لسنوات ، كان الخبراء في C ++ يناقشون دلالات القيم والثبات وتقاسم الموارد من خلال التواصل. حول عالم جديد بدون كائنات وأجناس ، بدون أنماط القيادة والمراقب. في الواقع ، كل شيء ليس بهذه البساطة. لا تزال المشكلة الرئيسية في هياكل البيانات لدينا. هياكل البيانات الثابتة لا تغير قيمها. للقيام بشيء معهم ، تحتاج إلى إنشاء قيم جديدة. تبقى القيم القديمة في نفس المكان ، بحيث يمكن قراءتها من تيارات مختلفة دون مشاكل وأقفال. ونتيجة لذلك ، يمكن مشاركة الموارد بشكل أكثر عقلانية وترتيب ، لأن القيم القديمة والجديدة يمكن أن تستخدم البيانات المشتركة. وبفضل هذا ، فهي أسرع بكثير في المقارنة مع بعضها البعض وتخزين تاريخ العمليات بشكل مضغوط مع إمكانية الإلغاء. كل هذا يناسب تمامًا الأنظمة متعددة الخيوط والتفاعلية: تبسط هياكل البيانات هذه بنية تطبيقات سطح المكتب وتسمح للخدمات بالتوسع بشكل أفضل. الهياكل غير الثابتة هي سر نجاح كلوجور وسكالا ، وحتى مجتمع جافا سكريبت يستفيد منها الآن ، لأن لديهم مكتبة Immutable.js ،مكتوب في أحشاء شركة الفيسبوك.تحت المقطع - فيديو وترجمة لتقرير Juan Puente من مؤتمر C ++ Russia 2019 في موسكو. يتحدث جوان عن Immer ، وهي مكتبة من الهياكل غير القابلة للتغيير لـ C ++. في المنشور:
هياكل البيانات الثابتة لا تغير قيمها. للقيام بشيء معهم ، تحتاج إلى إنشاء قيم جديدة. تبقى القيم القديمة في نفس المكان ، بحيث يمكن قراءتها من تيارات مختلفة دون مشاكل وأقفال. ونتيجة لذلك ، يمكن مشاركة الموارد بشكل أكثر عقلانية وترتيب ، لأن القيم القديمة والجديدة يمكن أن تستخدم البيانات المشتركة. وبفضل هذا ، فهي أسرع بكثير في المقارنة مع بعضها البعض وتخزين تاريخ العمليات بشكل مضغوط مع إمكانية الإلغاء. كل هذا يناسب تمامًا الأنظمة متعددة الخيوط والتفاعلية: تبسط هياكل البيانات هذه بنية تطبيقات سطح المكتب وتسمح للخدمات بالتوسع بشكل أفضل. الهياكل غير الثابتة هي سر نجاح كلوجور وسكالا ، وحتى مجتمع جافا سكريبت يستفيد منها الآن ، لأن لديهم مكتبة Immutable.js ،مكتوب في أحشاء شركة الفيسبوك.تحت المقطع - فيديو وترجمة لتقرير Juan Puente من مؤتمر C ++ Russia 2019 في موسكو. يتحدث جوان عن Immer ، وهي مكتبة من الهياكل غير القابلة للتغيير لـ C ++. في المنشور:- المزايا المعمارية للحصانة ؛
- إنشاء نوع ناقل مستمر فعال يعتمد على أشجار لجنة لوائح الراديو ؛
- تحليل العمارة على سبيل المثال محرر نص بسيط.
مأساة العمارة القائمة على القيمة
لفهم أهمية هياكل البيانات الثابتة ، نناقش دلالات القيم. هذه ميزة مهمة جدًا في C ++ ، أعتبرها واحدة من المزايا الرئيسية لهذه اللغة. لكل هذا ، من الصعب جدًا استخدام دلالات القيم كما نرغب. أعتقد أن هذه مأساة العمارة القائمة على القيمة ، والطريق إلى هذه المأساة مرصوفة بالنوايا الحسنة. لنفترض أننا بحاجة إلى كتابة برنامج تفاعلي بناءً على نموذج بيانات مع تمثيل مستند قابل للتحرير من قبل المستخدم. عندما تستخدم العمارة القائمة على القيم في قلب هذا النموذج أنواعًا بسيطة ومريحة من القيم الموجودة بالفعل في اللغة: vector، map، tuple، ،struct. يتم إنشاء منطق التطبيق من الوظائف التي تأخذ المستندات حسب القيمة وترجع نسخة جديدة من المستند حسب القيمة. قد يتغير هذا المستند داخل الوظيفة (كما يحدث أدناه) ، ولكن دلالات القيم في C ++ ، المطبقة على الوسيطة حسب القيمة ونوع الإرجاع حسب القيمة ، تضمن عدم وجود أي آثار جانبية.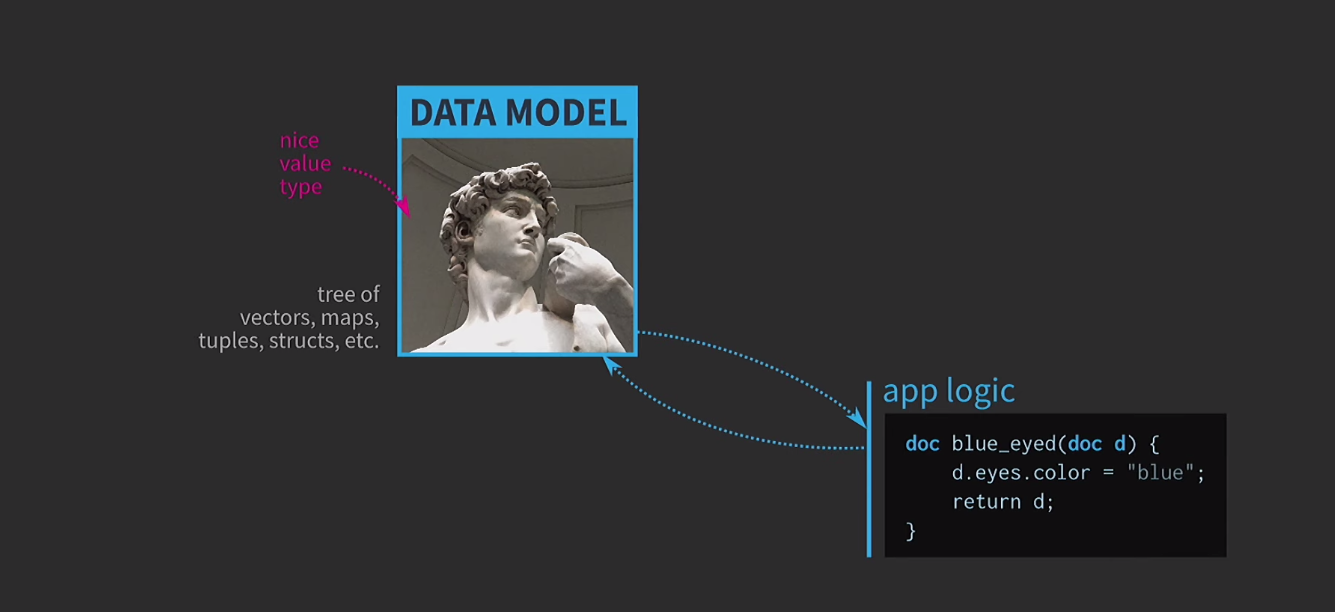 هذه الميزة سهلة للغاية للتحليل والاختبار.
هذه الميزة سهلة للغاية للتحليل والاختبار. نظرًا لأننا نعمل مع القيم ، سنحاول تنفيذ التراجع عن الإجراء. يمكن أن يكون هذا صعبًا ، ولكن مع نهجنا ، تكون مهمة تافهة: لدينا
نظرًا لأننا نعمل مع القيم ، سنحاول تنفيذ التراجع عن الإجراء. يمكن أن يكون هذا صعبًا ، ولكن مع نهجنا ، تكون مهمة تافهة: لدينا std::vectorنسخ مختلفة من الوثيقة مع حالات مختلفة.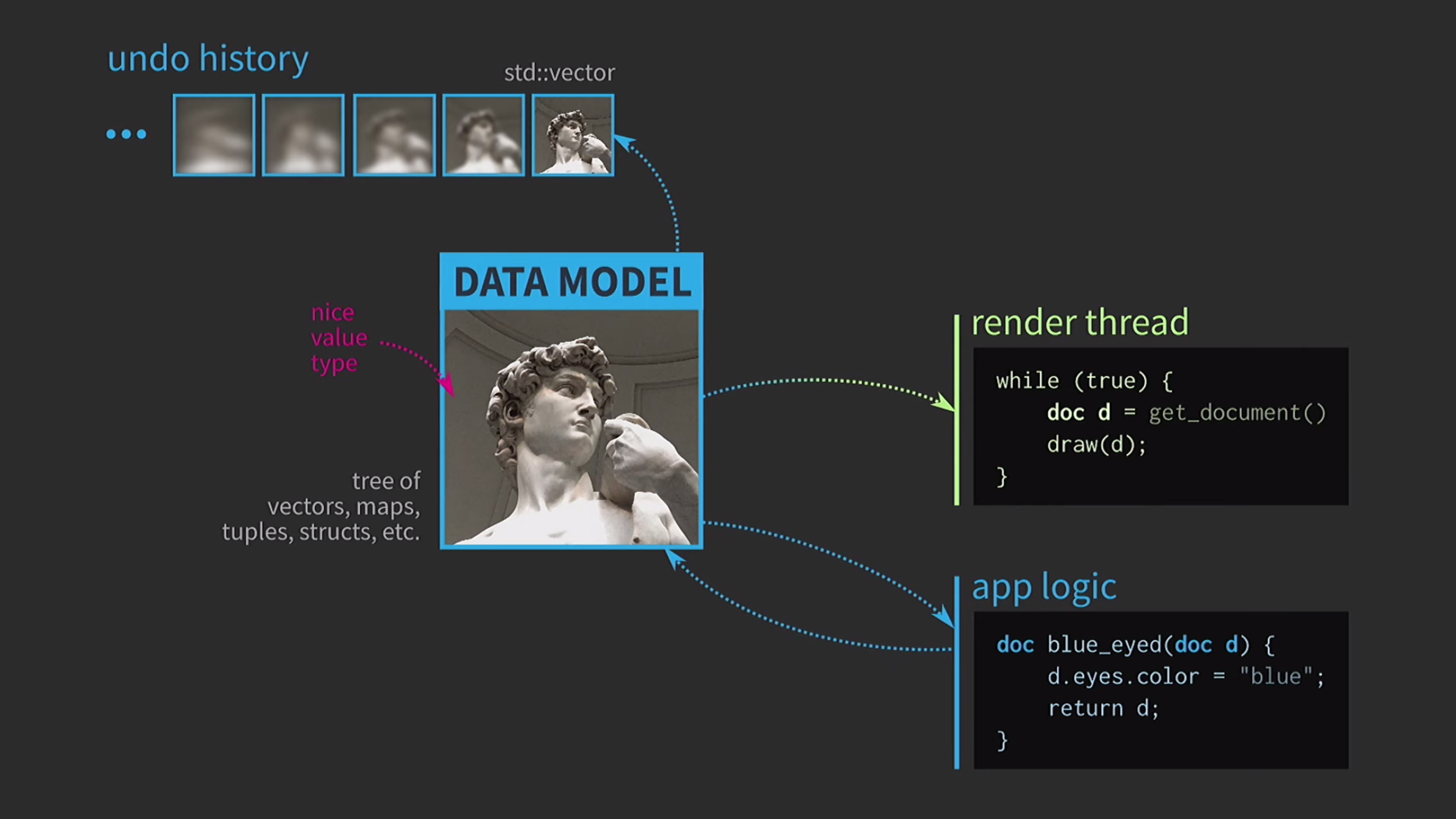 لنفترض أن لدينا أيضًا واجهة مستخدم ، ولضمان استجابتها ، يجب أن يتم تعيين واجهة المستخدم في سلسلة محادثات منفصلة. يتم إرسال المستند إلى دفق آخر عن طريق الرسالة ، ويتم التفاعل أيضًا على أساس الرسائل ، وليس من خلال مشاركة الحالة باستخدام
لنفترض أن لدينا أيضًا واجهة مستخدم ، ولضمان استجابتها ، يجب أن يتم تعيين واجهة المستخدم في سلسلة محادثات منفصلة. يتم إرسال المستند إلى دفق آخر عن طريق الرسالة ، ويتم التفاعل أيضًا على أساس الرسائل ، وليس من خلال مشاركة الحالة باستخدام mutexes. عندما يتم استلام النسخة من قبل الدفق الثاني ، هناك يمكنك تنفيذ جميع العمليات اللازمة. غالبًا ما يكون حفظ المستند على القرص بطيئًا جدًا ، خاصة إذا كان المستند كبيرًا. لذلك ، يتم استخدام
غالبًا ما يكون حفظ المستند على القرص بطيئًا جدًا ، خاصة إذا كان المستند كبيرًا. لذلك ، يتم استخدام std::asyncهذه العملية بشكل غير متزامن. نحن نستخدم لامدا ، ونضع علامة مساوية بداخله للحصول على نسخة ، والآن يمكنك الحفظ بدون أنواع بدائية أخرى من المزامنة.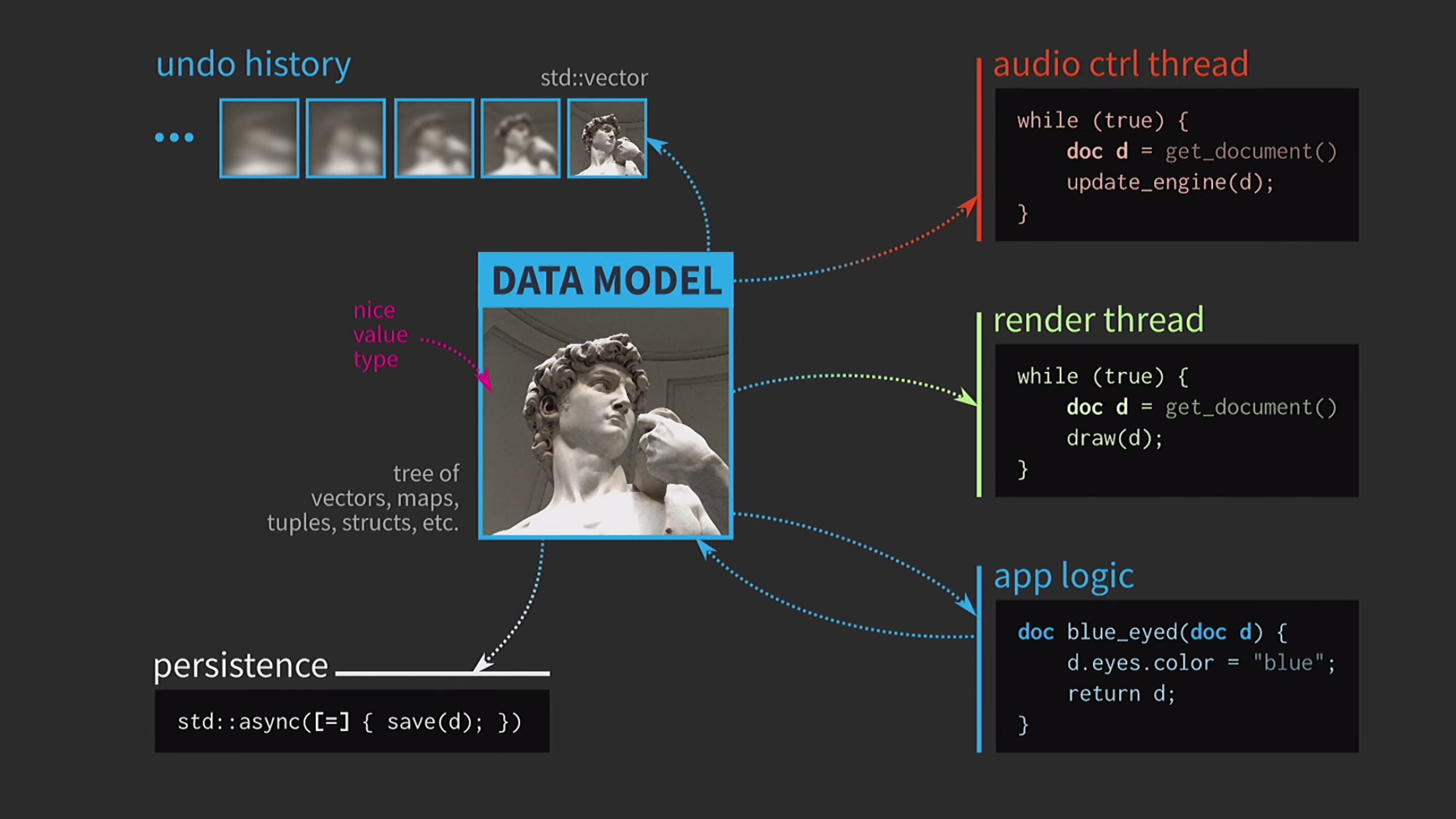 علاوة على ذلك ، لنفترض أن لدينا أيضًا تدفق تحكم في الصوت. كما قلت ، لقد عملت كثيرًا مع برنامج الموسيقى ، والصوت هو تمثيل آخر لمستندنا ، يجب أن يكون في دفق منفصل. لذلك ، يلزم أيضًا نسخة من المستند لهذا الدفق.ونتيجة لذلك ، حصلنا على مخطط جميل للغاية ، ولكن ليس واقعيًا جدًا.
