تحية للجميع!أريد أن أتحدث عن مشروع ممل للغاية حيث تتقاطع الروبوتات ، وتعلم الآلة (وهذا معًا هو تعلم الروبوت) ، والواقع الافتراضي وقليل من التكنولوجيا السحابية. وكل هذا في الواقع منطقي. بعد كل شيء ، من الملائم حقًا الانتقال إلى الروبوت وإظهار ما يجب فعله ، ثم تدريب الأوزان على خادم ML باستخدام البيانات المخزنة.تحت الخفض ، سنخبر كيف يعمل الآن ، وبعض التفاصيل حول كل جانب من الجوانب التي يجب تطويرها.
لماذا
بالنسبة للمبتدئين ، من الجدير بالكشف قليلاً.يبدو أن الروبوتات المسلحة مع Deep Learning على وشك إخراج الناس من وظائفهم في كل مكان. في الواقع ، كل شيء ليس على ما يرام. عندما تتكرر الإجراءات بشكل صارم ، تكون العمليات مؤتمتة بشكل جيد بالفعل. إذا كنا نتحدث عن "الروبوتات الذكية" ، أي التطبيقات التي تكون فيها رؤية الكمبيوتر والخوارزميات كافية بالفعل. ولكن هناك أيضًا العديد من القصص المعقدة للغاية. بالكاد تستطيع الروبوتات التعامل مع مجموعة متنوعة من الأشياء التي يجب أن تتعامل معها ، وتنوع البيئة.النقاط الرئيسية
هناك 3 أشياء رئيسية من حيث التنفيذ لم يتم العثور عليها بعد في كل مكان:- (data-driven learning). .. , , , . , .
- ()
- - (Human-machine collaboration)
والثاني مهم أيضًا لأنه في الوقت الحالي سنلاحظ تغييرًا في مناهج التعلم والخوارزميات وخلفها وأدوات الحوسبة. ستصبح خوارزميات الإدراك والتحكم أكثر مرونة. ترقية الروبوت تكلف المال. ويمكن استخدام الآلة الحاسبة بشكل أكثر كفاءة إذا كانت ستقدم العديد من الروبوتات في وقت واحد. يسمى هذا المفهوم "الروبوتات السحابية".مع هذا الأخير ، كل شيء بسيط - لم يتم تطوير الذكاء الاصطناعي بشكل كافٍ الآن لتوفير الموثوقية والدقة بنسبة 100٪ في جميع المواقف التي تتطلبها الأعمال. لذلك ، لن يضر عامل المشرف ، الذي يمكنه أحيانًا مساعدة الروبوتات ،مخطط
بادئ ذي بدء ، حول برنامج / شبكة منصة توفر جميع الوظائف الموصوفة: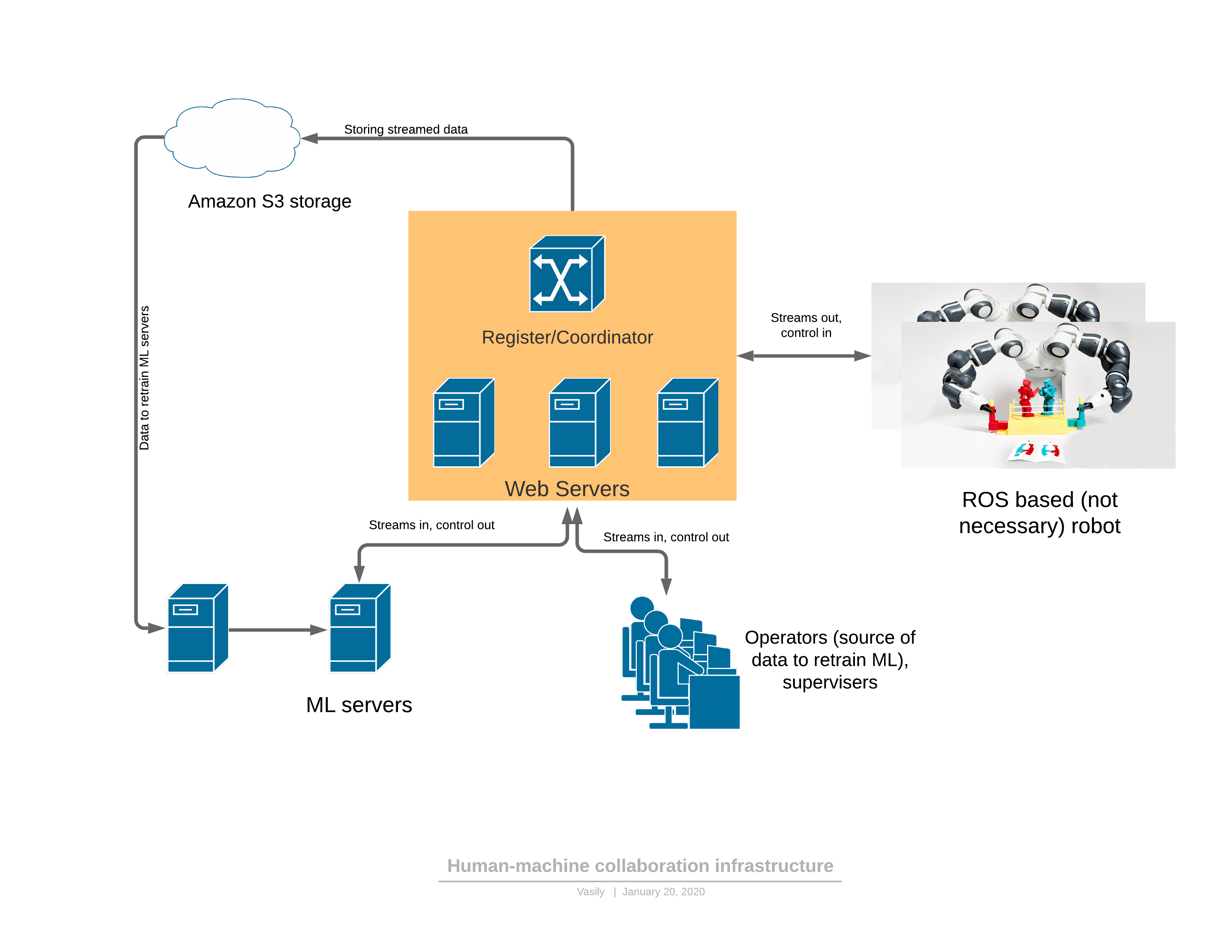 المكونات:
المكونات:- يرسل الروبوت دفق فيديو ثلاثي الأبعاد إلى الخادم ويتلقى التحكم في الاستجابة.
- : - , (, , , )
- ML ( ), , , . — 3D , .
- - , 3D , UI . — .
هناك نوعان من طرق عمل الروبوت: تلقائي ويدوي.في الوضع اليدوي ، يعمل الروبوت إذا لم يتم تدريب خدمة ML بعد. ثم ينتقل الروبوت من تلقائي إلى يدوي إما بناء على طلب المشغل (رأيت سلوكيات غريبة أثناء مشاهدة الروبوت) ، أو عندما تكتشف خدمات ML نفسها شذوذًا. حول الكشف عن الشذوذ سيكون لاحقًا - هذا جزء مهم جدًا ، بدونه من المستحيل تطبيق النهج المقترح.تطور التحكم كما يلي:- يتم تشكيل مهمة الروبوت بعبارات يسهل على الإنسان قراءتها ويتم وصف مؤشرات الأداء.
