في مقال سابق ، درسنا آلية الانتباه ، وهي طريقة شائعة للغاية في نماذج التعلم العميق الحديثة التي يمكنها تحسين مؤشرات أداء تطبيقات الترجمة الآلية العصبية. في هذه المقالة ، سنلقي نظرة على Transformer ، وهو نموذج يستخدم آلية الانتباه لزيادة سرعة التعلم. علاوة على ذلك ، بالنسبة لعدد من المهام ، تتفوق المحولات على نموذج الترجمة الآلية العصبية من Google. ومع ذلك ، فإن أكبر ميزة للمحولات هي كفاءتها العالية في ظروف التوازي. حتى Google Cloud توصي باستخدام Transformer كنموذج عند العمل على Cloud TPU . دعونا نحاول معرفة ما يتكون النموذج والوظائف التي يؤديها.
تم اقتراح نموذج Transformer لأول مرة في المقالة الاهتمام هو كل ما تحتاجه . يتوفر تطبيق على TensorFlow كجزء من حزمة Tensor2Tensor ، بالإضافة إلى ذلك ، قامت مجموعة من الباحثين في البرمجة اللغوية العصبية من جامعة هارفارد بإنشاء شرح توضيحي للمقال مع تطبيق على PyTorch . في هذا الدليل نفسه ، سنحاول تحديد الأفكار والمفاهيم الرئيسية ببساطة وبشكل مستمر ، والتي نأمل أن تساعد الأشخاص الذين ليس لديهم معرفة عميقة بمجال الموضوع على فهم هذا النموذج.
مراجعة عالية المستوى
دعونا ننظر إلى النموذج كنوع من الصندوق الأسود. في تطبيقات الترجمة الآلية ، يقبل جملة في لغة واحدة كمدخل ويعرض جملة في لغة أخرى.

, , , .
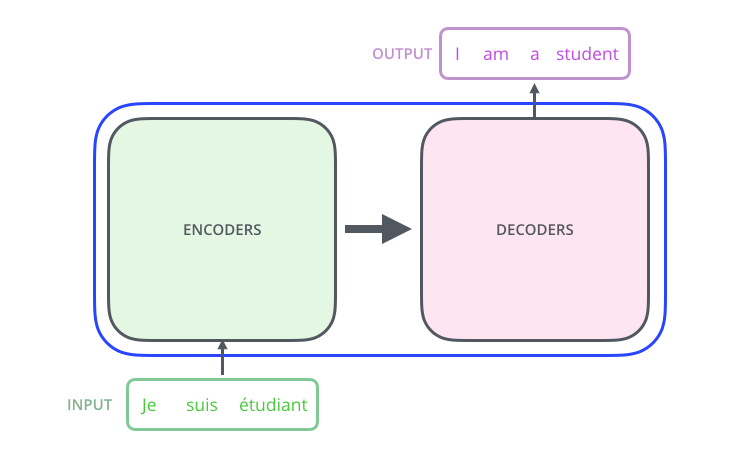
– ; 6 , ( 6 , ). – , .
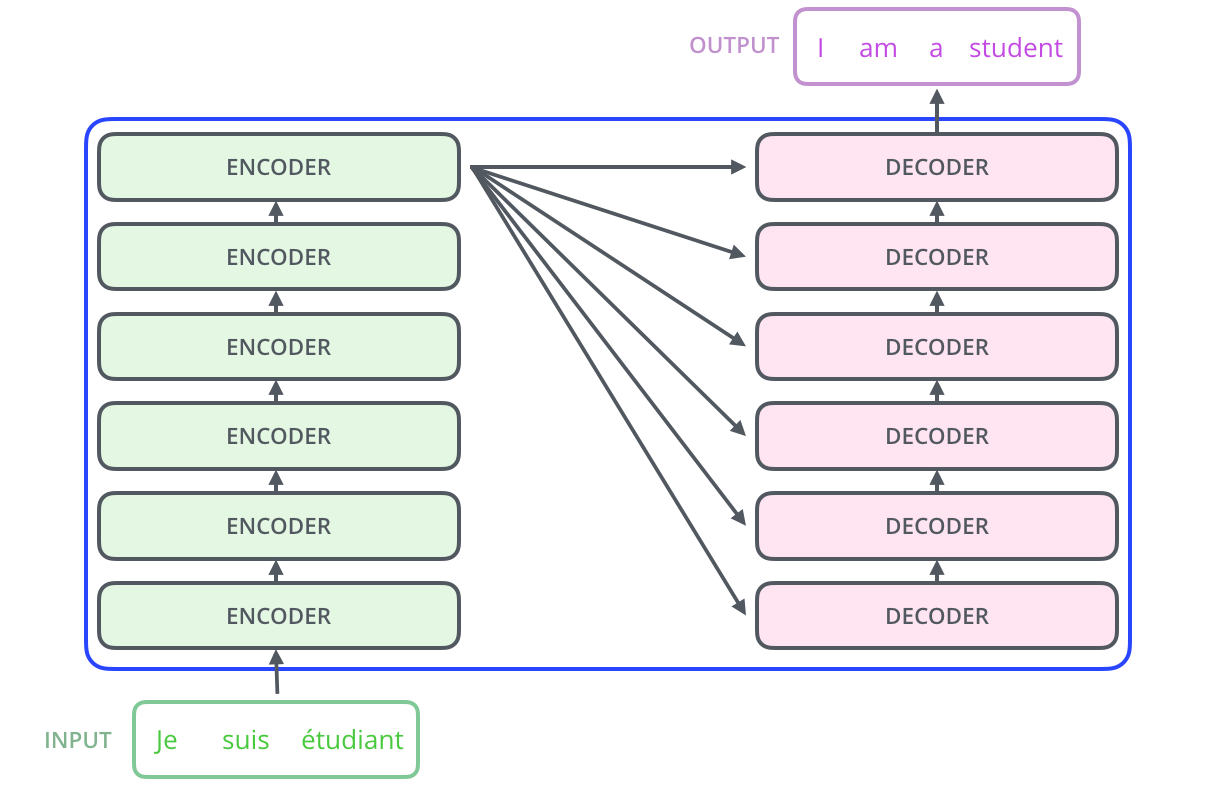
, . :
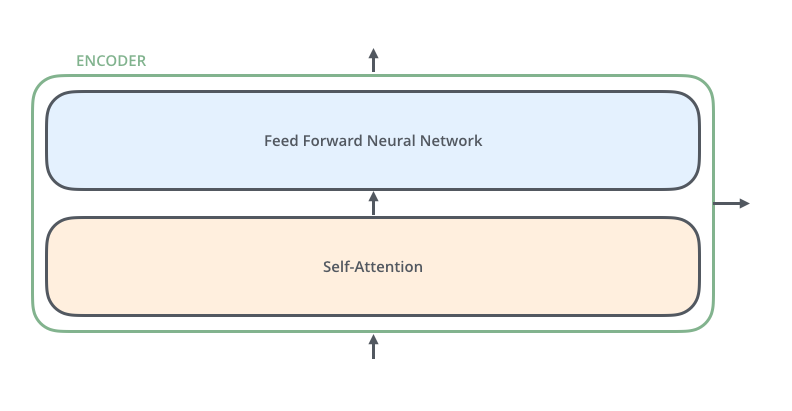
, , (self-attention), . .
(feed-forward neural network). .
, , ( , seq2seq).
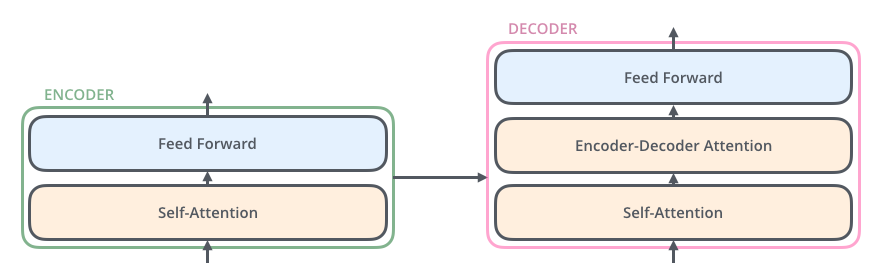
, , /, , .
NLP-, , , (word embeddings).

512. .
. , , : 512 ( , – ). , , , , .
, .
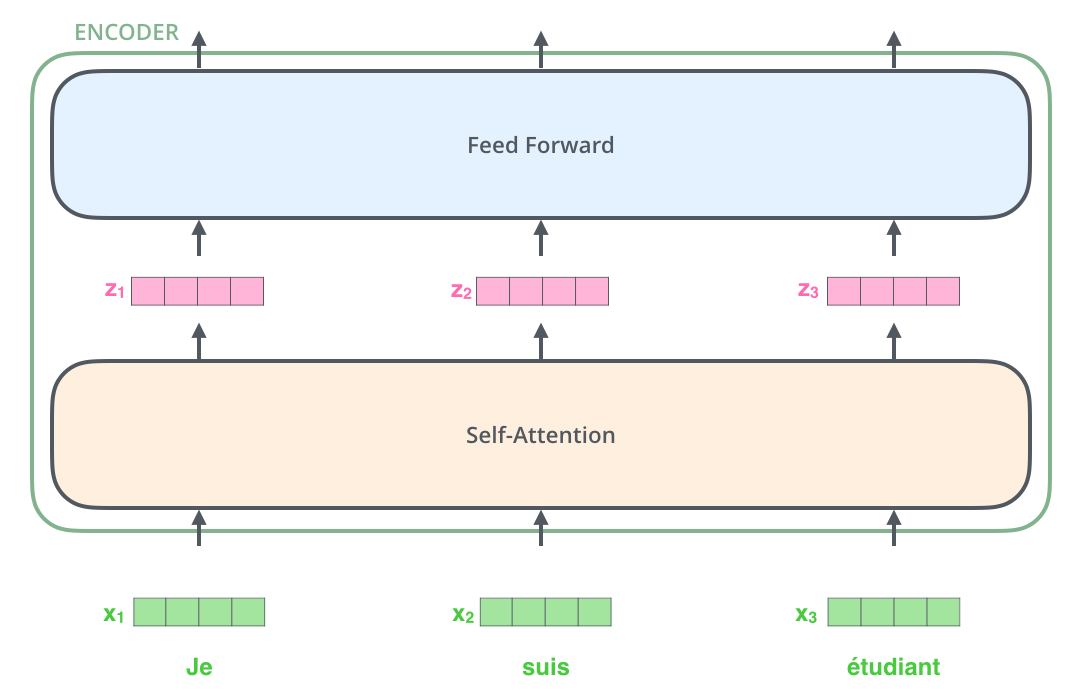
: . , , , .
, .
!
, , – , , , .