علاوة على ذلك ، لنفترض أن لدينا أيضًا تدفق تحكم في الصوت. كما قلت ، لقد عملت كثيرًا مع برنامج الموسيقى ، والصوت هو تمثيل آخر لمستندنا ، يجب أن يكون في دفق منفصل. لذلك ، يلزم أيضًا نسخة من المستند لهذا الدفق.ونتيجة لذلك ، حصلنا على مخطط جميل للغاية ، ولكن ليس واقعيًا جدًا.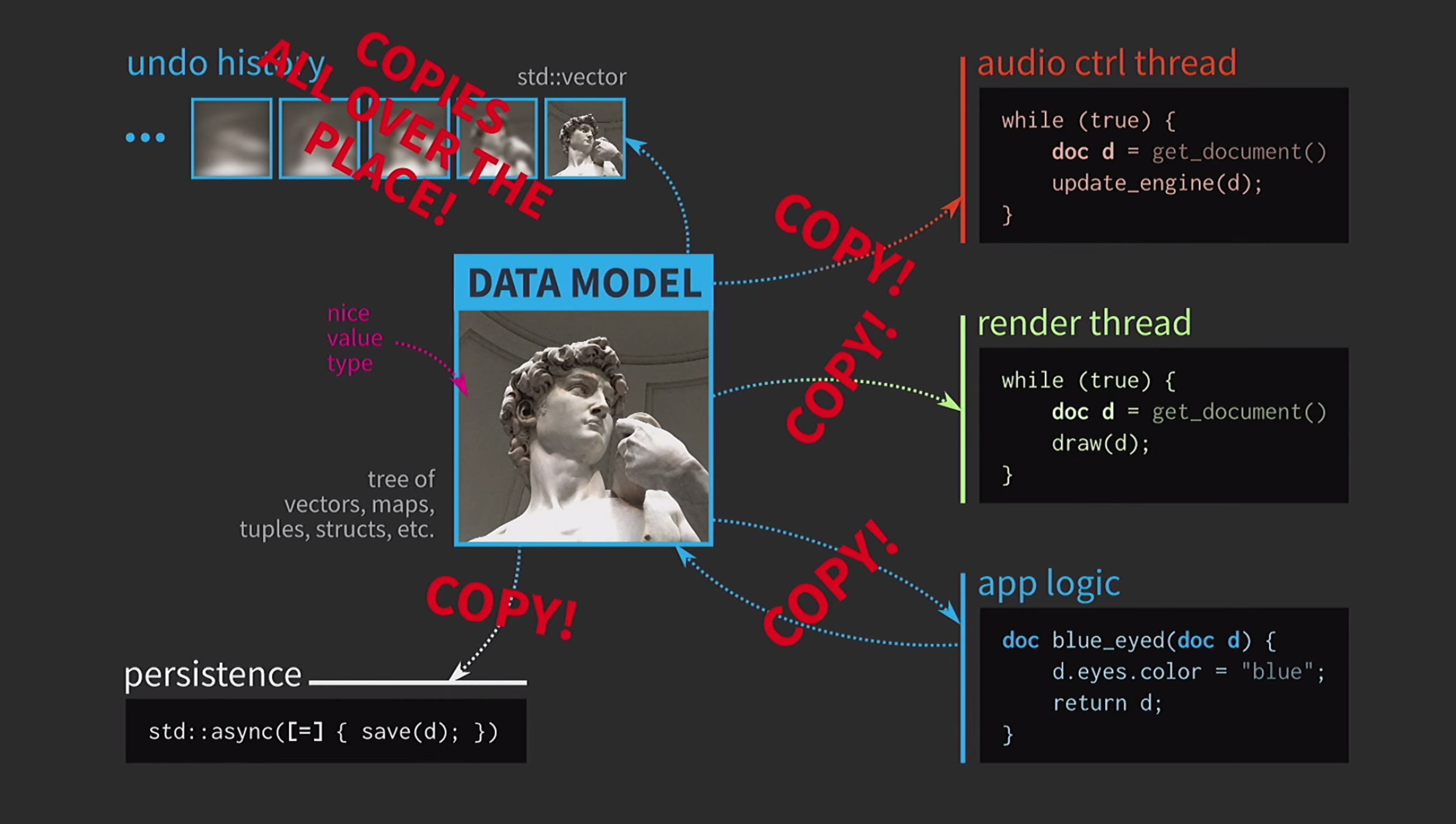 يجب عليه نسخ المستندات باستمرار ، ويأخذ سجل الإجراء للإلغاء غيغابايت ، ولكل عرض لواجهة المستخدم تحتاج إلى إنشاء نسخة عميقة من المستند. بشكل عام ، كل التفاعلات مكلفة للغاية.
يجب عليه نسخ المستندات باستمرار ، ويأخذ سجل الإجراء للإلغاء غيغابايت ، ولكل عرض لواجهة المستخدم تحتاج إلى إنشاء نسخة عميقة من المستند. بشكل عام ، كل التفاعلات مكلفة للغاية.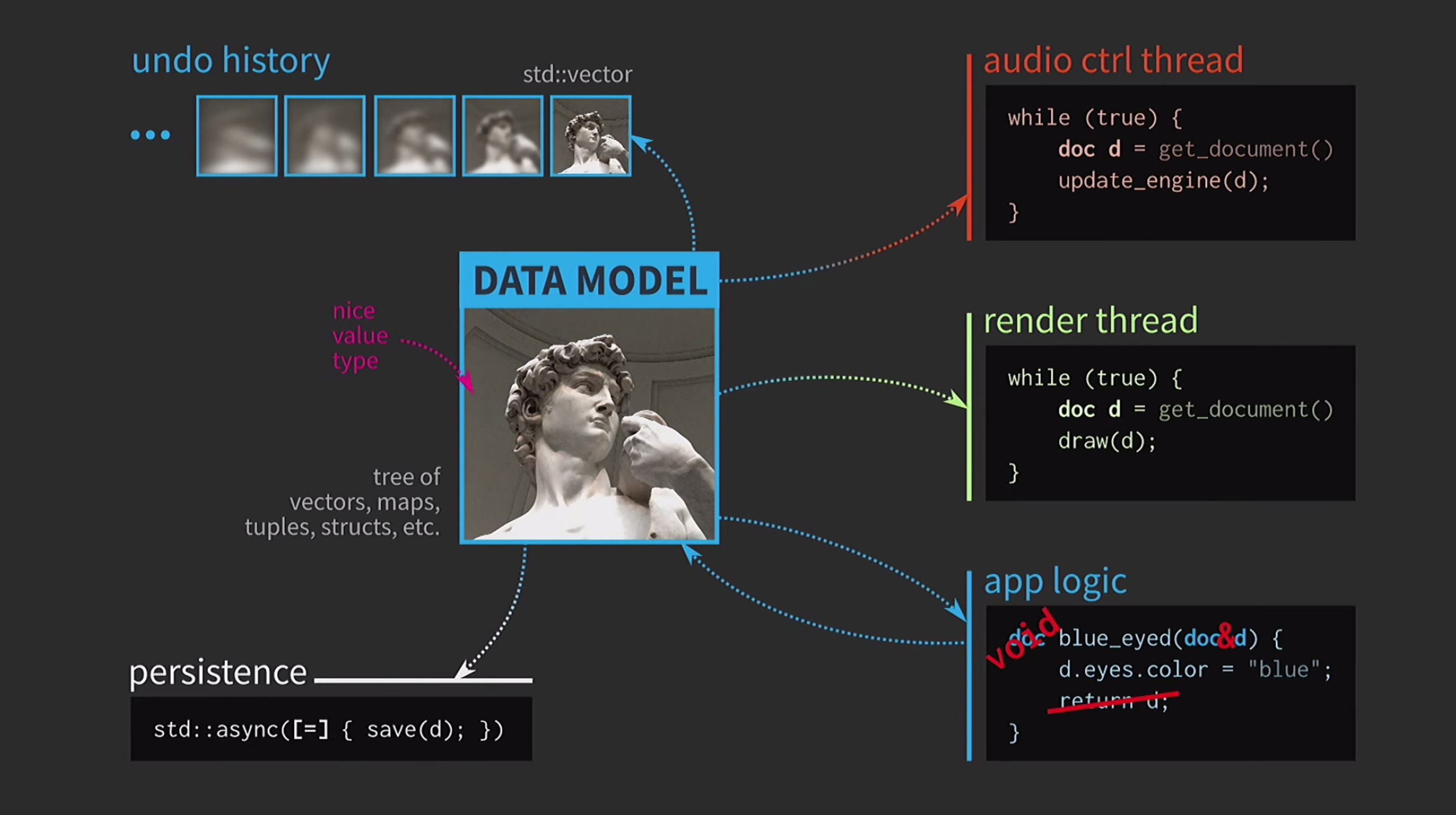 ماذا يفعل مطور C ++ في هذه الحالة؟ بدلاً من قبول المستند حسب القيمة ، يقبل منطق التطبيق الآن رابطًا للمستند ويقوم بتحديثه إذا لزم الأمر. في هذه الحالة ، لا تحتاج إلى إرجاع أي شيء. لكننا الآن لا نتعامل مع القيم ، ولكن مع الأشياء والمواقع. هذا يخلق مشاكل جديدة: إذا كان هناك رابط إلى الدولة مع وصول مشترك ، فأنت بحاجة إليه
ماذا يفعل مطور C ++ في هذه الحالة؟ بدلاً من قبول المستند حسب القيمة ، يقبل منطق التطبيق الآن رابطًا للمستند ويقوم بتحديثه إذا لزم الأمر. في هذه الحالة ، لا تحتاج إلى إرجاع أي شيء. لكننا الآن لا نتعامل مع القيم ، ولكن مع الأشياء والمواقع. هذا يخلق مشاكل جديدة: إذا كان هناك رابط إلى الدولة مع وصول مشترك ، فأنت بحاجة إليه mutex. هذا أمر مكلف للغاية ، لذلك سيكون هناك بعض التمثيل لواجهة المستخدم لدينا في شكل شجرة معقدة للغاية من مختلف الحاجيات.يجب أن تتلقى جميع هذه العناصر تحديثات عند تغيير المستند ، لذلك هناك حاجة إلى بعض آلية قائمة الانتظار لإشارات التغيير. علاوة على ذلك ، لم يعد تاريخ المستند عبارة عن مجموعة من الحالات ؛ بل سيكون تنفيذًا لنمط الفريق. يجب تنفيذ العملية مرتين ، في اتجاه واحد وفي الآخر ، والتأكد من أن كل شيء متماثل. إن الحفظ في سلسلة رسائل منفصلة أمر صعب للغاية ، لذا يجب التخلي عن هذا.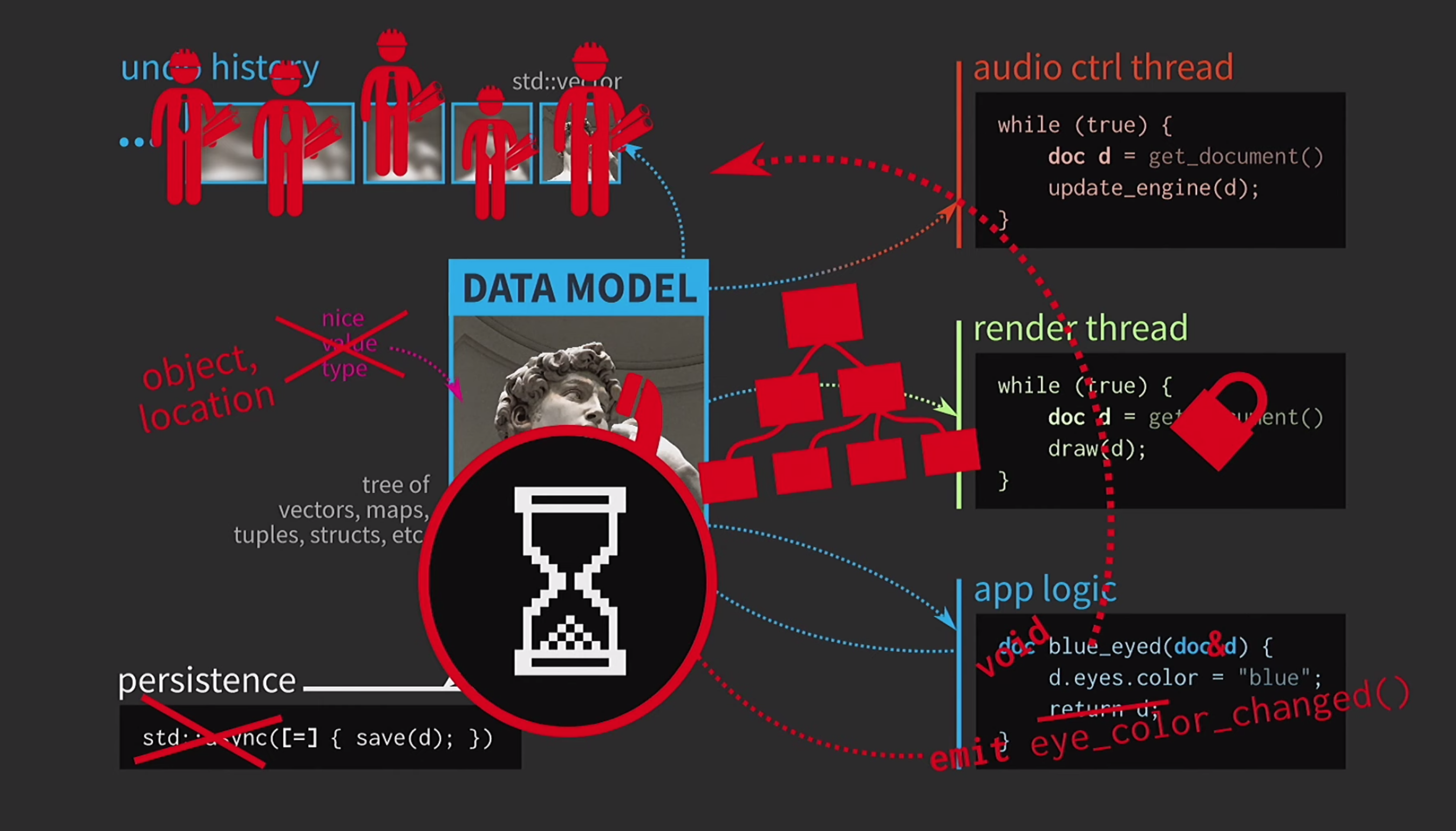 اعتاد المستخدمون على صورة الساعة الرملية ، لذلك لا بأس إذا انتظروا قليلاً. شيء آخر مخيف - وحش المعكرونة يحكم الآن رمزنا.في أي نقطة انحدر كل شيء؟ لقد قمنا بتصميم الكود الخاص بنا بشكل جيد للغاية ، ثم اضطررنا إلى التنازل بسبب النسخ. ولكن في C ++ ، يلزم النسخ لتمرير القيمة فقط للبيانات القابلة للتغيير. إذا كان الكائن غير قابل للتغيير ، فيمكن عندئذ تنفيذ عامل التخصيص بحيث يقوم بنسخ المؤشر فقط إلى التمثيل الداخلي وليس أكثر.
اعتاد المستخدمون على صورة الساعة الرملية ، لذلك لا بأس إذا انتظروا قليلاً. شيء آخر مخيف - وحش المعكرونة يحكم الآن رمزنا.في أي نقطة انحدر كل شيء؟ لقد قمنا بتصميم الكود الخاص بنا بشكل جيد للغاية ، ثم اضطررنا إلى التنازل بسبب النسخ. ولكن في C ++ ، يلزم النسخ لتمرير القيمة فقط للبيانات القابلة للتغيير. إذا كان الكائن غير قابل للتغيير ، فيمكن عندئذ تنفيذ عامل التخصيص بحيث يقوم بنسخ المؤشر فقط إلى التمثيل الداخلي وليس أكثر.const auto v0 = vector<int>{};
فكر في بنية بيانات يمكن أن تساعدنا. في المتجه أدناه ، يتم وضع علامة على جميع الطرق على constأنها غير قابلة للتغيير. عند التنفيذ .push_back، لا يتم تحديث المتجه ؛ بدلاً من ذلك ، يتم إرجاع متجه جديد تتم إضافة البيانات المنقولة إليه. للأسف ، لا يمكننا استخدام الأقواس المربعة مع هذا النهج بسبب كيفية تعريفها. بدلاً من ذلك ، يمكنك استخدام الوظيفة.setالذي يُرجع إصدارًا جديدًا بعنصر محدث. يحتوي هيكل البيانات لدينا الآن على خاصية تسمى المثابرة في البرمجة الوظيفية. هذا لا يعني أننا نحفظ بنية البيانات هذه على محرك الأقراص الثابتة ، ولكن حقيقة أنه عندما يتم تحديثها ، لا يتم حذف المحتوى القديم - بدلاً من ذلك ، يتم إنشاء شوكة جديدة من عالمنا ، أي الهيكل. بفضل هذا ، يمكننا مقارنة القيم السابقة بالحاضر - يتم ذلك بمساعدة اثنين assert.const auto v0 = vector<int>{};
const auto v1 = v0.push_back(15);
const auto v2 = v1.push_back(16);
const auto v3 = v2.set(0, 42);
assert(v2.size() == v0.size() + 2);
assert(v3[0] - v1[0] == 27);
يمكن الآن التحقق من التغييرات مباشرة ، فهي لم تعد خصائص مخفية لبنية البيانات. هذه الميزة ذات قيمة خاصة في الأنظمة التفاعلية حيث يتعين علينا باستمرار تغيير البيانات.خاصية أخرى مهمة هي المشاركة الهيكلية. نحن الآن لا نقوم بنسخ جميع البيانات لكل إصدار جديد من بنية البيانات. حتى مع .push_backو.setلا يتم نسخ جميع البيانات ، ولكن فقط جزء صغير منها. تتمتع جميع شوكاتنا بإمكانية وصول مشتركة إلى عرض مضغوط يتناسب مع عدد التغييرات وليس عدد النسخ. ويترتب على ذلك أيضًا أن المقارنة سريعة جدًا: إذا تم تخزين كل شيء في كتلة ذاكرة واحدة ، في مؤشر واحد ، فيمكنك ببساطة مقارنة المؤشرات وعدم فحص العناصر الموجودة داخلها ، إذا كانت متساوية.منذ متجه من هذا القبيل، كما يبدو لي، أمر مفيد للغاية، وأنا تنفيذه في مكتبة منفصلة: هذا هو إمير - مكتبة هياكل ثابتة، وهو مشروع مفتوح المصدر.عند كتابته ، أردت أن يكون استخدامه مألوفًا لمطوري C ++. هناك العديد من المكتبات التي تطبق مفاهيم البرمجة الوظيفية في C ++ ، ولكنها تعطي الانطباع بأن المطورين يكتبون لـ Haskell ، وليس لـ C ++. هذا يخلق إزعاجًا. بالإضافة إلى ذلك ، حققت أداءً جيدًا. يستخدم الناس لغة C ++ عندما تكون الموارد المتاحة محدودة. وأخيرًا ، أردت أن تكون المكتبة قابلة للتخصيص. يرتبط هذا المتطلب بمتطلبات الأداء.بحثا عن ناقل سحري
