قبل بضعة أسابيع في محادثة على العشاء ، اشتكى زميل من نوع من العملية البطيئة. قام بحساب عدد وحدات البايت التي تم إنشاؤها ، وعدد دورات المعالجة ، وفي النهاية ، كمية ذاكرة الوصول العشوائي. قال أحد الزملاء أن وحدة معالجة الرسوميات الحديثة ذات النطاق الترددي للذاكرة التي تزيد عن 500 جيجابايت / ثانية ستستهلك مهمتها وليس الاختناق.بدا لي أن هذا نهج مثير للاهتمام. أنا شخصياً لم أقم بتقييم أهداف الأداء من هذا المنظور. نعم ، أنا أعرف الاختلاف في أداء المعالج والذاكرة. أنا أعرف كيفية كتابة التعليمات البرمجية التي تجعل الاستخدام المكثف لذاكرة التخزين المؤقت. أعرف أرقام التأخير التقريبية. لكن هذا لا يكفي لتقييم عرض النطاق الترددي للذاكرة على الفور.هنا تجربة فكرية. تخيل في الذاكرة مجموعة مستمرة من مليار عدد صحيح 32 بت. هذا هو 4 غيغابايت. كم من الوقت سيستغرق التكرار على هذا الصفيف وإضافة القيم؟ كم بايت في الثانية يمكن قراءة وحدة المعالجة المركزية من ذاكرة الوصول العشوائي؟ البيانات المستمرة؟ دخول عشوائي؟ كيف يمكن موازاة هذه العملية؟ستقول أن هذه أسئلة عديمة الفائدة. إن البرامج الحقيقية معقدة للغاية بحيث لا تجعل مثل هذا المعلم الساذج. وهناك! الجواب الحقيقي هو "حسب الموقف".ومع ذلك ، أعتقد أن هذه القضية تستحق استكشافها. أنا لا أحاول أن أجد الجواب . ولكن أعتقد أنه يمكننا تحديد بعض الحدود العليا والدنيا ، وبعض النقاط المثيرة للاهتمام في الوسط وتعلم شيء في هذه العملية.
أنا أعرف كيفية كتابة التعليمات البرمجية التي تجعل الاستخدام المكثف لذاكرة التخزين المؤقت. أعرف أرقام التأخير التقريبية. لكن هذا لا يكفي لتقييم عرض النطاق الترددي للذاكرة على الفور.هنا تجربة فكرية. تخيل في الذاكرة مجموعة مستمرة من مليار عدد صحيح 32 بت. هذا هو 4 غيغابايت. كم من الوقت سيستغرق التكرار على هذا الصفيف وإضافة القيم؟ كم بايت في الثانية يمكن قراءة وحدة المعالجة المركزية من ذاكرة الوصول العشوائي؟ البيانات المستمرة؟ دخول عشوائي؟ كيف يمكن موازاة هذه العملية؟ستقول أن هذه أسئلة عديمة الفائدة. إن البرامج الحقيقية معقدة للغاية بحيث لا تجعل مثل هذا المعلم الساذج. وهناك! الجواب الحقيقي هو "حسب الموقف".ومع ذلك ، أعتقد أن هذه القضية تستحق استكشافها. أنا لا أحاول أن أجد الجواب . ولكن أعتقد أنه يمكننا تحديد بعض الحدود العليا والدنيا ، وبعض النقاط المثيرة للاهتمام في الوسط وتعلم شيء في هذه العملية.الأرقام التي يجب أن يعرفها كل مبرمج
إذا قرأت مدونات البرمجة ، فربما صادفت "أرقامًا يجب أن يعرفها كل مبرمج". إنهم يبدون شيء مثل هذا:تصل إلى ذاكرة التخزين المؤقت L1 0.5 نانوثانية
تنبؤ خاطئ 5 نانوثانية
رابط إلى ذاكرة التخزين المؤقت L2 7 ns 14x إلى ذاكرة التخزين المؤقت L1
التقاط Mutex / الإصدار 25 نانوثانية
رابط للذاكرة الرئيسية 100 ns 20x إلى ذاكرة التخزين المؤقت L2 ، 200x إلى ذاكرة التخزين المؤقت L1
ضغط 1000 بايت باستخدام Zippy 3000 ns 3 μs
إرسال 1000 بايت عبر شبكة بسرعة 1 جيجابت في الثانية 10000 نانومتر 10 ثانية
قراءة عشوائية 4000 مع SSD 150،000 ns 150 ~s ~ 1GB / s SSD
اقرأ 1 ميجابايت بالتتابع من 250.000 نانومتر 250 ثانية
حزمة ذهابا وإيابا داخل مركز البيانات 500000 نانوثانية 500 ميكرومتر
1 ميغا بايت قراءة متتالية في SSD 1،000،000 ns 1،000 μs 1 ms ~ 1 GB / s SSD، 4x memory
البحث في القرص 10،000،000 ns 10،000 10s 10 ms 20x إلى مركز البيانات
اقرأ 1 ميجا بايت بالتتابع من القرص 20000.000 نانوثانية 20000 ثانية 20 مللي ثانية 80x إلى الذاكرة ، 20x إلى SSD
إرسال الحزمة CA-> هولندا-> CA 150،000،000 ns 150،000 150s 150 ms
المصدر:قائمة جوناس بونر العظيمة. يبرز على موقع HackerNews مرة واحدة على الأقل في السنة. يجب أن يعرف كل مبرمج هذه الأرقام.لكن هذه الأرقام تتعلق بشيء آخر. الكمون وعرض النطاق الترددي ليست الشيء نفسه.التأخير في 2020
تم تجميع هذه القائمة في عام 2012 ، وهذه المقالة لعام 2020 ، تغيرت الأوقات. فيما يلي أرقام Intel i7 مع StackOverflow .ضرب في ذاكرة التخزين المؤقت L1 ، ~ 4 دورات (2.1 - 1.2 نانوثانية)
ضرب في ذاكرة التخزين المؤقت L2 ، ~ 10 دورات (5.3 - 3.0 نانوثانية)
ضرب في ذاكرة التخزين المؤقت L3 ، من أجل قلب واحد ~ 40 دورة (21.4 - 12.0 نانوثانية)
ضرب في ذاكرة التخزين المؤقت L3 ، معًا لنواة أخرى ~ 65 دورة (34.8 - 19.5 نانوثانية)
اضغط على ذاكرة التخزين المؤقت L3 ، مع تغيير نواة أخرى ~ 75 دورة (40.2 - 22.5 نانوثانية)
ذاكرة الوصول العشوائي المحلية ~ 60 نانوثانية
مثير للإعجاب! ما الذي تغير؟- أصبح L1 أبطأ.
