Kafka Streams هي مكتبة جافا لتحليل ومعالجة البيانات المخزنة في Apache Kafka. كما هو الحال مع أي نظام أساسي آخر لمعالجة الدفق ، فهي قادرة على إجراء معالجة البيانات مع و / أو بدون الحفاظ على الحالة في الوقت الحقيقي. في هذا المنشور ، سأحاول أن أصف لماذا يمثل تحقيق التوافر العالي (99.99٪) مشكلة في تيارات كافكا وما يمكننا القيام به لتحقيق ذلك.ماذا نحتاج ان نعرف
قبل وصف المشكلة والحلول الممكنة ، دعونا نلقي نظرة على المفاهيم الأساسية لتدفقات كافكا. إذا كنت قد عملت مع واجهات برمجة تطبيقات Kafka للمستهلكين / المنتجين ، فإن معظم هذه النماذج مألوفة لك. في الأقسام التالية ، سأحاول أن أصف ببضع كلمات تخزين البيانات في أقسام ، وإعادة التوازن بين مجموعات المستهلكين وكيف تتناسب المفاهيم الأساسية لعملاء كافكا مع مكتبة كافكا ستريمز.كافكا: تقسيم البيانات
في عالم كافكا ، ترسل تطبيقات المنتج البيانات كأزواج ذات قيمة رئيسية لموضوع معين. ينقسم الموضوع نفسه إلى قسم واحد أو أكثر في وسطاء كافكا. يستخدم Kafka مفتاح رسالة للإشارة إلى القسم الذي يجب كتابة البيانات فيه. وبالتالي ، دائمًا ما تنتهي الرسائل ذات المفتاح نفسه في نفس القسم.يتم تنظيم تطبيقات المستهلك في مجموعات المستهلكين ، ويمكن أن تحتوي كل مجموعة على مثيل واحد أو أكثر من المستهلكين.كل مثيل للمستهلك في مجموعة المستهلكين مسؤول عن معالجة البيانات من مجموعة فريدة من أقسام موضوع الإدخال.
تُعد مثيلات المستهلك في الأساس وسيلة لتوسيع نطاق المعالجة في مجموعة المستهلكين الخاصة بك.كافكا: إعادة التوازن لمجموعة المستهلكين
