أواجه بانتظام حالة يعتقد فيها العديد من المطورين بصدق أن الفهرس في PostgreSQL هو سكين سويسري يساعد عالميًا في أي مشكلة في أداء الاستعلام. يكفي إضافة بعض الفهرس الجديد إلى الجدول أو تضمين الحقل في مكان ما في الفهرس الموجود ، ثم (سحر السحر!) ستستخدم جميع الاستعلامات هذا الفهرس بفعالية. أولاً ، بالطبع ، إما أنهم لن يفعلوا ، أو لن يفعلوا ذلك بكفاءة ، أو ليسوا جميعًا. ثانيًا ، ستضيف الفهارس الإضافية فقط مشكلات في الأداء عند الكتابة.في أغلب الأحيان ، تحدث مثل هذه المواقف أثناء تطوير "التشغيل الطويل" ، عندما لا يتم تصنيع منتج مخصص وفقًا لنموذج "كتب مرة واحدة ، أعطي ، نسي" ، ولكن ، كما في حالتنا ، تم إنشاؤهخدمة مع دورة حياة طويلة .تحدث التحسينات بشكل متكرر من قبل قوى العديد من الفرق الموزعة ، والتي يتم توزيعها ليس فقط في الفضاء ولكن أيضًا في الوقت المناسب. وبعد ذلك ، من دون معرفة التاريخ الكامل لتطوير المشروع أو ميزات التوزيع التطبيقي للبيانات في قاعدة بياناته ، يمكنك بسهولة "الفوضى" مع المؤشرات. لكن الاعتبارات وطلبات الاختبار تحت القطع تسمح لك بالتنبؤ والكشف عن جزء من المشاكل مقدمًا:
أولاً ، بالطبع ، إما أنهم لن يفعلوا ، أو لن يفعلوا ذلك بكفاءة ، أو ليسوا جميعًا. ثانيًا ، ستضيف الفهارس الإضافية فقط مشكلات في الأداء عند الكتابة.في أغلب الأحيان ، تحدث مثل هذه المواقف أثناء تطوير "التشغيل الطويل" ، عندما لا يتم تصنيع منتج مخصص وفقًا لنموذج "كتب مرة واحدة ، أعطي ، نسي" ، ولكن ، كما في حالتنا ، تم إنشاؤهخدمة مع دورة حياة طويلة .تحدث التحسينات بشكل متكرر من قبل قوى العديد من الفرق الموزعة ، والتي يتم توزيعها ليس فقط في الفضاء ولكن أيضًا في الوقت المناسب. وبعد ذلك ، من دون معرفة التاريخ الكامل لتطوير المشروع أو ميزات التوزيع التطبيقي للبيانات في قاعدة بياناته ، يمكنك بسهولة "الفوضى" مع المؤشرات. لكن الاعتبارات وطلبات الاختبار تحت القطع تسمح لك بالتنبؤ والكشف عن جزء من المشاكل مقدمًا:- فهارس غير مستخدمة
- بادئة "استنساخ"
- الطابع الزمني "في المنتصف"
- منطقي قابل للفهرسة
- صفائف في الفهرس
- قمامة فارغة
أبسط شيء هو العثور على المؤشرات التي لم يكن هناك تمريرات لها على الإطلاق . تحتاج فقط إلى التأكد من أن إعادة تعيين الإحصائيات ( pg_stat_reset()) حدثت منذ فترة طويلة ، ولا تريد حذف الإضافة المستخدمة "نادرًا ولكن بشكل مناسب". نستخدم طريقة عرض النظام pg_stat_user_indexes:SELECT * FROM pg_stat_user_indexes WHERE idx_scan = 0;
ولكن حتى إذا تم استخدام الفهرس ولم يقع في هذا التحديد ، فهذا لا يعني على الإطلاق أنه مناسب تمامًا لاستفساراتك.ما هي المؤشرات [غير] المناسبة
