 عندما تتجاوز مشكلات التحليلات الأدوات المعدة مسبقًا ، ربما حان الوقت لتختار قاعدة بيانات للتحليلات. لا يجب كتابة نصوص الاستعلامات إلى قاعدة بيانات العمل ، لأنه يمكنك تغيير ترتيب البيانات ، وعلى الأرجح ، إبطاء التطبيق.يمكنك أيضًا حذف معلومات مهمة عن طريق الخطأ إذا عمل محللون أو مهندسون هناك.للتحليل ، تحتاج إلى نوع منفصل من قاعدة البيانات. ولكن أيهما صحيح؟في هذا المنشور ، سننظر في العروض وأفضل الممارسات لشركة متوسطة بدأت للتو العمل. أيًا كان الإعداد الذي تختاره ، يمكنك العثور على حل وسط في المستقبل لتحسين الأداء على ما نناقشه هنا.من خلال العمل مع عدد كبير من العملاء ، وجدنا أن أهم المعايير التي يجب أخذها في الاعتبار هي:
عندما تتجاوز مشكلات التحليلات الأدوات المعدة مسبقًا ، ربما حان الوقت لتختار قاعدة بيانات للتحليلات. لا يجب كتابة نصوص الاستعلامات إلى قاعدة بيانات العمل ، لأنه يمكنك تغيير ترتيب البيانات ، وعلى الأرجح ، إبطاء التطبيق.يمكنك أيضًا حذف معلومات مهمة عن طريق الخطأ إذا عمل محللون أو مهندسون هناك.للتحليل ، تحتاج إلى نوع منفصل من قاعدة البيانات. ولكن أيهما صحيح؟في هذا المنشور ، سننظر في العروض وأفضل الممارسات لشركة متوسطة بدأت للتو العمل. أيًا كان الإعداد الذي تختاره ، يمكنك العثور على حل وسط في المستقبل لتحسين الأداء على ما نناقشه هنا.من خلال العمل مع عدد كبير من العملاء ، وجدنا أن أهم المعايير التي يجب أخذها في الاعتبار هي:- نوع البيانات التي تم تحليلها
- كم لديك من البيانات؟
- تركيز فريق الهندسة الخاص بك
- مدى السرعة التي تحتاج إلى المعلومات
ما أنواع البيانات التي تقوم بتحليلها؟
فكر في البيانات التي تريد تحليلها. هل تتناسب بشكل جيد مع الصفوف والأعمدة مثل جدول بيانات Excel ضخم؟ أو سيكون من المنطقي إذا وضعتها في مستند Word؟إذا أجبت على Excel ، فستناسب قاعدة بيانات علائقية مثل Postgres أو MySQL أو Amazon Redshift أو BigQuery احتياجاتك. تعد قواعد البيانات العلائقية المنظمة هذه رائعة عندما تعرف بالضبط ما هي البيانات التي ستتلقاها وكيف ترتبط ببعضها البعض - بشكل أساسي ، كيف ترتبط الصفوف والأعمدة. بالنسبة لمعظم أنواع تحليل المستخدم ، تعمل قواعد البيانات العلائقية بشكل جيد. تتناسب سمات المستخدم مثل الأسماء ورسائل البريد الإلكتروني وخطط الفوترة بشكل مثالي مع الجدول ، مثل أحداث المستخدم وخصائصه .من ناحية أخرى ، إذا كانت بياناتك مناسبة بشكل أفضل على قطعة من الورق ، فيجب عليك الرجوع إلى قاعدة بيانات غير علائقية (NoSQL) مثل Hadoop أو Mongo.تتميز قواعد البيانات غير العلائقية بعدد كبير جدًا من القيم الخاصة (بالملايين) من البيانات شبه المنظمة. الأمثلة الكلاسيكية للبيانات شبه المنظمة هي نصوص مثل البريد الإلكتروني والكتب والشبكات الاجتماعية والبيانات السمعية البصرية والبيانات الجغرافية. إذا كنت تقوم بالكثير من عمليات استخراج النصوص أو معالجة اللغة أو معالجة الصور ، فستحتاج على الأرجح إلى استخدام مخازن البيانات غير العلائقية.