- يتصل المشغل بالروبوت في الواقع الافتراضي ويقوم بالمهمة ضمن سير العمل الحالي لبعض الوقت
- يتم تدريب جزء ML على البيانات الواردة
- , ML
3D
في كثير من الأحيان ، تستخدم الروبوتات بيئة ROS (نظام تشغيل الروبوت) ، والتي هي في الواقع إطار عمل لإدارة "العقد" (العقد) ، كل منها يوفر جزءًا من وظيفة الروبوت. بشكل عام ، هذه طريقة ملائمة نسبيًا لبرمجة الروبوتات ، والتي تشبه في بعض النواحي بنية الخدمات الصغيرة لتطبيقات الويب في جوهرها. الميزة الرئيسية لـ ROS هي معيار الصناعة وهناك بالفعل عدد كبير من الوحدات اللازمة لإنشاء روبوت. حتى الأسلحة الآلية الصناعية يمكن أن تحتوي على وحدة واجهة ROS.أبسط شيء هو إنشاء نموذج جسر بين جزء الخادم الخاص بنا و ROS. على سبيل المثال ، مثل. يستخدم مشروعنا الآن إصدارًا أكثر تطورًا من "عقدة" ROS ، التي تقوم بتسجيل الدخول واستقصاء الخدمة الدقيقة للسجل الذي يمكن لخادم ترحيل أن يتصل به روبوت معين. يتم إعطاء رمز المصدر فقط كمثال للتعليمات لتثبيت وحدة ROS. في البداية ، عندما تتقن هذا الإطار (ROS) ، يبدو كل شيء غير ودي إلى حد ما ، ولكن الوثائق جيدة جدًا ، وبعد أسبوعين ، يبدأ المطورون في استخدام وظائفه بثقة تامة.من المثير للاهتمام - مشكلة ضغط دفق البيانات ثلاثية الأبعاد ، والتي يجب إنتاجها مباشرة على الروبوت.ليس من السهل ضغط خريطة العمق. حتى مع درجة صغيرة من ضغط تدفق RGB ، فإن التشويه المحلي الخطير للغاية للسطوع من البكسل الحقيقي عند الحدود أو عند السماح بتحريك الكائنات. لا تلاحظ العين ذلك تقريبًا ، ولكن بمجرد السماح بالتشوهات نفسها في خريطة العمق ، عندما يصبح عرض 3D كل شيء سيئًا للغاية: (من المقالة )هذه العيوب عند الحواف تفسد المشهد ثلاثي الأبعاد بشكل كبير ، لأنه هناك الكثير من القمامة في الهواء.بدأنا في استخدام ضغط إطار بإطار - JPEG لـ RGB و PNG لخريطة عمق مع اختراق صغير. تعمل هذه الطريقة على ضغط دفق 30 إطارًا في الثانية لدقة ماسحة ثلاثية الأبعاد تبلغ 640 × 480 بسرعة 25 ميجابت في الثانية. يمكن أيضًا توفير ضغط أفضل إذا كانت حركة المرور مهمة للتطبيق. هناك برامج ترميز دفق تجارية ثلاثية الأبعاد يمكن استخدامها أيضًا لضغط هذا الدفق.
