تحسين استعلام PostgreSQL الضخم. كيريل بوروفيكوف (تينسور)
يقدم التقرير بعض الأساليب التي تسمح لك بمراقبة أداء استعلامات SQL عند وجود الملايين منها يوميًا ، ومئات من خوادم PostgreSQL التي يتم التحكم فيها.ما هي الحلول التقنية التي تسمح لنا بمعالجة مثل هذا الحجم من المعلومات بكفاءة ، وكيف تسهل حياة المطور العادي.من يهتم بتحليل مشكلات معينة وتقنيات مختلفة لتحسين استعلامات SQL وحل مشكلات DBA النموذجية في PostgreSQL ؟ يمكنك أيضًا قراءة سلسلة من المقالات حول هذا الموضوع. اسمي كيريل بوروفيكوف ، أمثل شركة "Tensor" . على وجه التحديد ، أنا متخصص في العمل مع قواعد البيانات في شركتنا.اليوم ، سأخبرك كيف نقوم بتحسين الاستعلام ، عندما لا تحتاج إلى "التقاط" أداء طلب واحد ، ولكن لحل المشكلة بشكل جماعي. عندما يكون هناك الملايين من الطلبات ، وتحتاج إلى إيجاد بعض الأساليب لحل هذه المشكلة الكبيرة.بشكل عام ، "Tensor" لملايين عملائنا هو VLSI - تطبيقنا : شبكة اجتماعية مؤسسية ، حلول اتصالات الفيديو ، لإدارة المستندات الداخلية والخارجية ، أنظمة محاسبية لحفظ الدفاتر والتخزين ... أي ، هذا "الجمع الضخم" لإدارة الأعمال المتكاملة ، وهو أكثر من 100 مشروع داخلي مختلف.للتأكد من أنها تعمل جميعها وتتطور بشكل طبيعي ، لدينا 10 مراكز تطوير في جميع أنحاء البلاد ، ولديها أكثر من 1000 مطور .نحن نعمل مع PostgreSQL منذ عام 2008 وقد تراكمت لدينا كمية كبيرة مما نعالجه - هذه هي بيانات العميل ، والإحصاءات ، والتحليل ، والبيانات من أنظمة المعلومات الخارجية - أكثر من 400 تيرابايت . فقط "في الإنتاج" هناك حوالي 250 خادمًا ، وإجماليًا خوادم قواعد البيانات التي نراقبها حوالي 1000.
اسمي كيريل بوروفيكوف ، أمثل شركة "Tensor" . على وجه التحديد ، أنا متخصص في العمل مع قواعد البيانات في شركتنا.اليوم ، سأخبرك كيف نقوم بتحسين الاستعلام ، عندما لا تحتاج إلى "التقاط" أداء طلب واحد ، ولكن لحل المشكلة بشكل جماعي. عندما يكون هناك الملايين من الطلبات ، وتحتاج إلى إيجاد بعض الأساليب لحل هذه المشكلة الكبيرة.بشكل عام ، "Tensor" لملايين عملائنا هو VLSI - تطبيقنا : شبكة اجتماعية مؤسسية ، حلول اتصالات الفيديو ، لإدارة المستندات الداخلية والخارجية ، أنظمة محاسبية لحفظ الدفاتر والتخزين ... أي ، هذا "الجمع الضخم" لإدارة الأعمال المتكاملة ، وهو أكثر من 100 مشروع داخلي مختلف.للتأكد من أنها تعمل جميعها وتتطور بشكل طبيعي ، لدينا 10 مراكز تطوير في جميع أنحاء البلاد ، ولديها أكثر من 1000 مطور .نحن نعمل مع PostgreSQL منذ عام 2008 وقد تراكمت لدينا كمية كبيرة مما نعالجه - هذه هي بيانات العميل ، والإحصاءات ، والتحليل ، والبيانات من أنظمة المعلومات الخارجية - أكثر من 400 تيرابايت . فقط "في الإنتاج" هناك حوالي 250 خادمًا ، وإجماليًا خوادم قواعد البيانات التي نراقبها حوالي 1000. SQL هي لغة تعريفية. أنت تصف ليس "كيف" يجب أن يعمل شيء ما ، ولكن "ماذا" تريد الحصول عليه. يعرف DBMS بشكل أفضل كيفية الانضمام - كيفية توصيل الأجهزة اللوحية الخاصة بك ، وما هي الشروط التي يجب فرضها ، وما الذي سيتم حسب الفهرس ، وما لا ...تقبل بعض DBMSs تلميحات: "لا ، قم بتوصيل هذين الجهازين في قائمة الانتظار هذه" ، ولكن PostgreSQL لا يفعل ذلك. هذا هو الموقف الواعي للمطورين الرائدين: "من الأفضل إنهاء محسن الاستعلام بدلاً من السماح للمطورين باستخدام نوع من التلميحات".ولكن ، على الرغم من حقيقة أن PostgreSQL لا تسمح "للخارج" بالتحكم في نفسها ، فإنها تسمح لك تمامًا بمعرفة ما يحدث "بالداخل" عند تنفيذ استعلامك وحيث توجد مشكلات.
SQL هي لغة تعريفية. أنت تصف ليس "كيف" يجب أن يعمل شيء ما ، ولكن "ماذا" تريد الحصول عليه. يعرف DBMS بشكل أفضل كيفية الانضمام - كيفية توصيل الأجهزة اللوحية الخاصة بك ، وما هي الشروط التي يجب فرضها ، وما الذي سيتم حسب الفهرس ، وما لا ...تقبل بعض DBMSs تلميحات: "لا ، قم بتوصيل هذين الجهازين في قائمة الانتظار هذه" ، ولكن PostgreSQL لا يفعل ذلك. هذا هو الموقف الواعي للمطورين الرائدين: "من الأفضل إنهاء محسن الاستعلام بدلاً من السماح للمطورين باستخدام نوع من التلميحات".ولكن ، على الرغم من حقيقة أن PostgreSQL لا تسمح "للخارج" بالتحكم في نفسها ، فإنها تسمح لك تمامًا بمعرفة ما يحدث "بالداخل" عند تنفيذ استعلامك وحيث توجد مشكلات. بشكل عام ، ما هي المشاكل الكلاسيكية التي عادةً ما يطوِّرها المطور [يأتي إلى DBA]؟ "هنا قمنا بتلبية الطلب ، وكل شيء بطيء ، كل شيء معلق ، يحدث شيء ... نوع من المشاكل!"الأسباب هي نفسها دائمًا تقريبًا:
بشكل عام ، ما هي المشاكل الكلاسيكية التي عادةً ما يطوِّرها المطور [يأتي إلى DBA]؟ "هنا قمنا بتلبية الطلب ، وكل شيء بطيء ، كل شيء معلق ، يحدث شيء ... نوع من المشاكل!"الأسباب هي نفسها دائمًا تقريبًا:
: « SQL 10 JOIN...» — , «», . , (10 FROM) - . []
PostgreSQL, «» , — «» . 10 , 10 , PostgreSQL , . []- «»
, , , . … - , .
, (INSERT, UPDATE, DELETE) — .
... ولأي شيء آخر ، نحن بحاجة إلى خطة ! نحن بحاجة لمعرفة ما يحدث داخل الخادم. خطة تنفيذ الاستعلام لـ PostgreSQL هي شجرة خوارزمية تنفيذ الاستعلام في تمثيل نصي. إنها الخوارزمية ، نتيجة للتحليل من قبل المخطط ، تم الاعتراف بها على أنها الأكثر فعالية.كل عقدة شجرة هي عملية: استخراج البيانات من جدول أو فهرس ، أو إنشاء صورة نقطية ، أو ربط جدولين ، أو الانضمام ، أو التقاطع ، أو حذف العينات. إنجاز الطلب هو ممر من خلال عقد هذه الشجرة.للحصول على خطة استعلام ، فإن أسهل طريقة هي تنفيذ العبارة
خطة تنفيذ الاستعلام لـ PostgreSQL هي شجرة خوارزمية تنفيذ الاستعلام في تمثيل نصي. إنها الخوارزمية ، نتيجة للتحليل من قبل المخطط ، تم الاعتراف بها على أنها الأكثر فعالية.كل عقدة شجرة هي عملية: استخراج البيانات من جدول أو فهرس ، أو إنشاء صورة نقطية ، أو ربط جدولين ، أو الانضمام ، أو التقاطع ، أو حذف العينات. إنجاز الطلب هو ممر من خلال عقد هذه الشجرة.للحصول على خطة استعلام ، فإن أسهل طريقة هي تنفيذ العبارة EXPLAIN. للحصول على جميع السمات الحقيقية ، فعليك تنفيذ استعلام قائم على - EXPLAIN (ANALYZE, BUFFERS) SELECT ....النقطة السيئة: عند تنفيذها ، يحدث "هنا والآن" ، وبالتالي فهي مناسبة فقط لتصحيح الأخطاء المحلية. إذا كنت تستخدم خادمًا عالي التحميل ، والذي يخضع لتدفق قوي من تغييرات البيانات ، وسترى: "حسنًا! نحن هنا أبطأ في طلب شيا ". منذ نصف ساعة ، قبل ساعة - أثناء تشغيلك والحصول على هذا الطلب من السجلات ، وحمله مرة أخرى إلى الخادم ، تم تغيير مجموعة البيانات والإحصاءات بالكامل. يمكنك تنفيذه لتصحيح الأخطاء - ويعمل بسرعة! ولا يمكنك أن تفهم لماذا ، لماذا كانت بطيئة. من أجل فهم ما كان بالضبط في اللحظة التي يتم فيها تنفيذ الطلب على الخادم ، كتب الأشخاص الأذكياء وحدة auto_explain module. إنه موجود في جميع توزيعات PostgreSQL الأكثر شيوعًا ، ويمكنك ببساطة تنشيطه في ملف التكوين.إذا كان يفهم أن الطلب يتم تنفيذه لفترة أطول من الحدود التي أخبرته بها ، فإنه يأخذ "لقطة" للخطة الخاصة بهذا الطلب ويكتبها معًا في سجل .
من أجل فهم ما كان بالضبط في اللحظة التي يتم فيها تنفيذ الطلب على الخادم ، كتب الأشخاص الأذكياء وحدة auto_explain module. إنه موجود في جميع توزيعات PostgreSQL الأكثر شيوعًا ، ويمكنك ببساطة تنشيطه في ملف التكوين.إذا كان يفهم أن الطلب يتم تنفيذه لفترة أطول من الحدود التي أخبرته بها ، فإنه يأخذ "لقطة" للخطة الخاصة بهذا الطلب ويكتبها معًا في سجل . يبدو أن كل شيء على ما يرام الآن ، نذهب إلى السجل ونرى هناك ... [خطوة بخطوة]. لكن لا يمكننا قول أي شيء عنه ، باستثناء حقيقة أن هذه خطة ممتازة ، لأنها استغرقت 11 ملي ثانية.يبدو أن كل شيء على ما يرام - ولكن لا يوجد شيء واضح بشأن ما حدث بالفعل. بالإضافة إلى الوقت الإجمالي ، لا نرى الكثير. لأن النظر إلى مثل هذا النص العادي "latuha" هو محبوب بشكل عام.ولكن حتى لو كان محبوبًا ، وإن كان غير مريح ، ولكن هناك مشاكل أكبر:
يبدو أن كل شيء على ما يرام الآن ، نذهب إلى السجل ونرى هناك ... [خطوة بخطوة]. لكن لا يمكننا قول أي شيء عنه ، باستثناء حقيقة أن هذه خطة ممتازة ، لأنها استغرقت 11 ملي ثانية.يبدو أن كل شيء على ما يرام - ولكن لا يوجد شيء واضح بشأن ما حدث بالفعل. بالإضافة إلى الوقت الإجمالي ، لا نرى الكثير. لأن النظر إلى مثل هذا النص العادي "latuha" هو محبوب بشكل عام.ولكن حتى لو كان محبوبًا ، وإن كان غير مريح ، ولكن هناك مشاكل أكبر:- . , Index Scan — , - . , «» , CTE — « ».