من أجل فهم سبب كون بعض الاستعلامات "تسوء في الفهرس" ، سنفكر في بنية فهرس btree العادي ، وهو أكثر الحالات شيوعًا في الطبيعة. عادة لا تخلق المؤشرات من حقل واحد أي مشاكل ، لذلك ، فإننا نعتبر المشاكل التي تنشأ على مركب من الحقول.طريقة مبسطة للغاية ، كما يمكن تصوره ، هي "كعكة ذات طبقات" ، حيث توجد في كل طبقة أشجار مرتبة وفقًا لقيم المجال المقابل بالترتيب.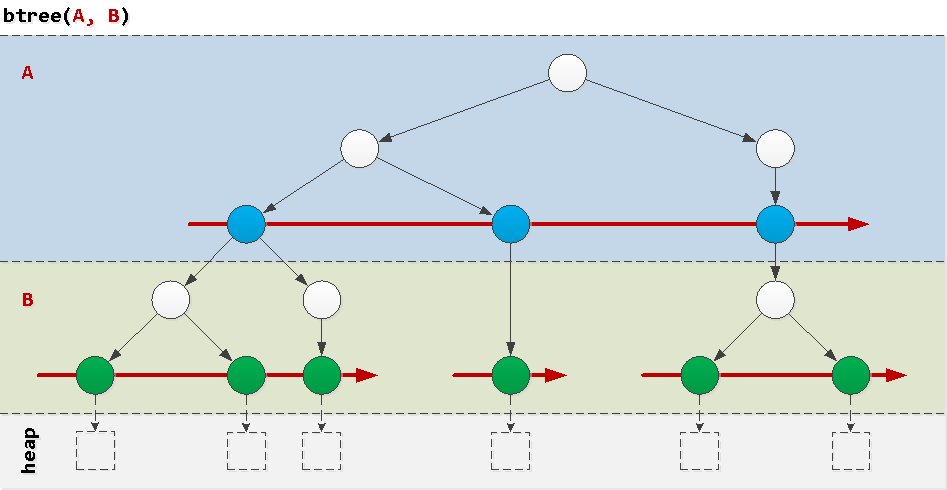 الآن فمن الواضح أن حقل A أمر على الصعيد العالمي، وB - فقط ضمن قيمة محددة و . دعنا نلقي نظرة على أمثلة للظروف التي تحدث في الاستعلامات الحقيقية ، وكيف "ستسير" حول الفهرس.
الآن فمن الواضح أن حقل A أمر على الصعيد العالمي، وB - فقط ضمن قيمة محددة و . دعنا نلقي نظرة على أمثلة للظروف التي تحدث في الاستعلامات الحقيقية ، وكيف "ستسير" حول الفهرس.جيد: شرط البادئة
لاحظ أن الفهرس btree(A, B)يتضمن " مؤشر فرعي" btree(A). هذا يعني أن جميع القواعد الموضحة أدناه ستعمل مع أي فهرس بادئة.بمعنى ، إذا قمت بإنشاء فهرس أكثر تعقيدًا من المثال الخاص بنا ، فهناك شيء من هذا النوع btree(A, B, C)- يمكنك افتراض أن قاعدة البيانات الخاصة بك "تظهر" تلقائيًا:btree(A, B, C)btree(A, B)btree(A)
وهذا يعني أن الوجود "المادي" لمؤشر البادئة في قاعدة البيانات لا لزوم له في معظم الحالات. بعد كل شيء ، كلما زاد عدد الفهارس التي يجب أن يكتبها الجدول - كلما كان الأمر أسوأ بالنسبة لـ PostgreSQL ، لأنه يسمي تضخيم الكتابة - اشتكى Uber من ذلك (وهنا يمكنك العثور على تحليل لمطالباتهم ).وإذا كان هناك شيء يمنع القاعدة من العيش بشكل جيد ، فمن الجدير العثور عليه والقضاء عليه. لنلقي نظرة على مثال:CREATE TABLE tbl(A integer, B integer, val integer);
CREATE INDEX ON tbl(A, B)
WHERE val IS NULL;
CREATE INDEX ON tbl(A)
WHERE val IS NULL;
CREATE INDEX ON tbl(A, B, val);
CREATE INDEX ON tbl(A);
استعلام بحث فهرس البادئةWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid AND
idx.indexprs IS NULL
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, pre AS (
SELECT
nmt
, wh
, nmf$
, tpf$
, nmi
, def
FROM
fld
ORDER BY
1, 2, 3
)
SELECT DISTINCT
Y.*
FROM
pre X
JOIN
pre Y
ON Y.nmi <> X.nmi AND
(Y.nmt, Y.wh) IS NOT DISTINCT FROM (X.nmt, X.wh) AND
(
Y.nmf$[1:array_length(X.nmf$, 1)] = X.nmf$ OR
X.nmf$[1:array_length(Y.nmf$, 1)] = Y.nmf$
)
ORDER BY
1, 2, 3;
من الناحية المثالية ، يجب أن تحصل على تحديد فارغ ، ولكن انظر - هذه هي مجموعات الفهرس المشبوهة لدينا:nmt | wh | nmf$ | tpf$ | nmi | def
---------------------------------------------------------------------------------------
tbl | (val IS NULL) | {a} | {int4} | tbl_a_idx | CREATE INDEX ...
