتخزينباركيه حيث يوجد ضغط ، وبفضل مخطط البيانات ، يكون قراءته أسرع بكثير عند قراءته. ومنحدر قادر تمامًا على العمل معه. فقط الآن لا يمكن قراءتها في شظايا. ماذا أفعل؟- دعونا نلهو ، خذ الأكورديون زر داسك وتسريع!داسك! بديل عن المنحدر خارج الصندوق ، قادر على قراءة الملفات الكبيرة ، قادر على العمل بالتوازي على عدة نوى واستخدام الحسابات البطيئة. لدهشتي حول Dask on Habré هناك 4 منشورات فقط .لذا ، نأخذ الدسكة ، وننقل إليها ملف csv الأصلي ، وبأقل قدر من التحويل ، نقودها إلى الأرض. عند القراءة ، يقسم dask على غموض أنواع البيانات في بعض الأعمدة ، لذلك قمنا بتعيينها بشكل صريح (من أجل الوضوح ، تم عمل نفس الشيء للمنحدر ، وقت التشغيل أعلى مع مراعاة هذا العامل ، يتم قطع القاموس مع dtypes للتوضيح من جميع الاستعلامات) ، والباقي لنفسه . علاوة على ذلك ، للتحقق ، نجري تحسينات صغيرة على الأرضيات ، أي أننا نحاول تقليل أنواع البيانات إلى الأنواع الأكثر إحكاما ، واستبدال زوج من الأعمدة بنص نعم / لا بأخرى منطقية ، وتحويل البيانات الأخرى إلى الأنواع الأكثر اقتصادا (بالنسبة لعدد أسطوانات المحرك ، uint8 كافية بالتأكيد). نحفظ الأرضيات المحسنة بشكل منفصل ونرى ما نحصل عليه.أول شيء يرضي عند العمل مع Dask هو أننا لا نحتاج إلى كتابة أي شيء غير ضروري ببساطة لأن لدينا بيانات سميكة. إذا لم تنتبه إلى حقيقة أن dask مستوردة ، وليس منحدرًا ، فإن كل شيء يبدو مثل معالجة ملف يحتوي على مائة سطر في المنحدر (بالإضافة إلى صافرات زينة للتشكيل الجانبي).def dask_query():
print('reading CSV file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_csv('C:\Open_data\RDW_full.CSV')
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts().compute())
rprof.visualize()
قارن الآن تأثير ملف المصدر على الأداء عند العمل مع داسكو. أولاً ، نقرأ ملف csv نفسه عند العمل مع المنحدر. نفس الشيء حوالي دقيقتين وذاكرة من غيغابايت (1:38 2096 ميجا بايت). يبدو ، هل كان يستحق التقبيل في الأدغال؟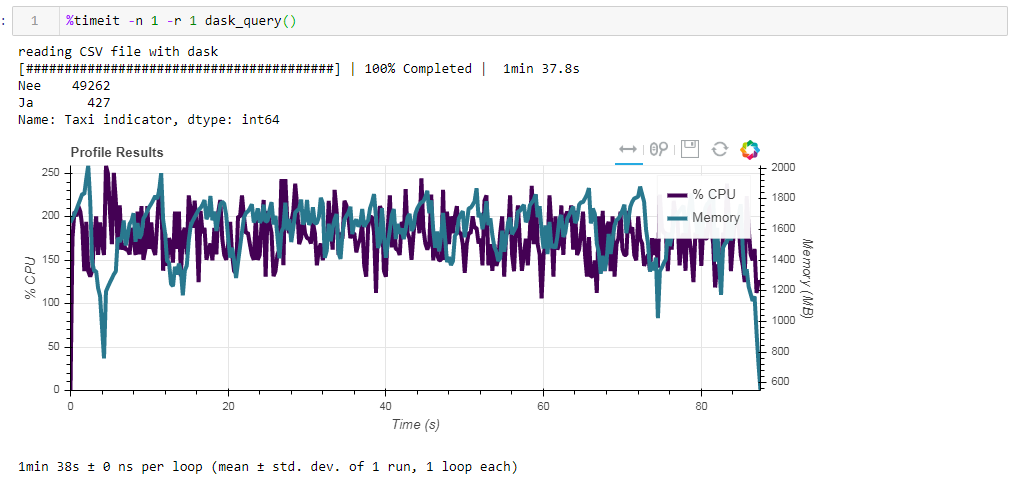 الآن قم بتغذية ملف الباركيه غير المحسن. تمت معالجة الطلب في حوالي 54 ثانية ، واستهلك 1388 ميجابايت من الذاكرة ، وصار الملف نفسه للطلب أصغر بعشر مرات (حوالي 700 ميجابايت). هنا المكافآت مرئية بالفعل محدبة. استخدام وحدة المعالجة المركزية لمئات من المئة هو موازاة عبر عدة نوى.