كما قلنا سابقًا ، يتلقى كل مثيل من مجموعة المستهلكين مجموعة من الأقسام الفريدة التي تستهلك منها البيانات. عندما ينضم مستهلك جديد إلى مجموعة ، يجب أن تتم إعادة التوازن حتى يحصل على قسم. يحدث الشيء نفسه عندما يموت المستهلك ، يجب أن يأخذ بقية المستهلك أقسامه لضمان معالجة جميع الأقسام.تيارات كافكا: تيارات
في بداية هذا المنشور ، تعرّفنا على حقيقة أن مكتبة Kafka Streams مبنية على أساس واجهات برمجة التطبيقات للمنتجين والمستهلكين ويتم تنظيم معالجة البيانات بنفس طريقة الحل القياسي على Kafka. في حقل كافكا ستريمز ، حقل application.id يساوي group.idفي واجهة برمجة تطبيقات المستهلك. يُنشئ Kafka Streams عددًا معينًا من سلاسل المحادثات ويقوم كل منها بمعالجة البيانات من قسم واحد أو أكثر من مواضيع الإدخال. يتحدث في مصطلحات واجهة برمجة تطبيقات المستهلك ، تتزامن التدفقات بشكل أساسي مع أمثلة المستهلك من نفس المجموعة. سلاسل المحادثات هي الطريقة الرئيسية لتوسيع نطاق معالجة البيانات في Kafka Streams ، ويمكن القيام بذلك عموديًا عن طريق زيادة عدد الخيوط لكل تطبيق Kafka Streams على جهاز واحد ، أو أفقيًا بإضافة جهاز إضافي بنفس التطبيق .id.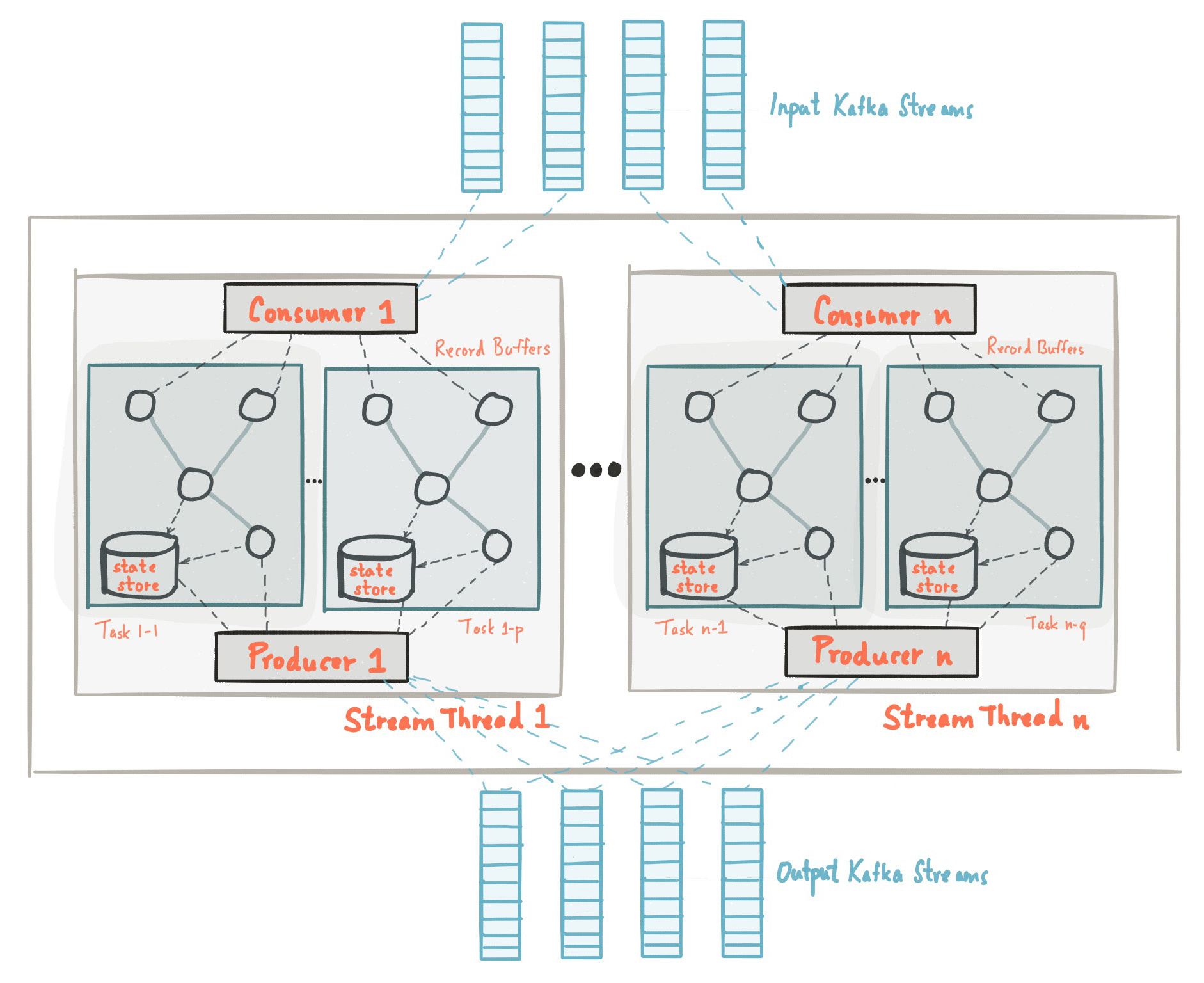 المصدر: kafka.apache.org/21/documentation/streams/arch architectureهناك العديد من العناصر في تيارات كافكا ، مثل المهام ومعالجة الهيكل ونموذج الترابط وما إلى ذلك ، والتي لن نناقشها في هذا المنشور. يمكن العثور على مزيد من المعلومات هنا.
