لدى متخصصي معالجة البيانات وتحليلها العديد من الأدوات لإنشاء نماذج التصنيف. واحدة من أكثر الطرق شعبية وموثوقة لتطوير مثل هذه النماذج هي استخدام خوارزمية Random Forest (RF). من أجل محاولة تحسين أداء نموذج تم إنشاؤه باستخدام خوارزمية RF ، يمكنك استخدام أمثلية المعلمة الفائقة للموديل ( Hyperparameter Tuning ، HT). بالإضافة إلى ذلك ، هناك نهج واسع الانتشار يتم من خلاله معالجة البيانات ، قبل نقلها إلى النموذج ، باستخدام تحليل المكون الرئيسي ، PCA). ولكن هل يستحق استخدامه؟ أليس الغرض الأساسي من خوارزمية التردد اللاسلكي هو مساعدة المحلل على تفسير أهمية السمات؟نعم ، يمكن أن يؤدي استخدام خوارزمية PCA إلى تعقيد طفيف في تفسير كل "ميزة" في تحليل "أهمية الميزات" لنموذج RF. ومع ذلك ، تقلل خوارزمية PCA بُعد مساحة الميزة ، مما قد يؤدي إلى انخفاض عدد الميزات التي تحتاج إلى معالجتها بواسطة نموذج RF. يرجى ملاحظة أن حجم الحسابات هو أحد العيوب الرئيسية لخوارزمية الغابة العشوائية (أي أنه يمكن أن يستغرق وقتًا طويلاً لإكمال النموذج). يمكن أن يكون تطبيق خوارزمية PCA جزءًا مهمًا جدًا من النمذجة ، خاصة في الحالات التي تعمل فيها مع مئات أو حتى آلاف الميزات. ونتيجة لذلك ، إذا كان الشيء الأكثر أهمية هو ببساطة إنشاء النموذج الأكثر فاعلية ، وفي الوقت نفسه يمكنك التضحية بدقة تحديد أهمية السمات ، فإن PCA قد يستحق المحاولة.الآن إلى النقطة. سنعمل مع مجموعة بيانات لسرطان الثدي - Scikit-Learn "سرطان الثدي" . سنقوم بإنشاء ثلاثة نماذج ومقارنة فعاليتها. وبالتحديد نتحدث عن النماذج التالية:
، PCA). ولكن هل يستحق استخدامه؟ أليس الغرض الأساسي من خوارزمية التردد اللاسلكي هو مساعدة المحلل على تفسير أهمية السمات؟نعم ، يمكن أن يؤدي استخدام خوارزمية PCA إلى تعقيد طفيف في تفسير كل "ميزة" في تحليل "أهمية الميزات" لنموذج RF. ومع ذلك ، تقلل خوارزمية PCA بُعد مساحة الميزة ، مما قد يؤدي إلى انخفاض عدد الميزات التي تحتاج إلى معالجتها بواسطة نموذج RF. يرجى ملاحظة أن حجم الحسابات هو أحد العيوب الرئيسية لخوارزمية الغابة العشوائية (أي أنه يمكن أن يستغرق وقتًا طويلاً لإكمال النموذج). يمكن أن يكون تطبيق خوارزمية PCA جزءًا مهمًا جدًا من النمذجة ، خاصة في الحالات التي تعمل فيها مع مئات أو حتى آلاف الميزات. ونتيجة لذلك ، إذا كان الشيء الأكثر أهمية هو ببساطة إنشاء النموذج الأكثر فاعلية ، وفي الوقت نفسه يمكنك التضحية بدقة تحديد أهمية السمات ، فإن PCA قد يستحق المحاولة.الآن إلى النقطة. سنعمل مع مجموعة بيانات لسرطان الثدي - Scikit-Learn "سرطان الثدي" . سنقوم بإنشاء ثلاثة نماذج ومقارنة فعاليتها. وبالتحديد نتحدث عن النماذج التالية:- النموذج الأساسي القائم على خوارزمية RF (سنختصر هذا النموذج RF).
- نفس النموذج مثل رقم 1 ، ولكن نموذجًا يتم فيه تطبيق تقليل أبعاد مساحة الميزة باستخدام طريقة المكون الرئيسي (RF + PCA).
