مرحبا يا هابر.اسمي ميشا بوتريموف ، أود أن أتحدث قليلاً عن كاساندرا. ستكون قصتي مفيدة لأولئك الذين لم يسبق لهم أن واجهوا قواعد بيانات NoSQL - فهي تحتوي على الكثير من ميزات التنفيذ والمزالق التي تحتاج إلى معرفتها. وإذا لم تشاهد أي شيء ، بخلاف Oracle أو أي قاعدة علاقية أخرى ، فإن هذه الأشياء ستنقذ حياتك.ما هو الجيد في كاساندرا؟ هذه قاعدة بيانات NoSQL مصممة بدون نقطة فشل واحدة ، والتي تتطور بشكل جيد. إذا كنت بحاجة إلى إضافة بضعة تيرابايت لأي قاعدة ، ما عليك سوى إضافة العقد إلى الحلقة. هل تريد توسيعه إلى مركز بيانات آخر؟ أضف العقد إلى الكتلة. زيادة RPS المجهزة؟ أضف العقد إلى الكتلة. الطريقة الأخرى تعمل أيضًا. ما هي الأخرى التي تجيدها؟ هو التعامل مع الكثير من الطلبات. ولكن كم هو كم؟ 10 ، 20 ، 30 ، 40 ألف طلب في الثانية - هذا ليس كثيرًا. 100 ألف طلب في الثانية للتسجيل أيضًا. هناك شركات قالت أنها تحتجز مليوني طلب في الثانية. هنا ربما عليهم أن يصدقوا.ومن حيث المبدأ ، فإن كاساندرا لديها فرق كبير واحد من البيانات العلائقية - فهي لا تبدو على الإطلاق. وهذا أمر مهم للغاية تذكره.
ما هي الأخرى التي تجيدها؟ هو التعامل مع الكثير من الطلبات. ولكن كم هو كم؟ 10 ، 20 ، 30 ، 40 ألف طلب في الثانية - هذا ليس كثيرًا. 100 ألف طلب في الثانية للتسجيل أيضًا. هناك شركات قالت أنها تحتجز مليوني طلب في الثانية. هنا ربما عليهم أن يصدقوا.ومن حيث المبدأ ، فإن كاساندرا لديها فرق كبير واحد من البيانات العلائقية - فهي لا تبدو على الإطلاق. وهذا أمر مهم للغاية تذكره.ليس كل شيء يبدو متشابهًا يعمل بنفس الطريقة
بمجرد أن جاء إلي زميل وسأل: "هذه هي لغة الاستعلام CQL Cassandra ، ولديها بيان محدد ، ولديها مكان ، ولها و. أكتب رسائل ولا تعمل. لماذا ا؟". إذا كنت تتعامل مع كاساندرا كقاعدة بيانات علائقية ، فهذه طريقة مثالية لإنهاء حياتك عن طريق الانتحار الوحشي. وأنا لا أدافع عن ذلك ، إنه محظور في روسيا. أنت فقط تصمم شيئًا خاطئًا.على سبيل المثال ، يأتي إلينا أحد العملاء ويقول: "دعونا نبني قاعدة بيانات للبرامج التلفزيونية ، أو قاعدة بيانات لدليل الوصفات. سيكون لدينا أطباق طعام هناك أو قائمة من المسلسلات والممثلين فيها ". نقول بفرح: "هيا!". هذه هي وحدتي بايت للإرسال ، زوج من اللوحات وكل شيء جاهز ، كل شيء سيعمل بسرعة كبيرة وموثوقة. وكل شيء على ما يرام حتى يأتي العملاء ويقولون إن ربات البيوت يقمن أيضًا بحل المشكلة العكسية: لديهم قائمة بالمنتجات ويريدون معرفة الطبق الذي يريدون طهيه. أنت ميت.