المصدر: kafka.apache.org/21/documentation/streams/arch architectureهناك العديد من العناصر في تيارات كافكا ، مثل المهام ومعالجة الهيكل ونموذج الترابط وما إلى ذلك ، والتي لن نناقشها في هذا المنشور. يمكن العثور على مزيد من المعلومات هنا.تيارات كافكا: تخزين الدولة
في معالجة الدفق ، هناك عمليات مع الحفاظ على الدولة وبدونها. الحالة هي ما يسمح للتطبيق بتذكر المعلومات الضرورية التي تتجاوز نطاق السجل الذي تتم معالجته حاليًا.عمليات الدولة ، مثل الحساب ، أي نوع من التجميع ، الصلات ، إلخ ، أكثر تعقيدًا. ويرجع ذلك إلى حقيقة أن وجود سجل واحد فقط ، لا يمكنك تحديد الحالة الأخيرة (مثل العد) لمفتاح معين ، لذلك تحتاج إلى تخزين حالة التدفق الخاص بك في التطبيق الخاص بك. كما ناقشنا سابقًا ، يعالج كل مؤشر ترابط مجموعة من الأقسام الفريدة ؛ وبالتالي ، يعالج مؤشر الترابط مجموعة فرعية فقط من مجموعة البيانات بأكملها. هذا يعني أن كل خيط تطبيق Kafka Streams بنفس التطبيق .id يحافظ على حالته المعزولة. لن ندخل في تفاصيل حول كيفية تشكيل الدولة في Kafka Streams ، ولكن من المهم أن نفهم أنه يتم استعادة الولاية باستخدام موضوع سجل التغيير ويتم حفظها ليس فقط على القرص المحلي ، ولكن أيضًا في Kafka Broker.يتم حفظ سجل التغييرات في الحالة في Kafka Broker كموضوع منفصل ليس فقط للتسامح مع الخطأ ، ولكن أيضًا بحيث يمكنك بسهولة نشر مثيلات جديدة من Kafka Streams باستخدام نفس التطبيق. نظرًا لأنه يتم تخزين الحالة كموضوع سجل التغيير من جانب الوسيط ، يمكن لمثيل جديد تحميل حالته الخاصة من هذا الموضوع.يمكن العثور على مزيد من المعلومات حول تخزين الدولة هنا .لماذا تعد مشكلة التوافر العالي مشكلة مع كافكا ستريمز؟
استعرضنا المفاهيم والمبادئ الأساسية لمعالجة البيانات مع Kafka Streams. الآن دعنا نحاول الجمع بين جميع الأجزاء معًا ونحلل سبب صعوبة الوصول إلى التوفر الكبير. من الأقسام السابقة ، يجب أن نتذكر:- تنقسم البيانات في موضوع كافكا إلى أقسام يتم توزيعها بين تيارات تيارات كافكا.
- تطبيقات Kafka Streams مع نفس التطبيق. في الواقع ، هي مجموعة واحدة من المستهلكين ، وكل سلسلة من خيوطها هي حالة منفصلة منفصلة للمستهلك.
- بالنسبة لعمليات الدولة ، يحافظ الخيط على حالته الخاصة ، والتي "محفوظة" من قبل موضوع كافكا في شكل سجل التغيير.
- , Kafka , .
TransferWise SPaaS (Stream Processing as a Service)
قبل تسليط الضوء على جوهر هذا المنشور ، دعني أخبرك أولاً بما قمنا بإنشائه في TransferWise ولماذا يعد التوفر العالي أمرًا مهمًا للغاية بالنسبة لنا.في TransferWise ، لدينا العديد من العقد لمعالجة الدفق ، وتحتوي كل عقدة على عدة مثيلات من Streamka Streams لكل فريق منتج. تحتوي مثيلات Kafka Streams المصممة لفريق تطوير معين على تطبيق خاص. وعادةً ما تحتوي على أكثر من 5 سلاسل. بشكل عام ، عادةً ما تحتوي الفرق على 10-20 سلسلة (ما يعادل عدد حالات المستهلكين) في جميع أنحاء المجموعة. تستمع التطبيقات التي يتم نشرها على العقد حول موضوعات الإدخال وتقوم بتنفيذ عدة أنواع من العمليات مع بيانات الإدخال أو بدونها وتوفر تحديثات البيانات في الوقت الفعلي للخدمات الدقيقة اللاحقة.تحتاج فرق المنتج إلى تحديث البيانات المجمعة في الوقت الفعلي. يعد ذلك ضروريًا لتزويد عملائنا بالقدرة على تحويل الأموال على الفور. اتفاقية مستوى الخدمة المعتادة لدينا:في أي يوم معين ، يجب أن تتوفر 99.99٪ من البيانات المجمعة في أقل من 10 ثوانٍ.