- نفس النموذج مثل رقم 2 ، ولكن تم إنشاؤه باستخدام تحسين المعلمات الفائقة (RF + PCA + HT).
1. استيراد البيانات
للبدء ، قم بتحميل البيانات وقم بإنشاء Patas dataframe. نظرًا لأننا نستخدم مجموعة بيانات "لعبة" تم مسحها مسبقًا من Scikit-Learn ، يمكننا بعد ذلك بدء عملية النمذجة بالفعل. ولكن حتى عند استخدام هذه البيانات ، يوصى بأن تبدأ العمل دائمًا بإجراء تحليل أولي للبيانات باستخدام الأوامر التالية المطبقة على إطار البيانات ( df):df.head() - لإلقاء نظرة على إطار البيانات الجديد ومعرفة ما إذا كان يبدو كما هو متوقع.df.info()- لمعرفة خصائص أنواع البيانات ومحتويات الأعمدة. قد يكون من الضروري إجراء تحويل نوع البيانات قبل المتابعة.df.isna()- للتأكد من عدم وجود قيم في البيانات NaN. قد يلزم معالجة القيم المقابلة ، إن وجدت ، بطريقة أو بأخرى ، أو ، إذا لزم الأمر ، قد يكون من الضروري إزالة صفوف كاملة من إطار البيانات.df.describe() - لمعرفة قيم الحد الأدنى والحد الأقصى والمتوسط للمؤشرات في الأعمدة ، لمعرفة مؤشرات متوسط مربع والانحراف المحتمل في الأعمدة.
في مجموعة البيانات الخاصة بنا ، يمثل العمود cancer(السرطان) المتغير المستهدف الذي نريد توقع قيمته باستخدام النموذج. 0يعني "لا مرض". 1- "وجود المرض".import pandas as pd
from sklearn.datasets import load_breast_cancer
columns = ['mean radius', 'mean texture', 'mean perimeter', 'mean area', 'mean smoothness', 'mean compactness', 'mean concavity', 'mean concave points', 'mean symmetry', 'mean fractal dimension', 'radius error', 'texture error', 'perimeter error', 'area error', 'smoothness error', 'compactness error', 'concavity error', 'concave points error', 'symmetry error', 'fractal dimension error', 'worst radius', 'worst texture', 'worst perimeter', 'worst area', 'worst smoothness', 'worst compactness', 'worst concavity', 'worst concave points', 'worst symmetry', 'worst fractal dimension']
dataset = load_breast_cancer()
data = pd.DataFrame(dataset['data'], columns=columns)
data['cancer'] = dataset['target']
display(data.head())
display(data.info())
display(data.isna().sum())
display(data.describe())
. . , cancer, , . 0 « ». 1 — « »2.
الآن قم بتقسيم البيانات باستخدام وظيفة Scikit-Learn train_test_split. نريد أن نعطي النموذج أكبر قدر ممكن من بيانات التدريب. ومع ذلك ، نحتاج إلى وجود بيانات كافية تحت تصرفنا لاختبار النموذج. بشكل عام ، يمكننا القول أنه مع زيادة عدد الصفوف في مجموعة البيانات ، يزداد أيضًا مقدار البيانات التي يمكن اعتبارها تعليمية.