0,5 → 1,5
- L2 أسرع ؛
7 → 4,2
- يتم تقليل نسبة L1 و L2 بشكل كبير ؛
2,5x 14(رائع!)
- أصبحت ذاكرة التخزين المؤقت L3 هي المعيار ؛
12 40
- أصبحت ذاكرة الوصول العشوائي أسرع.
100 → 60
لن نستخلص نتائج بعيدة المدى. من غير الواضح كيف تم حساب الأرقام الأصلية. لن نقارن التفاح بالبرتقال.فيما يلي بعض الأشكال من wikichip على عرض النطاق الترددي وحجم ذاكرة التخزين المؤقت للمعالج الخاص بي.عرض نطاق الذاكرة: 39.74 جيجا بايت في الثانية
ذاكرة التخزين المؤقت L1: 192 كيلوبايت (32 كيلوبايت لكل نواة)
ذاكرة التخزين المؤقت L2: 1.5 ميغابايت (256 كيلوبايت لكل نواة)
ذاكرة التخزين المؤقت L3: 12 ميغابايت (مشتركة ؛ 2 ميغابايت لكل مركز)
ما الذي اريد ان اعرفه:- الحد الأعلى لأداء ذاكرة الوصول العشوائي
- الحد الأدنى
- حدود ذاكرة التخزين المؤقت L1 / L2 / L3
قياس السذاجة
لنقم ببعض الاختبارات. لقياس عرض النطاق الترددي ، كتبت برنامج C ++ بسيط. تقريبا تبدو مثل هذا.
std::vector<int> nums;
for (size_t i = 0; i < 1024*1024*1024; ++i)
nums.push_back(rng() % 1024);
for (int thread_count = 1; thread_count <= MAX_THREADS; ++thread_count) {
auto slice_len = nums.size() / thread_count;
for (size_t thread = 0; thread < thread_count; ++thread) {
auto begin = nums.begin() + thread * slice_len;
auto end = (thread == thread_count - 1)
? nums.end() : begin + slice_len;
futures.push_back(std::async([begin, end] {
int64_t sum = 0;
for (auto ptr = begin; ptr < end; ++ptr)
sum += *ptr;
return sum;
}));
}
int64_t sum = 0;
for (auto& future : futures)