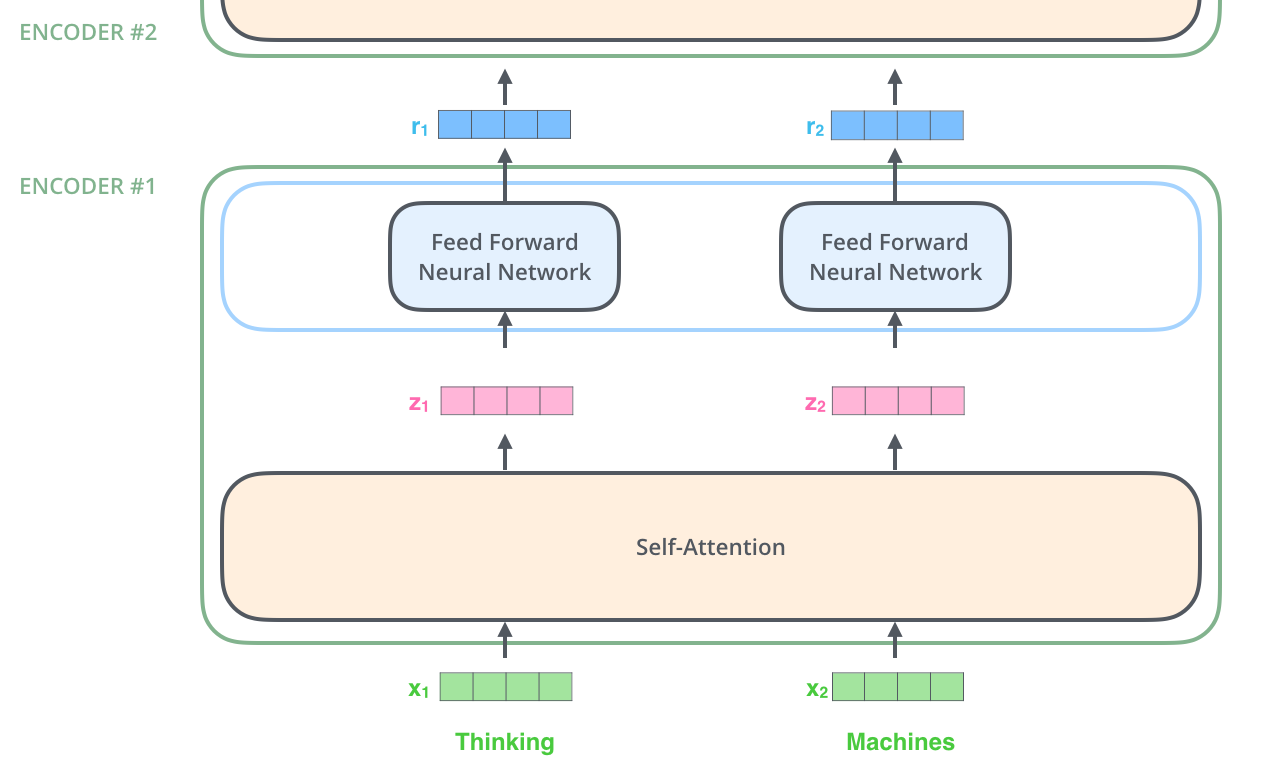
. , .
, « » -, . , «Attention is All You Need». , .
– , :
”The animal didn't cross the street because it was too tired”
«it» ? (street) (animal)? .
«it», , «it» «animal».
( ), , .
(RNN), , RNN /, , . – , , «» .

«it» #5 ( ), «The animal» «it».
Tensor2Tensor, , .
, , , .
– ( – ): (Query vector), (Key vector) (Value vector). , .
, , . 64, / 512. , (multi-head attention) .
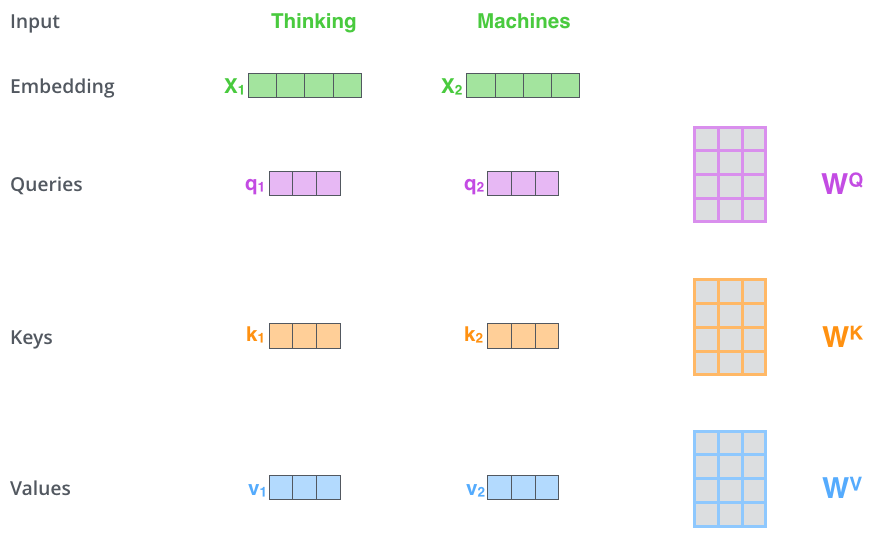
x1 WQ q1, «», . «», «» «» .
«», «» «»?
, . , , , .
– (score). , – «Thinking». . , .
. , #1, q1 k1, — q1 k2.
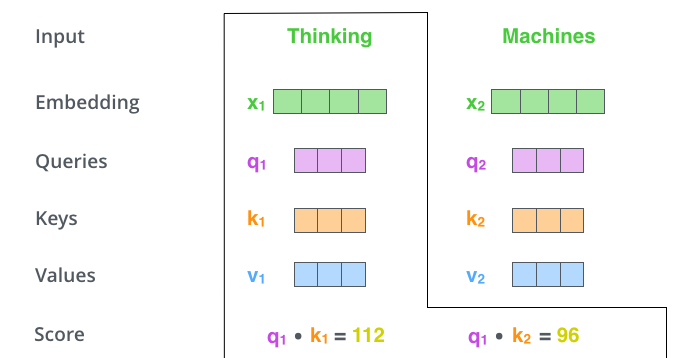
– 8 ( , – 64; , ), (softmax). , 1.
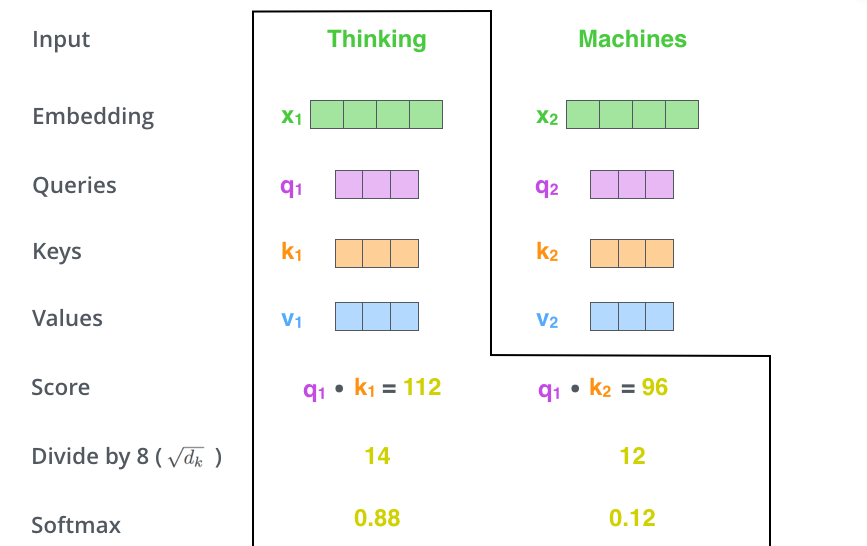
- (softmax score) , . , -, , .
– - ( ). : , , ( , , 0.001).
– . ( ).
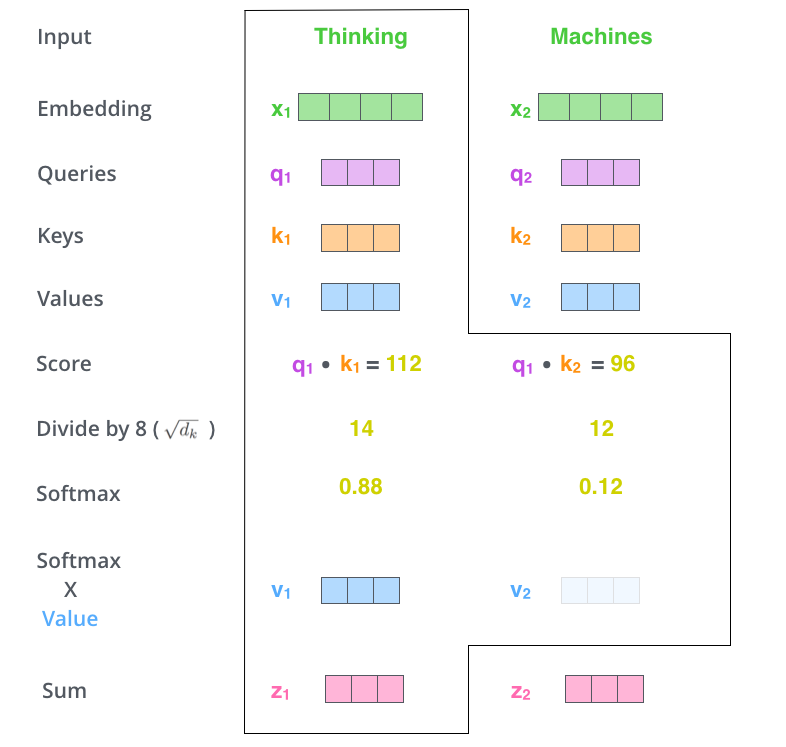
. , . , , . , , .
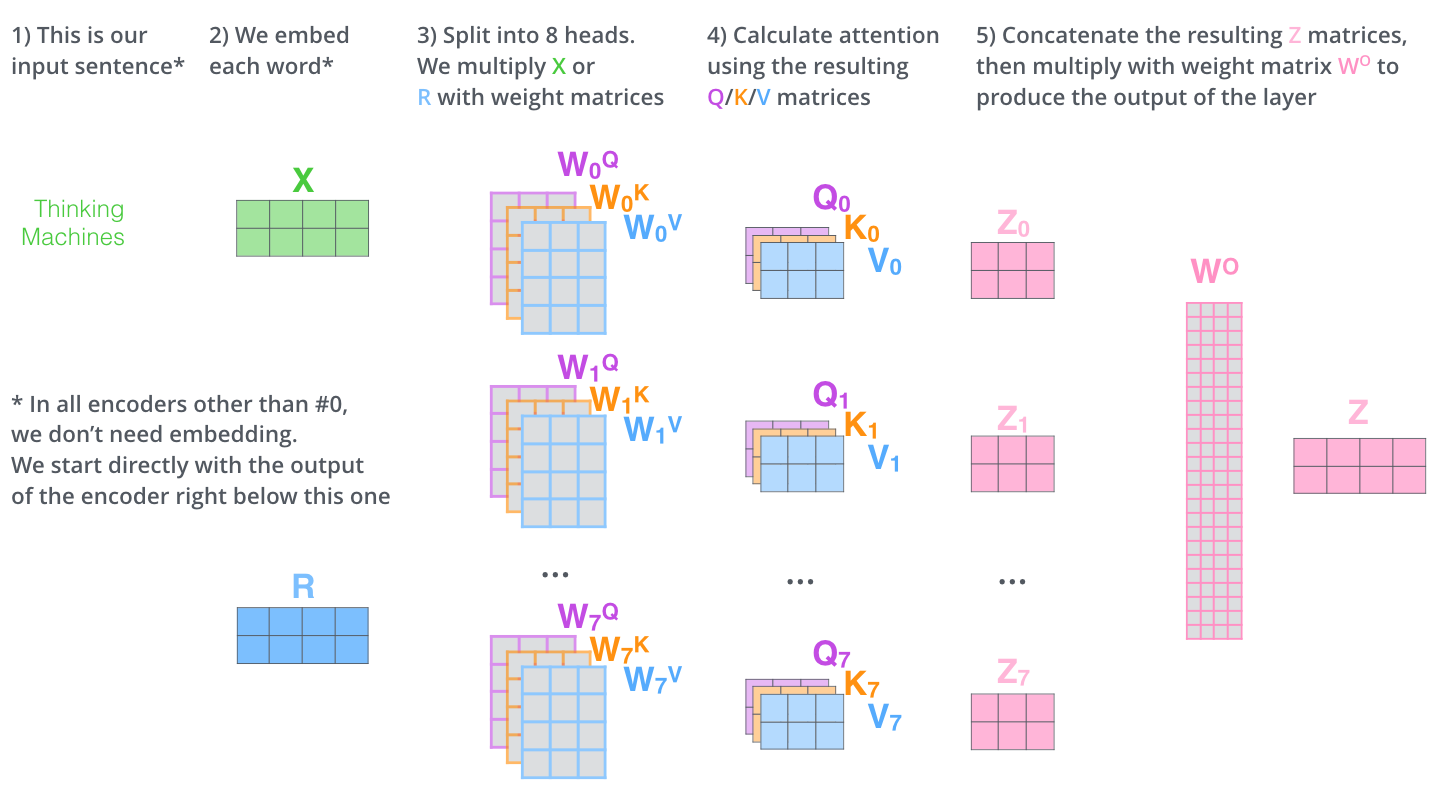
– , . X , (WQ, WK, WV).