على سبيل المثال ، إذا كان هناك ملايين الخطوط ، يمكنك تقسيم المجموعة من خلال تمييز 90٪ من خطوط بيانات التدريب و 10٪ لبيانات الاختبار. لكن مجموعة بيانات الاختبار تحتوي على 569 صفًا فقط. وهذا ليس كثيرًا للتدريب واختبار النموذج. ونتيجة لذلك ، لكي نكون منصفين فيما يتعلق ببيانات التدريب والتحقق ، سنقسم المجموعة إلى جزأين متساويين - 50٪ - بيانات التدريب و 50٪ - بيانات التحقق. نقوم بتثبيتstratify=y للتأكد من أن كل من مجموعات بيانات التدريب والاختبار لها نفس نسبة 0 و 1 مثل مجموعة البيانات الأصلية.from sklearn.model_selection import train_test_split
X = data.drop('cancer', axis=1)
y = data['cancer']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.50, random_state = 2020, stratify=y)
3. تحجيم البيانات
قبل الشروع في النمذجة ، تحتاج إلى "توسيط" و "توحيد" البيانات عن طريق تحجيمها . يتم إجراء القياس بسبب حقيقة أنه يتم التعبير عن الكميات المختلفة بوحدات مختلفة. يسمح لك هذا الإجراء بتنظيم "معركة عادلة" بين العلامات في تحديد أهميتها. بالإضافة إلى ذلك ، نقوم بالتحويل y_trainمن نوع بيانات Pandas Seriesإلى صفيف NumPy بحيث يمكن للنموذج لاحقًا العمل مع الأهداف المقابلة.import numpy as np
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
X_train_scaled = ss.fit_transform(X_train)
X_test_scaled = ss.transform(X_test)
y_train = np.array(y_train)
4. تدريب النموذج الأساسي (نموذج رقم 1 ، RF)
الآن إنشاء نموذج رقم 1. في ذلك ، نتذكر أنه يتم استخدام خوارزمية الغابة العشوائية فقط. يستخدم جميع الميزات ويتم تكوينه باستخدام القيم الافتراضية (يمكن العثور على تفاصيل حول هذه الإعدادات في وثائق sklearn.ensemble.RandomForestClassifier ). تهيئة النموذج. بعد ذلك ، سوف نقوم بتدريبها على البيانات المتدرجة. يمكن قياس دقة النموذج على بيانات التدريب:from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import recall_score
rfc = RandomForestClassifier()
rfc.fit(X_train_scaled, y_train)
display(rfc.score(X_train_scaled, y_train))
إذا كنا مهتمين بمعرفة الميزات الأكثر أهمية لنموذج RF في التنبؤ بسرطان الثدي ، فيمكننا تصور وتحديد مؤشرات أهمية العلامات من خلال الإشارة إلى السمة feature_importances_:feats = {}
for feature, importance in zip(data.columns, rfc_1.feature_importances_):
feats[feature] = importance
importances = pd.DataFrame.from_dict(feats, orient='index').rename(columns={0: 'Gini-Importance'})
importances = importances.sort_values(by='Gini-Importance', ascending=False)
importances = importances.reset_index()
importances = importances.rename(columns={'index': 'Features'})
sns.set(font_scale = 5)
sns.set(style="whitegrid", color_codes=True, font_scale = 1.7)
fig, ax = plt.subplots()
fig.set_size_inches(30,15)
sns.barplot(x=importances['Gini-Importance'], y=importances['Features'], data=importances, color='skyblue')