ذلك لأن كاساندرا هي قاعدة بيانات مختلطة: فهي في الأساس قيمة رئيسية وتخزن البيانات في أعمدة واسعة. يتحدث في Java أو Kotlin ، يمكن وصفه على النحو التالي:Map<RowKey, SortedMap<ColumnKey, ColumnValue>>أي ، خريطة ، يوجد فيها أيضًا خريطة مرتبة. المفتاح الأول لهذه الخريطة هو مفتاح الصف أو مفتاح القسم - مفتاح القسم. المفتاح الثاني ، وهو مفتاح الخريطة التي تم فرزها بالفعل ، هو مفتاح التجميع.لتوضيح توزيع قاعدة البيانات ، نرسم ثلاث عقد. الآن أنت بحاجة إلى فهم كيفية تحليل البيانات إلى عقد. لأنه إذا قمنا بدفع كل شيء إلى واحد (بالمناسبة ، قد يكون هناك ألف أو ألفان أو خمسة - أي عدد تريده) ، فهذا لا يتعلق حقًا بالتوزيع. لذلك ، نحتاج إلى دالة رياضية ستعيد رقمًا. مجرد رقم ، عدد صحيح طويل يقع في نطاق ما. ولدينا عقدة واحدة ستكون مسؤولة عن نطاق واحد ، والثاني - للنقطة الثانية ، n - th - للنقطة n. يتم أخذ هذا الرقم باستخدام دالة التجزئة التي تنطبق فقط على ما نسميه مفتاح القسم. هذا هو العمود المحدد في توجيه المفتاح الأساسي ، وهو العمود الذي سيكون مفتاح الخريطة الأول والأساسي. يحدد العقدة التي تحصل على البيانات. يتم إنشاء جدول في كاساندرا بنفس البنية تقريبًا كما في SQL:
يتم أخذ هذا الرقم باستخدام دالة التجزئة التي تنطبق فقط على ما نسميه مفتاح القسم. هذا هو العمود المحدد في توجيه المفتاح الأساسي ، وهو العمود الذي سيكون مفتاح الخريطة الأول والأساسي. يحدد العقدة التي تحصل على البيانات. يتم إنشاء جدول في كاساندرا بنفس البنية تقريبًا كما في SQL:CREATE TABLE users (
user_id uu id,
name text,
year int,
salary float,
PRIMARY KEY(user_id)
)
يتكون المفتاح الأساسي في هذه الحالة من عمود واحد ، وهو أيضًا مفتاح قسم.كيف سيقع المستخدمون معنا؟ جزء يقع على ملاحظة واحدة ، وجزء على آخر ، وجزء على ثالث. يتحول إلى جدول تجزئة عادي ، وهو أيضًا خريطة ، وهو أيضًا قاموس في Python ، وهو أيضًا هيكل قيمة مفتاح بسيط يمكننا من خلاله قراءة جميع القيم والقراءة والكتابة حسب المفتاح.