- : , , — . , , , , loops — . . , , , — - « ».
في ظل هذه الظروف ، افهم "من هو الرابط الأضعف؟" يكاد يكون غير واقعي. لذلك ، حتى المطورين أنفسهم في "الدليل" يكتبون أن "فهم الخطة هو فن يحتاج إلى التعلم والخبرة ..." .ولكن لدينا 1000 مطور ، ولن ينقل كل منهم هذه التجربة إلى رؤوسهم. أنا وأنت - هم يعرفون ، وشخص ما هناك - لم يعد هناك. ربما سيتعلم ، أو ربما لا ، لكنه يحتاج إلى العمل الآن - ومن أين سيحصل على هذه التجربة.تخطيط التصور
لذلك ، أدركنا أنه من أجل التعامل مع هذه المشاكل ، نحتاج إلى تصور جيد للخطة . [مقالة]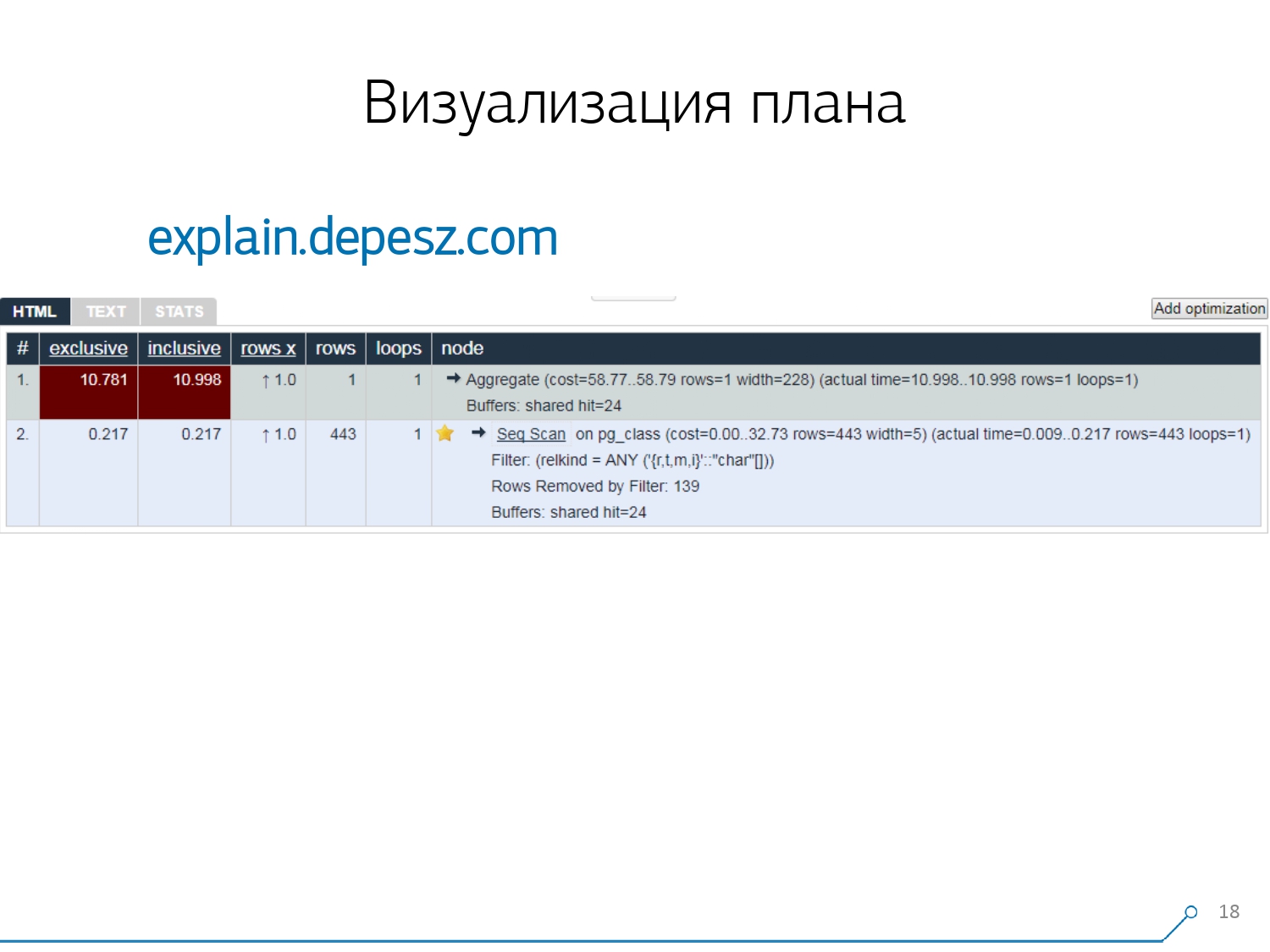 ذهبنا أولاً "حول السوق" - دعنا ننظر على الإنترنت إلى ما هو موجود بشكل عام.ولكن اتضح أن الحلول "الحية" نسبيًا والتي تكون أكثر أو أقل تطورًا ، هناك عدد قليل جدًا - حرفياً ، شيء واحد: شرح.depesz.com من Hubert Lubaczewski . عند مدخل الحقل "تغذية" تمثيل نصي للخطة ، يظهر لك لوحة مع البيانات المحللة:
ذهبنا أولاً "حول السوق" - دعنا ننظر على الإنترنت إلى ما هو موجود بشكل عام.ولكن اتضح أن الحلول "الحية" نسبيًا والتي تكون أكثر أو أقل تطورًا ، هناك عدد قليل جدًا - حرفياً ، شيء واحد: شرح.depesz.com من Hubert Lubaczewski . عند مدخل الحقل "تغذية" تمثيل نصي للخطة ، يظهر لك لوحة مع البيانات المحللة:- وقت عمل العقدة المناسبة
- إجمالي الوقت على الشجرة الفرعية بأكملها
- عدد السجلات التي تم استردادها والتي كانت متوقعة إحصائيًا
- الجسم العقدة نفسها
يمكن لهذه الخدمة أيضًا مشاركة أرشيف الروابط. لقد ألقيت خطتك هناك وتقول: "مرحبًا ، فازيا ، إليك رابط لك ، هناك خطأ ما." ولكن هناك بعض المشاكل البسيطة.أولاً ، كمية كبيرة من لصق النسخ. تأخذ قطعة من السجل ، وتضعها هناك ، مرارا وتكرارا.ثانيًا ، لا يوجد تحليل لكمية البيانات المقروءة - المخازن المؤقتة التي تعرضها
ولكن هناك بعض المشاكل البسيطة.أولاً ، كمية كبيرة من لصق النسخ. تأخذ قطعة من السجل ، وتضعها هناك ، مرارا وتكرارا.ثانيًا ، لا يوجد تحليل لكمية البيانات المقروءة - المخازن المؤقتة التي تعرضها EXPLAIN (ANALYZE, BUFFERS)، هنا لا نرى. فهو ببساطة لا يعرف كيفية تفكيكها وفهمها والعمل معها. عندما تقرأ الكثير من البيانات وتفهم أنه يمكنك "التحلل" بشكل غير صحيح على القرص وذاكرة التخزين المؤقت في الذاكرة ، فإن هذه المعلومات مهمة جدًا.النقطة السلبية الثالثة هي التطور الضعيف للغاية لهذا المشروع. العمليات صغيرة جدًا ، إنها جيدة إذا كانت كل ستة أشهر ، والرمز في بيرل.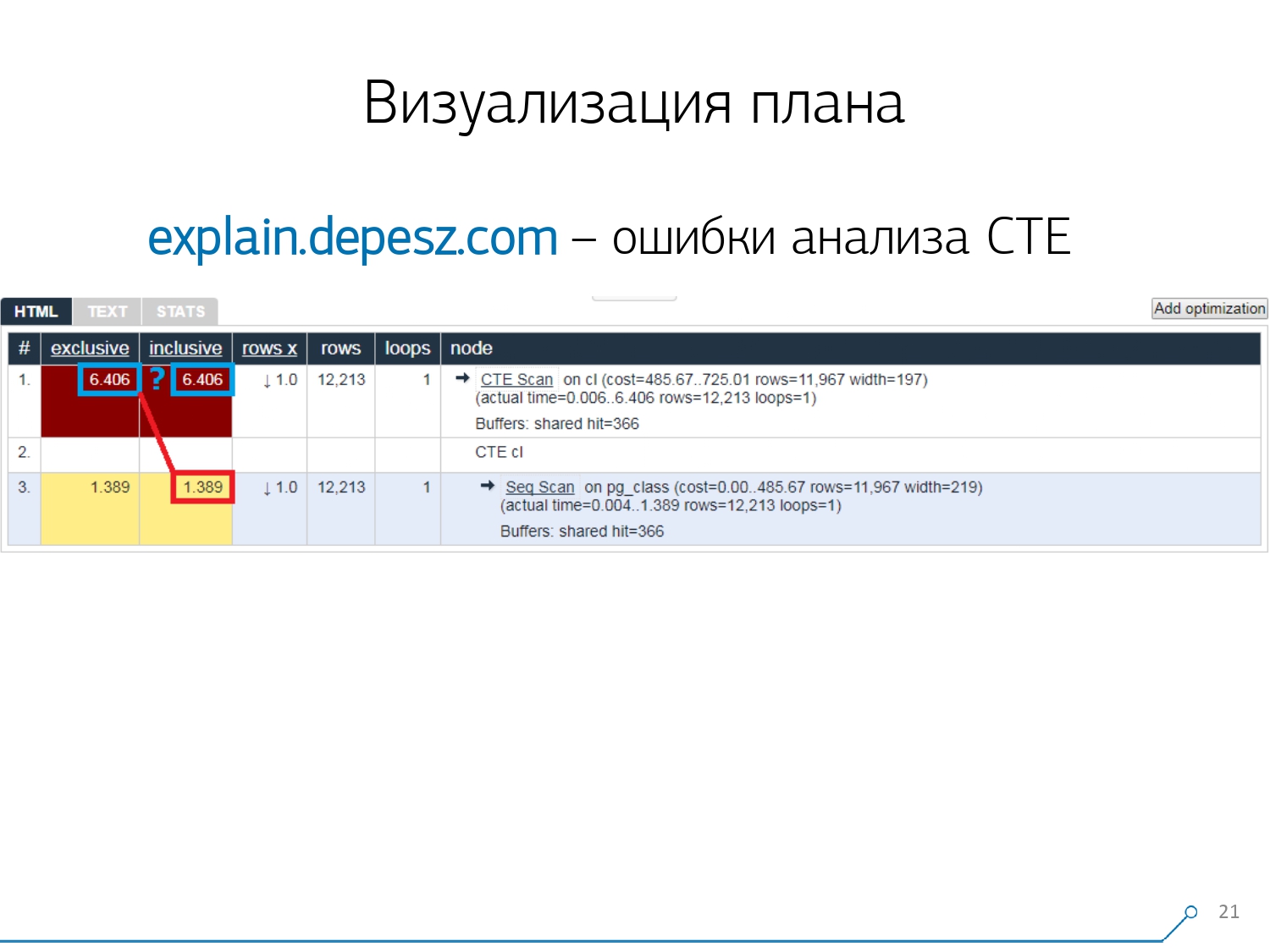 ولكن هذه كلها "كلمات" ، يمكن للمرء أن يعيش معها بطريقة أو بأخرى ، ولكن هناك شيء واحد أبعدنا عن هذه الخدمة. هذه أخطاء تحليل تعبير الجدول المشترك (CTE) والعديد من العقد الديناميكية مثل InitPlan / SubPlan.إذا كنت تعتقد أن هذه الصورة ، فلدينا وقت التنفيذ الإجمالي لكل عقدة فردية أكبر من إجمالي وقت التنفيذ للطلب بأكمله. الأمر بسيط - لم يتم طرح وقت إنشاء CTE من عقدة CTE Scan . لذلك ، لم نعد نعرف الإجابة الصحيحة ، كم أخذ مسح CTE نفسه.