(من المقالة )هذه العيوب عند الحواف تفسد المشهد ثلاثي الأبعاد بشكل كبير ، لأنه هناك الكثير من القمامة في الهواء.بدأنا في استخدام ضغط إطار بإطار - JPEG لـ RGB و PNG لخريطة عمق مع اختراق صغير. تعمل هذه الطريقة على ضغط دفق 30 إطارًا في الثانية لدقة ماسحة ثلاثية الأبعاد تبلغ 640 × 480 بسرعة 25 ميجابت في الثانية. يمكن أيضًا توفير ضغط أفضل إذا كانت حركة المرور مهمة للتطبيق. هناك برامج ترميز دفق تجارية ثلاثية الأبعاد يمكن استخدامها أيضًا لضغط هذا الدفق.التحكم في الواقع الافتراضي
بعد معايرة الإطار المرجعي للكاميرا والروبوت (وكتبنا بالفعل مقالة حول المعايرة ) ، يمكن التحكم في ذراع الروبوت في الواقع الافتراضي. تقوم وحدة التحكم بتعيين كل من الموضع في 3D XYZ والاتجاه. بالنسبة لبعض roboruk ، ستكون 3 إحداثيات فقط كافية ، ولكن مع وجود عدد كبير من درجات الحرية ، يجب أيضًا توجيه اتجاه الأداة المحددة بواسطة وحدة التحكم. بالإضافة إلى ذلك ، هناك ما يكفي من عناصر التحكم في وحدات التحكم لتنفيذ أوامر الروبوت مثل تشغيل / إيقاف المضخة ، والتحكم في القابض ، وغيرها.في البداية ، تقرر استخدام إطار JavaScript للواقع الافتراضي A-frame ، استنادًا إلى محرك WebVR. وتم الحصول على النتائج الأولى (عرض فيديو في نهاية المقالة لذراع الإحداثيات الأربع) على الإطار A.في الواقع ، اتضح أن WebVR (أو A-frame) كان حلًا غير ناجح لعدة أسباب:- التوافق بشكل أساسي مع FireFox ، وفي FireFox لم يقم إطار A-frame بإصدار موارد نسيج (تم ضبط باقي المتصفحات) حتى وصل استهلاك الذاكرة إلى 16 جيجابايت
- تفاعل محدود مع وحدات تحكم VR وخوذة. لذلك ، على سبيل المثال ، لم يكن من الممكن إضافة علامات إضافية يمكنك من خلالها تحديد موضع مرفقي المشغل ، على سبيل المثال.
- يتطلب التطبيق عمليات متعددة أو عدة عمليات. في خيط / عملية واحدة ، كان من الضروري فك إطارات الفيديو ، في آخر - رسم. ونتيجة لذلك ، تم تنظيم كل شيء من خلال العمال ، ولكن وقت التفريغ بلغ 30 مللي ثانية ، ويجب أن يتم العرض في VR على تردد 90 إطارًا في الثانية.