sum += future.get();
}
تم حذف بعض التفاصيل. لكنك فهمت الفكرة. قم بإنشاء مجموعة كبيرة ومتواصلة من العناصر. قسم الصفيف إلى أجزاء منفصلة. معالجة كل جزء في خيط منفصل. تجميع النتائج.تحتاج أيضًا إلى قياس الوصول العشوائي. انه صعب جدا. لقد جربت عدة طرق ، قررت في النهاية مزج الفهارس المحسوبة مسبقًا. كل فهرس موجود مرة واحدة بالضبط. ثم تتكرر الحلقة الداخلية فوق المؤشرات وتحسب sum += nums[index].std::vector<int> nums = ;
std::vector<uint32_t> indices = ;
int64_t sum = 0;
for (auto ptr = indices.begin(); ptr < indices.end(); ++ptr) {
auto idx = *ptr;
sum += nums[idx];
}
return sum;
عند حساب الإنتاجية ، لا أعتبر ذاكرة صفيف الفهرس. يتم حساب وحدات البايت التي تساهم في الإجمالي فقط sum. لا أقوم بمقارنة أجهزتي ، ولكني أقدر القدرة على العمل مع مجموعات بيانات ذات أحجام مختلفة ومخططات وصول مختلفة.سنجري اختبارات بثلاثة أنواع من البيانات:int- العدد الصحيح الرئيسي 32 بتmatri4x4- يحتوي على int[16]؛ يلائم خط ذاكرة التخزين المؤقت 64 بايتmatrix4x4_simd- يستخدم أدوات مدمجة__m256iكتلة كبيرة
أول اختبار لي يعمل مع كتلة كبيرة من الذاكرة. Nتم تمييز كتلة 1 غيغابايت من العناصر ومليئة بقيم عشوائية صغيرة. تتكرر حلقة بسيطة عبر مصفوفة N مرة ، بحيث تصل إلى الذاكرة باستخدام وحدة تخزين N لحساب المجموع int64_t. تقسم عدة سلاسل الصفيف ، ويحصل كل منها على نفس العدد من العناصر.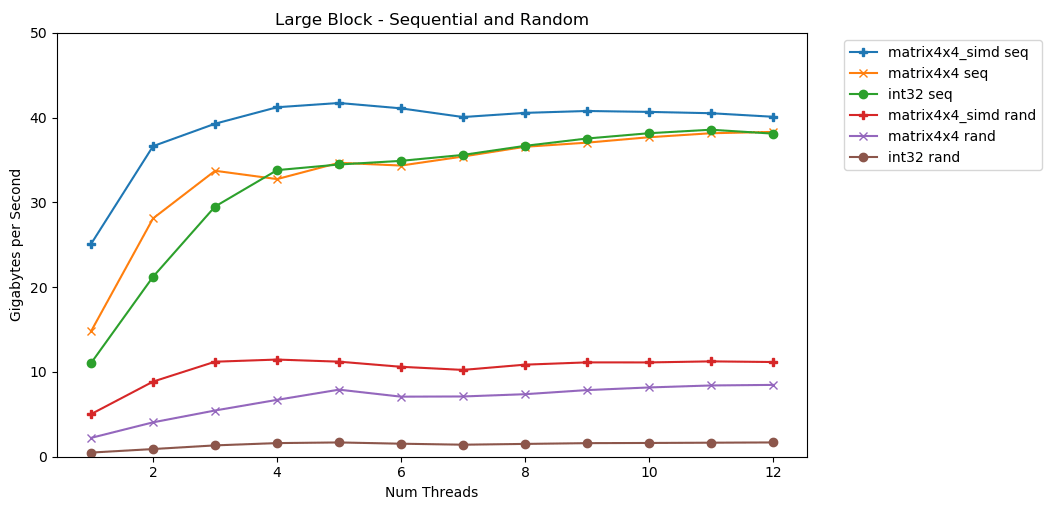 الداه تا! في هذا الرسم البياني ، نأخذ متوسط وقت تنفيذ عملية الجمع ونحولها من