plt.xlabel('Importance', fontsize=25, weight = 'bold')
plt.ylabel('Features', fontsize=25, weight = 'bold')
plt.title('Feature Importance', fontsize=25, weight = 'bold')
display(plt.show())
display(importances)
تصور "أهمية" العلاماتمؤشرات الدلالة5. طريقة المكونات الرئيسية
الآن دعونا نسأل كيف يمكننا تحسين نموذج RF الأساسي. باستخدام تقنية تقليل أبعاد مساحة الميزة ، من الممكن تقديم مجموعة البيانات الأولية من خلال متغيرات أقل وفي نفس الوقت تقليل كمية الموارد الحسابية اللازمة لضمان تشغيل النموذج. باستخدام PCA ، يمكنك دراسة تباين العينة التراكمي لهذه الميزات من أجل فهم الميزات التي تفسر معظم التباين في البيانات.نقوم بتهيئة كائن PCA ( pca_test) ، مع الإشارة إلى عدد المكونات (الميزات) التي يجب أخذها في الاعتبار. قمنا بتعيين هذا المؤشر إلى 30 من أجل رؤية التباين الموضح لجميع المكونات المولدة قبل اتخاذ قرار بشأن عدد المكونات التي نحتاجها. ثم ننتقل إلى pca_testالبيانات المقاسةX_trainباستخدام الطريقة pca_test.fit(). بعد ذلك نقوم بتصور البيانات.import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.decomposition import PCA
pca_test = PCA(n_components=30)
pca_test.fit(X_train_scaled)
sns.set(style='whitegrid')
plt.plot(np.cumsum(pca_test.explained_variance_ratio_))
plt.xlabel('number of components')
plt.ylabel('cumulative explained variance')
plt.axvline(linewidth=4, color='r', linestyle = '--', x=10, ymin=0, ymax=1)
display(plt.show())
evr = pca_test.explained_variance_ratio_
cvr = np.cumsum(pca_test.explained_variance_ratio_)
pca_df = pd.DataFrame()
pca_df['Cumulative Variance Ratio'] = cvr
pca_df['Explained Variance Ratio'] = evr
display(pca_df.head(10))
بعد أن تجاوز عدد المكونات المستخدمة 10 ، لا تؤدي الزيادة في عددها إلى زيادة التباين الموضح بشكل كبيريحتوي إطار البيانات هذا على مؤشرات مثل نسبة التباين التراكمي (الحجم التراكمي للتباين الموضح للبيانات) ونسبة التباين الموضحة (مساهمة كل مكون في الحجم الإجمالي للتباين الموضح)إذا نظرت إلى إطار البيانات أعلاه ، يتبين أن استخدام PCA للانتقال من 30 متغيرًا إلى 10 متغيرات إلى المكونات يسمح بشرح 95٪ من تشتت البيانات. تمثل المكونات 20 الأخرى أقل من 5 ٪ من التباين ، مما يعني أنه يمكننا رفضها. باتباع هذا المنطق ، نستخدم PCA لتقليل عدد المكونات من 30 إلى 10 لـX_trainوX_test. نكتب هذه مصطنع "خفض البعد" مجموعات البيانات فيX_train_scaled_pcaوX_test_scaled_pca.pca = PCA(n_components=10)
pca.fit(X_train_scaled)
X_train_scaled_pca = pca.transform(X_train_scaled)
X_test_scaled_pca = pca.transform(X_test_scaled)
كل مكون عبارة عن مجموعة خطية من متغيرات المصدر مع "الأوزان" المقابلة. يمكننا أن نرى هذه "الأوزان" لكل مكون من خلال إنشاء إطار بيانات.pca_dims = []