. (512, 4 ) q/k/v (64, 3 ).
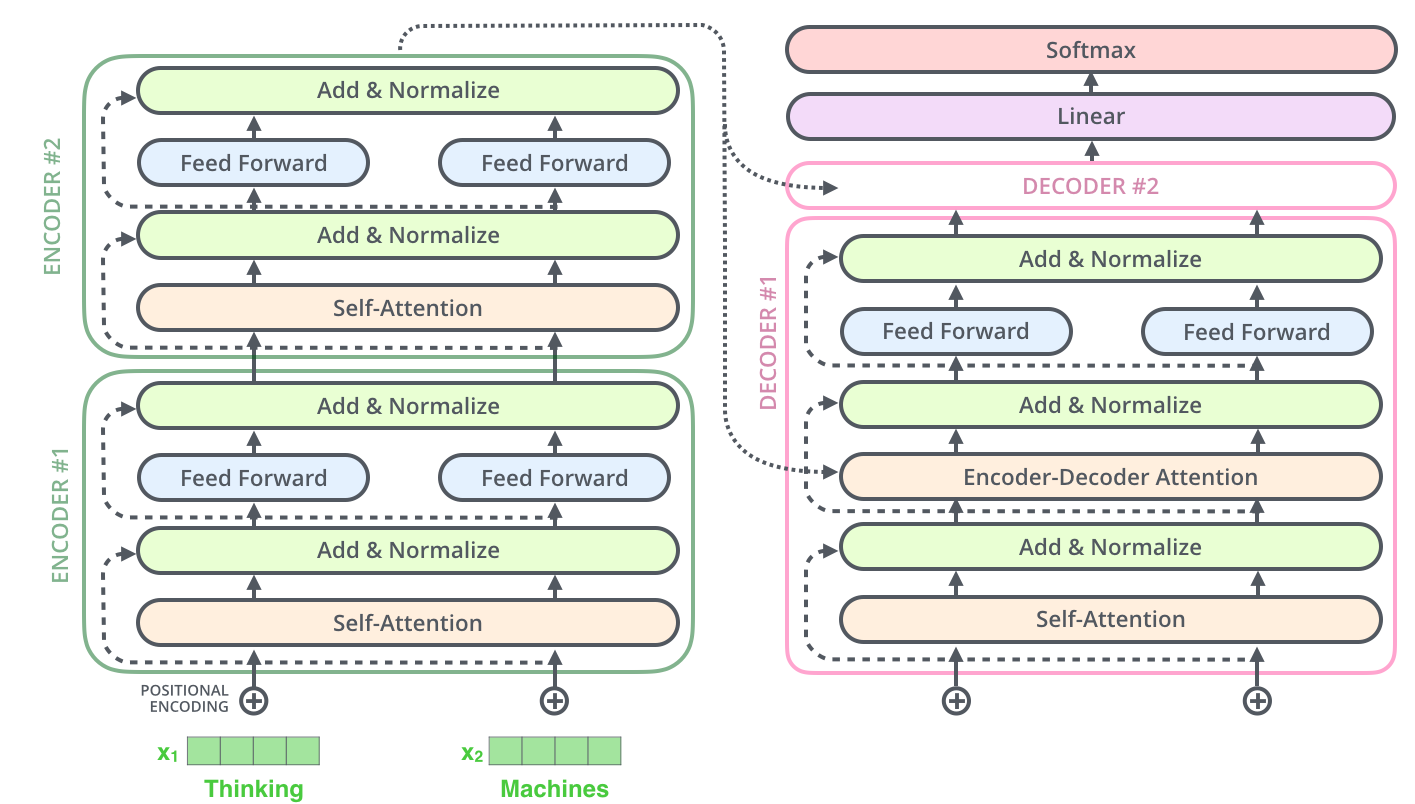
, , 2-6 .
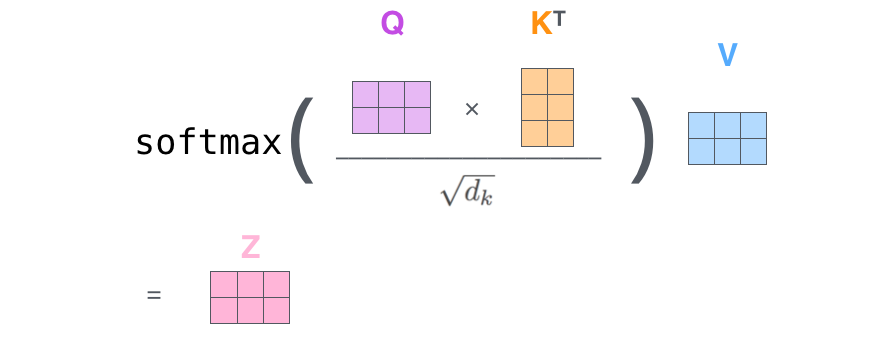
.
, (multi-head attention). :
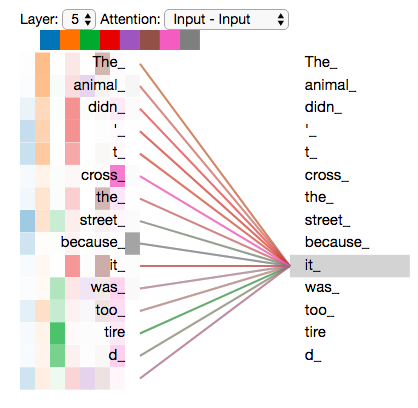
- . , , z1 , . «The animal didn’t cross the street because it was too tired», , «it».
- « » (representation subspaces). , , // ( 8 «» , 8 /). . ( /) .
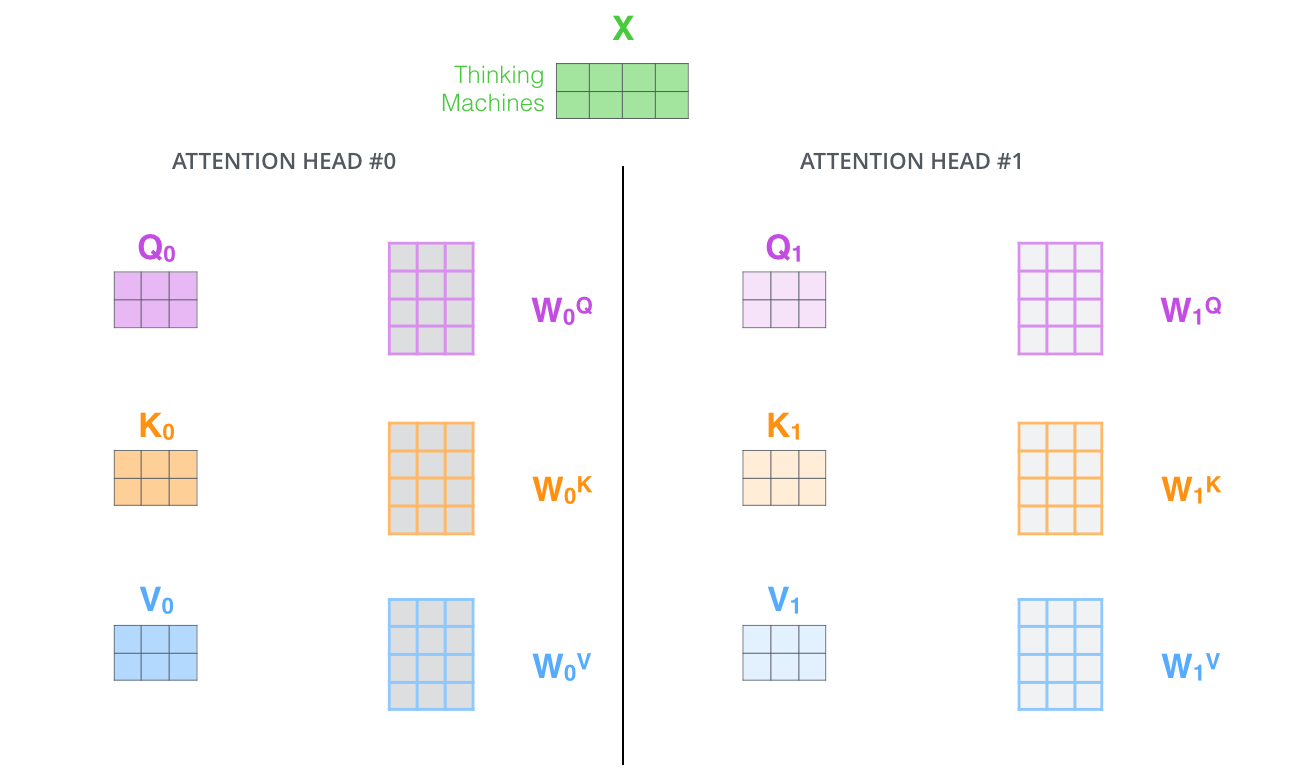
, WQ/WK/WV «», Q/K/V . , WQ/WK/WV Q/K/V .
, , 8 , 8 Z .
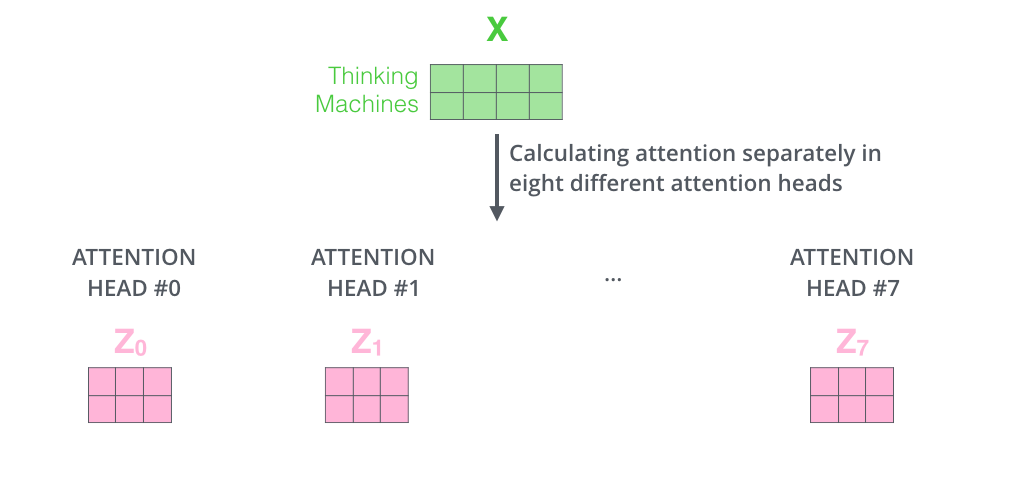
. , 8 – ( ), Z .