الداه تا! في هذا الرسم البياني ، نأخذ متوسط وقت تنفيذ عملية الجمع ونحولها من runtime_in_nanosecondsإلى gigabytes_per_second.نتيجة جيدة جدا. int32يمكنه قراءة 11 جيجابايت / ثانية بالتتابع في دفق واحد. يتم قياسها خطياً حتى تصل إلى 38 جيجابايت / ثانية. اختبارات matrix4x4و matrix4x4_simdأسرع، ولكن بقية ضد نفس السقف.هناك سقف واضح وواضح لكمية البيانات التي يمكننا قراءتها من ذاكرة الوصول العشوائي في الثانية. على نظامي ، هذا هو حوالي 40 جيجابايت / ثانية. هذا يتوافق مع المواصفات الحالية المذكورة أعلاه.إذا حكمنا من خلال الرسوم البيانية الثلاثة السفلية ، فإن الوصول العشوائي بطيء. بطيء جدا جدا. أداء واحد الخيوط int32لا يكاد يذكر 0.46 جيجابايت / ثانية. هذا أبطأ 24 مرة من التراص المتسلسل بسرعة 11.03 جيجابايت / ثانية! matrix4x4يظهر الاختبار أفضل نتيجة ، لأنه يعمل على خطوط ذاكرة التخزين المؤقت الكاملة. لكنه لا يزال أبطأ أربع إلى سبع مرات من الوصول المتسلسل ، ويصل إلى 8 غيغابايت / ثانية فقط.كتلة صغيرة: قراءة متسلسلة
على نظامي ، يبلغ حجم ذاكرة التخزين المؤقت L1 / L2 / L3 لكل دفق 32 كيلوبايت و 256 كيلوبايت و 2 ميغابايت. ماذا يحدث إذا أخذت كتلة من العناصر ذات 32 كيلوبايت وقمت بتكرارها أكثر من 125000 مرة؟ هذا هو 4 غيغابايت من الذاكرة ، لكننا سنذهب دائمًا إلى ذاكرة التخزين المؤقت.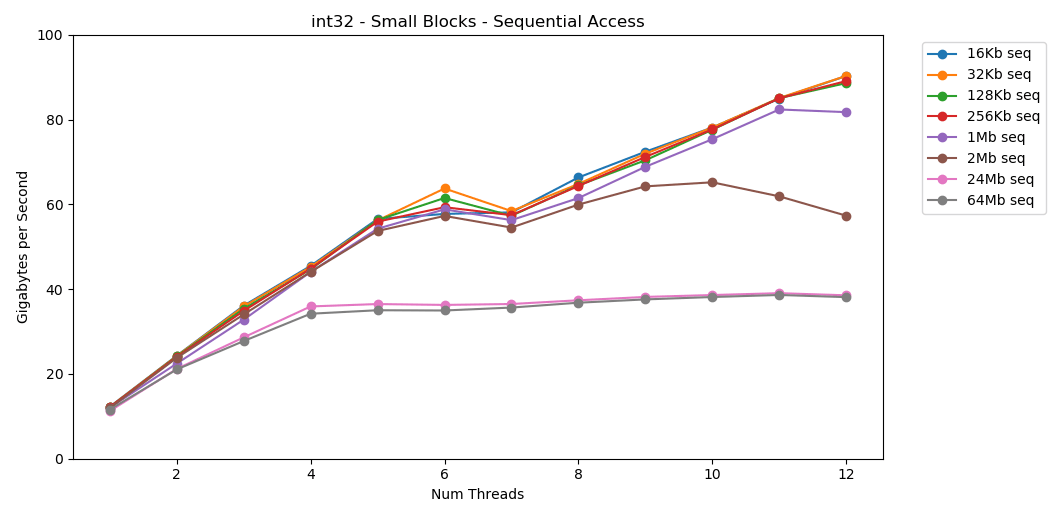 مدهش! يشبه الأداء الخيوط الفردية قراءة كتلة كبيرة ، حوالي 12 جيجابايت / ثانية. باستثناء هذه المرة ، فواصل تعدد مؤشرات الترابط من خلال سقف 40 جيجابايت / ثانية. يبدو الأمر معقولا. تبقى البيانات في ذاكرة التخزين المؤقت ، لذلك لا يظهر اختناق ذاكرة الوصول العشوائي. بالنسبة للبيانات التي لم يتم احتواؤها في ذاكرة التخزين المؤقت L3 ، يتم تطبيق نفس السقف الذي يبلغ حوالي 38 جيجابايت / ثانية. يظهرالاختبار