أدت كل هذه العيوب إلى حقيقة أن عرض الإطار لم يكن لديه وقت في 10 مللي ثانية المخصصة وكان هناك تشنجات غير سارة للغاية في الواقع الافتراضي. ربما يمكن التغلب على كل شيء ، لكن هوية كل متصفح كانت مزعجة قليلاً.قررنا الآن المغادرة إلى منفذ C # و OpenTK و C # في مكتبة OpenVR. لا يزال هناك بديل - الوحدة. يكتبون أن الوحدة للمبتدئين ... لكنها صعبة.أهم شيء يجب إيجاده ومعرفته لاكتساب الحرية:VRTextureBounds_t bounds = new VRTextureBounds_t() { uMin = 0, vMin = 0, uMax = 1f, vMax = 1f };
OpenVR.Compositor.Submit(EVREye.Eye_Left, ref leftTexture, ref bounds, EVRSubmitFlags.Submit_Default);
OpenVR.Compositor.Submit(EVREye.Eye_Right, ref rightTexture, ref bounds, EVRSubmitFlags.Submit_Default);
(هذا هو الرمز لإرسال نسيجين إلى العين اليمنى واليسرى للخوذة) ،أي ارسم OpenGL في الملمس ما تراه العيون المختلفة ، وأرسله إلى النظارات. لم يعرف جوي حدودًا عندما اتضح لملء العين اليسرى باللون الأحمر ، واليمين باللون الأزرق. بضعة أيام فقط والآن تم نقل العمق وخريطة RGB القادمة عبر webSocket إلى النموذج متعدد الأضلاع في 10 مللي ثانية بدلاً من 30 على JS. ثم استفسر فقط إحداثيات وأزرار وحدات التحكم ، وأدخل نظام الأحداث للأزرار ، ومعالجة نقرات المستخدم ، وادخل State Machine لواجهة المستخدم ، ويمكنك الآن الحصول على كوب من الإسبريسو:الآن جودة Realsense D435 محبطة إلى حد ما ، لكنها ستمر بمجرد أن نثبت على الأقل مثل هذا الماسح الضوئي ثلاثي الأبعاد المثير للاهتمام من Microsoft ، حيث تكون السحابة النقطية أكثر دقة.جانب الخادم
خادم الترحيلالعنصر الوظيفي الرئيسي هو تتابع الخادم (الخادم في الوسط) ، الذي يتلقى دفق فيديو من الروبوت مع صور ثلاثية الأبعاد وقراءات أجهزة الاستشعار وحالة الروبوت ويوزعه بين المستهلكين. بيانات الإدخال - الإطارات المعبأة وقراءات أجهزة الاستشعار القادمة عبر TCP / IP. يتم التوزيع للمستهلكين بواسطة مقابس الويب (آلية ملائمة جدًا للتدفق إلى العديد من المستهلكين ، بما في ذلك المتصفح).