? WO.
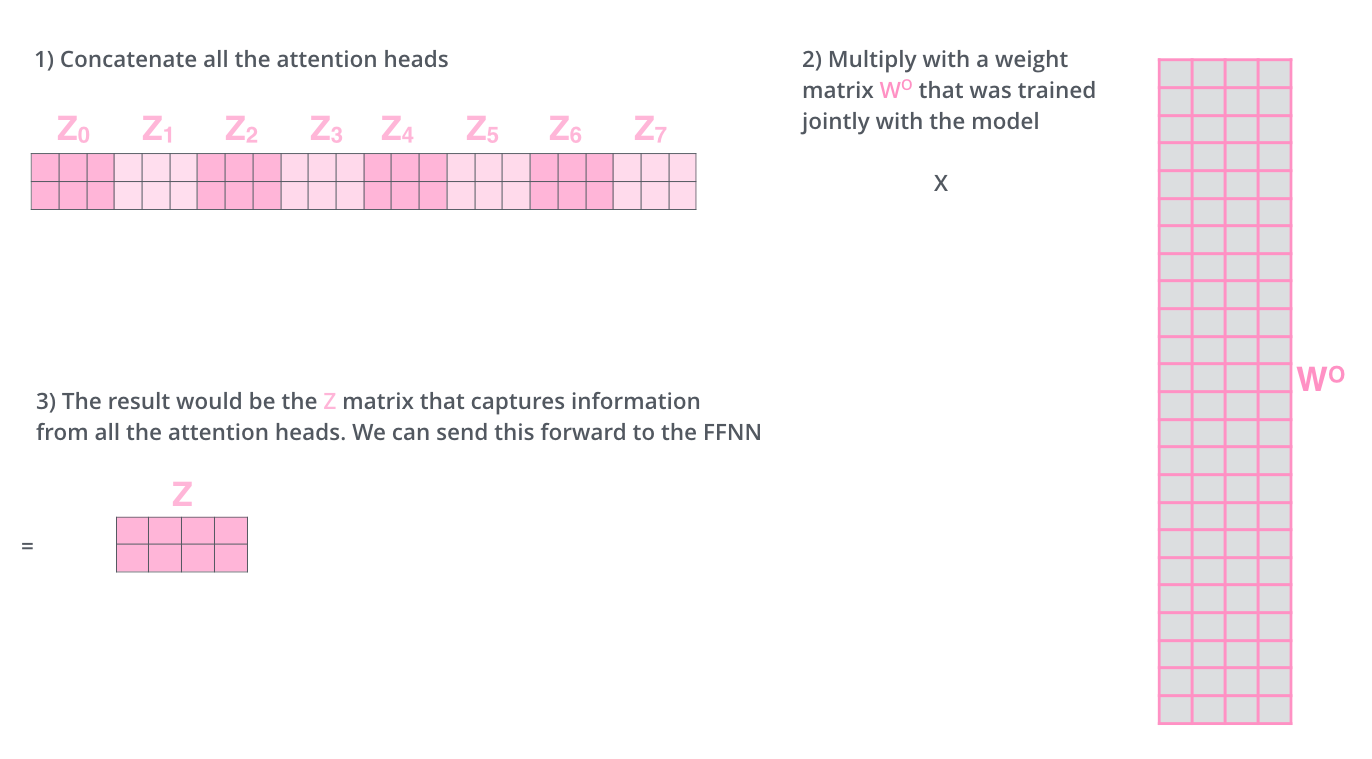
, , . , . , .
, «» , , , «» «it» :

«it», «» «the animal», — «tired». , «it» «animal» «tired».
«» , , .
— .
. , . , Q/K/V .
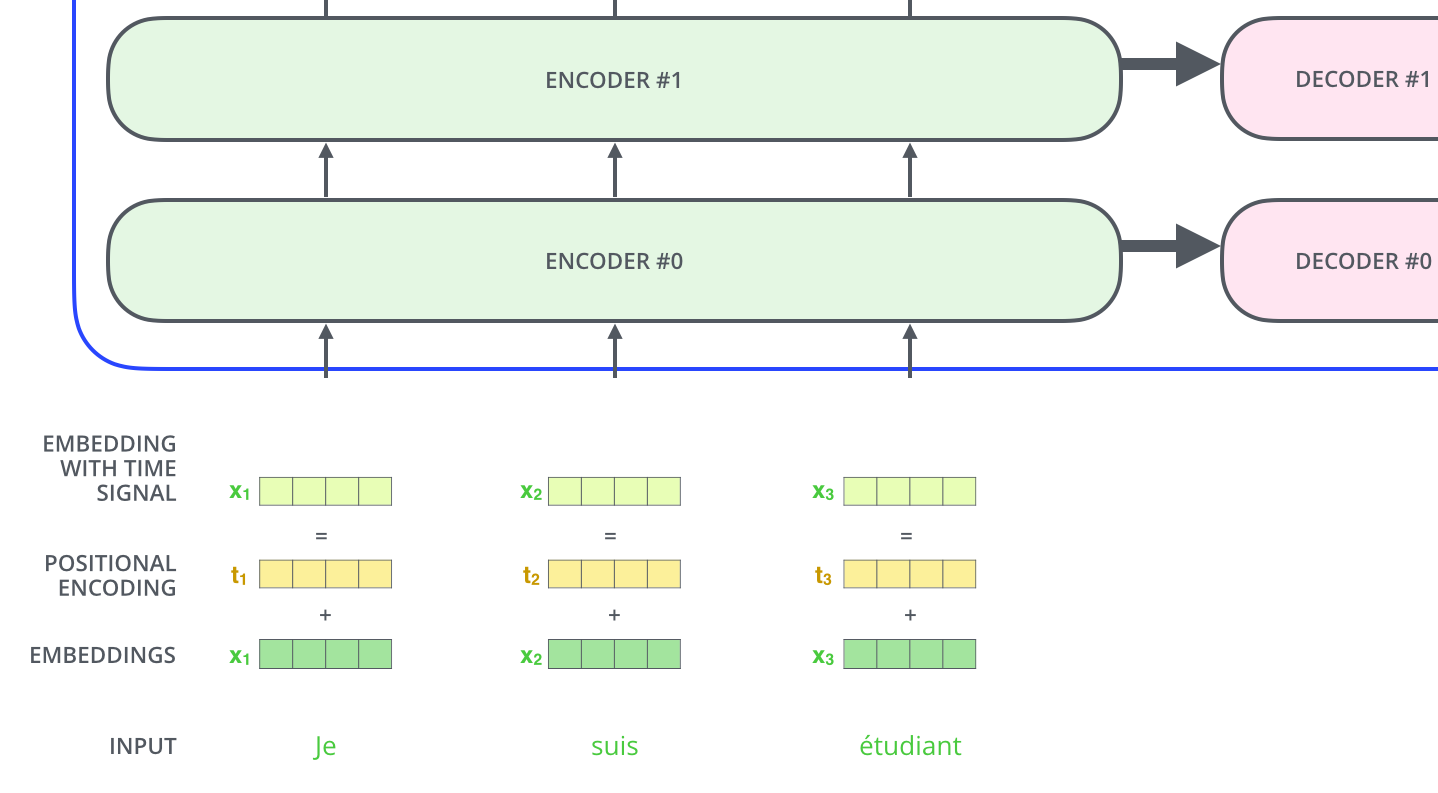
, , , .
, 4, :
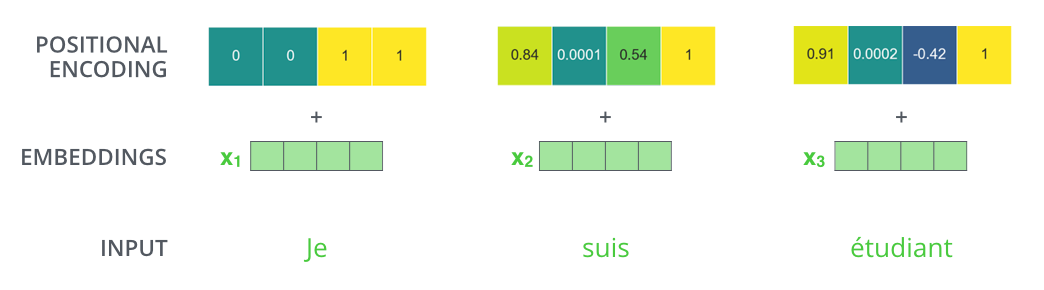
?
: , , , — .. 512 -1 1. , .
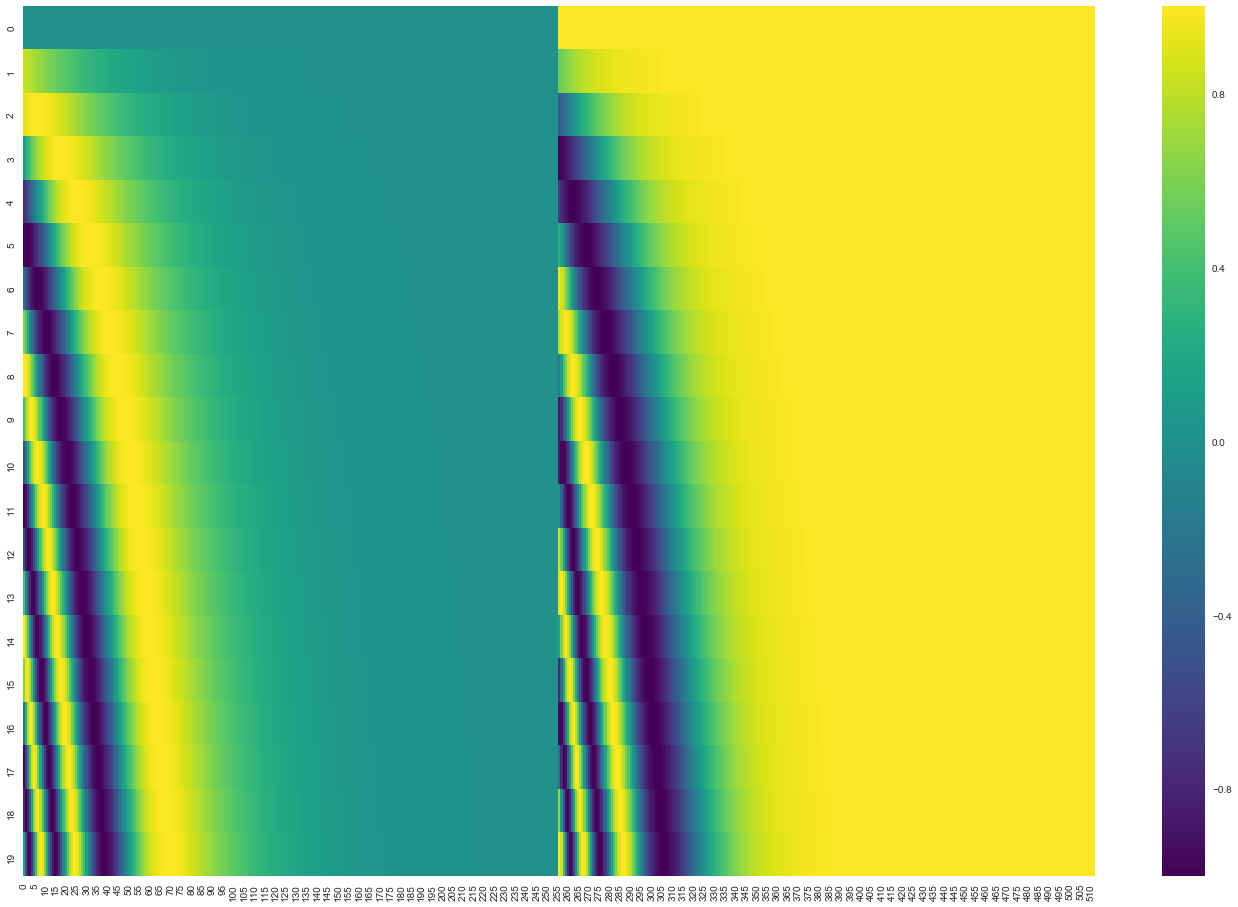
20 () 512 (). , : ( ), – ( ). .