الآن قم بتغذية ملف الباركيه غير المحسن. تمت معالجة الطلب في حوالي 54 ثانية ، واستهلك 1388 ميجابايت من الذاكرة ، وصار الملف نفسه للطلب أصغر بعشر مرات (حوالي 700 ميجابايت). هنا المكافآت مرئية بالفعل محدبة. استخدام وحدة المعالجة المركزية لمئات من المئة هو موازاة عبر عدة نوى.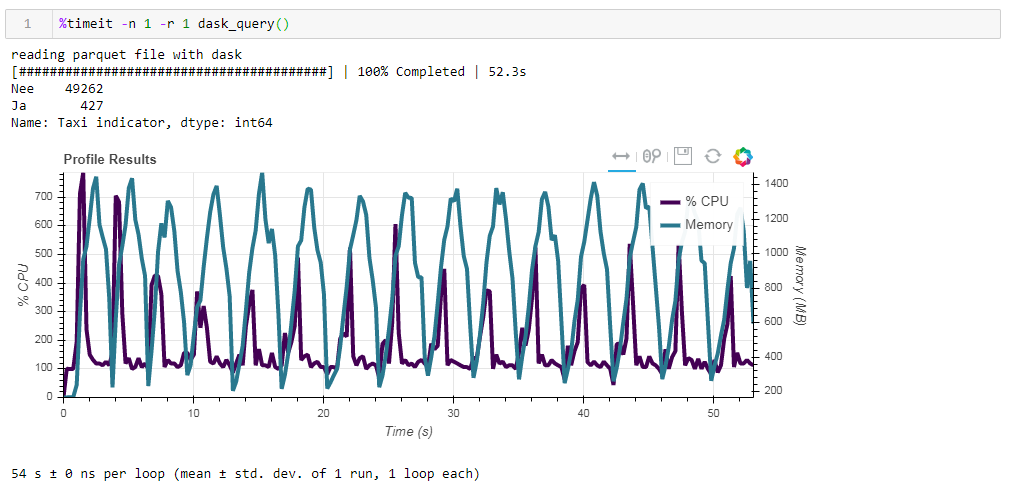 الباركيه المحسّن سابقًا مع أنواع البيانات المعدلة قليلاً في شكل مضغوط هو 1 ميغابايت فقط أقل ، مما يعني أنه بدون تلميحات يتم ضغط كل شيء بكفاءة. كما أن الزيادة في الإنتاجية ليست كبيرة بشكل خاص. يستغرق الطلب نفس 53 ثانية ويأكل ذاكرة أقل بقليل - 1332 ميجابايت.بعد نتائج تماريننا نستطيع أن نقول ما يلي:
الباركيه المحسّن سابقًا مع أنواع البيانات المعدلة قليلاً في شكل مضغوط هو 1 ميغابايت فقط أقل ، مما يعني أنه بدون تلميحات يتم ضغط كل شيء بكفاءة. كما أن الزيادة في الإنتاجية ليست كبيرة بشكل خاص. يستغرق الطلب نفس 53 ثانية ويأكل ذاكرة أقل بقليل - 1332 ميجابايت.بعد نتائج تماريننا نستطيع أن نقول ما يلي:- إذا كانت بياناتك "دهنية" وكنت معتادًا على منحدر - ستساعد القطع الصغيرة المنحدر على هضم هذا الحجم ، فستكون السرعة محتملة.
- إذا كنت ترغب في الضغط بسرعة أكبر ، وفر مساحة أثناء التخزين ولا تتراجع باستخدام منحدر ، فإن الغسق مع الباركيه هو مزيج جيد.