حدد: عندما يتحول السماح بالتصفية إلى مسح كامل ، أو كيف لا تفعل ذلك
دعونا إرسال بعض بيان لاختيار: select * from users where, userid = . يبدو ، كما هو الحال في Oracle: نكتب تحديد ، نحدد الشروط وكل شيء يعمل ، يحصل عليه المستخدمون. ولكن إذا اخترت ، على سبيل المثال ، مستخدمًا لديه سنة معينة من الميلاد ، فإن كاساندرا تقسم أنها لا تستطيع تلبية الطلب. لأنها لا تعرف شيئًا عن كيفية توزيع البيانات عن سنة الميلاد - لديها عمود واحد محدد كمفتاح. ثم تقول: "حسنًا ، لا يزال بإمكاني تلبية هذا الطلب. إضافة السماح بالتصفية ". نضيف توجيه ، كل شيء يعمل. وفي تلك اللحظة يحدث شيء فظيع.عندما نقود على بيانات الاختبار ، كل شيء على ما يرام. وعندما تستوفي الطلب في الإنتاج ، حيث ، على سبيل المثال ، لدينا 4 ملايين سجل ، فإن كل شيء ليس جيدًا جدًا معنا. لأن السماح بالفلترة هو توجيه يسمح لـ Cassandra بجمع جميع البيانات من هذا الجدول من جميع العقد ، وجميع مراكز البيانات (إذا كان هناك الكثير منها في هذه المجموعة) ، ثم فقط تصفيتها. هذا هو نظير Full Scan ، ولا يكاد أي شخص مسرور به.إذا كنا بحاجة فقط إلى المستخدمين من خلال المعرفات ، فهذا يناسبنا. ولكن في بعض الأحيان نحتاج إلى كتابة استفسارات أخرى وفرض قيود أخرى على التحديد. لذلك ، نتذكر: لدينا جميعًا خريطة تحتوي على مفتاح تقسيم ، ولكن داخلها خريطة مرتبة.ولديها أيضًا مفتاح نسميه مفتاح التكتل. هذا المفتاح ، والذي يتكون بدوره من الأعمدة التي نختارها ، والتي تفهم كاساندرا كيف يتم فرز بياناتها ماديًا وسوف تقع على كل عقدة. هذا ، بالنسبة لبعض مفاتيح القسم ، سيخبرك مفتاح التجميع بالتحديد بكيفية دفع البيانات إلى هذه الشجرة ، والمكان الذي ستأخذه هناك.هذه شجرة حقًا ، ويطلق عليها ببساطة اسم مقارن هناك ، حيث نمرر مجموعة معينة من الأعمدة في شكل كائن ، ويتم تعيينها أيضًا في شكل قائمة أعمدة.CREATE TABLE users_by_year_salary_id (
user_id uuid,
name text,
year int,
salary float,
PRIMARY KEY((year), salary, user_id)