( 3.5). get_timing_signal_1d(). , , (, , , ).
, , , , ( , ) , (layer-normalization step).
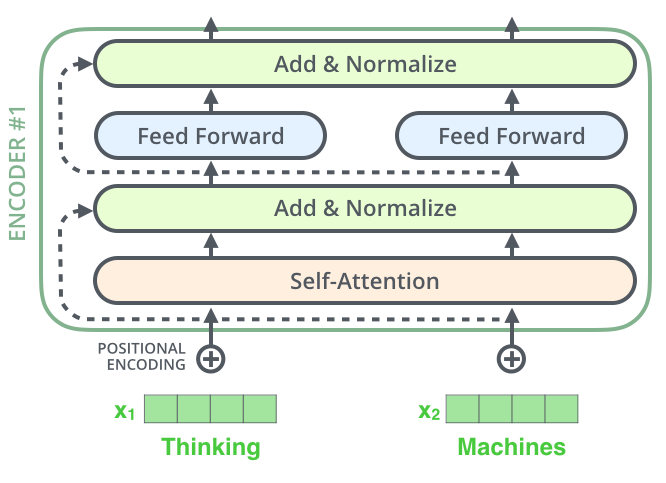
, , :
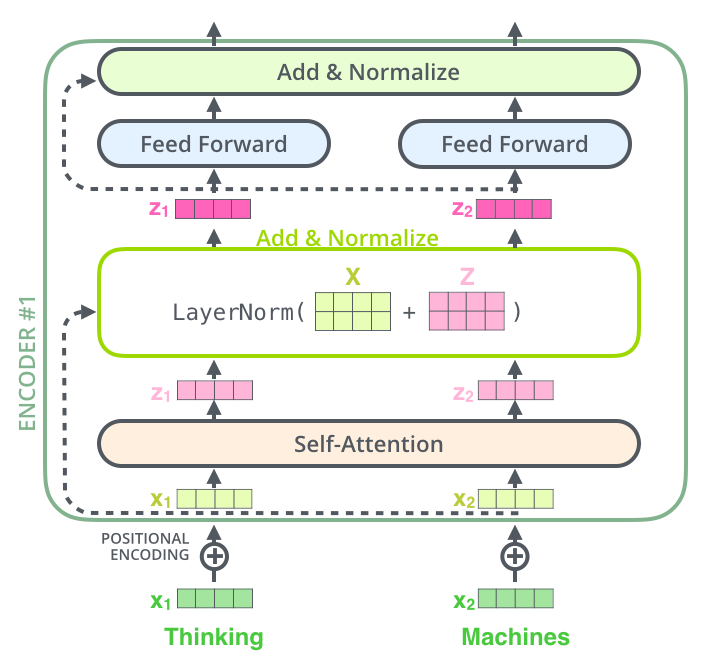
. , :
, , , . , .
. K V. «-» , :