لإعطائك فكرة ، أثناء اختبار الإجهاد ، تمكنت Kafka Streams من معالجة وتجميع 20،085 رسالة إدخال في الثانية. وهكذا ، بدا 10 ثوان من SLA تحت الحمل العادي قابلة للتحقيق تماما. لسوء الحظ ، لم يتم الوصول إلى اتفاقية مستوى الخدمة الخاصة بنا أثناء التحديث المستمر للعقد التي يتم نشر التطبيقات عليها ، وسأوضح أدناه سبب حدوث ذلك.تحديث العقدة المنزلقة
في TransferWise ، نحن نؤمن بشدة بالتوصيل المستمر لبرامجنا وعادةً ما نطلق إصدارات جديدة من خدماتنا بضع مرات في اليوم. دعنا نلقي نظرة على مثال لتحديث خدمة مستمر بسيط ونرى ما يحدث أثناء عملية الإصدار. مرة أخرى ، يجب أن نتذكر أن:- تنقسم البيانات في موضوع كافكا إلى أقسام يتم توزيعها بين تيارات تيارات كافكا.
- تطبيقات Kafka Streams مع نفس التطبيق. في الواقع ، هي مجموعة واحدة من المستهلكين ، وكل سلسلة من خيوطها هي حالة منفصلة منفصلة للمستهلك.
- بالنسبة لعمليات الدولة ، يحافظ الخيط على حالته الخاصة ، والتي "محفوظة" من قبل موضوع كافكا في شكل سجل التغيير.
- , Kafka , .
عادةً ما تستغرق عملية التحرير على عقدة واحدة من 8 إلى 9 ثوانٍ. أثناء الإصدار ، حالات "تيار كافكا" على العقدة "تعيد التشغيل برفق". وبالتالي ، بالنسبة للعقدة المفردة ، فإن الوقت المطلوب لإعادة تشغيل الخدمة بشكل صحيح هو ما يقرب من ثماني إلى تسع ثوان. من الواضح أن إغلاق مثيل كافكا ستريمز على عقدة يسبب إعادة التوازن لمجموعة المستهلكين. نظرًا لأن البيانات مقسمة ، يجب توزيع جميع الأقسام التي تنتمي إلى مثيل قابل للتمهيد بين تطبيقات Kafka Streams النشطة بنفس التطبيق. ينطبق هذا أيضًا على البيانات المجمعة التي تم حفظها على القرص. حتى تكتمل هذه العملية ، لن تتم معالجة البيانات.نسخ احتياطية
لتقليل وقت إعادة التوازن لتطبيقات Kafka Streams ، هناك مفهوم النسخ المتماثلة الاحتياطية ، التي تم تعريفها في التكوين على أنها num.standby.replicas. النسخ الاحتياطية هي نسخ من متجر الولاية المحلي. تجعل هذه الآلية من الممكن تكرار مخزن الدولة من مثيل واحد من تيارات كافكا إلى أخرى. عندما يموت خيط تيار كافكا لأي سبب ، يمكن تقليل مدة عملية استرداد الحالة إلى أدنى حد. لسوء الحظ ، للأسباب التي سأوضحها أدناه ، حتى النسخ المتماثلة الاحتياطية لن تساعد في تحديث الخدمة المتداول.لنفترض أن لدينا حالتين من تيارات كافكا على جهازين مختلفين: العقدة أ والعقدة ب. لكل حالة من مثيلات Kafka Streams ، يشار إلى num.standby.replicas = 1 في هذه العقدتين. باستخدام هذا التكوين ، يحتفظ كل مثيل من أحداث Streamka بنسخته الخاصة من المستودع على عقدة أخرى. أثناء التحديث المستمر ، لدينا الحالة التالية:- تم نشر الإصدار الجديد من الخدمة إلى العقدة a.
- تم تعطيل مثيل Kafka Streams على العقدة-أ.
- بدأت إعادة التوازن.
- تم بالفعل نسخ المستودع من العقدة-أ إلى العقدة-ب ، حيث حددنا التكوين num.standby.replicas = 1.