for x in range(0, len(pca_df)):
pca_dims.append('PCA Component {}'.format(x))
pca_test_df = pd.DataFrame(pca_test.components_, columns=columns, index=pca_dims)
pca_test_df.head(10).T
عنصر بيانات معلومات المكون6. تدريب نموذج RF الأساسي بعد تطبيق طريقة المكونات الرئيسية على البيانات (النموذج رقم 2 ، RF + PCA)
الآن يمكننا أن تمر على لبيانات RF-نموذج أساسي آخر X_train_scaled_pcaو y_trainويمكن معرفة ما إذا كان هناك تحسن في دقة التوقعات الصادرة عن هذا النموذج.rfc = RandomForestClassifier()
rfc.fit(X_train_scaled_pca, y_train)
display(rfc.score(X_train_scaled_pca, y_train))
مقارنة النماذج أدناه.7. تحسين المعايير الفائقة. الجولة 1: البحث العشوائي
بعد معالجة البيانات باستخدام طريقة المكون الرئيسي ، يمكنك محاولة استخدام أمثلية المعلمات النموذجية من أجل تحسين جودة التنبؤات التي ينتجها نموذج RF. يمكن اعتبار المعايير الفائقة على أنها شيء مثل "إعدادات" النموذج. لن تعمل الإعدادات المثالية لمجموعة بيانات واحدة لمجموعة أخرى - ولهذا السبب تحتاج إلى تحسينها.يمكنك البدء باستخدام خوارزمية RandomizedSearchCV ، والتي تتيح لك استكشاف مجموعة كبيرة من القيم تقريبًا. يمكن العثور على أوصاف جميع المعاملات الفائقة لنماذج التردد اللاسلكي هنا .في سياق العمل ، نقوم بإنشاء كيان param_distيحتوي ، لكل معلمة مفرطة ، على مجموعة من القيم التي يجب اختبارها. بعد ذلك ، نقوم بتهيئة الكائن.rsباستخدام الوظيفة RandomizedSearchCV()، تمريرها في نموذج RF param_dist، وعدد التكرارات وعدد عمليات التحقق المتقاطع التي يتعين إجراؤها. تسمح لكالمعلمة الفائقة verboseبالتحكم في كمية المعلومات التي يعرضها النموذج أثناء تشغيله (مثل إخراج المعلومات أثناء تدريب النموذج). n_jobsيسمح لك hyperparameter بتحديد عدد نوى المعالج التي تحتاج إلى استخدامها لضمان تشغيل النموذج. تعيينها n_jobsإلى قيمة -1من شأنها أن تؤدي إلى نموذج أسرع، لأن هذا سوف نستخدم كل من نوى المعالج.سننخرط في اختيار المعايير الفائقة التالية:n_estimators - عدد "الأشجار" في "الغابة العشوائية".max_features - عدد الميزات لاختيار التقسيم.max_depth - أقصى عمق للأشجار.min_samples_split - الحد الأدنى من عدد العناصر اللازمة لتقسيم عقدة الشجرة.min_samples_leaf - الحد الأدنى من الأشياء في الأوراق.bootstrap - تستخدم لبناء أشجار عينة فرعية مع العودة.
from sklearn.model_selection import RandomizedSearchCV
n_estimators = [int(x) for x in np.linspace(start = 100, stop = 1000, num = 10)]
max_features = ['log2', 'sqrt']
max_depth = [int(x) for x in np.linspace(start = 1, stop = 15, num = 15)]
min_samples_split = [int(x) for x in np.linspace(start = 2, stop = 50, num = 10)]