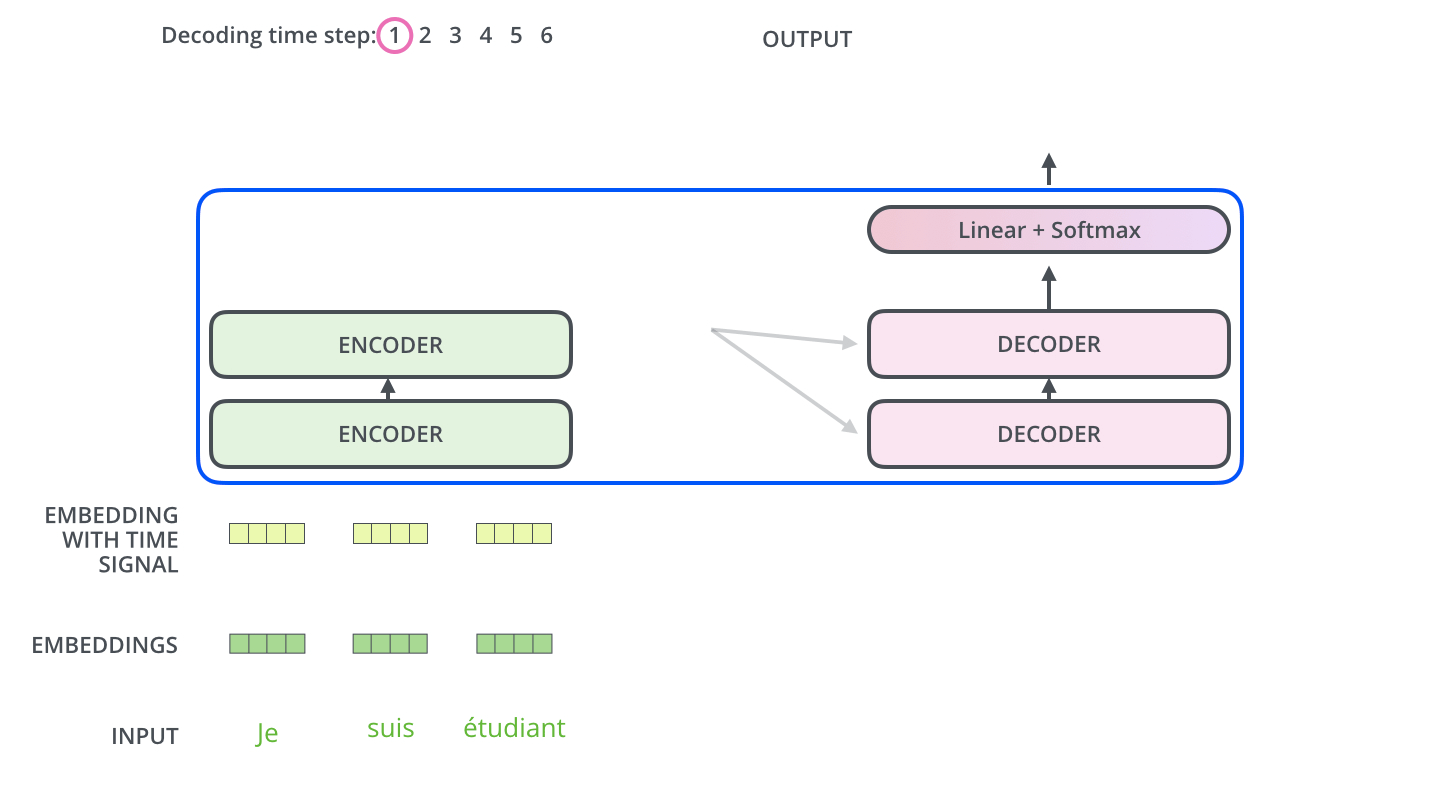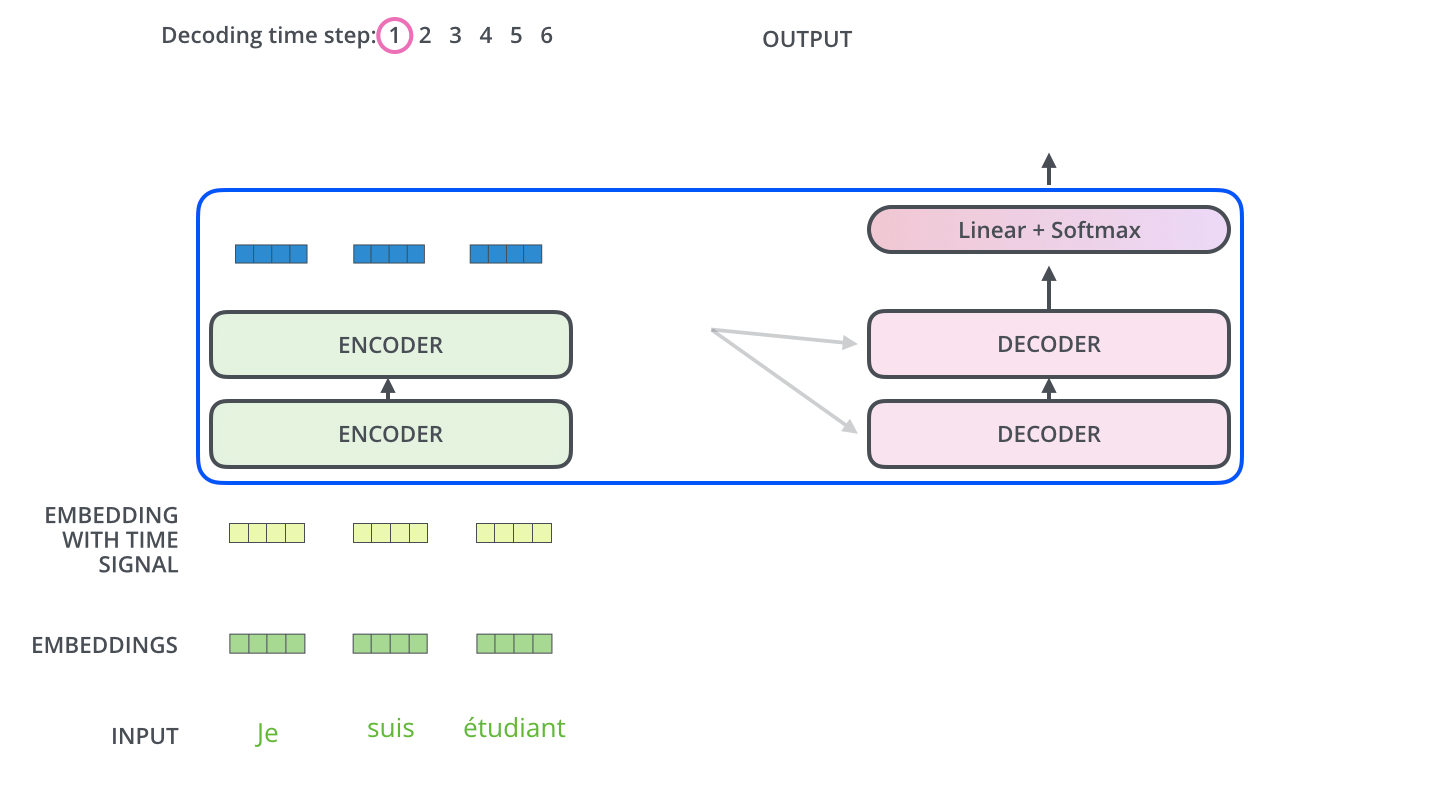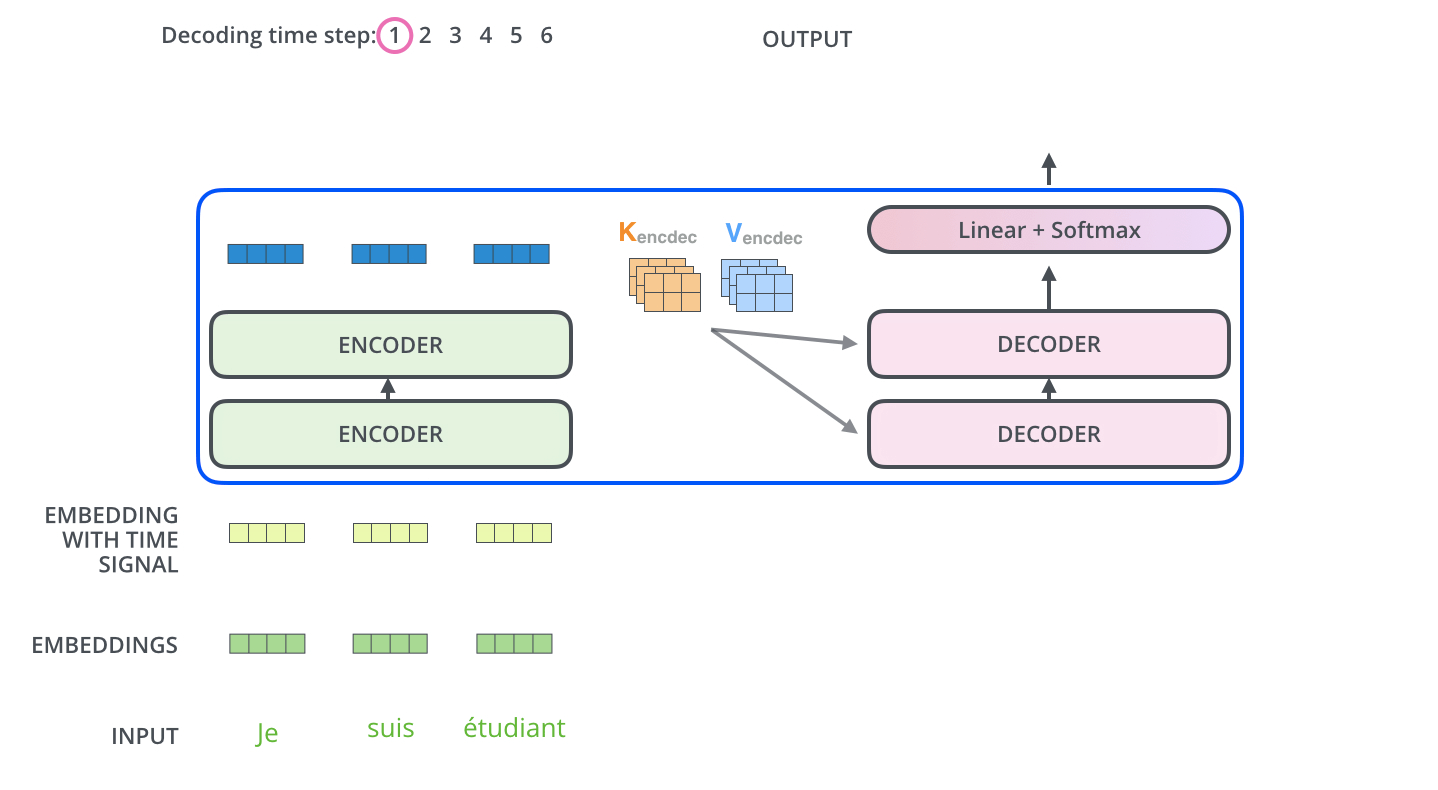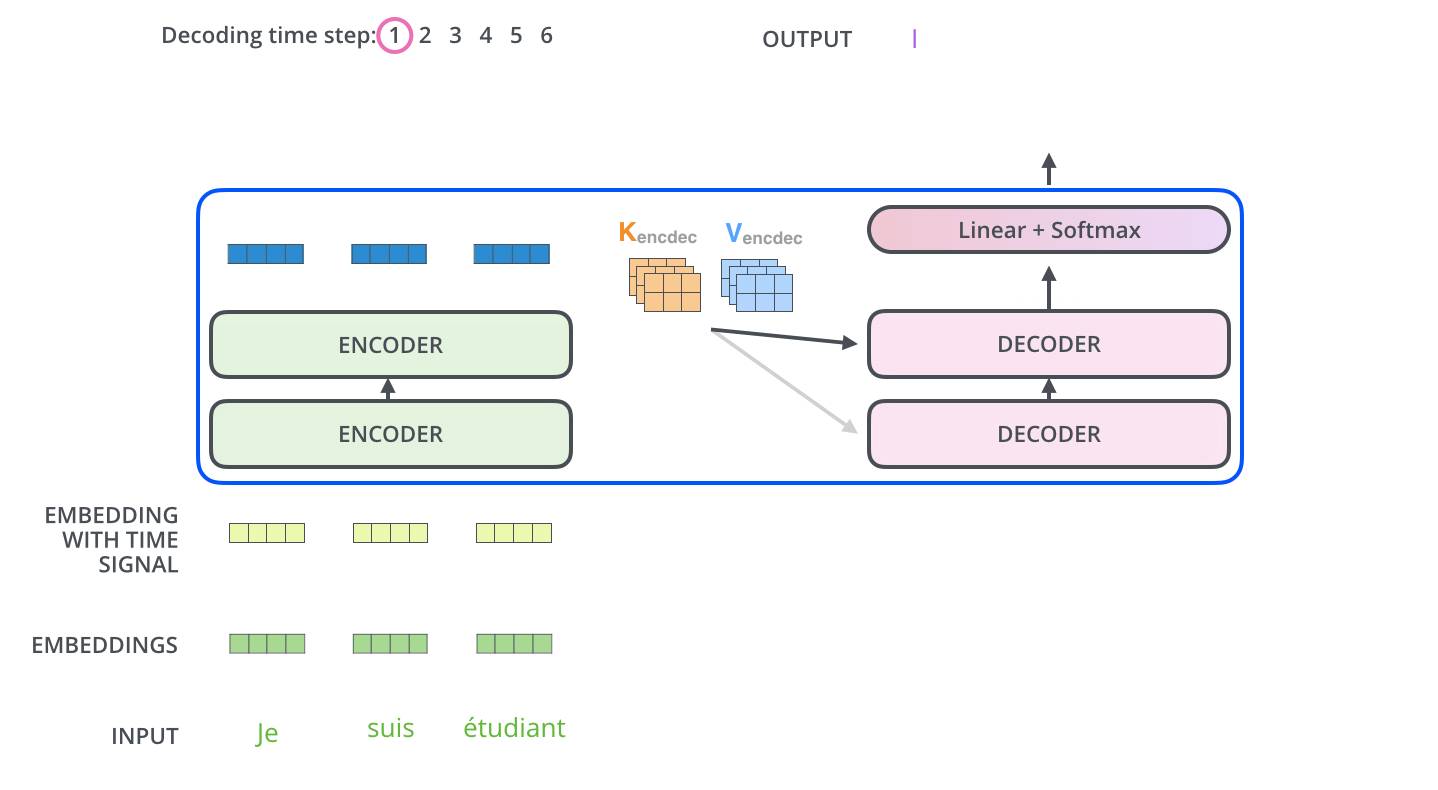
. ( – ).
, , . , , . , , , .
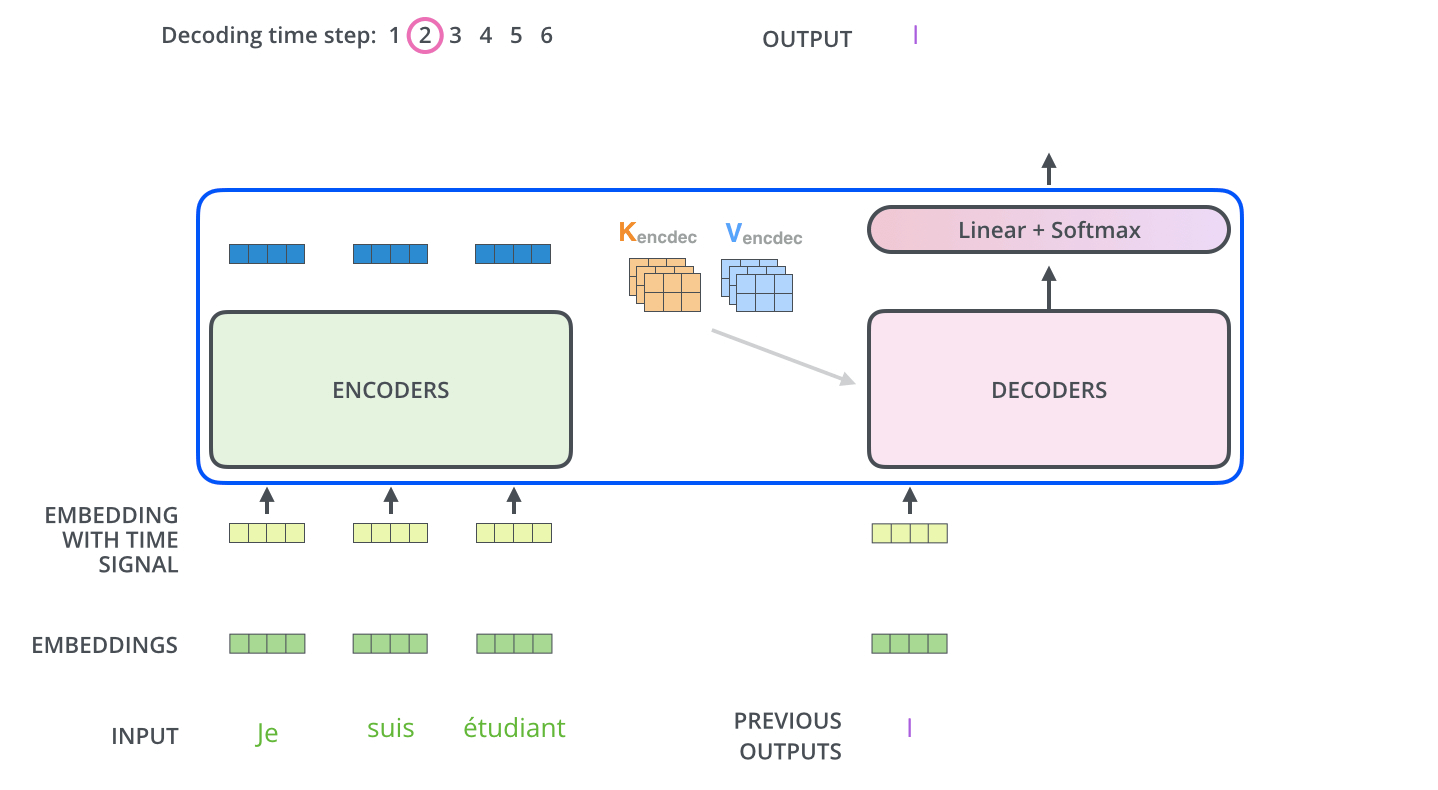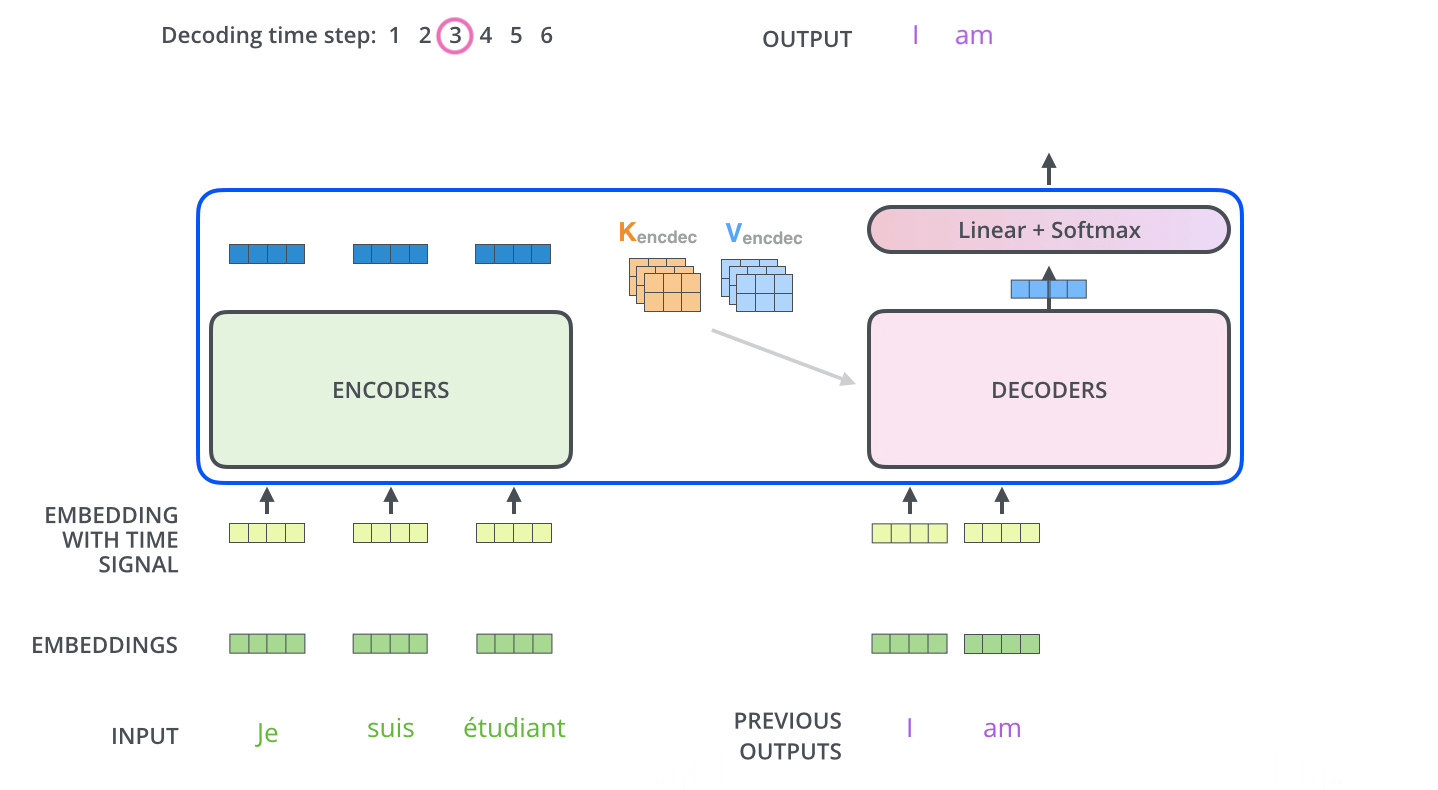