مدهش! يشبه الأداء الخيوط الفردية قراءة كتلة كبيرة ، حوالي 12 جيجابايت / ثانية. باستثناء هذه المرة ، فواصل تعدد مؤشرات الترابط من خلال سقف 40 جيجابايت / ثانية. يبدو الأمر معقولا. تبقى البيانات في ذاكرة التخزين المؤقت ، لذلك لا يظهر اختناق ذاكرة الوصول العشوائي. بالنسبة للبيانات التي لم يتم احتواؤها في ذاكرة التخزين المؤقت L3 ، يتم تطبيق نفس السقف الذي يبلغ حوالي 38 جيجابايت / ثانية. يظهرالاختبار matrix4x4نتائج مماثلة للدائرة ، ولكن بشكل أسرع ؛ 31 جيجابايت / ثانية في وضع الخيوط الفردية ، 171 جيجابايت / ثانية في الخيوط المتعددة.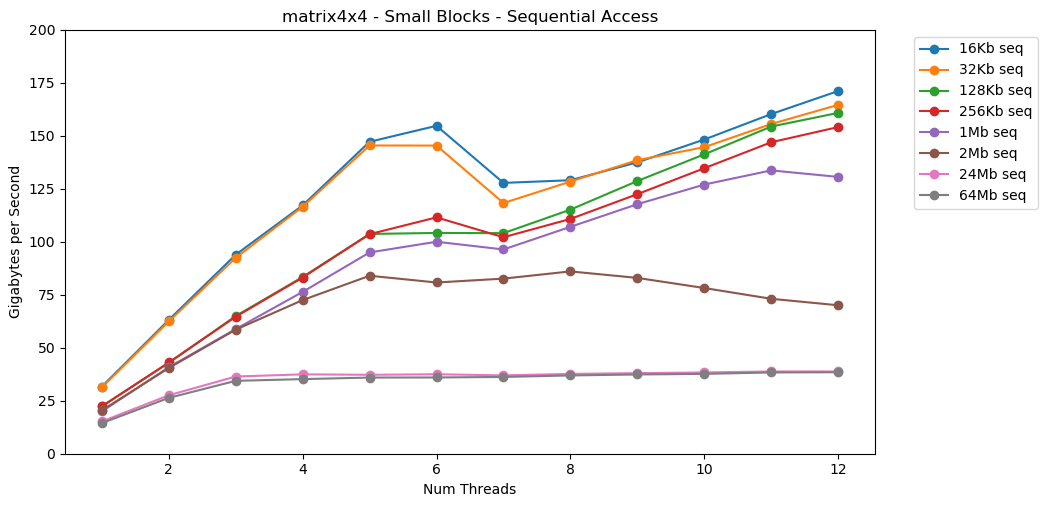 الآن دعونا نلقي نظرة
الآن دعونا نلقي نظرة matrix4x4_simd. انتبه إلى المحور ص.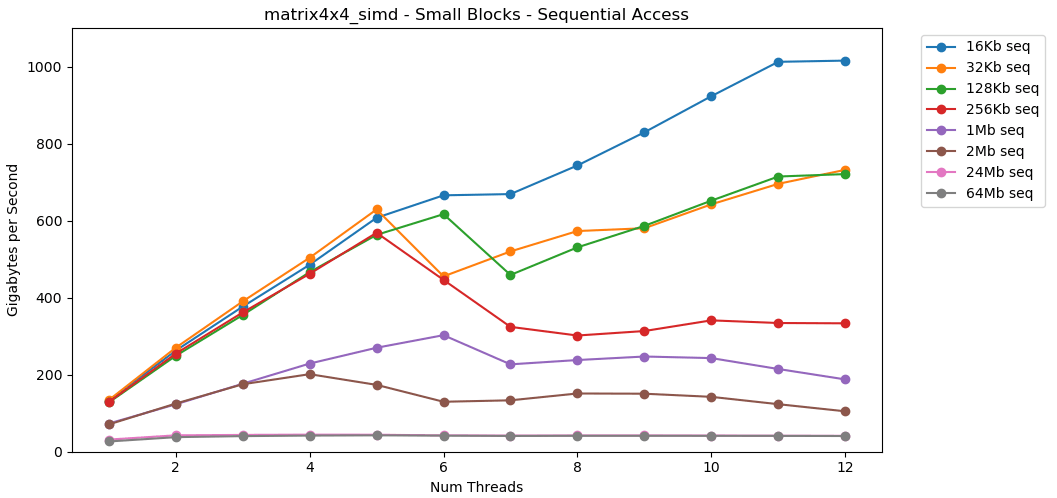
matrix4x4_simdيؤدى بسرعة استثنائية. إنه أسرع 10 مرات من int32. على كتلة 16 كيلو بايت ، فإنه يكسر حتى 1000 جيجا بايت / ثانية!من الواضح أن هذا اختبار اصطناعي سطحي. لا تقوم معظم التطبيقات بنفس العملية بنفس البيانات مليون مرة على التوالي. الاختبار لا يظهر الأداء في العالم الحقيقي.لكن الدرس واضح. داخل ذاكرة التخزين المؤقت ، تتم معالجة البيانات بسرعة . مع سقف مرتفع جدًا عند استخدام SIMD: أكثر من 100 جيجابايت / ثانية في وضع الخيوط المفردة ، وأكثر من 1000 جيجابايت / ثانية في الخيوط المتعددة. كتابة البيانات إلى ذاكرة التخزين المؤقت بطيئة وبحد أقصى يصل إلى 40 جيجابايت / ثانية.كتلة صغيرة: قراءة عشوائية