أخيرا ، حول الحوسبة البطيئة. واحدة من ميزات dask هي أنها تستخدم حسابات كسولة ، أي أن الحسابات لا يتم تنفيذها على الفور كما تم العثور عليها في التعليمات البرمجية ، ولكن عندما تكون هناك حاجة إليها حقًا أو عندما تطلبها صراحة باستخدام طريقة الحساب. على سبيل المثال ، في دالتنا ، لا يقرأ dask جميع البيانات في الذاكرة عندما نشير إلى قراءة الملف. يقرأها لاحقًا ، فقط تلك الأعمدة التي تتعلق بالطلب.يمكن مشاهدة ذلك بسهولة في المثال التالي. نأخذ ملفًا تمت تصفيته مسبقًا تركنا فيه 12 عمودًا فقط من 64 ، الباركيه المضغوط المضغوط يأخذ 203 ميغابايت. إذا قمت بتشغيل طلبنا المعتاد عليه ، فسيتم إكماله في 8.8 ثانية ، وسيبلغ ذروة استخدام الذاكرة حوالي 300 ميجابايت ، وهو ما يعادل عشر الملف المضغوط إذا تجاوزته في ملف csv بسيط.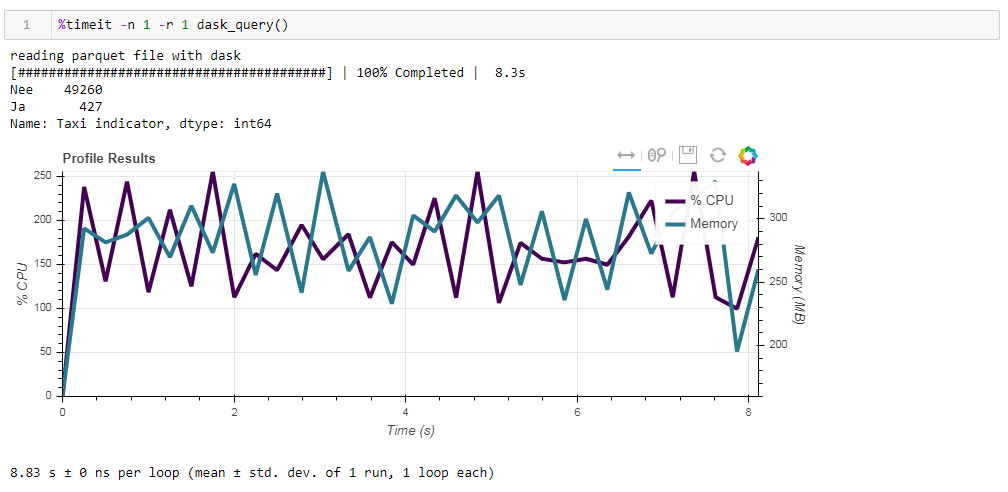 إذا طلبنا صراحة منك قراءة الملف ، ثم تنفيذ الطلب ، فسيكون استهلاك الذاكرة أكثر من 10 مرات تقريبًا. نقوم بتعديل وظيفتنا بشكل طفيف من خلال قراءة الملف بشكل صريح:
إذا طلبنا صراحة منك قراءة الملف ، ثم تنفيذ الطلب ، فسيكون استهلاك الذاكرة أكثر من 10 مرات تقريبًا. نقوم بتعديل وظيفتنا بشكل طفيف من خلال قراءة الملف بشكل صريح:def dask_query():
print('reading parquet file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_parquet('C:\Open_data\RDW_filtered.parquet' ).compute()
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts())
rprof.visualize()
وهذا ما نحصل عليه ، 10.5 ثانية و 3568 ميجا بايت من الذاكرة (!)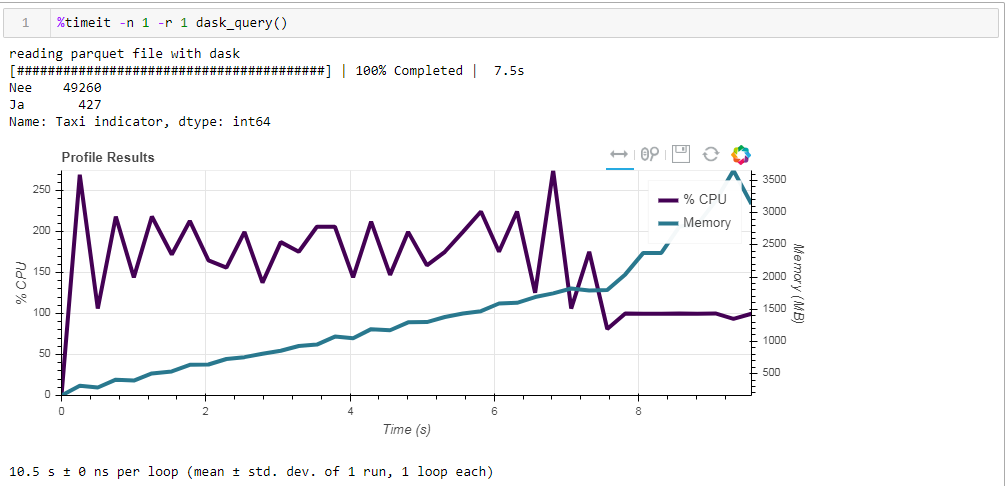 مرة أخرى نحن مقتنعون بأن الداسك - إنها قادرة على التعامل مع مهامها نفسها ، ومرة أخرى التسلق إليها مع الإدارة الدقيقة لا معنى له.
مرة أخرى نحن مقتنعون بأن الداسك - إنها قادرة على التعامل مع مهامها نفسها ، ومرة أخرى التسلق إليها مع الإدارة الدقيقة لا معنى له.