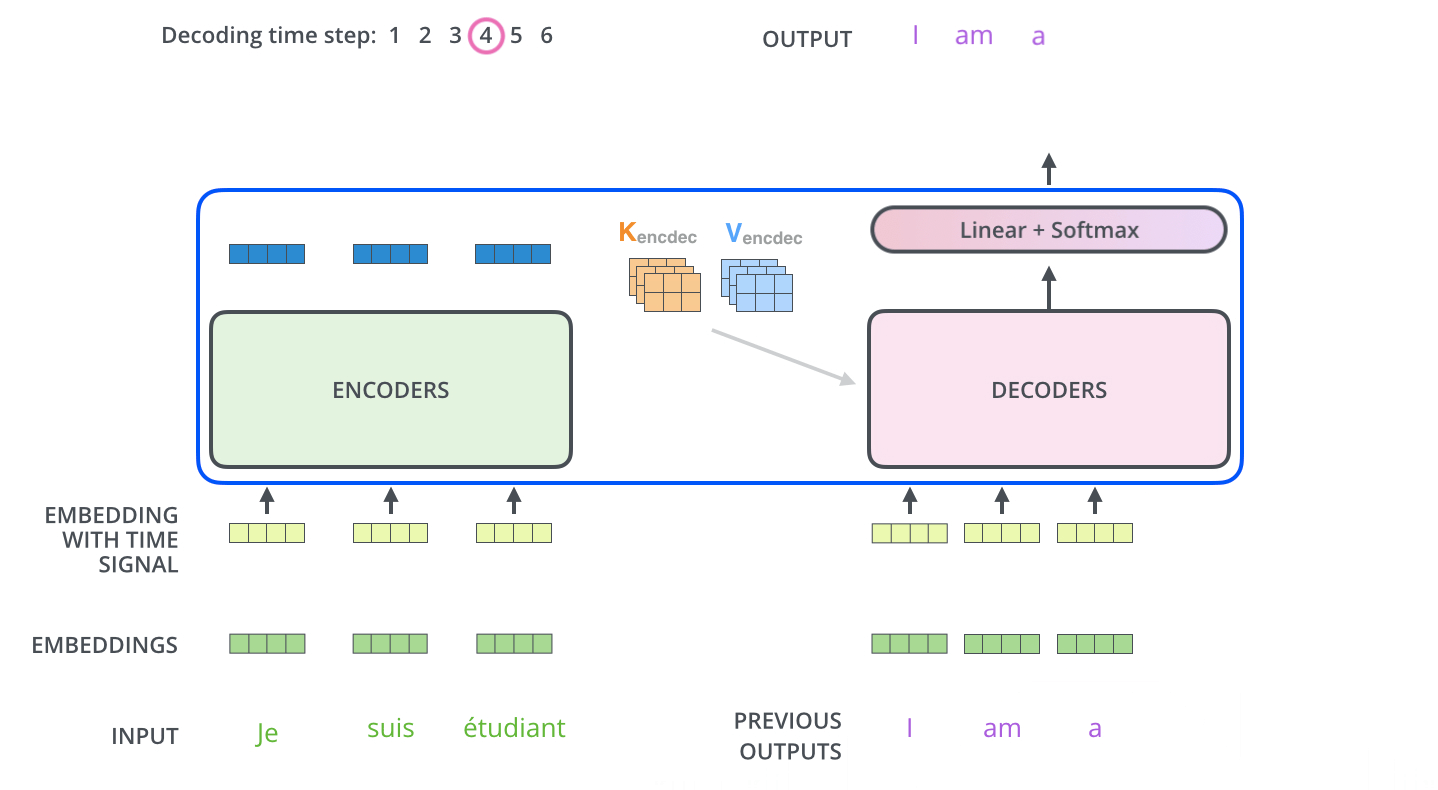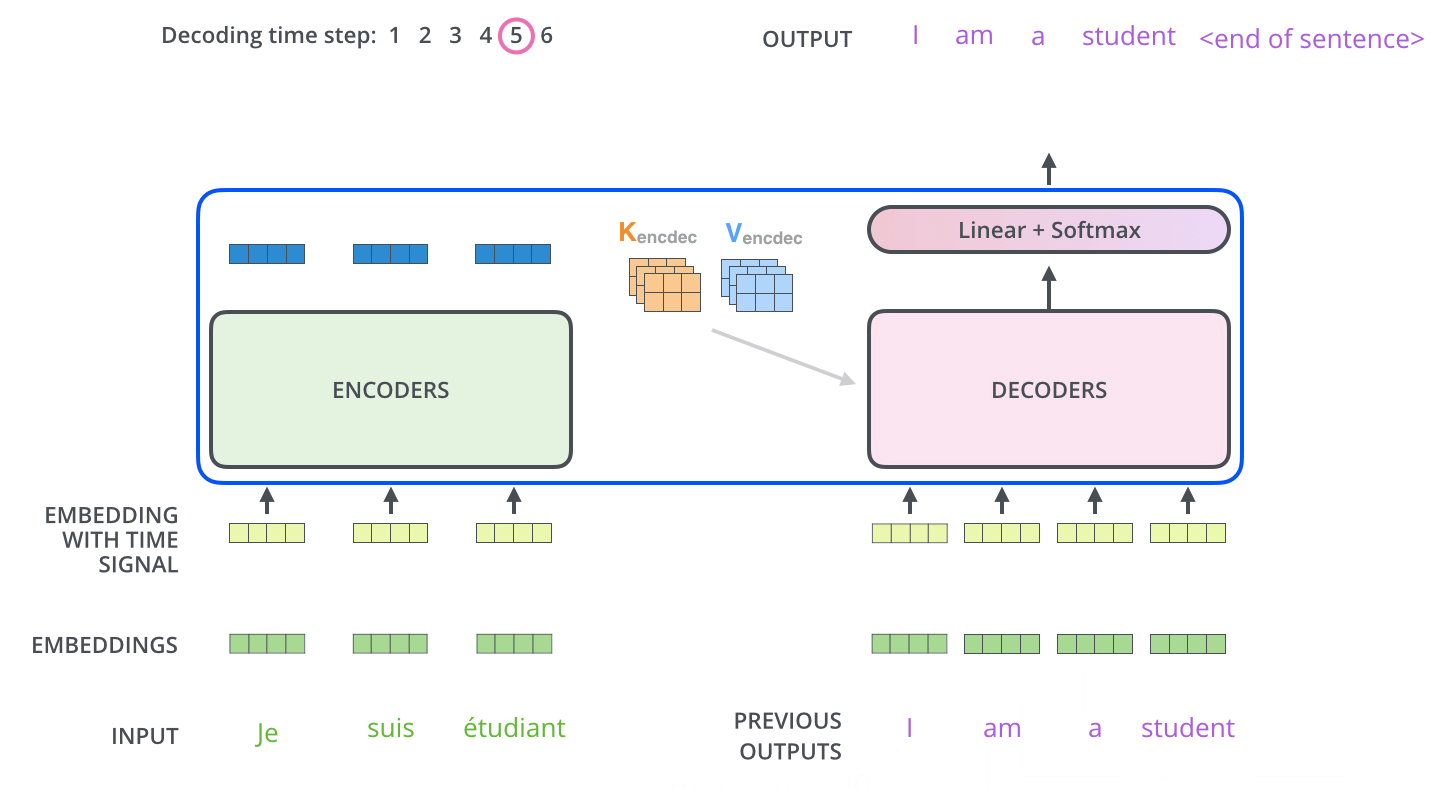
.
. ( –inf) .
«-» , , , , .
. ? .
– , , , , (logits vector).
10 (« » ), . , 10 000 – . .
( , 1). .
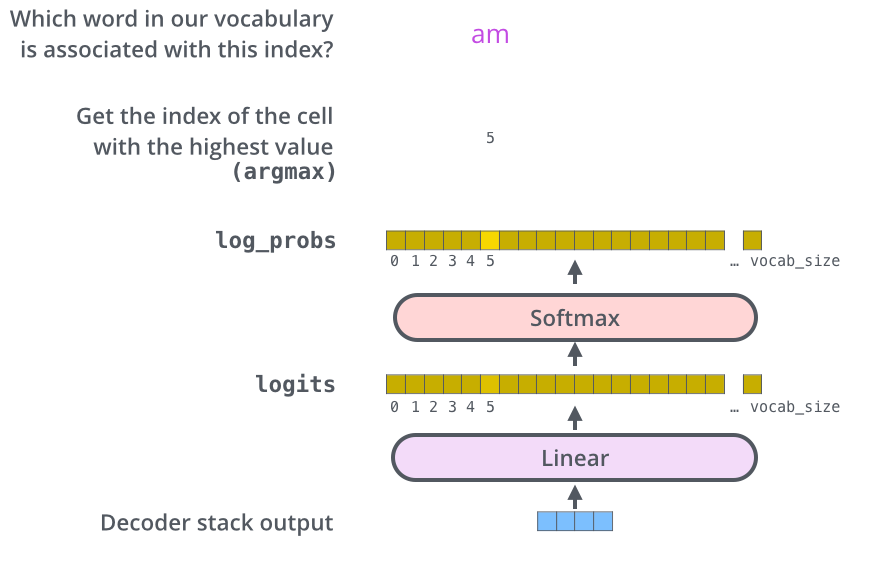
, , .