في الجزء الثاني من التقرير ، سننظر في كيفية هيكلة هذا الناقل غير الثابت. أسهل طريقة لفهم مبادئ بنية البيانات هذه هي البدء بقائمة منتظمة. إذا كنت معتادًا قليلاً على البرمجة الوظيفية (باستخدام Lisp أو Haskell كمثال) ، فأنت تعلم أن القوائم هي أكثر هياكل البيانات غير الثابتة شيوعًا.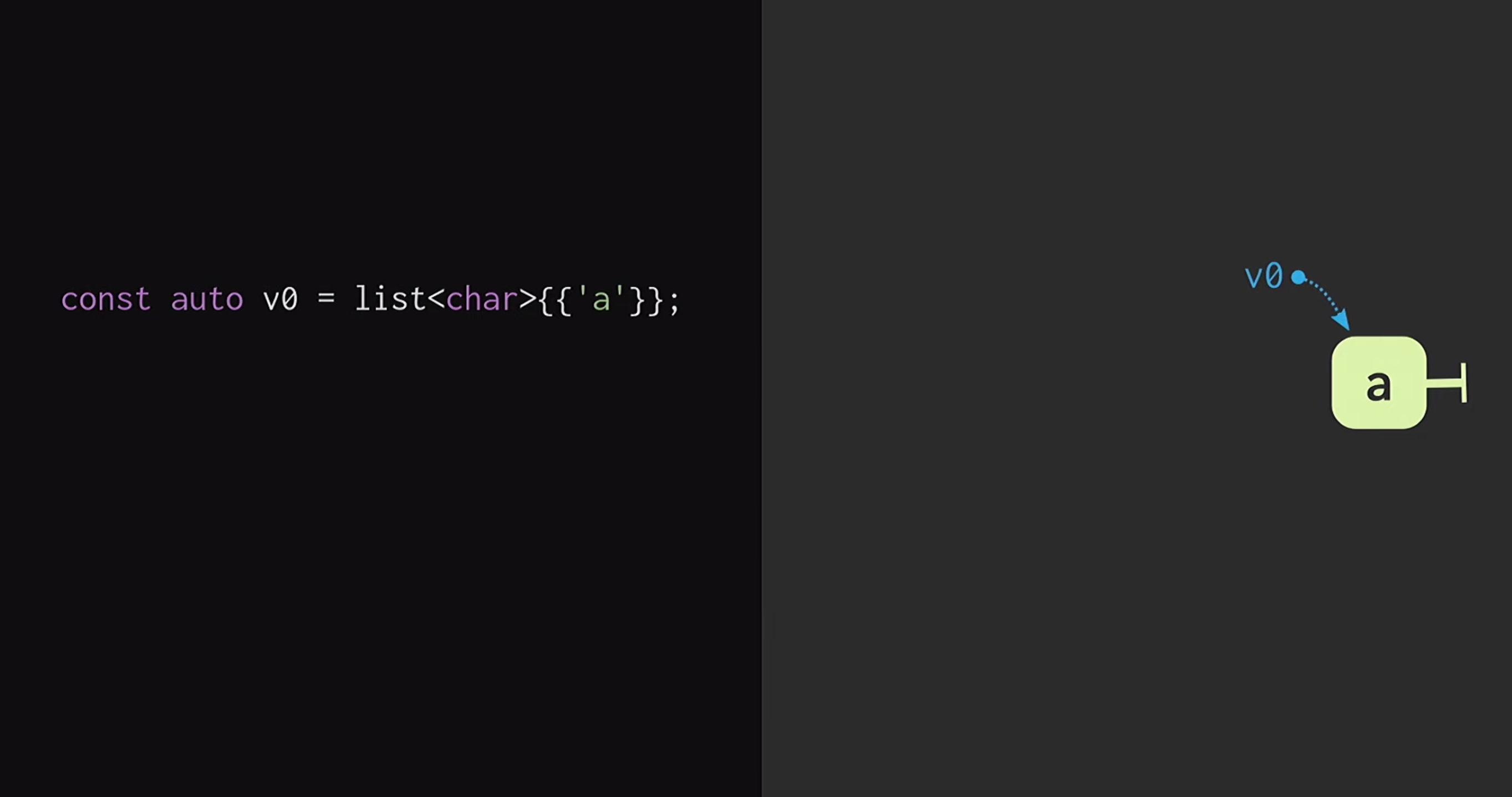 في البداية ، لنفترض أن لدينا قائمة بها عقدة واحدة
في البداية ، لنفترض أن لدينا قائمة بها عقدة واحدة v1أنها v0تشير إلى عناصر مختلفة.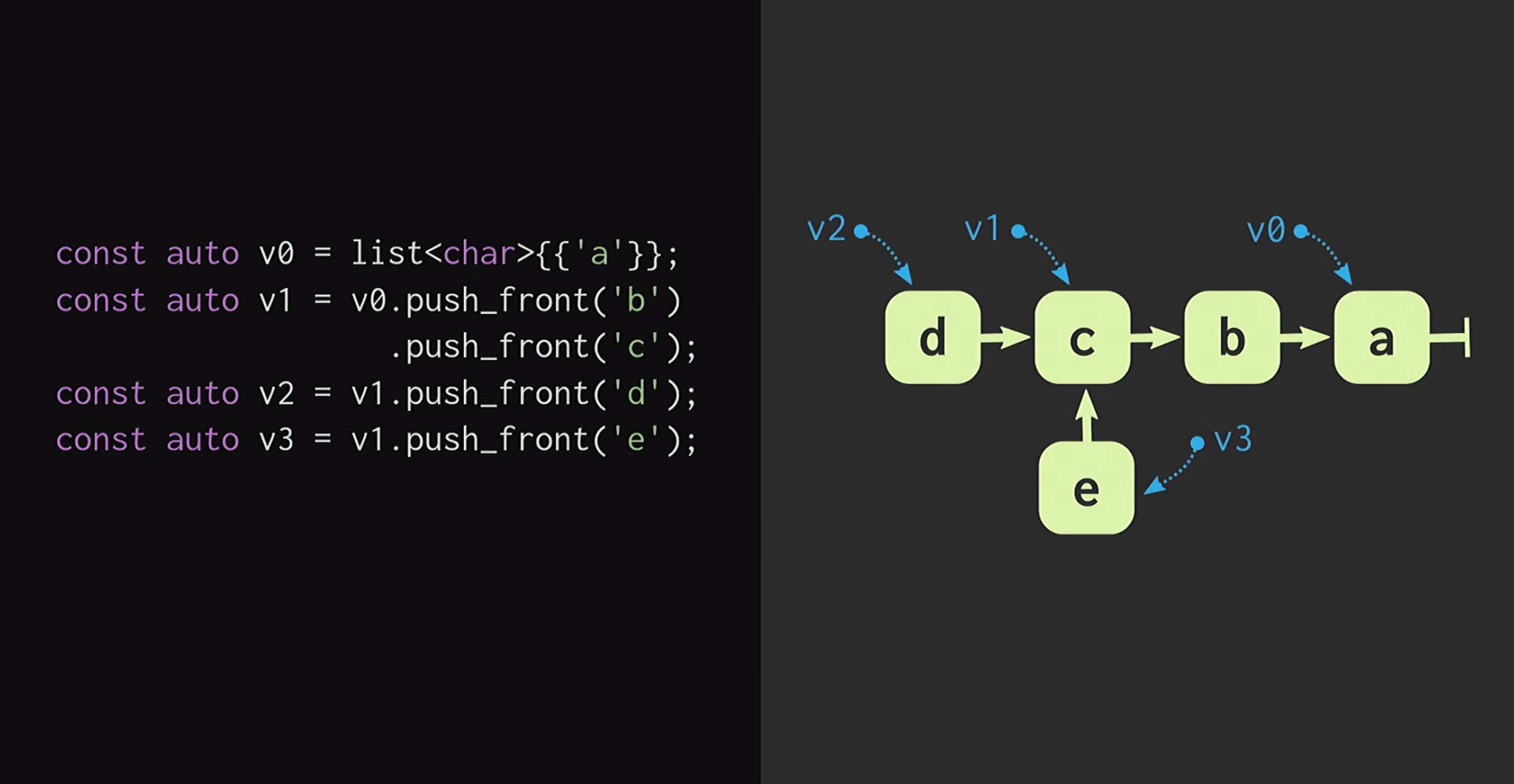 يمكننا أيضًا إنشاء شوكة للواقع ، أي إنشاء قائمة جديدة لها نفس النهاية ، ولكن بداية مختلفة.تمت دراسة هياكل البيانات هذه لفترة طويلة: كتب كريس أوكاساكي العمل الأساسي لهياكل البيانات الوظيفية البحتة . بالإضافة إلى ذلك ، فإن بنية بيانات Finger Tree التي اقترحها Ralf Hinze و Ross Paterson مثيرة للاهتمام للغاية . ولكن بالنسبة لـ C ++ ، فإن هياكل البيانات هذه لا تعمل بشكل جيد. يستخدمون العقد الصغيرة ، ونحن نعلم أن العقد الصغيرة في C ++ تعني نقصًا في كفاءة التخزين المؤقت.بالإضافة إلى ذلك ، غالبًا ما يعتمدون على الخصائص التي لا تمتلكها C ++ ، مثل الكسل. لذلك ، فإن عمل Phil Bagwell على هياكل البيانات الثابتة هو أكثر فائدة بالنسبة لنا - رابط مكتوب في أوائل 2000s ، وكذلك عمل Rich Hickey - link، مؤلف كلوجور. أنشأ ريتش هيكي قائمة ، وهي في الواقع ليست قائمة ، ولكنها تستند إلى هياكل البيانات الحديثة: المتجهات وخرائط التجزئة. تتمتع هياكل البيانات هذه بكفاءة التخزين المؤقت وتتفاعل بشكل جيد مع المعالجات الحديثة ، والتي من غير المرغوب فيها العمل مع العقد الصغيرة. يمكن استخدام هذه الهياكل في C ++.كيف تبني ناقلات مناعية؟ في صميم أي هيكل ، حتى أنه يشبه عن بعد ناقل ، يجب أن يكون مصفوفة. لكن الصفيف ليس لديه مشاركة هيكلية. لتغيير أي عنصر من عناصر الصفيف ، دون فقدان خاصية الثبات ، يجب نسخ الصفيف بأكمله. من أجل عدم القيام بذلك ، يمكن تقسيم الصفيف إلى قطع منفصلة.الآن ، عند تحديث عنصر متجه ، نحتاج إلى نسخ قطعة واحدة فقط ، وليس نسخ المتجه بأكمله. لكن هذه القطع نفسها ليست بنية بيانات ؛ يجب دمجها بطريقة أو بأخرى. ضعهم في مصفوفة أخرى. مرة أخرى ، تبرز المشكلة أن المصفوفة يمكن أن تكون كبيرة جدًا ، ومن ثم يستغرق نسخها مرة أخرى الكثير من الوقت.نقسم هذا الصفيف إلى أجزاء ، ونضعه مرة أخرى في صفيف منفصل ، ونكرر هذا الإجراء حتى يكون هناك صفيف جذر واحد فقط. يسمى الهيكل الناتج بشجرة متبقية. يتم وصف هذه الشجرة بواسطة الثابت M = 2B ، أي عامل التفرع. يجب أن يكون هذا المؤشر الفرعي قوة من اثنين ، وسنكتشف قريبًا السبب. في المثال الموجود على الشريحة ، يتم استخدام الكتل المكونة من أربعة أحرف ، ولكن في الممارسة العملية ، يتم استخدام الكتل المكونة من 32 حرفًا. هناك تجارب يمكنك من خلالها العثور على حجم الكتلة الأمثل لهيكل معين. يسمح لك هذا بتحقيق أفضل نسبة للوصول المشترك الهيكلي إلى وقت الوصول: كلما انخفضت الشجرة ، قل وقت الوصول.قراءة هذا ، ربما يعتقد المطورون الذين يكتبون بلغة C ++: لكن أي هياكل قائمة على الأشجار بطيئة جدًا! تنمو الأشجار مع زيادة في عدد العناصر فيها ، وبسبب هذا ، يتم تقليل أوقات الوصول. هذا هو السبب في أن المبرمجين يفضلون
يمكننا أيضًا إنشاء شوكة للواقع ، أي إنشاء قائمة جديدة لها نفس النهاية ، ولكن بداية مختلفة.تمت دراسة هياكل البيانات هذه لفترة طويلة: كتب كريس أوكاساكي العمل الأساسي لهياكل البيانات الوظيفية البحتة . بالإضافة إلى ذلك ، فإن بنية بيانات Finger Tree التي اقترحها Ralf Hinze و Ross Paterson مثيرة للاهتمام للغاية . ولكن بالنسبة لـ C ++ ، فإن هياكل البيانات هذه لا تعمل بشكل جيد. يستخدمون العقد الصغيرة ، ونحن نعلم أن العقد الصغيرة في C ++ تعني نقصًا في كفاءة التخزين المؤقت.بالإضافة إلى ذلك ، غالبًا ما يعتمدون على الخصائص التي لا تمتلكها C ++ ، مثل الكسل. لذلك ، فإن عمل Phil Bagwell على هياكل البيانات الثابتة هو أكثر فائدة بالنسبة لنا - رابط مكتوب في أوائل 2000s ، وكذلك عمل Rich Hickey - link، مؤلف كلوجور. أنشأ ريتش هيكي قائمة ، وهي في الواقع ليست قائمة ، ولكنها تستند إلى هياكل البيانات الحديثة: المتجهات وخرائط التجزئة. تتمتع هياكل البيانات هذه بكفاءة التخزين المؤقت وتتفاعل بشكل جيد مع المعالجات الحديثة ، والتي من غير المرغوب فيها العمل مع العقد الصغيرة. يمكن استخدام هذه الهياكل في C ++.كيف تبني ناقلات مناعية؟ في صميم أي هيكل ، حتى أنه يشبه عن بعد ناقل ، يجب أن يكون مصفوفة. لكن الصفيف ليس لديه مشاركة هيكلية. لتغيير أي عنصر من عناصر الصفيف ، دون فقدان خاصية الثبات ، يجب نسخ الصفيف بأكمله. من أجل عدم القيام بذلك ، يمكن تقسيم الصفيف إلى قطع منفصلة.الآن ، عند تحديث عنصر متجه ، نحتاج إلى نسخ قطعة واحدة فقط ، وليس نسخ المتجه بأكمله. لكن هذه القطع نفسها ليست بنية بيانات ؛ يجب دمجها بطريقة أو بأخرى. ضعهم في مصفوفة أخرى. مرة أخرى ، تبرز المشكلة أن المصفوفة يمكن أن تكون كبيرة جدًا ، ومن ثم يستغرق نسخها مرة أخرى الكثير من الوقت.