ولكن هذه كلها "كلمات" ، يمكن للمرء أن يعيش معها بطريقة أو بأخرى ، ولكن هناك شيء واحد أبعدنا عن هذه الخدمة. هذه أخطاء تحليل تعبير الجدول المشترك (CTE) والعديد من العقد الديناميكية مثل InitPlan / SubPlan.إذا كنت تعتقد أن هذه الصورة ، فلدينا وقت التنفيذ الإجمالي لكل عقدة فردية أكبر من إجمالي وقت التنفيذ للطلب بأكمله. الأمر بسيط - لم يتم طرح وقت إنشاء CTE من عقدة CTE Scan . لذلك ، لم نعد نعرف الإجابة الصحيحة ، كم أخذ مسح CTE نفسه. ثم أدركنا أن الوقت قد حان لكتابة الخاصة بنا -! يقول كل مطور: "الآن سنكتب الخاصة بنا ، ستكون رائعة!"أخذوا مجموعة خدمات ويب نموذجية: النواة على Node.js + Express ، سحبت Bootstrap والمخططات الجميلة - D3.js. وكانت توقعاتنا لها ما يبررها - تلقينا أول نموذج أولي في أسبوعين:
ثم أدركنا أن الوقت قد حان لكتابة الخاصة بنا -! يقول كل مطور: "الآن سنكتب الخاصة بنا ، ستكون رائعة!"أخذوا مجموعة خدمات ويب نموذجية: النواة على Node.js + Express ، سحبت Bootstrap والمخططات الجميلة - D3.js. وكانت توقعاتنا لها ما يبررها - تلقينا أول نموذج أولي في أسبوعين:
أي محلل الخطة الخاص بنا ، أي يمكننا الآن بشكل عام تحليل أي خطة من تلك التي تم إنشاؤها بواسطة PostgreSQL.- التحليل الصحيح للعقد الديناميكية - CTE Scan و InitPlan و SubPlan
- تحليل توزيع المخازن المؤقتة - حيث تتم قراءة صفحات البيانات من الذاكرة وأين من ذاكرة التخزين المؤقت المحلية وأين من القرص
- تلقي الرؤية
بحيث لا يكون "في السجل" هو "حفر" ، ولكن ترى "الرابط الأضعف" على الفور في الصورة.
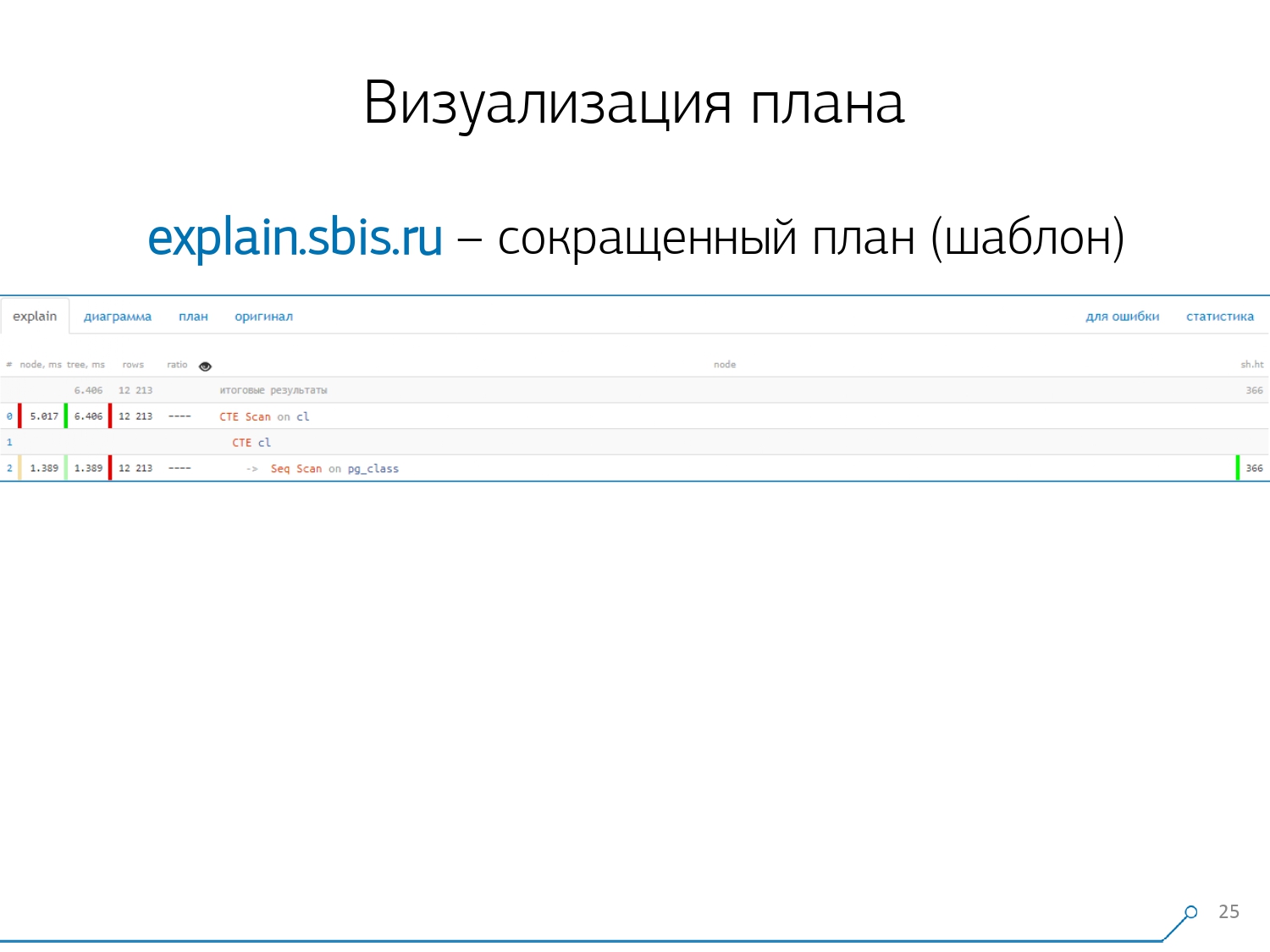 لدينا شيء من هذا القبيل - على الفور مع تسليط الضوء على بناء الجملة. ولكن عادةً ما لم يعد مطورو البرامج يعملون مع عرض كامل للخطة ، ولكن مع خطة أقصر. بعد كل شيء ، قمنا بالفعل بتحليل جميع الأرقام وقمنا برميها يسارًا ويمينًا ، وتركنا السطر الأول فقط في المنتصف ، أي نوع من العقدة هو: CTE Scan أو CTE أو Seq Scan الجيل حسب نوع من التسمية.هذا العرض المختصر هو ما نسميه قالب الخطة .