لنفعل الشيء نفسه ، ولكن الآن مع وصول عشوائي. هذا هو الجزء المفضل لدي من المقال.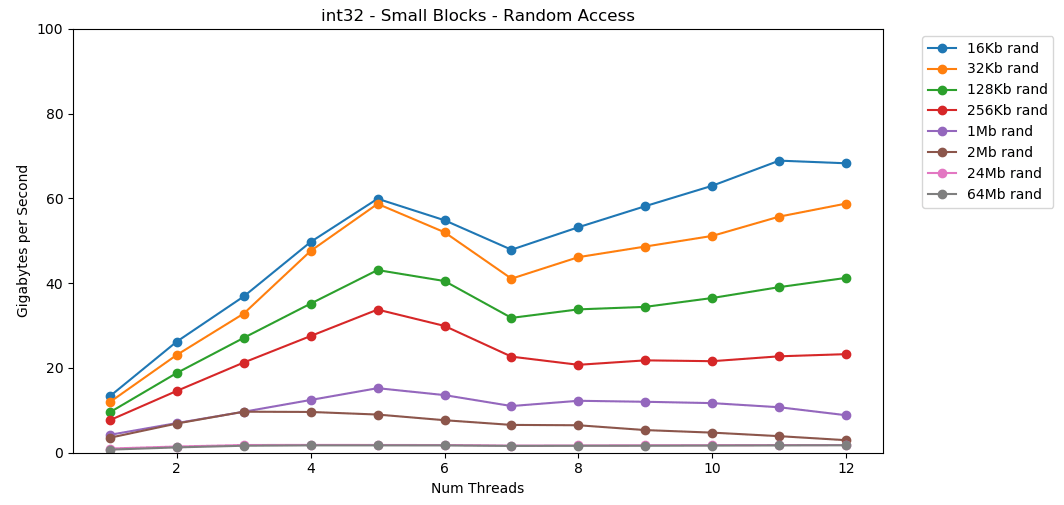 قراءة القيم العشوائية من ذاكرة الوصول العشوائي بطيئة ، فقط 0.46 جيجابايت / ثانية. قراءة القيم العشوائية من ذاكرة التخزين المؤقت L1 سريعة جدًا: 13 جيجابايت / ثانية. هذا أسرع من قراءة البيانات التسلسلية
قراءة القيم العشوائية من ذاكرة الوصول العشوائي بطيئة ، فقط 0.46 جيجابايت / ثانية. قراءة القيم العشوائية من ذاكرة التخزين المؤقت L1 سريعة جدًا: 13 جيجابايت / ثانية. هذا أسرع من قراءة البيانات التسلسلية int32من ذاكرة الوصول العشوائي (11 جيجا بايت / ثانية). يظهر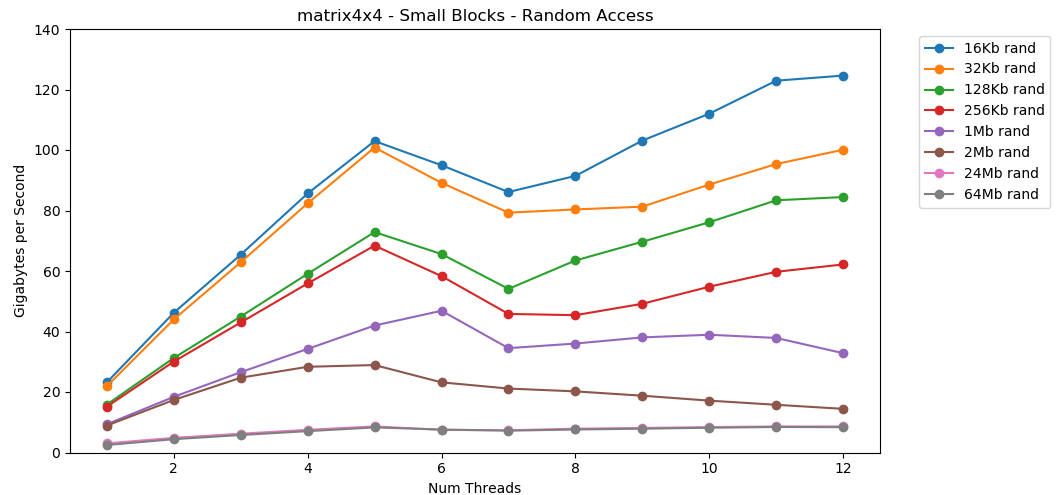 الاختبار
الاختبار matrix4x4نتيجة مشابهة لنفس القالب ، ولكن أسرع مرتين تقريبًا int.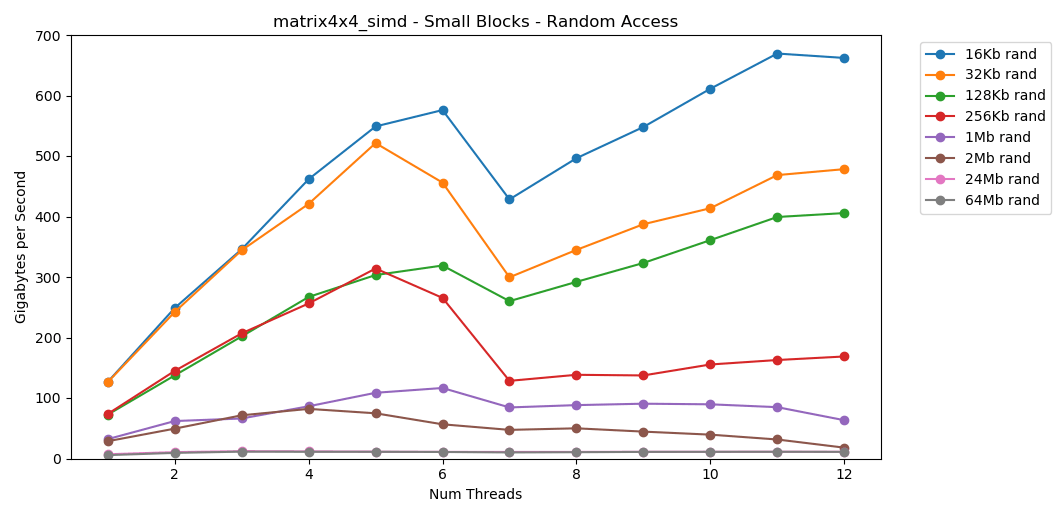 الوصول العشوائي
الوصول العشوائي matrix4x4_simdسريع بجنون.نتائج الوصول العشوائي
القراءة المجانية من الذاكرة بطيئة. بطيء بشكل كارثي. أقل من 1 جيجابايت / ثانية لكلتا حالتا الاختبار int32. في الوقت نفسه ، القراءات العشوائية من ذاكرة التخزين المؤقت سريعة بشكل مدهش. يمكن مقارنته بالقراءة التسلسلية من ذاكرة الوصول العشوائي.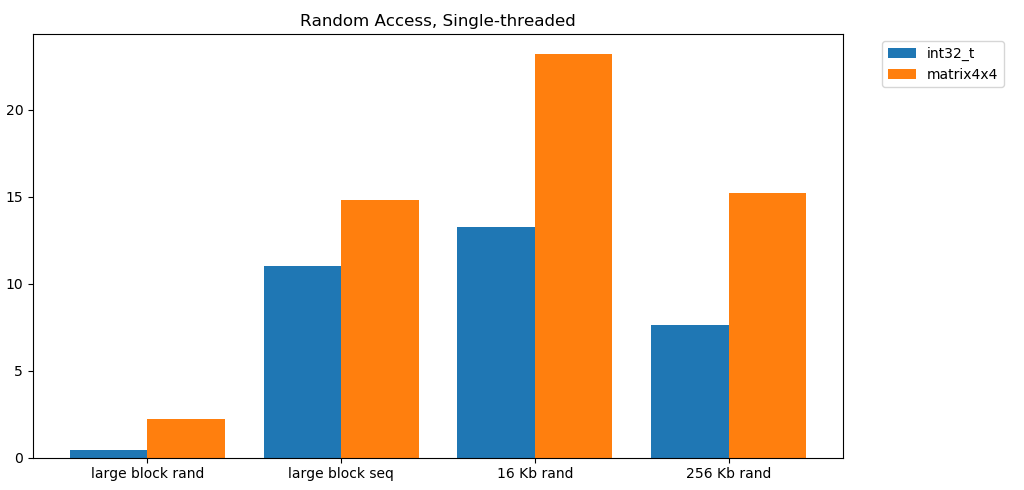 يجب هضمها. يمكن مقارنة الوصول العشوائي إلى ذاكرة التخزين المؤقت بسرعة الوصول التسلسلي إلى ذاكرة الوصول العشوائي. انخفاض من L1 16 كيلو بايت إلى L2 256 كيلو بايت فقط نصف أو أقل.أعتقد أن هذا سيكون له عواقب وخيمة.