ما مقدار البيانات التي تتعامل معها؟
السؤال التالي الذي يجب أن تطرحه على نفسك هو مقدار البيانات التي تتعامل معها. كلما زادت البيانات لديك ، زادت فائدة قاعدة البيانات غير الارتباطية ، لأنها لن تفرض قيودًا على البيانات الواردة ، مما سيسمح لك بالكتابة إلى قاعدة البيانات بشكل أسرع. هذه ليست قيودًا صارمة ، ويمكن لكل واحد معالجة بيانات أكثر أو أقل اعتمادًا على عوامل مختلفة ، لكننا وجدنا أن كل قاعدة بيانات تعمل بشكل مثالي ضمن هذه الحدود.إذا كان لديك أقل من 1 تيرابايت من البيانات ، فستحصل مع Postgres على أداء جيد. لكنه يتباطأ عند حوالي 6 تيرابايت. إذا كنت تحب MySQL ولكنك تحتاج إلى نطاق أكبر قليلاً ، يمكن أن يصل Aurora (إصدار أمازون الخاص) إلى 64 تيرابايت. بالنسبة لحجم البيتابايت ، يعد Amazon Redshift عادةً خيارًا جيدًا لأنه محسن للتحليلات حتى 2PB. للمعالجة المتوازية أو حتى بيانات MOAR ، ربما حان الوقت لإلقاء نظرة على Hadoop.ومع ذلك ، أخبرتنا AWS أنهم يشغلون Amazon.com على Redshift ، لذلك إذا كان لديك فريق DBA من الدرجة الأولى ، فقد تتمكن من التوسع إلى ما هو أبعد من "حد" 2PB.
هذه ليست قيودًا صارمة ، ويمكن لكل واحد معالجة بيانات أكثر أو أقل اعتمادًا على عوامل مختلفة ، لكننا وجدنا أن كل قاعدة بيانات تعمل بشكل مثالي ضمن هذه الحدود.إذا كان لديك أقل من 1 تيرابايت من البيانات ، فستحصل مع Postgres على أداء جيد. لكنه يتباطأ عند حوالي 6 تيرابايت. إذا كنت تحب MySQL ولكنك تحتاج إلى نطاق أكبر قليلاً ، يمكن أن يصل Aurora (إصدار أمازون الخاص) إلى 64 تيرابايت. بالنسبة لحجم البيتابايت ، يعد Amazon Redshift عادةً خيارًا جيدًا لأنه محسن للتحليلات حتى 2PB. للمعالجة المتوازية أو حتى بيانات MOAR ، ربما حان الوقت لإلقاء نظرة على Hadoop.ومع ذلك ، أخبرتنا AWS أنهم يشغلون Amazon.com على Redshift ، لذلك إذا كان لديك فريق DBA من الدرجة الأولى ، فقد تتمكن من التوسع إلى ما هو أبعد من "حد" 2PB.ما الذي يركز عليه فريقك الهندسي؟
هذا سؤال مهم آخر لطرحه على نفسك عند مناقشة قاعدة البيانات. كلما كان فريقك بشكل عام أصغر ، زاد احتمال تركيز مهندسيك بشكل أساسي على إنشاء المنتج ، بدلاً من معالجة البيانات وإدارتها. سيؤثر عدد الأشخاص الذين يمكنك تخصيصهم لهذه المشاريع بشكل كبير على خياراتك.مع بعض الموارد الهندسية ، لديك المزيد من الخيارات - يمكنك الانتقال إلى قاعدة بيانات علائقية أو غير علائقية. تستغرق قواعد البيانات العلائقية وقتًا أقل من NoSQL.إذا كان لديك العديد من المهندسين الذين يعملون على التثبيت ، ولكن لا يمكنك إحضار أي شخص إلى الخدمة ، فاختر شيئًا مثل Postgres أو Google SQL (استضافة MySQL اختيارية) أو مستودعات Segment.(استضافة Redshift) ربما يكون خيارًا أفضل من Redshift أو Aurora أو BigQuery ، لأنها تتطلب تصحيحًا دوريًا لمعالجة البيانات. إذا كان لديك المزيد من الوقت للخدمة ، فإن اختيار Redshift أو BigQuery سيوفر استعلامات أسرع وأوسع نطاقًا.