نقسم هذا الصفيف إلى أجزاء ، ونضعه مرة أخرى في صفيف منفصل ، ونكرر هذا الإجراء حتى يكون هناك صفيف جذر واحد فقط. يسمى الهيكل الناتج بشجرة متبقية. يتم وصف هذه الشجرة بواسطة الثابت M = 2B ، أي عامل التفرع. يجب أن يكون هذا المؤشر الفرعي قوة من اثنين ، وسنكتشف قريبًا السبب. في المثال الموجود على الشريحة ، يتم استخدام الكتل المكونة من أربعة أحرف ، ولكن في الممارسة العملية ، يتم استخدام الكتل المكونة من 32 حرفًا. هناك تجارب يمكنك من خلالها العثور على حجم الكتلة الأمثل لهيكل معين. يسمح لك هذا بتحقيق أفضل نسبة للوصول المشترك الهيكلي إلى وقت الوصول: كلما انخفضت الشجرة ، قل وقت الوصول.قراءة هذا ، ربما يعتقد المطورون الذين يكتبون بلغة C ++: لكن أي هياكل قائمة على الأشجار بطيئة جدًا! تنمو الأشجار مع زيادة في عدد العناصر فيها ، وبسبب هذا ، يتم تقليل أوقات الوصول. هذا هو السبب في أن المبرمجين يفضلون std::unordered_map، بدلاً من std::map. أسارع إلى طمأنتك: تنمو شجرتنا ببطء شديد. إن المتجه الذي يحتوي على جميع القيم الممكنة لـ 32 بت هو ارتفاع 7 مستويات فقط. يمكن تجريبًا أنه مع حجم البيانات هذا ، تؤثر نسبة ذاكرة التخزين المؤقت إلى حجم التحميل بشكل كبير على الأداء من عمق الشجرة.دعونا نرى كيف يتم الوصول إلى عنصر شجرة. افترض أنك بحاجة إلى الرجوع إلى العنصر 17. نأخذ تمثيلًا ثنائيًا للفهرس ونقسمه إلى مجموعات بحجم عامل التفرع. في كل مجموعة ، نستخدم القيمة الثنائية المقابلة وبالتالي ننزل إلى أسفل الشجرة.بعد ذلك ، لنفترض أننا بحاجة إلى إجراء تغيير في بنية البيانات هذه ، أي تنفيذ الطريقة
في كل مجموعة ، نستخدم القيمة الثنائية المقابلة وبالتالي ننزل إلى أسفل الشجرة.بعد ذلك ، لنفترض أننا بحاجة إلى إجراء تغيير في بنية البيانات هذه ، أي تنفيذ الطريقة .set.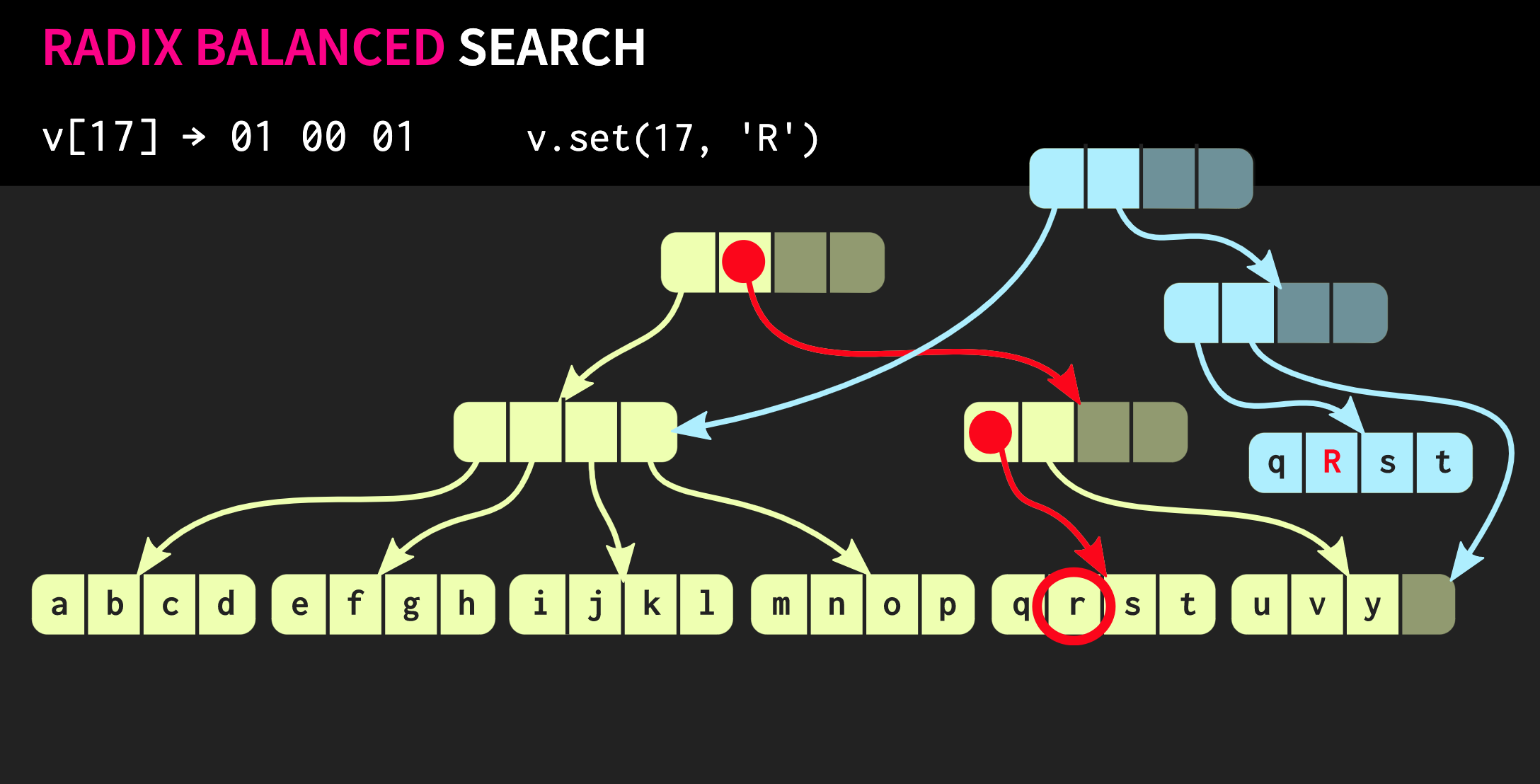 للقيام بذلك ، تحتاج أولاً إلى نسخ الكتلة التي يوجد فيها العنصر ، ثم نسخ كل عقدة داخلية في الطريق إلى العنصر. من ناحية ، يجب نسخ الكثير من البيانات ، ولكن في الوقت نفسه جزء كبير من هذه البيانات شائع ، وهذا يعوض عن حجمها.بالمناسبة ، هناك بنية بيانات أقدم بكثير تشبه إلى حد كبير تلك التي وصفتها. هذه صفحات ذاكرة بها شجرة جدول صفحة. تتم إدارتها أيضًا باستخدام مكالمة
للقيام بذلك ، تحتاج أولاً إلى نسخ الكتلة التي يوجد فيها العنصر ، ثم نسخ كل عقدة داخلية في الطريق إلى العنصر. من ناحية ، يجب نسخ الكثير من البيانات ، ولكن في الوقت نفسه جزء كبير من هذه البيانات شائع ، وهذا يعوض عن حجمها.بالمناسبة ، هناك بنية بيانات أقدم بكثير تشبه إلى حد كبير تلك التي وصفتها. هذه صفحات ذاكرة بها شجرة جدول صفحة. تتم إدارتها أيضًا باستخدام مكالمة fork.دعونا نحاول تحسين هيكل البيانات لدينا. لنفترض أننا بحاجة لربط متجهين. بنية البيانات الموصوفة حتى الآن لها نفس القيود std::vector:التي تحتوي على خلايا فارغة في أقصى يمينها. نظرًا لأن الهيكل متوازن تمامًا ، لا يمكن أن تكون هذه الخلايا الفارغة في منتصف الشجرة. لذلك ، إذا كان هناك متجه ثاني نريد دمجه مع الأول ، فسنحتاج إلى نسخ العناصر إلى خلايا فارغة ، والتي ستنشئ خلايا فارغة في المتجه الثاني ، وفي النهاية سيتعين علينا نسخ المتجه الثاني بالكامل. مثل هذه العملية لها تعقيد حسابي O (n) ، حيث n هو حجم المتجه الثاني.سنحاول تحقيق نتيجة أفضل. هناك نسخة معدلة من هيكل البيانات لدينا تسمى شجرة متوازنة جذرية متوازنة. في هذه البنية ، قد تحتوي العُقد غير الموجودة في المسار أقصى اليسار على خلايا فارغة. لذلك ، في مثل هذه العقد غير المكتملة (أو المريحة) ، من الضروري حساب حجم الشجرة الفرعية. يمكنك الآن تنفيذ عملية ربط معقدة ولكن لوغاريتمية. هذه العملية لتعقيد الوقت الثابت هي O (log (32)). نظرًا لأن الأشجار ضحلة ، فإن وقت الوصول ثابت ، وإن كان طويلًا نسبيًا. نظرًا لحقيقة أن لدينا مثل هذه العملية النقابية ، فإن نسخة مريحة من بنية البيانات هذه تسمى متقاربة: بالإضافة إلى كونها ثابتة ، ويمكنك شوكة ذلك ، يمكن الجمع بين اثنين من هذه الهياكل في واحد.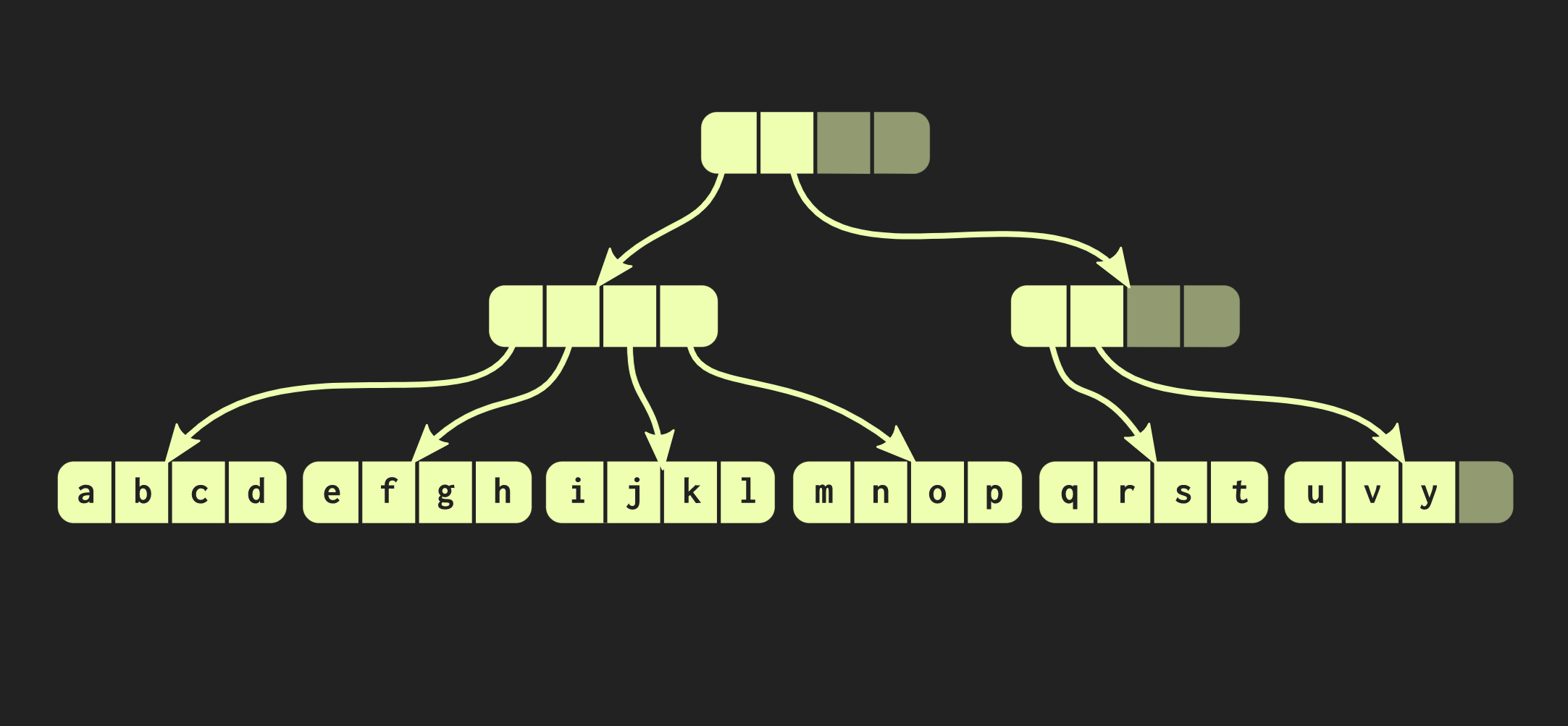 في المثال الذي عملنا معه حتى الآن ، فإن هيكل البيانات أنيق للغاية ، ولكن في الممارسة العملية ، تبدو عمليات التنفيذ في لغة Clojure واللغات الوظيفية الأخرى مختلفة. ينشئون حاويات لكل قيمة ، أي أن كل عنصر في المتجه موجود في خلية منفصلة ، وتحتوي العقد الورقية على مؤشرات لهذه العناصر. لكن هذا النهج غير فعال للغاية ، في C ++ عادة لا تضع كل قيمة في الحاوية. لذلك ، سيكون من الأفضل إذا كانت هذه العناصر موجودة في العقد مباشرة. ثم تنشأ مشكلة أخرى: العناصر المختلفة لها أحجام مختلفة. إذا كان العنصر بنفس حجم المؤشر ، فسيبدو هيكلنا كما هو موضح أدناه:
في المثال الذي عملنا معه حتى الآن ، فإن هيكل البيانات أنيق للغاية ، ولكن في الممارسة العملية ، تبدو عمليات التنفيذ في لغة Clojure واللغات الوظيفية الأخرى مختلفة. ينشئون حاويات لكل قيمة ، أي أن كل عنصر في المتجه موجود في خلية منفصلة ، وتحتوي العقد الورقية على مؤشرات لهذه العناصر. لكن هذا النهج غير فعال للغاية ، في C ++ عادة لا تضع كل قيمة في الحاوية. لذلك ، سيكون من الأفضل إذا كانت هذه العناصر موجودة في العقد مباشرة. ثم تنشأ مشكلة أخرى: العناصر المختلفة لها أحجام مختلفة. إذا كان العنصر بنفس حجم المؤشر ، فسيبدو هيكلنا كما هو موضح أدناه: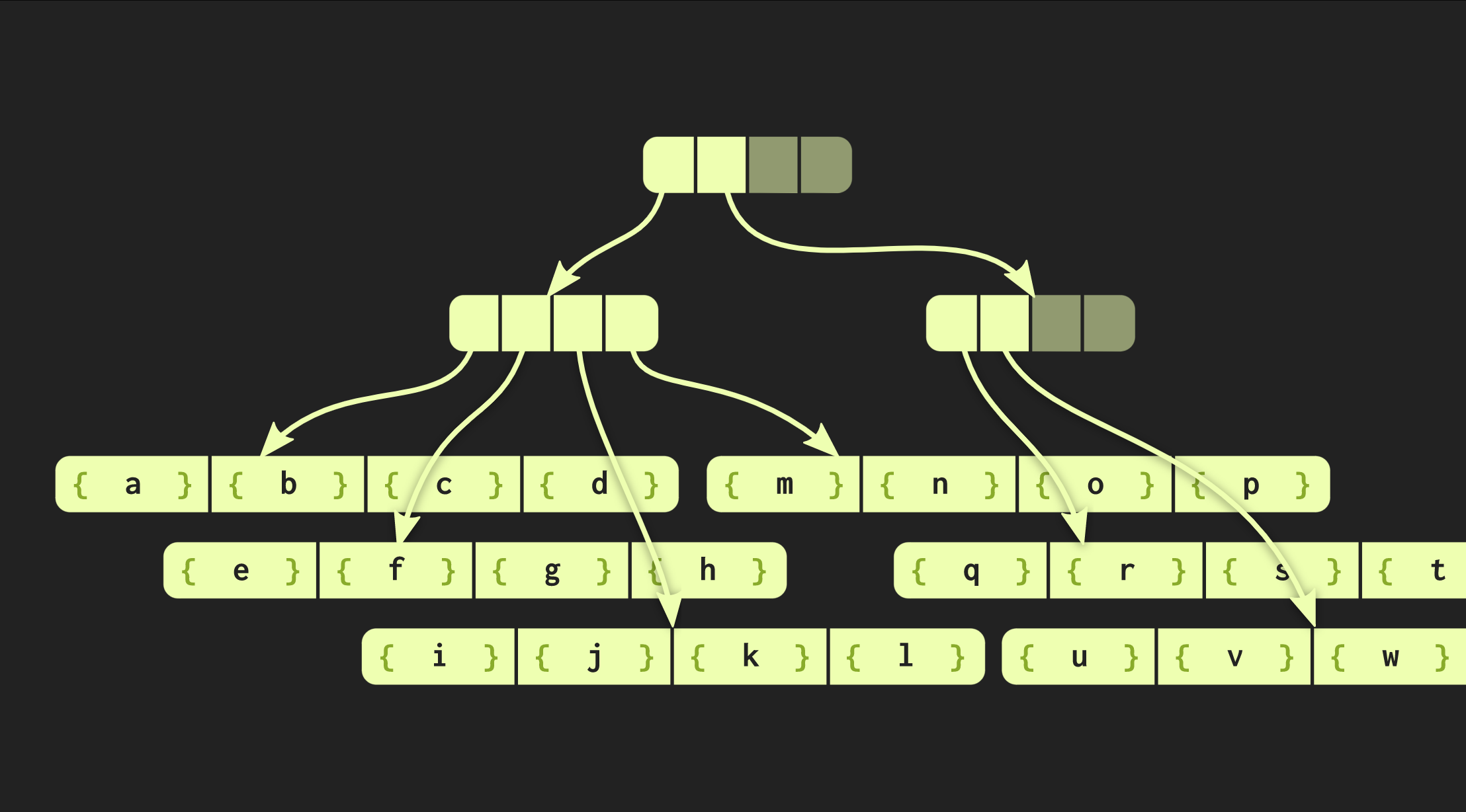 ولكن إذا كانت العناصر كبيرة ، فإن بنية البيانات تفقد الخصائص التي قمنا بقياسها (وقت الوصول O (تسجيل (32) ()) ، لأن نسخ إحدى الأوراق يستغرق الآن وقتًا أطول. لذلك ، قمت بتغيير بنية البيانات هذه بحيث مع زيادة الحجم قلل عدد العناصر الموجودة فيها من عدد هذه العناصر في العقد الورقية ، بل على العكس ، إذا كانت العناصر صغيرة ، يمكن أن تتناسب الآن أكثر ، فالنسخة الجديدة من الشجرة تدعى تضمين شجرة متوازنة الجذر ، لا يتم وصفها من خلال ثابت واحد ، ولكن بواسطة اثنين: واحد منهم يصف العقد الداخلية ، والثانية - المورقة .. تنفيذ الشجرة في C ++ يمكن أن يحسب الحجم الأمثل لعنصر الورقة حسب حجم المؤشرات والعناصر نفسها.تعمل شجرتنا بالفعل بشكل جيد ، ولكن لا يزال من الممكن تحسينها. ألق نظرة على وظيفة مشابهة لوظيفة
ولكن إذا كانت العناصر كبيرة ، فإن بنية البيانات تفقد الخصائص التي قمنا بقياسها (وقت الوصول O (تسجيل (32) ()) ، لأن نسخ إحدى الأوراق يستغرق الآن وقتًا أطول. لذلك ، قمت بتغيير بنية البيانات هذه بحيث مع زيادة الحجم قلل عدد العناصر الموجودة فيها من عدد هذه العناصر في العقد الورقية ، بل على العكس ، إذا كانت العناصر صغيرة ، يمكن أن تتناسب الآن أكثر ، فالنسخة الجديدة من الشجرة تدعى تضمين شجرة متوازنة الجذر ، لا يتم وصفها من خلال ثابت واحد ، ولكن بواسطة اثنين: واحد منهم يصف العقد الداخلية ، والثانية - المورقة .. تنفيذ الشجرة في C ++ يمكن أن يحسب الحجم الأمثل لعنصر الورقة حسب حجم المؤشرات والعناصر نفسها.تعمل شجرتنا بالفعل بشكل جيد ، ولكن لا يزال من الممكن تحسينها. ألق نظرة على وظيفة مشابهة لوظيفة iota:vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = v.push_back(i);
return v;
}
يستغرق الإدخال vector، وينفذ push_backفي نهاية المتجه لكل عدد صحيح بين firstو last، ويعيد ما حدث. كل شيء منظم مع صحة هذه الوظيفة ، لكنها تعمل بشكل غير فعال. تقوم كل مكالمة push_backبنسخ الكتلة الموجودة في أقصى اليسار دون داعٍ: تقوم المكالمة التالية بدفع عنصر آخر ويتم تكرار النسخة مرة أخرى ، ويتم حذف البيانات المنسوخة بالطريقة السابقة.يمكنك تجربة تنفيذ آخر لهذه الوظيفة ، حيث نتخلى عن الثبات داخل الوظيفة. يمكن استخدامه transient vectorمع واجهة برمجة تطبيقات قابلة للتغيير متوافقة مع واجهة برمجة التطبيقات العادية vector. داخل هذه الوظيفة ، كل مكالمة push_backتغير بنية البيانات.vector<int> myiota(vector<int> v, int first, int last)
{
auto t = v.transient();
for (auto i = first; i < last; ++i)
t.push_back(i);
return t.persistent();
}
هذا التطبيق أكثر كفاءة ، ويسمح لك بإعادة استخدام عناصر جديدة على المسار الصحيح. في نهاية الوظيفة ، .persistent()يتم إجراء مكالمة غير قابلة للتغيير vector. الآثار الجانبية المحتملة تظل غير مرئية من خارج الوظيفة. الأصلي vectorكان ولا يزال غير قابل للتغيير ، فقط البيانات التي تم إنشاؤها داخل الوظيفة يتم تغييرها. كما قلت ، فإن الميزة المهمة لهذا النهج هي أنه يمكنك استخدام std::back_inserterالخوارزميات القياسية التي تتطلب واجهات برمجة تطبيقات قابلة للتغيير.تأمل في مثال آخر.vector<char> say_hi(vector<char> v)
{
return v.push_back('h')
.push_back('i')
.push_back('!');
}
لا تقبل الوظيفة وتعود vector، ولكن يتم تنفيذ سلسلة نداء في الداخل push_back. هنا ، كما في المثال السابق ، قد يحدث نسخ غير ضروري داخل المكالمة push_back. لاحظ أن القيمة الأولى التي يتم تنفيذها push_backهي القيمة المسماة ، والباقي هو قيمة r ، أي الروابط المجهولة. إذا كنت تستخدم العد المرجعي ، push_backيمكن أن تشير الطريقة إلى العدادات المرجعية للعقد التي يتم تخصيص ذاكرة لها في الشجرة. وفي حالة قيمة r ، إذا كان عدد الروابط واحدًا ، يصبح من الواضح أنه لا يوجد جزء آخر من البرنامج يصل إلى هذه العقد. الأداء هنا هو نفسه تمامًا كما هو الحال مع transient.vector<char> say_hi(vector<char> v)
{
return v.push_back('h') ⟵ named value: v
.push_back('i') ⟵ r-value value
.push_back('!'); ⟵ r-value value
}
علاوة على ذلك ، لمساعدة المترجم ، يمكننا تنفيذه move(v)، لأنه vلا يستخدم في أي مكان آخر في الوظيفة. كانت لدينا ميزة مهمة ، لم تكن في transientالبديل: إذا مررنا القيمة المرتجعة من say_hi أخرى إلى دالة say_hi ، فلن تكون هناك نسخ إضافية. في حالة c ، transientهناك حدود يمكن أن يحدث فيها نسخ زائد. بعبارة أخرى ، لدينا بنية بيانات ثابتة وغير قابلة للتغيير ، يعتمد أدائها على الكمية الفعلية للوصول المشترك في وقت التشغيل. إذا لم يكن هناك مشاركة ، فسيكون الأداء هو نفسه أداء بنية البيانات القابلة للتغيير. هذه خاصية مهمة للغاية. يمكن إعادة كتابة المثال الذي أظهرته بالفعل أعلاه باستخدام طريقة move(v).vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = std::move(v).push_back(i);
return v;
}