min_samples_leaf = [int(x) for x in np.linspace(start = 2, stop = 50, num = 10)]
bootstrap = [True, False]
param_dist = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}
rs = RandomizedSearchCV(rfc_2,
param_dist,
n_iter = 100,
cv = 3,
verbose = 1,
n_jobs=-1,
random_state=0)
rs.fit(X_train_scaled_pca, y_train)
rs.best_params_
مع قيم المعلمات n_iter = 100و cv = 3، أنشأنا 300 نماذج RF، اختيار عشوائي مجموعات من فرط المعلمات الواردة أعلاه. يمكننا الرجوع إلى السمة best_params_ للحصول على معلومات حول مجموعة من المعلمات التي تسمح لك بإنشاء أفضل نموذج. ولكن في هذه المرحلة ، قد لا يعطينا هذا البيانات الأكثر إثارة للاهتمام حول نطاقات المعلمات التي تستحق استكشافها في الجولة التالية من التحسين. من أجل معرفة نطاق القيم الذي يستحق الاستمرار في البحث ، يمكننا بسهولة الحصول على إطار بيانات يحتوي على نتائج خوارزمية RandomizedSearchCV.rs_df = pd.DataFrame(rs.cv_results_).sort_values('rank_test_score').reset_index(drop=True)
rs_df = rs_df.drop([
'mean_fit_time',
'std_fit_time',
'mean_score_time',
'std_score_time',
'params',
'split0_test_score',
'split1_test_score',
'split2_test_score',
'std_test_score'],
axis=1)
rs_df.head(10)
نتائج خوارزمية RandomizedSearchCVالآن سنقوم بإنشاء رسوم بيانية عمودية ، على المحور X ، هي قيم المعلمات المفرطة ، وعلى المحور Y هي القيم المتوسطة التي تظهرها النماذج. سيجعل هذا من الممكن فهم قيم المعلمات المفرطة ، في المتوسط ، التي تظهر أفضل أداء لها.fig, axs = plt.subplots(ncols=3, nrows=2)
sns.set(style="whitegrid", color_codes=True, font_scale = 2)
fig.set_size_inches(30,25)
sns.barplot(x='param_n_estimators', y='mean_test_score', data=rs_df, ax=axs[0,0], color='lightgrey')
axs[0,0].set_ylim([.83,.93])axs[0,0].set_title(label = 'n_estimators', size=30, weight='bold')
sns.barplot(x='param_min_samples_split', y='mean_test_score', data=rs_df, ax=axs[0,1], color='coral')
axs[0,1].set_ylim([.85,.93])axs[0,1].set_title(label = 'min_samples_split', size=30, weight='bold')
sns.barplot(x='param_min_samples_leaf', y='mean_test_score', data=rs_df, ax=axs[0,2], color='lightgreen')
axs[0,2].set_ylim([.80,.93])axs[0,2].set_title(label = 'min_samples_leaf', size=30, weight='bold')
sns.barplot(x='param_max_features', y='mean_test_score', data=rs_df, ax=axs[1,0], color='wheat')
axs[1,0].set_ylim([.88,.92])axs[1,0].set_title(label = 'max_features', size=30, weight='bold')
sns.barplot(x='param_max_depth', y='mean_test_score', data=rs_df, ax=axs[1,1], color='lightpink')
axs[1,1].set_ylim([.80,.93])axs[1,1].set_title(label = 'max_depth', size=30, weight='bold')