tbl | (val IS NULL) | {a,b} | {int4,int4} | tbl_a_b_idx | CREATE INDEX ...
tbl | | {a} | {int4} | tbl_a_idx1 | CREATE INDEX ...
tbl | | {a,b,val} | {int4,int4,int4} | tbl_a_b_val_idx | CREATE INDEX ...
ثم تقرر لكل مجموعة بنفسك ما إذا كان الأمر يستحق إزالة الفهرس الأقصر أم أنه لم يعد هناك حاجة للمؤشر الأطول.حسن: جميع الثوابت عدا الحقل الأخير
إذا تم تعيين قيم جميع حقول الفهرس ، باستثناء الأخيرة ، بواسطة الثوابت (في هذا المثال ، هذا هو الحقل أ) ، يمكن استخدام الفهرس بشكل طبيعي. في هذه الحالة ، يمكن تعيين قيمة الحقل الأخير بشكل تعسفي: ثابت أو عدم مساواة أو فاصل أو طلب عبر IN (...)أو = ANY(...). وأيضا يمكن فرزها به.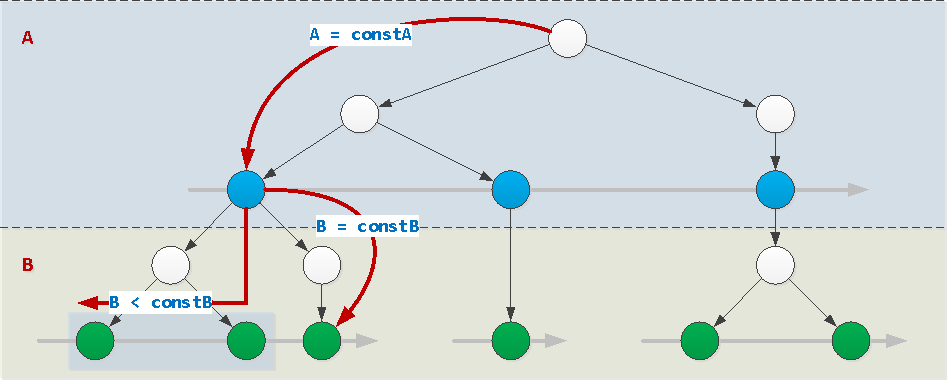
WHERE A = constA AND B [op] constB / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A = constA AND B BETWEEN constB1 AND constB2WHERE A = constA ORDER BY B
بناءً على فهارس البادئات الموضحة أعلاه ، سيعمل هذا بشكل جيد:WHERE A [op] const / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A BETWEEN const1 AND const2ORDER BY AWHERE (A, B) [op] (constA, constB) / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }ORDER BY A, B
سيئ: العد الكامل لـ "الطبقة"
باستخدام جزء من الاستعلامات ، يصبح التعداد الوحيد للحركة في الفهرس تعدادًا كاملاً لجميع القيم في إحدى "الطبقات". من المحظوظ إذا كانت هناك وحدة لهذه القيم - وإذا كان هناك الآلاف؟ ..عادة تحدث مثل هذه المشكلة إذا تم استخدام عدم المساواة في الاستعلام ، فإن الشرط لا يحدد الحقول السابقة في ترتيب الفهرس أو تم انتهاك هذا الأمر أثناء الفرز.WHERE A <> constWHERE B [op] const / = ANY(...) / IN (...)ORDER BY BORDER BY B, A
تالف: الفاصل الزمني أو المجموعة غير موجود في الحقل الأخير
نتيجة للقيمة السابقة - إذا كنت بحاجة إلى العثور على العديد من القيم أو نطاقها على "طبقة" وسيطة ، ثم التصفية أو الفرز حسب الحقول الموجودة في "أعمق" في الفهرس ، ستكون هناك مشاكل إذا كان عدد القيم الفريدة "في منتصف" الفهرس هو عظيم.WHERE A BETWEEN constA1 AND constA2 AND B BETWEEN constB1 AND constB2WHERE A = ANY(...) AND B = constWHERE A = ANY(...) ORDER BY BWHERE A = ANY(...) AND B = ANY(...)