انتبه إلى توجيه المفتاح الأساسي ، حيث أن الحجة الأولى (في حالتنا السنة) هي دائمًا مفتاح القسم. يمكن أن تتكون من عمود واحد أو عدة أعمدة ، لا يهم. إذا كانت هناك عدة أعمدة ، فأنت بحاجة إلى إزالتها مرة أخرى بين قوسين حتى يفهم المعالج المسبق للغة أن هذا هو المفتاح الأساسي ، وخلفه جميع الأعمدة الأخرى - مفتاح التجميع. في هذه الحالة ، سيتم نقلهم في المقارنة بالترتيب الذي يذهبون إليه. أي أن العمود الأول أكثر أهمية ، والثاني أقل أهمية وهكذا. بينما نكتب لفئات البيانات ، على سبيل المثال ، تساوي الحقول: نقوم بسرد الحقول ، وبالنسبة لهم نكتب أيها أكبر منها وأيها أصغر. في كاساندرا ، هذا ، نسبيًا ، هو حقل فئة البيانات الذي سيتم تطبيق المتساويين عليه.وضعنا هذا الترتيب ، وفرض قيود
يجب أن نتذكر أن ترتيب الفرز (تناقص ، زيادة ، لا يهم) يتم تعيينه في نفس الوقت الذي يتم فيه إنشاء المفتاح ، ومن ثم لا يمكنك تغييره لاحقًا. يحدد ماديًا كيفية فرز البيانات وكيف ستكمن. إذا كنت بحاجة إلى تغيير مفتاح التجميع أو ترتيب الفرز ، فسيتعين عليك إنشاء جدول جديد وصب البيانات فيه. مع القائمة الموجودة ، لن يعمل هذا.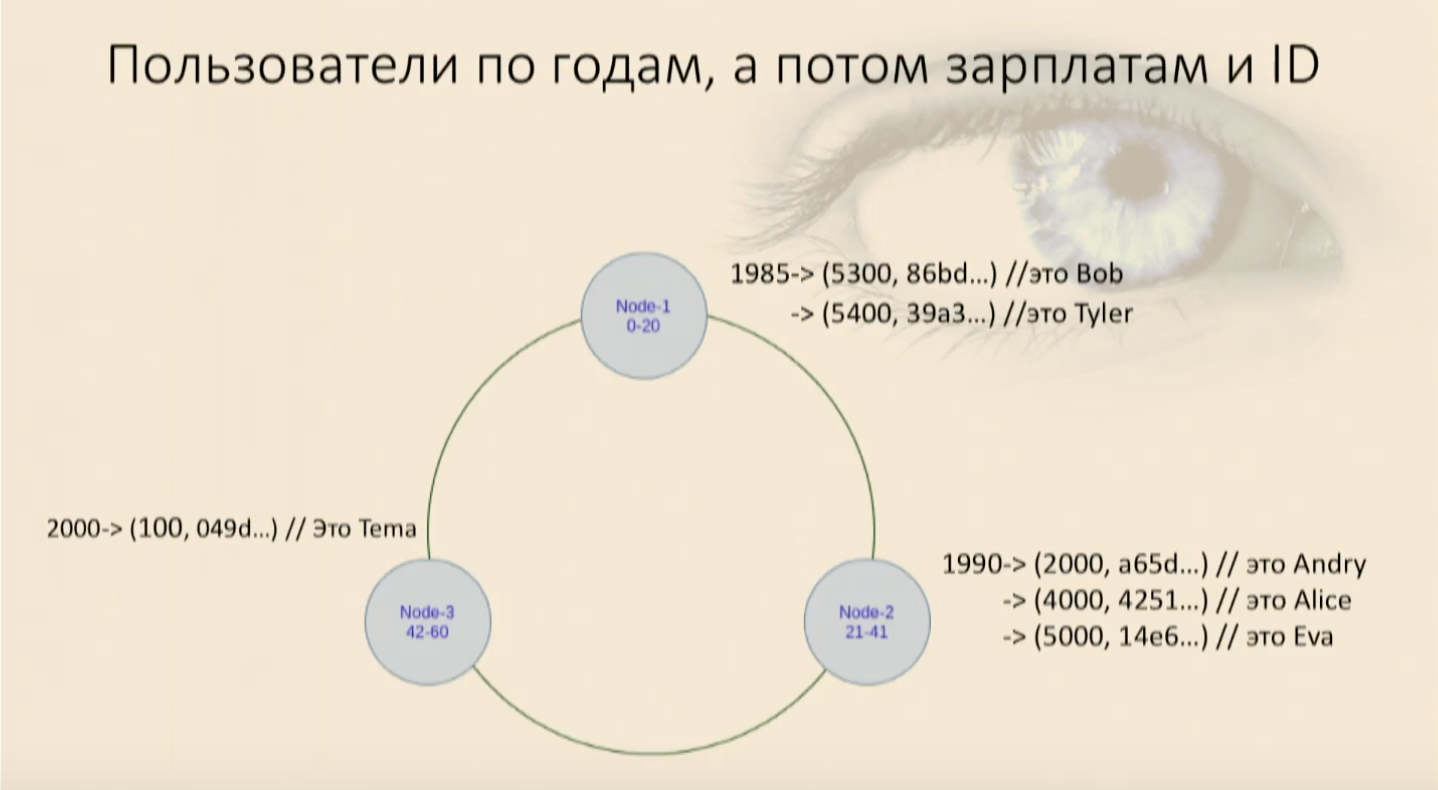 ملأنا طاولتنا بالمستخدمين ورأينا أنهم دخلوا في حلقة ، أولاً حسب سنة الميلاد ، ثم داخل كل عقدة حسب الراتب ومعرف المستخدم. الآن يمكننا الاختيار وفرض القيود.يبدو عملنا مرة أخرى
ملأنا طاولتنا بالمستخدمين ورأينا أنهم دخلوا في حلقة ، أولاً حسب سنة الميلاد ، ثم داخل كل عقدة حسب الراتب ومعرف المستخدم. الآن يمكننا الاختيار وفرض القيود.يبدو عملنا مرة أخرىwhere, and، ويصل إلينا المستخدمون ، وكل شيء على ما يرام مرة أخرى. ولكن إذا حاولنا استخدام الجزء الرئيسي من المجموعة فقط ، وهو الجزء الأقل أهمية ، فستقسم كاساندرا على الفور التي لا يمكننا العثور عليها في خريطتنا حيث يحتوي هذا الكائن على هذه الحقول للمقارنة فارغة ، ولكن هذا الجزء الذي تم تعيينه للتو - أين تقع. سأضطر إلى التقاط جميع البيانات من هذه العقدة مرة أخرى وتصفيتها. وهذا تناظري للفحص الكامل داخل العقدة ، هذا سيئ.في أي موقف غير مفهوم ، قم بإنشاء جدول جديد