يجب هضمها. يمكن مقارنة الوصول العشوائي إلى ذاكرة التخزين المؤقت بسرعة الوصول التسلسلي إلى ذاكرة الوصول العشوائي. انخفاض من L1 16 كيلو بايت إلى L2 256 كيلو بايت فقط نصف أو أقل.أعتقد أن هذا سيكون له عواقب وخيمة.تعتبر القوائم المرتبطة ضارة
مطاردة مؤشر (القفز على المؤشرات) أمر سيئ. سيء للغاية. كم هو انخفاض الأداء؟ انظر بنفسك. فعلت اختبار الإضافية التي يلتف matrix4x4في std::unique_ptr. كل وصول يمر من خلال المؤشر. هذه نتيجة كارثية رهيبة. موضوع واحد | matrix4x4 | unique_ptr | فرق |
-------------------- | --------------- | ------------ | -------- |
كتلة كبيرة - Seq | 14.8 جيجابايت / ثانية | 0.8 جيجابايت / ثانية | 19x |
16 كيلوبايت - Seq | 31.6 جيجابايت / ثانية | 2.2 جيجابايت / ثانية | 14x |
256 كيلوبايت - Seq | 22.2 جيجابايت / ثانية | 1.9 جيجا بايت / ثانية | 12x |
كتلة كبيرة - راند | 2.2 جيجابايت / ثانية | 0.1 جيجابايت / ثانية | 22x |
16 كيلوبايت - راند | 23.2 جيجابايت / ثانية | 1.7 جيجابايت / ثانية | 14x |
256 كيلوبايت - راند | 15.2 جيجابايت / ثانية | 0.8 جيجابايت / ثانية | 19x |
6 خيوط | matrix4x4 | unique_ptr | فرق |
-------------------- | --------------- | ------------ | -------- |
كتلة كبيرة - Seq | 34.4 جيجابايت / ثانية | 2.5 جيجا بايت / ثانية | 14x |
16 كيلوبايت - Seq | 154.8 جيجابايت / ثانية | 8.0 جيجابايت / ثانية | 19x |
256 كيلوبايت - Seq | 111.6 جيجابايت / ثانية | 5.7 جيجابايت / ثانية | 20x |
كتلة كبيرة - راند | 7.1 جيجابايت / ثانية | 0.4 جيجابايت / ثانية | 18x |
16 كيلوبايت - راند | 95.0 جيجابايت / ثانية | 7.8 جيجابايت / ثانية | 12x |
256 كيلوبايت - راند | 58.3 جيجابايت / ثانية | 1.6 جيجابايت / ثانية | 36x |يتم إجراء الجمع المتسلسل للقيم خلف المؤشر بسرعة أقل من 1 جيجابايت / ثانية. سرعة الوصول العشوائية المزدوجة للتخزين المؤقت هي 0.1 جيجابايت / ثانية فقط.يؤدي البحث عن مؤشر إلى إبطاء تنفيذ التعليمات البرمجية 10-20 مرة. لا تدع أصدقائك يستخدمون القوائم المرتبطة. يرجى التفكير في ذاكرة التخزين المؤقت.تقدير الميزانية للإطارات
من الشائع أن يضع مطورو الألعاب حدًا (ميزانية) للحمل على وحدة المعالجة المركزية ومقدار الذاكرة. لكنني لم أر أبدًا ميزانية النطاق الترددي.في الألعاب الحديثة ، تستمر FPS في النمو. الآن في 60 FPS. يعمل VR بتردد 90 هرتز. لدي شاشة ألعاب 144 هرتز. إنه رائع ، لذلك يبدو أن 60 إطارًا في الثانية مثل القرف. لن أعود إلى الشاشة القديمة. الرياضات واللافتات تراقب Twitch 240 هرتز. هذا العام ، قدمت شركة Asus وحشًا بقوة 360 هرتز في CES.يبلغ الحد الأقصى لمعالجتي حوالي 40 جيجابايت / ثانية. يبدو أن هذا عدد كبير! ومع ذلك ، على تردد 240 هرتز ، يتم الحصول على 167 ميغابايت فقط لكل إطار. يمكن للتطبيق الواقعي أن يولد حركة مرور 5 جيجا بايت / ثانية عند 144 هرتز ، وهو 69 ميجا بايت فقط لكل إطار.هنا جدول بأرقام قليلة. | 1 | 10 | 30 | 60 | 90 | 144 | 240 | 360 |
-------- | ------- | -------- | -------- | -------- | ------ - | -------- | -------- | -------- |
40 جيجابايت / ثانية | 40 غيغابايت | 4 جيجا بايت | 1.3 غيغابايت | 667 ميجا بايت | 444 ميجا بايت | 278 ميجا بايت | 167 ميجابايت | 111 ميجابايت |