- العقدة-ب لديها بالفعل نسخة مظللة من العقدة-أ ، لذلك تحدث عملية إعادة التوازن على الفور تقريبًا.
- العقدة - a تبدأ مرة أخرى.
- العقدة - أ تنضم إلى مجموعة من المستهلكين.
- يرى وسيط كافكا مثالاً جديدًا على تيارات كافكا ويبدأ إعادة التوازن.
كما نرى ، يساعد num.standby.replicas فقط في سيناريوهات الإغلاق الكامل للعقدة. هذا يعني أنه في حالة تعطل العقدة-أ ، يمكن أن تستمر العقدة-ب في العمل بشكل صحيح على الفور تقريبًا. ولكن في حالة تحديث متجدد ، بعد قطع الاتصال ، ستنضم العقدة-أ إلى المجموعة مرة أخرى ، وستؤدي هذه الخطوة الأخيرة إلى إعادة التوازن. عندما تنضم العقدة-أ إلى مجموعة المستهلكين بعد إعادة التشغيل ، سيتم اعتبارها مثالاً جديدًا للمستهلك. مرة أخرى ، يجب أن نتذكر أن معالجة البيانات في الوقت الحقيقي تتوقف حتى يستعيد مثيل جديد حالته من موضوع سجل التغيير.يرجى ملاحظة أن إعادة توازن الأقسام عند انضمام مثيل جديد إلى مجموعة لا تنطبق على واجهة برمجة تطبيقات Kafka Streams ، حيث أن هذه هي الطريقة التي يعمل بها بروتوكول مجموعة مستهلك Apache Kafka بالضبط.الإنجاز: التوفر العالي مع تيارات كافكا
على الرغم من حقيقة أن مكتبات عملاء كافكا لا توفر وظائف مضمنة للمشكلة المذكورة أعلاه ، إلا أن هناك بعض الحيل التي يمكن استخدامها لتحقيق توافر عالي للكتلة أثناء التحديث المستمر. تظل الفكرة الكامنة وراء النسخ الاحتياطية صالحة ، وامتلاك آلات النسخ الاحتياطي عندما يحين الوقت هو حل جيد نستخدمه لضمان التوفر العالي في حالة فشل المثيل.كانت المشكلة في الإعداد الأولي لدينا أنه لدينا مجموعة واحدة من المستهلكين لجميع الفرق على جميع العقد. الآن ، بدلاً من مجموعة واحدة من المستهلكين ، لدينا اثنان ، والثاني يعمل كمجموعة "ساخنة". في العقد ، تحتوي العقد على متغير خاص CLUSTER_ID ، والذي تتم إضافته إلى application.id في حالات Kafka Streams. فيما يلي عينة لتكوين application.yml Boot Boot:application.ymlspring.profiles: production
streaming-pipelines:
team-a-stream-app-id: "${CLUSTER_ID}-team-a-stream-app"
team-b-stream-app-id: "${CLUSTER_ID}-team-b-stream-app"
عند نقطة زمنية واحدة ، توجد مجموعة واحدة فقط في الوضع النشط ، على التوالي ، لا تقوم مجموعة النسخ الاحتياطي بإرسال رسائل في الوقت الفعلي إلى الخدمات المصغرة. أثناء إصدار الإصدار ، تصبح مجموعة النسخ الاحتياطي نشطة ، مما يسمح بتحديث متجدد على المجموعة الأولى. نظرًا لأن هذه مجموعة مختلفة تمامًا من المستهلكين ، فإن عملائنا لا يلاحظون حتى أي انتهاكات في المعالجة ، وتستمر الخدمات اللاحقة في تلقي الرسائل من المجموعة النشطة حديثًا. إحدى العيوب الواضحة لاستخدام مجموعة احتياطية من المستهلكين هي النفقات العامة الإضافية واستهلاك الموارد ، ولكن ، مع ذلك ، توفر هذه البنية ضمانات إضافية وتحكمًا وتسامحًا مع الأخطاء في نظام معالجة التدفق لدينا.بالإضافة إلى إضافة مجموعة إضافية ، هناك أيضًا حيل يمكن أن تخفف من المشكلة مع إعادة التوازن المتكررة.زيادة المجموعة. الأولية. إعادة التوازن. تأخير. ms
بدءًا من Kafka 0.11.0.0 ، تمت إضافة مجموعة التكوين. initial.rebalance.delay.ms. وفقًا للوثائق ، فإن هذا الإعداد مسؤول عن:مقدار الوقت بالمللي ثانية الذي سيؤخره GroupCoordinator لإعادة التوازن المبدئي لمستهلك المجموعة.