sns.barplot(x='param_bootstrap',y='mean_test_score', data=rs_df, ax=axs[1,2], color='skyblue')
axs[1,2].set_ylim([.88,.92])
axs[1,2].set_title(label = 'bootstrap', size=30, weight='bold')
plt.show()
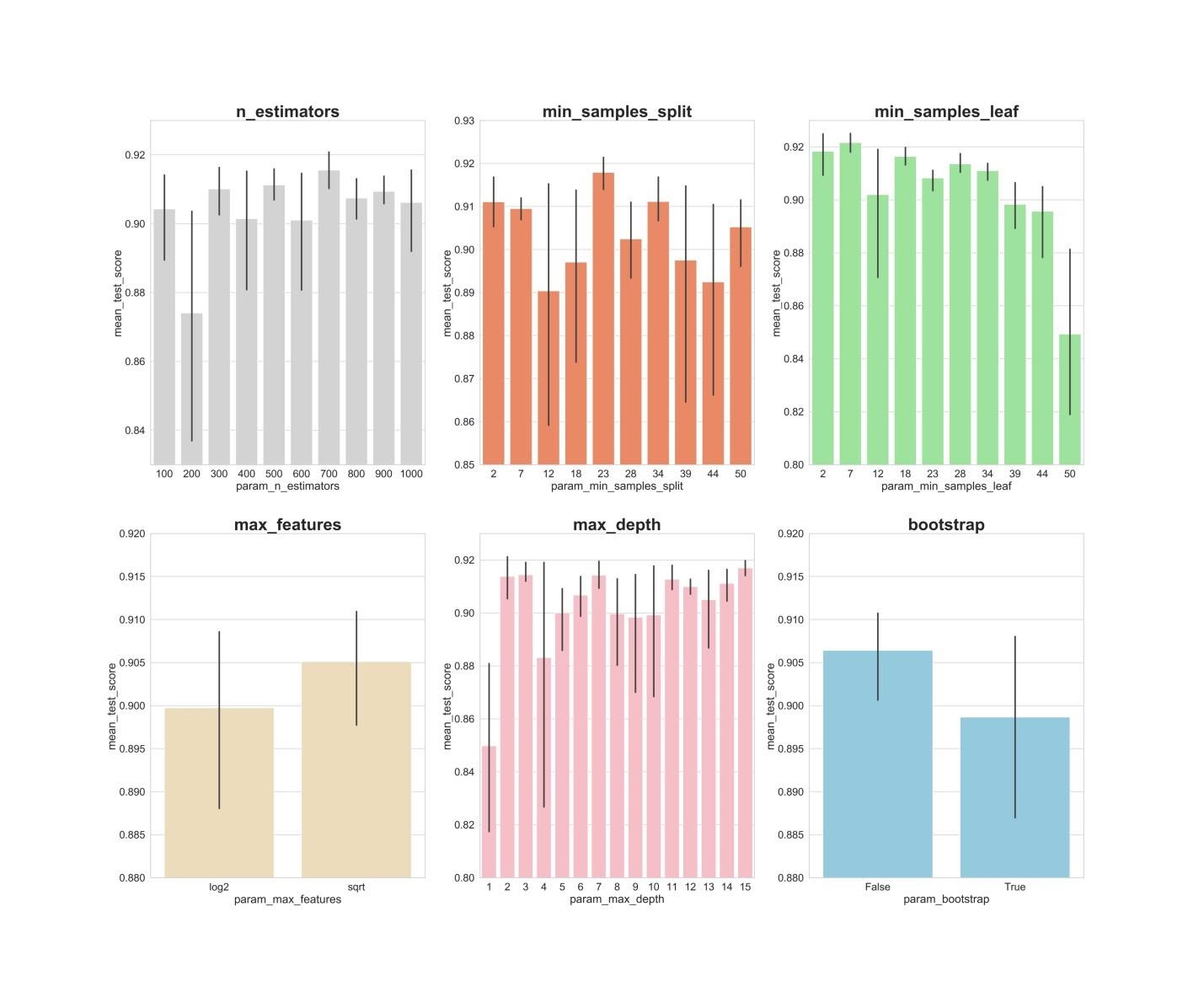
n_estimators: القيم 300 ، 500 ، 700 ، على ما يبدو ، تظهر أفضل متوسط النتائج.min_samples_split: يبدو أن القيم الصغيرة مثل 2 و 7 تظهر أفضل النتائج. تبدو القيمة 23 جيدة أيضًا. يمكنك فحص عدة قيم لهذا المعلمة الزائدة التي تزيد عن 2 ، بالإضافة إلى عدة قيم تبلغ حوالي 23.min_samples_leaf: هناك شعور بأن القيم الصغيرة لهذا الباراميتر تعطي نتائج أفضل. هذا يعني أنه يمكننا تجربة القيم بين 2 و 7.max_features: الخيار sqrtيعطي أعلى متوسط نتيجة.max_depth: لا توجد علاقة واضحة بين قيمة المعلمة المفرطة ونتائج النموذج ، ولكن هناك شعور بأن القيم 2 ، 3 ، 7 ، 11 ، 15 تبدو جيدة.bootstrap: Falseتظهر القيمة أفضل نتيجة متوسط.
الآن ، باستخدام هذه النتائج ، يمكننا الانتقال إلى الجولة الثانية من التحسين للمعلمات المفرطة. سيؤدي ذلك إلى تضييق نطاق القيم التي نهتم بها.8. تحسين المعايير الفائقة. الجولة 2: GridSearchCV (الإعداد النهائي لمعلمات النموذج رقم 3 ، RF + PCA + HT)
بعد تطبيق خوارزمية RandomizedSearchCV ، سنستخدم خوارزمية GridSearchCV لإجراء بحث أكثر دقة للحصول على أفضل تركيبة من المعلمات الفائقة. يتم فحص نفس المعلمات الزائدة هنا ، ولكننا نقوم الآن بإجراء بحث "أكثر شمولاً" عن أفضل تركيبة لها. باستخدام خوارزمية GridSearchCV ، يتم فحص كل مجموعة من المعلمات المفرطة. يتطلب هذا موارد حسابية أكثر بكثير من استخدام خوارزمية RandomizedSearchCV عندما نقوم بتعيين عدد عمليات تكرار البحث بشكل مستقل. على سبيل المثال ، يتطلب البحث عن 10 قيم لكل من 6 معلمات مفرطة مع التحقق المتقاطع في 3 مجموعات 10 × 3 أو 3،000،000 جلسة تدريب نموذجية. هذا هو السبب في أننا نستخدم خوارزمية GridSearchCV بعد ، بعد تطبيق RandomizedSearchCV ، قمنا بتضييق نطاقات قيم المعلمات المدروسة.لذا ، باستخدام ما اكتشفناه بمساعدة RandomizedSearchCV ، ندرس قيم المعلمات الفائقة التي أظهرت نفسها بشكل أفضل:from sklearn.model_selection import GridSearchCV
n_estimators = [300,500,700]
max_features = ['sqrt']
max_depth = [2,3,7,11,15]
min_samples_split = [2,3,4,22,23,24]
min_samples_leaf = [2,3,4,5,6,7]
bootstrap = [False]
param_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}
gs = GridSearchCV(rfc_2, param_grid, cv = 3, verbose = 1, n_jobs=-1)
gs.fit(X_train_scaled_pca, y_train)
rfc_3 = gs.best_estimator_
gs.best_params_