لقد تحدثنا حتى الآن عن المتجهات ، بالإضافة إلى وجود خرائط تجزئة. إنهم مكرسون لتقرير مفيد للغاية من قبل فيل ناش: الكأس المقدسة. صفيف تجزئة تعيين تري لـ C ++ . يصف جداول التجزئة التي تم تنفيذها بناءً على نفس المبادئ التي تحدثت عنها للتو.أنا متأكد من أن الكثير منكم لديه شكوك حول أداء مثل هذه الهياكل. هل يعملون بسرعة في الممارسة العملية؟ لقد أجريت العديد من الاختبارات ، وباختصار جوابي نعم. إذا كنت ترغب في معرفة المزيد عن نتائج الاختبار ، يتم نشرها في مقالتي للمؤتمر الدولي للبرمجة الوظيفية 2017. الآن ، أعتقد أنه من الأفضل مناقشة ليس القيم المطلقة ، ولكن تأثير هيكل البيانات هذا على النظام ككل. بالطبع ، تحديث ناقل البيانات لدينا أبطأ لأنك تحتاج إلى نسخ عدة كتل بيانات وتخصيص ذاكرة للبيانات الأخرى. ولكن يتم تجاوز ناقلنا بنفس سرعة السرعة العادية تقريبًا. كان من المهم جدًا بالنسبة لي تحقيق ذلك ، نظرًا لأن قراءة البيانات تتم في كثير من الأحيان أكثر من تغييرها.بالإضافة إلى ذلك ، نظرًا لبطء التحديث ، لا توجد حاجة لنسخ أي شيء ، فقط يتم نسخ بنية البيانات. لذلك ، يتم استهلاك الوقت المستغرق في تحديث الناقل ، كما تم استهلاكه ، لجميع النسخ التي يتم إجراؤها في النظام. لذلك ، إذا قمت بتطبيق بنية البيانات هذه في بنية مشابهة لتلك التي وصفتها في بداية التقرير ، فسيزداد الأداء بشكل ملحوظ.يويغ
لن أكون على أساس من الصحة وأثبت هيكل بياناتي باستخدام مثال. لقد كتبت محرر نص صغير. هذه أداة تفاعلية تسمى ewig ، حيث يتم تمثيل المستندات بواسطة ناقلات غير قابلة للتغيير. لدي نسخة من الإسبرانتو ويكيبيديا بأكملها على القرص الخاص بي ، ويزن 1 غيغابايت (في البداية كنت أرغب في تنزيل النسخة الإنجليزية ، ولكنها كبيرة جدًا). مهما كان محرر النصوص الذي تستخدمه ، أنا متأكد من أنه لن يحب هذا الملف. وعندما تقوم بتنزيل هذا الملف في ewig ، يمكنك تحريره على الفور ، لأن التنزيل غير متزامن. يعمل التنقل في الملفات ، لا شيء معلق ، لا mutex، لا مزامنة. كما ترى ، يأخذ الملف الذي تم تنزيله 20 مليون سطر من التعليمات البرمجية.قبل النظر في أهم خصائص هذه الأداة ، دعنا ننتبه إلى التفاصيل المضحكة. في بداية السطر ، مظللة باللون الأبيض في أسفل الصورة ، ترى واصلتين. من المرجح أن واجهة المستخدم هذه مألوفة للمستخدمين emacs ؛ الواصلات هناك تعني أن المستند لم يتم تعديله بأي شكل من الأشكال. إذا قمت بإجراء أي تغييرات ، يتم عرض العلامات النجمية بدلاً من الواصلات. ولكن ، على عكس المحررين الآخرين ، إذا قمت بمسح هذه التغييرات في ewig (لا تقم بالتراجع عنها ، فقط قم بحذفها) ، فسيتم عرض الواصلات بدلاً من العلامات النجمية لأنه يتم حفظ جميع الإصدارات السابقة من النص في ewig . وبفضل هذا ، ليست هناك حاجة إلى إشارة خاصة لإظهار ما إذا كان قد تم تغيير المستند: يتم تحديد وجود التغييرات من خلال المقارنة مع المستند الأصلي.ضع في اعتبارك خاصية أخرى مثيرة للاهتمام للأداة: انسخ النص بالكامل والصقه بضع مرات في منتصف النص الحالي. كما ترون ، يحدث هذا على الفور. الانضمام إلى المتجهات هنا هو عملية لوغاريتمية ، ولوغاريتم عدة ملايين ليست عملية طويلة. إذا حاولت حفظ هذا المستند الضخم على محرك الأقراص الثابتة ، فسيستغرق وقتًا أطول بكثير ، لأن النص لم يعد يتم تقديمه كمتجه تم الحصول عليه من الإصدار السابق من هذا المتجه. عند الحفظ على القرص ، يحدث التسلسل ، لذلك يتم فقد الثبات.
في بداية السطر ، مظللة باللون الأبيض في أسفل الصورة ، ترى واصلتين. من المرجح أن واجهة المستخدم هذه مألوفة للمستخدمين emacs ؛ الواصلات هناك تعني أن المستند لم يتم تعديله بأي شكل من الأشكال. إذا قمت بإجراء أي تغييرات ، يتم عرض العلامات النجمية بدلاً من الواصلات. ولكن ، على عكس المحررين الآخرين ، إذا قمت بمسح هذه التغييرات في ewig (لا تقم بالتراجع عنها ، فقط قم بحذفها) ، فسيتم عرض الواصلات بدلاً من العلامات النجمية لأنه يتم حفظ جميع الإصدارات السابقة من النص في ewig . وبفضل هذا ، ليست هناك حاجة إلى إشارة خاصة لإظهار ما إذا كان قد تم تغيير المستند: يتم تحديد وجود التغييرات من خلال المقارنة مع المستند الأصلي.ضع في اعتبارك خاصية أخرى مثيرة للاهتمام للأداة: انسخ النص بالكامل والصقه بضع مرات في منتصف النص الحالي. كما ترون ، يحدث هذا على الفور. الانضمام إلى المتجهات هنا هو عملية لوغاريتمية ، ولوغاريتم عدة ملايين ليست عملية طويلة. إذا حاولت حفظ هذا المستند الضخم على محرك الأقراص الثابتة ، فسيستغرق وقتًا أطول بكثير ، لأن النص لم يعد يتم تقديمه كمتجه تم الحصول عليه من الإصدار السابق من هذا المتجه. عند الحفظ على القرص ، يحدث التسلسل ، لذلك يتم فقد الثبات.العودة إلى العمارة القائمة على القيمة
 لنبدأ بكيفية عدم الرجوع إلى هذه البنية: باستخدام وحدة التحكم والطراز والعرض المعتاد على غرار Java ، والتي يتم استخدامها غالبًا للتطبيقات التفاعلية في C ++. لا حرج عليهم ، لكنهم ليسوا مناسبين لمشكلتنا. من ناحية ، يسمح نموذج Model-View-Controller بفصل المهام ، ولكن من ناحية أخرى ، فإن كل عنصر من هذه العناصر عبارة عن كائن ، سواء من وجهة نظر موجهة للكائن ومن وجهة نظر C ++ ، أي أنها مناطق ذاكرة مع متغيرة حالة. عرض يعرف عن النموذج ؛ ما هو أسوأ بكثير - يعرف النموذج بشكل غير مباشر عن العرض ، لأنه يوجد بالتأكيد رد اتصال يتم من خلاله إخطار العرض عندما يتغير النموذج. حتى مع أفضل تطبيق للمبادئ الشيئية ، نحصل على الكثير من التبعيات المتبادلة.