سيء: التعبير بدلاً من الحقل
في بعض الأحيان يقوم المطور بتحويل عمود في استعلام دون وعي إلى شيء آخر - إلى بعض التعبيرات التي لا يوجد لها فهرس. يمكن إصلاح ذلك عن طريق إنشاء فهرس من التعبير المطلوب ، أو عن طريق إجراء التحويل العكسي:WHERE A - const1 [op] const2
الإصلاح: WHERE A [op] const1 + const2WHERE A::typeOfConst = const
الإصلاح: WHERE A = const::typeOfA
نأخذ بعين الاعتبار أصالة الحقول
افترض أنك بحاجة إلى المؤشر (A, B)، وتريد أن تختار إلا من خلال المساواة : (A, B) = (constA, constB). سيكون استخدام مؤشر التجزئة مثاليًا ، ولكن ... بالإضافة إلى عدم تسجيل هذه الفهارس (عدم تسجيلها) حتى الإصدار 10 ، لا يمكن أن توجد أيضًا في عدة حقول:CREATE INDEX ON tbl USING hash(A, B);
بشكل عام ، لقد اخترت btree. إذن ما هي أفضل طريقة لترتيب الأعمدة فيه - (A, B)أو (B, A)؟ للإجابة على هذا السؤال ، من الضروري أن تأخذ بعين الاعتبار معلمة مثل أصالة البيانات في العمود المقابل - أي عدد القيم الفريدة التي تحتوي عليها.دعونا نتخيل ذلك A = {1,2}, B = {1,2,3,4}، ونرسم مخططًا تفصيليًا لشجرة الفهرس لكلا الخيارين: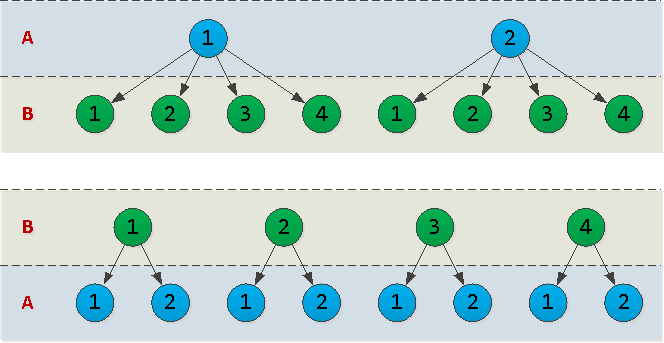 في الواقع ، كل عقدة في الشجرة التي نرسمها هي صفحة في الفهرس. وكلما زاد عدد مساحة القرص التي سيشغلها الفهرس ، زادت المدة التي تستغرقها القراءة منه.في مثالنا ،
في الواقع ، كل عقدة في الشجرة التي نرسمها هي صفحة في الفهرس. وكلما زاد عدد مساحة القرص التي سيشغلها الفهرس ، زادت المدة التي تستغرقها القراءة منه.في مثالنا ، (A, B)يحتوي الخيار على 10 عقد ، و (B, A)- 12. أي أنه من الأكثر ربحية وضع "الحقول" بأقل عدد ممكن من القيم الفريدة "الأولى" .سيئ: الكثير وفي غير مكانه (الطابع الزمني "في الوسط")
لهذا السبب بالضبط ، يبدو دائمًا مشبوهًا إذا لم يكن الحقل الذي يحتوي على تغير كبير واضح مثل الطابع الزمني [tz] هو الأخير في الفهرس الخاص بك . كقاعدة ، تزداد قيم حقل الطابع الزمني بشكل رتيب ، ولحقول الفهرس التالية قيمة واحدة فقط في كل نقطة زمنية.CREATE TABLE tbl(A integer, B timestamp);
CREATE INDEX ON tbl(A, B);
CREATE INDEX ON tbl(B, A);

استعلام البحث عن فهارس الطابع الزمني [tz] غير النهائيةWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
'timestamp' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamptz' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamp' = ANY(opc$[1:array_length(opc$, 1) - 1]) OR
'timestamptz' = ANY(opc$[1:array_length(opc$, 1) - 1])
ORDER BY
1, 2;
هنا نحلل على الفور كل من أنواع حقول الإدخال نفسها وفئات عوامل التشغيل المطبقة عليها - نظرًا لأن بعض وظيفة timestamptz مثل date_trunc قد تتحول إلى حقل فهرس.nmt | nmi | def | nmf$ | tpf$ | opc$