تتمتع قواعد البيانات العلائقية بميزة أخرى: يمكنك استخدام SQL للاستعلام عنها. SQL معروفة جيدًا لكل من المحللين والمهندسين ، وهي أسهل في التعلم من معظم لغات البرمجة.من ناحية أخرى ، تتطلب تحليلات البيانات شبه المنظمة عادة ، كحد أدنى ، خبرة في البرمجة الموجهة للكائنات أو ، أفضل ، تجربة كتابة التعليمات البرمجية للعمل مع البيانات الكبيرة. حتى مع ظهور أدوات التحليلات مثل Hunkبالنسبة إلى Hadoop أو Slamdata لـ MongoDB ، ستحتاج إلى محلل متمرس أو أخصائي بيانات لتحليل هذه الأنواع من قواعد البيانات.ما مدى سرعة احتياجك لهذه البيانات؟
في حين أن "التحليلات في الوقت الفعلي" تحظى بشعبية كبيرة في حالات مثل كشف الاحتيال ومراقبة النظام ، فإن معظم التحليلات لا تتطلب بيانات في الوقت الفعلي أو تحليل فوري.عندما تجيب على أسئلة ، على سبيل المثال ، ما الذي يسبب تدفق المستخدمين الخارجيين أو كيفية تحول الأشخاص من تطبيقك إلى موقع الويب الخاص بك ، فإن الوصول إلى بياناتك بتأخير بسيط (فترات كل ساعة أو يومية) مقبول تمامًا. لا تتغير بياناتك دقيقة بدقيقة.لذلك ، إذا كنت تعمل بشكل أساسي على التحليل الفعلي ، فيجب عليك الرجوع إلى قاعدة بيانات محسنة للتحليلات ، مثل Redshift أو BigQuery. تم تصميم قواعد البيانات هذه لاستيعاب كمية كبيرة من البيانات وقراءة البيانات ودمجها بسرعة ، مما يجعل الاستعلامات سريعة. يمكنهم أيضًا تنزيل البيانات بسرعة كافية (كل ساعة) أثناء قيام شخص بعملية تنظيف وتغيير حجم الكتلة ومراقبتها.إذا كنت بحاجة إلى بيانات في الوقت الفعلي تمامًا ، فيجب عليك اللجوء إلى قاعدة بيانات غير منظمة مثل Hadoop. يمكنك تصميم قاعدة بيانات Hadoop الخاصة بك بحيث يتم تحميل البيانات إليها بسرعة كبيرة ، على الرغم من أن الاستعلام عنها قد يستغرق وقتًا أطول اعتمادًا على استخدام ذاكرة الوصول العشوائي ومساحة القرص المتوفرة وهيكل البيانات.Postgres مقابل أمازون Redshift مقابل. استعلام جوجل
ربما أدركت بالفعل أن قاعدة البيانات العلائقية ستكون الخيار الأفضل لتحليل معظم أنواع سلوك المستخدم. يمكن أن تتناسب المعلومات حول كيفية تفاعل المستخدمين مع موقعك وتطبيقاتك بسهولة في شكل منظم.analytics.track('Completed Order') — select * from ios.completed_order
 لذا فإن السؤال هو أي قاعدة بيانات SQL لاستخدامها؟ يجب مراعاة أربعة معايير.
لذا فإن السؤال هو أي قاعدة بيانات SQL لاستخدامها؟ يجب مراعاة أربعة معايير.الحجم مقابل سرعة
عندما تحتاج إلى سرعة ، يجدر التفكير في Postgres: بالنسبة لقاعدة بيانات أقل من 1 تيرابايت ، فإن Postgres سريع جدًا في تحميل البيانات والاستعلامات. بالإضافة إلى أنه متاح. مع اقترابك من 6 تيرابايت (الموروث من Amazon RDS) ، ستعمل استفساراتك بشكل أبطأ.لذلك ، عندما تحتاج إلى حجم أكبر ، فإننا عادةً ما نوصي باستخدام Redshift. تظهر تجربتنا أن Redshift لديه أفضل قيمة مقابل المال.تمييز SQL