لنبدأ بكيفية عدم الرجوع إلى هذه البنية: باستخدام وحدة التحكم والطراز والعرض المعتاد على غرار Java ، والتي يتم استخدامها غالبًا للتطبيقات التفاعلية في C ++. لا حرج عليهم ، لكنهم ليسوا مناسبين لمشكلتنا. من ناحية ، يسمح نموذج Model-View-Controller بفصل المهام ، ولكن من ناحية أخرى ، فإن كل عنصر من هذه العناصر عبارة عن كائن ، سواء من وجهة نظر موجهة للكائن ومن وجهة نظر C ++ ، أي أنها مناطق ذاكرة مع متغيرة حالة. عرض يعرف عن النموذج ؛ ما هو أسوأ بكثير - يعرف النموذج بشكل غير مباشر عن العرض ، لأنه يوجد بالتأكيد رد اتصال يتم من خلاله إخطار العرض عندما يتغير النموذج. حتى مع أفضل تطبيق للمبادئ الشيئية ، نحصل على الكثير من التبعيات المتبادلة.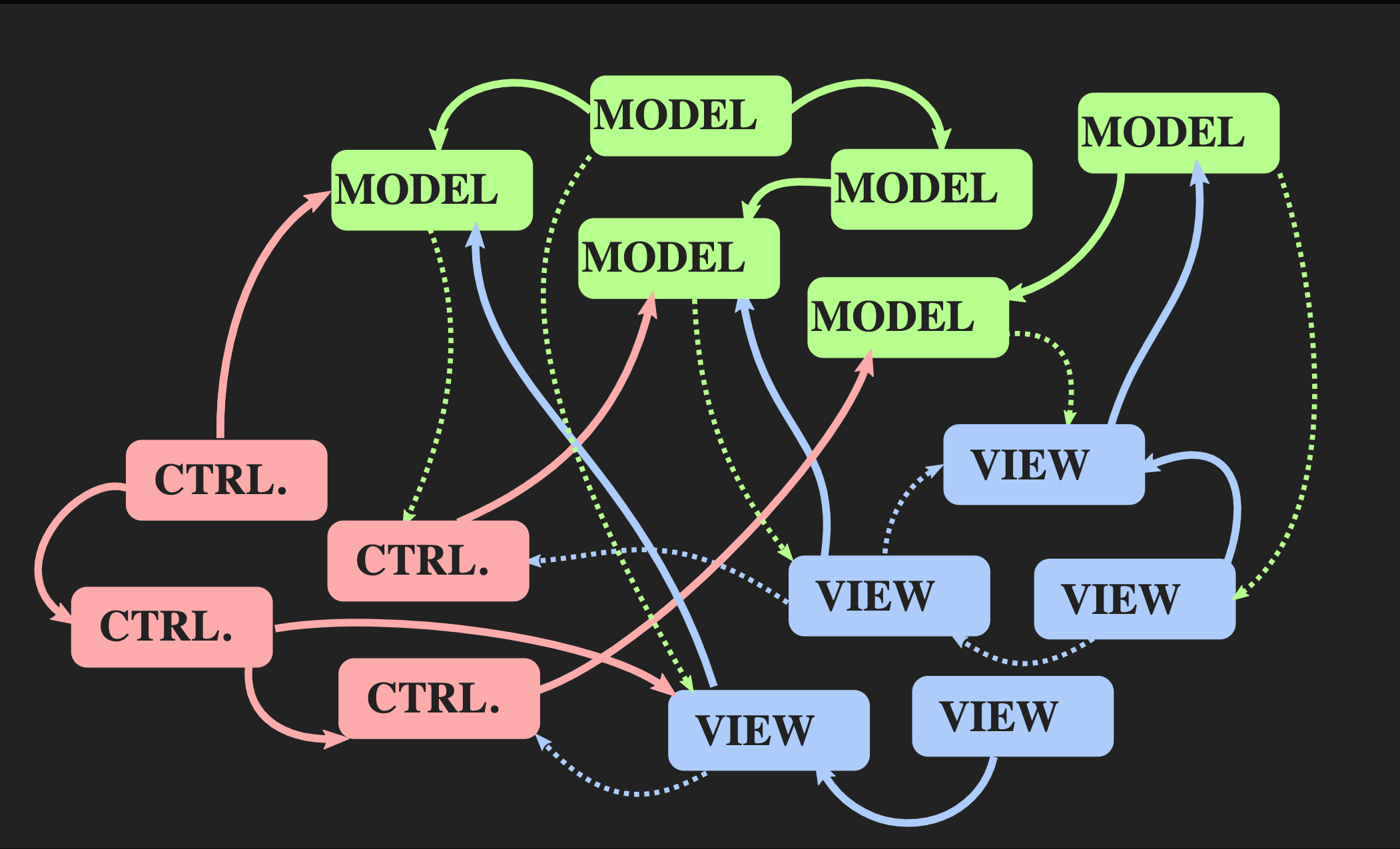 مع نمو التطبيق وإضافة نموذج جديد ، وجهاز تحكم ، وطريقة عرض ، ينشأ موقف عندما تحتاج إلى تغيير جزء من البرنامج ، تحتاج إلى معرفة جميع الأجزاء المرتبطة به ، حول كل طريقة العرض التي تتلقى إشعارًا من خلال
مع نمو التطبيق وإضافة نموذج جديد ، وجهاز تحكم ، وطريقة عرض ، ينشأ موقف عندما تحتاج إلى تغيير جزء من البرنامج ، تحتاج إلى معرفة جميع الأجزاء المرتبطة به ، حول كل طريقة العرض التي تتلقى إشعارًا من خلال callback، وما إلى ذلك. ونتيجة لذلك ، للجميع يبدأ وحش المعكرونة المألوف في النظر من خلال هذه التبعيات.هل هناك هندسة أخرى ممكنة؟ هناك نهج بديل لنموذج وحدة تحكم نموذج العرض يسمى "بنية تدفق البيانات أحادية الاتجاه". لم أخترع هذا المفهوم ، يتم استخدامه في كثير من الأحيان في تطوير الويب. على Facebook ، يسمى هذا بنية Flux ، ولكن في C ++ ، لم يتم تطبيقه بعد.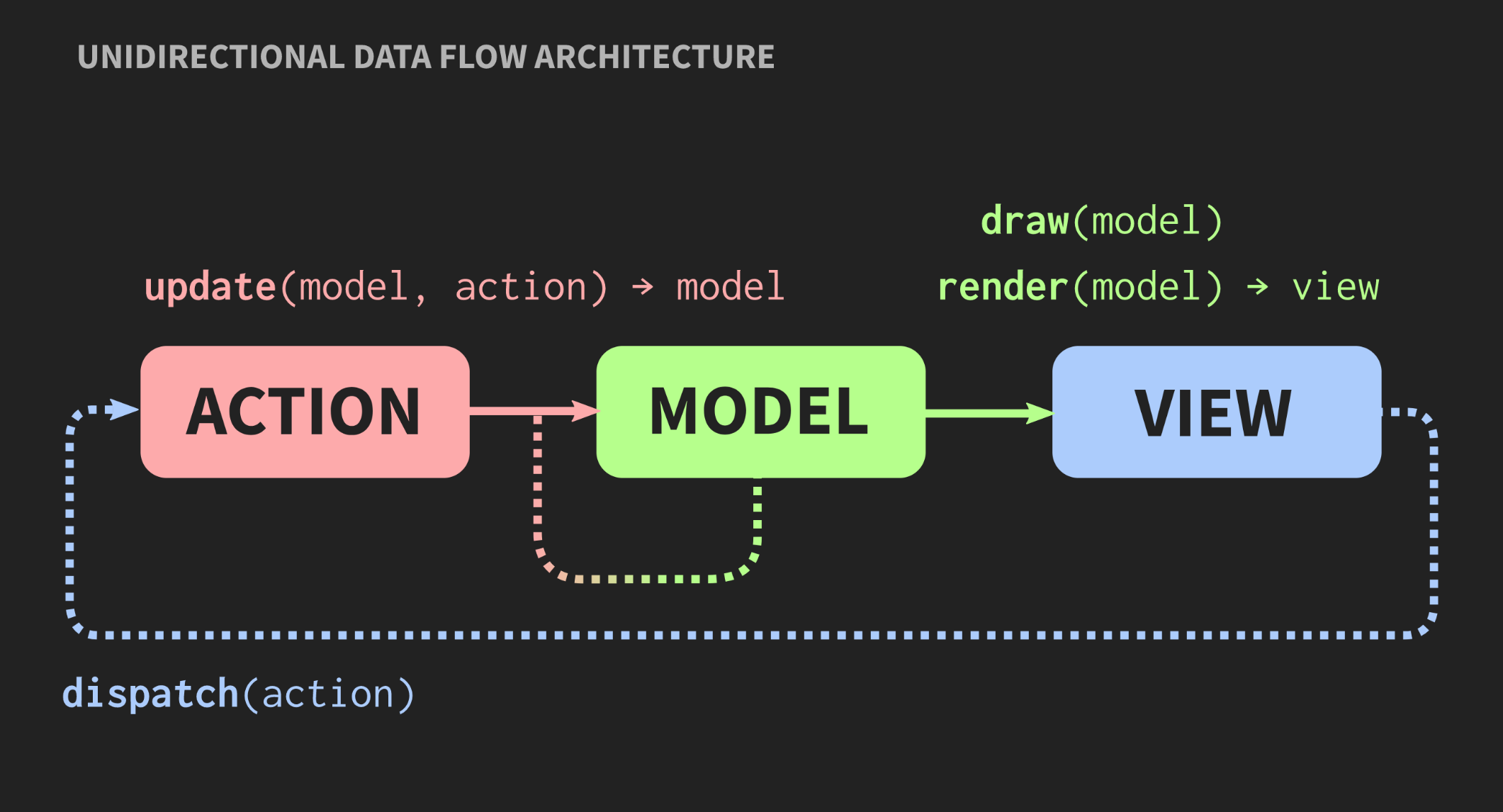 عناصر مثل هذه الهندسة المعمارية مألوفة لنا بالفعل: العمل والنموذج والعرض ، لكن معنى الكتل والسهام مختلف. الكتل هي قيم ، وليست كائنات وليست مناطق ذات حالات قابلة للتغيير. هذا ينطبق حتى على العرض. علاوة على ذلك ، الأسهم ليست روابط ، لأنه بدون كائنات لا يمكن أن تكون هناك روابط. هنا الأسهم هي وظائف. بين الإجراء والنموذج ، هناك وظيفة تحديث تقبل النموذج الحالي ، أي الحالة الحالية للعالم ، والإجراء ، وهو تمثيل لحدث ، على سبيل المثال ، نقرة بالماوس ، أو حدث بمستوى آخر من التجريد ، على سبيل المثال ، إدراج عنصر أو رمز في مستند. تقوم وظيفة التحديث بتحديث المستند وإرجاع الحالة الجديدة للعالم. يتصل النموذج بجهاز عرض الوظيفة ، الذي يأخذ النموذج ويعيد العرض. يتطلب هذا إطار عمل يمكن فيه عرض العرض كقيم.في تطوير الويب ، يقوم React بذلك ، ولكن في C ++ لا يوجد شيء مثل هذا حتى الآن ، على الرغم من من يعرف ، إذا كان هناك أشخاص يريدون دفع لي لكتابة شيء مثل هذا ، فقد يظهر قريبًا. في هذه الأثناء ، يمكنك استخدام واجهة برمجة تطبيقات الوضع الفوري ، حيث تتيح لك وظيفة الرسم إنشاء قيمة كأثر جانبي.أخيرًا ، يجب أن يكون للعرض آلية تسمح للمستخدم أو مصادر الأحداث الأخرى بإرسال الإجراء. هناك طريقة سهلة لتنفيذ ذلك ، وهي معروضة أدناه:
عناصر مثل هذه الهندسة المعمارية مألوفة لنا بالفعل: العمل والنموذج والعرض ، لكن معنى الكتل والسهام مختلف. الكتل هي قيم ، وليست كائنات وليست مناطق ذات حالات قابلة للتغيير. هذا ينطبق حتى على العرض. علاوة على ذلك ، الأسهم ليست روابط ، لأنه بدون كائنات لا يمكن أن تكون هناك روابط. هنا الأسهم هي وظائف. بين الإجراء والنموذج ، هناك وظيفة تحديث تقبل النموذج الحالي ، أي الحالة الحالية للعالم ، والإجراء ، وهو تمثيل لحدث ، على سبيل المثال ، نقرة بالماوس ، أو حدث بمستوى آخر من التجريد ، على سبيل المثال ، إدراج عنصر أو رمز في مستند. تقوم وظيفة التحديث بتحديث المستند وإرجاع الحالة الجديدة للعالم. يتصل النموذج بجهاز عرض الوظيفة ، الذي يأخذ النموذج ويعيد العرض. يتطلب هذا إطار عمل يمكن فيه عرض العرض كقيم.في تطوير الويب ، يقوم React بذلك ، ولكن في C ++ لا يوجد شيء مثل هذا حتى الآن ، على الرغم من من يعرف ، إذا كان هناك أشخاص يريدون دفع لي لكتابة شيء مثل هذا ، فقد يظهر قريبًا. في هذه الأثناء ، يمكنك استخدام واجهة برمجة تطبيقات الوضع الفوري ، حيث تتيح لك وظيفة الرسم إنشاء قيمة كأثر جانبي.أخيرًا ، يجب أن يكون للعرض آلية تسمح للمستخدم أو مصادر الأحداث الأخرى بإرسال الإجراء. هناك طريقة سهلة لتنفيذ ذلك ، وهي معروضة أدناه:application update(application state, action ev);
void run(const char* fname)
{
auto term = terminal{};
auto state = application{load_buffer(fname), key_map_emacs};
while (!state.done) {
draw(state);
auto act = term.next();
state = update(state, act);
}
}
باستثناء الحفظ والتحميل بشكل غير متزامن ، هذا هو الرمز المستخدم في المحرر المقدم للتو. يوجد كائن هنا terminalيسمح لك بالقراءة والكتابة من سطر الأوامر. علاوة على ذلك ، applicationهذه هي قيمة النموذج ، فهي تخزن الحالة الكاملة للتطبيق. كما ترى في أعلى الشاشة ، هناك وظيفة تقوم بإرجاع نسخة جديدة application. يتم تنفيذ الدورة داخل الوظيفة حتى يحتاج التطبيق إلى الإغلاق ، أي حتى !state.done. في الحلقة ، يتم رسم حالة جديدة ، ثم يتم طلب الحدث التالي. أخيرًا ، يتم تخزين الحالة في متغير محلي state، وتبدأ الحلقة مرة أخرى. هذه الشفرة لها ميزة مهمة للغاية: يوجد متغير واحد قابل للتحول فقط خلال تنفيذ البرنامج ، إنه كائن state.يسمي مطورو Clojure هذه البنية أحادية الذرة: هناك نقطة واحدة عبر التطبيق بأكمله يتم من خلالها إجراء جميع التغييرات. لا يشارك منطق التطبيق في تحديث هذه النقطة بأي شكل من الأشكال ؛ وهذا يجعل دورة مصممة خصيصًا لذلك. وبفضل هذا ، فإن منطق التطبيق يتكون بالكامل من وظائف نقية ، مثل الوظائف update.مع هذا النهج لكتابة التطبيقات ، تتغير طريقة التفكير في البرامج. لا يبدأ العمل الآن بمخطط UML للواجهات والعمليات ، ولكن بالبيانات نفسها. هناك بعض أوجه التشابه مع التصميم الموجه للبيانات. عادة ما يتم استخدام التصميم الموجه للبيانات للحصول على أقصى أداء ، هنا ، بالإضافة إلى السرعة ، نسعى جاهدين من أجل البساطة والتصحيح. يختلف التركيز قليلاً ، ولكن هناك أوجه تشابه مهمة في المنهجية.using index = int;
struct coord
{
index row = {};
index col = {};
};
using line = immer::flex_vector<char>;
using text = immer::flex_vector<line>;
struct file
{
immer::box<std::string> name;
text content;
};
struct snapshot
{
text content;
coord cursor;
};
struct buffer
{
file from;
text content;
coord cursor;
coord scroll;
std::optional<coord> selection_start;
immer::vector<snapshot> history;
std::optional<std::size_t> history_pos;
};
struct application
{
buffer current;
key_map keys;
key_seq input;
immer::vector<text> clipboard;
immer::vector<message> messages;
};
struct action { key_code key; coord size; };
أعلاه هي أنواع البيانات الرئيسية لتطبيقنا. يتكون الجسم الرئيسي للتطبيق من line، وهو flex_vector ، و flex_vector هو vectorالذي يمكنك من أجله إجراء عملية ربط . التالي textهو الناقل الذي يتم تخزينه فيه line. كما ترى ، هذا تمثيل بسيط للغاية للنص. Textالمخزنة بمساعدة fileالتي لها اسم ، أي عنوان في نظام الملفات ، وفي الواقع text. كما fileتستخدم نوع آخر، بسيطة ولكنها مفيدة جدا: box. هذه حاوية عنصر واحد. يسمح لك بوضع كومة ونقل كائن ، قد يكون النسخ الذي يتطلب الكثير من الموارد.نوع آخر مهم: snapshot. بناءً على هذا النوع ، تكون وظيفة الإلغاء نشطة. يحتوي على مستند (في النموذجtext) وموضع المؤشر (التنسيق). يتيح لك ذلك إعادة المؤشر إلى الموضع الذي كان عليه أثناء التحرير.النوع التالي هو buffer. هذا مصطلح من vim و emacs ، حيث يتم استدعاء المستندات المفتوحة هناك. في bufferوجود الملف الذي تم تحميل النص، فضلا عن محتوى النص - وهذا يسمح لك للتحقق من التغييرات في المستند. لتمييز جزء من النص ، هناك متغير اختياري selection_startيشير إلى بداية التحديد. ناقل snapshotالقصة النصية. لاحظ أننا لا نستخدم نمط الفريق ؛ فالتاريخ يتكون فقط من حالات. أخيرًا ، إذا كان الإلغاء قد اكتمل للتو ، فنحن بحاجة إلى مؤشر موقع في تاريخ الولاية history_pos.نوع المقبل: application. يحتوي على وثيقة مفتوحة (عازلة) ، key_mapوkey_seqلاختصارات لوحة المفاتيح ، بالإضافة إلى متجه من textالحافظة ومتجه آخر للرسائل المعروضة أسفل الشاشة. حتى الآن ، في الإصدار الأول من التطبيق سيكون هناك موضوع واحد فقط ونوع واحد من الإجراءات التي تأخذ المدخلات key_codeو coord.على الأرجح ، الكثير منكم يفكر بالفعل في كيفية تنفيذ هذه العمليات. إذا تم أخذها بالقيمة وإعادتها بالقيمة ، ففي معظم الحالات تكون العمليات بسيطة للغاية. يتم نشر كود محرر النصوص الخاص بي على github ، حتى تتمكن من رؤية كيف يبدو بالفعل. الآن سأتحدث بالتفصيل فقط عن الرمز الذي ينفذ وظيفة الإلغاء.إلغاء