----------------------------------------------------------------------------------
tbl | tbl_b_a_idx | CREATE INDEX ... | {b,a} | {timestamp,int4} | {timestamp,int4}
سيئ: قليل جدًا (منطقي)
على الجانب الآخر من نفس العملة ، يصبح الوضع هو الفهرس حيث يكون المجال المنطقي ، والذي يمكن أن يأخذ 3 قيم فقط NULL, FALSE, TRUE. بطبيعة الحال ، فإن وجودها منطقي إذا كنت تريد استخدامه للفرز التطبيقي - على سبيل المثال ، عن طريق تعيينها كنوع من العقدة في التسلسل الهرمي للشجرة - سواء كان مجلدًا أو ورقة شجر ("المجلدات أولاً").CREATE TABLE tbl(
id
serial
PRIMARY KEY
, leaf_pid
integer
, leaf_type
boolean
, public
boolean
);
CREATE INDEX ON tbl(leaf_pid, leaf_type);
CREATE INDEX ON tbl(public, id);
ولكن ، في معظم الحالات ، ليس هذا هو الحال ، وتأتي الطلبات مع بعض القيمة المحددة للمجال المنطقي. ثم يصبح من الممكن استبدال الفهرس بهذا الحقل بنسخته الشرطية:CREATE INDEX ON tbl(id) WHERE public;
استعلام البحث المنطقي في الفهارسWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
(
'bool' = ANY(tpf$) OR
'bool' = ANY(opc$)
) AND
NOT(
ARRAY(
SELECT
nmf$[i:i+1]::text
FROM
generate_series(1, array_length(nmf$, 1) - 1) i
) &&
ARRAY[
'{leaf_pid,leaf_type}'
]
)
ORDER BY
1, 2;
nmt | nmi | def | nmf$ | tpf$ | opc$
------------------------------------------------------------------------------------
tbl | tbl_public_id_idx | CREATE INDEX ... | {public,id} | {bool,int4} | {bool,int4}
صفائف في btree
نقطة منفصلة هي محاولة "فهرسة المصفوفة" باستخدام فهرس btree. هذا ممكن تمامًا نظرًا لأن العوامل المقابلة تنطبق عليهم :(<, >, = . .) , B-, , . ( ). , , .
ولكن المشكلة هي أن لاستخدام شيء يريد أن مشغلي إدراج والتقاطع : <@, @>, &&. بالطبع ، هذا لا يعمل - لأنهم بحاجة إلى أنواع أخرى من الفهارس . كيف لا يعمل هذا btree لوظيفة الوصول إلى عنصر معين arr[i].نتعلم أن نجد مثل:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, pid
integer
, list
integer[]
);
CREATE INDEX ON tbl(pid);
CREATE INDEX ON tbl(list);
صفيف استعلام البحث في btreeWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid AND
cli.relam = (
SELECT
oid
FROM
pg_am
WHERE
amname = 'btree'
LIMIT 1
)
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, nmf$
, tpf$
, def
FROM
fld
WHERE
tpf$ && ARRAY(
SELECT
typname
FROM
pg_type
WHERE
typname ~ '^_'
)
ORDER BY
1, 2;
nmt | nmi | nmf$ | tpf$ | def
--------------------------------------------------------
tbl | tbl_list_idx | {list} | {_int4} | CREATE INDEX ...