10 جيجابايت / ثانية | 10 جيجا بايت | 1 جيجا بايت | 333 ميجا بايت | 166 ميجابايت | 111 ميجابايت | 69 ميغابايت | 42 ميجابايت | 28 ميجابايت |
1 جيجا بايت / ثانية | 1 جيجا بايت | 100 ميجابايت | 33 ميجابايت | 17 ميجابايت | 11 ميجابايت | 7 ميجا بايت | 4 ميجا بايت | 3 ميجا بايت |
يبدو لي أنه من المفيد تقييم المشاكل من هذا المنظور. هذا يوضح أن بعض الأفكار غير مجدية. ليس من السهل الوصول إلى 240 هرتز. هذا لن يحدث من تلقاء نفسه.الأرقام التي يجب أن يعرفها كل مبرمج (2020)
القائمة السابقة قديمة. الآن يجب تحديثه والامتثال بحلول عام 2020.فيما يلي بعض الأرقام لجهاز الكمبيوتر في المنزل. هذا مزيج من AIDA64 ، ساندرا وعلاماتي. لا تعطي الأرقام صورة كاملة وهي مجرد نقطة بداية.الكمون L1: 1 ns
تأخير L2: 2.5 نانوثانية
تأخير L3: 10 نانو ثانية
زمن وصول ذاكرة الوصول العشوائي: 50 نانوثانية
(لكل خيط)
نطاق L1: 210 جيجابايت / ثانية
النطاق L2: 80 جيجابايت / ثانية
النطاق L3: 60 جيجابايت / ثانية
(النظام بأكمله)
نطاق ذاكرة الوصول العشوائي: 45 جيجابايت / ثانية
سيكون من الجيد إنشاء معيار صغير وبسيط مفتوح المصدر. بعض ملفات C التي يمكن تشغيلها على أجهزة الكمبيوتر المكتبية والخوادم والأجهزة المحمولة ووحدات التحكم وما إلى ذلك. لكني لست من النوع الذي يكتب مثل هذه الأداة.إنكار المسؤولية
قياس عرض النطاق الترددي للذاكرة أمر صعب. صعب جدا. ربما توجد أخطاء في الكود الخاص بي. العديد من العوامل غير المعلومة. إذا كان لديك بعض الانتقادات لتقنيتي ، فأنت على الأرجح محق.في النهاية ، أعتقد أن هذا أمر طبيعي. لا تتناول هذه المقالة الأداء الدقيق لسطح المكتب. هذا بيان مشكلة من وجهة نظر معينة. وحول كيفية تعلم كيفية القيام ببعض الحسابات الرياضية التقريبية.استنتاج
شارك أحد الزملاء رأيًا مثيرًا للاهتمام حول عرض النطاق الترددي لذاكرة GPU وأداء التطبيق. دفعني هذا إلى دراسة أداء الذاكرة على أجهزة الكمبيوتر الحديثة.للحسابات التقريبية ، إليك بعض الأرقام لسطح المكتب الحديث:- أداء ذاكرة الوصول العشوائي
- أقصى:
45 / - في المتوسط ، تقريبًا:
5 / - الحد الأدنى:
1 /
- أداء ذاكرة التخزين المؤقت L1 / L2 / L3 (لكل مركز)
- الحد الأقصى (ج سيمد):
210 // 80 //60 / - في المتوسط ، حوالي:
25 // 15 //9 / - الحد الأدنى:
13 // 8 //3,5 /
ترتبط تقييمات العينة بالأداء matrix4x4. الكود الحقيقي لن يكون بهذه البساطة. ولكن بالنسبة للحسابات على منديل ، هذه نقطة بداية معقولة. تحتاج إلى ضبط هذا الرقم بناءً على أنماط الوصول إلى الذاكرة في برنامجك ، وخصائص معداتك ورمزك.ومع ذلك ، فإن أهم شيء هو طريقة جديدة للتفكير في المشاكل. يعد عرض المشكلة بالبايت في الثانية أو البايتات لكل إطار عدسة أخرى يجب النظر إليها. هذه أداة مفيدة فقط في حالة.شكرا للقراءة.مصدر
بيانات معيار C ++PythonGraph.jsonمزيد من البحوث
تطرق هذا المقال قليلا فقط على الموضوع. ربما لن أخوض في ذلك. ولكن إذا فعل ذلك ، فيمكنه تغطية بعض الجوانب التالية:خصائص النظام
تم إجراء الاختبارات على جهاز الكمبيوتر في المنزل. فقط إعدادات المخزون ، لا رفع تردد التشغيل.- نظام التشغيل: Windows 10 v1903 build 18362
- المعالج: Intel i7-8700k @ 3.70 GHz
- ذاكرة الوصول العشوائي: 2x16 GSkill Ripjaw DDR4-3200 (16-18-18-38 @ 1600 MHz)
- اللوحة الأم: Asus TUF Z370-Plus Gaming