بالإضافة إلى ذلك ، يقوم الخادم المرحلي بتخزين دفق البيانات في التخزين السحابي S3 بحيث يمكن استخدامه فيما بعد للتدريب.يدعم كل خادم مرحل واجهة برمجة تطبيقات http ، والتي تتيح لك معرفة حالتها الحالية ، وهي ملائمة لمراقبة الاتصالات الحالية.مهمة الترحيل صعبة للغاية ، من وجهة نظر الحوسبة ومن وجهة نظر حركة المرور. لذلك ، اتبعنا هنا المنطق الذي يتم نشر خوادم الترحيل فيه على مجموعة متنوعة من الخوادم السحابية. وهذا يعني أنك بحاجة إلى تتبع الأشخاص الذين يتصلون بأين (خاصة إذا كانت الروبوتات والمشغلين في مناطق مختلفة).التسجيلسيكون الأكثر موثوقية الآن من الصعب تعيينه لكل روبوت يمكن للخوادم التي يمكنه الاتصال به (لن يضر ذلك). ترتبط خدمة إدارة ML بالروبوت ، حيث تقوم باستقصاء خادم الترحيل لتحديد أيهما يتصل الروبوت ويتصل بالخادم المقابل ، إذا كان لديه بالطبع حقوق كافية لذلك. يعمل تطبيق عامل التشغيل بطريقة مماثلة.الأكثر متعة! نظرًا لأن تدريب الروبوتات هو خدمة ، فإن الخدمة مرئية لنا فقط في الداخل. لذا ، يمكن أن تكون الواجهة الأمامية مريحة قدر الإمكان بالنسبة لنا! أولئك. إنها وحدة تحكم في المتصفح (هناك مكتبة TerminalJS جميلة في بساطتها ، والتي من السهل جدًا تعديلها إذا كنت تريد وظائف إضافية ، مثل الإكمال التلقائي لـ TAB أو تشغيل سجل المكالمات) ويبدو هذا: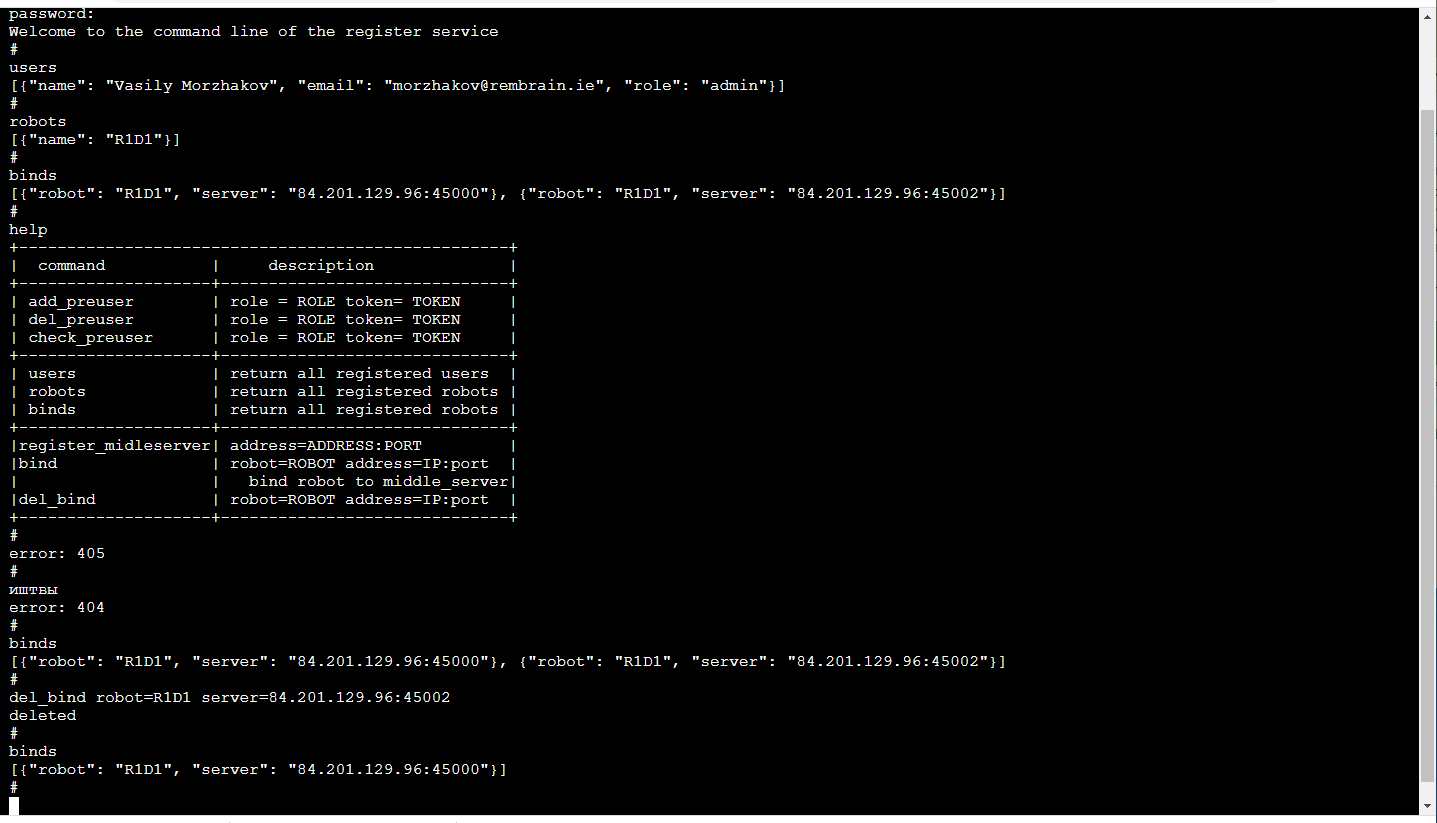 هذا بالطبع موضوع منفصل للنقاش ، لماذا سطر الأوامر مريح جدا. بالمناسبة ، من الملائم بشكل خاص إجراء اختبار الوحدة لمثل هذه الواجهة الأمامية.بالإضافة إلى http API ، تطبق هذه الخدمة آلية لتسجيل المستخدمين باستخدام الرموز المؤقتة ، ومشغلي تسجيل الدخول / الخروج ، والمسؤولين والروبوتات ، ودعم الجلسة ، ومفاتيح تشفير الجلسة لتشفير حركة المرور بين خادم الترحيل والروبوت.كل هذا يتم في Python مع Flask - مجموعة قريبة جدًا لمطوري ML (أي نحن). نعم ، بالإضافة إلى ذلك ، فإن البنية التحتية الحالية للقرص المضغوط / القرص المضغوط الخاصة بالخدمات الصغيرة تعمل بشروط ودية مع Flask.