لدينا شيء من هذا القبيل - على الفور مع تسليط الضوء على بناء الجملة. ولكن عادةً ما لم يعد مطورو البرامج يعملون مع عرض كامل للخطة ، ولكن مع خطة أقصر. بعد كل شيء ، قمنا بالفعل بتحليل جميع الأرقام وقمنا برميها يسارًا ويمينًا ، وتركنا السطر الأول فقط في المنتصف ، أي نوع من العقدة هو: CTE Scan أو CTE أو Seq Scan الجيل حسب نوع من التسمية.هذا العرض المختصر هو ما نسميه قالب الخطة .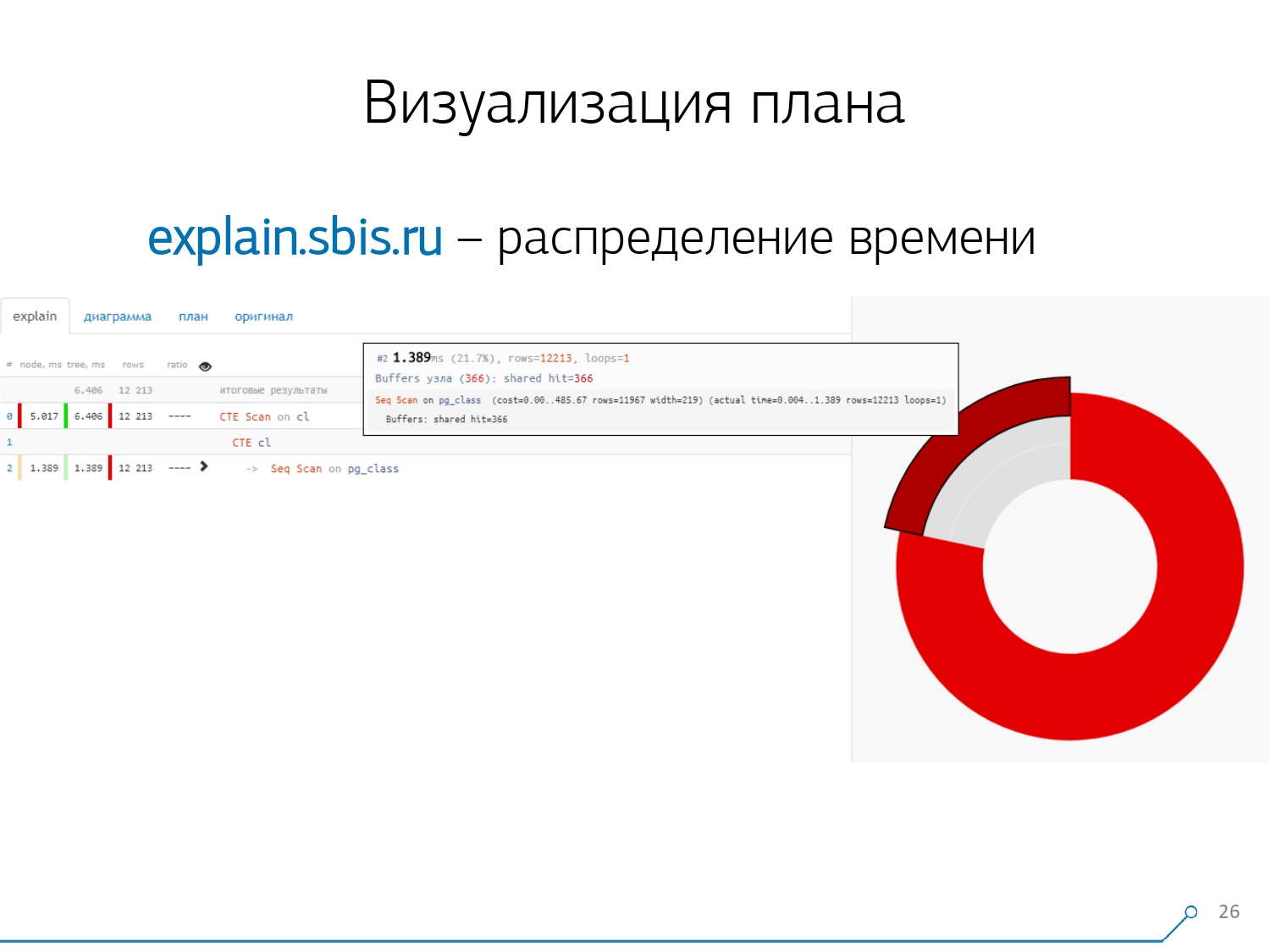 ماذا سيكون مناسبًا أيضًا؟ سيكون من الملائم معرفة نسبة العقدة من الوقت الإجمالي المخصص لنا - و "لصق" المخطط الدائري على الجانب فقط .نشير إلى العقدة ونرى - معنا ، تبين أن Seq Scan استغرق أقل من ربع الوقت بأكمله ، و 3/4 المتبقية أخذت CTE Scan. رعب! هذه ملاحظة صغيرة حول "معدل إطلاق النار" في CTE Scan ، إذا كنت تستخدمها بنشاط في استفساراتك. إنهم ليسوا سريعين للغاية - فهم يخسرون حتى عند فحص الجدول المعتاد. [مقالة] [مقالة]ولكن عادة ما تكون هذه الرسوم البيانية أكثر إثارة للاهتمام وأكثر تعقيدًا عندما نشير على الفور إلى مقطع ونرى ، على سبيل المثال ، أنه في أكثر من نصف الوقت ، تناولت بعض Seq Scan. علاوة على ذلك ، كان هناك نوع من التصفية في الداخل ، تم إسقاط مجموعة من السجلات عليه ... يمكنك رمي هذه الصورة مباشرة إلى المطور وقول: "Vasya ، كل شيء سيئ معك هنا! فهم ، انظر - هناك خطأ ما! "
ماذا سيكون مناسبًا أيضًا؟ سيكون من الملائم معرفة نسبة العقدة من الوقت الإجمالي المخصص لنا - و "لصق" المخطط الدائري على الجانب فقط .نشير إلى العقدة ونرى - معنا ، تبين أن Seq Scan استغرق أقل من ربع الوقت بأكمله ، و 3/4 المتبقية أخذت CTE Scan. رعب! هذه ملاحظة صغيرة حول "معدل إطلاق النار" في CTE Scan ، إذا كنت تستخدمها بنشاط في استفساراتك. إنهم ليسوا سريعين للغاية - فهم يخسرون حتى عند فحص الجدول المعتاد. [مقالة] [مقالة]ولكن عادة ما تكون هذه الرسوم البيانية أكثر إثارة للاهتمام وأكثر تعقيدًا عندما نشير على الفور إلى مقطع ونرى ، على سبيل المثال ، أنه في أكثر من نصف الوقت ، تناولت بعض Seq Scan. علاوة على ذلك ، كان هناك نوع من التصفية في الداخل ، تم إسقاط مجموعة من السجلات عليه ... يمكنك رمي هذه الصورة مباشرة إلى المطور وقول: "Vasya ، كل شيء سيئ معك هنا! فهم ، انظر - هناك خطأ ما! " بطبيعة الحال ، كان هناك "أشعل النار".أول شيء "داسوا عليه" هو مشكلة التقريب. يشار إلى وقت العقدة لكل فرد في الخطة بدقة 1 ميكرومتر. وعندما يتجاوز عدد دورات العقدة ، على سبيل المثال ، 1000 - بعد التنفيذ ، قسمت PostgreSQL "ما يصل إلى" ، ثم في الحساب العكسي نحصل على الوقت الإجمالي "في مكان ما بين 0.95 مللي ثانية و 1.05 مللي ثانية". عندما يتم إنفاق الحساب بالميكروثانية - لا شيء حتى الآن ، ولكن عندما يكون بالفعل لمدة [ملي] ثانية - من الضروري أخذ هذه المعلومات في الاعتبار عند "فك" الموارد الموجودة على عقد الخطة "من الذي يستهلك من".
بطبيعة الحال ، كان هناك "أشعل النار".أول شيء "داسوا عليه" هو مشكلة التقريب. يشار إلى وقت العقدة لكل فرد في الخطة بدقة 1 ميكرومتر. وعندما يتجاوز عدد دورات العقدة ، على سبيل المثال ، 1000 - بعد التنفيذ ، قسمت PostgreSQL "ما يصل إلى" ، ثم في الحساب العكسي نحصل على الوقت الإجمالي "في مكان ما بين 0.95 مللي ثانية و 1.05 مللي ثانية". عندما يتم إنفاق الحساب بالميكروثانية - لا شيء حتى الآن ، ولكن عندما يكون بالفعل لمدة [ملي] ثانية - من الضروري أخذ هذه المعلومات في الاعتبار عند "فك" الموارد الموجودة على عقد الخطة "من الذي يستهلك من". النقطة الثانية ، الأكثر تعقيدًا ، هي توزيع الموارد (تلك المخازن المؤقتة نفسها) بين العقد الديناميكية. هذا كلفنا أول أسبوعين على النموذج الأولي بالإضافة إلى زائد للأسبوع 4.إن الحصول على هذه المشكلة أمر بسيط للغاية - نقوم بعمل CTE ويفترض أننا نقرأ شيئًا فيه. في الواقع ، PostgreSQL ذكي ولن يقرأ أي شيء هناك. ثم نأخذ أول سجل منه ، والأول مائة من نفس CTE إليه.
النقطة الثانية ، الأكثر تعقيدًا ، هي توزيع الموارد (تلك المخازن المؤقتة نفسها) بين العقد الديناميكية. هذا كلفنا أول أسبوعين على النموذج الأولي بالإضافة إلى زائد للأسبوع 4.إن الحصول على هذه المشكلة أمر بسيط للغاية - نقوم بعمل CTE ويفترض أننا نقرأ شيئًا فيه. في الواقع ، PostgreSQL ذكي ولن يقرأ أي شيء هناك. ثم نأخذ أول سجل منه ، والأول مائة من نفس CTE إليه.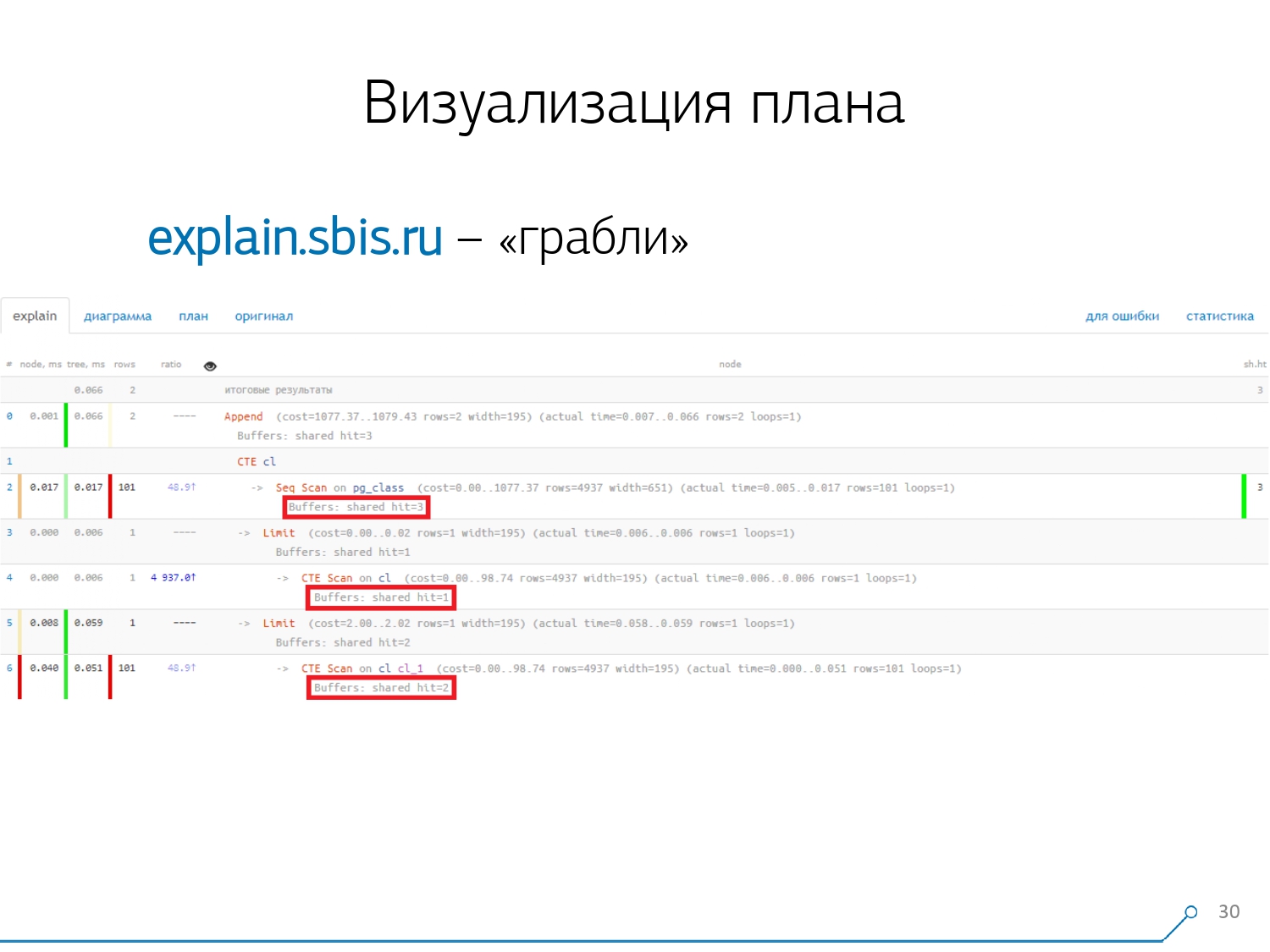 نحن ننظر إلى الخطة ونفهم - غريب ، لدينا 3 مخازن (صفحات بيانات) تم "استهلاكها" في Seq Scan ، وواحد آخر في CTE Scan ، واثنين آخرين في CTE Scan. أي إذا تم تلخيص كل شيء ببساطة ، نحصل على 6 ، ولكن من اللوحة نقرأ 3 فقط! لا يقرأ CTE Scan أي شيء من أي مكان ، ولكنه يعمل مباشرة مع ذاكرة العملية. أي أنه من الواضح أن هناك خطأ ما هنا!في الواقع ، اتضح أنه هنا جميع هذه الصفحات الثلاث من البيانات التي تم طلبها من Seq Scan ، طلبت 1 أولاً فحص CTE الأول ، ثم الثانية ، وقراءة 2 أخرى. أي ، تم قراءة 3 صفحات في المجموع البيانات ، وليس 6.