, , , , .
, . .. , .
, 6 («a», «am», «i», «thanks», «student» «<eos>» (« »).
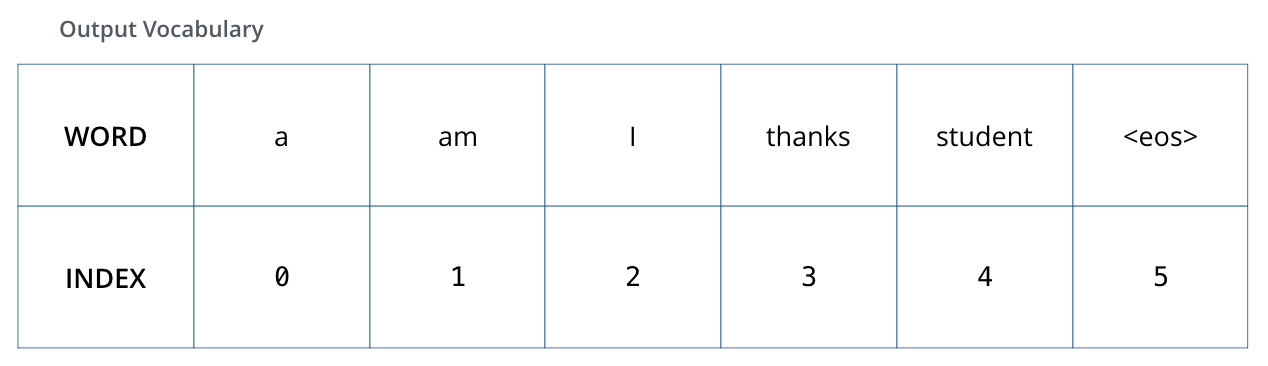
.
, (, one-hot-). , «am», :
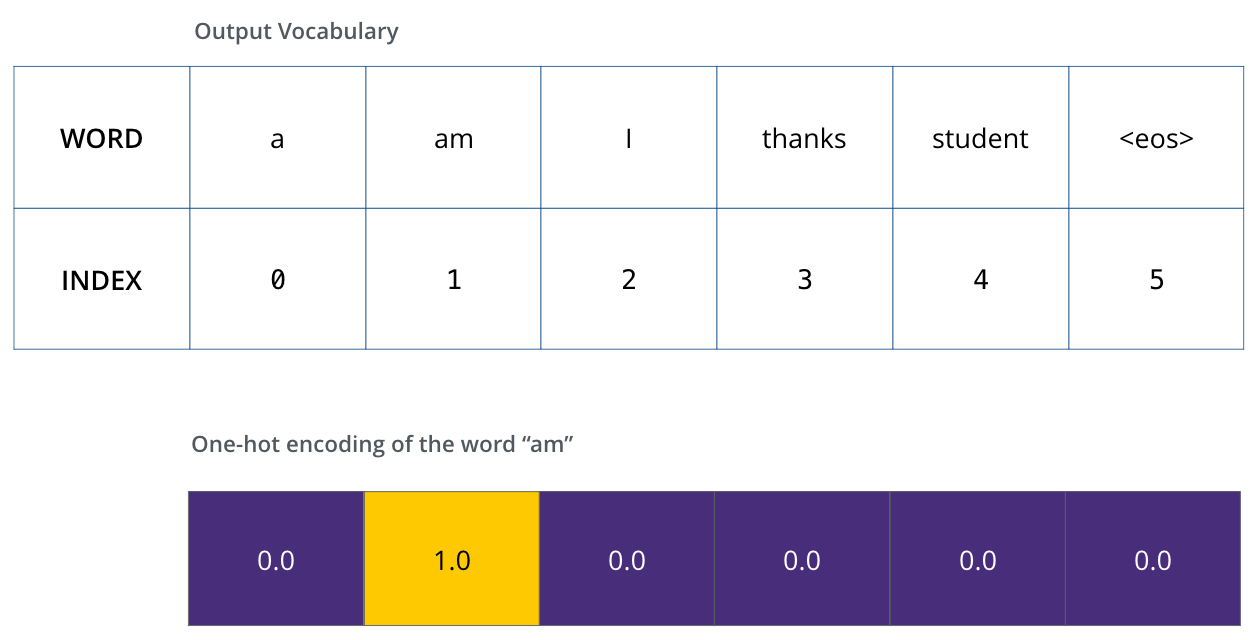
: one-hot- .
(loss function) – , , , .
, . – «merci» «thanks».
, , , «thanks». .. , .
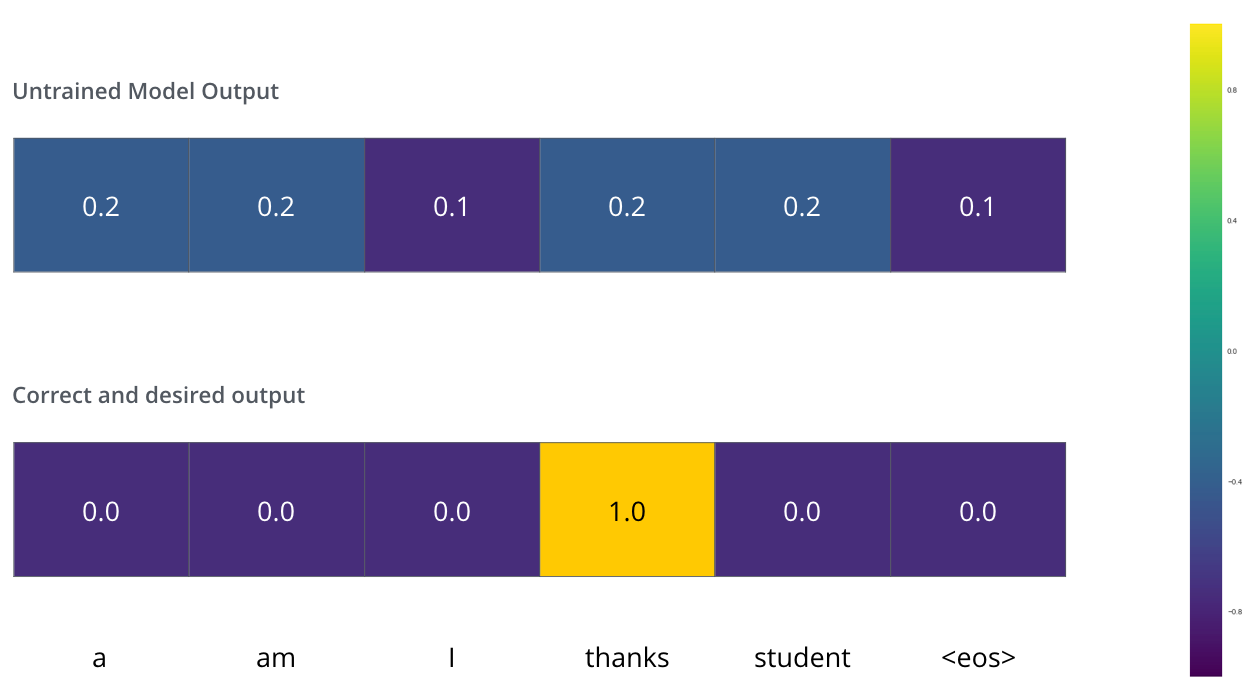
() , /. , , , .
? . , . -.
, . . , «je suis étudiant» – «I am a student». , , , :
- (6 , – 3000 10000);
- , «i»;
- , «am»;
- .. , .
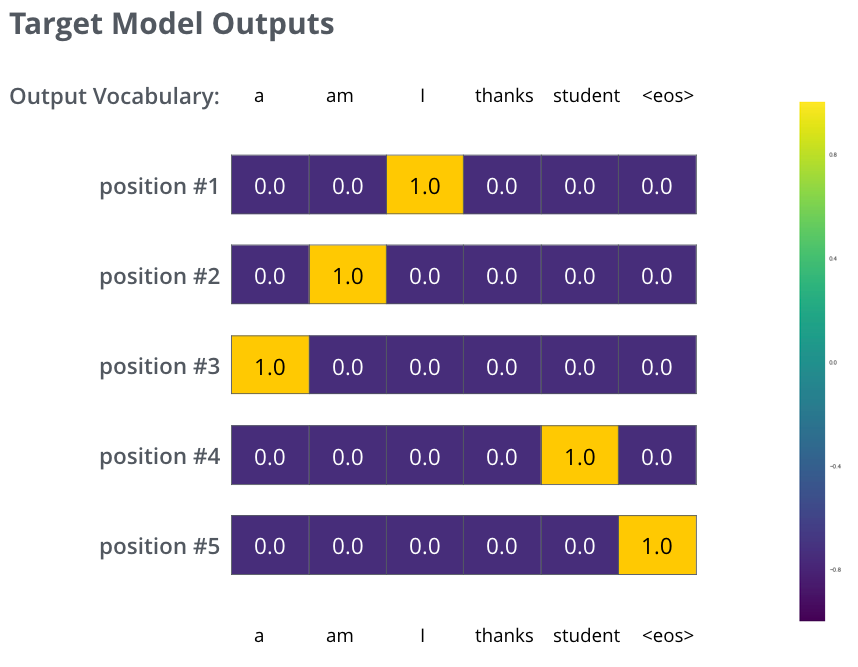
, :
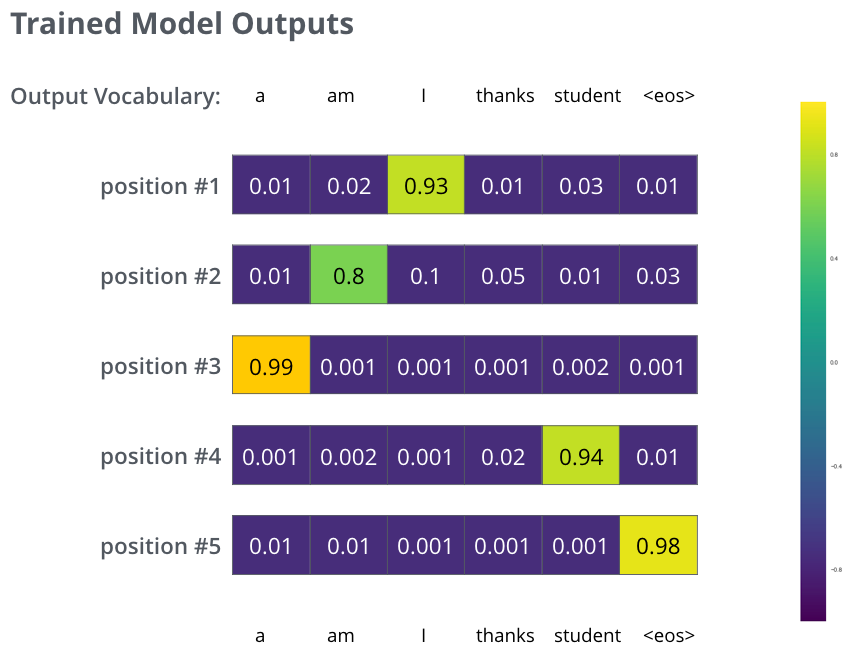
, . , , (.: ). , , , – , .
, , , , . , (greedy decoding). – , , 2 ( , «I» «a») , , : , «I», , , «a». , , . #2 #3 .. « » (beam search). (beam_size) (.. #1 #2), - (top_beams) ( ). .
, . , :
:
المؤلفون