هذا بالطبع موضوع منفصل للنقاش ، لماذا سطر الأوامر مريح جدا. بالمناسبة ، من الملائم بشكل خاص إجراء اختبار الوحدة لمثل هذه الواجهة الأمامية.بالإضافة إلى http API ، تطبق هذه الخدمة آلية لتسجيل المستخدمين باستخدام الرموز المؤقتة ، ومشغلي تسجيل الدخول / الخروج ، والمسؤولين والروبوتات ، ودعم الجلسة ، ومفاتيح تشفير الجلسة لتشفير حركة المرور بين خادم الترحيل والروبوت.كل هذا يتم في Python مع Flask - مجموعة قريبة جدًا لمطوري ML (أي نحن). نعم ، بالإضافة إلى ذلك ، فإن البنية التحتية الحالية للقرص المضغوط / القرص المضغوط الخاصة بالخدمات الصغيرة تعمل بشروط ودية مع Flask.مشكلة التأخير
إذا أردنا التحكم في المتلاعبين في الوقت الفعلي ، فإن الحد الأدنى من التأخير مفيد للغاية. إذا أصبح التأخير كبيرًا جدًا (أكثر من 300 مللي ثانية) ، فمن الصعب جدًا التحكم في المتلاعبين بناءً على الصورة في الخوذة الافتراضية. في حلنا ، بسبب ضغط الإطار بإطار (أي أنه لا يوجد تخزين مؤقت) وعدم استخدام الأدوات القياسية مثل GStreamer ، فإن التأخير حتى مع مراعاة الخادم الوسيط حوالي 150-200 مللي ثانية. وقت الإرسال عبر الشبكة حوالي 80 مللي ثانية. يرجع سبب التأخير المتبقي إلى كاميرا Realsense D435 وتردد الالتقاط المحدود.بالطبع ، هذه مشكلة كاملة الارتفاع تنشأ في وضع "التتبع" ، عندما يتبع المتلاعب في واقعه باستمرار وحدة تحكم المشغل في الواقع الافتراضي. في وضع الانتقال إلى نقطة معينة XYZ ، لا يسبب التأخير أي مشاكل للمشغل.جزء ML
هناك نوعان من الخدمات: الإدارة والتدريب.تقوم خدمة التدريب بجمع البيانات المخزنة في مخزن S3 وتبدأ إعادة تدريب أوزان النموذج. في نهاية التدريب ، يتم إرسال الأوزان إلى خدمة الإدارة.لا تختلف خدمة الإدارة من حيث بيانات المدخلات والمخرجات عن تطبيق المشغل. وبالمثل ، دفق RGBD (RGB + عمق) الإدخال ، وقراءات أجهزة الاستشعار وحالة الروبوت ، وأوامر التحكم في الإخراج. بسبب هذه الهوية ، يبدو من الممكن التدريب في إطار مفهوم "التدريب القائم على البيانات".حالة الروبوت (وقراءات المستشعر) هي قصة رئيسية لـ ML. يحدد السياق. على سبيل المثال ، سيكون لدى الروبوت آلة حالة مميزة لعمله ، والتي تحدد إلى حد كبير نوع التحكم الضروري. يتم إرسال هاتين القيمتين مع كل إطار: وضع التشغيل ومتجه الحالة للروبوت.وقليلاً عن التدريب:في العرض التوضيحي في نهاية المقال كانت مهمة العثور على كائن (مكعب للأطفال) على مشهد ثلاثي الأبعاد. هذه مهمة أساسية لاختيار التطبيقات ومكانها.اعتمد التدريب على زوج من الإطارات "قبل وبعد" وتعيين الهدف الذي تم الحصول عليه باستخدام التحكم اليدوي: نظرًا لوجود خريطتي عمق ، كان من السهل حساب قناع الكائن المتحرك في الإطار:
نظرًا لوجود خريطتي عمق ، كان من السهل حساب قناع الكائن المتحرك في الإطار: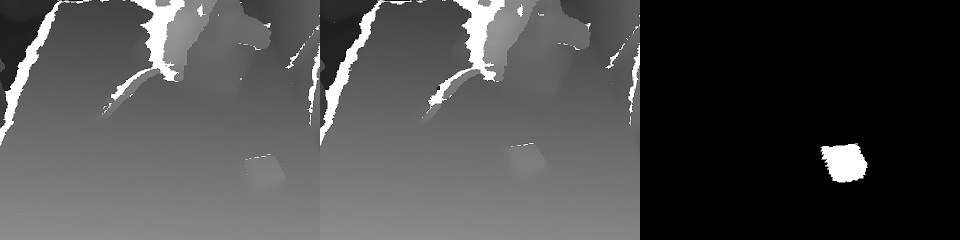 بالإضافة إلى ذلك ، يتم عرض xyz على مستوى الكاميرا ويمكنك تحديد حي الكائن الملتقط:
بالإضافة إلى ذلك ، يتم عرض xyz على مستوى الكاميرا ويمكنك تحديد حي الكائن الملتقط: في الواقع مع هذا الحي وستعمل.أولاً نحصل على XY من خلال تدريب Unet على شبكة تلافيفية لتجزئة المكعب.بعد ذلك ، نحتاج إلى تحديد العمق وفهم ما إذا كانت الصورة غير طبيعية أمامنا. يتم ذلك باستخدام التشفير التلقائي في RGB وترميز تلقائي مشروط في العمق.بنية النموذج لتدريب التشفير التلقائي:
في الواقع مع هذا الحي وستعمل.أولاً نحصل على XY من خلال تدريب Unet على شبكة تلافيفية لتجزئة المكعب.بعد ذلك ، نحتاج إلى تحديد العمق وفهم ما إذا كانت الصورة غير طبيعية أمامنا. يتم ذلك باستخدام التشفير التلقائي في RGB وترميز تلقائي مشروط في العمق.بنية النموذج لتدريب التشفير التلقائي: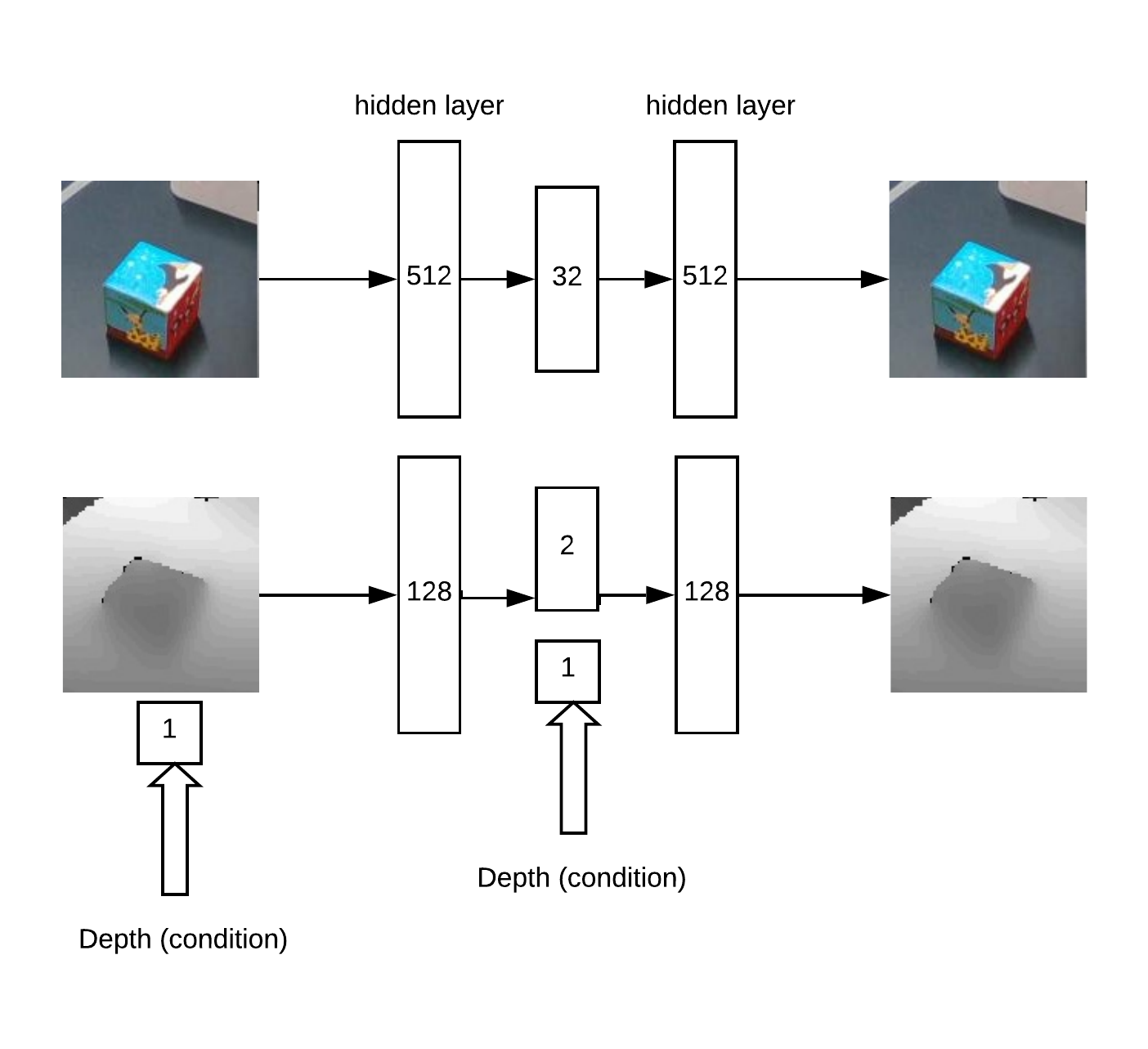 ونتيجة لذلك ، فإن منطق العمل:
ونتيجة لذلك ، فإن منطق العمل:- ابحث عن الحد الأقصى على "خريطة الحرارة" (حدد إحداثيات الزاوية = u / x / zv = y / z للكائن) التي تتجاوز العتبة
- ثم يقوم برنامج التشفير التلقائي بإعادة بناء حي النقطة التي تم العثور عليها لجميع الفرضيات في العمق (مع خطوة معينة من min_depth إلى max_depth) ويحدد العمق الذي يكون فيه التناقض بين إعادة البناء والإدخال في حده الأدنى
- بوجود الإحداثيات الزاوية u و v والعمق ، يمكنك الحصول على الإحداثيات x و y و z
مثال على إعادة ترميز التشفير التلقائي لخريطة أعماق المكعب بعمق محدد بشكل صحيح: جزئيًا ، تستند فكرة طريقة البحث عن العمق إلى مقالة حول مجموعات من الترميز التلقائي .يعمل هذا النهج بشكل جيد مع الكائنات ذات الأشكال المختلفة.ولكن ، بشكل عام ، هناك العديد من الطرق المختلفة للعثور على كائن XYZ من صورة RGBD. بالطبع ، من الضروري في الممارسة العملية وعلى كمية كبيرة من البيانات اختيار الطريقة الأكثر دقة.كانت هناك أيضًا مهمة الكشف عن الشذوذ ، لذلك نحن بحاجة إلى شبكة تلافيفية تجزئة للتعلم من الأقنعة المتاحة. بعد ذلك ، وفقًا لهذا القناع ، يمكنك تقييم دقة إعادة إنشاء برنامج التشفير التلقائي في خريطة العمق و RGB. بسبب هذا التناقض ، يمكن للمرء أن يقرر وجود شذوذ.بفضل هذه الطريقة ، من الممكن الكشف عن مظهر الكائنات التي لم تشاهدها من قبل في الإطار ، والتي تم اكتشافها من خلال خوارزمية البحث الأساسية.