نحن ننظر إلى الخطة ونفهم - غريب ، لدينا 3 مخازن (صفحات بيانات) تم "استهلاكها" في Seq Scan ، وواحد آخر في CTE Scan ، واثنين آخرين في CTE Scan. أي إذا تم تلخيص كل شيء ببساطة ، نحصل على 6 ، ولكن من اللوحة نقرأ 3 فقط! لا يقرأ CTE Scan أي شيء من أي مكان ، ولكنه يعمل مباشرة مع ذاكرة العملية. أي أنه من الواضح أن هناك خطأ ما هنا!في الواقع ، اتضح أنه هنا جميع هذه الصفحات الثلاث من البيانات التي تم طلبها من Seq Scan ، طلبت 1 أولاً فحص CTE الأول ، ثم الثانية ، وقراءة 2 أخرى. أي ، تم قراءة 3 صفحات في المجموع البيانات ، وليس 6.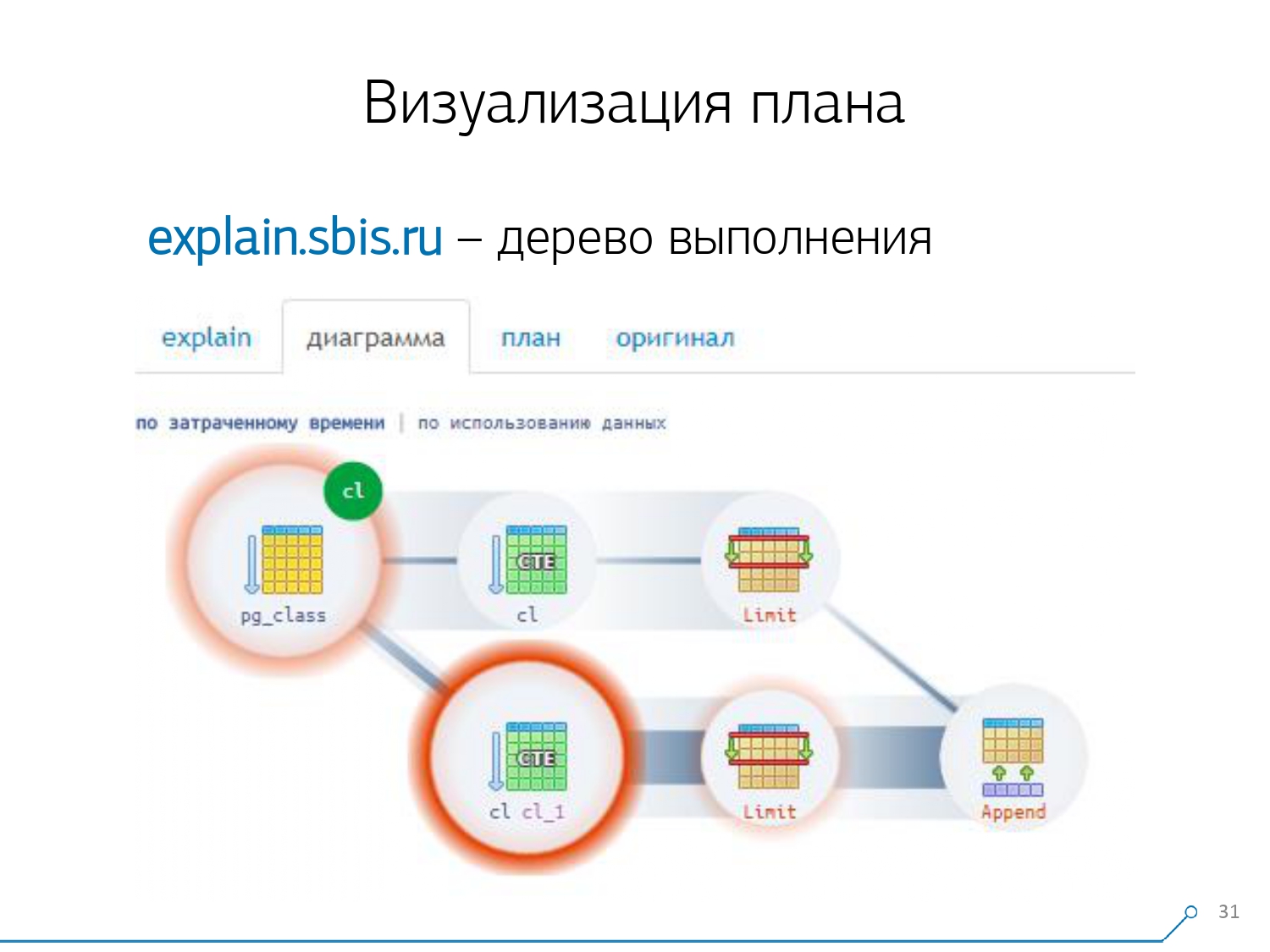 وقد قادتنا هذه الصورة إلى أن نفهم أن تنفيذ الخطة لم يعد شجرة ، بل مجرد نوع من الرسم البياني الحلقية. وحصلنا على مخطط مثل هذا حتى نفهم "من أين جاء على الإطلاق". أي أننا هنا أنشأنا CTE من pg_class ، وطلبناها مرتين ، وطوال الوقت تقريبًا استغرقتنا في الفرع عندما طلبناها في المرة الثانية. من الواضح أن قراءة الرقم 101 أغلى بكثير من القراءة الأولى للكمبيوتر اللوحي.
وقد قادتنا هذه الصورة إلى أن نفهم أن تنفيذ الخطة لم يعد شجرة ، بل مجرد نوع من الرسم البياني الحلقية. وحصلنا على مخطط مثل هذا حتى نفهم "من أين جاء على الإطلاق". أي أننا هنا أنشأنا CTE من pg_class ، وطلبناها مرتين ، وطوال الوقت تقريبًا استغرقتنا في الفرع عندما طلبناها في المرة الثانية. من الواضح أن قراءة الرقم 101 أغلى بكثير من القراءة الأولى للكمبيوتر اللوحي. زفيرنا لفترة من الوقت. قالوا: "الآن ، تعرف ، الكونغ فو! الآن تجربتنا مباشرة على شاشتك. الآن يمكنك استخدامه ". [مقالة - سلعة]
زفيرنا لفترة من الوقت. قالوا: "الآن ، تعرف ، الكونغ فو! الآن تجربتنا مباشرة على شاشتك. الآن يمكنك استخدامه ". [مقالة - سلعة]دمج السجل
تنفسنا 1000 مطمئن الصعداء. لكننا أدركنا أن لدينا فقط المئات من خوادم "المعارك" ، وأن كل "لصق النسخ" هذا من قبل المطورين ليس مناسبًا على الإطلاق. أدركنا أننا بحاجة إلى جمعها بأنفسنا. بشكل عام ، هناك وحدة عادية يمكنها جمع الإحصائيات ، ومع ذلك ، يجب أيضًا تنشيطها في التكوين - هذه هي وحدة pg_stat_statements . لكنه لم يناسبنا.أولاً ، يقوم بتعيين QueryId مختلف لنفس الاستعلامات في مخططات مختلفة داخل نفس قاعدة البيانات . بمعنى ، إذا قمت بإجراء ذلك أولاً
بشكل عام ، هناك وحدة عادية يمكنها جمع الإحصائيات ، ومع ذلك ، يجب أيضًا تنشيطها في التكوين - هذه هي وحدة pg_stat_statements . لكنه لم يناسبنا.أولاً ، يقوم بتعيين QueryId مختلف لنفس الاستعلامات في مخططات مختلفة داخل نفس قاعدة البيانات . بمعنى ، إذا قمت بإجراء ذلك أولاً SET search_path = '01'; SELECT * FROM user LIMIT 1;، ثم SET search_path = '02';نفس الطلب ، فستكون لإحصائيات هذه الوحدة النمطية إدخالات مختلفة ، ولن أتمكن من جمع إحصائيات عامة بدقة في سياق ملف تعريف الطلب هذا ، دون مراعاة المخططات.النقطة الثانية التي منعتنا من استخدامها هي عدم وجود خطط . أي أنه لا توجد خطة ، هناك فقط الطلب نفسه. نرى ما كان يتباطأ ، لكننا لا نفهم لماذا. وهنا نعود إلى مشكلة مجموعة البيانات المتغيرة بسرعة.والنقطة الأخيرة هي عدم وجود "الحقائق" . أي أنه من المستحيل معالجة نسخة معينة من تنفيذ الاستعلام - فهي ليست موجودة ، فهناك إحصائيات مجمعة فقط. على الرغم من أنه من الممكن العمل معه ، إلا أنه ببساطة صعب للغاية.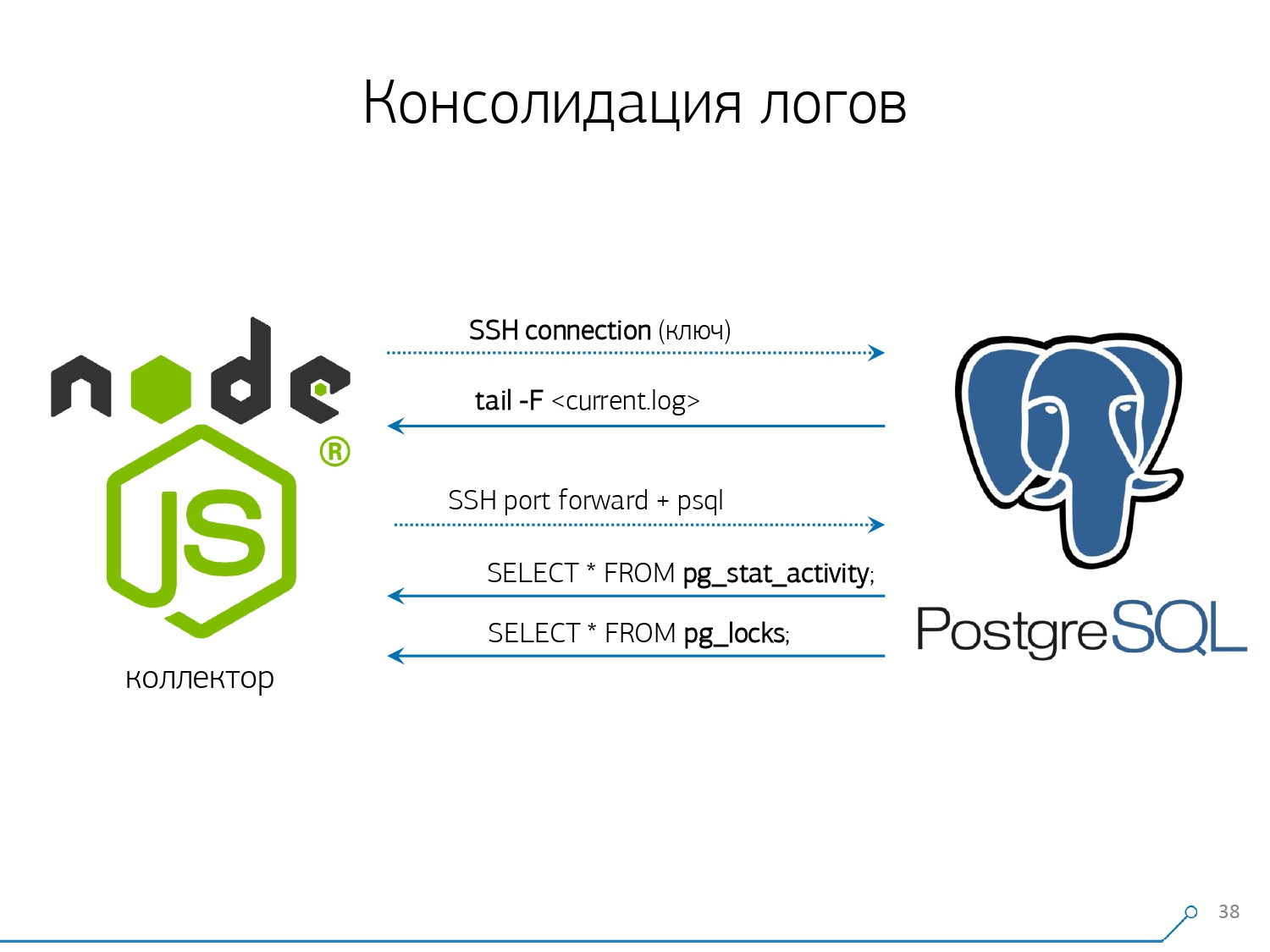 لذلك ، قررنا محاربة "نسخ ولصق" وبدأنا في كتابة جامع .يتم توصيل أداة التجميع عبر SSH ، "تسحب" اتصالاً آمنًا بالخادم باستخدام قاعدة البيانات باستخدام الشهادة و
لذلك ، قررنا محاربة "نسخ ولصق" وبدأنا في كتابة جامع .يتم توصيل أداة التجميع عبر SSH ، "تسحب" اتصالاً آمنًا بالخادم باستخدام قاعدة البيانات باستخدام الشهادة و tail -F"يتمسك" بها إلى ملف السجل. لذلك في هذه الجلسةنحصل على "نسخة متطابقة" كاملة من ملف السجل الذي يقوم الخادم بإنشائه. الحمل على الخادم نفسه ضئيل ، لأننا لا نحلل أي شيء هناك ، نحن ببساطة نعكس حركة المرور.نظرًا لأننا بدأنا بالفعل في كتابة الواجهة على Node.js ، واصلنا كتابة المُجمع عليها. وقد أثمرت هذه التكنولوجيا ، لأنه من الملائم جدًا استخدام جافا سكريبت للعمل مع بيانات نصية سيئة التنسيق ، وهي السجل. والبنية التحتية Node.js نفسها كمنصة خلفية تسمح لك بالعمل بسهولة ويسر مع اتصالات الشبكة ، وفي الواقع مع نوع من تدفقات البيانات.وبناءً على ذلك ، نقوم "بسحب" اتصالين: الأول هو "الاستماع" إلى السجل نفسه ونقله إلى أنفسنا ، والثاني هو طلب قاعدة البيانات بشكل دوري. "ولكن في السجل وصلنا إلى أن اللوحة التي تحمل OID 123 تم حظرها" ، لكنها لا تقول أي شيء للمطور ، وسيكون من الجيد أن تسأل قاعدة البيانات "ما هو OID = 123 بعد كل شيء؟" ولذلك نسأل القاعدة بشكل دوري عن شيء لا نعرفه في المنزل بعد. "أنت لم تأخذ بعين الاعتبار ، هناك نوع من النحل يشبه الفيل! .." بدأنا في تطوير هذا النظام عندما أردنا مراقبة 10 خوادم. الأكثر أهمية في فهمنا ، حيث كانت هناك بعض المشاكل التي كان من الصعب التعامل معها. لكن خلال الربع الأول حصلنا على مائة مراقبة - لأن النظام "دخل" ، أراد الجميع ذلك ، كان الجميع مرتاحين.يجب إضافة كل هذا ، تدفق البيانات كبير ونشط. في الواقع ، نحن نراقب ما نحن قادرون على التعامل معه - ثم نستخدمه. نستخدم أيضًا PostgreSQL كمستودع بيانات. ولكن لا شيء أسرع "لصب" البيانات فيه من