هنا نطبق التحقق المتقاطع في 3 كتل لجلسات تدريب نموذج 540 (3 × 1 × 5 × 6 × 6 × 1) ، والتي تعطي 1620 جلسة تدريب نموذج. والآن ، بعد أن استخدمنا RandomizedSearchCV و GridSearchCV ، يمكننا أن ننتقل إلى السمة best_params_لمعرفة قيم المعلمات المفرطة التي تسمح للنموذج بالعمل بشكل أفضل مع مجموعة البيانات قيد الدراسة (يمكن رؤية هذه القيم في أسفل كتلة التعليمات البرمجية السابقة) . يتم استخدام هذه المعلمات لإنشاء نموذج رقم 3.9. تقييم جودة النماذج على بيانات التحقق
الآن يمكنك تقييم النماذج التي تم إنشاؤها على بيانات التحقق. وبالتحديد ، نتحدث عن تلك النماذج الثلاثة الموضحة في بداية المادة.تحقق من هذه النماذج:y_pred = rfc.predict(X_test_scaled)
y_pred_pca = rfc.predict(X_test_scaled_pca)
y_pred_gs = gs.best_estimator_.predict(X_test_scaled_pca)
أنشئ مصفوفات خطأ للنماذج واكتشف مدى قدرة كل منها على التنبؤ بسرطان الثدي:from sklearn.metrics import confusion_matrix
conf_matrix_baseline = pd.DataFrame(confusion_matrix(y_test, y_pred), index = ['actual 0', 'actual 1'], columns = ['predicted 0', 'predicted 1'])
conf_matrix_baseline_pca = pd.DataFrame(confusion_matrix(y_test, y_pred_pca), index = ['actual 0', 'actual 1'], columns = ['predicted 0', 'predicted 1'])
conf_matrix_tuned_pca = pd.DataFrame(confusion_matrix(y_test, y_pred_gs), index = ['actual 0', 'actual 1'], columns = ['predicted 0', 'predicted 1'])
display(conf_matrix_baseline)
display('Baseline Random Forest recall score', recall_score(y_test, y_pred))
display(conf_matrix_baseline_pca)
display('Baseline Random Forest With PCA recall score', recall_score(y_test, y_pred_pca))
display(conf_matrix_tuned_pca)
display('Hyperparameter Tuned Random Forest With PCA Reduced Dimensionality recall score', recall_score(y_test, y_pred_gs))
نتائج عمل النماذج الثلاثةهنا يتم تقييم مقياس "الاكتمال" (الاسترجاع). الحقيقة هي أننا نتعامل مع تشخيص للسرطان. لذلك ، نحن مهتمون للغاية بتقليل التوقعات السلبية الخاطئة الصادرة عن النماذج.بالنظر إلى ذلك ، يمكننا أن نستنتج أن نموذج RF الأساسي أعطى أفضل النتائج. كان معدل اكتماله 94.97٪. في مجموعة بيانات الاختبار ، كان هناك سجل لـ 179 مريضًا مصابًا بالسرطان. وجد النموذج 170 منهم.ملخص
توفر هذه الدراسة ملاحظة مهمة. في بعض الأحيان ، قد لا يعمل نموذج RF ، الذي يستخدم طريقة المكون الأساسي والتحسين واسع النطاق للمعلمات الفائقة ، مثل النموذج العادي مع الإعدادات القياسية. لكن هذا ليس سبباً لتقتصر على أبسط النماذج فقط. بدون تجربة نماذج مختلفة ، من المستحيل تحديد النموذج الذي سيظهر أفضل نتيجة. وفي حالة النماذج المستخدمة للتنبؤ بوجود السرطان في المرضى ، يمكننا القول أنه كلما كان النموذج أفضل - كلما أمكن إنقاذ المزيد من الأرواح.القراء الأعزاء! ما المهام التي تحلها باستخدام طرق التعلم الآلي؟