كتابة الإلغاء بشكل صحيح بدون البنية التحتية المناسبة ليست بهذه البساطة. في محرري ، قمت بتطبيقه على غرار emacs ، لذلك أولاً بضع كلمات حول مبادئه الأساسية. أمر العودة مفقود هنا ، وبفضل هذا ، لا يمكنك أن تفقد وظيفتك. إذا كانت العودة ضرورية ، يتم إجراء أي تغيير على النص ، ثم تصبح جميع إجراءات الإلغاء مرة أخرى جزءًا من سجل الإلغاء. تم توضيح هذا المبدأ أعلاه. يظهر المعين الأحمر هنا موقعًا في التاريخ: إذا لم يكتمل الإلغاء ، فإن المعين الأحمر دائمًا ما يكون في النهاية. إذا قمت بالإلغاء ، فسوف يعيد المعين حالة واحدة إلى الوراء ، ولكن في نفس الوقت ، ستتم إضافة حالة أخرى إلى نهاية قائمة الانتظار - نفس الحالة التي يراها المستخدم حاليًا (S3). إذا ألغيت مرة أخرى وعادت إلى الحالة S2 ، فستتم إضافة الحالة S2 إلى نهاية قائمة الانتظار. إذا قام المستخدم الآن بإجراء نوع من التغيير ، فستتم إضافته إلى نهاية قائمة الانتظار كحالة جديدة لـ S5 ، وسيتم نقل المعين إليه. الآن ، عند التراجع عن الإجراءات السابقة ، سيتم تمرير إجراءات التراجع السابقة أولاً. لتنفيذ نظام الإلغاء هذا ، يكفي الرمز التالي:
تم توضيح هذا المبدأ أعلاه. يظهر المعين الأحمر هنا موقعًا في التاريخ: إذا لم يكتمل الإلغاء ، فإن المعين الأحمر دائمًا ما يكون في النهاية. إذا قمت بالإلغاء ، فسوف يعيد المعين حالة واحدة إلى الوراء ، ولكن في نفس الوقت ، ستتم إضافة حالة أخرى إلى نهاية قائمة الانتظار - نفس الحالة التي يراها المستخدم حاليًا (S3). إذا ألغيت مرة أخرى وعادت إلى الحالة S2 ، فستتم إضافة الحالة S2 إلى نهاية قائمة الانتظار. إذا قام المستخدم الآن بإجراء نوع من التغيير ، فستتم إضافته إلى نهاية قائمة الانتظار كحالة جديدة لـ S5 ، وسيتم نقل المعين إليه. الآن ، عند التراجع عن الإجراءات السابقة ، سيتم تمرير إجراءات التراجع السابقة أولاً. لتنفيذ نظام الإلغاء هذا ، يكفي الرمز التالي:buffer record(buffer before, buffer after)
{
if (before.content != after.content) {
after.history = after.history.push_back({before.content, before.cursor});
if (before.history_pos == after.history_pos)
after.history_pos = std::nullopt;
}
return after;
}
buffer undo(buffer buf)
{
auto idx = buf.history_pos.value_or(buf.history.size());
if (idx > 0) {
auto restore = buf.history[--idx];
buf.content = restore.content;
buf.cursor = restore.cursor;
buf.history_pos = idx;
}
return buf;
}
هناك إجراءان ، recordو undo. Recordيتم إجراؤه أثناء أي عملية. يعد هذا أمرًا مريحًا للغاية لأننا لا نحتاج إلى معرفة ما إذا حدث أي تعديل للمستند. الوظيفة شفافة لمنطق التطبيق. بعد أي إجراء ، تتحقق الوظيفة من تغير المستند. إذا حدث تغيير ، يتم تنفيذ push_backالمحتويات وموضع المؤشر history. إذا لم يؤد الإجراء إلى تغيير history_pos(أي أن الإدخال المستلم bufferليس بسبب إجراء الإلغاء) ، فسيتم history_posتعيين قيمة null. إذا لزم الأمر undo، نتحقق history_pos. إذا لم يكن لها معنى ، فنحن نعتبرها history_posفي نهاية القصة. إذا لم يكن سجل الإلغاء فارغًا (أيhistory_posليس في بداية القصة) ، يتم الإلغاء. يتم استبدال المحتوى الحالي والمؤشر وتغييرهما history_pos. يتم تحقيق عدم قابلية التراجع عن عملية التراجع عن طريق الوظيفة record، والتي يتم استدعاؤها أيضًا أثناء عملية التراجع.لذلك ، لدينا عملية undoتستغرق 10 أسطر من التعليمات البرمجية ، والتي يمكن استخدامها بدون تغييرات (أو مع تغييرات طفيفة) في أي تطبيق آخر تقريبًا.السفر عبر الزمن
عن السفر عبر الزمن. كما سنرى الآن ، هذا موضوع متعلق بالإلغاء. سأوضح عمل إطار عمل من شأنه أن يضيف وظائف مفيدة لأي تطبيق له بنية مماثلة. يسمى الإطار هنا ewig-debug . يتضمن هذا الإصدار من ewig بعض ميزات التصحيح. الآن من المتصفح ، يمكنك فتح المصحح ، حيث يمكنك فحص حالة التطبيق. نرى أن الإجراء الأخير كان يتم تغيير حجمه ، لأنني فتحت نافذة جديدة ، وقام مدير نافذتي بتغيير حجم النافذة المفتوحة بالفعل. بالطبع ، من أجل التسلسل التلقائي في JSON ، اضطررت إلى إضافة تعليق توضيحي للبنية من مكتبة الانعكاس الخاصة. لكن باقي النظام عالمي تمامًا ، يمكن توصيله بأي تطبيق مماثل. الآن في المتصفح يمكنك رؤية جميع الإجراءات المكتملة. بالطبع ، هناك حالة أولية ليس لها عمل. هذه هي الحالة التي كانت قبل التنزيل. علاوة على ذلك ، من خلال النقر المزدوج ، يمكنني إعادة التطبيق إلى حالته السابقة. هذه أداة تصحيح مفيدة للغاية تسمح لك بتتبع حدوث عطل في التطبيق.إذا كنت مهتمًا ، يمكنك الاستماع إلى تقريري حول CPPCON 19 ، القيم الأكثر قيمة ، هناك سأقوم بفحص مصحح الأخطاء هذا بالتفصيل.بالإضافة إلى ذلك ، تتم مناقشة العمارة القائمة على القيمة بمزيد من التفصيل هناك. في ذلك ، أقول لك أيضًا كيفية تنفيذ الإجراءات وتنظيمها بشكل هرمي. هذا يضمن نموذجية النظام ويزيل الحاجة إلى الاحتفاظ بكل شيء في وظيفة تحديث كبيرة واحدة. بالإضافة إلى ذلك ، يتحدث هذا التقرير عن تنزيل الملفات غير المتزامنة والمترابطة. هناك نسخة أخرى من هذا التقرير حيث نصف ساعة من المواد الإضافية هي هياكل بيانات ثابتة لما بعد الحداثة.
نرى أن الإجراء الأخير كان يتم تغيير حجمه ، لأنني فتحت نافذة جديدة ، وقام مدير نافذتي بتغيير حجم النافذة المفتوحة بالفعل. بالطبع ، من أجل التسلسل التلقائي في JSON ، اضطررت إلى إضافة تعليق توضيحي للبنية من مكتبة الانعكاس الخاصة. لكن باقي النظام عالمي تمامًا ، يمكن توصيله بأي تطبيق مماثل. الآن في المتصفح يمكنك رؤية جميع الإجراءات المكتملة. بالطبع ، هناك حالة أولية ليس لها عمل. هذه هي الحالة التي كانت قبل التنزيل. علاوة على ذلك ، من خلال النقر المزدوج ، يمكنني إعادة التطبيق إلى حالته السابقة. هذه أداة تصحيح مفيدة للغاية تسمح لك بتتبع حدوث عطل في التطبيق.إذا كنت مهتمًا ، يمكنك الاستماع إلى تقريري حول CPPCON 19 ، القيم الأكثر قيمة ، هناك سأقوم بفحص مصحح الأخطاء هذا بالتفصيل.بالإضافة إلى ذلك ، تتم مناقشة العمارة القائمة على القيمة بمزيد من التفصيل هناك. في ذلك ، أقول لك أيضًا كيفية تنفيذ الإجراءات وتنظيمها بشكل هرمي. هذا يضمن نموذجية النظام ويزيل الحاجة إلى الاحتفاظ بكل شيء في وظيفة تحديث كبيرة واحدة. بالإضافة إلى ذلك ، يتحدث هذا التقرير عن تنزيل الملفات غير المتزامنة والمترابطة. هناك نسخة أخرى من هذا التقرير حيث نصف ساعة من المواد الإضافية هي هياكل بيانات ثابتة لما بعد الحداثة.كي تختصر
أعتقد أن الوقت قد حان للتقييم. سأقتبس من آندي وينغو - إنه مطور ممتاز ، وكرس الكثير من الوقت لـ V8 والمجمعين بشكل عام ، وأخيرًا ، يشارك في دعم Guile ، وتنفيذ مخطط لـ GNU. كتب مؤخرًا على موقعه على تويتر: "لتحقيق تسارع طفيف في البرنامج ، نقيس كل تغيير صغير ونترك فقط تلك التي تعطي نتيجة إيجابية. لكننا حقًا نحقق تسارعًا كبيرًا ، وبشكل أعمى ، نستثمر الكثير من الجهد ، وليس لدينا ثقة بنسبة 100 ٪ ونسترشد فقط بالحدس. يا لها من انقسام غريب. "يبدو لي أن مطوري C ++ ينجحون في النوع الأول. امنحنا نظامًا مغلقًا ، ونحن ، مسلحون بأدواتنا ، سنضغط على كل ما هو ممكن منه. لكن في النوع الثاني لم نعتد على العمل. بالطبع ، النهج الثاني أكثر خطورة ، وغالبًا ما يؤدي إلى إهدار جهد كبير. من ناحية أخرى ، من خلال إعادة كتابة برنامج بالكامل ، يمكن جعله أسهل وأسرع. آمل أن أتمكن من إقناعك على الأقل بتجربة هذا النهج الثاني.تحدث خوان بوينتي في مؤتمر C ++ Russia 2019 في موسكو وتحدث عن هياكل البيانات التي تسمح لك بالقيام بأشياء مثيرة للاهتمام. جزء من سحر هذه الأكاذيب الهياكل في نسخة ترخيم - وهذا هو ما انطون Polukhin والرومانية Rusyaev سوف نتحدث عنها في المؤتمر القادم . اتبع تحديثات البرنامج على الموقع.