"أنت لم تأخذ بعين الاعتبار ، هناك نوع من النحل يشبه الفيل! .." بدأنا في تطوير هذا النظام عندما أردنا مراقبة 10 خوادم. الأكثر أهمية في فهمنا ، حيث كانت هناك بعض المشاكل التي كان من الصعب التعامل معها. لكن خلال الربع الأول حصلنا على مائة مراقبة - لأن النظام "دخل" ، أراد الجميع ذلك ، كان الجميع مرتاحين.يجب إضافة كل هذا ، تدفق البيانات كبير ونشط. في الواقع ، نحن نراقب ما نحن قادرون على التعامل معه - ثم نستخدمه. نستخدم أيضًا PostgreSQL كمستودع بيانات. ولكن لا شيء أسرع "لصب" البيانات فيه من COPYعدم وجود مشغل حتى الآن.لكن مجرد "صب" البيانات ليست في الحقيقة تقنيتنا. لأنه إذا كان لديك حوالي 50 ألف طلب في الثانية على مائة خادم ، فسيؤدي ذلك إلى إنشاء 100-150 جيجابايت من السجلات يوميًا لك. لذلك ، كان علينا أن "نرى" بعناية القاعدة.أولاً ، قمنا بالتقسيم كل يوم ، لأنه ، على العموم ، لا أحد مهتم بالعلاقة بين الأيام. ما الفرق الذي كان لديك بالأمس ، إذا قمت الليلة بإصدار نسخة جديدة من التطبيق - وبعض الإحصائيات الجديدة بالفعل.ثانيًا ، تعلمنا (أجبرنا) على الكتابة بسرعة كبيرة جدًا باستخدامCOPY . هذا ليس فقط COPYلأنه أسرع من ذلك INSERT، ولكن أسرع. النقطة الثالثة - اضطررت إلى التخلي عن المشغلات ، على التوالي ، ومن المفاتيح الخارجية . أي أننا لا نمتلك مرجعية مطلقة. لأنه إذا كان لديك جدول به زوج من FK ، وتقول في بنية قاعدة البيانات أن "هنا إدخال سجل يشير إلى FK ، على سبيل المثال ، مجموعة من السجلات" ، فعند إدخاله ، فإن PostgreSQL ليس لديه ما يفعله سوى كيفية اتخاذ وتنفيذ بصدق
النقطة الثالثة - اضطررت إلى التخلي عن المشغلات ، على التوالي ، ومن المفاتيح الخارجية . أي أننا لا نمتلك مرجعية مطلقة. لأنه إذا كان لديك جدول به زوج من FK ، وتقول في بنية قاعدة البيانات أن "هنا إدخال سجل يشير إلى FK ، على سبيل المثال ، مجموعة من السجلات" ، فعند إدخاله ، فإن PostgreSQL ليس لديه ما يفعله سوى كيفية اتخاذ وتنفيذ بصدق SELECT 1 FROM master_fk1_table WHERE ...مع المعرف الذي تحاول إدراجه - فقط للتحقق من وجود هذا الإدخال ، من أنك لا "تكسر" هذا المفتاح الخارجي مع إدخالك.نحصل بدلاً من سجل واحد في الجدول الهدف ومؤشراته ، بالإضافة إلى قراءة أخرى من جميع الجداول التي تشير إليها. ولا نحتاجها على الإطلاق - مهمتنا هي تدوين أكبر قدر ممكن وبأسرع وقت ممكن بأقل حمل. حتى FK - إلى أسفل!النقطة التالية هي التجميع والتجزئة. في البداية ، تم تنفيذها في قاعدة بياناتنا - بعد كل شيء ، من الملائم ، فور وصول التسجيل ، إجراء "زائد واحد" في نوع ما من لوحة في الزناد . إنه جيد ومريح ، ولكن الشيء نفسه سيء - أدخل سجلًا واحدًا ، لكنك مجبر على قراءة وكتابة شيء آخر من جدول آخر. علاوة على ذلك ، ليس هذا فقط ، اقرأ واكتب - وقم بذلك أيضًا في كل مرة.تخيل الآن أن لديك لوحة تحسب فيها ببساطة عدد الطلبات التي مرت على مضيف معين:+1, +1, +1, ..., +1. وأنت ، من حيث المبدأ ، لا تحتاج إليها - كل هذا يمكن تلخيصه في الذاكرة على المجمع وإرساله إلى قاعدة البيانات في كل مرة +10.نعم ، قد "تنهار" سلامتك المنطقية في حالة حدوث بعض المشاكل ، ولكن هذه حالة غير واقعية تقريبًا - لأن لديك خادم عادي ، ولديه بطارية في وحدة التحكم ، ولديك سجل معاملات ، وسجل على نظام الملفات ... بشكل عام ، لا يستحق كل هذا العناء. لا يستحق فقدان الإنتاجية التي تحصل عليها بسبب عمل مشغلات / FK ، والتكاليف التي تتكبدها في نفس الوقت.نفس الشيء مع التجزئة. يتوجه إليك طلب معين ، وتقوم بحساب معرّف معين من قاعدة البيانات منه ، وتكتب إلى قاعدة البيانات ثم تخبره للجميع. كل شيء على ما يرام ، حتى وقت تسجيل شخص آخر يأتي إليك الذي يريد تسجيله - ولديك قفل ، وهذا أمر سيئ بالفعل. لذلك ، إذا كان بإمكانك إخراج بعض المعرفات على العميل (بالنسبة لقاعدة البيانات) ، فمن الأفضل القيام بذلك.لقد كنا مناسبين تمامًا لاستخدام MD5 من النص - طلب ، خطة ، قالب ، ... نحسبه على جانب المجمع ، و "نصب" المعرّف الجاهز في قاعدة البيانات. يسمح لنا طول MD5 والتقسيم اليومي بعدم القلق بشأن التصادمات المحتملة.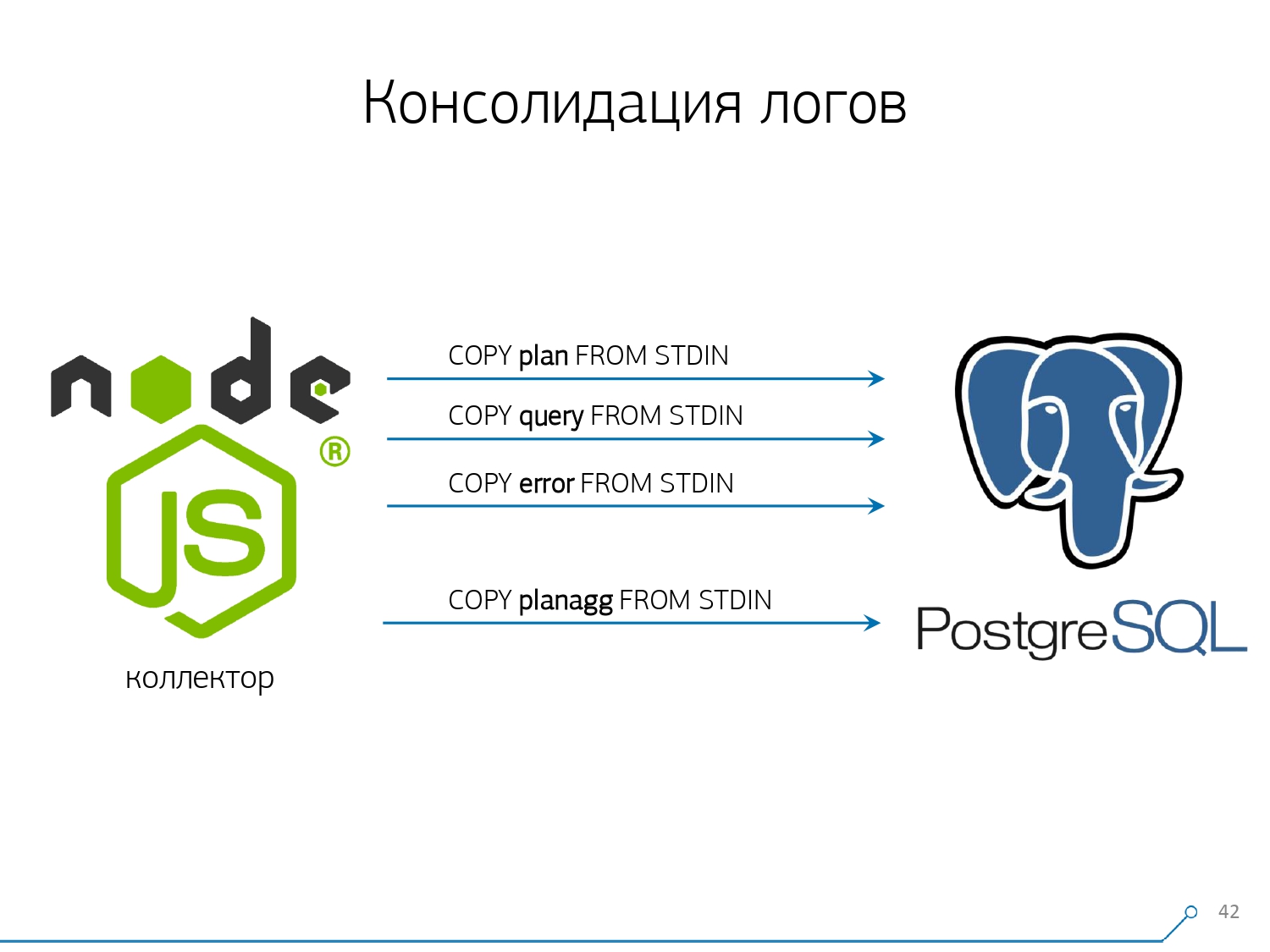 ولكن من أجل تسجيل كل هذا بسرعة ، كنا بحاجة إلى تعديل إجراء التسجيل نفسه.كيف تكتب البيانات عادة؟ لدينا نوع من مجموعة البيانات ، ونقوم بتحليلها إلى عدة جداول ، ثم نسخ - أولاً في الأول ، ثم في الثانية ، في الثالثة ... وهو غير مريح ، لأننا نوعًا ما نكتب دفق بيانات واحد في ثلاث خطوات بالتسلسل. غير سارة. هل من الممكن القيام بشكل أسرع؟ يستطيع!للقيام بذلك ، يكفي فقط تحليل هذه التدفقات بالتوازي مع بعضها البعض. اتضح أن لدينا أخطاء ، طلبات ، قوالب ، أقفال ، تحلق في تدفقات منفصلة ... - ونكتب كل ذلك بالتوازي. للقيام بذلك ، ما عليك سوى إبقاء قناة COPY مفتوحة بشكل دائم على كل جدول هدف فردي .