على سبيل المثال ، إذا قمنا بتعيين 60،000 مللي ثانية في هذا الإعداد ، فمع التحديث المتدرج ، قد يكون لدينا نافذة دقيقة لإصدار الإصدار. إذا تمت إعادة تشغيل مثيل تيارات كافكا بنجاح في هذه النافذة الزمنية ، فلن يتم استدعاء إعادة التوازن. يرجى ملاحظة أن البيانات التي كان مثيل Kafka Streams المعاد تشغيله مسؤولاً عنه ستظل غير متاحة حتى تعود العقدة إلى وضع الاتصال. على سبيل المثال ، إذا كانت إعادة تشغيل مثيل تستغرق حوالي ثماني ثوانٍ ، فسيكون لديك ثماني ثوانٍ من وقت التعطل للبيانات المسؤولة عن هذا المثيل.وتجدر الإشارة إلى أن العيب الرئيسي لهذا المفهوم هو أنه في حالة فشل العقدة ، ستتلقى تأخيرًا إضافيًا لمدة دقيقة واحدة أثناء الاستعادة ، مع مراعاة التكوين الحالي.تقليص حجم المقطع في مواضيع سجل التغيير
يرجع التأخير الكبير في إعادة توازن كافكا ستريم إلى استعادة متاجر الدولة من مواضيع سجل التغيير. مواضيع سجل التغيير عبارة عن موضوعات مضغوطة ، مما يسمح لك بتخزين أحدث سجل لمفتاح معين في الموضوع. سأذكر بإيجاز هذا المفهوم أدناه.يتم تنظيم المواضيع في Kafka Broker في قطاعات. عندما يصل المقطع إلى حجم العتبة المكونة ، يتم إنشاء مقطع جديد وضغط الجزء السابق. بشكل افتراضي ، يتم تعيين هذا الحد إلى 1 غيغابايت. كما تعلم ، فإن بنية البيانات الرئيسية التي تستند إليها موضوعات Kafka وأقسامها هي بنية السجل مع كتابة أمامية ، أي عندما يتم إرسال الرسائل إلى الموضوع ، يتم إضافتها دائمًا إلى الجزء "النشط" الأخير ، ولا يتم الضغط يحدث.ولذلك ، فإن معظم حالات التخزين المخزنة في سجل التغيير تكون دائمًا في ملف "الجزء النشط" ولا يتم ضغطها مطلقًا ، مما يؤدي إلى ملايين رسائل التغيير غير المضغوطة. بالنسبة إلى Kafka Streams ، هذا يعني أنه أثناء إعادة التوازن ، عندما يستعيد مثيل Kafka Streams حالته من موضوع التغيير ، فإنه يحتاج إلى قراءة الكثير من الإدخالات الزائدة من موضوع التغيير. بالنظر إلى أن مخازن الولاية تهتم فقط بالحالة الأخيرة ، وليس بالتاريخ ، فإن وقت المعالجة هذا يضيع. سيؤدي تقليل حجم المقطع إلى ضغط أكثر قوة للبيانات ، لذا يمكن لحالات جديدة من تطبيقات Kafka Streams التعافي بشكل أسرع.استنتاج
على الرغم من أن Kafka Streams لا يوفر قدرة مدمجة لتوفير إمكانية توفر عالية أثناء تحديث الخدمة المتدحرجة ، إلا أنه لا يزال من الممكن القيام بذلك على مستوى البنية التحتية. يجب أن نتذكر أن Kafka Streams ليس "إطار عمل عنقودي" بخلاف Apache Flink أو Apache Spark. إنها مكتبة Java خفيفة الوزن تسمح للمطورين بإنشاء تطبيقات قابلة للتطوير لتدفق البيانات. على الرغم من ذلك ، فإنه يوفر لبنات البناء الضرورية لتحقيق أهداف التدفق الطموحة مثل توفر "99.99٪".