Redshift مبني على مجموعة متنوعة من Postgres ، وكلاهما يدعم لغة SQL القديمة الجيدة. الانزياح نحو الأحمر لا يدعم كافة أنواع البيانات و ظائف هذا بوستجرس الدعم، وإنما هو أقرب إلى معيار الصناعة من الاستعلام الشامل، التي لديها SQL الخاصة به.على عكس العديد من الأنظمة الأخرى المستندة إلى SQL ، يستخدم BigQuery بناء الجملة المفصول بفواصل للإشارة إلى عمليات ربط الجدول ، وليس وفقًا لوثائق SQL . هذا يعني أنه بدون تحذير ، يمكن أن تؤدي استعلامات SQL إلى أخطاء أو نتائج غير متوقعة. لذلك ، لا تستطيع العديد من الفرق التي التقينا بها إقناع محلليها بتعلم BigQuery SQL.النظام البيئي للغير
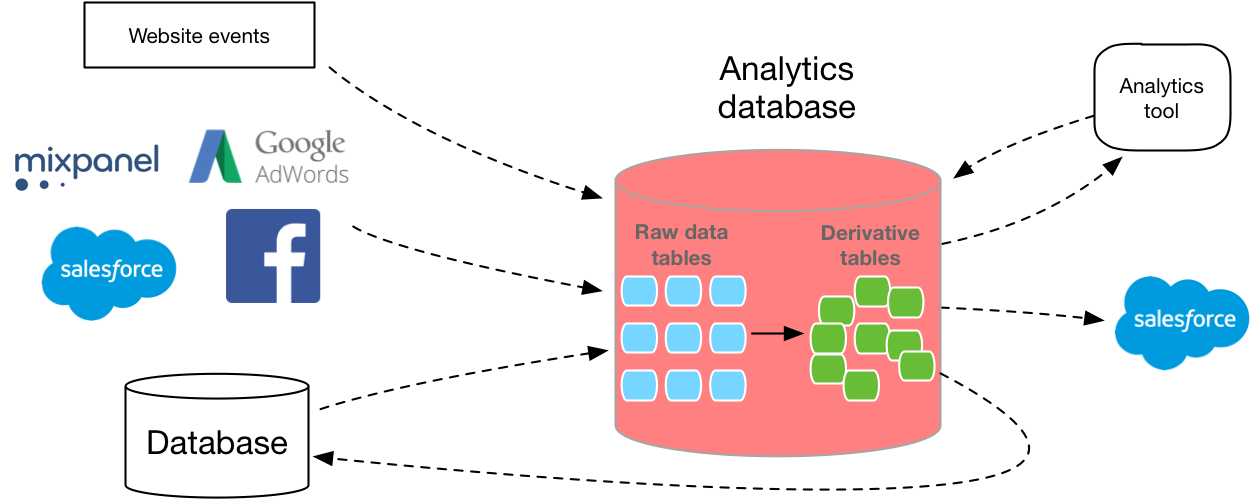
نادرًا ما يعيش مستودع بياناتك بمفرده. تحتاج إلى وضع البيانات في قاعدة بيانات ، بالإضافة إلى ذلك ، تحتاج إلى استخدام نوع من البرامج لتحليلها. (ما لم تقم بتشغيل استعلام SQL من سطر الأوامر).لذلك ، غالبًا ما يحب الناس ذلك Redshift لديه نظام بيئي كبير جدًا من أدوات الطرف الثالث. تمتلك AWS إمكانات مثل Segment Data Warehouse لتحميل البيانات إلى Redshift من واجهة برمجة التطبيقات التحليلية ، كما أنها تعمل أيضًا مع جميع أدوات تصور البيانات تقريبًا في السوق. يتصل عدد أقل من خدمات الجهات الخارجية بـ Google ، لذا قد يستغرق نقل نفس البيانات إلى BigQuery وقتًا أطول للتطوير ، ولن يكون لديك الكثير من الخيارات لبرنامج BI.يمكنك أن ترى شركاء أمازونهنا وجوجل هنا .ومع ذلك ، إذا كنت تستخدم Google Cloud Storage بالفعل بدلاً من Amazon S3 ، فقد يكون من المفيد لك البقاء في نظام Google البيئي. تعمل كلتا الخدمتين على تبسيط تحميل البيانات إذا كانت موجودة بالفعل في مستودع التخزين السحابي المقابل ، لذلك ، على الرغم من أنها لن تنتهك شروط الاستخدام ، فسيكون الأمر أسهل بكثير إذا توقفت عن استخدام أحد هؤلاء المزودين.تدريب
الآن بعد أن أصبحت لديك فكرة أوضح عن قاعدة البيانات التي ستستخدمها ، فإن الخطوة التالية هي معرفة كيف ستجمع البيانات في قاعدة البيانات.يستخف العديد من مطوري قواعد البيانات الجدد بمدى صعوبة بناء خط أنابيب بيانات قابلة للتطوير. يجب عليك كتابة طبقة الاستخراج الخاصة بك ، وواجهة برمجة التطبيقات لجمع البيانات ، وطبقة الاستعلام والتحويل. ويجب على الجميع التوسع. بالإضافة إلى ذلك ، تحتاج إلى تحديد التخطيط الصحيح بناءً على حجم ونوع كل عمود. يكرر MVP قاعدة بيانات الإنتاج الخاصة بك إلى مثيل جديد ، ولكن هذا يعني عادة استخدام قاعدة بيانات غير محسنة للتحليلات.لحسن الحظ ، هناك العديد من الخيارات في السوق التي يمكن أن تساعدك في التغلب على بعض هذه العقبات وإجراء ETL تلقائيًا لك.ولكن سواء كان ذلك تطويرك أو شرائك ، فإن الحصول على البيانات في SQL يستحق ذلك.استنادًا إلى بيانات المستخدم الأولية ، باستخدام تنسيق SQL المرن فقط ، ستتمكن من الإجابة بالتفصيل على الأسئلة حول ما يفعله عملاؤك ، وتقييم التوزيع بدقة ، وفهم السلوك عبر الأنظمة الأساسية ، وإنشاء لوحات تحكم لشركة معينة ، وأكثر من ذلك بكثير.