إذا أردنا أن نكون قادرين على الحصول على المستخدمين عن طريق الهوية أو العمر أو الراتب ، فماذا نفعل؟ لا شيئ. مجرد استخدام جدولين. إذا كنت بحاجة إلى جذب المستخدمين بثلاث طرق مختلفة - ستكون هناك ثلاثة جداول. لقد ولت الأيام التي وفرنا فيها مساحة على المسمار. هذا هو أرخص مورد. يكلف أقل بكثير من وقت الاستجابة ، والتي يمكن أن تكون قاتلة للمستخدم. المستخدم أجمل بكثير للحصول على شيء في ثانية مما كان عليه في 10 دقائق.نتبادل المساحة الزائدة ، والبيانات غير المنتظمة من أجل القدرة على التوسع بشكل جيد ، والعمل بشكل موثوق. في الواقع ، إن الكتلة التي تتكون من ثلاثة مراكز بيانات ، لكل منها خمس عقد ، بمستوى مقبول من تخزين البيانات (عندما لا يتم فقدان أي شيء على وجه اليقين) ، قادرة على النجاة من وفاة مركز بيانات واحد تمامًا. وعقدين إضافيين في كل من المتبقيين. وفقط بعد ذلك تبدأ المشاكل. هذا تكرار جيد للغاية ، ويكلف بضع محركات أقراص ومعالجات غير ضرورية. لذلك ، من أجل استخدام كاساندرا ، وهي ليست SQL أبدًا ، حيث لا توجد علاقات ، ولا مفاتيح أجنبية ، تحتاج إلى معرفة قواعد بسيطة.نقوم بتصميم كل شيء من طلب. الشيء الرئيسي ليس البيانات ، ولكن كيف سيعمل التطبيق معهم. إذا كان يحتاج إلى تلقي بيانات مختلفة بطرق مختلفة أو نفس البيانات بطرق مختلفة ، يجب أن نضعها بالطريقة التي تناسب التطبيق. خلاف ذلك ، سوف نفشل في Full Scan ولن تعطينا كاساندرا أي ميزة.المعيار هو إلغاء البيانات. ننسى الأشكال العادية ، لم يعد لدينا قواعد بيانات علائقية. نضع شيئًا 100 مرة ، سيقع 100 مرة. إنه أرخص من إيقافه على أي حال.نختار مفاتيح التقسيم بحيث يتم توزيعها بشكل طبيعي. نحن لسنا بحاجة إلى التجزئة من مفاتيحنا لتقع في نطاق ضيق واحد. أي أن سنة الميلاد في المثال أعلاه هي مثال سيء. بدلاً من ذلك ، من الجيد أن يتم توزيع مستخدمينا عادةً حسب سنة الميلاد ، وسيئ إذا كنا نتحدث عن طلاب الصف الخامس - لن يكون من الجيد التقسيم هناك.يتم تحديد التصنيف مرة واحدة أثناء إنشاء مفتاح التجميع. إذا كنت بحاجة إلى تغييره ، فسيتعين عليك ملء طاولتنا بمفتاح مختلف.والأكثر أهمية: إذا كنا بحاجة إلى جمع نفس البيانات بـ 100 طريقة مختلفة ، فسيكون لدينا 100 جدول مختلف.