جزئيًا ، تستند فكرة طريقة البحث عن العمق إلى مقالة حول مجموعات من الترميز التلقائي .يعمل هذا النهج بشكل جيد مع الكائنات ذات الأشكال المختلفة.ولكن ، بشكل عام ، هناك العديد من الطرق المختلفة للعثور على كائن XYZ من صورة RGBD. بالطبع ، من الضروري في الممارسة العملية وعلى كمية كبيرة من البيانات اختيار الطريقة الأكثر دقة.كانت هناك أيضًا مهمة الكشف عن الشذوذ ، لذلك نحن بحاجة إلى شبكة تلافيفية تجزئة للتعلم من الأقنعة المتاحة. بعد ذلك ، وفقًا لهذا القناع ، يمكنك تقييم دقة إعادة إنشاء برنامج التشفير التلقائي في خريطة العمق و RGB. بسبب هذا التناقض ، يمكن للمرء أن يقرر وجود شذوذ.بفضل هذه الطريقة ، من الممكن الكشف عن مظهر الكائنات التي لم تشاهدها من قبل في الإطار ، والتي تم اكتشافها من خلال خوارزمية البحث الأساسية.برهنة
تم فحص وتصحيح النظام الأساسي للبرمجيات التي تم إنشاؤها بالكامل في المنصة:- كاميرا ثلاثية الأبعاد Realsense D435
- 4 تنسيق Dobot Magician
- خوذة VR HTC Vive
- الخوادم على Yandex Cloud (تقلل من الكمون مقارنة بـ AWS cloud)
في الفيديو ، نعلم كيفية العثور على مكعب في مشهد ثلاثي الأبعاد من خلال أداء مهمة في مكان واختيار VR. حوالي 50 مثال كانت كافية للتدريب على المكعب. ثم يتغير الكائن ويظهر حوالي 30 مثالاً آخر. بعد إعادة التدريب ، يمكن للروبوت العثور على كائن جديد.استغرقت العملية برمتها حوالي 15 دقيقة ، منها حوالي نصف تدريب نموذج الأوزان.وفي هذا الفيديو ، يتحكم YuMi في الواقع الافتراضي. لمعرفة كيفية التعامل مع الكائنات ، تحتاج إلى تقييم اتجاه الأداة وموقعها. الرياضيات مبنية على مبدأ مماثل ، لكنها الآن في مرحلة الاختبار والتطوير.استنتاج
البيانات الضخمة والتعلم العميق ليست كلها.نحن نغير نهج التعلم ، ونتجه نحو كيفية تعلم الناس لأشياء جديدة - من خلال تكرار ما يرونه.يهدف الجهاز الرياضي "تحت الغطاء" ، الذي سنقوم بتطويره في التطبيقات الحقيقية ، إلى مشكلة التفسير والتحكم الحساس للسياق. السياق هنا هو معلومات طبيعية متاحة من أجهزة استشعار الروبوت أو معلومات خارجية حول العملية الحالية.وكلما زادت العمليات التكنولوجية التي نتقنها ، كلما تم تطوير بنية "الدماغ في الغيوم" ، وسيتم تدريب أجزائه الفردية.قدرات هذا النهج:- إمكانية تعلم كيفية معالجة الأشياء المتغيرة
- التعلم في بيئة متغيرة (مثل الروبوتات المحمولة)
- مهام سيئة التنظيم
- وقت قصير للسوق. يمكنك تنفيذ الهدف حتى في الوضع اليدوي باستخدام عوامل التشغيل
الحد:- الحاجة إلى إنترنت موثوق وجيد
- هناك حاجة إلى طرق إضافية لتحقيق دقة عالية ، على سبيل المثال ، الكاميرات الموجودة في المعالج
نحن نعمل حاليًا على تطبيق نهجنا على مهمة الاختيار والمكان القياسية للكائنات المختلفة. ولكن يبدو لنا (بطبيعة الحال!) أنه قادر على المزيد. أي أفكار أخرى لمحاولة يدك؟شكرآ لك على أهتمامك!