ولكن من أجل تسجيل كل هذا بسرعة ، كنا بحاجة إلى تعديل إجراء التسجيل نفسه.كيف تكتب البيانات عادة؟ لدينا نوع من مجموعة البيانات ، ونقوم بتحليلها إلى عدة جداول ، ثم نسخ - أولاً في الأول ، ثم في الثانية ، في الثالثة ... وهو غير مريح ، لأننا نوعًا ما نكتب دفق بيانات واحد في ثلاث خطوات بالتسلسل. غير سارة. هل من الممكن القيام بشكل أسرع؟ يستطيع!للقيام بذلك ، يكفي فقط تحليل هذه التدفقات بالتوازي مع بعضها البعض. اتضح أن لدينا أخطاء ، طلبات ، قوالب ، أقفال ، تحلق في تدفقات منفصلة ... - ونكتب كل ذلك بالتوازي. للقيام بذلك ، ما عليك سوى إبقاء قناة COPY مفتوحة بشكل دائم على كل جدول هدف فردي . وهذا يعني أن المجمع لديه دفق دائمًايمكنني كتابة البيانات التي أحتاج إليها. ولكن حتى ترى قاعدة البيانات هذه البيانات ، ولا يعلق شخص ما في الأقفال ، في انتظار كتابة هذه البيانات ، يجب مقاطعة COPY بتردد معين . بالنسبة لنا ، اتضح أن فترة طلب 100 مللي ثانية هي الأكثر فعالية - أغلقها وافتحها على الفور مرة أخرى على نفس الجدول. وإذا لم يكن لدينا دفق واحد في بعض القمم ، فإننا نقوم بالتجميع إلى حد معين.بالإضافة إلى ذلك ، اكتشفنا أنه بالنسبة لملف تعريف التحميل هذا ، فإن أي تجميع عندما يتم جمع السجلات في حزم هو أمر شرير. الشر الكلاسيكي
وهذا يعني أن المجمع لديه دفق دائمًايمكنني كتابة البيانات التي أحتاج إليها. ولكن حتى ترى قاعدة البيانات هذه البيانات ، ولا يعلق شخص ما في الأقفال ، في انتظار كتابة هذه البيانات ، يجب مقاطعة COPY بتردد معين . بالنسبة لنا ، اتضح أن فترة طلب 100 مللي ثانية هي الأكثر فعالية - أغلقها وافتحها على الفور مرة أخرى على نفس الجدول. وإذا لم يكن لدينا دفق واحد في بعض القمم ، فإننا نقوم بالتجميع إلى حد معين.بالإضافة إلى ذلك ، اكتشفنا أنه بالنسبة لملف تعريف التحميل هذا ، فإن أي تجميع عندما يتم جمع السجلات في حزم هو أمر شرير. الشر الكلاسيكي INSERT ... VALUESيتجاوز 1000 سجل. لأنه في هذه اللحظة لديك ذروة التسجيل على الوسائط ، وكل شخص آخر يحاول كتابة شيء على القرص سينتظر.للتخلص من هذه الحالات الشاذة ، ببساطة لا تجمع أي شيء ، لا تخزن على الإطلاق . وإذا حدث التخزين المؤقت على القرص (لحسن الحظ ، تسمح لك Stream API في Node.js بمعرفة ذلك) - تأجيل هذا الاتصال. هذا عندما يأتي الحدث إليك أنه مجاني مرة أخرى - اكتب إليه من قائمة الانتظار المتراكمة. في غضون ذلك ، إنه مشغول - خذ النموذج المجاني التالي من حوض السباحة واكتب إليه.قبل تنفيذ هذا النهج لتسجيل البيانات ، كان لدينا ما يقرب من عمليات كتابة 4K ، وبهذه الطريقة قمنا بتقليل الحمل بمقدار 4 مرات. الآن نمت 6 مرات أخرى بسبب قواعد جديدة يمكن ملاحظتها - تصل إلى 100 ميجابايت / ثانية. والآن نقوم بتخزين السجلات للأشهر الثلاثة الأخيرة بمبلغ حوالي 10-15 تيرابايت ، على أمل أنه في غضون ثلاثة أشهر فقط يمكن لأي مطور حل أي مشكلة.نحن نفهم المشاكل
لكن مجرد جمع كل هذه البيانات أمر جيد ومفيد ومناسب ولكنه غير كافٍ - فأنت بحاجة إلى فهمها. لأنه يحتوي على ملايين الخطط المختلفة يوميًا. لكن الملايين لا يمكن السيطرة عليهم ، يجب عليك أولاً "أقل". وقبل كل شيء ، من الضروري أن تقرر كيف ستنظم هذا "الأصغر".لقد حددنا لأنفسنا ثلاث نقاط رئيسية:
لكن الملايين لا يمكن السيطرة عليهم ، يجب عليك أولاً "أقل". وقبل كل شيء ، من الضروري أن تقرر كيف ستنظم هذا "الأصغر".لقد حددنا لأنفسنا ثلاث نقاط رئيسية:- الذي أرسل هذا الطلب
، أي التطبيق الذي "طار" منه: واجهة الويب أو الواجهة الخلفية أو نظام الدفع أو أي شيء آخر. - أين حدث هذا
على أي خادم معين. لأنه إذا كان لديك العديد من الخوادم تحت تطبيق واحد ، وفجأة "مقطوع" (لأن "القرص قد تفسد" ، "تسربت الذاكرة" ، بعض المشاكل الأخرى) ، فأنت بحاجة إلى معالجة الخادم على وجه التحديد. - كيف تتجلى المشكلة بطريقة أو بأخرى
لفهم "من" أرسل لنا الطلب ، نستخدم أداة عادية - إعداد متغير جلسة: SET application_name = '{bl-host}:{bl-method}';- إرسال اسم المضيف لمنطق الأعمال الذي تم تقديم الطلب منه ، واسم الطريقة أو التطبيق الذي بدأه.بعد تمرير "مالك" الطلب ، يجب عرضه في السجل - لهذا نقوم بتكوين المتغير log_line_prefix = ' %m [%p:%v] [%d] %r %a'. يمكن لأي شخص مهتم أن يرى في الدليل ما يعنيه كل هذا. اتضح أننا نرى في السجل:- زمن
- معرّفات العمليات والمعاملات
- الاسم الأساسي
- IP للشخص الذي أرسل هذا الطلب
- واسم الطريقة
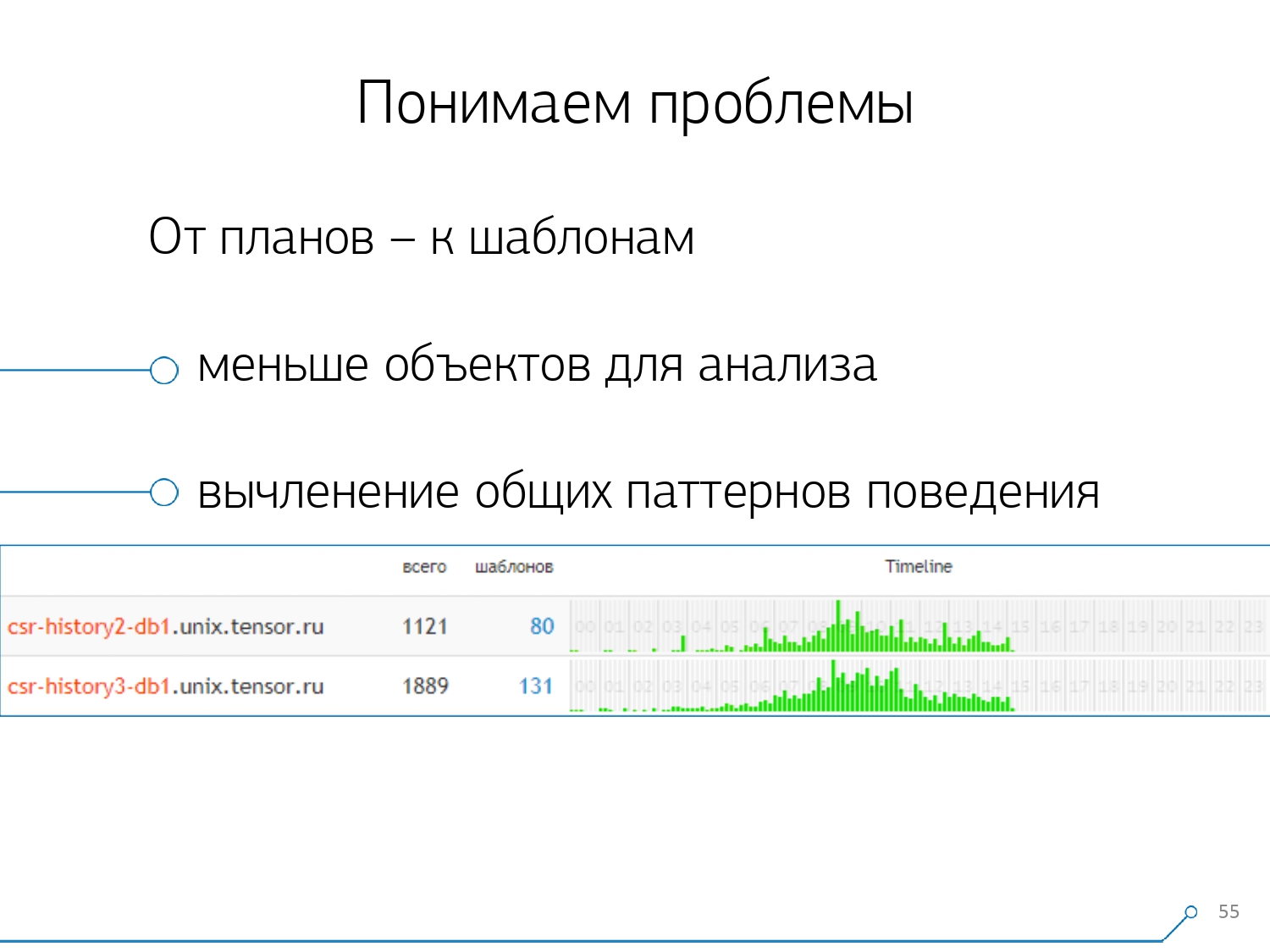 ثم أدركنا أنه ليس من المثير للاهتمام أن ننظر في علاقة طلب واحد بين خوادم مختلفة. يحدث ذلك بشكل غير متكرر عندما يكون لديك تطبيق واحد يحظى بالتساوي هنا وهناك. ولكن حتى لو كان هو نفسه ، انظر إلى أي من هذه الخوادم.لذا ، تبين أن قسم "خادم واحد - يوم واحد" كافٍ لأي تحليل.القسم التحليلي الأول هو "القالب" - شكل مختصر لعرض الخطة ، تم مسحه من جميع المؤشرات العددية. القسم الثاني هو التطبيق أو الطريقة ، والثالث هو العقدة المحددة للخطة التي تسببت لنا في المشاكل.عندما انتقلنا من حالات معينة إلى النماذج ، تلقينا على الفور ميزتين:
ثم أدركنا أنه ليس من المثير للاهتمام أن ننظر في علاقة طلب واحد بين خوادم مختلفة. يحدث ذلك بشكل غير متكرر عندما يكون لديك تطبيق واحد يحظى بالتساوي هنا وهناك. ولكن حتى لو كان هو نفسه ، انظر إلى أي من هذه الخوادم.لذا ، تبين أن قسم "خادم واحد - يوم واحد" كافٍ لأي تحليل.القسم التحليلي الأول هو "القالب" - شكل مختصر لعرض الخطة ، تم مسحه من جميع المؤشرات العددية. القسم الثاني هو التطبيق أو الطريقة ، والثالث هو العقدة المحددة للخطة التي تسببت لنا في المشاكل.عندما انتقلنا من حالات معينة إلى النماذج ، تلقينا على الفور ميزتين:
, .
, «» - , . , - , , , — , , — , , . , , .
 تعتمد الطرق المتبقية على المؤشرات التي نستخلصها من الخطة: كم مرة حدث مثل هذا القالب ، إجمالي الوقت ومتوسطه ، مقدار البيانات التي تم قراءتها من القرص ، وكم من الذاكرة ...لأنك ، على سبيل المثال ، تأتي إلى صفحة التحليلات حسب المضيف ، انظر - شيء على القرص لقراءة البداية. لا يتعامل القرص على الخادم - ومن يقرأ منه؟ويمكنك الفرز حسب أي عمود وتحديد ما ستتعامل معه الآن - مع الحمل على المعالج أو القرص ، أو مع العدد الإجمالي للطلبات ... التي تم فرزها ، وتبدو "أعلى" ، وإصلاح - طرح إصدار جديد من التطبيق.[محاضرة فيديو]وعلى الفور يمكنك رؤية التطبيقات المختلفة التي تأتي مع نفس القالب من طلب مثل
تعتمد الطرق المتبقية على المؤشرات التي نستخلصها من الخطة: كم مرة حدث مثل هذا القالب ، إجمالي الوقت ومتوسطه ، مقدار البيانات التي تم قراءتها من القرص ، وكم من الذاكرة ...لأنك ، على سبيل المثال ، تأتي إلى صفحة التحليلات حسب المضيف ، انظر - شيء على القرص لقراءة البداية. لا يتعامل القرص على الخادم - ومن يقرأ منه؟ويمكنك الفرز حسب أي عمود وتحديد ما ستتعامل معه الآن - مع الحمل على المعالج أو القرص ، أو مع العدد الإجمالي للطلبات ... التي تم فرزها ، وتبدو "أعلى" ، وإصلاح - طرح إصدار جديد من التطبيق.[محاضرة فيديو]وعلى الفور يمكنك رؤية التطبيقات المختلفة التي تأتي مع نفس القالب من طلب مثلSELECT * FROM users WHERE login = 'Vasya'. الواجهة الأمامية والخلفية والمعالجة ... وتتساءل لماذا يجب على المستخدم قراءة المعالجة إذا لم يتفاعل معه.والطريقة المعاكسة هي أن ترى على الفور ما يفعله التطبيق. على سبيل المثال ، الواجهة الأمامية هي هذه ، هذه ، هذه ، وهذه مرة واحدة في الساعة (يساعد المخطط الزمني فقط). وعلى الفور يطرح السؤال - يبدو أنه ليس من عمل الواجهة الأمامية أن تفعل شيئًا مرة واحدة في الساعة ... بعد مرور بعض الوقت ، أدركنا أننا نفتقر إلى الإحصائيات المجمعة من حيث عقد الخطة . لقد عزلنا عن الخطط فقط تلك العقد التي تفعل شيئًا مع بيانات الجداول نفسها (اقرأ / اكتبها حسب الفهرس أم لا). في الواقع ، بالنسبة للصورة السابقة ، تمت إضافة جانب واحد فقط - عدد السجلات التي جلبتها لنا هذه العقدة ، وعددها الذي تم إسقاطه (الصفوف التي تمت إزالتها بواسطة الفلتر).ليس لديك فهرس مناسب على اللوحة ، تقدم طلبًا إليه ، يمر فوق الفهرس ، يقع في Seq Scan ... لقد قمت بتصفية جميع السجلات باستثناء سجل واحد. ولماذا تحتاج إلى 100 مليون سجل مُصفى يوميًا ، فهل من الأفضل أن تبدأ المؤشر؟
بعد مرور بعض الوقت ، أدركنا أننا نفتقر إلى الإحصائيات المجمعة من حيث عقد الخطة . لقد عزلنا عن الخطط فقط تلك العقد التي تفعل شيئًا مع بيانات الجداول نفسها (اقرأ / اكتبها حسب الفهرس أم لا). في الواقع ، بالنسبة للصورة السابقة ، تمت إضافة جانب واحد فقط - عدد السجلات التي جلبتها لنا هذه العقدة ، وعددها الذي تم إسقاطه (الصفوف التي تمت إزالتها بواسطة الفلتر).ليس لديك فهرس مناسب على اللوحة ، تقدم طلبًا إليه ، يمر فوق الفهرس ، يقع في Seq Scan ... لقد قمت بتصفية جميع السجلات باستثناء سجل واحد. ولماذا تحتاج إلى 100 مليون سجل مُصفى يوميًا ، فهل من الأفضل أن تبدأ المؤشر؟ بعد فحص جميع الخطط حسب العقد ، أدركنا أن هناك بعض الهياكل النموذجية في الخطط التي من المرجح أن تبدو مشبوهة. وسيكون من اللطيف إخبار المطور: "صديق ، هنا تقرأ أولاً حسب الفهرس ، ثم تصنفه ثم تقطعه" - كقاعدة عامة ، هناك سجل واحد.من المحتمل أن كل من كتب استعلامات بهذا النمط قد صادف: "أعطني آخر طلب لـ Vasya ، تاريخه" وإذا لم يكن لديك فهرس حسب التاريخ ، أو إذا لم يكن للفهرس المستخدم تاريخًا ، فانتقل بالضبط إلى "أشعل النار" وخطو على .لكننا نعلم أن هذه "أشعل النار" - فلماذا لا تخبر المطور فورًا بما يجب عليه فعله. وبناءً على ذلك ، عند فتح الخطة الآن ، يرى مطورنا على الفور صورة جميلة مع مطالبات ، حيث يتم إخباره على الفور: "لديك مشاكل هنا وهنا ، ولكن يتم حلها بهذه الطريقة وذاك".ونتيجة لذلك ، انخفض مقدار الخبرة المطلوبة لحل المشكلات في البداية والآن انخفض بشكل ملحوظ. هنا لدينا مثل هذه الأداة.
بعد فحص جميع الخطط حسب العقد ، أدركنا أن هناك بعض الهياكل النموذجية في الخطط التي من المرجح أن تبدو مشبوهة. وسيكون من اللطيف إخبار المطور: "صديق ، هنا تقرأ أولاً حسب الفهرس ، ثم تصنفه ثم تقطعه" - كقاعدة عامة ، هناك سجل واحد.من المحتمل أن كل من كتب استعلامات بهذا النمط قد صادف: "أعطني آخر طلب لـ Vasya ، تاريخه" وإذا لم يكن لديك فهرس حسب التاريخ ، أو إذا لم يكن للفهرس المستخدم تاريخًا ، فانتقل بالضبط إلى "أشعل النار" وخطو على .لكننا نعلم أن هذه "أشعل النار" - فلماذا لا تخبر المطور فورًا بما يجب عليه فعله. وبناءً على ذلك ، عند فتح الخطة الآن ، يرى مطورنا على الفور صورة جميلة مع مطالبات ، حيث يتم إخباره على الفور: "لديك مشاكل هنا وهنا ، ولكن يتم حلها بهذه الطريقة وذاك".ونتيجة لذلك ، انخفض مقدار الخبرة المطلوبة لحل المشكلات في البداية والآن انخفض بشكل ملحوظ. هنا لدينا مثل هذه الأداة.
Source: https://habr.com/ru/post/undefined/
All Articles