إدخالات فهرس فارغة
آخر مشكلة شائعة هي "تلويث" الفهرس بإدخالات فارغة تمامًا. بمعنى ، يسجل حيث يكون التعبير المفهرس في كل من الأعمدة NULL . ليس لهذه السجلات أي فائدة عملية ، لكنها تضيف ضررًا مع كل إدخال.عادة ما تظهر عند إنشاء حقل FK أو علاقة قيمة مع المساحة الاختيارية في الجدول. ثم قم بتحريك المؤشر حتى يعمل FK بسرعة ... وهنا هم. كلما قل الاتصال في كثير من الأحيان ، كلما سقطت المزيد من "القمامة" في الفهرس. سنقوم بمحاكاة:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, fk
integer
);
CREATE INDEX ON tbl(fk);
INSERT INTO tbl(fk)
SELECT
CASE WHEN i % 10 = 0 THEN i END
FROM
generate_series(1, 1000000) i;
في معظم الحالات ، يمكن تحويل هذا الفهرس إلى فهرس شرطي ، والذي يستغرق أيضًا أقل:CREATE INDEX ON tbl(fk) WHERE (fk) IS NOT NULL;
_tmp=# \di+ tbl*
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+----------------+-------+----------+----------+---------+-------------
public | tbl_fk_idx | index | postgres | tbl | 36 MB |
public | tbl_fk_idx1 | index | postgres | tbl | 2208 kB |
public | tbl_pkey | index | postgres | tbl | 21 MB |
للعثور على هذه الفهارس ، نحتاج إلى معرفة التوزيع الفعلي للبيانات - أي ، بعد كل شيء ، قراءة جميع محتويات الجداول وتثبيتها وفقًا لظروف حدوث (سنقوم بذلك باستخدام dblink ) ، والتي يمكن أن تستغرق وقتًا طويلاً جدًا .استعلام بحث عن مداخل NULL في الفهارسWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisprimary AND
idx.indisready AND
idx.indisvalid AND
NOT EXISTS(
SELECT
NULL
FROM
pg_constraint
WHERE
conindid = cli.oid
LIMIT 1
) AND
pg_relation_size(cli.oid) > 1 << 20
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, regexp_replace(
CASE
WHEN def ~ ' USING btree ' THEN
regexp_replace(def, E'.* USING btree (.*?)($| WHERE .*)', E'\\1')
END
, E' ([a-z]*_pattern_ops|(ASC|DESC)|NULLS\\s?(?:FIRST|LAST))'
, ''
, 'ig'
) fld
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, q AS (
SELECT
nmt
, $q$
SET search_path = $q$ || quote_ident((TABLE sch)) || $q$, public;
SELECT
ARRAY[
count(*)
$q$ || string_agg(
', coalesce(sum((' || coalesce(wh, 'TRUE') || ')::integer), 0)' || E'\n' ||
', coalesce(sum(((' || coalesce(wh, 'TRUE') || ') AND (' || fld || ' IS NULL))::integer), 0)' || E'\n'
, '' ORDER BY nmi) || $q$
]
FROM
$q$ || quote_ident((TABLE sch)) || $q$.$q$ || quote_ident(nmt) || $q$
$q$ q
, array_agg(clioid ORDER BY nmi) oid$
, array_agg(nmi ORDER BY nmi) idx$
, array_agg(fld ORDER BY nmi) fld$
, array_agg(wh ORDER BY nmi) wh$
FROM
fld
WHERE
fld IS NOT NULL
GROUP BY
1
ORDER BY
1
)
, res AS (
SELECT
*
, (
SELECT
qty
FROM
dblink(
'dbname=' || current_database() || ' port=' || current_setting('port')
, q
) T(qty bigint[])
) qty
FROM
q
)
, iter AS (
SELECT
*
, generate_subscripts(idx$, 1) i
FROM
res
)
, stat AS (
SELECT
nmt table_name
, idx$[i] index_name
, pg_relation_size(oid$[i]) index_size
, pg_size_pretty(pg_relation_size(oid$[i])) index_size_humanize
, regexp_replace(fld$[i], E'^\\((.*)\\)$', E'\\1') index_fields
, regexp_replace(wh$[i], E'^\\((.*)\\)$', E'\\1') index_cond
, qty[1] table_rec_count
, qty[i * 2] index_rec_count
, qty[i * 2 + 1] index_rec_count_null
FROM
iter
)
SELECT
*
, CASE
WHEN table_rec_count > 0
THEN index_rec_count::double precision / table_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_cover_prc
, CASE
WHEN index_rec_count > 0
THEN index_rec_count_null::double precision / index_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_null_prc
FROM
stat
WHERE
index_rec_count_null * 4 > index_rec_count
ORDER BY
1, 2;
-[ RECORD 1 ]--------+--------------
table_name | tbl
index_name | tbl_fk_idx
index_size | 37838848
index_size_humanize | 36 MB
index_fields | fk
index_cond |
table_rec_count | 1000000
index_rec_count | 1000000
index_rec_count_null | 900000
index_cover_prc | 100.00 -- 100%
index_null_prc | 90.00 -- 90% NULL-""
آمل أن تساعدك بعض الاستفسارات في هذه المقالة.